사용자의 실시간 상황정보를 이용한 사용자 맞춤 검색 시스템
(Customized Search System using Real-time Contexts of User)
권 미 림1), 홍 광 진2), 정 기 철3)*
(Mi-Rim Kwon, Kwang-Jin Hong, and Kee-Chul Jung)
요 약 오늘날 우리는 인터넷에서 쉽게 정보를 얻지만, 수많은 정보들은 데이터 검색에 방해가 되며 비효율적이다. 그러므로 적절한 정보를 제공하는 사용자 맞춤의 웹 검색 시스템이 필요하다. 본 논문에서는 날씨, 위치, 시간 등 사용자가 처한 상황 정보를 반자동으로 수집하여 사용자에게 필요한 정보를 제공할 수 있는 검색 시스템을 제안한다. 이러한 상황 정보를 이용하면 검색 시스템은 사용자가 특정한 상황에서 어떤 정보를 원하는지 알 수 있으며, 사용자에게 보다 더 유용한 정보를 제공할 수 있다. 제안된 시스템은
‘자발적 공유경제 방식의 개인 한글 콘텐츠 제작/공유 서비스’에 기반 하여 각 입력, 저장, 검색 부분에 데이터 파싱 알고리즘을 추가하였다. 실험에서는 몇 개의 일반적인 검색어를 이용해서 기존의 시스템과 제안된 시스템의 결과를 비교한다.
핵심주제어 : 상황 정보, 데이터 파싱 알고리즘
Abstract In these days, people get information from internet easily. However, there are too many information. It makes interrupt and inefficient for searching data. Therefore, we need user customized web search system which provides appropriate information. In this paper, we propose a searching system that can collect semi-automatically conditions of users such as weather, location and time and provide essential information to users. Using these context data, the proposed system can understand what information users want in specific situations and can provide more useful information to users than existing systems. The proposed system based on ‘Production/Sharing Service of Personal Korean Contents with Voluntary Sharing Economy System’ and we add data parsing algorithm in each input, store and search part. In the experiments, we compare and analyze the results of existing system and the proposed system using some general key words.
Key Words : Context Data, Data Parsing Algorithm
1. 서 론
* Corresponding Author : [email protected]
Manuscript received Oct. 17 2016 / revised Oct. 31 2016 / accepted Nov. 1 2016
1) 숭실대학교 글로벌미디어학부 제1저자 2) 숭실대학교 글로벌미디어학부 교신저자 3) 숭실대학교 글로벌미디어학부 교신저자
오늘날 우리는 웹을 통한 인터넷 정보 접근을 보편적으로 수행하지만, 엄청난 정보의 양과 다 양성은 오히려 효율적인 정보 검색을 방해한다.
사용자가 필요로 하는 지식과 정보를 얻기까지는 여러 인터넷 사이트를 찾아다녀야 하고, 단편적 인 지식과 정보를 통합하는 과정을 거쳐야 한다
[1]. 기존의 검색 엔진이 사용자의 검색 상황과 무관하게 일반적으로 타당한 모든 정보를 제공하 기 때문이다. 그러나 대부분의 사용자가 찾고자 하는 정보의 범위나 주제는 한정되어 있다. 이에 따라 적절한 정보를 찾기 위한 사용자의 부담을 덜어주고 편의를 제공하는, 즉 사용자 맞춤의 웹 검색 시스템이 필요함을 알 수 있다.
이에 대응하여 다양한 사용자 맞춤 정보 검색 이 제공되고 있긴 하지만 여전히 한계가 있으며, 개인마다 필요로 하고 선호하는 콘텐츠가 다르기 때문에 소셜 북마크 서비스처럼 사용자 각각에 맞는 콘텐츠를 골라 저장하고 필요할 때 검색할 수 있는 서비스가 요구되었다. 그러나 기존의 소 셜 북마크 서비스는 콘텐츠의 저장에 집중하고 있기 때문에, 본 논문에서는 소셜 북마크 서비스 에 기존 검색 서비스의 장점을 적용하여 개인에 게 적합한 정보를 편리하게 제공할 수 있는 방법 을 제시한다.
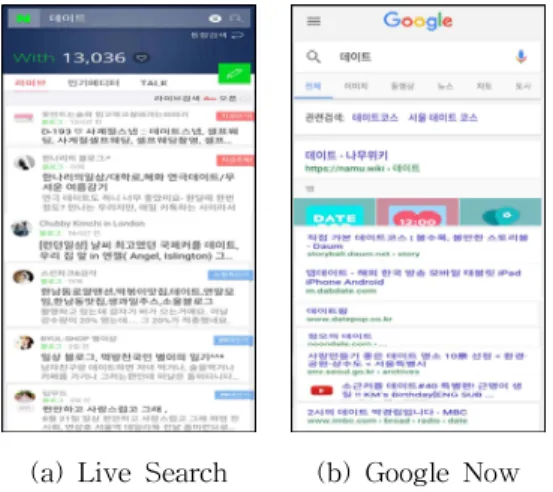
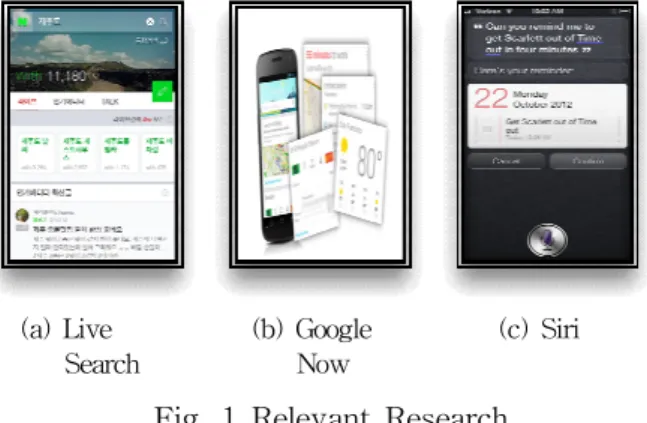
현재 일반적으로 제공되고 있는 사용자 맞춤 정보 검색 서비스는 ‘Fig. 1’의 네이버 라이브 검 색, 구글 나우, Siri 등이다. 광고성 블로그가 검 색 결과의 상위에 자주 노출되던 네이버는 2016 년 새로운 검색 알고리즘을 사용한 ‘라이브 검색’
서비스를 도입하였다. 이는 모바일 검색 방식으 로 사용자 환경에 따른 문맥을 고려해 모바일에 서 이용자 요구를 즉시 해결하고, 검색 의도에 맞는 역동적이고 생생한 정보를 제공하려는 콘셉 트로 개발되고 있다. 라이브 검색은 정보 생산자 (Creator)에 대한 이용자들의 선호도를 계산하는 알고리즘인 C-Rank를 바탕으로 구현해낸 검색 방식으로 검색어에 대해 공통의 관심사를 가진 이용자 간의 네트워크를 찾아내고 현재 가장 인 기 있는 문서와 생산자의 정보를 찾아 상호 소통 하게 하는 것을 목표로 한다. 기존의 이용자 클 릭을 중심으로 검색 의도를 분석하는 방식과 달 리 문서와 생산자에 대한 피드백을 반영함으로써 이용자들의 검색 의도를 보다 입체적으로 파악해 검색 결과를 보여준다. 라이브 검색의 주요 요소 는 이용자의 좋아요, 댓글 등을 활용한 피드백 (Feedback), 관심사가 유사한 이용자의 네트워크 정보를 활용한 위드니스(Withness), 장소, 시간, 날씨 등 이용자의 현재 상황에 따른 맥락을 고려
하는 콘텍스트(Context) 등이다.
이보다 더 개인화 된 서비스인 ‘구글 나우 (Google Now)'는 사용자의 요구를 사전에 예측 해 제안하는 최초의 가상 비서 서비스로, 위치정 보를 바탕으로 사용자가 일일이 검색하지 않아도 날씨, 교통, 식당 등 주변의 교통/지역 정보나 스 포츠, 관심 장소 등의 정보를 제공한다. 또한 집 에서 회사까지의 최적 경로 및 소요시간 등, 내 가 요구하는 다양한 정보를 때맞춰 알려주는 역 할을 하며, 나의 검색 습관을 기반으로 관심사에 대한 정보를 띄워주기도 한다.
(a) Live
Search (b) Google
Now (c) Siri
Fig. 1 Relevant Research (Using Context Data)
모바일 지능형 개인비서 서비스인 애플(Apple) 사의 시리(Siri)와 삼성(Samsung)사의 S 보이스 (S Voice) 또한 실세계에서 발생하는 다양한 상 황을 이해하고 이에 맞는 서비스를 제공하고 있 다. 이러한 서비스들은 사용자들의 상황에 맞춘 콘텐츠들을 자동적으로 검색하여 제공하고 있다.
그러나 구글 나우의 경우, 국내에서는 국가 안보상의 이유로 지도 데이터를 공개하지 않기 때문에 구글 지도와 연동된 기능을 사용할 수 없 으며 시리, S 보이스 등과 마찬가지로 음성인식 이 제대로 되지 않으면 사용자가 원하는 작업을 정확히 수행하기 어렵다는 단점이 있다. 또한 위 에서 언급한 서비스들은 모두 안드로이드나 ios 등 모바일 운영체제에 최적화되어 컴퓨터 웹상에 서는 사용할 수 없으며, 사용자의 개인적인 정보 를 다량 수집하기 때문에 개인 정보 유출의 문제 도 있다. 웹 검색에서 사용자의 날씨, 기분 등 다 양한 상황에 맞는 검색 결과를 제공하기 보다는
위치 정보를 위주로 검색 결과를 제공한다는 한 계도 있다.
기존의 소셜 북마크 서비스의 예시로는 Delicious 와 Diigo, Pearltrees를 들 수 있다.
Fig. 2 ‘Delicious’ Rank System
Delicious 북마크 서비스는 ‘Fig. 2’ 에 보이는 것처럼 북마크가 많이 된 웹페이지의 순위를 매 겨 보여주기 때문에 사용자가 특정 이슈에 관한 유용한 정보를 쉽게 얻을 수 있다. 이러한 Delicious는 태그와 카테고리를 이용한 분류 기 능, 소셜 공유 기능 등을 내장하는 데 그쳤지만 이후 ‘Fig. 3’과 같이 더 많은 기능이 추가된 소 셜 북마크 서비스들이 등장하였다.
(a) Diigo (b) Pearltrees Fig. 3 Social Bookmark Service
Diigo는 하이라이트, 웹 클리핑, 보고서 기능 등이 첨가되어 더욱 강력한 웹 자료의 보관, 정리, 활용, 공유에까지 그 기능이 확대되었다. Pearltrees 는 마인드 맵 형태와 트리 방식으로 북마크를 관 리하여 광범위한 북마크를 효율적으로 분류, 정
리할 수 있다. 또한 더욱 강화된 소셜 공유 기능 을 통해 타인의 북마크 트리를 가져오거나 특정 주제의 북마크 트리의 공유, 확장, 댓글 기능 등 을 가진다. 그러나 이러한 서비스들의 경우 기능 이 지나치게 많이 사용자가 이용하지 않는 기능 들이 생길 수 있으며, 사용법이 복잡하고 한글화 가 잘 되어있지 않아서 국내 사용자들은 불편함 을 느낄 수 있다.
Fig. 4 Based System Working
이에 본 논문은 북마크 서비스 상에서의 검색 에 집중하여 ‘자발적 공유경제 방식의 개인 한글 콘텐츠 제작/공유 서비스[2]’를 기반으로 사용자 의 다양한 상황정보들을 추가로 입력받아 사용자 가 어떠한 상황에서 해당 정보를 수집했는지 혹 은 검색을 하고 있는지를 파악해 사용자 맞춤형 검색 결과를 제공하는 시스템 모델을 제안한다.
이는 기존 북마크 서비스에서 제공하지 않는 ‘사 용자 상황 정보 기반 검색 서비스’ 기능을 추가 하여, 서비스 사용자들이 서로 북마킹한 콘텐츠 (URL)들을 검색을 통해 공유할 수 있도록 하는 것이다. 본 서비스의 검색 결과는 사용자의 위치, 날씨 등의 다양한 상황정보를 적용하여 ‘사용자 상황 적합성’ 이라는 특징을 가질 수 있다.
본 연구에서 기반으로 하는 ‘자발적 공유경제 방식의 개인 한글 콘텐츠 제작/공유 서비스’는 개인이 작성한 콘텐츠를 정형화된 틀로 편입시킬 수 있는 자동화된 플랫폼을 개발하고, 인터넷과 SNS에 산재되어 있는 개인이 작성한 콘텐츠를 활성화할 수 있는 서비스를 제공하는 것을 목적 으로 한다[2]. 이는 기존의 공유경제 방식 서비스 와 달리, 콘텐츠 작성자에게 일정수익을 배분할 수 있는 수익구조를 창출할 수 있고, 개인이 소 장하고 있는 디지털 콘텐츠를 보다 쉽고 편리하 게 저장/확인/관리/공유할 수 있다[2]. 기본적으 로 ‘Fig. 4’에 보이는 것처럼 입력, 저장, 결과 출 력의 단계를 거친다.
예를 들어, A라는 사람이 포털 검색 사이트에 서 ‘데이터베이스’라는 키워드로 자료를 찾다 유 용한 정보를 담고 있는 웹 페이지를 발견하면, 위 서비스를 통해 해당 URL 주소와 관련 키워 드를 작성하여 DB에 저장한다. 저장된 정보들은 다른 사용자들도 공유가 가능하여, B라는 사람이 위 서비스의 검색 창에 ‘데이터베이스’를 입력하 면 A가 저장했던 URL 정보를 포함하여, 다른 사용자들이 ‘데이터베이스’라는 키워드로 저장해 놓았던 URL 목록이 출력된다. 사람들은 자신이 원하는 정보를 찾기 위해 광고성 글이나 쓸모없 는 정보가 담긴 글들을 일일이 열어보지 않아도, 이 서비스를 이용하여 보다 쓸모 있는 정보를 효 율적으로 얻을 수 있게 된다. 이러한 기존 연구 는 서비스 이용자들이 직접 선별한 질 높은 콘텐 츠를 공유할 수 있다는 장점이 있지만, 사용자의 상황정보가 없는 상태로 URL의 저장과 검색이 이루어지기 때문에 상황에 맞는 적절한 검색 결 과를 얻기 힘들다는 단점이 있다.
이를 보완하기 위해 본 논문에서는 위 서비스 의 정보 입력과 정보 검색 과정에 사용자의 ‘상 황 정보’를 추가하여, 사용자가 어떤 상황에서 해 당 정보를 수집했는지 혹은 검색을 하고 있는지 를 파악해 사용자의 상황 맞춤형 검색 결과를 제 공하는 시스템 모델을 제안한다. 이는 기존 연구 에 새로운 기능을 추가한 것으로 서비스 내 검색 을 이용하는 사용자에게 더 적절한 정보를 제공 할 수 있어, 검색 결과의 정확도와 사용자 만족 도 향상을 기대할 수 있다.
2. 사용자 맞춤 검색을 제공하는 시스템 모델 본 논문에서는 사용자가 직접 입력하는 URL 관련 키워드 외에 사용자가 처한 상황과 관련한 상황 정보 키워드를 반자동으로 수집하는 방법과 그에 따른 효과를 다룰 것이다. 자동으로 수집할 수 있는 사용자의 실시간 상황 정보는 날씨, 위 치, 시간, 계절, 교통 등의 정보가 있으며, 사용자 의 현재 기분 상태와 같이 외부에서 알 수 없는 정보는 직접 입력받아 데이터베이스에 수집한다.
수집된 추가 키워드들은 사용자가 어떠한 상황에
서 해당 정보를 수집했는지 파악할 수 있으며,
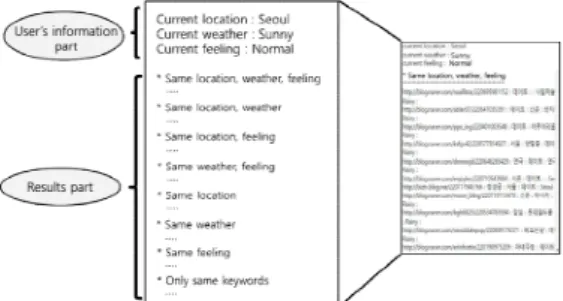
‘Fig. 5’의 그림처럼 정보들과 결합하여 사용자의 검색 상황에 맞춘 효과적인 검색 결과를 제공하 는데 쓰인다.
Fig. 5 User Customized Search with Contexts
2.1 상황 정보 생성
상황 정보란 위에서 언급한 바와 같이 사용자 가 처한 상황에서 실시간으로 받아올 수 있는 모 든 외부 정보를 말하며 시간, 날씨, 위치, 계절, 교통 등의 정보가 될 수 있다. 상황정보를 이용 하면 사용자가 어떤 상황에서 정보를 수집했는지 알 수 있으며, 이를 검색에 이용하면 사용자가 처한 상황에 맞는 정보를 제공할 수 있게 되어, 검색의 효율과 편리를 가져올 수 있다.
예를 들어, 비가 오는 날 갈만한 술집 정보를 얻고자 할 때, 검색 키워드에 ‘술집’ 라는 단어만 넣어도 이전에 사용자들이 비가 오던 날 저장했 던 막걸리 집이나 파전 집 등 비 오는 날씨에 갈 만한 술집과 관련된 URL 정보들을 얻을 수 있 게 된다. 혹은 여행 중에 맛 집을 검색할 때, ‘부 산 수영구 맛집’ 이라는 식으로 위치 정보를 검 색 키워드에 포함할 필요 없이 ‘맛집’ 이라는 단 어만 검색해도 검색자의 위치를 자동으로 파악하 여 가까운 위치의 맛 집을 검색해 준다.
이처럼 비슷한 상황에서 비슷한 정보를 얻고 싶어 할 가능성이 높기 때문에, 다양한 상황 정 보를 검색에 활용하는 것은 사용자가 보다 적합 한 정보를 찾고자 할 때 유용하다.
2.1.1 상황정보 자동 확보
외부 상황 키워드는 웹페이지 파싱(parsing)의 방식을 이용하여 자동으로 얻을 수 있다. 파싱이 란 파서(parser) 역할을 하는 컴퓨터가 문장 단 위의 문자열을 의미 있다고 여겨지는 토큰
(token)으로 분류하고 이들을 구문 트리(parse tree)로 재구성하는 구문 분석 과정을 뜻한다.
즉, 많은 정보를 담고 있는 웹 페이지에서 내가 원하는 문자열만을 지정하여 가져올 수 있다.
Fig. 6 Data Parsing Process
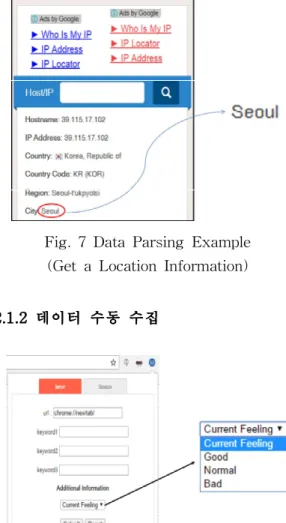
본 논문에서는, 다양한 상황 정보 중 외부 상황 을 직관적으로 인식/분류 가능하고 정보 활용도 가 높은 날씨와 위치 정보 두 가지를 얻는다. 이 는 정보를 저장할 때와 검색 할 때, 두 번 이루 어지며 ‘Fig. 6’과 같은 과정을 거친다. 위치와 날 씨 정보를 얻는 과정은 접속한 PC의 IP주소를 이용하여 해당 PC의 위치를 알려주는 웹 사이트 와 검색된 지역의 날씨 정보를 알려주는 웹 사이 트에서 원하는 정보를 지정하여 가져오는 방식으 로 이루어진다. 예를 들어, 아래의 ‘Fig. 7’에 보 이는 것처럼 접속한 PC의 위치정보를 알려주는 웹 사이트에서 원하는 정보인 도시 이름, 즉 Seoul 이라는 텍스트 정보만을 가져온다. 이 정 보를 날씨를 알려주는 웹사이트에 보내서 Seoul 의 현재 날씨 정보를 얻는다. 얻은 정보들은 URL과 관련 키워드가 저장될 때 함께 데이터베 이스로 보내진다. 이런 방식으로 위치와 날씨 뿐 만 아니라 계절, 시간, 국가 등 사용자의 다양한 상황 정보를 얻을 수 있다.
Fig. 7 Data Parsing Example (Get a Location Information) 2.1.2 데이터 수동 수집
Fig. 8 Input Context Information (Current Feeling)
사용자의 위치와 날씨 정보는 자동으로 수집되 고, 검색 시에도 자동으로 사용되지만 기분 정보 는 URL과 관련 키워드를 입력받을 때 혹은 검 색 할 때 사용자가 직접 선택해야 한다. 기분 정 보는 ‘Fig. 8’에 보이는 것처럼 좋음, 보통, 나쁨 세 가지로 분류된다. 해당 정보는 옵션으로 입력 이나 검색 시 사용자가 꼭 선택하지 않아도 되지 만 현재 기분과 관련된 정보를 얻고 싶을 때는 기분정보를 설정 한 후 검색하면 해당 기분정보 까지 포함하고 있는 더 세부적인 검색 결과를 얻 을 수 있다. 입력 시에도 마찬가지로 기분 정보 까지 함께 입력한다면 URL을 수집한 사람이 그 당시 어떤 기분으로 그 정보를 얻었는지 알 수 있으므로 더 자세한 정보 공유가 가능하다.
URL keyword1 keyword2 keyword3 addkey1 addkey2 addkey3 https://geoiptool.com/ IP location automatic Seoul Sunny Good
Fig. 9 Saved Data in Database 2.2 입력 및 저장
전체 데이터의 입력과 저장은 ‘자발적 공유경 제 방식의 개인 한글 콘텐츠 제작/공유 서비스 [2]’와 같은 방식으로 이루어진다. ‘Fig. 8’에 보이 는 것처럼 URL과 키워드의 입력은 웹브라우저 의 플러그인 버튼을 이용하는데, 플러그인 버튼 을 클릭하면 데이터를 입력하고 검색할 수 있는 작은 창이 뜬다. Input 파트에서는 현재 열려있 는 웹 사이트의 URL과 함께 관련된 키워드를 전송할 수 있다[2]. 여기에 자동으로 얻은 상황 정보들과 수동으로 얻은 ‘현재 기분’ 정보를 함께 저장하여 최종적으로 DB에는 ‘Fig. 9’처럼 저장 된다.
DB의 각 column 이름은 url, keyword1, keyword2, keyword3으로 사용자가 입력한 URL 주소와 관련 키워드들이 순서대로 하나의 레코드 를 이루며 저장된다. 여기에 자동으로 수집된 상 황 정보 키워드가 추가로 같이 저장되는데, addkeyword1, addkeyword2, addkeyword3이라는 이름의 column들에 위치정보, 날씨정보, 기분정 보가 순서대로 저장된다. 이러한 상황 정보 키워 드들 또한 ‘Fig. 9’ 에 나타난 것처럼 URL, 관련 키워드들과 함께 하나의 레코드로 묶여 저장된다.
2.3 사용자 맞춤 검색
검색은 ‘Fig. 10’에 보이는 검색 탭에서 이루어 진다. 검색 입력창에 검색하고자 하는 단어를 입 력 후 submit 버튼을 누르면, 입력된 단어를 포 함하는 관련 키워드를 가진 URL 목록이 데이터 베이스에서 검색된다. 이 과정에서 앞에서 설명 한 데이터 파싱 즉, 상황정보의 확보 과정이 자 동으로 이루어져 검색하는 순간의 위치, 날씨 정 보와 일치하는 상황 정보를 가진 URL이 함께 검색된다. 현재 기분 정보는 입력 때와 마찬가지 로 검색 시 수동으로 선택할 수 있다.
Fig. 10 Search Tab
데이터 검색의 과정은 ‘Fig. 11’의 그림과 같다.
사용자가 검색 키워드를 입력하면 keyword1, keyword2, keyword3 에 저장된 관련 키워드 중 검색 키워드와 일치하는 것을 찾아내고, 그것과 같은 레코드에 묶여 저장되어 있는 URL 주소를 결과 창에 출력한다. 여기에 상황 정보 검색이 이루어지기 위해, 검색하는 사람의 위치정보나 날씨정보, 기분정보 등을 DB에 저장되어 있는 addkeyword1, addkeyword2, addkeyword3 과 각 각 비교하여 검색 키워드와 관련 키워드가 일치 하면서, 상황정보까지 일치하는 URL목록을 찾아 출력한다.
Fig. 11 Context Data Search Process
즉, 사용자 맞춤 검색은 검색된 단어를 관련 키워드로 가지고 있는 URL 정보를 검색 후, 그 러한 정보 중에 검색된 순간과 같은 위치, 날씨 정보를 가지고 있는 URL 만을 추려서 출력한다.
이는 검색 키워드와 관련된 모든 정보를 출력 하 는 대신에 사용자가 특정한 상황에서 얻고자 하 는 정보만을 높은 적합성으로 제공하므로 사용자
가 효율적으로 검색 시스템을 이용할 수 있게 된 다. 또한, 세 가지 상황정보를 사용자가 원하는 방향으로 조합하여 검색결과를 확인할 수 있도록 여러 파트로 나뉜 검색 결과가 제공된다.
‘Fig. 12’ 에 보이듯이 검색 결과 화면 위쪽은 현재 검색하고 있는 사용자의 위치, 날씨, 기분 (선택) 정보가 나오며 아래 부분은 사용자가 검 색한 단어를 포함하는 정보들 중에 사용자의 상 황정보와 일치하는 검색 결과들이 출력된다. 위 치/날씨/기분이 모두 같을 때, 위치/날씨만 같을 때, 날씨/기분이 같을 때 혹은 날씨만 같을 때 등 정보의 다양한 조합으로 검색결과가 출력되기 때문에 사용자가 원하는 정보의 조합으로 결과를 얻을 수 있다.
Fig. 12 Context Data Search Result Screen
3. 실험 비교 및 결과
상황정보를 고려한 검색은 사용자의 요구에 맞 는 검색결과를 제공할 가능성이 높다. 본 논문에 서는 예시와 실험, 결과를 타 서비스와 비교 분 석하여 사용자가 원하는 정보를 어떻게, 얼마나 제공할 수 있는지 확인한다.
우선 일반적인 검색 사이트와 비교하여 상황 정보 검색이 사용자에게 훨씬 적절한 검색 결과 를 제공할 수 있다는 것을 몇 가지 예를 들어 실 험하고, 구체적인 수치를 통해 분석한다. 그 후 기존의 북마크 서비스와의 비교를 통해 북마크 내의 상황 정보 검색이 얼마나 효율적으로 사용 자가 찾고자 하는 콘텐츠에 도달하는지 실험한다.
3.1 검색 사이트와의 비교
제안하는 시스템에 저장된 전체 데이터의 수는 300개이다. 아직 공개된 서비스가 아니기 때문에 제한된 사용자에게서 데이터를 수집했고, 그 결 과를 토대로 실험에 사용하였다. 실험을 위해 다 음의 3가지 상황을 가정하였다.
1. 서울에 위치한 사람이 비가 오는 날 ‘데이 트’ 코스를 검색
2. 겨울철 부산을 방문한 사람이 ‘맛 집’을 검색 3. 우울할 때 볼 만한 ‘영화’ 추천을 검색
첫 번째 가정인 ‘서울에서 비 오는 날 데이트 코스’를 실험하기 위해 검색 창에 ‘데이트’라는 키워드를 입력 후, ‘서울’ 과 ‘비 오는 날’ 의 정 보가 일치해야하기 때문에 위치와 날씨가 같은 검색 결과를 확인하였다. 아래 ‘Fig. 13’의 정보들 은 서울에서 비가 오는 날 저장된 데이트 코스와 관련된 것들만 골라 출력된 것이다. 누군가 비가 오는 날의 서울에서 데이트 코스와 관련된 URL 들을 저장했다면, 그것은 비가 오는 날, ‘서울에 서 할 만한 데이트 코스’를 검색하다 수집한 정 보들일 가능성이 크다. 사용자들은 이렇게 저장 된 정보들을 위치와 날씨 등의 상황에 맞게 효율 적으로 검색하고 이용할 수 있게 되는 것이다.
Fig. 13 Result of Customized Search (Keyword : ‘데이트’)
(a) Live Search (b) Google Now Fig. 14 Results of Relevant Research
(Keyword : ‘데이트’)
이를 타 서비스와 비교해보기 위해 네이버 라 이브 검색과 구글 나우에 각각 ‘데이트’라고 검색 해보았다. 실험 전에, 구글 나우는 상황 정보를 저장하지 않고 실시간으로 수행하는 서비스이기 때문에, 본 논문에서 제시하는 시스템과 동일한 가정을 사용하지 않으며 실험 결과의 정확도가 떨어진다는 것을 밝힌다.
‘Fig. 14’에 나타난 네이버 라이브 검색에서는 사용자가 원하는 ‘비 오는 날 서울에서 할 수 있 는 데이트’와 상관없이, 일반적인 데이트에 관한 각종 정보들이 실시간 인기 혹은 나이대별 인기 게시물 순으로 나타난다. 검색하는 사람의 위치 와 날씨 등과는 상관없는 검색결과를 보여준다는 것을 알 수 있다. 구글 나우 또한 사용자의 위치 나 날씨와 전혀 상관없는 검색 결과들을 무분별
Fig. 15 Result Analysis
(Precision and Recall, Keyword : ‘데이트’)
하게 보여주고 있다.
각 서비스의 검색 결과를 정확률과 재현율을 이용하여 분석해보면 ‘Fig. 15’ 와 같은 결과가 나온다. 정확률은 검색된 문서들이 얼마나 적합 한가를 나타내며, 재현율은 적합문서가 얼마나 많이 검색되었는가를 나타낸다. 즉, 정확률은 검 색의 정확성을 측정하는 것이고, 재현율은 검색 의 완전성을 측정하는 것이다. 정확률과 재현율 을 구하는 식은 다음과 같다.
Precision(정확률) = | R ∩ A |/| A | * 100 (%) Recall(재현율) = | R ∩ A |/| R | * 100 (%)
(※ R=전체 문서 중 관련된 문서, A=검색엔진이 찾은 전체 문서)
네이버 라이브 검색과 구글 나우의 경우, 서비 스의 전체 데이터 수를 알 수 없어 재현율은 구 하지 않았다. 정확률만으로 비교했을 때, 네이버 라이브 검색의 상위 50개 노출 문서 중 17개가 사용자의 날씨 혹은 위치를 고려한 게시물이었 다. 적지 않은 숫자이지만 정확률이 50%에도 미 치지 못해, 여전히 사용자의 요구를 충족하기 힘 든 결과이다. 구글 나우의 경우는 상위 50개 노 출 문서 중 2개만이 사용자가 얻고자하는 결과와 가까웠다. 2개의 문서 모두 검색 사용자의 위치, 날씨정보를 고려하지 않은 결과로, 단지 데이트 코스를 소개하는 정보였다.
반면 본 논문에서 제안하는 상황정보 검색의 경우, 데이트와 관련된 전체 문서 50개 중 사용 자의 날씨, 위치와 일치하는 검색 결과는 총 27 개로 나타났고, 이 중 1개를 제외한 모든 문서가 서울에서 비 오는 날 할 수 있는 데이트 정보를 담고 있었다. 이는 사용자의 위치와 날씨를 고려 한 검색이 더 효율적인 정보를 제공한다는 것을 알 수 있다.
두 번째 가정인 ‘겨울철 부산 맛 집’을 실험하기 위해 상황정보 검색 서비스와 구글 나우에 각각
‘맛 집’ 이라는 키워드를 검색하여 ‘Fig. 16’의 결 과를 얻었다.
(a) Customized
Search (b) Google Now Fig. 16 Results of Search (Keyword : ‘맛집’)
상황정보 검색에서 사용자의 현재 위치는 부산 이며 현재 날씨는 눈이 내린다. 서비스가 가진
‘맛 집’과 관련한 총 101개의 데이터 중 ‘겨울철 부산’에서 수집된 맛 집 문서는 총 29개이다. 이 29개 데이터 모두 추운 날 부산에서 먹을 만 한 맛 집 정보들을 가지고 있어, 사용자에게 적합한 검색 결과를 나타내고 있다. 구글 나우에서는 사 용자의 위치에 기반 한 맛 집 정보들이 출력된 다. 상위 50개 데이터 중 46개가 검색자의 위치 를 고려한 결과였다. 검색을 서울에서 수행하였 기 때문에 서울의 맛 집 정보들이 나타나는 것을 확인할 수 있었다. 네이버 라이브 검색은 베타 버전으로 키워드 검색에 한계가 있어, 아직 ‘맛 집’이라는 키워드는 검색하지 못해 실험을 수행 할 수 없었다.
Fig. 17 Result Analysis (Precision and Recall, Keyword : ‘맛집’) 위 결과를 정확률과 재현율로 분석한 결과는
‘Fig. 17’ 과 같다. 구글 나우는 정확률이 92%로 높은 수치이긴 하지만 날씨 등 다른 상황 정보들 을 제외하고 단지 위치 정보만을 고려한 결과라 는 아쉬움이 있다.
세 번째 가정인 ‘우울할 때 영화 추천’을 실험 하기 위해 상황정보 검색 서비스의 검색화면에서 현재기분을 ‘Bad’로 설정한 후 검색을 수행하였 고, 구글 나우에서도 ‘영화’ 키워드로 검색하여
‘Fig. 18’의 결과를 얻었다.
(a) Customized
Search (b) Google Now Fig. 18 Results of Search (Keyword : ‘영화’)
서비스가 가진 영화 관련 데이터 총 75개 중 이용자들이 ‘Bad' 기분 상태에서 데이터베이스에 저장했었던 영화 관련 데이터 30개가 결과 목록 에 출력되며, 이는 모두 우울한 상태에서 보기 좋은 영화들을 추천한 정보들이었다. 구글 나우
Fig. 19 Result Analysis (Precision and Recall, Keyword : ‘영화’)
에서는 두 번째 가정에서의 실험과 마찬가지로 검색 수행자의 위치에 기반 한 영화 상영 정보들 이 나올 뿐, 사용자의 기분과는 상관없는 검색 결과들이 출력되었다. 네이버 라이브 검색은 ‘영 화’라는 키워드를 제공하지 않아 실험을 수행할 수 없었다. 위 실험을 정확률과 재현율로 분석한 결과를 ‘Fig. 19’에 그래프로 나타내었다.
본 논문이 제안하는 서비스에서 검색된 30개 데이터 모두 우울한 날 보기 좋은 영화를 추천하 는 문서로 확인되어 정확률이 100%이며, 구글 나우의 경우는 상위 노출 50개 데이터 중 단 하 나의 게시물도 영화 추천과 관련 있지 않았으므 로, 정확률이 0%로 계산되었다.
위 실험들을 바탕으로, 사용자의 위치/날씨/기 분 등의 상황 정보를 수집하여 이를 다양한 조합 으로 이용한다면, 검색 상황에 적합한 결과들을 사용자에게 더 효율적으로 제공할 수 있다는 것 을 알 수 있다.
3.2 소셜 북마크 서비스와의 비교
(a) 'Delicious'
Search (b) Customized Search
Fig. 20 Results of Search (Keyword : ‘맛집’)
서론에서 언급했던 Delicious와 Diigo, Pearltrees 북마크 서비스와 비교실험을 진행하여 ‘Fig. 20’
의 결과를 얻었다. Delicious에서는 내가 저장한 링크 라이브러리 내에서 키워드 검색이 가능하 며, 검색된 키워드를 저장된 링크의 타이틀, 태그 와 비교하여 일치하는 결과를 출력해준다. 그러 나 사용자가 어떤 상황(위치, 날씨, 기분 등)에서 해당 링크를 저장했는지 혹은 검색했는지 알 수
없기 때문에 단순한 키워드 검색만이 가능하다.
예를 들어 서울에 위치한 사람이 서울에 있는 맛 집을 검색하고자 할 때, Delicious에서 ‘맛 집’이 라는 키워드로 검색하면 내가 저장한 링크들 중
‘맛 집’이라는 키워드를 가지고 있는 모든 링크를 결과로 출력하기 때문에 서울에 위치한 맛 집 정 보를 일일이 다시 찾아보아야 한다. ‘Fig. 20 (a)’
에 나타나듯, 서울의 맛 집에 집중하기보다는 전 국의 맛 집들이 검색된다.
그러나 상황정보를 이용한 북마크의 저장 및 검색이 이루어진 ‘Fig. 20 (b)’ 에서는 검색 사용 자가 위치하고 있는 서울에서 저장된 맛 집 정보 들을 출력해 보여준다. 서울에서 저장된 맛 집 정보가 모두 서울에 위치한 맛 집일 수는 없겠지 만, 상황 정보를 이용하지 않은 검색보다 사용자 가 원하는 정보를 더 적절히 보여준다는 것을 알 수 있다. 또한 내가 저장한 링크 내에서만 검색 되 는 것이 아니라, 해당 서비스를 이용하는 모든 사 람들이 저장한 링크에서 검색되기 때문에 더 많은 정보들 사이에서 검색 결과를 추출할 수 있다.
(a) Diigo Search (b) Pearltrees Collection Search Fig. 21 Results of Social Bookmark Service
(Keyword : ‘맛집’)
Diigo 북마크는 ‘그룹’ 기능을 통해 내가 저장 한 링크를 다른 사람들과 공유 가능하며, 검색 또한 가능하다. 그러나 앞의 Delicious와 마찬가 지로 상황 정보를 고려하지 않은 키워드 검색만 이 가능하기 때문에, ‘Fig. 21 (a)’ 에 나타나듯 출력된 결과가 상황에 따른 적절한 정보인지 알
수 없으며, 내가 소속한 그룹 내에서만 검색이 가능하다는 한계가 있다. Pearltrees 북마크는 해 당 서비스를 이용하는 사람들이 저장한 모든 정 보의 검색이 가능하지만, 해당 검색어를 가지고 있는 링크만 검색 되는 것이 아니라 그것이 속해 있는 콜렉션(폴더) 전체가 검색 결과로 나오기 때문에 ‘Fig. 21 (b)’처럼 콜렉션에 들어가서 일 일이 게시물을 찾아야 한다. 그렇기 때문에 키워 드와 관련한 다양한 정보를 접할 수는 있겠지만, 사용자가 원하는 정보를 검색으로 얻는 것에는 한계가 있다.
4. 결 론
본 논문에서는 사용자의 상황 정보에 맞는 효 율적인 검색 결과를 출력하는 검색 시스템을 제 안하며, 이것은 일반적인 검색결과를 보완하며 사용자에게 더 필요한 정보를 상황에 맞게 제공 할 수 있다. 본 검색 시스템은 ‘자발적 공유경제 방식의 개인 한글 콘텐츠 제작/공유 서비스[2]’를 기반으로, 입력/저장/검색의 각 부분에 데이터 파 싱 즉, 상황 정보의 확보 단계를 추가하였다. 파 싱으로 날씨와 위치, 기분의 상황 정보를 가져와 이를 정보의 저장과 검색에 이용하였다. 결론적 으로 본 논문에서 제안한 실시간 상황 정보를 이 용한 ‘사용자 맞춤 검색 시스템’은 사용자의 현재 위치나 날씨, 기분 등의 정보를 데이터의 입력, 저장, 검색의 전 단계에 적용하여 사용자가 얻고 자 하는 정보와 가장 적합한 검색 결과를 제공한 다.
그러나 본 검색 시스템은 사용자 자신이 원하 는 장소에서 필요한 정보 및 서비스를 유연하게 받을 수 있지만 자신의 위치가 노출되어 프라이 버시 염려로 이어질 수 있을 것이다[13]. 이는 개 인 정보의 이용으로 확대될 가능성이 있어 이러 한 방면에서는 신중해야 할 필요가 있으며, 상황 정보가 일치한다고 해서 사용자가 얻고자 하는 정보를 무조건 제공할 수 있는 것도 아니다. 그 러므로 일반적인 검색결과에 상황 정보가 일치하 는 URL 들만 따로 모아 상단에 출력하거나, 자
신이 수집하여 결과에 활용하고자 하는 시간, 날 씨, 위치, 계절 등의 다양한 상황 정보들을 옵션 버튼 등으로 활성화/비활성화 하여 이용하면 보 다 효율적이고 도움이 되는 검색환경을 만들 수 있을 것이다. 또한 단순히 사용자가 저장한 URL 관련 키워드의 일치에만 의존할 것이 아니라, URL의 웹 페이지 본문이 포함하고 있는 키워드 의 검색까지도 고려하거나, 사용자의 예전 검색 기록 혹은 인터넷 이용 패턴 등 더 다양한 분야 의 상황 정보를 이용한다면, 사용자의 요구에 맞 는 보다 정확한 검색 결과를 제공할 수 있게 될 것이다.
References
[1] J. H. Joo, “A System of Personalized and Intelligent Tourism Content Service Based on Semantic Web”, The Journal of Information Systems, Vol. 18, No. 3, pp.
211-229, 2009.
[2] H. S. Ryu and M. R. Kwon and K. J.
Hong and K. C. Jung, “Production/Sharing Service of Personal Korean Contents with Voluntary Sharing Economy System”, Korean Institute of Information Scientists and Engineers, pp. 1999-2001, 2015.
[3] H. M. Lee and S. I. Kim, “Comparative Study on the Usability of Mobile Intelligent Personal Assistance Service Based on Voice Recognition Technology - Focused on 'Samsung S Voice' and 'Apple Siri'”, Korea Digital Design Council, Vol.
14, No. 1, pp. 231-240, 2014.
[4] M. J. Ahn, “Location Based Social Search Scheme Considering User Preferences in Mobile Environments”, Master’s Thesis of Chungbuk National University of engineering, 2014.
[5] T. Lianhua, “Famous Restaurant Recommendation System Based in Social Information”, Master’s
Thesis of Ewha Womans University of engineering, 2013.
[6] J. I. Namgoong and Y. J. Kim, "Intelligent M2M platform for Social M2M Services,"
Journal of The Korean Institute of Communications and Information Sciences, Vol. 30, No. 8, pp. 20-28, 2013.
[7] M. J. Choi, “Exploratory Research about Offering Private Information following Using Experiences of Location-Based of Smart Phone,” Korean Associations for Advertising and Public Relations, Vol. 96, pp. 249-277, 2013.
[8] Y. B. Kim, “A Study on Design of the Contents Recommendations Method based on Location Information”, Master’s Thesis of Chonbuk National University of Social Science, 2011.
[9] J. H. Park, “Efficiency Analysis of Search Algorithm for Personalized Context-Aware Service”, Master’s Thesis of Korea Aerospace University of engineering, 2009.
[10] J. H. Hwang, “Query Optimization for an Advanced Keyword Search on Relational Data Stream”, Master’s Thesis of Hanyang University of engineering, 2009.
[11] J. W. Lee, “Design of Personalized Search Engine Based on Service Provider List”, Master’s Thesis of Sungkyunkwan Univer- sity of engineering, 2006.
[12] T. H. Kim and J. M. Choi, “An Intelligent Web Browsing Agent for User-oriented Internet Information Retrieval”, Korean Institute of Information Scientists and Engineers, pp. 1064-1078, 1998.
[13] D. M. Lee and S. H. Jang, “Effect of Privacy Concerns on Protection Behaviors of Location-Based Services and Moderating Effect of Innovativeness”, The Journal of Internet Electronic Commerce Research, Vol. 14, No. 4, pp. 1-22, 2014.
권 미 림 (Mi-Rim Kwon)
∙학생 회원
∙숭실대학교 글로벌미디어학부 학부생
∙관심분야 : 웹 분야
홍 광 진 (Kwang-Jin Hong)
∙정회원
∙숭실대학교 미디어공학 공학석사
∙숭실대학교 미디어공학 공학박사
∙숭실대학교 IT 대학 글로벌미 디어학부 조교수
∙관심분야 : 컴퓨터비전, 영상처리, IoT
정 기 철 (Kee-Chul Jung)
∙정회원
∙경북대학교 컴퓨터공학 공학석사
∙경북대학교 컴퓨터공학 공학박사
∙USA, Michigan State University, PRIP Lab., 박사 후 연구원
∙숭실대학교 IT대학 글로벌미디어학부 부교수
∙관심분야 : 패턴인식, 인공지능, HCI, 컴퓨터비전
![Fig. 9 Saved Data in Database2.2 입력 및 저장전체 데이터의 입력과 저장은 ‘자발적 공유경제 방식의 개인 한글 콘텐츠 제작/공유 서비스[2]’와 같은 방식으로 이루어진다](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5129504.580447/6.892.487.763.141.299/database-저장전체-데이터의-입력과-저장은-공유경제-방식으로-이루어진다.webp)