저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게 l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다: l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다. l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다. 저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다. Disclaimer 저작자표시. 귀하는 원저작자를 표시하여야 합니다. 비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다. 변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
알츠하이머성 치매 환자의
숫자 처리 및 계산 특성
연세대학교 대학원
언어병리학협동과정
알츠하이머성 치매 환자의
숫자 처리 및 계산 특성
지도교수 김 향 희
이 논문을 석사 학위논문으로 제출함
2016년
12월
일
연세대학교 대학원
언어병리학협동과정
김주연의 석사 학위논문을 인준함
심사위원
김 향 희
인
심사위원
조 성 래
인
심사위원
윤 지 혜
인
감사의 글
입학을 위해 달려왔던 시간이 과거가 되어, 어느덧 졸업을 앞둔
미래가 기다리고 있는 시간이 왔습니다. 2년 동안 학문을 즐기고 진정
한 언어병리학을 공부할 수 있도록 지도해주신 김향희 교수님 감사하고
존경합니다. 온화한 미소로 아낌없는 조언을 해주신 윤지혜 교수님, 따
뜻한 카리스마로 이끌어주신 조성래 교수님 감사합니다. 언어재활사로
서의 소양을 알려주신 박혜원 선생님과 이영미 선생님 감사합니다. 제
가 가는 이 길의 귀감이 되어주시는 김정완 교수님 감사합니다. 또 좋
은 논문을 쓸 수 있도록 도와주신 서울시 치매지원센터 및 부산 요양병
원 관계자분들 감사합니다.
오합지졸로 시작해 일사불란하게 움직이다 화룡점정을 찍고 마
침내 유종의 미를 거둔 자랑스러운 동기들 린이, 혜경, 자은, 혜숙 언니
고마워. 실습으로 바쁜 와중에도 배려하고 도와준 솔희, 선우, 승현, 하
은, Kammy, 진영 언니, 재목, 성건 선배, 가영 언니 고마워. 호출하면
언제든 시간내주는 수민이(앞으로도 부탁해), 멀리서 응원 가득 보내주
는 소중한 친구들 은선, 소혜, 은영, 성우, 은애, 순철, 정은, 선미, 영화,
나래 선배, 연주 선배, 지연 언니 그리고 무적 친구들과 모든 친구들 고
마워.
마지막으로 더 큰 세상을 향해 나아가기 위한 발판을 마련해주
시고 전폭적인 지원과 격려를 해주시는 부모님과 동생, 그리고 모든 가
족들 너무나 감사하고 사랑하고 존경합니다. 언제나 겸손한 자세로 배
우고 공부하며 능력 있는 전문가로 발전하겠습니다. 감사합니다.
저 자
씀
차 례
표 차례 ··· ⅲ
그림 차례 ··· ⅴ
국문요약 ··· 1
Ⅰ. 서론 ··· 3
1. 이론적 배경 ··· 3
2. 연구의 필요성 및 목적 ··· 8
3. 연구 문제 ··· 10
Ⅱ. 재료 및 방법 ··· 11
1. 연구 대상 ··· 11
2. 연구 방법 ··· 15
가. 측정 도구 ··· 15
(1) 한국판 간이정신상태검사 ··· 15
(2) 노인우울척도 단축형 ··· 15
나. 연구 절차 ··· 16
(1) 자료 수집 ··· 16
(2) 숫자 처리 및 계산 ··· 16
다. 자료 분석 ··· 19
(1) 과제 채점 ··· 19
(2) 오류율 ··· 20
(3) 오류 유형 ··· 20
라. 통계 분석 ··· 24
Ⅲ. 결과 ··· 25
1. 숫자 처리 오류율 ··· 25
2. 숫자 처리 오류 유형 ··· 28
가. 숫자 이해 ··· 29
나. 숫자 산출 ··· 30
다. 숫자 변환 ··· 31
3. 계산 오류율 ··· 36
4. 계산 오류 유형 ··· 37
가. 덧셈 ··· 39
나. 뺄셈 ··· 40
다. 곱셈 ··· 43
라. 나눗셈 ··· 45
Ⅳ. 고찰 ··· 47
Ⅴ. 결론 ··· 52
참고문헌 ··· 53
Abstract ··· 57
표 차례
표 1. 대상자군별 정보 ··· 12
표 2. 대상자별 정보 ··· 13
표 3. 연구 과제 ··· 17
표 4. 아라비아 숫자 쓰기 오류 유형의 정의 및 예시 ··· 21
표 5. 한글 숫자 읽기 오류 유형의 정의 및 예시 ··· 22
표 6. 한글 숫자 쓰기 오류 유형의 정의 및 예시 ··· 23
표 7. 계산 오류 유형의 정의 및 예시 ··· 24
표 8. 숫자 처리 오류율 검정 결과 ··· 25
표 9. 환자별 숫자 처리 및 계산 오류 빈도 ··· 26
표 10. 정상 노인별 숫자 처리 및 계산 오류 빈도 ··· 27
표 11. 대상자군별 숫자 산출 오류 유형 빈도 ··· 30
표 12. 대상자군별 숫자 받아쓰기 오류 유형 빈도 ··· 31
표 13. 대상자군별 숫자 읽기 오류 유형 빈도 ··· 32
표 14. 환자별 한글 변환 오류 유형 빈도 ··· 34
표 15. 정상 노인별 한글 변환 오류 유형 빈도 ··· 35
표 16. 계산 오류율 검정 결과 ··· 36
표 17. 대상자군별 덧셈 오류 유형 빈도 ··· 39
표 18. 환자별 뺄셈 오류 유형 빈도 ··· 41
표 19. 정상 노인별 뺄셈 오류 유형 빈도 ··· 42
표 20. 환자별 곱셈 오류 유형 빈도 ··· 43
표 21. 정상 노인별 곱셈 오류 유형 빈도 ··· 44
표 22. 환자별 나눗셈 오류 유형 빈도 ··· 45
표 23. 정상 노인별 나눗셈 오류 유형 빈도 ··· 46
그림 차례
그림 1. McCloskey’s model ··· 4
그림 2. 환자군과 정상군의 숫자 처리 오류 유형 ··· 28
그림 3. 환자군과 정상군의 숫자 처리 오류 유형별 백분율 ··· 29
그림 4. 환자군과 정상군의 계산 오류 유형 ··· 37
그림 5. 환자군과 정상군의 계산 오류 유형별 백분율 ··· 38
국문요약
알츠하이머성 치매 환자의 숫자 처리 및 계산 특성
독립적인 생활이 가능한 경도 치매환자도 지속적인 인지 기능의
저하로 인해 숫자를 처리하고 계산하는 과정에서 어려움이 발생한다.
이에 본 연구에서는 알츠하이머성 치매 환자 및 일반 노인 각 16명씩을
대상으로 숫자 표기 방법에 따른 숫자 처리 및 계산 과제를 실시하였
다. 환자군은 정상군에 비해 숫자 처리와 계산 수행 시 오류율과 오류
유형에서 어떠한 차이가 있는지 살펴보았다.
연구 결과에 따르면 첫째, 환자군은 정상군보다 숫자 산출 및 숫
자 변환(숫자 받아쓰기, 숫자 읽기, 한글 변환)에서 오류율이 높았다. 숫
자 처리 오류 유형은 환자군이 정상군보다 다양하였고, 두 집단 모두에
서 구문적 오류가 가장 높았다. 둘째, 환자군은 정상군보다 덧셈과 곱셈
에서 오류율이 높았다. 계산의 오류 유형 또한 환자군이 정상군보다 다
양하였으며, 두 군에서 모두 산술 규칙 오류와 사실적 오류가 가장 많
았다. 여러 오류 유형 중, 받아내림 오류가 환자군에서 더 적게 나타난
원인은 정상군에서 암산으로 과제를 수행한 대상자가 많았기 때문이다.
셋째, 숫자 처리와 계산 사이에는 이중 해리가 있었다.
본 연구를 통해 숫자 표기법에 따라 분류된 아라비아 숫자와 한
글 숫자로 치매군에서 나타나는 숫자 처리 및 계산의 오류를 제시하고,
숫자 처리를 신경인지장애의 선별 문항으로 제안한 점에서 임상적 의의
를 찾을 수 있다. 후속 연구에서는 한국어의 음운 특성을 고려하여 숫
자 자극을 선정하고, 의미 기억의 영향이 최소한으로 적용되는 질문을
개발하여 치매 환자의 숫자 산출 특성 연구가 이루어져야겠다. 나아가
치매의 종류, 중증도 등의 기준을 설정하여 치매군 내에서의 숫자 처리
및 계산 특성을 비교 분석하는 연구가 이루어지길 기대해 본다.
1) 핵심되는 말: 알츠하이머 치매, 숫자 처리, 숫자 변환, 계산, 아라비아 숫자, 한글 숫자본 논문의 일부는 2016 대한치매학회 추계학술대회(2016.11.12.)에서 발표하였음.
알츠하이머성 치매 환자의 숫자 처리 및 계산 특성
<지도교수 김 향 희>
연세대학교 대학원 언어병리학협동과정
김 주 연
I. 서 론 1. 이론적 배경 숫자(number)는 크기, 양, 순서 등을 나타내는 추상적인 개념이며,1 전 세계에서 공통적으로 사용하는 아라비아 숫자(arabic numeral) 기호로 표현하 거나, 각 나라의 언어(verbal numeral)에 따라 다르게 명기될 수 있다. 그런데 숫자는 언어와는 다른 특성이 있다. 즉, 언어는 고유의 음소(phoneme) 체계가 있고, 음소가 모여 음절(syllable)이 형성되며, 음절 또는 음절이 모인 단어가 의미를 갖게 된다. 이와는 대조적으로 아라비아 숫자는 독립된 기호로서 각각 의 의미를 가질 수 있고, 문법 체계도 다르므로 단순한 위치의 배열에 의해 서로 다른 단위의 숫자 개념을 표시하게 된다. 이에 따라 언어 체계와 아라비 아 숫자 체계는 서로 다른 인지 영역을 분담하고 있을 것으로 추정되며, 뇌손 상으로 인하여 언어 체계는 유지되나 숫자 체계는 손상되는 또는 그 반대되는해리(dissociation) 현상이 일어날 수 있다.1 그런데 숫자 영역에는 숫자 처리 (number processing) 그리고 계산(calculation)과 관련된 체계가 따로 존재하 며 대표적으로 맥클로스키 모형(McCloskey et al, 1985, 1991)에 근거한다. 그림 1. McCloskey’s model (1991) 첫째, 숫자 처리 체계는 수를 이해하기 위한 요소들의 집합인 숫자 이 해(number comprehension)영역과 수를 생성하기 위한 요소들의 집합인 숫자 산출(number production)영역으로 구성된다. 숫자 이해 체계는 숫자 입력을 내부의 의미적 표상(semantic representation)으로 전환하는 역할을 하며, 이 의미적 표상은 후에 다른 처리 과정에서 사용된다. 숫자 산출 체계는 내부의 의미적 표상을 적절한 산출 형태로 전환하는 역할을 한다. 숫자 이해와 산출 의 각 하위 체계 내에는 아라비아 숫자(arabic number system, 예: 53)와 말 로 표현되는 숫자(verbal number system, 예: 오십삼)를 처리하는 별개의 요
소들이 있다. 둘째, 계산 체계에서는 산술 사실 지식(arithmetic fact
knowledge), 개념 지식(conceptual knowledge), 절차 지식(procedural
한 자릿수(single-digit) 계산으로 이루어져 있다. 절차 지식은 여러 자릿수 (multi-digit) 문제를 풀 때 요구되는 산술 알고리즘을 포함하며, 개념 지식은 산술 사실과 계산 과정에서 기초가 되는 산술 원리의 이해를 제공한다.3 이 모 형에서 숫자 변환(number transcoding)을 별개로 구분 짓지 않았지만 설명할 수 있다. 숫자 변환이란 아라비아 숫자를 말로 표현되는 숫자로 바꾸거나 또 는 말로 표현되는 숫자를 아라비아 숫자로 변형시키는 과정을 말한다. 이러한 숫자 변환 과제는 수 개념, 문법적, 어휘적 언어 영역 간의 연결이 정상적인지 를 측정하는 도구로 사용될 수 있다.4 숫자를 표기하는 방법에는 명수법과 기수법이 있다. 명수법은 수를 말 로 나타내는 것이고, 기수법은 수를 기호로 나타내는 것이다. 기수법으로 표현 하는 숫자에는 아라비아 숫자(1, 2, 3)와 로마 숫자(Ⅰ, Ⅱ, Ⅲ)가 대표적인데, 한자 문화권에서는 한자 숫자(一, 二, 三)도 함께 사용하고 있다.5 명수법은 각
나라의 언어권에 따라 한국어(하나, 둘, 셋), 영어(one, two, three), 일본어(い ち, に, さん)등으로 표현하는 것이다. 한편 수와 관련된 개념을 표현하는 말을 수사(數詞, numeral)라고 하는데 수사에는 ‘하나, 둘, 셋’으로 표현되는 기수(基 數, cardinal number; 크기를 나타내는 수)와 ‘첫째, 둘째, 셋째’로 표현되는 서 수(序數, ordinal number; 순서를 나타내는 수)가 있다.5 한국어의 수사는 언어 계통에 따라 순수 한국어인 고유어(예: 일곱, 열)와 한자어(예: 칠, 십)로 구분 하며, 두 계통 모두 서수, 기수, 정수(定數, 정확히 정해진 수, 예: 한, 두, 일), 부정수(不定數, 정확히 정해지지 않은 수, 예: 한두, 서너)를 나타내는 표현을 가진다.6 한글 숫자로 표기 할 때 20을 중심으로 그 이하의 수에서는 고유어 수사를, 100이상의 수에서는 한자어 수사를 허용한다.7 단위를 포함하여 천의 단위까지 사용하는 본 연구에서는 한자어 수사로 통일하나 고유어를 사용하였 을 때 의미가 정확하다면 정반응으로 처리하였다.
애진단 통계 편람 제5판(Diagnostic and Statistical Manual of Mental Disorders-Fifth, DSM-V, 2014)에 따르면, 치매를 주요 신경인지장애(major neurocognitive disorders)로 분류하였다. 하나 또는 그 이상의 인지 영역(복합 적 주의, 집행 기능, 학습과 기억, 언어, 지각-운동 또는 사회 인지)에서 인지 저하가 이전의 수행 수준보다 현저히 낮아야 하고, 이는 가급적 표준화된 신 경심리검사에 의해 평가가 입증되어야 한다. 또 인지 결손은 일상 활동에서 독립성을 방해하고, 인지 결손이 섬망이 있는 상황에서만 발생하는 것이 아니 어야 한다.8 가장 대표적인 치매의 원인질환은 알츠하이머병(Alzheimer’s disease, 이하 AD)으로 전체 치매의 60∼70% 정도를 차지한다. 그 다음으로 흔한 것은 혈관성 치매(vascular dementia, 이하 VD)로 전체 치매의 약 30% 를 차지한다.9 국내의 치매 선별검사 및 신경심리검사에서 숫자가 포함된 과제 는 대부분 계산 중심이기 때문에 계산을 제외한 숫자 처리에서 나타나는 AD 의 특성 연구는 부족한 편이다. 하지만 측두엽과 두정엽의 혈류 및 대사 감소 로 AD가 발병하는 것을 고려하면, 이들은 치매 초기 단계에서 숫자와 관련된 장애가 발생할 수 있음을 예상할 수 있다.10-18 AD는 크기 비교(magnitude comparison)과제 중 아라비아 숫자 비교 과제보다 구어 숫자 비교 과제에서 오류율이 높았다.18 숫자 크기 비교 과제에서 오류가 낮은 원인은 이 과제의 난이도가 다른 과제보다 상대적으로 쉽기 때문이다.19 숫자 변환의 숫자 받아 쓰기에서는 AD가 정상군보다 오류율이 높고 또 다양한 오류 유형이 나타났으 며, 아라비아 숫자 받아쓰기보다 구어 숫자 받아쓰기에서 오류율이 높았다.18 아라비아 숫자 읽기와 아라비아 숫자 받아쓰기에서는 구문적 오류가 가장 높 았으며 아라비아 숫자를 구어 숫자로 변환하는 과제에서는 특정 코드(code; 아라비아 숫자 또는 언어 숫자)가 반복되거나 일부만 반복되는 이동 오류 (shift error)가 정상군보다 유의하게 높았다.11,17,18,20 이동 오류는 방해 오류와 보속 오류로 나뉘는데 그 중 방해 오류는 AD의 특징이며 진단 기준으로 적용
할 수 있다고 하였다.21 AD가 숫자 변환에서 오류가 높은 원인은 어휘 및 구 문 처리, 읽기, 쓰기가 포함된 언어와 숫자 처리를 하는데 어려움이 있기 때문 이다.20,22 계산 특성을 살펴보면 경도 AD는 한 자릿수와 여러 자릿수로 구성된 덧셈과 뺄셈, 한 자릿수 나눗셈 능력이 유지된 반면 중등도 AD는 한 자릿수 덧셈 능력만 보존된 것으로 나타났다. 경도 및 중등도 AD 모두 연산 대치 오 류와 숫자 위치 오류가 가장 많았다. 특히 중등도 AD는 경도 AD보다 오류 유형이 다양하였고 오류율 또한 높았다.23 덧셈과 곱셈에서의 AD와 VD의 산 술 능력을 비교한 결과, 두 집단 간의 오류율 차이는 없었지만 각 집단 내의 중증도와 산술 능력은 상관성이 있었는데 중증도가 높아질수록 산술 능력은 저하되었다.24 초기 AD는 정상군보다 숫자 처리 오류율이 낮았지만 두 군 간 의 통계적 차이는 없었고, 계산의 산술 사실 지식과 절차 지식은 현저히 떨어 졌다. AD가 계산에서 오류가 발생하는 원인은 계산 과제가 추가적인 인지기 능이 포함되는 매우 복잡한 과제이기 때문이다.20 한편 산술 사실 지식과 절차 지식, 숫자 처리와 계산 사이에 이중 해리(double dissociation)가 있었고,25 몇 명의 경도 AD는 숫자 처리 중 숫자 이해와 숫자 산출사이에서도 해리가 있었 다.10
2. 연구의 필요성 및 목적 일정 수준의 독립적인 생활이 가능한 경도의 치매도 전반적인 인지 기능의 저하가 진행 중이므로 숫자를 처리하고 또 계산 하는 과정에서 분명 어려움이 존재할 것이다. 기억력의 손상은 치매의 주요 특성이며 치매 초기 단계에서 환자들이 호소하는 주된 증상이다.26 그래서 치매의 실산증(acalculia) 은 치매를 진단하는데 있어서 중요한 주제가 아니었기 때문에 소수의 연구만 이 AD의 수학적 기술에 대해 연구하였다. 그러나 뇌에 병리학적 문제가 발생 할 경우 계산의 방해가 일어나고, 이는 치매에서도 실산증이 일어날 수 있음 을 예상할 수 있다.27 이에 본 연구에서는 AD가 숫자 처리와 계산에서 어떠한 특성이 나타나는지 분석하고자 하였다. 치매를 진단하기 위해서는 병력 청취, 인지기능 및 정신상태 평가, 신 체검사와 신경학적 검사, 표준화된 신경심리검사, 일상생활능력평가, 뇌영상검 사 등의 종합적인 평가가 필요하다.9 그러나 한국에서의 선별검사 및 신경심리 평가는 아라비아 숫자로 구성된 과제(‘동전으로 1000원 만들기’, ‘숫자 외우기’, ‘간단한 계산’, ‘시각 말하기’ 등)를 통해 숫자 능력을 평가한다. 최근 국내에 소개된 DemTect은 경도인지장애 및 초기 치매를 선별하는 평가도구로 2000 년에 독일 버전으로 처음 발표되었으며, 미국을 포함하여 세계 여러 나라에서 사용되고 있는 인지선별검사도구이다.22 5가지의 하위 과제들로는 10개의 단어 목록, 숫자 변환, 단어 유창성, 숫자 거꾸로 외우기, 단어 목록의 지연회상이 있다. 숫자 변환 문항은 아라비아 숫자를 한글 숫자로, 한글 숫자를 아라비아 숫자로 바꾸게 한다. DemTect은 국내에서 처음으로 한글 숫자를 숫자 변환의 한 문항으로 제시하였으며 이는 숫자 표기 방법을 구분하여 숫자 처리 평가가 가능함을 의미한다. 따라서 본 연구에서는 한글 숫자가 포함된 숫자 처리 과제에서 치매
환자군이 일반 노인군에 비해 어떠한 양상을 나타내는지 살펴보고자 하였다. 그러나 한글 숫자, 즉 명수법을 제시 자극으로 한 과제는 결과가 도출되었을 때 언어, 숫자, 인지 등 손상 영역의 구분이 모호할 수 있다. 그 이유는 초기 치매에서도 실독증(dyslexia) 또는 실서증(dysgraphia)이 발생할 수 있으므로 과제에 대한 오반응이 결코 숫자 처리만의 장애로 단정 지을 수 없기 때문이 다. 따라서 명수법을 포함하되 기타 언어적 문제가 최소한으로 영향을 끼치는 기수법 과제를 통해 초기 치매의 특성을 분석하고자 하였다. 해외의 선행연구 에서 수행한 여러 과제를 종합하여 연구 과제를 구성하였고, 숫자 사용의 대 표 과제인 계산을 함께 진행하였다. 기존의 검사 도구에서 한 자릿수와 두 자 릿수의 계산을 제시한 것과 달리, 본 연구에서는 세 자릿수의 덧셈과 뺄셈 과 제를 추가함으로써 변별성을 두었다.
3. 연구 문제 본 연구의 연구 문제는 다음과 같다. 알츠하이머성 치매 환자군은 일반 노인군과 비교하여, 1. 숫자 처리 수행력에서 가. 오류율의 차이가 있는가 나. 오류 유형의 차이가 있는가 2. 계산 수행력에서 가. 오류율의 차이가 있는가 나. 오류 유형의 차이가 있는가
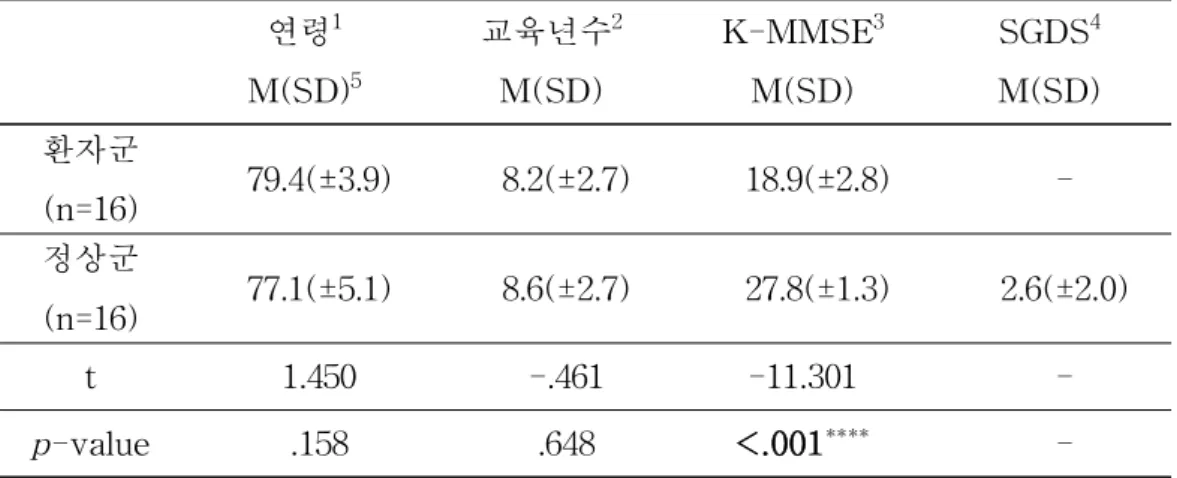
II. 재료 및 방법 1. 연구 대상 본 연구의 환자군은 서울 소재 ○○치매지원센터, 경기도 소재 △△ 노인전문요양병원, 부산 소재 □□노인전문요양병원에서 모집한 치매 환자 20 명 중 다음의 조건을 만족하는 16명을 선정하였다. 정상군은 서울 및 부산 지 역에서 모집한 일반 노인 25명 중 조건을 만족하는 16명을 선정하였다. 두 집 단의 성비는 각 남자 8명, 여자 8명으로 일치하였다. 환자군은 (1) 신경과 또는 정신과 전문의가 신경심리학적 평가를 하여 AD로 진단받고, (2) 전반적퇴화척도(Global Deterioration Scale, 이하 GDS)에
서 3점(경미한 인지장애) 또는 4점(중등도의 인지장애)으로 평가받고,28 (3) 한
국판 간이정신상태검사(Korean Mini-Mental State Examination, 이하
K-MMSE)의 읽기, 쓰기 문항에서 만점(2점)을 획득하였으며, (4) 초등학교 졸 업(6년)이상의 교육년수를 가진 자로 선정하였다. 연령 범위는 73세에서 85세 로 평균 79.4세(±3.9), 평균 교육년수는 8.2년(±2.7), 평균 K-MMSE 점수는 18.9점(±2.8)이었다. 정상군은 (1) 사전 면담을 실시하여 신경과 및 정신과적 질환 또는 사 고력에 영향을 줄 수 있는 질환이 없고, (2) K-MMSE의 규준에 따른 총점수 가 정상 범주에 속하며29 읽기 및 쓰기 문항에서 만점(2점)을 획득하고, (3) 노
인우울척도 단축형(Short Form of Geriatric Depression Scale, 이하 SGDS)의
규준에 따른 총점수가 8점 이하,30 (4) 초등학교 졸업(6년)이상의 교육년수를
가진 자로 선정하였다. 연령 범위는 70세에서 88세로 평균 77.1세(±5.1), 평균 교육년수는 8.6년(±2.7), 평균 K-MMSE 점수는 27.8점(±1.3), 평균 SGDS 점 수는 2.6점(±2.0)이다.
연령1 M(SD)5 교육년수2 M(SD) K-MMSE3 M(SD) SGDS4 M(SD) 환자군 (n=16) 79.4(±3.9) 8.2(±2.7) 18.9(±2.8) -정상군 (n=16) 77.1(±5.1) 8.6(±2.7) 27.8(±1.3) 2.6(±2.0) t 1.450 -.461 -11.301 -p-value .158 .648 <.001**** -두 집단 간의 연령, 학력, K-MMSE 점수를 독립표본 t검정
(Independent t-test)을 통해 비교하였다. 그 결과, K-MMSE 점수는 환자군이 정상군보다 유의하게 낮았으나 연령과 교육년수는 유의한 차이가 없었다(표 1, 표 2).
표 1. 대상자군별 정보
1 나이를 나타내며 단위는 ‘세’ 2 교육년수를 나타내며 단위는 ‘년’
3 K-MMSE(Korean Mini-Mental State Examination), 점수를 나타내며 단위는 ‘점’ 4 SGDS(Short Form of Geriatric Depression Scale), 점수를 나타내며 단위는 ‘점’ 5 M(Mean)은 평균, SD(Standard Deviation)는 표준편차
대상자 성별1 연령2 교육년수3 GDS4 K-MMSE5 SGDS6 환자1 F 73 12 3 22 -환자2 M 77 6 3 22 -환자3 M 77 12 3 21 -환자4 M 83 6 3 20 -환자5 F 74 6 4 17 -환자6 F 75 6 4 16 -환자7 M 75 12 4 21 -환자8 F 77 6 4 20 -환자9 F 81 6 4 17 -환자10 F 81 6 4 15 -환자11 M 81 11 4 22 -환자12 M 82 6 4 24 -환자13 F 83 6 4 17 -환자14 M 83 9 4 16 -환자15 M 83 12 4 17 -환자16 F 85 9 4 16 -정상1 F 71 6 - 27 4 정상2 F 72 6 - 29 1 정상3 F 70 9 - 29 1 정상4 F 73 12 - 27 2 정상5 M 73 12 - 30 3 정상6 F 76 6 - 29 2 정상7 M 76 12 - 28 0 정상8 M 76 12 - 29 4 정상9 F 77 6 - 28 0 정상10 M 77 9 - 27 3 정상11 M 81 12 - 28 4 표 2. 대상자별 정보
정상12 M 76 9 - 26 5 정상13 M 83 6 - 25 3 정상14 F 79 6 - 27 2 정상15 F 85 6 - 28 7 정상16 M 88 9 - 27 0 1 M(male)은 남성, F(female)는 여성 2 나이를 나타내며 단위는 ‘세’ 3 교육년수를 나타내며 단위는 ‘년’
4 GDS(Global Deterioration Scale), 단위는 ‘점’
5 K-MMSE(Korean Mini-Mental State Examination), 단위는 ‘점’ 6 SGDS(Short Form of Geriatric Depression Scale), 단위는 ‘점’
2. 연구 방법 가. 측정 도구 (1) 한국판 간이정신상태검사(K-MMSE) 대상자의 전반적 인지기능 및 연구 과제를 수행하기 위한 선별 문항 으로서의 읽기, 쓰기 평가를 위해 K-MMSE를 시행하였다. K-MMSE는 시간 지남력(5점), 장소 지남력(5점), 기억등록(3점), 기억회상(3점), 주의집중과 계산 능력(5점), 언어(8점), 시각적 구성(1점) 등 총 30점 만점으로 구성된다. 24점 이상은 정상, 24점 미만부터 20점 이상은 경도, 20점 미만부터 10점 이상은 중 도, 10점 미만은 심도 치매로 선별된다.31 (2) 노인우울척도 단축형(SGDS)
노인우울척도(Geriatric Depression Scale) 30문항을 15문항으로 축약 한 SGDS를 사용하였다. SGDS는 1, 5, 7, 11, 13번의 문항에서 ‘아니오’ 대답 시 1점, 그 외 문항에서 ‘예’ 대답 시 1점을 획득한다. 우울증이 노인의 인지 수준에 영향을 끼친다는 연구에 따라 주요 우울증의 1차 선별을 위한 절단점 8점을 대상자 선정 기준으로 설정하였다. 따라서 8점 이하의 일반 노인만을
나. 연구 절차 (1) 자료 수집 본 검사 실시 전, 연구에 대한 설명 및 연구 참여 동의를 구하였다. 사례 면담을 통해 대상자의 이름, 나이, 교육년수에 대한 정보를 수집하였고, 수집된 정보는 면담지에 기록하였다. 검사는 대상자와 검사자가 일대일로 진 행되었으며 청각적 과제는 1회만 들려주는 것을 원칙으로 하였다. 숫자 처리 과제는 한 글자 당 5cm × 4cm 크기로 구성된 PDF파일을 아이패드로 제시하 였고, 계산 과제는 한 글자 당 2cm × 2cm 크기로 A4용지에 인쇄하여 제시하 였다. 대상자가 피곤함을 호소할 경우, 약 30분의 휴식 후 재시작 하였다. (2) 숫자 처리 및 계산 숫자 처리 과제는 숫자 이해, 숫자 산출, 숫자 변환으로 구성하였으며 연구용 숫자는 Sala SD 등(2000)을 인용하였다.17 숫자는 숫자의 자릿수(일, 십, 백, 천)와 숫자 배열에서 ‘0’의 위치를 고려하여 선정하였다. 계산 과제는 덧셈, 뺄셈, 곱셈, 나눗셈으로 구성하였으며 초등학교 3학 년 수준의 난이도로 일치시켰다. 따라서 덧셈과 뺄셈은 한 자릿수부터 세 자 릿수까지의 숫자로 구성하였고, 곱셈과 나눗셈은 한 자릿수와 두 자릿수로 구 성하였다(표 3).
분류 제시 자극 목표 문항 숫자 이해 시각적 아라비아 숫자 큰 수 고르기 11 / 13 380 / 308 537 / 720 9018 / 1908 6128 / 6150 4370 / 4106 숫자 산출 구어 질문 아라비아 숫자 쓰기 1년은 며칠 입니까? (365) 하루는 몇 시간 입니까? (24) (돈을 보여주고) 이것은 얼마입니까? (1500) 생년월일이 언제입니까? (년, 월, 일) 숫자 변환 시각적 아라비아 숫자 한글 숫자 쓰기 40 / 76 314 / 409 / 720 3207 / 8039 / 4370 / 2521 / 6002 한글 숫자 읽기 청각적 한글 숫자 아라비아 숫자 쓰기 계산 덧셈 아라비아 숫자 쓰기 (a산술규칙) 8 + 8 = 16 58 + 47 = 105 604 + 25 = 629a(n+0=n) 뺄셈 426 – 108 = 318a(n-0=n) 14 – 4 = 10a(n-n=0) 320 – 27 = 293 곱셈 10 × 3 = 30a(n×1=n, n×0=0) 7 × 4 = 28 47 × 6 = 282 나눗셈 7 ÷ 1 = 7a(n÷1=n) 9 ÷ 3 = 3 24 ÷ 2 = 12a(n÷n=1) 표 3. 연구 과제
① 숫자 이해 숫자 이해를 평가하기 위해 숫자 크기 비교를 실시하였다. 문항은 두 자릿수 1개, 세 자릿수 2개, 네 자릿수 3개로 모두 6개이며, 대상자는 시각적 자료로 제시된 두 개의 아라비아 숫자(예: 1, 2)를 보고 큰 수를 선택하였다. ② 숫자 산출 숫자 산출을 평가하기 위해 숫자와 관련된 정보를 묻는 질문에 응답 하였다. 문항은 모두 4개이며 의미 지식이 최소한으로 내포되어 있는 것으로 구성하였다. 질문은 ‘일 년의 총 날짜 수(365)’, ‘하루의 총 시간(24)’, ‘돈 세기 (1500)’, ‘대상자의 생년월일(예: 1954. 10. 14)’이며 응답은 아라비아 숫자로 쓰 는 것이었다. ③ 숫자 변환 숫자 변환을 평가하기 위해 3가지의 하위 과제를 실시하였다. 각 과제 는 두 자릿수 2개, 세 자릿수 3개, 네 자릿수 5개로 각 10개씩 모두 30개이다. 과제의 유형은 청각적으로 제시된 한글 숫자를 아라비아 숫자로 쓰기(이하, 숫자 받아쓰기), 시각적으로 제시된 아라비아 숫자를 한글 숫자로 읽기(이하, 숫자 읽기), 시각적으로 제시된 아라비아 숫자를 한글 숫자로 쓰기(이하, 한글 변환)로 구성하였다.
④ 계산 계산을 평가하기 위해 사칙연산(덧셈, 뺄셈, 곱셈, 나눗셈)을 실시하였 다. 모든 문제는 가로 방향의 시각적 아라비아 숫자로 제시하였고, 대상자가 원하는 경우에는 문제를 세로 방향으로 전환하여 수행하는 것을 허용하였다. 덧셈과 뺄셈은 한 자릿수, 두 자릿수, 세 자릿수로 구성하였고, 곱셈과 나눗셈 은 한 자릿수와 두 자릿수로 구성하였다. 네 가지의 연산에는 각 연산에서 적용되는 산술 규칙을 포함하였다. 각 연산의 산술규칙은 덧셈 ‘n+0=n’, 뺄셈 ‘n-n=0’ 과 ‘n-0=n’, 곱셈 ‘n×1=n’ 과 ‘n×0=0’, 나눗셈 ‘n÷1=n’ 과 ‘n÷n=1’이다. 다. 자료 분석 (1) 과제 채점 과제의 채점은 정반응(1점), 오반응(0점)으로 처리하였다. 과제 응답 시, 한자어 숫자 사용을 원칙으로 하나 한자어와 고유어 숫자 사용은 개인의 선호도에 따라 다르게 나타날 수 있다.7 따라서 한자어 또는 고유어에 관계없 이 수의 의미를 정확히 전달하였다면 정반응으로 하였다. 본 연구 과제의 총 문항은 52개이고, 총 점수는 52점이다. 중도 포기 문항은 오반응으로 처리하였 다.
오류 유형 각 오류 유형의 빈도총 오류의 수 × 오류율 총 문항의 수오류 빈도 × (2) 오류율 오류율은 총 9가지의 하위 과제(숫자 이해, 숫자 산출, 숫자 받아쓰기, 숫자 읽기, 한글 변환, 덧셈, 뺄셈, 곱셈, 나눗셈)로 나누어 분석하였다. 수식은 각 하위 과제 내의 총 문항 수 중 오반응 한 문항에 대한 백분율이다. 중도 포기 문항은 오반응으로 처리하여 오류율 분석에 포함하였다. 계산의 산술 규 칙 오류는 연산 오류 분석 후 추가적인 오류 유형 분석이기 때문에 연산에서 분석한 결과만을 오류율로 산출하였다. (3) 오류 유형 오류 유형은 응답 방식(아라비아 숫자 또는 한글 숫자)에 따라 다르 며, 중도 포기 문항은 오류 유형 분석에 포함하지 않았다. 각 하위 과제에서의 오류 유형은 오류 빈도로 분석하였다. 모든 오류 유형을 분석한 후, 하위 과제 의 구분 없이 숫자 처리와 계산에서 나타난 총 오류의 수 중 각 오류 유형에 대한 백분율을 산출하였다.
오류 유형 정의 예시 구문 오류 구성하고 있는 각각의 숫자는 같으나 구조 가 틀려 숫자 전체의 크기가 변하는 것 365 → 3650 어휘 오류 숫자의 구조는 동일하나 구성 요소인 개별 적 숫자들이 전혀 다른 것으로 바뀌는 것 365 → 367 보속 오류 제시 자극과 동일하게 반복해서 쓰는 것 365 → 333 방해 오류 목표 자극에 도달하지 못하고 제시 자극으 로 다시 돌아와서 숫자와 한글이 섞이는 형 태가 되는 것 365 → 3백6십오 복합 오류 여러 가지 오류가 동시에 나타나는 것 365 → 3십65 숫자 분리 오류 제시 자극이 하나씩 분리되는 것 365 → 3, 6, 5 베껴 쓰기 오류 제시 자극을 그대로 베껴 쓰는 것 365 → 365 자소 오류 숫자의 형태를 완전히 갖추지 못한 것 6 → ㅇ 기억 오류 의미 기억 손상으로 응답하지 못한 것 무응답 ① 숫자 이해 숫자 이해의 오류 유형은 작은 숫자를 선택하는 크기 비교 오류 1개 로 구성하였다. ② 숫자 산출 숫자 산출의 오류 유형은 구문 오류, 어휘 오류, 보속 오류, 방해 오류, 복합 오류, 숫자 분리 오류, 베껴 쓰기 오류, 자소 오류, 기억 오류 등 총 9개 로 구분하였다.17,18 환자군의 경우 의미 기억의 저하로 응답하지 못하는 질문 이 발생할 수 있으므로 기억 오류를 포함하였다(표 4). 표 4. 아라비아 숫자 쓰기 오류 유형의 정의 및 예시
오류 유형 정의 예시 구문 오류 구성하고 있는 각각의 숫자는 같으나 구 조가 틀려 숫자 전체의 크기가 변하는 것 365 → 삼천육백오십 어휘 오류 숫자의 구조는 동일하나 구성 요소인 개 별적 숫자들이 전혀 다른 것으로 바뀌는 것 365 → 삼백육십일 보속 오류 제시 자극과 동일하게 반복해서 쓰는 것 365 → 삼삼삼 숫자 분리 오류 제시 된 자극이 하나씩 분리되는 것 365 → 삼, 육 ③ 숫자 변환 아라비아 숫자 받아쓰기의 오류 유형은 기억 오류를 제외하고 (표 4) 와 동일하다. 한글 숫자 읽기의 오류 유형은 구문 오류, 어휘 오류, 보속 오류, 숫자 분리 오류 등 총 4개로 구분하였다(표 5).17,18 한글 숫자 쓰기의 오류 유 형은 구문 오류, 어휘 오류, 보속 오류, 방해 오류, 복합 오류, 숫자 분리 오류, 베껴 쓰기 오류, 자소 오류 등 총 8개로 구분하였다(표 6).17,18 표 5. 한글 숫자 읽기 오류 유형의 정의 및 예시
오류 유형 정의 예시 구문 오류 구성하고 있는 각각의 숫자는 같으나 구조 가 틀려 숫자 전체의 크기가 변하는 것 365 → 삼천육백오십 어휘 오류 숫자의 구조는 동일하나 구성 요소인 개별 적 숫자들이 전혀 다른 것으로 바뀌는 것 365 → 삼백육십일 보속 오류 제시 자극과 동일하게 반복해서 쓰는 것 365 → 삼삼삼백 방해 오류 목표 자극에 도달하지 못하고 제시 자극으 로 다시 돌아와서 숫자와 한글이 섞이는 형태가 되는 것 365 → 삼백6십5 복합 오류 여러 가지 오류가 동시에 나타나는 것 365 → 삼십65 숫자 분리 오류 제시 자극이 하나씩 분리되는 것 365 → 삼, 육 베껴 쓰기 오류 제시 자극을 그대로 베껴 쓰는 것 365 → 365 자소 오류 음소 오류가 나타나는 것 36 → 삼심유 표 6. 한글 숫자 쓰기 오류 유형의 정의 및 예시 ④ 계산 사칙연산에서 공통적으로 나타날 수 있는 오류는 사실적 오류, 과제 대치 오류, 위치 오류, 보속 오류, ‘0’ 사용의 오류, 산술 규칙 오류 등 총 6개 로 구성하였다. 덧셈과 곱셈은 받아올림 오류, 뺄셈은 받아내림 오류를 추가하 였다. 따라서 사칙연산의 오류 유형은 모두 8개이다(표 7).23
오류 유형 정의 예시 사실적 오류 연산 자체가 특정 오류 유형으로 분류되지 않고 완전히 틀리는 것 5+2=6 과제 대치 오류 하나의 계산 과정이 다른 계산으로 대치되 는 것 7-1=8 위치 오류 문제의 위치를 가로 또는 세로로 정렬 할 때, 위치 오류가 나타나는 것 -보속 오류 계산의 대상이 되는 수를 다른 수로 복사 하거나 같은 수를 반복해서 쓰는 것 7-1=71 ‘0’ 사용의 오류 ‘0’을 잘못 사용 하거나 잘못 이해하는 것 100-4=6 산술 규칙 오류 각 연산에 포함된 산술 규칙을 잘못 수행 하는 것 3×1=1 받아올림 오류 10을 주는 과정의 생략 또는 부정확하게 수행하는 것 14+7=11 받아내림 오류 10을 빌려 주는 과정의 생략 또는 부정확 하게 수행하는 것 10-3=8 표 7. 계산 오류 유형의 정의 및 예시 라. 통계 분석
본 연구의 통계 분석을 위해 IBM SPSS(Statistical Package for the Social Science, Version 23.0) for Window 프로그램을 이용하였다. 네 가지 연구 문제에 대한 통계분석은 다음과 같다.
두 집단 간의 기수법 숫자 처리 및 계산에서의 오류율 차이 검정을 위해 모수 통계 기법인 독립표본 t 검정(Independent t-test)을 실시하였다. 통 계 분석에 대한 유의수준은 0.05, 0.01, 0.005, 0.001로 하였다.
평균 표준편차 범위 t p-value 숫자 이해 환자군 .938 1.1236 0 ∼ 4 1.754 .090 정상군 .375 .6191 0 ∼ 2 숫자 산출 환자군 .500 .632 0 ∼ 2 2.087 .048* 정상군 .130 .342 0 ∼ 1 숫자 받아쓰기 환자군 2.880 .380 0 ∼ 7 3.735 .002*** 정상군 2.604 .619 0 ∼ 2 숫자 읽기 환자군 1.130 .130 0 ∼ 2 2.954 .008** 정상군 1.258 .500 0 ∼ 4 한글 변환 환자군 5.130 1.690 1 ∼ 9 4.760 <.001**** 정상군 2.391 1.621 0 ∼ 5 III. 결 과 1. 숫자 처리 오류율 환자군은 정상군보다 숫자 산출(p=0.048), 숫자 받아쓰기(p=0.002), 숫 자 읽기(p=0.008), 한글 변환(p<.001)에서 오류율이 높았다(표 8, 표 9, 표 10). 표 8. 숫자 처리 오류율 검정 결과 * p < .05 ** p < .01 *** p < .005 **** p < .001
이해 산출 받아쓰기1 읽기2 한글3 덧셈 뺄셈 곱셈 나눗셈 환자1 0 0 0 0 1 0 2 0 1 환자2 1 0 1 0 5 0 0 0 0 환자3 0 0 0 0 4 0 2 0 0 환자4 1 0 3 2 5 0 0 1 0 환자5 0 1 5 3 1 2 3 2 3 환자6 0 0 0 1 6 1 1 2 3 환자7 4 0 6 1 5 1 2 1 0 환자8 0 2 7 2 6 1 0 2 2 환자9 2 1 6 1 9 2 2 2 3 환자10 2 0 3 2 8 2 2 2 2 환자11 1 0 1 0 4 0 2 1 0 환자12 2 1 1 4 7 1 1 0 2 환자13 1 1 0 0 3 0 0 0 1 환자14 0 0 3 2 7 0 1 0 0 환자15 0 1 7 0 3 2 2 1 0 환자16 1 1 3 0 8 1 0 1 0 소계 15 8 46 18 82 13 20 15 17 표 9. 환자별 숫자 처리 및 계산 오류 빈도 1 숫자 받아쓰기, 2 숫자 읽기, 3 한글 변환, 단위는 ‘회’
이해 산출 받아쓰기1 읽기2 한글3 덧셈 뺄셈 곱셈 나눗셈 정상1 0 0 0 0 2 0 1 0 0 정상2 0 0 2 0 2 0 1 0 0 정상3 0 0 0 0 1 0 0 0 0 정상4 0 1 1 2 0 0 1 0 1 정상5 0 0 0 0 0 0 0 0 0 정상6 2 0 1 0 1 0 2 3 3 정상7 0 0 0 0 0 0 1 0 0 정상8 0 0 0 0 0 0 1 0 1 정상9 1 0 0 0 2 0 1 0 1 정상10 0 0 0 0 0 1 0 0 0 정상11 0 0 0 0 1 0 0 0 0 정상12 1 0 0 0 2 0 1 1 3 정상13 1 0 0 0 4 0 1 1 2 정상14 0 1 1 0 5 0 3 0 0 정상15 0 0 1 0 3 0 1 0 0 정상16 1 0 0 0 4 0 0 0 0 소계 6 2 6 2 27 1 14 5 11 표 10. 정상 노인별 숫자 처리 및 계산 오류 빈도 1 숫자 받아쓰기, 2 숫자 읽기, 3 한글 변환, 단위는 ‘회’
2. 숫자 처리 오류 유형 환자군은 숫자 처리에서 숫자 이해를 제외하고 총 오류의 수가 154개, 총 오류 유형이 9개 있었다. 정상군도 숫자 이해를 제외하고 총 오류의 수가 37개, 총 오류 유형이 6개 있었다. 환자군은 정상군보다 총 오류의 수가 많았 고, 정상군에서 나타나지 않은 기억 오류, 보속 오류, 베껴 쓰기 오류가 있었 다(그림 2). 그림 2. 환자군과 정상군의 숫자 처리 오류 유형
총 오류의 수에서 각 오류 유형에 대한 백분율을 산출한 결과, 환자군 은 구문(38.3%), 분리(18.8%), 복합(16.2%), 어휘(10.4%), 방해(7.8%), 자소 (5.2%), 기억 및 베껴 쓰기(각 1.3%), 보속(0.6%)순으로 높았다. 정상군은 구문 (35.1%), 어휘(21.6%), 분리 및 방해(각 13.5%), 자소(10.8%), 복합(5.4%)순으 로 높았다. 환자군과 정상군 모두 구문 오류가 가장 많았다(그림 3). 그림 3. 환자군과 정상군의 숫자 처리 오류 유형별 백분율 가. 숫자 이해 환자군은 총 15회의 오류가 있었고, 정상군은 총 6회의 오류가 있었 다. 환자군은 세 자릿수 숫자에서 4회, 네 자릿수 숫자에서 11회의 오류가 있 었다. 정상군은 세 자릿수 숫자에서 1회, 네 자릿수 숫자에서 5회의 오류가 있 었다.
어휘 자소 기억 구문 구문 환자1 0 0 0 0 정상1 0 환자2 0 0 0 0 정상2 0 환자3 0 0 0 0 정상3 0 환자4 0 0 0 0 정상4 1 환자5 0 0 0 1 정상5 0 환자6 0 0 0 0 정상6 0 환자7 0 0 0 0 정상7 0 환자8 1 0 0 1 정상8 0 환자9 0 1 0 0 정상9 0 환자10 0 0 0 0 정상10 0 환자11 0 0 0 0 정상11 0 환자12 0 0 0 1 정상12 0 환자13 0 0 1 0 정상13 0 환자14 0 0 0 0 정상14 1 환자15 0 0 0 1 정상15 0 환자16 0 0 1 0 정상16 0 소계 1 1 2 4 소계 2 나. 숫자 산출 환자군은 어휘 오류 및 자소 오류 각 1회, 기억 오류 2회, 구문 오류 4회로 총 8회의 오류가 있었다. 정상군은 구문 오류가 2회 있었다. 환자군은 정상군에서 나타나지 않은 어휘 오류, 자소 오류, 기억 오류가 관찰되었다(표 11). 표 11. 대상자군별 숫자 산출 오류 유형 빈도 단위는 ‘회
어휘 구문 구문 환자1 0 0 정상1 0 환자2 1 0 정상2 2 환자3 0 0 정상3 0 환자4 1 2 정상4 1 환자5 0 5 정상5 0 환자6 0 0 정상6 1 환자7 2 4 정상7 0 환자8 0 7 정상8 0 환자9 0 6 정상9 0 환자10 1 2 정상10 0 환자11 0 1 정상11 0 환자12 0 1 정상12 0 환자13 0 0 정상13 0 환자14 1 2 정상14 1 환자15 1 6 정상15 1 환자16 0 3 정상16 0 소계 7 39 소계 6 다. 숫자 변환 숫자 받아쓰기는 환자군이 어휘 오류 7회, 구문 오류 39회로 총 46회 의 오류가 있었다. 정상군은 구문 오류가 6회 있었다(표 12). 표 12. 대상자군별 숫자 받아쓰기 오류 유형 빈도 단위는 ‘회’
어휘 숫자 분리 구문 구문 환자1 0 0 0 정상1 0 환자2 0 0 0 정상2 0 환자3 0 0 0 정상3 0 환자4 0 0 2 정상4 2 환자5 0 0 3 정상5 0 환자6 0 0 1 정상6 0 환자7 0 0 1 정상7 0 환자8 1 0 1 정상8 0 환자9 0 0 1 정상9 0 환자10 0 2 0 정상10 0 환자11 0 0 0 정상11 0 환자12 0 4 0 정상12 0 환자13 0 0 0 정상13 0 환자14 0 1 1 정상14 0 환자15 0 0 0 정상15 0 환자16 0 0 0 정상16 0 소계 1 7 10 소계 2 숫자 읽기는 환자군이 어휘 오류 1회, 숫자 분리 오류 7회, 구문 오류 10회로 총 18회의 오류가 있었다. 정상군은 구문 오류가 2회 있었다(표 13). 표 13. 대상자군별 숫자 읽기 오류 유형 빈도 단위는 ‘회’
한글 변환은 환자군이 보속 오류 1회, 베껴쓰기 오류 2회, 구문 오류 6회, 어휘 오류 및 자소 오류 각 7회, 방해 오류 12회, 숫자 분리 오류 22회, 복합 오류 25회로 총 82회의 오류가 있었다. 정상군은 복합 오류 2회, 구문 오 류 3회, 자소 오류 4회, 숫자 분리 오류 및 방해 오류 각 5회, 어휘 오류 8회 로 총 27회의 오류가 있었다. 환자군에서 나타난 복합 오류를 살펴보면, ‘방해 + 자소’, ‘방해 + 베껴쓰기’, ‘숫자 분리 + 자소’, ‘구문 + 자소’가 각 1회, ‘방해 + 어휘’, ‘방해 + 숫자 분리 + 자소’ 각 2회, ‘방해 + 구문’ 4회, ‘방해 + 숫자 분리’ 13회로 나타났다. 정상군의 복합 오류는 ‘방해 + 숫자 분리’, ‘자소 + 어 휘’가 각 1회씩 있었다. 환자군은 정상군보다 오류 유형이 다양하였으며 오류 빈도 또한 높았다.
보속 베껴쓰기 구문 어휘 자소 방해 숫자 분리 복합 환자1 0 0 0 0 1 0 0 0 환자2 0 0 0 0 0 5 0 0 환자3 0 0 0 0 0 3 0 1 환자4 1 0 1 1 1 0 1 0 환자5 0 0 0 1 0 0 0 0 환자6 0 0 0 1 0 0 1 4 환자7 0 0 2 1 0 0 2 0 환자8 0 0 0 0 0 0 4 2 환자9 0 0 1 0 0 2 0 6 환자10 0 0 0 1 0 0 1 6 환자11 0 0 1 0 0 0 3 0 환자12 0 0 0 0 1 0 6 0 환자13 0 0 0 2 0 0 1 0 환자14 0 2 0 0 0 1 1 3 환자15 0 0 0 0 1 0 2 0 환자16 0 0 1 0 3 1 0 3 소계 1 2 6 7 7 12 22 25 표 14. 환자별 한글 변환 오류 유형 빈도 단위는 ‘회’
복합 구문 자소 방해 숫자 분리 어휘 정상1 0 0 0 1 0 1 정상2 0 1 0 0 1 0 정상3 0 0 0 1 0 0 정상4 0 0 0 0 0 0 정상5 0 0 0 0 0 0 정상6 0 0 1 0 0 0 정상7 0 0 0 0 0 0 정상8 0 0 0 0 0 0 정상9 0 1 0 1 0 0 정상10 0 0 0 0 0 0 정상11 0 0 0 1 0 0 정상12 1 0 0 0 0 1 정상13 0 1 0 0 1 2 정상14 0 0 0 0 2 3 정상15 1 0 1 0 1 0 정상16 0 0 2 1 0 1 소계 2 3 4 5 5 8 표 15. 정상 노인별 한글 변환 오류 유형 빈도 단위는 ‘회’
평균 표준편차 범위 t p-value 덧셈 환자군 .810 .834 0 ∼ 2 3.445 .003*** 정상군 .060 .250 0 ∼ 1 뺼셈 환자군 1.250 1.000 0 ∼ 3 1.168 .252 정상군 .880 .806 0 ∼ 3 곱셈 환자군 .940 .854 0 ∼ 2 2.145 .040* 정상군 .310 .793 0 ∼ 3 나눗셈 환자군 1.060 .690 0 ∼ 3 .914 .368 정상군 1.237 1.078 0 ∼ 3 3. 계산 오류율 환자군은 정상군보다 덧셈(p=0.003)과 곱셈(p=0.040)에서 오류율이 유 의하게 높았다(표 16). 표 16. 계산 오류율 검정 결과 * p < .05 ** p < .01 *** p < .005 **** p < .001
4. 계산 오류 유형 환자군은 계산에서 총 오류의 수가 73개, 총 오류 유형이 10개 있었 다. 정상군은 총 오류의 수가 35개, 총 오류 유형이 5개 있었다. 환자군은 정 상군보다 총 오류의 수가 많았고, 정상군에서 나타나지 않은 위치 오류, ‘0’ 오 류, 생략 오류, 복합 오류가 있었다(그림 4). 오류율과 오류 유형에서의 총 오 류 수가 다른 것은 오류 유형 분석 시, 산술 규칙 오류를 추가로 분석하였기 때문이다. 그림 4. 환자군과 정상군의 계산 오류 유형
총 오류의 수에서 각 오류 유형에 대한 백분율을 산출한 결과, 환자군 은 산술 규칙 오류(28.8%), 사실적 오류(26%), 대치 오류(13.7%), 받아내림 오 류(12.3%), 받아올림 오류(5.5%), 위치 및 보속 오류(각 4.1%), 복합 오류 (2.7%), 생략 및 ‘0’ 오류(각 1.4%)의 순으로 높았다. 정상군은 사실적 및 받아 내림 오류(각 31.4%), 산술 규칙 오류(22.9%), 대치 오류(11.4%), 받아올림 오 류(2.9%)순으로 높았다(그림 5). 그림 5. 환자군과 정상군의 계산 오류 유형별 백분율
보속 받아올림 위치 사실적 산술 규칙 (n+0=n) 사실적 환자1 0 0 0 0 0 정상1 0 환자2 0 0 0 0 0 정상2 0 환자3 0 0 0 0 0 정상3 0 환자4 0 0 0 0 0 정상4 0 환자5 0 0 0 1 0 정상5 0 환자6 0 0 0 1 0 정상6 0 환자7 0 1 0 0 0 정상7 0 환자8 0 0 1 0 1 정상8 0 환자9 1 0 0 0 0 정상9 0 환자10 0 1 0 1 1 정상10 1 환자11 0 0 0 0 0 정상11 0 환자12 0 0 1 0 1 정상12 0 환자13 0 0 0 0 0 정상13 0 환자14 0 0 0 0 0 정상14 0 환자15 0 1 1 0 1 정상15 0 환자16 0 0 0 1 0 정상16 0 소계 1 3 3 4 4 소계 1 가. 덧셈 환자군은 보속 오류 1회, 받아올림 오류 및 위치 오류 각 3회, 사실적 오류 및 산술 규칙 ‘n+0=n’ 오류 각 4회로 총 15회의 오류가 있었다. 정상군은 사실적 오류가 1회 있었다(표 17). 표 17. 대상자군별 덧셈 오류 유형 빈도 단위는 ‘회’
나. 뺄셈 환자군은 보속 오류, ‘0’의 오류, 생략 오류, 산술 규칙 ‘n-n=0’ 오류가 각 1회, 복합 오류 2회, 사실적 오류 및 산술 규칙 ‘n-0=n’ 오류 각 3회, 받아 내림 오류 9회로 총 21회의 오류가 있었다. 정상군은 대치 오류, 산술 규칙 ‘n-n=0’ 오류, 산술 규칙 ‘n-0=n’ 오류가 각 1회, 사실적 오류 3회, 받아내림 오류 11회로 총 17회의 오류가 있었다. 환자군은 정상군에 비해 다양한 오류 유형이 관찰되었으나, 받아내림 오류는 정상군보다 낮았다(표 18, 표 19).
보속 ‘0’ 오류 생략 산술 규칙 (n-n=0) 복합 산술 규칙 (n-0=n) 사실적 받아내림 환자1 0 0 0 0 1 0 1 0 환자2 0 0 0 0 0 0 0 0 환자3 0 1 0 0 0 0 0 2 환자4 0 0 0 0 0 0 0 0 환자5 1 0 0 1 0 0 0 0 환자6 0 0 0 0 0 1 0 1 환자7 0 0 0 0 0 1 0 2 환자8 0 0 0 0 0 0 0 0 환자9 0 0 0 0 0 0 0 0 환자10 0 0 0 0 0 1 2 0 환자11 0 0 0 0 0 0 0 2 환자12 0 0 1 0 1 0 0 1 환자13 0 0 0 0 0 0 0 0 환자14 0 0 0 0 0 0 0 1 환자15 0 0 0 0 0 0 0 0 환자16 0 0 0 0 0 0 0 0 소계 1 1 1 1 2 3 3 9 표 18. 환자별 뺄셈 오류 유형 빈도 단위는 ‘회’
산술 규칙 (n-n=0) 산술 규칙 (n-0=n) 대치 사실적 받아내림 정상1 0 0 0 1 0 정상2 0 0 0 1 0 정상3 0 0 0 0 0 정상4 0 0 0 0 1 정상5 0 0 0 0 0 정상6 0 1 0 0 3 정상7 0 0 0 1 0 정상8 0 0 0 0 1 정상9 0 0 0 0 1 정상10 0 0 0 0 0 정상11 0 0 0 0 0 정상12 0 0 0 0 1 정상13 0 0 0 0 1 정상14 1 0 1 0 2 정상15 0 0 0 0 1 정상16 0 0 0 0 0 소계 1 1 1 3 11 표 19. 정상 노인별 뺄셈 오류 유형 빈도 단위는 ‘회’
받아올림 보속 대치 산술 규칙 (n×1=n) 산술 규칙 (n×0=0) 사실적 환자1 0 0 0 0 0 0 환자2 0 0 0 0 0 0 환자3 0 0 0 0 0 0 환자4 0 0 0 0 0 1 환자5 0 0 2 1 1 0 환자6 0 0 0 1 0 1 환자7 1 0 0 0 0 0 환자8 0 1 0 0 1 1 환자9 0 0 0 0 0 1 환자10 0 0 1 1 1 1 환자11 0 0 0 0 0 1 환자12 0 0 0 0 0 0 환자13 0 0 0 0 0 0 환자14 0 0 0 0 0 0 환자15 0 0 0 0 0 0 환자16 0 0 0 0 0 1 소계 1 1 3 3 3 7 다. 곱셈 환자군은 받아올림 오류 및 보속 오류 각 1회, 대치 오류, 산술 규칙 ‘n×1=n’ 오류, 산술 규칙 ‘n×0=0’ 오류 각 3회, 사실적 오류 7회로 총 18회의 오류가 있었다. 정상군은 받아올림 오류, 대치 오류, 산술 규칙 ‘n×1=n’ 오류, 산술 규칙 ‘n×0=0’ 오류가 각 1회, 사실적 오류 3회로 총 7회의 오류가 있었다 (표 20, 표 21). 표 20. 환자별 곱셈 오류 유형 빈도 단위는 ‘회’
받아올림 대치 산술 규칙 (n×1=n) 산술 규칙 (n×0=0) 사실적 정상1 0 0 0 0 0 정상2 0 0 0 0 0 정상3 0 0 0 0 0 정상4 0 0 0 0 0 정상5 0 0 0 0 0 정상6 0 0 1 1 3 정상7 0 0 0 0 0 정상8 0 0 0 0 0 정상9 0 0 0 0 0 정상10 0 0 0 0 0 정상11 0 0 0 0 0 정상12 0 1 0 0 1 정상13 1 0 0 0 1 정상14 0 0 0 0 0 정상15 0 0 0 0 0 정상16 0 0 0 0 0 소계 1 1 1 1 3 표 21. 정상 노인별 곱셈 오류 유형 빈도 단위는 ‘회’
산술 규칙 (n÷n=1) 산술 규칙 (n÷1=n) 사실적 대치 환자1 1 0 1 0 환자2 0 0 0 0 환자3 0 0 0 0 환자4 0 0 0 0 환자5 0 1 1 0 환자6 0 0 0 0 환자7 0 0 0 0 환자8 0 0 1 0 환자9 0 0 0 0 환자10 0 0 0 2 환자11 1 1 1 2 환자12 0 1 1 0 환자13 0 0 0 0 환자14 0 0 0 0 환자15 0 0 0 0 환자16 1 1 0 3 소계 3 4 5 7 라. 나눗셈 환자군은 산술 규칙 ‘n÷n=1’ 오류 3회, 산술 규칙 ‘n÷1=n’ 오류 4회, 사실적 오류 5회, 대치 오류 7회로 총 19회의 오류가 있었다. 정상군은 산술 규칙 ‘n÷n=1’ 오류 1회, 대치 오류 2회, 산술 규칙 ‘n÷1=n’ 오류 3회, 사실적 오류 4회로 총 10회의 오류가 있었다(표 22, 표 23). 표 22. 환자별 나눗셈 오류 유형 빈도 단위는 ‘회’
산술 규칙 (n÷n=1) 대치 산술 규칙 (n÷1=n) 사실적 정상1 0 0 0 0 정상2 0 0 0 0 정상3 0 0 0 0 정상4 0 0 0 0 정상5 0 0 0 0 정상6 1 1 1 2 정상7 0 0 0 0 정상8 0 0 1 1 정상9 0 0 0 0 정상10 0 0 0 0 정상11 0 0 0 0 정상12 0 0 0 0 정상13 0 1 1 1 정상14 0 0 0 0 정상15 0 0 0 0 정상16 0 0 0 0 소계 1 2 3 4 표 23. 정상 노인별 나눗셈 오류 유형 빈도 단위는 ‘회’
IV. 고 찰 숫자 처리와 계산 장애는 생활 속에서 연락처를 받아쓰거나 버스 번 호를 읽는 등의 숫자를 처리하는 것에 어려움을 야기한다.33 본 연구에서 환자군과 정상군 간의 숫자 처리 오류율을 비교한 결과, 환자군은 정상군보다 숫자 산출, 숫자 변환(숫자 받아쓰기, 숫자 읽기, 한글 변환)에서 오류율이 높았다. 첫째, 환자군은 숫자 산출 과제 응답 시, 의미 기 억의 손상으로 오류가 있었다. 두 명의 환자는 모두 자신의 생년월일을 기억 하지 못해 질문에 응답할 수 없었다. 다섯 명의 환자는 연구자의 질문에 구두 로 응답하였을 때 틀렸지만, 연구자가 정답을 알려주면 아라비아 숫자 쓰기로 정확하게 응답할 수 있었다. 따라서 의미 기억이 영향을 미친 본 과제에서의 두 집단 차이는 숫자 산출의 오류로 보기 어렵다. 둘째, 숫자 처리에서의 오류 유형은 환자군이 정상군보다 더 다양한 유형의 오류를 보였으나 두 집단 모두 구문적 오류가 가장 많았다. 구문적 오류는 숫자를 구성하고 있는 각각의 숫 자는 동일하나 구조가 틀려 숫자 전체의 크기가 변하는 오류이다. 이는 숫자 의 배열인 자릿값과 연관 지을 수 있다. 자릿값 이해의 기본 요소는 수세기에 대한 개념적 모델, 기호적 표현, 언어적 표현으로 구성된다. 자릿값 개념은 개 념적 모델을 바탕으로 수를 세는 활동을 통해 말(언어)로 설명하는 것과 아라 비아 숫자(기호)로 표현하는 것을 연결하면서 형성되는 것이다. 따라서 자릿값 의 개념이 효과적으로 일어나기 위해서는 개념적 모델에서 기호적 표현으로 변환하는 활동이 반복되고, 여기에 개념적 모델과 기호적 표현 사이의 관계를 말로 표현하는 활동으로 연결되어야 하는 것이다.34 환자군은 개념적 모델에서 기호적 표현으로 변환할 때, 한글 숫자를 글자 그대로 인식한 후 아라비아 숫 자로 받아써 ‘사백구(409)’를 ‘4009’로 쓰는 오류가 발생하였다. 만약 ‘409’에서 ‘0’의 의미를 정확하게 설명한다면 말로 표현하는 과정에서의 어려움이 없는
것이고, ‘0’의 의미를 부정확하게 설명한다면 개념적 모델을 기호적 표현과 언 어적 표현으로 설명하는 과정 모두에서 오류가 발생한 것임을 추정할 수 있 다. 그러나 본 연구에서 ‘0’의 의미를 설명하는 과제는 시행하지 않아 환자군 이 그 의미를 정확하게 이해하는지에 대한 유무는 분석할 수 없었다. 자릿값 의 이해는 기본적인 연산을 수행하기 위한 개념적 지식과 절차적 지식이 모두 포함되는 기초 과정이다. 그런데 숫자 처리에서 오류가 많더라도 계산은 정확 하게 수행하거나 반대로 계산에서의 오류는 높지만 숫자 처리에서의 오류는 낮은 대상자가 있었다. 전자의 경우 숫자 처리 중 숫자 변환의 하위 과제인 한글 변환에서 특히 오류가 높았다. 즉, 숫자 처리의 오류가 완전히 자릿값의 오류로 해석하기 어렵고 또한 숫자 처리와 계산사이에 이중 해리가 있었으며 이는 선행연구와 일치하였다.25 한글 변환에서의 높은 오류는 다음과 같이 설 명 할 수 있다. 이동 오류라 일컬어지는 방해 오류와 보속 오류는 한글 변환 에서만 관찰되었다. 이 오류는 특히 치매 환자에서 많이 나타나기 때문에 치 매 진단 시 프로토콜로 적용될 수 있지만,11,17,18,35 본 연구의 환자군에서는 이 동 오류 보다 숫자 분리 오류가 근소하게 높았다. 이동 오류가 정상군에서 나 타나지 않는다는 선행 연구와는 대조적으로17 본 연구의 정상군에서 방해 오 류는 있었고 보속 오류는 나타나지 않았다. 이와 같은 현상의 원인은 전두엽 집행기능의 저하, 주의력 저하, 과제의 친숙도 때문이다.17,20,35 대뇌 피질에서
다중연합피질(multimodal or heteromodal association cortex)의 병변과 함께 전두엽의 대사저하가 주의감독체계(supervisory attentional system)의 손상으
로 이어질 수 있고, 그 결과 이동 오류가 발생하는 것이다.18 다중연합피질은
다양한 감각 양식(multiple sensory modalities)으로부터의 입력(input)을 수용 하여 고차 인지 기능(higher order cognitive functions)을 통해 정보를 통합한 다. 치매 초기부터 다중연합피질의 손상이 진행되면서 전두엽 집행기능이 저
(attention)은 지속적 주의력, 선택적 주의력, 분리적 주의력, 교대적 주의력 등 이 있으나 숫자 변환과 관련 있는 것은 선택적 주의력(selective attention)이 다. 숫자 변환에서의 선택적 주의력은 아라비아 숫자를 언어 숫자로 바꿀 때, 더 자동화되어 있는 아라비아 숫자 사용을 억제하여 목표 자극인 언어 숫자를 산출 하는 것을 의미한다.20,35 이는 단어의 색과 글자가 일치하지 않는 조건에 서 자동화된 반응을 억제하고 글자의 색상을 말해야하는 스트룹 색상-단어 검 사(STROOP -test)와 비슷하다.38 마지막 원인은 과제와의 친숙도로 특히 친 숙도가 낮으면 선택적 주의력에 더 영향을 끼치는 것으로 보았다.35 우리는 아 라비아 숫자 산출에 익숙하기 때문에 한글 숫자 변환은 더 어렵게 느껴질 수 있다. 따라서 한글 변환은 숫자 처리 능력의 평가라기보다 집행기능이나 주의 력 평가에 더욱 적합할 것이다. 환자군과 정상군 간의 계산 오류율을 비교한 결과, 환자군은 정상군보 다 덧셈과 곱셈에서 오류율이 높았으며 이는 선행연구와 일치하였다.23,24,39,40 환자군이 사칙연산에서 오류가 발생하는 원인은 계산 과제가 여러 가지 인지 기능이 복합적으로 작용하는 어려운 과제이기 때문이다.19 장기기억에 저장된 산술 사실은 자동적으로 인출되는 반면 계산은 여러 종류의 인지 기능들이 일 련의 과정을 따라 순서대로 진행되기 때문에 각 연산 과정을 모니터링 하는 능력이 떨어져서 계산의 오류가 발생한다. 따라서 뇌의 퇴행이 계속적으로 진 행되는 치매의 경우 복잡한 연산을 수행하는데 더욱 어려움이 커지는 것이다.3 환자군은 정상군보다 계산의 오류 유형이 더 다양하였다. 고빈도 오류 유형의 순위는 다르지만 두 집단은 모두 규칙 오류와 사실적 오류가 높았다. 환자군 은 규칙 오류가 가장 많았는데 사칙연산에 적용되는 모든 규칙에서 오류가 있 었다. 그 중 나눗셈의 ‘n÷1=n’ 규칙은 두 집단 모두에서 오류가 많았지만 나눗 셈 연산을 포기한 대상자가 많아 두 군 간의 정확한 차이를 분석할 수 없었 다. 한편 환자군은 정상군보다 뺄셈의 받아내림 오류가 낮았다. 이는 연구자가
가로로 제시한 연산 문제를 환자군은 세로로 전환하여 풀었음에도 오류가 생 긴 것이고 대부분의 정상군 대상자는 암산으로 과제를 수행하여 오류가 증가 한 것으로 보인다. 본 연구를 통해 다음과 같은 임상적 의의를 얻을 수 있었다. 현재 치매 진단을 위한 여러 신경심리검사에서 숫자 처리와 계산 능 력을 평가하는 문항이 제한적인 편이다. DemTect에서 ‘한글 변환’이라는 새로 운 문항이 도입되어 그나마 숫자와 관련된 문항에 변화가 생겼다고 할 수 있 다. 실제로 이 도구가 임상현장에서 얼마나 자주 사용되고 있는지 알 수 없지 만, DemTect에서 처음으로 제시한 한글 변환 문항이 치매군과 정상군을 선별 하는데 있어서 새로운 변인임은 틀림없어 보인다. 2014년 이탈리아에서 소개 된 NADL(Numerical Activities of Daily Living, 이하 NADL) 선별검사도구 는 환자와의 인터뷰, 간병인과의 인터뷰, 일상적 검사(날짜, 파스타의 양, 전화 번호, 가격 등), 정식 검사(숫자 이해, 아라비아 숫자 읽기 및 쓰기, 암산, 계
산) 등 4개의 하위 과제로 구성된다.41 이 도구는 기존의 선별검사도구인
MMSE 또는 MoCA(Montreal Cognitive Assessment)에서는 인지기능의 전반 적 퇴화 정도를 측정하기 어려운 점을 보완하면서 숫자 사용의 기능이 어느 정도 손상되었는지 평가하기 위해 개발되었다. 국내의 종합적 인지기능평가에 사칙연산은 포함되나 숫자를 읽고 받아쓰는 등의 숫자 처리는 포함되어 있지 않다. 따라서 NADL과 같이 숫자 처리를 검사 항목으로 도입하여 신경인지장 애를 선별할 수 있는 새로운 틀을 제시할 수 있을 것이다. 본 연구의 제한점은 다음과 같다. 첫째, 연구 과제를 위한 숫자 선정의 기준이 다소 모호하였다. 선행연 구에서 사용된 아라비아 숫자를 본 과제에서 인용하였으나, 숫자를 선정하게 된 배경이 밝혀지지 않아 어떠한 기준으로 숫자가 추출되었는지 알 수 없었 다. 따라서 본 연구자는 선행 연구에서 사용된 숫자 자극을 연구자만의 기준
을 바탕으로 선정하였다. 청각적 및 시각적으로 지각되는 한국어의 음운 특성 또한 자극 선정 시 고려되어야 한다. 조음위치가 동일한 음소는 청각적 또는 시각적으로 변별하는데 어려움이 있기 때문이다. 둘째, 앞서 언급하였듯이 환자군의 경우 의미 기억과 관련된 문항에 응답할 수 없는 오류가 있었다. 이는 환자군이 숫자 산출에서의 어려움이 있 다고 단정 지을 수 없는 부분이다. 따라서 의미 기억이 최소한으로 적용되는 과제를 통해 알츠하이머성 치매 환자의 숫자 산출 평가가 이루어지는 것이 바 람직하다. 셋째, 알츠하이머성 치매 환자가 숫자 처리와 계산에서 다양한 오류가 있다는 사실은 선행연구에서도 충분히 밝혀졌다.3,10-12,15,17,18,22-25 그러나 같은 치 매 환자군 이더라도 중증도 또는 치매 종류에 따라 오류 특성이 매우 다양할 것이다. 실제로 본 연구자가 GDS 6인 치매 환자 3명에게 과제를 실시하였는 데, 한글 변환은 전혀 수행하지 못하였고, 숫자 읽기는 문항의 절반 이상에서 숫자 분리 오류가 나타나는 것을 확인할 수 있었다. 이는 GDS 4인 치매 환자 가 숫자 읽기에서 구문적 오류가 더 많이 나타나는 것과 대조적인 현상이었 다. 따라서 특정 기준으로 환자군을 선별하여 후속 연구가 이루어져야하며, 나 아가 환자군에서 있었던 숫자 처리의 오류가 자릿값의 이해와 관련되는지에 대한 후속 연구를 제안하고자 한다.
V. 결 론 본 연구에서는 알츠하이머성 치매 환자 및 일반 노인 각 16명을 대상 으로 숫자 표기방법에 따른 숫자 처리 및 계산의 오류율과 오류 유형에 어떠 한 차이가 있는지 비교하여 다음과 같은 결론을 얻었다. 첫째, 숫자 처리의 숫자 산출과 숫자 변환은 환자군이 정상군보다 오 류율이 유의하게 높았다. 숫자 처리 오류 유형은 환자군이 정상군보다 다양하 였고, 두 집단 모두 구문적 오류가 가장 많았다. 둘째, 계산의 덧셈과 곱셈은 환자군이 정상군보다 오류율이 유의하게 높았다. 계산의 오류 유형도 숫자 처리와 마찬가지로 환자군이 정상군보다 다 양하였으며, 두 집단 모두 산술 규칙 오류와 사실적 오류가 가장 많았다. 특히 나눗셈의 ‘n÷1=n’ 규칙은 환자군과 정상군 모두에서 높았으나 나눗셈 연산을 포기한 대상자가 많아 정확한 분석은 할 수 없었다. 받아내림 오류는 환자군 이 정상군보다 낮았는데, 이는 대부분의 정상군 대상자가 암산으로 과제를 수 행하였기 때문에 오류가 증가한 것으로 보인다. 셋째, 숫자 처리와 계산 사이에는 이중해리가 있었다. 본 연구는 아라비아 숫자에 국한되지 않고 숫자를 표기하는 방법을 아라비아 숫자와 한글 숫자로 구분하여 환자군에서 나타나는 숫자 처리와 계 산 오류의 특성을 제시하였고, 나아가 숫자 처리 과제를 신경인지장애 선별 문항으로 제안하였다는 점에서 임상적 의의를 찾을 수 있다. 추후 연구에서는 한국어의 음운 특성을 고려하여 숫자 자극을 선정하고, 의미 기억이 최소한으 로 내포되는 질문을 통해 치매군의 숫자 산출 능력 연구가 이루어지길 바란 다. 더하여 치매의 종류, 중증도 등을 통제하여 후속 연구가 이루어져야 할 것 이다.
참고문헌
1. 김병곤, 김향희, 나덕렬. 한글 숫자와 아라비아 숫자간의 해리: 증례연구. 대 한신경과학회지 1997;5(1):186-99.
2. 김종백, 신종호. 마음, 뇌, 그리고 학습. 서울: 학지사; 2008.
3. Mantovan MC, Delazer M, Ermani M, Denes G. The breakdown of calculation procedures in Alzheimer’s disease. Cortex 1999;35:21-38.
4. 김연미. 신경심리학적 이론에 근거한 수학학습장애의 유형분류 및 심층진단 검사의 개발을 위한 기초연구. 초등수학교육 2011;14(3):237-59. 5. 채완. 수의 표현과 의미. 한국어의미학회 2001;8:109-32. 6. 정영임, 김정세, 김상훈, 이영직, 윤애선. 현대 한국어에서 아라비안 숫자의 읽기 규칙 연구. 제14회 한글 및 한국어 정보처리 학술대회 2002;10:16-23. 7. 유재원. 자연어 처리를 위한 수사의 하위 범주 분류. 언어와 언어학 1999;24:103-10. 8. 권준수, 김재진, 남궁기, 박원명, 신민섭, 유범희 외. 정신질환의 진단 및 통 계 편람 제5판. 서울: 학지사; 2015. 9. 구본대, 김신겸, 이준영, 박기형, 신준현, 김광기 외. 한국형 치매임상진료지 침소개. 한국의사협회지 2011;54(8):861-75.
10. Deloche G, Hannequin D, Carlomagno S, Agniel A, Dordain M, Pasquier F et al. Calculation and number processing in mild Alzheimer’s disease. J Clin Exp Neuropsychol 1995;17(4):634-9.
11. Thioux M, Ivanoiu A, Turconi E, Seron X. Intrusion of the verbal code during the production of arabic numerals: a single case study in a patient with probable Alzheimer’s disease. Cogn Neuropsychol 1999;16(8):749-73.
12. Girelli L, Delazer M. Numerical abilities in dementia. Aphasiology 2011;15(7):681-94.
13. Hirono N, Mori E, Ishii K, Imamura T, Shimomura T, Tanimukai S et al. Regional metabolism: associations with dyscalculia in Alzheimer’s disease. J Neurol Neurosurg Psychiatry 1998;65:913-6.
14. Rickard TC, Romero SG, Basso G, Wharton C, Flitman S, Grafman J. The calculating brain: an fMRI study. Neuropsychologia 2000;38:325-35. 15. Park YH, Jang JW, Baek MJ, Kim JE, Kim SY. Parietal varient
Alzheimer’s disease processing with dyscalculia. Neurol Sci 2013;34:779-80.
16. Mariska JV, Martin GB, Zac VF, Dora H, Erik JA, Frans SSL et al. Spatiotemporal characteristics of electrocortical brain activity during mental calculation. Hum Brain Mapp 2014;35:5903-20.
17. Sala SD, Gentileshi V, Gray C, Spinnler H. Intrusion errors in numerical transcoding by Alzheimer patients. Neuropsychologia 2000;38:768-77.
18. Kessler J, Kalbe E. Written numeral transcoding in patents with Alzheimer’s disease. Cortex 1996;32:755-61.
19. Cappelletti M, Butterworth B, Kopelman M. Numeracy skills in patients with degenerative disorders and focal brain lesions: a neuropsychological investigation. Neuropsychology 2012;26(1):1-19.
20. Tegnér R, Nybäck H. “To hundred and twenty4our”: a study of transcoding in dementia. Acta Neurol Scand 1990;81:177-8.
21. Fuld PA, Katzman R, Davies P, Terry RD. Intrusions as a sign of Alzheimer dementia: chemical and pathological verification. Ann Neurol
1982;11(2):155-9.
22. 최현세, 이두호, 김유진, 양영애. 경도인지장애 및 초기치매를 선별하기 위 한 새로운 평가도구: DemTect. 한국고령친화건강정책학회지 2014;6(2):35-43. 23. Martin RC, Annis SM, Darling LZ, Wadley V, Harrell L, Marson DC.
Loss of calculation abilities in patients with mild moderate Alzheimer disease. Arch Neurol 2003;60:1585-9.
24. Marterer A, Danielczyk W, Simanyi M, Fischer P. Calculation abilities in dementia of Alzheimer’s type and vascular dementia. Arch Gerontol Geriatr 1996;23:189-97.
25. Kaufmann L, Montanes P, Jacquier M, Matallana D, Eibl G, Delazer M. About the relationship between basic numerical processing and arithmetics in early Alzheimer’s disease a follow-up study. Brain Cogn 2002;48(2-3):398-405.
26. 강연욱. 치매의 신경심리학적 평가. 대한신경과학회지 1999;17:6-9.
27. Ardila A, Rosselli M. Acalculia and dyscalculia. Neuropsychol Rev 2002;12(4):179-231.
28. 대한노인정신의학회. (한국형) 치매 평가검사. 서울: 학지사; 2003.
29. 강연욱. K-MMSE(Korean-Mini Mental State Examination)의 노인 규준 연구. 한국심리학회지 2006;6:1-12.
30. 조맹제, 배재남, 서국희, 함봉진, 김장규, 이동우 외. DSM-Ⅲ-R의 주요우 울증에 대한 한국어판 Geriatric Depression Scale(GDS)의 진단적 타당성 연구. 신경정신의학 1999;38(1):48-62.
31. 강연욱, 나덕렬, 한승혜. 치매환자들을 대상으로 한 K-MMSE의 타당도 연 구. 대한신경과학회지 1997;15(2):300-8.