한국정보통신학회논문지 Vol. 25, No. 4: 537~542, Apr. 2021
다중속성 LSTM 모델 기반 TV 시청 패턴 분석 시스템
이종원1·성미경2·정회경3*
TV Watching Pattern Analysis System based on Multi-Attribute LSTM Model
Jongwon Lee
1· Mikyung Sung
2· Hoekyung Jung
3*1
Researcher, National Science & Technology Information Service, KISTI, Daejeon 34141 Korea
2
Graduate Student, Department of Computer Engineering, Paichai University, Daejeon 35345 Korea
3*
Professor, Department of Computer Engineering, Paichai University, Daejeon 35345 Korea
요 약
스마트 TV는 인터넷을 기반으로 기존의 TV에 비해 다양한 서비스와 정보를 제공하고 있다. 보다 개인화된 서비 스나 정보를 제공하기 위해서는 사용자의 시청 패턴을 분석하고 이를 기반으로 맞춤형 서비스나 정보를 제공해야한 다. 제안하는 시스템은 사용자의 TV 시청 패턴을 입력받고 이를 분석하여 사용자에게 맞춤형 정보로써 TV 프로그 램이나 영화를 추천한다. 이를 위해 전처리기와 딥러닝(deep learning) 모델로 시스템을 구성하였다. 전처리기는 사 용자가 시청한 TV 프로그램의 이름과 해당 TV 프로그램을 시청한 날짜, 시청한 시간 등을 입력하면 이를 정제한다.
그리고 정제된 데이터를 다중속성 LSTM 모델이 학습하고 예측을 수행하게 된다. 제안하는 시스템은 사용자에게 맞 춤형 정보를 제공하는 시스템으로써 기존의 IoT 기술과 딥러닝 기술을 융합한 디지털 컨버전스(convergence)의 선 도 기술이 될 것으로 사료된다.
ABSTRACT
Smart TVs provide a variety of services and information compared to existing TVs based on the Internet. In order to provide more personalized services or information, it is necessary to analyze users' viewing patterns and provide customized services or information based on them. The proposed system receives the user's TV viewing pattern, analyzes it, and recommends a TV program or movie as customized information to the user. For this, the system was constructed with a preprocessor and a deep learning model. The preprocessor refines the name of the TV program watched by the user, the date the TV program was watched, and the watched time. Then, the multi-attribute LSTM model trains the refined data and performs prediction.The proposed system is a system that provides customized information to users, and is believed to be a leading technology in digital convergence that combines existing IoT technology and deep learning technology.
키워드
: 딥러닝, 미래 예측, 시청 관리, 패턴 분석, LSTM
Keywords
: Deep learning, Future prediction, Watching management, Pattern analysis, LSTM
Received 31 January 2021, Revised 25 February 2021, Accepted 9 March 2021
* Corresponding Author Hoekyung Jung(E-mail:[email protected], Tel:+82-42-520-5640) Professor, Department of Computer Engineering, Paichai University, Daejeon 35345 Korea
Open Access
http://doi.org/10.6109/jkiice.2021.25.4.537
print ISSN: 2234-4772 online ISSN: 2288-4165Ⅰ. 서 론
스마트 TV는 인터넷을 통해 특정 TV 프로그램이나 영화 등을 사용자가 원하는 시간에 시청하는 것이 가능 해졌다. 또한 사용자가 다른 서비스들도 받을 수 있도록 매개체의 역할을 하고 있다. 스마트 TV는 기존의 TV에 비해서 다양한 서비스를 제공할 수 있지만 사용자의 패 턴을 분석하여 맞춤형 정보를 제공하기에는 구조적인 한계로 인해 어려움이 있다[1,2].
제안하는 시스템은 사용자의 TV 시청 패턴을 분석하 고 사용자에게 TV 프로그램을 추천한다. 이를 위해 전 처리기와 딥러닝 모델로 구성하였다. 또한 기존의 스마 트 TV들이 사용자가 시청했던 히스토리를 분석하지 못 했던 점을 해결하고자 한다.
이를 위해 전처리기에서는 사용자가 스마트 TV를 시 청했을 때의 데이터를 기반으로 분석한다. TV 프로그램 의 이름과 해당 TV 프로그램을 시청한 날짜, 시청한 시 간 등을 분석하거나 딥러닝 모델이 학습할 수 있도록 삽 입한 데이터를 순차 데이터로 변환한다. 그리고 정제된 순차 데이터를 다중속성 LSTM(Long Short-Term Memory) 모델이 학습하고 사용자가 시청하게 될 TV 프로그램을 예측하게 된다. 다중속성 LSTM 모델은 다양한 속성의 데이터를 분석할 때 효율적인 구조이며 비정형 데이터 를 순차 데이터로 정제함으로써 LSTM 모델의 구조적 인 장점을 활용할 수 있도록 하였다[3,4].
제안하는 시스템을 활용할 경우 사용자의 TV 시청 패턴을 분석할 수 있고 분석 결과를 기반으로 사용자가 볼만한 TV 프로그램을 추천받을 수 있다. 이는 IoT 분 야와 딥러닝 분야의 융합연구로써 차세대 스마트 TV 개 발에 핵심 기술이 될 것으로 생각한다.
Ⅱ. 시스템 설계
본 장에서는 제안하는 시스템의 설계를 다룬다.
2.1. 전처리기
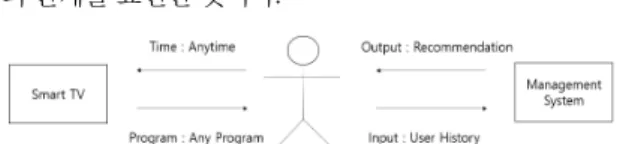
스마트 TV가 보급됨에 따라 사용자들은 원하는 시간 에 원하는 TV 프로그램이나 영화를 볼 수 있다. 이는 기 존 TV에 비해 스마트 TV가 제공하는 차별화된 서비스 이다. 그림 1은 스마트 TV와 사용자, 제안하는 시스템
의 관계를 표현한 것이다.
Fig. 1 Smart TV and user and management system
스마트 TV는 사용자가 다양한 선택을 할 수 있도록 도움을 주지만 사용자에게 맞춤형 서비스를 제공하는 것은 아니다. 현대인들은 자신의 성향이나 패턴을 분석 하여 TV 프로그램이나 영화를 추천하는 맞춤형 서비스 를 원하고 있다. 이러한 사회적인 변화에 따라 사용자가 스마트 TV를 시청하는 패턴을 분석하고 맞춤형 서비스 를 제공하기 위해서는 딥러닝 모델을 활용해야 한다. 그 리고 딥러닝 모델의 학습을 돕기 위해서는 비정형 데이 터에 순차 데이터로 변환하는 전처리기가 요구된다[5-8].
제안하는 시스템은 전처리기와 딥러닝 모델로 구성 하였으며 전처리기에는 사용자가 TV를 시청했을 때의 요일과 TV 프로그램의 이름, 시청한 시간 등을 입력한 다. 전처리기는 딥러닝 모델이 학습할 수 있도록 데이터 를 가공하는 역할을 수행한다. 또한 2가지 방식으로 데 이터를 분석하는데 첫 번째 분석 방법은 요일별 분석이 다. 대부분의 TV 프로그램들은 정해진 요일과 정해진 시간대에 방영된다. 이러한 특징을 활용하여 사용자가 특정 요일에 어떤 TV 프로그램을 보는지 분석할 수 있 다. 그림 2는 요일별 분석에 대한 개념도이다.
Fig. 2 Design of daily pattern analysis
두 번째 분석 방법은 프로그램별 분석하는 것이다. 요 일별 분석의 비교 대상이 같은 요일에 시청한 TV 프로 그램이라면 프로그램별 분석은 비교 대상이 사용자가 시청한 TV 프로그램 전체이기 때문에 사용자의 선호도 를 보다 직관적으로 나타낸다. 그림 3은 프로그램별 분 석에 대한 개념도이다. 표 1은 전처리기가 요일별 분석 과 프로그램별 분석을 진행하기 위해 사용할 함수들을 정의한 것이다.
Fig. 3 Design of analysis each TV program
Table. 1 Required function
Function Definition
Scanner_Day() Insertion Watched Day Scanner_Program() Insertion for Watched TV Program
Scanner_Time() Insertion for TV Watch time Analysis_Day()
Analysis_Program()
Daily Analysis Analysis for Each Program Output() Sorting and Print
각 함수는 차례대로 다음과 같은 기능을 수행한다. 사 용자가 TV를 시청한 요일을 입력하는 기능과 시청한 TV 프로그램의 이름을 입력하는 기능, 시청한 시간을 입력하는 기능, 분석 방식을 사용자가 선택하는 기능, 결과로 도출하는 기능이다.
전처리기는 딥러닝 모델이 사용자가 입력한 데이터 를 학습할 수 있도록 데이터를 정제하는 기능을 수행해 야 한다. 이를 위해 데이터를 2가지 형태로 도출한다. 제 안하는 시스템은 순차적인 데이터를 분석할 때 가장 많 이 활용되는 모델인 LSTM 모델을 활용한다. 이를 위해 사용자가 입력한 데이터들을 순서쌍으로 변환하고 모 델이 학습을 진행할 수 있도록 변형시킨다. 그림 4는 전 처리기가 LSTM 모델이 학습할 수 있도록 사용자가 입 력했던 데이터들을 변환하는 과정을 그림으로 나타낸 것이다. 데이터에 순서를 부여하여 2가지 형태로 출력 하고 해당 데이터들을 딥러닝 모델이 학습하게 된다. 표 3은 해당 과정을 위해 사용할 함수들을 정의한 것이다.
출력된 데이터는 (순서, 데이터), (데이터, 순서)와 같은 구조를 갖게 된다.
Fig. 4 Design of changing data type
표 2는 딥러닝 모델이 학습할 수 있도록 사용자가 입 력한 정보를 변환시키는 기능들이다. 제안하는 시스템 이 사용한 딥러닝 모델은 LSTM 모델이며 순차 데이터 를 처리하고 미래를 예측할 때 활용된다.
Table. 2 Required function 2
Function Definition
index to code() Changing data type(index, code) code to index() Changing data type(code, index)
제안 시스템에서는 사용자가 입력한 TV 시청 정보를 2가지 방식으로 분석한다. 또한 딥러닝 모델을 활용하 여 입력한 정보들을 학습하고 다음에 시청할 TV 프로그 램을 예측한다. 이는 사용자의 패턴을 지속하여 분석하 는 것으로 사용자가 입력하는 정보의 양이 많아질수록 정확도가 상승할 것이며 사용자의 패턴을 분석하고 맞 춤형 정보를 제공하는 시스템이 될 것이다. 그림 5와 6 은 시스템의 구성도와 구조도이다.
Fig. 5 Configuration of proposed system
Fig. 6 Architecture of proposed system
시스템은 전처리기와 딥러닝 모델로 구성된다. 전처
리기는 사용자의 TV 시청 기록을 입력받고 이를 요일별
분석이나 프로그램별로 분석하고 딥러닝 모델이 학습
할 수 있도록 데이터를 가공하는 역할을 수행한다. 딥러
닝 모델은 가공된 데이터를 학습하여 사용자의 다음 시
청 패턴을 예측하고 이를 반복하면서 정확도를 향상시
킨다. 학습이 완료된 시점에서 사용자가 볼만한 TV 프
로그램을 추천하는 기능을 수행한다.
Ⅲ. 시스템 구현
3.1. 구현 환경
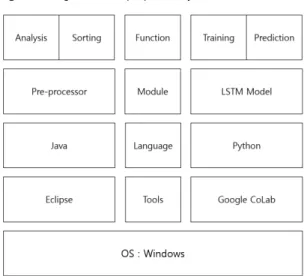
구현한 환경은 Windows 운영체제 기반의 CPU–
Intel i7-10700K, RAM –32G PC 환경이고, 사용한 툴은 이클립스와 구글 코랩 환경이다. 전처리기와 딥러닝 모 델은 Windows 환경에서 구축하며 프로그래밍 언어로 는 Java와 Python을 사용하였다. 전처리기가 수행하는 기능은 분석과 정렬이며 딥러닝 모델이 수행하는 기능 은 학습과 예측이다.
3.2. 전처리기 구현
전처리기가 시작되면 사용자는 자신이 TV 프로그램 을 시청했던 요일과 TV 프로그램명, 시청한 시간을 입 력하게 된다. 그림 7은 사용자가 TV 프로그램을 시청했 던 요일과 시청했던 TV 프로그램명, 시청한 시간을 입 력을 완료하는 화면이다.
Fig. 7 Screen of pre_processing 1
그림 8은 사용자가 데이터 입력을 완료한 뒤 요일별 분석을 선택했을 경우 도출되는 화면이다. 월요일과 화 요일에 TV 프로그램을 시청하였고 시청 시간과 시청한 TV 프로그램 목록을 보여준다.
Fig. 8 Screen of pre_processing 2
그림 9는 사용자가 데이터 입력을 완료한 뒤 프로그 램별 분석을 선택했을 경우 도출되는 화면이다. 시청한 TV 프로그램명과 시청 시간 목록을 보여준다.
Fig. 9 Screen of pre_processing 3
그림 10은 사용자가 데이터 입력을 완료한 뒤 딥러닝 모델이 학습할 수 있는 형태로 사용자가 입력한 데이터 들을 정렬하는 것이다. TV 프로그램명과 시청 시간을 입력하기 때문에 같은 TV 프로그램명이어도 시청 시간 이 다를 경우 다른 데이터로 인식할 수 있어야 한다. 그 러기 위해서는 전처리기가 위와 같이 데이터를 변환해 야한다. 그리고 변환된 데이터를 다중속성 LSTM 모델 로 학습하도록 한다.
Fig. 10 Screen of Pre_Processing 4
3.3. 딥러닝 모델 구현
딥러닝 모델을 구현하기 위해 구글 코랩 환경을 활용
하였다. 논문에서는 딥러닝 모델로 다중속성 LSTM 모
델을 선정하였고 3장에서 설명한 기초 실험을 바탕으로
하이퍼 파라미터들을 정의한다. 모델의 레이어는 1개,
학습데이터의 개수와 시퀀스 개수의 비율은 1/8로 설정
한다. 상태유지 기능을 활용하고 배치사이즈는 1로 지
정한다. 그림 11은 다중속성 LSTM 모델을 구현하기 위
해 필요한 케라스 및 각종 라이브러리를 import 한다. 케
라스는 파이썬으로 작성된 오픈 소스 신경망 라이브러
리로써 tensorflow를 백엔드로 활용하기 때문에 활용도
가 가장 높은 라이브러리 중 하나이다. 그림 12는 다중
속성 LSTM 모델의 구조를 정의하는 화면이다. 레이어
의 개수는 1개이며 출력을 담당하는 Dense 레이어를 추
가한다. 그리고 모델이 예측하게 되는 데이터는 여러 개
이기 때문에 활성함수로는 ‘softmax’를 사용한다.
Fig. 11 Implementation of LSTM-V 1
Fig. 12 Implementation of LSTM-V 2
3.4. 실험 및 고찰
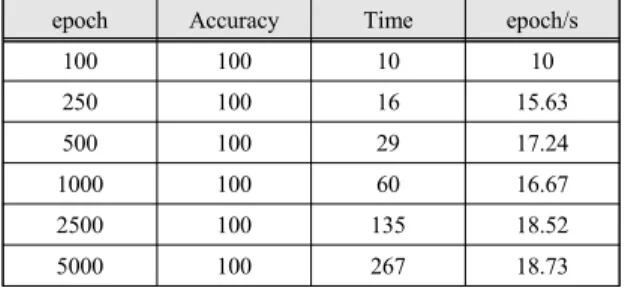
구현한 전처리기와 딥러닝 모델의 효율성을 검증하 기 위해 실험방법은 학습데이터의 개수를 변경하고 개 수를 변경할 때 마다 학습의 반복 횟수가 미치는 영향에 대해서 분석하였다. 이는 학습의 반복 횟수가 적을 경우 정확도를 보장할 수 없고 많을 경우 과적합이 될 수 있 기 때문이다. 표 4와 5, 6, 7은 학습 데이터의 길이를 변 경해가며 실험을 진행한 결과를 보인다.
총 24회 실험을 진행하였고 학습데이터의 개수 변화 에 따라 학습 및 예측에 소요되는 시간이 비례적으로 상 승하였다. 그리고 사용자가 입력한 TV 프로그램명과 시 청 시간을 서로 다른 속성으로 정리하고 다중속성 LSTM 모델이 학습하도록 하였다. 다중속성 LSTM 모 델의 경우 타 모델들에 비해 여러 개의 속성으로 학습 및 예측을 수행할 수 있는 구조적인 장점이 있다. 이러 한 장점을 바탕으로 사용자의 TV 시청 패턴을 분석하고 이에 대한 예측을 수행하였다. 학습데이터의 개수가 많 아질수록 보다 많은 횟수로 잘못된 데이터를 예측하여 그래프에 기록되었다. 예측의 정확도는 학습데이터의 개수가 54개 이하이고 학습의 반복 횟수가 1000회 일 때 가장 오차 범위가 적었다.
본 논문의 시스템은 사용자가 입력한 TV 시청과 관 련된 데이터들을 분석 및 정제하고 딥러닝 모델이 학습 하여 사용자의 TV 시청 패턴을 예측하였고 정확도는 100퍼센트였다. 이는 사용자에게 맞춤형 데이터나 서비 스를 제공하는 시스템들의 연구 방향성을 제시해줄 수 있는 연구로 사료된다.
Table. 3 Result of test(training data 10)
epoch Accuracy Time epoch/s
100 100 10 10
250 100 16 15.63
500 100 29 17.24
1000 100 60 16.67
2500 100 135 18.52
5000 100 267 18.73
Table. 4 Result of test(training data 27)
epoch Accuracy Time epoch/s
100 100 12 8.33
250 100 29 8.62
500 100 46 10.87
1000 100 88 11.36
2500 100 214 11.68
5000 100 432 11.57
Table. 5 Result of test(training data 54)
epoch Accuracy Time epoch/s
100 100 22 4.55
250 100 47 5.32
500 100 92 5.43
1000 100 171 5.85
2500 100 430 5.81
5000 100 866 5.77
Table. 6 Result of test(training data 100)
epoch Accuracy Time epoch/s
100 100 42 2.38
250 100 101 2.48
500 100 197 2.54
1000 100 401 2.49
2500 100 969 2.58
5000 100 1949 2.57
Ⅳ. 결 론
본 논문에서는 사용자의 TV 시청 패턴을 분석하고
사용자의 패턴을 예측하여 특정 TV 프로그램을 추천하
는 시스템을 제안하였다. 시스템은 전처리기와 딥러닝
모델로 구성하였고 전처리기는 사용자가 입력한 데이 터들을 기반으로 2가지 형식의 분석을 진행할 수 있고 딥러닝 모델이 학습할 수 있도록 데이터의 구조를 변환 해준다. 변환된 데이터의 구조는 TV 프로그램명과 시청 시간으로 구성된 데이터이며 순차적으로 정렬된다. 이 러한 구조의 데이터를 기반으로 학습 및 예측을 수행하 기에 적합한 딥러닝 모델을 선정하기 위해 기초 실험을 진행하였고 다중속성 LSTM 모델을 선정하였다. 그리 고 모델의 하이퍼 파라미터들을 변경해가며 도출되는 정확도들을 정리하였고 최적화를 진행하였다. 최적화 를 진행한 다중속성 LSTM 모델로 학습데이터의 개수 를 변경해가며 여러 차례 실험을 진행하였고 높은 정확 도로 예측을 수행하였으며 이는 제안하는 시스템의 우 수성을 나타내는 결과였다.
이러한 실험 결과들을 바탕으로 본 논문에서 제안하 는 시스템은 맞춤형 서비스를 제공하기 위해 진행되고 있는 연구에 도움이 될 것으로 사료된다.
ACKNOWLEDGEMENT
This work was supported by the research grant of Pai Chai University in 2021.
References
[ 1 ] S. O. Kim, J. H. Koo, and S. J. Lee, “A Study on Combinations of Prediction Methods by Using Basic Statistics in Collaborative Filtering Recommender Systems,”
Journal of The Korean Data Analysis Society, vol. 21, no. 2, pp. 733-744, Apr. 2019.
[ 2 ] J. Y. Kang and H. S. Lim, “Proposal of Content Recommend System on Insurance Company Web Site Using Collaborative Filtering,” Journal of Digital Convergence, vol. 17, no. 11, pp. 201-206, Nov. 2019.
[ 3 ] J. Y. Park, “Estimation of Electrical Loads Patterns by Usage in the Urban Railway Station by RNN,” The Transactions of the Korean Institute of Electrical Engineers, vol. 67, no. 11, pp. 1536-1541, Feb. 2018.
[ 4 ] X. F. Wang and H. C. Kim, “Text Categorization with Improved Deep Learning Methods,” Journal of Information and Communication Convergence Engineering, vol. 16, no.
2, pp. 106-113, Jun.. 2018.
[ 5 ] D. H. Seo, J. S. Lyu, E. J. Choi, S. H. Cho, and D. K. Kim,
“Web based Customer Power Demand Variation Estimation System using LSTM,” Journal of the Korea Institute of Information and Communication Engineering, vol. 22, no.
4, pp. 587-594, Apr. 2018.
[ 6 ] J. W. Lee, H. Y. Kim, and H. K. Jung, “Deep Learning Module Optimization based on Sequential Data Prediction,”
ASM Science Journal, vol. 13, no. 1, pp. 82-91, Feb. 2020.
[ 7 ] H. I. Kim and J. Y. Lee, “Prediction of Urban Flood Extent by LSTM Model and Logistic Regression,” Journal of the Korean Society of Civil Engineers, vol. 40, no. 3, pp.
273-283, Jun. 2020.
[ 8 ] J. S. Park and H. H. Lee, “Prediction of high turbidity in rivers using LSTM algorithm,” Journal of the Korean Society of Water and Wastewater, vol. 34, no. 1, pp. 35-43, Feb. 2020.
이종원(Jongwon Lee)
2014년 배재대학교 컴퓨터공학과(공학사) 2016년 배재대학교 컴퓨터공학과(공학석사) 2019년 배재대학교 컴퓨터공학과(공학박사) 2020년 ~ 현재 한국과학기술정보연구원
NTIS센터 박사후연구원
※관심분야 : U-Healthcare, 빅 데이터, IoT
성미경(Mikyung Sung)
1994년 한남대학교 경영학과 (경영학사) 1996년 배재대학교 정보처리학과(이학석사) 1993년 배재대학교 컴퓨터공학과(박사과정) 1988년 ~ 현재 배재대학교 교직원
※관심분야 : 빅데이터, IoT, AI
정회경(Hoekyung Jung)
1985년 광운대학교 컴퓨터공학과(공학사) 1987년 광운대학교 컴퓨터공학과(공학석사) 1993년 광운대학교 컴퓨터공학과(공학박사) 1994년 ~ 현재 배재대학교 컴퓨터공학과 교수
※관심분야 : Machine learning, Big data, Embedded system, U-Healthcare, IoT