This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/
by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
*
**
Min Gyu Kim, Master’s Student, Dept. of GeoInformatic Engineering, Inha University. [email protected]
Soo Hong Park, Professor, Dept. of GeoInformatic Engineering, Inha University. [email protected] (Corresponding Author)
SNS를 이용한 POI 공간관계 데이터베이스 구축과 활용
Construction and Application of POI Database with Spatial Relations Using SNS
김민규*․ 박수홍**
Min Gyu Kim ․ Soo Hong Park
요 약 지도를 검색하는 사용자는 특정 장소에 대한 정식 명칭보다는 자신이 알고 있는 명칭이나 일반적으로 불리어 지는 명칭을 이용해 검색을 수행하기 때문에 원하는 장소를 찾는데 빈번히 실패하게 된다. 또한 지도의 공간검색에 있 어서 대표적인 웹 지도 서비스에서는 ‘근처’와 ‘주변’이라는 공간어휘를 가지고 공간상 인접 장소를 탐색하는데 2km 이 상 떨어진 장소까지 검색되어 원하지 않는 위치의 장소 정보를 제공하기도 한다. 본 연구에서는 SNS 중 트위터를 이용 하여 POI 데이터를 추출하고, 기구축되어 있는 기존POI로부터 공간관계를 구축해 사람이 인지할 수 있는 공간범위를 산정하였다. 그 결과, 다양한 장소 명칭을 획득하여 기존 POI 데이터의 다른 이름의 명칭으로 활용할 수 있었고, 기존에 없는 새로운 POI 데이터는 POI 변화가 많은 지역을 파악하는데 활용하여 POI 데이터 구축을 위한 지역선정에 도움이 될 것으로 기대된다. 또한 공간검색에 사용될 수 있는 다양한 공간어휘와 사람이 인지할 수 있는 공간범위를 이용해 보 다 효율적인 공간검색을 수행할 수 있을 것으로 기대된다.
키워드 : SNS(Social Network Service), POI(Point Of Interest), 공간어, 공간관계
Abstract Since users who search maps conduct their searching using the name they already know or is commonly called rather than formal name of a specific place, they tend to fail to find their destination. In addition, in typical web map service in terms of spatial searching of map. Location information of unintended place can be provided because when spatial searching is conducted with the vocabulary ‘nearby’ and ‘in the vicinity’, location exceeding 2 km from the current location is searched altogether as well. In this research, spatial range that human can perceive is calculated by extracting POI date with the usage of twitter data of SNS, constructing spatial relations with existing POI, which is already constructed. As a result, various place names acquired could be utilized as different names of existing POI data and it is expected that new POI data would contribute to select places for constructing POI data by utilizing to recognize places having lots of POI variation. Besides, we also expect efficient spatial searching be conducted using diverse spatial vocabulary which can be used in spatial searching and spatial range that human can perceive.
Keywords :SNS(Social Network Service), POI(Point Of Interest), Spatial Vocabulary, Spatial Relations
1. 서 론
지도 서비스는 사용자에게 지리정보와 다양한 교통·
생활정보 서비스를 제공한다. 이러한 서비스에서 지 도검색의 기본적인 기능은 사용자가 알고자하는 지점 의 명칭을 입력하면 검색된 결과를 지도에 표시하여 정보를 제공해주는 것이다. 이 때 지도 위에 표시되는 지점을 POI(Point Of Interest)라고 부르며 학교, 은행, 음식점 같이 주요 시설물이나 지명에 대한 위치와 명 칭을 지도에 나타내는데 사용된다. 지도는 기본적인 명칭 검색뿐만 아니라, 공간검색을 이용하여 특정 POI 를 기준으로 일정 거리 내에 있는 장소를 검색하여 주
변 장소의 정보를 제공하기도 한다. 이처럼 사용자는 POI 데이터를 이용해 기본적으로 찾고자 하는 장소의 명칭 검색과 공간검색을 수행하여 원하는 장소에 대 한 정보를 제공받는다.
지도 서비스는 사용자가 원하는 목적지를 효율적으 로 검색할 수 있도록 하는 것이 가장 중요하다. 기본적 으로 사용자가 이용하는 명칭으로의 검색 가능 여부, 공간검색에 검색된 장소들이 사용자가 원하는 지점에 서 얼마나 떨어져 있는지의 범위가 지도 검색 결과에 있어 사용자에게 영향을 미치게 된다. 이에 사용자는 그들이 알고 있는 축약된 명칭이나 다양한 키워드를 가지고 검색을 시도하므로 검색에 실패하는 경우가
Figure 2. Returned form of data for streaming API Figure 1. Flow chart of research method
빈번하게 발생된다[4]. 공간검색에 있어서 대표적인 네이버(naver), 다음(Daum) 지도 서비스는 ‘근처’와
‘주변’이라는 공간어휘를 가지고 검색되며, 네이버는 2km, 다음은 언급되어 있지 않지만 약 3km까지 떨어 져 있는 장소를 검색해주고 있다. 하지만 이때의 공간 검색 범위는 가까운 곳이라는 뜻을 가지는 ‘근처, 주 변’이라는 어휘의 의미와 달리 실제 공간상으로 인지 하기에는 넓은 범위이다. 또한 ‘인하대후문 앞 음식 점’처럼 ‘앞, 옆, 맞은편’과 같은 공간을 표현하는 다양 한 어휘가 존재하나 기존에 지도검색 서비스에서는 지원해주고 있지 않다. 이에 사람들이 이용하는 다양 한 POI 명칭을 획득하고, 다양한 공간어휘와 함께 공 간상 인지할 수 있는 공간범위를 산출한다면 보다 효 율적인 지도 검색 서비스를 제공할 수 있다.
지도업체는 존재하는 수많은 위치와 장소를 사용자 가 검색할 수 있도록 POI 데이터를 구축하고 있다. 추 가로 사용자가 직접 원하는 장소를 등록할 수 있는 서 비스까지 진행하고 있다. POI 데이터 취득을 위해서 는 사전에 지역별 조사를 위한 작업계획을 수립하거 나 고객의 요청에 따라 조사하게 된다. 이러한 조사 방 법은 현장조사와 관련 문헌자료를 참조하여 POI 데이 터를 취득하게 되는데, 사람이 직접 투입되어 데이터 를 취득해야 하므로 많은 시간과 비용이 요구된다. 이처 럼 사용자가 요구하기 전에 특정 지역에서 발생되는 새로운 POI를 발견할 수 있다면 보다 효과적인 지역 선정을 통한 POI 데이터 취득 작업을 수행할 수 있다.
이와 같이 사람들은 지도를 검색하는데 다양하고 새로운 형태의 명칭들을 활용할 수 있으나 지금까지 는 정식 POI 명칭 외에 규칙이나 패턴을 통해 대부분 의 가명(alias)을 생성하여 활용하였기에 사람들이 검 색시 입력하는 명칭에 대응하기 어렵다. 공간검색 에 있어서 기존에는 한정된 공간어휘를 이용해 광범위한
원의 형태로 검색했기 때문에 원하지 않는 위치의 정 보를 제공받기도 한다. 또한 POI 데이터 구축에서는 데이터 취득에 많은 시간과 비용이 요구되기 때문에 적합한 지역선정이 필요하다. 본 연구에서는 다양한 지리정보를 포함하고 있는 SNS 데이터를 이용해 새 로운 POI 데이터를 추출하고자 하며, POI간의 공간관 계를 활용한 범위산출로 공간검색에서의 정보검색을 효율적으로 하고자 한다. 이를 위하여 기계학습 방법 을 이용해 POI 명칭을 추출하고 공간어휘와 기구축되 어 있는 POI 데이터베이스를 이용하여 공간관계를 구 축하였다. 본 연구 방법을 평가하기 위해 데이터 추출 정확도를 파악하고, 추출된 POI 데이터의 실제 위치 와 비교분석을 수행하여 산정한 공간범위의 타당성을 확인하고자 한다. 마지막으로 공간관계를 활용한 공 간검색의 효율성을 입증하고자 한다. Figure 1은 연구 방법의 전체적인 흐름도를 나타낸다.
2. 배경이론 및 연구동향
2.1 SNS(Social Network Service)
SNS데이터는 사용자간의 의사소통에 의해 발생되 는 다양한 정보를 포함하고 있어 많은 분야에서 활용 되고 있다. 특히 정보나 소식을 빠르게 접할 수 있어 실시간의 최신정보를 획득할 수 있다는 특징이 있다.
SNS 중 트위터는 다양한 오픈 API를 통해 데이터 분석 에 활용할 수 있도록 지원해주고 있다. 여기에 Streaming API는 실시간으로 발생되는 전세계의 트위터 메시지 를 수집할 수 있어 트렌드 분석에 활용할 수도 있다.
Streaming API 중 Public Streams는 공개된 트위터 데 이터를 수집하는 방식으로 원하는 정보를 분석하는데
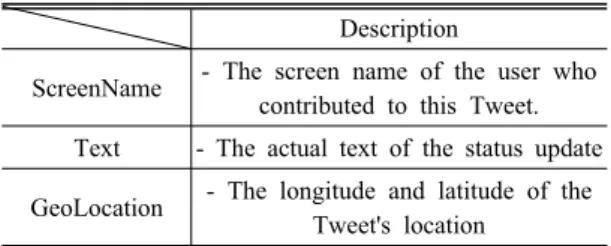
Table 1. Selection of twitter data field for analysis Description
ScreenName - The screen name of the user who contributed to this Tweet.
Text - The actual text of the status update GeoLocation - The longitude and latitude of the
Tweet's location
적합하게 활용될 수 있다[14]. 이렇게 수집된 데이터 는 Figure 2와 같이 Json형태로 반환되어 원하는 항목 의 데이터를 얻을 수 있다.
수집되는 트위터의 데이터 항목은 다양하지만 POI 나 공간분석에 활용되는 데는 사용자, 메시지 내용, 발신위치가 중요할 수 있다. 본 연구에서는 이 세 가지 항목을 수집하여 활용하며, 해당 항목에 대한 설명은 Table 1에 나타내었다.
2.2 기계학습
최근 비정형의 데이터를 분석하기 위해 다양한 기 술이 활용되고 있으며, 트위터와 같은 텍스트 형태는 그에 걸맞은 자연어처리(Natural Language Processing) 기술을 이용해야 한다. 여기에는 트위터 데이터의 비 정형이라는 특징과 영어보다 장소 정보를 추출하는데 문자 자체에서 얻을 수 있는 특징이 적은 한국어라는 점을 고려해야 한다. 예를 들어, 영어의 경우는 어휘마 다 띄어쓰기로 구분되어 있으며 장소와 관련된 정보 를 추출할 때 ‘at, in, behind’와 같은 전치사 품사로부 터 추출할 수 있다. 그에 반해 트위터 메시지 속 문장 들은 띄어쓰기나 문법자체가 맞지 않는 경우가 많고 장소 정보는 주격 조사, 일반 부사, 기호 등 다양한 품사형태와 같이 나올 수 있다. 그러므로 트위터 메시 지에서 필요한 POI 정보를 분석해서 추출하는데 다양 한 특징과 패턴을 고려할 수 있는 기계학습 방법이 적합하다. 기계학습은 추출하고자 하는 데이터의 특 징들을 학습시켜 원하는 데이터 속성에 따라 정보를 추출하는 방법이다. 최근 가장 많이 사용되는 기계학 습 모델로 K-Means, 계층적 군집화, 자기조직지도, 다 층퍼셉트론, 지지벡터머신, 커널 머신, 결정트리, 나이 브베이스, K-최근점 분류기, 베이지안 망, HMM. CRF 등이 있다[9].
여기서 텍스트 형태의 데이터에서 순서열에 따라 원하는 정보를 추출하는데 사용되는 모델에는 HMM (Hidden Markov Model)과 CRF(Conditional Random Fields Model)가 대표적이며, 이 중 CRF는 HMM과
달리 다양한 자질과 문맥정보를 활용할 수 있으므로 보다 널리 사용되고 있다[2].
2.3 형태소 분석
기계학습을 이용하는 데는 필요한 정보를 추출하기 위한 자질(Feature)을 선택하는 것이 중요하다. 여기서 자질은 데이터를 분류하는데 사용되는 특징을 말한 다. 실시간의 트위터 데이터는 최신의 정보를 담고 있 으며 사용자가 자주 사용하는 단어, 문법 등을 이용하 기 때문에 어휘와 품사에 대한 자질 외에는 사용하기 가 어렵다. 어휘와 품사 정보는 POI 명칭과 같은 개체 인식에 있어서 가장 직접적인 영향을 미치는 자질이 라고 할 수 있다.
트위터 메시지처럼 한국어 형태의 문장은 서로 다 른 형태소와 한 개 이상의 어절로 구성된다. 그리고 앞에서 말했다시피 트위터는 자유롭게 메시지 내용을 작성함에 따라 띄어쓰기 또한 되어있지 않는 경우가 발생된다. 그러므로 띄어쓰기를 수행하고 최소한의 형태소 단위로 분석하여 각각의 어휘와 품사를 구분 할 수 있는 형태소 분석기를 활용해야 한다. ‘꼬꼬마 한글 형태소 분석기’는 성능이 좋고 띄어쓰기에 민감 하지 않기 때문에 해당 데이터를 분석하기에 적합하 다. 형태소 분석기를 이용하면 ‘체언, 용언, 관형사, 부사, 감탄사, 조사, 어미, 접사, 어근, 부호, 한글 이외’
의 세부 품사를 구분할 수 있다.
2.4 공간어휘
사람들은 특정 장소나 위치에 대한 내용을 전달 할 때 ‘근처, 주변, 앞, 맞은편’과 같이 공간범위를 나타내 는 용어를 사용한다. 이처럼 공간정보를 전달하고 이해 하는 과정에서 사용하는 것으로, 공간을 표현하는 어 휘를 공간어로 정의하고 있다[3]. 공간어를 가지고 전 달하고자 하는 장소를 설명하기 위해서는 타깃이 되는 대상과 그 대상의 위치를 설명하기 위한 준거(Reference object)를 활용하게 된다[7]. 또한 이 준거는 공간정보 를 전달하는데 있어 전달받는 사람이 미리 알고 있을 만한 지점으로 이야기한다. 예를 들어, Figure 3 좌측 에 광고를 보면 피부과&성형외과를 설명하기 위한
‘EMART’가 준거의 역할을 하고 있으며, 해당 준거와
‘앞’이라는 공간어를 통해 병원에 대한 위치정보를 전 달하고 있다. 본 연구에서는 Jeong[10]이 정의한 어휘 들을 참고하여 Table 2의 공간어를 활용한다. 공간명 사는 공간성을 가지는 특정 사물의 부분을 나타내며, 공간동사는 공간에 위치한 사물의 상태와 움직임을
Figure 3. Example for utilizing spatial vocabulary in real life
Table 2. List of used spatial vocabulary
Type Vocabulary
Spatial noun
오른쪽, 오른편, 우회, 우회전, 우측, 왼쪽, 좌회, 좌회전, 좌측, 왼편, 근처, 주변, 주위, 부근, 인근, 아래, 꼭대기, 사이, 가운데, 맞은편, 건너편, 반대편, 모퉁이, 바깥, 앞,
뒤, 옆, 위, 겉, 밑, 안, 밖, 속, 내, 근방, 대각선, 지하, 골목, 동쪽, 서쪽, 북쪽, 남쪽
Spatial verb
위치하다, 존재하다 도착하다, 내리다, 오르다, 내려가다, 올라가다, 지나다, 건너다, 가로지르다,
돌아가다, 직진하다, 가다 Spatial
josa
~에 있는, ~에서부터 ~까지, 에서 보이는, 에서 보여지는
Figure 4. As a result of entering vocabulary for spatial search in internet portal site, Naver and Daum map
나타낸다. 공간조사는 두 개 이상의 사물을 대상으로 공간적 관련성을 나타내는 언어형식을 뜻한다.
2.5 관련 연구 및 현황
SNS 데이터는 유용한 정보를 추출하여 활용하는데 많은 분야에서 사용되고 있다. 본 연구와 같이 POI와 공간어를 이용해 새로운 POI 데이터를 추출하고, 공 간검색을 위한 공간범위 산출에 대한 연구 사례는 없 었지만 특정 데이터를 대상으로 지리정보를 추출하려 는 국내외 유사 연구가 존재하였다.
Kim[1]은 이메일 데이터를 대상으로 회의공지와 관 련된 장소를 추출해 회의 장소를 온라인 캘린더에 등 록해주는 시스템을 만들었다. CRF 기계학습 모델을 통해 장소명에 대한 개체를 추출하였으며, 지지벡터 머신을 이용해 추출된 장소 중 회의장소를 분류하였 다. 해당 연구는 이메일에 포함된 문장에서 장소 정보 를 추출하고자 하는 내용은 유사하나 새로운 POI 데
이터를 추출하고자 하는 것이 아니기 때문에 본 연구 와는 다르다고 할 수 있다. 또한 이메일 데이터 자체가 트위터보다 자세한 주소와 정확한 문장구조를 가지고 있다는 점도 다르다고 할 수 있다.
Rae[17]는 위키피디아와 소셜미디어(포스퀘어, 고 왈라)로부터 데이터를 수집하여 새로운 POI 데이터를 추출하고, 추출한 POI의 위치를 선정하고자 하였다.
데이터 내에 POI로 인식되는 개체를 CRF 기계학습 모델을 이용하여 추출하였다. 그리고 사진 공유 사이 트인 플리커(Flickr)를 통해 수집한 천만 건의 이미지 를 이용하였으며 지오태그된 이미지의 태그 키워드와 추출POI 명칭을 매칭시켜 일치할 경우 위치추정 모델 에 따라 POI의 위치를 결정하는 방법을 사용하였다.
해당 방법을 통해 추출한 POI의 위치를 선정할 수 있 었으나, 선정한 위치에 있어 1km의 오차 범위를 가지 고 있었다.
현재 대표적인 지도 서비스를 살펴보면, 공간검색 시 ‘근처, 주변’과 같은 어휘를 이용해 장소를 검색해 주고 있으나 단순한 특정 수치를 이용한 공간범위로 찾기 때문에 사람들이 원하지 않는 위치의 장소까지 검색되고는 한다. 또한 사람들이 흔히 장소에 대한 공 간정보를 알거나 전달하고자 할 때 사용하는 ‘앞, 옆, 맞은편’등의 어휘를 이용한 검색은 현재 제공되고 있 지 않다. Figure 4는 네이버와 다음지도에서 공간검색 에 사용될 수 있는 공간어를 입력한 결과로, 네이버의 경우 ‘근처’를 2km로 검색하고 있고 다음의 경우 나와 있지 않지만 2km이상 떨어진 장소를 검색하고 있었 다. 또한 앞에서 말한 ‘맞은편’과 같은 다른 어휘들은 검색되지 않거나 잘못 검색되고 있었다.
유사 연구들을 보면, 기계학습을 통해 특정 데이터 에서 지리정보를 추출하고자 하였다. Kim[1]은 기존에 구축되어 있는 지명데이터베이스를 회의장소 선정에 사용하고자 하였고, 새로운 POI를 추출하고자한 Rae[17]
Figure 5. Configuration of machine learning system for named entity recognition of POIs
Table 3. Result of morpheme analysis for twitter data (POS:Part of Speech)
Word POS Word POS Word POS Word POS
상 NNG 있 VV 국수 NNG 같이 MAG
남 NNG 는 ETD 에서 JKM 점심 NNG
시장 NNG 원조 NNG 현 NNG ! SF
에 JKM 촌 NNG 아랑 NNG
는 지오태그된 플리커 이미지를 활용하여 위치선정을 하였으나 오차범위로 인해 추정한 위치가 실제 위치와 는 상당부분 떨어질 수 있다. 공간검색에 있어서 기존 의 지도 서비스는 검색에 이용될 수 있는 어휘가 한정 되어 있고 검색되는 범위 또한 광범위하여 사용자가 인지하기 어려운 장소의 정보까지 제공할 수 있다.
본 연구에서는 유사 연구와는 다르게 기존에 가지 고 있는 POI 데이터와 공간어를 활용하여 추출한 POI 로부터 기존 POI의 새로운 가명 정보를 획득하고, 기 존에 없는 새로운 POI 데이터의 공간상 위치범위를 파악할 수 있는 방법을 제안한다. 또한 POI간의 공간 관계 구축을 통해 기존 지도 서비스에 단순한 원의 형태를 이용한 공간검색이 아닌 보다 정확하고 정밀 한 검색범위를 산출하여 공간검색에 활용하고자 한다.
3. POI 데이터 추출 및 공간관계 구축
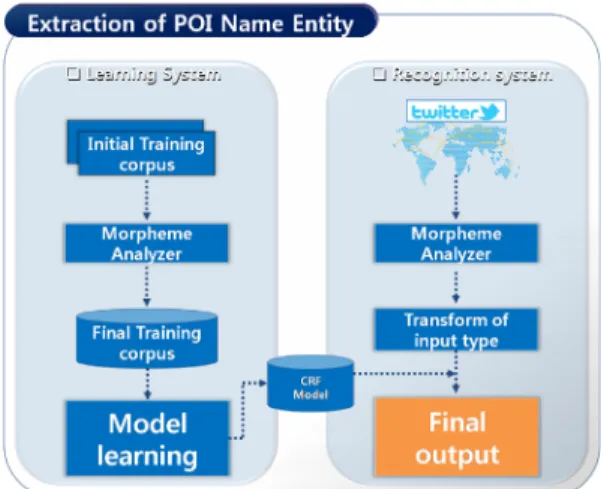
3.1 기계학습 기반 POI 명칭 추출
트위터 데이터를 대상으로 POI에 대한 정보를 추출 하기 위해 기계학습을 이용한다. 여기에 최근 자연어 처리에 있어 가장 좋은 성능을 보이고 있는 CRF 기계 학습 모델을 사용한다. 기계학습에는 학습시스템과 인식시스템으로 나뉘어 구성된다. 이에 대한 전체 시 스템 구성도는 Figure 5와 같다.
3.1.1 학습시스템 (Learning System)
학습시스템은 추출하고자하는 데이터의 패턴이나 특성을 분석해 원하는 개체명을 추출하기 위한 학습
과정이라고 할 수 있다. 본 연구에서의 개체명은 POI 명칭이다. 처리과정을 보면, 우선적으로 초기 학습말 뭉치가 필요하다. 학습말뭉치는 언어 연구영역에서 컴 퓨터가 읽을 수 있도록 모아 놓은 텍스트 형태의 자료 를 뜻한다. 여기서 초기학습말뭉치는 학습에 이용할 데이터로, 본 연구에서는 추출하고자 하는 데이터를 대상으로 학습말뭉치를 제작한 Kim[1]과 Rae[17]처 럼 트위터 메시지를 대상으로 기구축 되어있는 POI 데이터베이스의 데이터를 활용하여 POI 명칭이 포함 되어 있는 일부 트위터 데이터로 선정하였다.
초기 학습말뭉치를 선정하였다면, 개체 인식에 활 용될 자질을 선택해야 한다. 트위터 데이터는 앞서 설 명했다시피, POI를 추출하는데 어휘와 품사를 제외하 고는 다른 자질들을 사용하기 어렵다. 그러므로 형태 소 분석을 통한 형태소 단위의 어휘와 품사를 자질로 사용한다. 본 연구의 형태소 분석에 있어 어절구분이 정확히 되지 않는 트위터 데이터의 띄어쓰기 문제 해 결이 가능한 ‘꼬꼬마형태소분석기’를 이용한다. 트위 터 데이터를 대상으로 형태소 분석을 수행한 결과 예 는 Table 3와 같다. 해당 표는 기구축된 POI 데이터베 이스에 존재하는 ‘상남시장’과 ‘원조촌국수’라는 POI 데이터 명칭이 포함되어 있는 “상남시장에 있는 원조촌 국수에서 현아랑 같이 점심!”이라는 트위터 데이터를 분석한 결과이고, ‘상/남/시장’은 명사(NNG), ‘에’는 조사(JKM)처럼 각각 형태소의 어휘와 품사를 파악할 수 있다. 이렇게 형태소 분석을 통해 나온 어휘와 품사 를 최종 학습말뭉치 제작을 위한 자질로 활용한다.
기계학습 모델을 만들기 위해서는 최종 학습말뭉치 를 제작해야 한다. 최종 학습말뭉치는 각 형태소 단위 의 개체들이 POI인지 아닌지 구분할 수 있는 정답정 보를 가지는 말뭉치라고 할 수 있다. 즉 최종 학습말뭉 치는 초기 학습말뭉치를 기초로 자질과 각 개체를 구 분하는데 적합한 태그를 이용해서 정답정보를 가지는 말뭉치이다. ‘IOB2’는 특정 개체명만을 추출하는 태 깅모델로서, 앞에서 말한 정답정보로 태깅하는데 적 합하다. 이 태깅모델은 ‘B,I,O’의 세 가지 형태의 태그
Table 4. IOB2 notation utilized for training corpus production (POS:Part of Speech)
Word POS IOB2 Word POS IOB2 Word POS IOB2
상 NNG B-PLC 는 ETD O-PLC 현 NNG O-PLC
남 NNG I-PLC 원조 NNG B-PLC 아랑 NNG O-PLC
시장 NNG I-PLC 촌 NNG I-PLC 같이 MAG O-PLC
에 JKM O-PLC 국수 NNG I-PLC 점심 NNG O-PLC
있 VV O-PLC 에서 JKM O-PLC ! SF O-PLC
Table 5. Features used for named entity recognition of POIs
Range of application Word -w[t-2], w[t-1], w[t], w[t+1], w[t+2]
-w[t-1]|w[t], w[t]|w[t+1],
POS (Part of Speech)
-pos[t-2], pos[t-1], pos[t], pos[t+1], pos[t+2]
-pos[t-2]|pos[t-1],pos[t-1]|pos[t], pos[t]|pos[t+1], pos[t+1]|pos[t+2]
-pos[t-2]|pos[t-1]|pos[t], pos[t-1]|pos[t]|pos[t+1], pos[t]|pos[t+1]|pos[t+2]
Figure 6. Named entity recognition of POIs for inserted twitter data
를 통해 개체를 구분하게 되는데, B태그는 대상 POI 개체 경계의 시작 토큰을 나타내고, I태그는 B태그 이 후의 토큰, O태그는 POI가 아닌 개체의 토큰을 나타 낸다[12]. 이에 본 연구는 각 태그에 ‘Place’의 약자인
‘PLC’를 추가하여 ‘B-PLC, I-PLC, O-PLC’로 태그를 사용한다. 그러면 마지막에 최종 학습말뭉치를 제작 하고 기계학습 모델을 생성한 후, 새로운 트위터 데이 터를 입력했을 때 IOB2 태깅 모델에 맞게 분류되어
‘B-PLC’, ‘I-PLC’의 태그에 따라 개체를 추출할 수 있 게 된다. Table 4는 태깅 모델을 적용한 최종 학습말뭉 치를 만드는 예로, ‘상남시장’과 ‘원조촌국수’라는 기 존에 가지고 있는 POI 데이터의 명칭을 대상으로 ‘상 남시장’의 시작개체 ‘상’에 B-PLC, ‘남’에 I-PLC, ‘시 장’에 I-PLC를 태깅하고 ‘원조촌국수’의 시작개체 ‘원
조’에 B-PLC, ‘촌’에 I-PLC, ‘국수’에 I-PLC를 태깅한 다. 그리고 나머지 POI 개체가 아닌 어휘는 O-PLC로 태깅하여 POI가 아닌 개체로서 분류한다. 이렇게 최 종 학습말뭉치는 정답을 가지는 학습 데이터로 구성 된다.
본 연구에서는 최종 학습말뭉치를 만들기 위해 활 용하는 어휘와 품사 자질을 주변 문맥에 대한 특징까 지 활용할 수 있도록 사용한다. Table 5와 같이 형태소 로 구분된 어휘의 주변 ±1, 품사의 주변 ±2의 범위의 자질을 사용해 POI개체를 인식하는데 사용한다. 전체 자질의 수는 19가지이며 ‘t’는 형태소로 구분된 개체 의 순서열이고, ‘w’는 어휘, ‘pos’는 품사를 뜻한다.
이렇게 만든 최종 학습말뭉치는 CRF 기계학습 모 델을 만드는데 사용된다.
CRF 기계학습에 사용할 수 있는 툴에는 CRFsuite, CRF++, MALLET 등이 있으며, 본 연구에서는 벤치 마크 테스트 결과[20]에 따라 비교적 정확도가 높고 다른 툴에 비해 학습 속도가 빠른 CRFsuite를 사용한 다. 해당 툴을 사용하면 제작한 최종 학습말뭉치를 이 용해 기계학습 모델을 생성할 수 있으며, 생성된 기계 학습 모델은 인식시스템에서 새로 입력되는 트위터 데이터의 POI 개체 인식에 사용된다.
3.1.2 인식시스템 (Recognition system)
인식시스템에서는 학습시스템에서 최종적으로 만 든 기계학습 모델을 통해 실시간으로 수집되는 트위 터 데이터를 대상으로 POI로 인식되는 개체를 추출하 게 된다. 우선, 학습시스템에서 POI개체를 추출하기 위한 자질로 활용되는 어휘와 품사를 분석하기 위해 형태소 분석기를 이용한다. 그 다음에 Table 5의 자질 에 맞게 입력형태를 변환하고 학습시스템에서 생성한 기계학습 모델을 가지고 CRFsuite툴을 활용해 트위터 메시지 내 POI 개체를 추출한다. 이에 대한 예를 Figure 6에 나타내었다. 해당 그림을 보면, “홍대 커피 프린스 골목 아래 텅스텐홀”이라는 새로운 트위터 메 시지를 형태소 분석하고 자질에 맞게 데이터 형태를
Figure 7. Configuration field of twitter data for creating spatial relations
Figure 8. Get existing POIs included in twitter
변환하여 해당 툴에 입력하였다. 그 결과, ‘IOB2’ 태깅 모델에 따라 개체별로 분류되고, 여기서 ‘B-PLC’,
‘I-PLC’를 추출하면 ‘홍대커피프린스’와 ‘텅스텐홀’
을 추출할 수 있다.
3.2 공간어를 이용한 공간관계 구축
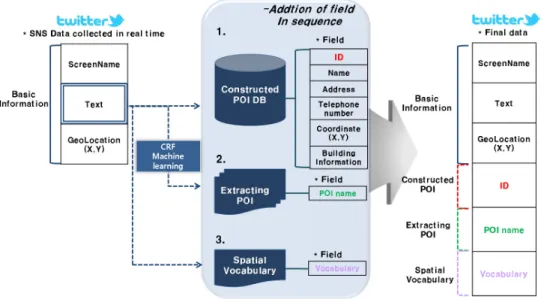
기계학습을 통해 추출한 POI 데이터는 명칭에 대한 것으로 공간상 위치정보는 포함하고 있지 않다. 본 연 구에서는 기존에 가지고 있는 POI 데이터베이스의 기 존POI를 준거로 활용하고, 공간어를 이용해 공간관계 를 구축하여 추출한 POI의 공간상 위치범위를 추정하 고자 한다. 또한 구축된 공간관계를 통해 공간검색을 위한 범위산출에 활용하고자 한다. 우선 수집되는 트 위터 데이터의 기본 항목 외에 공간관계 구축을 위한 기존POI, 추출POI, 공간어의 항목이 추가로 필요하며,
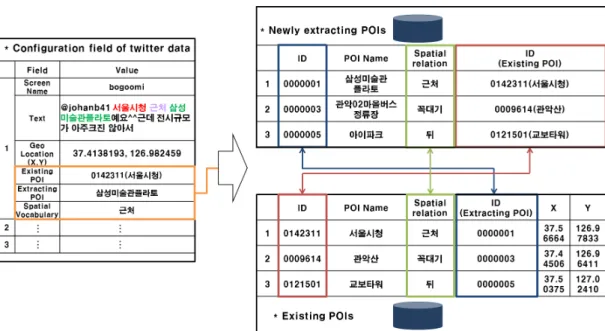
항목을 구성하기 위한 과정은 Figure 7과 같다. 해당 그림과 같이 수집된 트위터 데이터의 기본 항목은 사 용자명, 메시지, 발신 위치정보이다. 해당 그림의 1번 과정은 공간관계에서 준거로 활용할 메시지 내에 포 함된 기존POI를 찾아 항목을 추가하는 과정이다. 이 때는 메시지 내에 띄어쓰기와 기호를 제거해서 최소
‘2’에서 최대 ‘8’까지의 문자열 길이를 잘라내어 기존 POI를 찾는 방법을 사용한다. 예를 들어 Figure 8을 보면, 첫 문자열인 ‘서울’부터 ‘서울시청근처삼성’까 지 잘라내어 기구축된 POI 데이터베이스에 동일한 명 칭을 가지는 POI를 찾고, 그 다음에 두 번째 문자열 기준인 ‘울시’부터 같은 방법을 반복해 마지막 문자열 까지 찾는다. 해당 예는 ‘서울시청’과 ‘플라토’를 찾게 된다. 2번 과정은 기계학습을 통해 추출한 POI 명칭 정보를 추가하고, 3번 과정은 메시지에 포함된 공간어 를 추가한다. 이렇게 되면 기본 데이터 항목에서 세 가지 항목이 추가로 구성된다. 여기에 대한 항목의 예 로 Figure 9의 1번 메시지를 보면 ‘서울시청’은 기존 POI로 준거의 역할을 하며 ‘삼성미술관플라토’는 추 출POI, 그리고 ‘근처’는 공간어이다.
트위터 내 공간어가 한 개를 초과할 경우가 발생할 수 있다. 이때는 추출POI에 가장 가까운 공간어를 대 상으로 하고, 공간어 중 조사를 포함하는 공간어의 경 우는 준거로서 기존POI와 결합한 형태만 활용한다.
예를 들어, 6번 메시지에는 공간어로 ‘맞은편, 골목,
~에 있는’이 있는데, ‘맞은편’은 ‘교보타워’를 기준으 로 ‘신한은행’과 관계를 가지고, ‘골목’은 ‘신한은행’
Figure 9. Example of final twitter data
Figure 10. Spatial relations between newly extracting POIs and existing POIs 을 기준으로 ‘스위트스페이스’과 관계를 가지고 있다.
‘~에 있는’은 준거와 결합한 형태가 아니므로 제외한 다. 관계를 살펴보면 해당 추출POI인 ‘스위트스페이 스’와 가까운 공간어가 더 긴밀한 관계를 가진다는 것 을 파악할 수 있다. 그러므로 해당 예는 추출POI에 가까운 ‘골목’이라는 공간어를 선정한다.
이처럼 최종적으로 트위터 데이터는 준거로 활용할 기존POI, 추출POI, 그리고 공간어 항목을 가지게 되 며, 이 세 가지 항목을 가지고 공간관계를 구축하게 된다. Figure 10은 이와 같은 공간관계를 구축하는 방 법을 나타낸다. 예를 들어, 해당 그림의 트위터 데이터 는 최종적으로 구성된 항목이며, 이를 통해 ‘삼성미술 관플라토’는 새롭게 추출한 POI 데이터로 추가되고
기존POI인 ‘서울시청’ ID정보와 ‘근처’라는 공간관계 항목을 가진다. 그러면 반대로 기구축 POI 데이터베 이스에 ‘서울시청’은 ‘근처’라는 공간관계를 통해 ‘삼 성미술관플라토’의 추출POI ID정보를 가진다. 이렇게 공간관계를 구축하게 되면, ‘삼성미술관플라토’를 검 색시 ‘서울시청’의 위치좌표 값을 가지고 ‘근처’라는 공간 범위를 통해 나타내게 된다. 반대로 ‘서울시청’
을 검색하면 ‘근처’라는 범위에 ‘삼성미술관플라토’가 위치한다는 정보를 알 수 있다.
새로 추출한 POI는 기구축된 POI 데이터베이스에 존재할 수도 있다. 추출한 POI가 존재할 경우에는 기 구축된 POI 데이터를 이용해 기존 POI 데이터 간의 공간관계를 구성하여 공간어 범위 산정과 공간검색을 위한 범위 산출에 활용한다. 여기서 공간어의 공간범 위는 3.4 단락의 방법을 이용해 공간범위를 산정하게 된다. 공간검색시 범위산출은 4.6 단락에 예를 들어 나타내었다.
이와 같이 공간어와 기존POI 데이터를 이용해 공간 관계를 구축한다면 공간상 위치범위를 가지는 새로운 POI 데이터를 추출할 수 있다. 하지만 트위터 메시지 내에서 발신자가 말하는 대상의 준거를 알 수 없으므 로, 이를 선정할 수 있는 방안이 필요하다. 예를 들어, Figure 9 1번 메시지의 준거로서 ‘서울시청’은 우리나 라 한 곳에만 존재하므로 발신자가 말하는 장소를 파 악할 수 있다. 하지만 6번과 7번 메시지의 ‘신한은행’
과 ‘이마트’는 전국적으로 영업점을 가지고 있음에 따
Figure 11. Plan 1 for selection of reference object POI
Figure 12. User location in twitter including word ‘Inha University’
Figure 13. Plan 2 for selection of reference object POI 라 발신자가 말하는 특정 장소를 파악하기 어렵다. 그
러므로 발신자가 말하는 준거를 선정하기 위한 방안 이 필요하다. 여기에는 트위터 메시지 내 두 개 이상의 기존POI를 포함하고 있는 6번 유형과 한 개의 POI를 포함하고 있는 7번 유형으로 나누어 접근하고자 한다.
3.2.1 방안 1
트위터 메시지 내에 기존POI를 두 개 이상 포함하고 있는 경우를 대상으로 한다. 이 때는 공간어를 기준으 로 탐색사이즈 ‘20’의 길이 안에 기존POI와 추출POI 가 포함되는 것을 전제로 한다. 여기서 탐색사이즈는 공간어를 기준으로 띄어쓰기를 제외한 문자열의 길이 를 말한다. 예를 들어 Figure 11에 ‘신논현역’은 ‘골목’
이라는 문자열의 시작점을 기준으로 ‘15’의 길이를 가 지므로 해당 탐색사이즈에 포함된다. 준거를 선정하 기 위해서는 공간어에 가장 가까운 두 POI를 찾는데, 해당 그림에서는 ‘신논현역’, ‘교보타워’, ‘신한은행’
중 가까운 ‘교보타워’, ‘신한은행’를 대상으로 거리 계 산을 수행한다. 그 후, 두 POI가 위치적으로 가장 가까 이 있는 지점의 ‘신한은행’을 사용자가 말하는 지점으 로 판단해 ‘신한은행’ 골목에 ‘스위트스페이스’가 존 재한다는 관계를 도출하게 된다.
3.2.2 방안 2
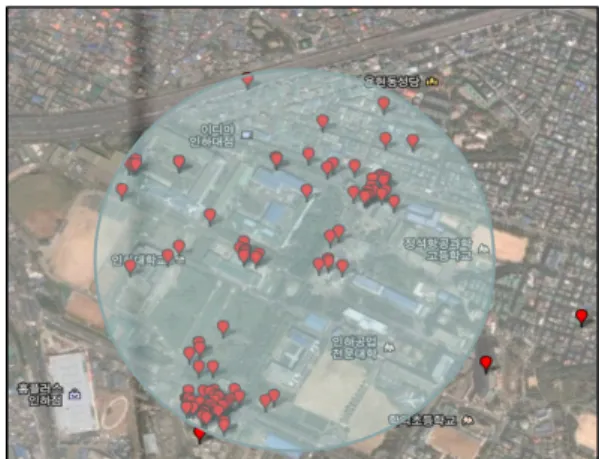
트위터 메시지 내에 기존POI를 한 개 포함하고 있는 경우를 대상으로 한다. 이 경우에는 Nagarajan[16]와 Sakaki[18] 같이 트위터 메시지의 발신위치를 하나의 센서로 간주하고, 이를 바탕으로 가장 가까운 지점을 찾는다. 이와 같은 전제를 확인하고자 트위터 메시지 에 ‘인하대학교’를 포함하고 있는 메시지의 발신위치 를 Figure 12와 같이 지도 위에 표현해 보았다. 붉은색 의 마커는 해당 사용자의 발신위치를 나타낸 것으로, 전체 153건의 트위터 중 9건을 제외한 나머지는 대부 분 인하대학교 근처로 확인되었다. 이처럼 트위터 메 시지 내에 특정 장소가 포함되어 있을 시 대개 그 장소 주변에서의 상황이나 행동 등을 담고 있는 내용이 작 성되는 것을 알 수 있다.
방안 2에서는 공간어를 기준으로 탐색사이즈 ‘10’
의 길이 안에 기존POI와 추출POI가 포함된다면, 사용 자의 발신위치와 가장 가까운 지점을 대상으로 기존 POI를 선정한다. 예를 들어, Figure 13의 ①을 보면 ‘이 마트’는 공간어인 ‘맞은편’의 문자열의 시작점을 기준 으로 ‘10’의 길이 안에 포함된다. 이처럼 포함여부를 판단하고, Figure 13의 ②와 같이 기존POI인 ‘이마트’
의 전국 지점을 대상으로 발신위치와 거리 계산을 수 행하여 사용자가 말하는 ‘이마트’를 찾는다. 해당 예 에서는 ‘이마트 동백점’으로 확인되었다. 그러면 해당
‘이마트’ 맞은편에 ‘금오리마을’이 존재한다는 관계를 도출할 수 있다.
3.3 필터링
기존POI와 추출POI간의 잘못된 공간관계 도출을 막 기 위해 필터링이 필요하다. 대부분 잘못된 추출에는 한글자의 공간어와 두 글자의 POI 명칭이 대상이 된다.
Figure 14. Morpheme analysis to utilize spatial voca- bulary with one syllable
Figure 15 . Decrease of search size to utilize one syll- able spatial vocabulary
Table 6. Words of two syllable with high frequency in twitter
Word Frequency Word Frequency
오빠 66,429 언니 19,572
오늘 65,900 영화 17,350
사람 51,052 친구 17,194
생각 34,703 사진 17,137
사랑 26,390 가요 16,678
지금 24,240 국민 16,324
시간 22,267 아이 14,364
내가 21,457 마음 13,563
감사 19,915 행복 13,556
내일 19,811 노래 12,794
3.3.1 한 글자 공간어 필터
한 글자 공간어는 ‘안, 속, 내’등이 있으며, 이는 다 른 의미로 사용되는 언어 안에 포함됨에 따라 공간어 로 잘못 인식될 수 있다. 예를 들어, ‘안경’, ‘속초’ 등 을 ‘안’과 ‘속’이라는 공간어로 인식할 수 있다. 이 경 우에는 형태소분석과 탐색사이즈를 줄이는 방법을 사 용한다.
(1) 형태소 분석 활용
대부분의 한 글자 공간어는 최소한의 형태소로 구 분되었을 때 한 글자로 분류되고 명사의 품사를 가지 고 공간어의 역할을 하게 된다. Figure 14의 1번 메시 지를 보면 ‘안’이라는 한 글자로 형태소가 구분되고 명사(NNG)의 품사를 가진다. 2번 메시지는 명사로 분 석됐지만 ‘안경’이라는 두 글자의 다른 의미를 가지는 형태소로 구분되었다. 이를 통해 2번 메시지는 ‘안’이 라는 어휘가 공간어가 아니라는 것을 알 수 있다.
(2) 탐색사이즈 감소
탐색사이즈를 줄이면 추출POI와 기존POI 간에 보 다 긴밀한 관계를 가질 수 있다. 예를 들어 Figure 15의 1번 메시지를 보면 명사의 품사를 가지고 ‘안’이라는 한 글자로 형태소가 구분되었다. 하지만 해당 메시지 속 ‘안’은 ‘하다’를 꾸미는 부사의 품사로 분석되어야 한다. 하지만 해당 형태소 분석기는 확률기반으로 품 사를 결정하기 때문에 항상 정확한 품사 분석을 할 수 없다. 그렇기 때문에 분석기의 오류를 최대한 배제
하고자 한 글자의 공간어의 경우는 탐색사이즈를 ‘0’
으로 줄이는 방법을 사용한다. 1번 메시지의 경우 ‘사 진이야기’와 ‘농아인협회’사이에 다른 어휘들이 존재 하고 있다. 2번 메시지의 경우는 탐색사이즈가 ‘0’으 로 두 POI사이에 다른 어휘가 존재하지 않아 보다 긴 밀한 관계를 가지는 것을 볼 수 있다. 이는 공간어를 기준으로 POI간의 거리가 멀어질수록 그만큼 관계가 낮아진다고 볼 수 있다.
3.3.2 두 글자 단어 필터
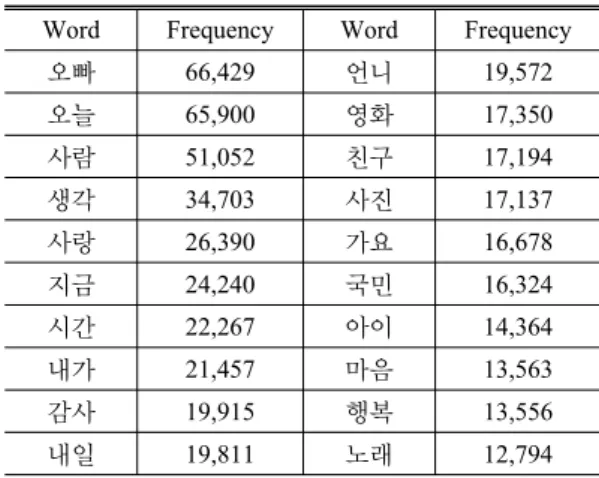
POI는 다양하기 때문에 ‘친구, 오빠, 마음’과 같이 흔히 사용하는 단어를 포함하기도 한다. 그렇기 때문 에 트위터 메시지에서 POI를 뜻하기 보다는 다른 의 미로 활용되는 경우가 많다. 본 연구에서는 흔하게 사 용되는 두 글자의 명칭을 파악해서 해당 단어와 같은 명칭을 가지는 기존POI와 추출POI는 사용하지 않는 다. 이를 위해 트위터에서 약 2,000,000건의 데이터를 샘플링하여 두 글자로 판단되는 단어의 빈도수를 계 산하였고, 빈도수 1,000이 넘는 단어를 필터링 하는데 활용했다. 트위터 메시지에서 높은 빈도수를 가지는 두 글자 명칭 일부를 Table 6에 나타내었다.
3.4 공간관계를 통한 공간어 범위 산정 방안 새로운 POI 데이터는 공간어가 의미하는 공간범위 를 가지고 특정 공간상 위치범위를 파악할 수 있다.
본 연구에서는 트위터 메시지에 포함된 기존POI 데이 터 간의 공간관계를 활용해 공간어의 공간범위를 산 정한다. 예를 들어 Figure 16의 1번 메시지를 보면 기 존POI인 ‘합정역’과 ‘옹달샘’은 ‘근처’라는 공간어를
Figure 16. Utilize the constructed POIs for calculation of spatial range of spatial vocabulary
Table 7. Matching result between constructed and extracting POIs
The number of POI Total number of POI 12,834
Identical with
constructed POI name 11,860 Not identical with
constructed POI name 974
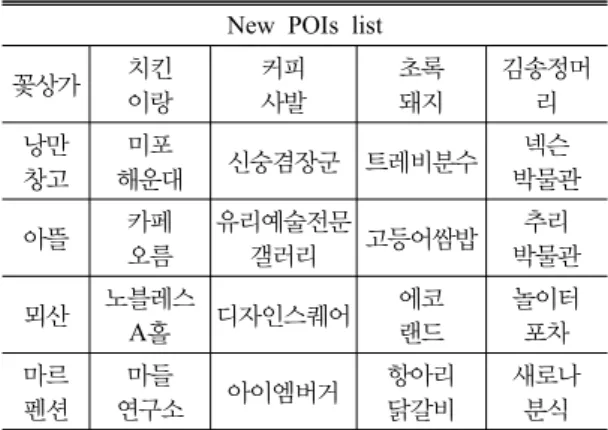
Table 8. Non-existing POIs in constructed POI database New POIs list
꽃상가 치킨
이랑
커피 사발
초록 돼지
김송정머 리 낭만
창고
미포
해운대 신숭겸장군 트레비분수 넥슨
박물관
아뜰 카페
오름
유리예술전문
갤러리 고등어쌈밥 추리
박물관
뫼산 노블레스
A홀 디자인스퀘어 에코
랜드
놀이터 포차 마르
펜션
마들
연구소 아이엠버거 항아리
닭갈비
새로나 분식 가지고 관계를 가진다. 이 때 두 POI간의 거리를 계산
하면 ‘근처’라는 공간어가 의미하는 공간범위를 파악 할 수 있다. 이처럼 계산된 거리를 평균하여 공간어의 공간범위를 산정한다.
4. 실험 및 분석
4.1 실험 개요
본 실험에서는 트위터에 포함된 POI 명칭을 기계학 습을 이용해 추출하여 새로운 POI 명칭을 파악한다.
그리고 공간관계를 가지는 POI를 추출하고, 공간어의 공간범위를 산정한다. 제안한 방법을 평가하기 위해 트위터 메시지를 토대로 문맥 내용상의 추출 정확도 를 평가하고, 추출한 POI 데이터의 실제 위치정보와 비교하여 본 연구에서 산정한 공간범위 내에 실제로 POI가 위치하는지 비교 분석한다. 마지막으로 공간관 계를 활용한 공간검색의 효율성을 입증하고자 한다.
실험에 사용될 트위터 데이터는 공간어를 포함하고 있는 3,052건을 대상으로 한다. 그리고 기구축된 POI 데이터베이스의 2,135,359건 데이터를 이용한다.
4.2 POI 명칭 추출
트위터에서 추출한 POI 명칭과 기구축된 POI 데이 터베이스의 데이터와 문자열 매칭을 수행하여, 트위 터 데이터의 새로운 명칭 정보를 파악하고자 한다. 기 계학습을 통해 추출한 POI 명칭은 Table 7과 같이 전 체 12,834건이다. 그 중 기구축된 POI 데이터베이스에 존재하는 데이터와 동일한 명칭을 가지는 데이터는 11,860건이며, 동일하지 않은 명칭의 데이터는 974건 이다. 동일하지 않은 명칭을 통해 사람들이 작성한 트 위터 메시지 속에는 다양한 POI정보를 포함하고 있다 는 점을 확인할 수 있다. Table 8은 기존 데이터와 동
일하지 않은 새로운 POI 명칭 일부를 나타낸다.
여기서 추출한 명칭은 기존 POI 데이터의 명칭과 동일한지 아니면 동일하지 않는지에 따라 활용용도가 다르다. 동일하지 않은 POI 명칭은 기존에 가지고 있 는 데이터의 가명인지 아니면 기존에 없는 새로운 POI 데이터인지 판단하여 활용된다. 판단하는 데는 참조자료(웹 사이트나 관련문헌 등)를 활용해 가명여 부를 확인하고, 가명으로 활용되지 않는다면 새로운 POI 데이터로 활용하게 된다. 기존POI 데이터와 동일 한 명칭은 새로운 POI 데이터로 활용될 수 있다. POI 는 위치를 가지는 데이터로 명칭이 동일하다고 해도 해당 위치에 따라 다른 데이터가 된다. 예를 들어, ‘투 썸플레이스’는 전국에 있는 카페로, 이는 POI 데이터 에 동일한 명칭이라도 다른 위치를 가지기 때문에 서 로 다른 데이터로 구성된다. 해당 실험은 명칭만을 파 악하여 비교하였기 때문에 다음 4.3 단락의 공간관계 를 통해 추출하여 공간상 존재여부를 판단해 기존에 구축되어 있던 POI데이터베이스에 존재하는지 파악 한다. 그러면 정확히 트위터 발신자가 말하는 대상 POI를 찾아 가명으로 활용하거나 새로운 POI 데이터 로 활용될 수 있다.
Table 9. Extracting POI data with spatial relations Extracting
POI
Spatial
Vocabulary Existing POI
1 비앙코
웨딩홀 옆 대구
미술관
2 주차장 밑 암남공원
3 할매유부
전골 골목 깡통
4 커피그루
나무 1층 제주KBS
5 윤재근
베이커리 근처 역곡역
6 교보타워 맞은편 신한은행
7 모델노래방 뒤 고려병원
8 머구리
식당 에 있는 마석역
9 대성학원 맞은편 홈마트
10 포항공대
학관 앞 운동장
Table 10. Accuracy evaluation of extraction method of POI data
The number of data Total number of POI 3,052
Correctly
extracting data 2,593 Incorrectly
extracting data 459
Accuracy ratio(%) 84.96
4.3 공간관계를 가지는 POI 추출
앞 단락은 POI 명칭만을 파악하였으며, 해당 단락에 서는 추출한 POI의 실제 공간상 위치범위를 추정하기 위해 공간관계를 가지는 POI를 추출한다. Table 9은 추출한 POI 데이터의 일부를 나타낸다. 여기서 추출 POI는 기계학습을 통해 추출한 POI 명칭이고 기존 POI는 준거로 활용되는 기구축된 POI 데이터베이스의 데이터이다. 이 두 POI는 공간어를 통해 관계를 가진 다. 예를 들어, 1번 항목은 ‘대구미술관’ 옆이라는 관 계를 통해 ‘비앙코웨딩홀’이 존재한다고 할 수 있다.
본 연구에서는 공간관계를 가지는 POI 데이터 추출 에 대한 정확도 검증을 위해 트위터 메시지의 문맥 내용을 파악하는 방법을 이용한다. 그 이유는, 트위터 메시지의 경우 최신 정보들이 수집되므로 여기에 대 해 비교할 수 있는 기초자료 구성이 어렵다. 그러므로 검토자가 직접 트위터 메시지의 문맥내용을 보고 준 거의 역할인 기존POI와 추출POI, 그리고 공간어의 활 용용도를 검토해 정확하게 추출되었는지 판단한다.
이에 총 트위터 데이터 3,052건을 대상으로 실험한 결과를 Table 10에 나타내었다. 정확하게 추출된 데이 터는 2,593건이며, 부정확하게 추출된 데이터는 459건 이다. 그 결과, 본 연구의 추출방법의 정확도는 84.96%
로 나타났다.
정확도 평가를 통해 부정확하게 추출된 데이터는
세 가지 유형으로 분석된다. 하나는 ‘장독대 옆 쌍둥이 돼지’와 같이 사용자의 주변 사물이나 환경을 나타내 는 경우이다. 두 번째는 ‘대치동학원가 가운데 영화관 (롯데시네마로) 하나 생겨씀 조켔다’와 같이 소망이나 추측이 담긴 메시지이다. 세 번째는 잘못된 형태소 분 석의 결과로 인한 추출이다. 예를 들어, ‘모래내시 장···’의 메시지에서 ‘모래내/ 시장’으로 구분되어 형태 소 분석이 되지 않고 ‘모래/ 내/ 시장’으로 되어 ‘내’가 공간어로 파악되는 경우다.
추출한 데이터는 실제 기구축된 POI 데이터베이스 에 존재할 수도 존재하지 않을 수도 있다. 그렇기 때문 에 정확하게 추출된 2,593건을 대상으로 기구축된 POI 데이터베이스에 존재유무를 판단해서 기존에 존 재하는 데이터의 경우 공간어의 공간범위 산정과 공간 검색시 범위산출에 활용하고, 기존에 없는 데이터의 경우 가명 혹은 새로운 POI 데이터로 활용한다. 기존 데이터의 존재유무를 구분하기 위해 우선, 공간관계 를 통해 준거가 되는 기존POI를 기준으로 공간질의 (Spatial Query)를 수행하여 주변 위치 공간상에 추출 POI가 기존 데이터에 존재하는지 찾는다. 이 때 공간 질의를 하는데 두 가지 탐색반경을 활용한다. 그 이유 는 ‘CU’라는 편의점처럼 공간상 잦은 분포를 가지는 POI가 있어, 검색반경을 크게 했을 때 사용자가 말하 는 지점이 아니라 다른 지역에 있는 지점을 찾아 기존 데이터에 존재하는 것으로 판단할 수 있기 때문이다.
본 연구에서는 기구축된 POI 데이터베이스를 대상으 로 데이터 빈도수가 1,000 이상일 경우 공간상 잦은 분포를 가지는 POI라고 판단하여 탐색반경을 0.5km 로 하고, 빈도수가 1,000이하일 경우 2km로 실험을 수행하였다. 예를 들어, Table 9에 1번 항목의 ‘비앙코 웨딩홀’은 기구축된 POI 데이터베이스를 대상으로 빈도 수가 1,000이하이므로 ‘대구미술관’을 기준으로 2km 의 공간질의를 수행하여 ‘비앙코웨딩홀’이 기존 데이 터에 존재하는지 확인한다. 다른 예로, 6번 항목의 ‘신 한은행’은 빈도수가 1,000 이상으로 0.5km의 탐색반
Table 11. Presence confirmation of extracting POIs in constructed POI database
The number of data Total number of data 2,593
Existing data 366
Non-existing data 2,227
Table 12. Calculated plot for spatial range of spatial vocabulary
Spatial vocabulary Range(m)
Class1 Class2 Class3
1 맞은편, 건너편, 반대편, 대각선 / 건너다, 가로지르다 60 120 300
2 골목 100 200 400
3 옆, 사이 / 오른쪽, 우회, 우회전, 우측, 오른편 / 왼쪽, 좌회, 좌회전,
좌측, 왼편 / 지나다 100 200 500
4 위, 아래, 밑 / 꼭대기 / 올라가다, 내려가다 100 200 1000
5 앞, 뒤 / 에서 보이는, 에서 보여지는 50 100 400
6 안, 속, 내 / 지하 / ~에 있는 / 들어가다 / i층 (i=1,2,3,···) 4 8 400
7
근처, 근방, 부근, / 주변, 주위, 인근 /위치하다, 존재하다, 도착하다, 내리다, 가다, 돌아가다, 직진하다 / ~에서 부터~까지 / 밖, 겉, 모퉁이,
바깥 / 동쪽, 서쪽, 북쪽, 남쪽
400 800 1200
경을 이용해 공간질의를 수행한다.
기구축된 POI 데이터베이스에 존재유무를 파악한 결과, Table 11과 같이 366건이 기존 데이터베이스에 존재했으며 2,227건이 기존에 없는 데이터였다. 2,227 건은 기존에 있는 데이터의 가명이거나 새로운 POI 데이터이다. 가명과 새로운 POI 데이터의 두 가지 활 용여부를 구분하는 데는 추출POI 명칭과 관계를 갖는 기존POI의 명칭을 가지고 참조자료를 활용한다. 여기 서 추출POI 명칭을 통해 관련 업종을 파악할 수 있다 면 해당 카테고리를 활용한다. 예를 들어, Table 9의 4번 항목을 보면 ‘커피그루나무’라는 추출POI 명칭을 통해 ‘카페’라는 카테고리를 파악할 수 있고, 이를 이 용해 ‘제주KBS’ 주변 카페를 찾는다. 찾은 카페가 ‘하 루에, 소담카페, 미래원, 커피그루나무···’라면 추출 POI인 ‘커피그루나무’와 찾은 ‘하루에’ 두 명칭을 참 고하여 가명으로 사용되는지 확인하고, 확인 되지 않 는다면 ‘커피그루나무’, ‘소담카페’처럼 그 다음 검색 된 카페 명칭으로 확인하는 방식이다. 해당 예의 경우 는 기존에 구축되어 있는 제주 KBS점 ‘커핀그루나루’
의 가명으로 활용되는 것으로 확인되었다. 10번 항목 인 ‘포항공대학관’의 경우는 ‘포항공과대학교학생회 관/포항공대학생회관’에 추가 가명으로 활용된다. 다
른 예로, 7번 항목은 앞의 가명확인을 위한 과정을 통 해 확인했을 때, 가명으로 활용되는 데이터가 없기 때 문에 ‘고려병원’ 뒤에 있는 ‘모델노래방’이라는 새로 운 POI 데이터로 활용한다.
4.4 공간어의 공간범위 산정
트위터 메시지에 포함된 기존POI간의 관계를 통해 공간어의 공간범위를 산정하여 사람들이 인지하는 정 도의 범위를 파악하고자 한다. 산정한 공간범위를 이 용한다면 기존에 없는 새로운 POI 데이터의 공간상 위치범위를 파악할 수 있고, 공간검색시 범위산출에 도 활용할 수 있다. 본 실험에서는 공간어의 공간범위 를 산정하는데 추출POI 중 기존에 가지고 있는 366건 을 대상으로 한다. Table 12에 산정한 공간어는 포함 하는 의미에 따라 상응하는 공간어를 일곱 그룹으로 구분하였으며, 공간범위 단위는 m(meter)이고, 산정시 십의 자리에서 반올림하였다. 여기에 공간범위를 세 가 지로 구분하였다. 그 이유는 일반적으로 시설물 자체만 을 가지는 POI뿐만 아니라 일정 경계를 가지는 POI도 있기 때문이다. 예를 들어, ‘앞’이라는 공간어는 준거가 되는 POI를 기준으로 해당 장소 밖에 위치하는 POI를 공간상 표현할 때 사용한다. 여기서 사람들이 말하는
‘앞’이라는 공간어가 50m정도의 공간범위를 뜻한다 면 대학교나 대형병원과 같이 일정 경계를 가지는 대 상을 준거로 활용할 때는 내부 경계만 50m가 넘기 때 문에 경계 밖에 있는 장소 정보를 나타낼 수 없다. 또 건물의 규모에 따라 사람들이 인지하는 공간범위도 다 를 수 있다. 본 연구에서는 공간범위를 세 가지로 구분 하는데, 경계가 없는 일반적인 대상을 구분 1, ‘백화점, 지하철역’등과 같이 일정 경계가 있는 대상을 구분 2,
Table 14. Information of reference object POI among search results
Reference object POI
POI with spatial relations (Extracting POI)
Coordinate (x,y)
1 서울
특별시청
-삼성미술관플라토 -버거킹
37.5666484, 126.9783364
2 세종
문화회관 -커리팟 37.5725974,
126.9757271
3 문화관 -명례방 37.5631122,
126.9867612
4 숭례문
수입상가 -MOMMOCOFFEE 37.5593623, 126.9761716
5 FEDEX
KINKOS -폴바셋 37.5752940,
126.9788510
Table 13. Information of extracting POIs among search results
Extracting POI Reference object POI
Spatial Relation
Spatial
Range(m) Formal name Address
1 삼성미술관플라토 서울특별시청 근처 800 플라토 서울특별시 중구 세종대로 55
2 버거킹 서울특별시청 뒤 100 버거킹 서울특별시 중구 무교로 17
3 커리팟 세종문화회관 지하 8 커리포트 서울특별시 종로구 세종로 81-3
4 명례방 문화관 3층 8 명례방 서울특별시 중구 명동길 74
문화관 3층
5 MOMMOCOFFEE 숭례문수입상가 옆 100 MOMMOCOFFEE 서울특별시 중구 남대문시장길 12
6 폴바셋 FEDEXKINKOS 맞은편 60 폴바셋 서울특별시 종로구 종로 1길 50
Figure 17. Interface of POI search system
Figure 18. Result screen of POI search system 구분 2보다 경계가 큰 ‘대학교, 콘도리조트, 시장’과 같은 대상을 구분 3으로 분류한다.
4.5 추출POI의 실제 명칭과 위치 비교 분석 본 연구에서 추출한 POI는 공간관계를 통해 공간상 위치범위를 가지고 있다. 해당 실험에서는 추출한 POI의 실제 명칭과 주소를 참조하여, 본 연구에서의 공간범위를 이용해 추정한 위치범위와 비교분석한다.
이를 통해 산정한 공간범위의 타당성을 보이고자 한다.
이를 위해 추출한 POI를 검색하고 지도에 표현하기 위한 검색 시스템을 개발하였다. 검색엔진으로는 Solr, 지도에는 Google map API를 이용하였다. Figure 17은 개발한 검색 시스템이며, ①에 검색란이 위치하고 ② 는 검색된 추출POI의 명칭과 위치범위 정보를 텍스트 로 나타낸다. ③은 지도위에 해당 POI의 위치를 표현 한다. 입력란에는 원하는 지역 또는 장소와 함께 검색 범위를 같이 입력한다. 그러면 입력한 지점에 대해 각 각의 준거POI를 기준으로 색을 가지는 원의 범위 형 태로 검색결과가 제공된다. 본 연구에서는 대상지역 을 ‘서울시청 1km’로 선정하였다. Figure 18은 이에 대한 검색 결과를 나타내며, 총 6건의 추출POI가 검색 되었다.
4.5.1 주소를 참조한 공간위치 비교
검색된 추출POI는 총 6건이며, 참조되는 준거POI는 5건이다. Table 13은 추출POI에 대한 준거POI, 공간관 계, 공간범위, 정식명칭, 실제주소를 나타내며, 정식명
Figure 19. Comparison of spatial range of location calculated in research and actual address of extracting POIs
Table 15. Comparative analysis of extracting POIs
Extracting POI
Calculated spatial range(m)
Actual spatial range(m)
1 삼성미술관플라토 800 634.94
2 버거킹 100 99.26
3 커리팟 8 -
4 명례방 8 -
5 MOMMOCOFFEE 100 75.92
6 폴바셋 60 66.72
칭과 실제주소는 웹 정보를 통해 획득하였다.
추출된 POI는 준거POI의 위치좌표를 기준으로 공간 상의 위치범위로 나타낸다. Table 14은 검색된 추출POI 에 대한 준거POI의 정보로, 이에 대한 위치좌표를 함 께 나타내었다.
검색된 결과를 토대로, 추정한 추출POI의 공간상 위 치범위와 실제주소를 참조한 위치범위를 비교한다.
해당 주소를 가지고 준거POI와의 거리를 계산하여 실 제 추출POI의 정확한 위치범위를 파악할 때는 Google map의 거리계산 기능을 활용한다. Figure 19은 검색된 추출POI의 추정 위치범위와 실제 주소를 이용한 범위 를 나타낸다. 좌측은 연구에서 산정한 공간범위를 이 용해 나타낸 것이고, 우측은 실제주소를 참고해 나타 낸 것이다. 이에 대해 산정한 공간범위와 실제 범위 값을 비교해 Table 15에 나타내었다. 대부분 연구에서 산정한 공간범위가 실제 범위 내 또는 근사 범위로 확 인된다. 그 이유는, 트위터 메시지에 사람들이 인지하는 POI간의 공간관계를 통해 범위를 산정했기 때문이다.
검색된 추출POI는 두 가지 형태로 활용된다. 하나는 기존 데이터의 가명이거나 새로운 POI 데이터이다.
검색된 추출POI 6건을 대상으로 참조자료(웹사이트) 로부터 활용여부를 판단했을 때 ‘삼성미술관플라토’
는 기존에 존재하는 ‘플라토’라는 정식명칭을 가지는 데이터의 가명으로 활용되었다. ‘플라토’ POI 데이터 는 기존에 ‘서울시태평로플라토/서울태평로플라토/
태평로플라토/플라토태평로/로댕갤러리(구)/플라토 미술관’의 가명을 가진다. 대부분의 가명들은 지명과 도로명을 결합한 기본적인 패턴을 가지는 가명이다.
Figure 20. Calculated range of spatial search utilized with spatial relations
하지만 트위터에서 추출한 ‘삼성미술관플라토’는 기 존과는 다른 사람들이 사용하는 새로운 형태의 가명 이라고 할 수 있다. 나머지 5건은 기존에 없는 데이터 로, 새로운 POI 데이터로 활용된다. 그 중 ‘커리팟’과
‘명례방’은 ‘지하’와 ‘3층’이라는 관계로 해당 준거 장 소 내부에 존재하는지의 파악이 중요하다. 해당 추출 POI는 실제로 세종문화회관과 문화관 안에 존재하는 것으로 확인되었다.
검색된 추출POI는 정확한 위치좌표로써 장소를 파 악하기는 어려우나, 특정 기준이 되는 장소에서 공간 범위를 통해 위치를 파악할 수 있다. 여기에 같은 장소 를 말하는 추출POI가 많아질수록 보다 정확하게 파악 할 수 있다. 예를 들어 ‘서울시청 뒤 버거킹’에 대한 정보에 추가로 ‘대한체육회 한국박물관 건너편 버거 킹’, ‘센트럴치과 옆 버거킹’이라는 데이터가 있다면 버거킹에 대한 위치를 더 정확하게 추정할 수 있다.
4.6 공간관계를 활용한 공간검색
본 연구에서 구축한 공간관계를 활용하면 ‘근처, 주 변’과 같은 공간검색 외에도 ‘맞은편, 앞’과 같은 방향 성을 가지는 공간어를 이용한 검색이 가능하다. 여기 에는 찾고자 하는 기준 대상이 되는 POI와 관계를 가 지는 POI를 발견하고, 해당 관계에 대한 공간어의 공 간범위 내에 또 다른 관계를 가지는 POI를 찾아서 범 위를 확장해가는 방법을 이용하게 된다. 이렇게 형성 되는 검색범위의 최대 반경은 Table 12의 구분 Class 3을 이용해 제한한다. 공간검색을 위한 범위산출의 예 는 Figure 20와 같다. 예를 들어, ‘교보타워 맞은편’을 찾고자한다면, 우선 기준이 되는 ‘교보타워’의 관계를 찾는다. 해당 예에서는 ‘신한은행’과 ‘맞은편’이라는 관계를 가지고 있어 해당 Figure 20의 ①과 같이 ‘교보 타워 맞은편’ 위치를 파악할 수 있다. 위치를 파악한 후, 해당 위치에서 특정 공간범위 내에 공간관계를 가 지는 또 다른 POI를 찾는다. 이 때 공간범위에는 준거 POI와 첫 번째 관계일 경우 ‘맞은편’ 위치의 기준이 되므로 거리를 계산하여 활용하고, 두 번째 관계부터 는 Table 12에서 산정한 범위 값을 활용한다. 이에 따 라 ‘신한은행’은 첫 번째 관계 POI로써 ‘교보타워’와 거리를 계산하여 해당 값을 반지름으로 하는 원의 범 위로부터 또 다른 관계를 가지는 POI를 찾는다. 해당 범위 내에 있는 ‘신한은행’은 ‘스위트스페이스 골목’
이라는 또 다른 관계가 존재한다는 것이 발견되었고, Figure 20의 ②와 같이 ‘골목(100m)’ 범위를 가지는
‘스위트스페이스’의 위치로부터 해당 공간어 범위 내
에 다른 관계를 가지는 POI를 다시 찾는다. 이 때 추가 로 ‘올리브영’을 찾고 ‘지나다’라는 관계를 가지는 ‘신 논현역’을 발견하게 된다. 그러면 또 다시 두 POI를 기준으로 ‘지나다(올리브영:100m, 신논현역:200m)’
의 공간범위로부터 관계 POI를 찾는다. 그러면 Figure 20의 ③과 같이 ‘신논현역’으로부터 관계를 갖고 있는
‘농협’을 찾게되고, 이와 ‘뒤(농협:50m, 카도야:50m)’
라는 관계를 갖는 ‘카도야’를 최종적으로 찾게 된다.
이러한 방법을 통해 최종적으로 ‘맞은편’에 대한 최대 범위는 Figure 20 ④와 같이 관계를 가지는 POI의 모 든 공간범위와 해당 공간어의 최대 범위인 300m내에 교차되는 면적(붉은색 빗금)의 공간범위가 형성된다.
본 연구에서 공간관계를 활용한 검색과 기존 지도 서비스의 검색을 비교해보고자 한다. 이때는 ‘교보타 워 맞은편 카페’를 찾을 때를 대상으로 한다. 기존의 지도 서비스는 ‘맞은편’을 이용한 검색이 제공되지 않 으므로 ‘근처, 주변’에 해당하는 검색범위를 비교한 다. Figure 21은 공간검색에 대한 비교 결과로, 검은색 마커는 ‘교보타워’이고 붉은색 마커는 검색된 카페이 다. Figure 21의 ①은 공간검색 범위를 비교한 것으로, 좌측은 기존 지도 서비스의 공간검색 범위인 2km를 나타내고, 우측은 본 연구에서 산출한 ‘맞은편’의 범 위를 나타낸다. 여기서 2km의 범위로는 정확히 맞은 편이라는 위치를 파악하기 어렵다. 하지만 본 연구의 공간관계를 이용한 방법은 ‘맞은편’의 위치를 정확히 파악하고 그에 해당하는 범위산출이 가능하다. Figure 21의 ②는 각 범위로부터 검색된 카페를 나타낸다. 좌
Figure 21. Comparison of spatial search between existing map-search service and utilizing spatial relations
측의 기존 지도 서비스는 ‘교보타워’를 기준으로 원의 형태로 멀리 떨어진 장소까지 검색이 되는 반면, 우측 의 공간관계를 통해 산출한 범위는 최대 범위를 제한 하기 때문에 최종적으로 원이 아닌 새로운 다각형 형 태의 범위 내에 ‘맞은편’에 위치한 카페의 검색결과를 얻을 수 있다.
또한 POI마다 각기 다른 관계를 가지기 때문에 같은
‘맞은편’이라고 검색을 해도 서로 다른 형태의 범위가 산출된다. 여기에는 해당 지점마다 달라지는 동적인 공간범위 산출로 인해 지도에서 파악하기 어려운 비 가시적 특성까지 고려된다고 할 수 있다. 예를 들어
‘63빌딩 앞’이라면 한강이 지나는 쪽보다는 공원이나 아파트 방향이 사람들이 말하는 ‘앞’이 될 것이다. 즉, 사람들이 언급되는 메시지를 통해 구축된 공간관계로 부터 공간범위를 산출한다면 사용자가 보는 시각적 관점에 따라 지도에서 판단하는데 혼동되는 공간어의 방향을 사람들이 실제로 이용하는 방향으로서 파악할 수 있다. 여기에 수집되는 트위터를 통해 공간관계를 계속해서 구축한다면 보다 정확한 검색범위 산출이 가능하다.
5. 결 론
본 연구에서는 SNS 데이터 중 트위터를 대상으로 기계학습 방법을 통해 POI 명칭을 추출하고, 공간어 를 활용해 POI간의 공간관계를 구축하였다. 제시한
방법을 통해 기구축된 기존POI와 추출POI간의 공간 관계로부터 새로운 데이터를 추출하였다. 또한 기존 POI간의 공간관계로부터 현재 지도 서비스의 공간검 색에서 사용되는 기본적인 원의 형태가 아닌 각각의 공간관계에 따라 산출되는 새로운 형태(다각형)의 범 위를 공간검색에 활용하였다. 추출한 데이터는 기존 데이터의 가명으로 쓰이거나 새로운 POI 데이터로 활 용할 수 있었다. 이로 인해 기존 데이터의 가명으로써 다양한 형태의 POI 명칭을 획득할 수 있었고, 기존에 없는 새로운 POI 데이터는 어느 특정 공간상 위치범 위로써 파악할 수 있었다. 그리고 공간관계를 활용한 공간검색에 있어 사람들이 인지할 수 있는 정확한 범 위를 산출할 수 있었고, 범위산출 방법을 통해 기존에 제공되지 않는 ‘맞은편, 앞’과 같이 방향성을 가지는 어휘를 이용한 공간검색을 할 수 있었다.
본 연구는 공간관계를 통해 새로운 POI 데이터 추출 과 공간검색에서의 범위산출에 활용하였으며, 이에 대한 한계점 및 향후 연구 계획은 다음과 같다.
첫째, 본 연구 방법은 트위터 메시지 전체 문맥내용 을 파악하여 추출하는 것이 아니기 때문에 실제로 존 재하지 않는 POI가 추출되기도 한다. 앞에서 예를 든
‘대치동학원가 가운데 영화관(롯데시네마로) 하나 생 겨씀 조켔다’와 같이 소망을 담고 있는 내용이 대표적 이다. 그렇기 때문에 이를 파악할 수 있는 전체 메시지 내의 부사와 동사 등의 품사를 이용해 구분할 수 있는 방안이 필요하다.
둘째, 추출POI 데이터를 가명 또는 새로운 데이터로 구분할 때 직접 검토하여 확인해야 한다. SNS 데이터 는 실시간으로 획득되기 때문에 데이터 양이 계속해 서 증가한다면 이를 구분하는데 많은 시간이 요구될 수 있다. 그렇기 때문에 참조할 수 있는 자료를 웹 상 에서 지속적으로 획득하여, 이를 구분할 수 있는 자동 화된 분류 기법을 고안할 필요가 있다.
셋째, 공간관계 구축에 있어서 트위터에서 언급된 공간적 관계만을 고려하였다. POI는 관광명소나 대형 건물, 지하철역 등과 같이 각각의 고유한 유형과 특성 을 가지고 있다. 그러므로 본 연구에서 트위터를 이용 하여 구축한 POI간의 공간관계로부터 관계가 구성되 는 특징(거리, 유형간 관계 등)을 분석한다면, 해당 특 징을 가지는 POI를 대상으로 선행적 공간관계를 추론 할 수 있을 것으로 기대된다. 그러면 트위터에서 추출 하는 관계뿐만 아니라 추가적으로 다양한 장소에 위 치한 POI의 공간관계를 구축하여 활용할 수 있을 것 으로 판단된다.
본 연구에서는 사용자들이 알고 있는 장소를 지칭
하는 다양한 명칭을 획득할 수 있었고, 기존과는 다른 형태의 공간검색 범위를 산출하여 활용할 수 있었다.
이를 통하여 기존의 검색방법보다 다양한 명칭 이용 과 효율적인 공간검색을 수행할 수 있어 사용자에게 보 다 정확하고 정밀한 정보를 제공할 수 있을 것으로 기 대된다. 또한 새로운 POI 데이터 획득을 통해 POI 변 화가 많은 지역을 파악할 수 있어 기존보다 효과적인 POI 데이터 구축작업을 할 수 있을 것으로 기대된다.
References
[1] Kim, K. R. 2012, Location Extraction from Meeting Announcements, KAIST, Master’s Thesis.
[2] Kim, J. H; Kim, H. C; Choi, Y. S. 2010, Feature Generation of Dictionary for Named-Entity Recognition based on Machine Learning, Journal of Information Management, 41(2):31-46.
[3] Sin, E. K. 2005, A Study on Semantic Change of Spatial Vocabulary in Korean - focused on Locational Words, Korea University, Doctoral Thesis.
[4] Yang, S. W; Lee, H. Y; Wang, J. H. 2009, A Point-Of-Interest Allomorph Database Construction System, Journal of the Korean Institute of Informa- tion Scientists and Engineer, 36(3):226-235.
[5] Oh, S. H. 2006, Infrastructure 21 Seminar - Current Situation of Construction and Future Direction of POI Data in Korea, Korea Research Institute for Human Settlements : planning and policy, 291(1):
152-157.
[6] Lee, J. E; Shin, S. H; Hwang, H. S; Jeong, S.
I; Kim, C. S. 2007, Service Model of Information Registration based on PoI in Life-GIS, Proc. of Korea Contents Association, Jun 16-20.
[7] Lee, J. W. 2008, Which Direction Is the Opposite Side? The Ambiguity of Spatial Language and Communication Problems, Journal of the Korean Geographical Society, 43(1):71-86.
[8] Lee, H. Y; Kim, H. Y; Jeong, B. Y; Jang, D.
J; Kim, K. H. 2011, The Growth of Social Media and Evolution of Online Social Relationship, Korea Information Society Development Institute.
[9] Jang, B. T. 2007, Next-Generation Machine Learning Technologies, Communications of the Korean Institute of Information Scientists and Engineers,
25(3):96-107.
[10] Jeong, S. J. 2011, A Study on Meaning Etension of Korean Spatial Language, Kyungpook National University, Doctoral Thesis.
[11] Jo, S. W. 2011, Technology in Age of Big Data, Kyungpook National University, Doctoral Thesis.
[12] Ek, T; Kirkegaard, C; Jonsson, H; Nugues, P.
2011, Named Entity Recognition for Short Text Messages, Proc. of International Conference of the Pacific Association for Computational Linguistics, p. 178-187.
[13] Hong, L; Ahmed, A; Gurumurthy, S; Smola, A;
Tsioutsiouliklis, K. 2012, Discovering geographical topics in the twitter stream, Proc. of the International Conference on World Wide Web, p. 769-778.
[14] Kumar, S; Morstatter, F; Liu, H. 2013, Twitter Data Analytics, Database Management & Informa- tion Retrieval.
[15] Mummidi, L. N; Krumm, J. 2008, Discovering points of interest from users’ map annotations, GeoJournal, 72(3):215-227.
[16] Nagarajan, M; Gomadam, K; Sheth, A. P; Ranabahu, A; Mutharaju, R; Jadhav, A. 2009, Spatio-Temporal- Thematic Analysis of Citizen Sensor Data: Challenges and Experiences, Proc. of International Conference on Web Information Systems Engineering, p. 539- 553.
[17] Rae, A; Popescu, A; Murdock, V; Bouchard, H.
2012, Mining the Web for Points of Interest, Proc.
of International SIGIR Conference on Research and Development in Information Retrieval, p. 711-720.
[18] Sakaki, T; Okazaki, M; Matsuo, Y. 2010, Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors, Proc. of International Conference on World Wide Web, p. 851-860.
[19] Kind Korean Morpheme Analyzer, http://kkma.snu.ac.kr.
[20] CRFsuite, http://www.chokkan.org/software/crfsuite/
benchmark.html
[21] Twitter Developers, https://dev.twitter.com.
[22] Twitter4j, http://twitter4j.org.
논문접수:2014.7.1 수 정 일:2014.8.4 심사완료:2014.8.18


![Table 5. Features used for named entity recognition of POIs Range of application Word -w[t-2], w[t-1], w[t], w[t+1], w[t+2] -w[t-1]|w[t], w[t]|w[t+1], POS (Part of Speech)](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5119681.333105/6.799.76.384.312.671/table-features-named-entity-recognition-range-application-speech.webp)