저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게
l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다:
l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다.
l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다.
저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다.
Disclaimer
저작자표시. 귀하는 원저작자를 표시하여야 합니다.
비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다.
변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
이 학 석 사 학 위 논 문
딥러닝을 이용한 음성합성 기술의 군사작전분야 적용
2021년 1월
서울대학교 대학원 통계학과
권 용 찬
딥려닝을 이용한 음성합성 기술의 군사작전분야 적용
지도교수 장 원 철
이 논문을 이학석사 학위논문으로 제출함
2020년 10월
서울대학교 대학원 통계학과
권 용 찬
권용찬 의 이학 석사 학위 논 문을 인준 함
2021년 1월
위 원 장 부 위 원 장
위 원
국문초록
권용찬 통계학과 대학원 서울대학교
본논문은딥러닝을 이용한 음성 합성 기술의 군사작전 적용의 가능성을 탐 색하기 위해 음성합성 모형을 이용한 북한말 합성에 관해 연구한다. Tacotron2 를음성합성모형로사용하여멜스펙트로그램(Mel-spectrogram)을생성하였으 며 vocoder로 griffin-Lim 알고리즘과 WaveNet을 사용하여 멜 스펙트로그램을 오디오로변환한다.두알고리즘의비교를위해주어진문장50개를각각의알고 리즘을 이용해 100개의 음성을 만든 후 19명의 성인남녀에게 들려주어 개인별 점수를 임의효과모형(random effect model)을 이용하여 분석하였다. Griffin- Lim 알고리즘으로 생성한 음성이 우위를 보였으며 추가적인 양질의 데이터를 얻고 조절모수를 최적화하면실질적으로군사작전에 적용 할수 있는수준으로 개발할 수 있을 것이다.
주요어 : Tacotron2, 주관적 음질 평가(MOS), Griffin-Lim, WaveNet, 음 성합성
학번 : 2019-25241
목차
제 1 장 서 론 1
제 2 장 분석 방법 5
제 1절 데이터 설명 . . . 6
1.1 데이터 전처리 . . . 6
1.2 멜 스펙트로그램 . . . 7
제 2절 Tacotron2모형. . . 8
2.1 인코더(Encoder) . . . 8
2.2 Attention . . . 9
2.3 디코더(Decoder) . . . 10
제 3절 Vocoder . . . 11
3.1 WaveNet . . . 11
3.2 Griffin-Lim 알고리즘 . . . 14
제 4절 두 알고리즘의 비교 . . . 16
4.1 실험설계 . . . 16
4.2 분석방법론 : 임의효과모형 . . . 17
제 3 장 분석 결과 19 제 1절 데이터의 불완전성 . . . 20
제 2절 발전방향 . . . 22
제 4 장 결 론 24
Abstract in English 27
부록 A 분석 R코드 28
제 1 장 서 론
2015년 8월 4일 새벽 육군 제 1보병사단에서 하사 2명이 DMZ를 순찰하는 도
중 목함지뢰가 폭발하여 발목을절단 당하는 사건이 발생했다.합동참보본부는 심층조사결과 조선인민군이 한반도 군사 분계선을 넘어 지뢰를 설치한 것으로 결론을내고이사건을남한에대한북한의도발로규정했다.이에한국군은11년 만에 대북 확성기 방송을 재개하였고, 남북의 군사경계태세는 최고조에이르게 되었다. 이후 8월 말 극적으로 고위급회담이 타결되어 북측으로부터 이 사건에
대해’유감’을표한다는사과를받는것으로사태는일단락되었다.이사건을통
해서 1976년 판문점 도끼만행 사건 이후로북한이 최초로 ’유감’을표명했다는
점에서 남한의 대북방송 재개 카드는 확실히 효과적인 대응책이었음을 증명해 보였다.
이처럼 대북방송뿐만 아니라 전단지 살포, 라디오 방송등과 같이 군사적, 비군사적 수단을 이용하여 적국의 주민들을 아군에 우호적인 세력으로 만들어 적의 정치지도부와 군부세력을 약화시키고 아군의 군사작전에 유리하게 만드 는것을 MISO(Military information support operation) 혹은 심리전이라고 한 다(U.S. Air Force, 1999). 하지만 북한사회의 특성상 폐쇄적이고 언론매체가 한정적이므로 정보전달과유포에있어서진위를확인하기가쉽지않다.본논문
은 이러한 특성을 이용하여 딥러닝을 이용한음성합성 모형으로 새로운심리전 수단을 제안하고 나아가 다양한 종류의 군사작전분야에 대한 적용가능성을 제 시하는것을 목표로 하고 있다.
최근딥러닝분야가 각광받으면서 다양한기법과방법이제시되고상용화되 고있다.그예로딥페이크(deep fake)는딥러닝의GAN(Generative Adversarial
Neural Network,생성적 적대신경망)을 이용한 이미지합성이나가짜뉴스등을
제작하여 이슈가 된 기술이다. 예를 들어 특정 영상에 등장하는 인물의 얼굴과
목소리를 GAN을 이용해 타인의 목소리와 얼굴을 씌울 수 있게 되는 것이다.
범죄 오용의 우려가있어서 부정적인 인식이강하지만 타인의 얼굴과목소리를 복제하여속인다는부분에서군사적목적으로활용가능성이 있다.생성적 적대 신경망뿐만 아니라 그외에도 기계학습 방법을 이용한 심리전 도구를확보하는 것은 여러모로 유용할 것이다.
그 중에서 이논문에서는 음성합성을 이용한 심리전 수단을 제시할 것이다.
음성합성은 현재 딥러닝을 적용하고 있는 분야중에 눈에 뛰는 성과를 보이고 있고 계속해서 연구가 이뤄지고 있는 유망한 분야이다. 또 심리전의 수단으로 음성은매우유용하고,기존에사용하던 도구(라디오,인터넷방송,언론매체,대 북방송)를이용해전달하기편리하다.앞서 서술했듯이북한사회구조적특성상 정보의 진위여부를 확인하는것이 쉽지 않으므로 내부 갈등을 조장하거나 우호 세력을 형성하는데 적합할 것으로예상된다.우리가 북한 국무위원장김정은의 목소리를 복제하거나, 노동당 및 군부의주요 지휘관, 공영매체 및 해외선전을 위한 방송사의 아나운서의 목소리를 복제하여 역으로 유입시킨다면 정보의 신 뢰도를판단할 수없는대다수의북한주민들에게기대하는무형의효과를얻을 수 있을 것이다.
예기치 않은사태로 북한의 체제붕괴시 우리 군이 선택할 수 있는군사작전 선택지 중한가지는조기에북한내부의안정성확보를위한안정화작전이다.그 러나작전지역의우군에대한여론이우호적이지않을경우현지인(북한시민및 군부세력 잔당)의강력한저항에 부딪칠가능성이 있다. 따라서여건 조성을 위
한 작전으로 전단살포,확성기방송과함께 아군의 의도대로 만든인위적이지만 자연스러운 합성음을 이용하면 더욱 강력한 설득효과를 가질 것이다.
본논문에서는end-to-end TTS(Text-To-Speech)를구현한Tacotron모형을 이용하여 음성합성을 구현한다. 기존에 음성합성에 사용되던 statistical para-
metric TTS 모형은텍스트 입력값에서 다양한 언어의 특징을 추출하는모듈과
duration 모듈, acoustic feature prediction 모듈,복잡한구조의 vocoder로구성 되었다. 이런 TTS 모형은 각 모듈을 만들어내는데 필요한 전문지식이 달라서 구성하기가 힘들고 각 모듈이 독립적으로 학습을 진행하게 되므로 오차(error) 가 축적되어 커지는 현상이 발생했다(Wang et al, 2017).
그러나Tacotron은 텍스트를character sequence로변환하여 입력값으로 받 아각프레임당오디오신호의주파수와시간,진폭의정보를시각적으로표현한 스펙트로그램을 예측한다. 예측된 스펙트로그램은 계산상의 편의를 위해 주파 수값에log10를취하여멜스펙트로그램으로변환하고 간단한구조의vocoder를 통해 음성합성이 이루어진다(Wang et al, 2017). 기존의 Statistical parametric
TTS 모형과 다른점은 딥러닝 기법을 적용하여 각각 나누어진 모듈을 하나의
pipeline으로 통합해서 한번에 학습이 진행되어 오차가 최소화 되고,각 모듈별
로 최적의 성능을 발휘하기 위해서 수동으로 값을 조절할 필요 없이 입력값을 넣으면 결과값이 나올 때까지 별도로 사용자가 개입할 필요가 없게 된 것이다.
이후 성능이 더욱 개선된 Tacotron2가 개발되었는데 음성합성 모형의 성능을
평가하는 척도중 하나인 MOS(mean opinion score)점수가 5점 만점에 4.53에 달한다.일반적으로실험실에서사람의목소리를녹음한오디오의MOS점수가
4.58인것으로 알려져 있는데 이는거의실제 인간의 음성과 유사한 수준이라고
볼 수 있는 것이다(Shen et al, 2018).
이어서2장에서는Tacotron2모형의구조와멜스펙트로그램을오디오로변
환시켜주는vocoder를소개한다.이때2가지vocoder를소개하는데비교적간단 한구조를갖는푸리에 역변환(inverse Fourier Transfrom)을 이용한Griffin-Lim 알고리즘과 복잡하고 깊은(Deep) 신경망구조를 갖는WaveNet이며 Tacotron2
모형에서 생성된 멜 스펙트로그램을 각각의 vocoder를 이용해 음성으로 변환 하여 피실험자에게 들려주는실험을실시하고 이들의 성능을MOS점수를측정 하여 비교했다. 3장에서는 실험결과를 바탕으로 김정은의 목소리를 합성 했을
때 발생한 몇 가지 이슈에 대해서 논한 후 4장에서는 전체적인 결론과 향후
군사작전분야에서음성합성의연구방향에대해서 서술하였다.
제 2 장 분석 방법
이번 장에서는 데이터 전처리와데이터 설명, 분석모형의 구조및 각 모듈에 대 한 설명을제시한다. 분석에사용된 모형은Tacotron2이며원래 Tacotron2에서 사용한 데이터셋이 US English dataset(단일 여성 화자, 24.6시간)이라는 점을 고려해서한국어음성합성모형과그에적합한데이터셋이필요하다.이와관련 하여 DEVIEW 2017(www.youtube.com/watch?v=klnfWhPGPRs&t=450s)에서 Tacotron의 인코더 모듈의 Text embedding을 한국어에 적합하게 설계한 모형
이 공개 되었으며 이를 기반으로 Tacotron2도 한국어 데이터셋이 적용가능한
모형이 공개되었다.
이논문에서초점을맞추고있는것은단순한국어가아닌북한말을 음성합성 모형으로생성해내는게목표이므로북한말대본과발화로이루어진데이터셋이 필요하다. 일상에서 북한말을 하는사람의 목소리를 확보하는것이 어렵고심리 전에 적용한다는 취지에 맞춰 북한의 최고지도자인 김정은의 목소리를 이용할 것이다.
제 1 절 데이터 설명
데이터는OTT서비스인 유튜브에공개된김정은의목소리중Martyn Williams 의2013년∼2015년, 2017년신년사(www.youtube.com/user/NorthKoreaTech) 와비디오머그(https://www.youtube.com/watch?v=QQQqRUM8EVY&list=WL&
index=48&t=174s), SBS(https://www.youtube.com/watch?v=XxPZF6fTNFE&
list=WL&index=49&t=7s)의2018년, 2019년신년사에서MP3를추출한후wav 파일로 변환하여 이용한다.
이렇게 wav파일로 변환된 데이터는 분석을 하기위한 전처리과정이 필요하
다. 6개년도의 신년사는 각각 20∼30분 분량의 연설문이다. 긴 연설문을 15초 이내의 발언단위로 나누는 작업을 실시한다. 이때 파이썬 pydub 패키지를 이 용하여 발언과 발언 사이의 침묵시간을 기준으로 분리하고 침묵이 아니더라도 호흡이나 기타의 이유로 특정 크기보다 작은 소리들은 제거했다. 6개 음성파 일을 모두 같은 조건으로 처리하는 것이 이상적이지만 각각의 음성의 출처가 다르다보니 일관성 있는 결과물이 나오지 않고 또 몇몇 음성은 김정은의 연설 사이사이에인위적인박수소리가삽입되어있어서각각의영상에적용된기준은 상이하다.
1.1 데이터 전처리
Tacotron은 입력값(Input)으로목소리데이터와 대본의 쌍를가지므로 위 작업
에서 생성된 음성데이터별로 대본을 작성하기위해 오디오 데이터에서텍스트 를 추출하는 파이썬 speech recognition 패키지를 이용했다.패키지의한글음성 인식에 대한 결과물은완벽하지 않아 별도로확보한 연설문 대본자료와비교하 여 수정작업을 거친 후 json 포맷으로 입력자료로 사용될 대본을 완성하였다.
또한 몇몇 영상에포함되어 있던 박수소리를제거하고 발언의 도입부에침묵구 간을 제거하는 작업을 실시하였다. 이렇게 확보된 데이터셋은 969개의 발언으
로 구성되며 길이는 전체 2시간 19분 분량이다. 하지만 2시간 분량의 데이터로
학습을 시켜본 결과원하는 텍스트로 합성을시도하면 마지막에 사용한훈련데 이터의 음성을 그대로 생성하는 현상이 생긴다. 이러한 현상은 데이터가 적을 경우 Tacotron에서 핵심적인모듈인 attention의 학습이 잘 이루어지지않아 생 기는현상이다.이를보완하기위해서다른발화자의 자료를확보하였다.추가로 확보한 자료는 Kaggle에 공개된 Korean Single Speaker Speech Dataset(www.
kaggle.com/bryanpark/korean-single-speaker-speech-dataset)으로 여 성단일화자의 12시간 분량의 데이터와 Kaggle의 Korean voice(www.kaggle.
com/zldzmfoq12/korean-voice)의 단일 남자성우의 1시간 55분 분량의 오디 오북데이터,그리고국립국어원의서울말낭독체발화말뭉치(https://ithub.
korean.go.kr/user/totalSearch/totalSearch.do)중에서 30대 남성의 1시 간 37분 분량의 낭독음성 데이터이며 종합하여 약 18시간 분량의 데이터셋을 구축했다.
1.2 멜 스펙트로그램
이렇게확보된 대본과발화데이터는입력값으로사용될때대본은 자연어처리
와 동일하게 embedding을 하게되고 발화는 원음상태로 처리를 하는것은 어렵
기 때문에 데이터가공을 하게된다. Tacotron은 발화자료를 멜스펙트로그램의 형태로 변환하여 입력값을 받는다. 멜 스펙트로그램이란 원음상태의 오디오를 국소 푸리에 변환(short time fourier transform)을 거쳐 주파수와 시간, 진폭의 데이터를갖는 스펙트로그램으로형성한후좀더다루기쉽게하기위해다음과 같이 주파수를 로그변환한 것을 뜻한다.
m = 2595 log10
1 + f 700
여기서 f는 주파수를, m은 멜 스펙트로그램의 변환된 주파수를 의미한다.
이와 같이 데이터를처리하는 이유는 일반적으로사람은 낮은 주파수의소리는 잘 구분하는 반면에 높은 주파수는 같은 간격이라도 구분을 잘 못하는 현상을
이용한 것이다. 멜스펙트로그램은 일반 스펙트로그램에 비해 크기가작아지고 간격이 좁아지기 때문에 계산속도 측면에서 유리하다(Stevens et al, 1937).
제 2 절 Tacotron2 모형
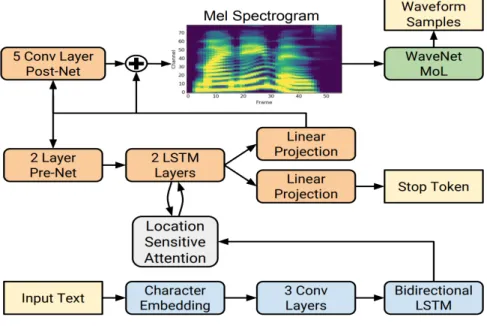
그림 2.1: Tacotron2 모형의 구조
2.1 인코더(Encoder)
인코더(encoder)는입력데이터인문자열을디코더(decoder)모듈에서입력값으 로 사용할 수 있는 encoded feature로 변환해주는 역할이다. 그림 2.1에서 보는 것처럼 먼저 한글의 자음과 모음을 512차원의 벡터로 embedding한 후 3개의 Convolutional-layer를통과한 후각각 256개의셀(cell)로 구성된Bi-directional LSTM(long short-term memeory)총 512개 셀을 거쳐 디코더에 사용되는 입력
값인 encoded feature가 된다.여기서 각각의 Convolutional-layer는 5×1크기 의 512개의 필터(filter)로 구성되어 있고 레이어(layer)를 통과할 때마다 batch normalization과 Relu activation을 적용한다.
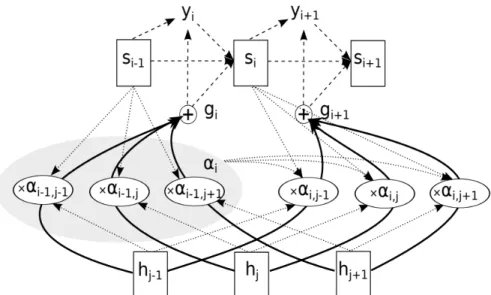
그림 2.2: Location sensitive attention
2.2 Attention
Attention은 ‘문장에 어떤 부분에 집중해야 할까?’에 대한 해답을 주는 모듈이
다. 인코더의 출력값을 이용하여 location-sensitive-attention은 디코더의 입력 값이되는context vector를 만들게된다.기존의attention기반RNN(Recurrent Neural Network)은 그림2.2에서 보는것처럼 encoded feature vector의성분인 hj(j = 1,2,· · · , L)가 순서에 상관없이 서로 값이 비슷한 것들이 있으면 같은 단어가 반복되거나 묵음(silence)이 발생하게 된다. 따라서 이같은 문제점을 보 완한 방법이 location-sensitive-attention이다.
이 방법의 원리는 i −1단계(i = 1,2,· · · , T)의 weight인 αi−1를 context vector yi를 계산할 때 문장의 위치정보로 반영하는 것이다. 정확히는 yi계산하 는데 필요한 gi를 구할때 weight를 반영하여 다음과 같은 score를 계산한다.
ei,j =w>tanh W si−1+V hj+U fi,j +b
(2.1) 여기서 w와 b는 vector이고 W와 V, U는 matrix이며 fi,j는 다음과 같이 계산 된αi−1의 convolution 연산값이다.
fi,j =F ∗αi−1 (2.2)
기존의 content-based-attention은 식 2.1 fi,j가 포함되어 있지 않는데 식 2.2을 통해i−1단계의 위치정보를반영하여계산한score는softmax normalization을 통해특정hj만을선별하여중복이나묵음과 같은현상을완화시켰다(Chorowski et al, 2015).
2.3 디코더(Decoder)
디코더는 encoded feature를 짧은 시간단위로 나누어진 프레임단위로 멜 스펙
트로그램을예측하는모듈이다.그림2.1에서보는것처럼이전단계에서예측된 값을 pre-net에서 재사용 하는데 pre-net은 2개의 fully connected layer(총 256 개 셀)와 Relu activation으로구성된다. pre-net은attention을학습하는데필수 적인계층으로알려져있는데pre-net의출력값과attention의출력값인context vector가 결합하여 2개의 LSTM(총 1024개 셀)을 거친 후 LSTM의 출력값과 context vector값을 결합하여 선형변환(linear transform)한 것을 Linear Pro- jection이라고 한다(Shen et al, 2018). 그리고 Linear projection은 post-net(5 개의 Conv-layer, 각각 5×1의 512개 필터, tanh activation으로 구성)을 거친 후 residual connection으로 목표 프레임의 멜 스펙트로그램을 예측한다. 이때 residual connection은 일반적으로 모형을 더욱 빠르게 수렴하게 하는 것으로 알려져 있다(He, et al, 2016).
제 3 절 Vocoder
Tacotron2 모형을 이용하여 멜 스펙트로그램을 생성하면 이를 아날로그 오디
오로 변환하기 위해서 vocoder 모듈을 이용해야 한다. 본 논문에서는 딥러닝
기반의 생성 모형인 WaveNet과 반복적 알고리즘으로 작동하는 Griffin-Lim 알 고리즘을 통해 김정은의 음성을 생성한다.
3.1 WaveNet
WaveNet은신경망(neural network) 기반의 자동회귀생성 모형(autoregressive generative model)이다(Oord et al, 2016).X를Waveform이라고하고xt를t라는 시간대의 오디오샘플이라고하자.Waveform X의결합확률분포(joint probabil- ity)는 다음과 같이 정의할 수 있다.
p(x) =
T
Y
t=1
p(xt|x1, . . . , xt−1)
즉 xt는 이전 시간대의 모든 오디오 샘플의 조건부확률의 곱으로 예측할 있으며 xt+1이나 xt+2와 같이 오디오 샘플의 이후 시간대를 고려하지 않는 구 조로 오류를 줄여준다. 위의 결합확률분포를 구현하기 위해 WaveNet은 causal dilated convolution 구조를 채택한다(Oord et al, 2016).
Causal dilated convolution은 causal convoulution과 dilated convolution의 장점을결합한구조이다. Causal convolution은xt를예측하는데있어xt+1,xt+2 등의 이후시간대의데이터를고려하지않고출력값을예측한다는점에서식2.1 의 공식을 잘 표현해 줄 수 있으며 X의 모든 시간대를 이미 알고 있기 때문에 모든시간대에 대해서동시에 연산이가능하고이로인해계산속도에있어서 다 른모형,특히순환신경망(recurrent neural network),보다우위를 가진다(Oord et al, 2016). 그러나 Causal convolution은 receptive field를 늘리기 위해선 레
이어를 늘리거나 필터의 숫자를 늘려야 한다. 이를 해결하기 위해 WaveNet은
dilated convolution의 개념을 적용한다.
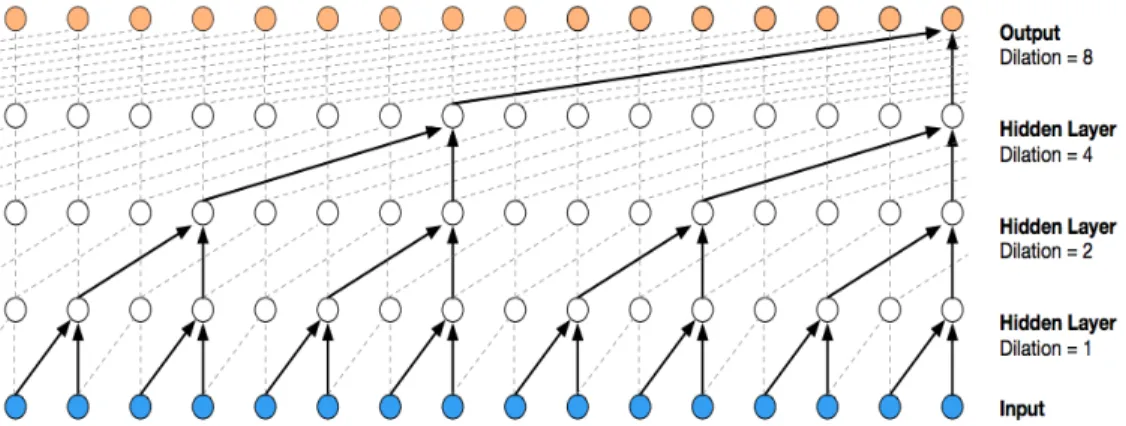
그림 2.3: Causal dilated convolution의 시각화(Visualization)
Dilated convolution은 필터를 필터의 길이(혹은 크기)보다 더 큰 범위의 데이터에 적용하기 위해 입력값의 일부분을 생략하는 방법이다. 이는 필터를 크게 만든 후에 필터 사이사이에 0값을 넣어주어 구현할 수 있다. 그림 2.3에서 보는 것처럼 크기가 16인 receptive field가 3개의 레이어를 통과하면서 충분히 확장될 수 있음을 알수 있다. 그러면서도입력값과 출력값의 크기가 같기때문 에 데이터의 손실이 줄어서 유용하다(Oord et al, 2016). 그리고 receptive field 가 넓어지므로 그만큼 모형의 성능이 좋아지고 계산을 효율적으로 할 수 있다.
Wavenet에서는 dilation을 1, 2, 4, . . . , 512까지 2배씩 계속해서 커지게 하여 레이어를 쌓아올린다.
식 2.1의 조건부확률을 모형화(modeling)하는 방법으로 softmax distribu-
tion을 이용하는데 softmax는 데이터의 분포 형태에 대한 가정을 하지 않기
때문에 매우 잘 작동하는것으로 알려져 있다(Oord et al, 2016).
그런데오디오 원음은 일반적으로16비트(bit)정수의수열로컴퓨터에서처 리되기때문에softmax는216개,즉65,536개의확률을모든시간대의오디오 샘 플마다출력해야한다.이를더쉽게다루기위해다음과 같은µ-law companding
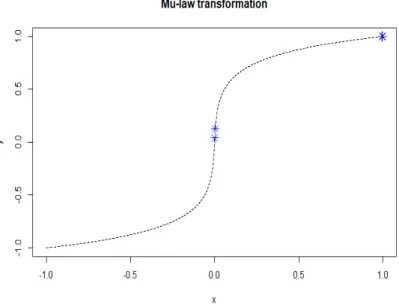
그림2.4: µ-law transformation결과로얻어지는비선형함수.파란색점은각각 xt = 32, 128, 32600, 32696을32768을 나누어서 표준화 한 값에 대한 함수값을 나타낸다.
transformation을 오디오에 적용한다.
f(xt) = sign(xt) ln(1 +µ|xt|) ln(1 +µ) µ= 255, xt= (−1,1)
(2.3)
µ-law companding transformation은 일반적으로 송신신호를 압축하고 수신시 다시 복구시키는 전송방식으로(Standard, F, 1996) 비선형(Non-linear) 함수를 이용하는데그이유는인간이더잘 인식하는저음역대의소리에더욱많은값을 부여하고잘구분하지못하는고음역대의소리에는비교적 적은값을부여할 수 있기 때문에 최대한 손실을 막는 방법이다.
그림 2.4를 보면 xt =32일 때 transformation 값은 0.0401이고 이를 128과 곱한수를바닥함수(floor function)로연산하면 5이고,xt = 128일때는15로96
간격 사이에 ’5’에서 ’15’ 로 숫자가 부여되지만 32600, 32696은 둘다 transfor- mation값이127로서간격은 서로96의차이를 보이지만transformation이후에 부여된 값은 큰 차이를 보이면서 저음역대의 정보손실을 줄였다.
결과적으로 softmax 연산량이 28, 즉 256개로 획기적으로 줄어든다. 활성 화 함수(activation function)로는 tanh를 사용하는데 tanh 활성화 함수는 Relu 활성화 함수보다 오디오 데이터를 다루는데 더욱 효율적인것으로 알려져 있 다(Oord et al, 2016).모형에Residual connection과skip connection을 이용하여 더욱 깊은 신경망에서 훈련과 수렴을 빠르게 해준다(He, et al, 2016).
3.2 Griffin-Lim 알고리즘
일반적으로 음성과 같은 신호정보를처리하기위해서 푸리에 변환을 이용한다.
특히 음성과 같은 시간축을 고려해야 하는 문제를 다룰 때는 국소 푸리에 변환 을 많이 사용한다. 그 이유는고속 푸리에 변환(Fast Fourier transformation)은 주파수와진폭의관계를가시적으로잘나타내주지만시간에대한정보가없기 때문에 언제 특정한 주파수가 나타나는지 알 수 없다는 한계가 있기 때문이다.
그에 반해 국소 푸리에 변환은 시간에 따른 주파수를 나타내고, 색깔을 통해서
진폭의크기를보여주기때문에정보전달력과데이터처리에유용하다고알려져 있다.
국소푸리에변환의 원리는 원자료를 일정한 시간 길이를 가진 윈도우로 자 른후에 각각 고속 푸리에 변환을 하여 시간대 별로 이어 붙이게 된다. 여기서 윈도우가 크면 주파수의 해상도는 좋아지지만 시간의 해상도는 감소하는 관계 를 갖게 된다. 이를 보완하기 위해 겹침의 개념을 적용한다. 겹침은 윈도우를 얼마나 겹쳐서 원자료를 분리하느냐는 것이고 보통 50∼70%가 겹치게끔 하여 시간에 대한 해상도를 증가시킬 수 있다.
실제 음성 신호를 x(n), Xw(mS, ω)을 x(n)의 STFT(Short Time Fourier Transfomation)라고 하자. S는 양의 정수값을 갖는 샘플링 주기(sampling pe- riod)이고 STFT에 적용되는 윈도우 w(n)을 길이가 L이고 0 ≤n ≤L−1에서
0이 아닌 실수라고 하면, STFT의 정의에 의해서, Xw(mS, ω) = Fl[xw(mS, l)] =
∞
X
l=−∞
xw(mS, l)exp(−iωl), xw(mS, l) = w(mS −l)x(l)
위 식에서 Fl[xw(mS, l)]은 변수l에 대하여 윈도우 분석을 한 신호인 xw(mS, l) 의 푸리에 변환을 의미한다. 멜 스펙트로그램은 MSTFT(modified short time Fourier transformation)으로나타낼수있는데이를Yw(mS, ω)라고하고yw(mS, l) 은 다음과 같이 정의된다.
yw(mS, l) = 1 2π
Z π
ω=−π
Yw(mS, ω)exp(iωl)dω. (2.4) Griffin-Lim알고리즘은추정한음성의STFT와MSTFT의평균제곱오차(mean squared error)를 다음과 같이 distance measure로 정의한다(Griffin & Lim, 1984).
D
x(n), Yw(mS, ω)
=
∞
X
m=−∞
1 2π
Z π
ω=−π
|Xw(mS, ω)−Yw(mS, ω)|2dω (2.5) 그리고 식 2.5은 Parseval’s Theorem에 의해서 다음과 같이 쓸 수 있다(Griffin
& Lim, 1984).
D
x(n), Yw(mS, ω)
=
∞
X
m=−∞
∞
X
l=−∞
xw(mS, l)−yw(mS, l)2
이는x(n)에대한이차다항식이므로D
x(n), Yw(mS, ω)
을x(n)에대하여 미분한 후 0으로 두고 x(n)에 대하여 정리하면,
x(n) = P∞
m=−∞w(mS−n)yw(mS, n) P∞
l=−∞w2(mS−n) (2.6)
이 x(n)의 해(solution)를 추정하기 위해 다음과 같은 반복적인 알고리즘을 사용한다. 먼저x(n)을추정할 때MSTFT의크기(magnitude)인|Yw(mS, ω)|을 이용한다고 가정하자.xi(n)을i번 반복해서추정한x(n)이라고하자.그러면i+ 1번째추정량인xi+1(n)을구하기위해xi(n)의STFT를그크기인|Xwi(mS, ω)|
와 주어진 크기 |Yw(mS, ω)|를 통해서 계산한 뒤 STFT와 MSTFT의 거리를 최소화하는 x(n)을 식 2.4,2.6를 통해 구한다.
xi+1(n) = P∞
m=−∞w(mS−n)2π1 Rπ
ω=−πXcwi(mS, ω)exp(iωn) P∞
m=−∞w2(mS−n) Xcwi(mS, ω) =|Yw(mS, ω)| Xwi(mS, ω)
|Xwi(mS, ω)|
또한식2.5은계속알고리즘을 반복할수록계산값이 감소하다는것이 이론 적으로 증명되었다(Griffin & Lim, 1984).그러나 실제로는 일정 수준의반복을 하게 되면 인간의감각으로는 차이를 구별하기어렵기 때문에 적당한수준에서 반복을 멈추게 설정한다.
제 4 절 두 알고리즘의 비교
4.1 실험설계
합성된 음성의 음질평가를 위해서 주관적 음질평가방법인 MOS(mean opinion score)점수를 측정한다(Union, I. T, 2006).
우선적절한 텍스트 작성을 위해서 훈련데이터에 포함되어 있지 않은2018 년 9월 평양 남북 정상회담시 김정은의 연설문 내용을 50개의 짧은 문장으로
나누어 각각의 vocoder를 이용하여 음성을 합성했다. 평가의 객관성을 유지하
기 위해 생성된 각각 50개의 문장을 합쳐서 100개의 설문 데이터셋을 만들고
이를무작위로섞어서 설문용음성을듣기전에는이 음성이WaveNet으로만든
음성인지 Griffin-Lim 알고리즘으로 만든 음성인지 알 수 없도록 설계하였다.
평가를 위한 참여자는 성인남녀 19명을 모집하였으며 적절히 차음된 공간에서
스피커를 통해 원본 음성 3개를 청취한 후 합성된 음성 100개를 들려준 후 5점
측도로 점수를 매기도록 했다. 이때 문장이 매우 짧기 때문에 연속 2회 들려준 후각문장에대해점수를부여한다.표2.1에제시된기준에따라서합성된음성 이 원본에 비교했을 때 잡음이 전혀 없고 음질이 매우 좋으면 5점,잡음이 없고 음질이 좋으면4점,약간잡음이 있고보통의 음질이면3점,잡음이많고음질이 낮으면 2점,잡음이 매우 심하고음질도듣기 불쾌할 정도로좋지 않으면 1점을 부여하도록 했다.
4.2 분석방법론 : 임의효과모형
설문을 통해얻은 데이터로각각의vocoder로생성한 음성의 음질을 MOS의 평
균 추정량으로 비교할 수있다. MOS는주관적인 점수 평가이기 때문에평가자
개개인의 기호도 영향을 미침을 고려해야 한다. 또한 WaveNet을 사용했느냐,
Griffin-Lim 알고리즘을 사용했느냐에 따라 같은 문장도 음질이 상이하기 때문
에 어떤텍스트를합성했느냐에따라서도MOS점수는영향을받을것이다.이에 따라서 평가자와 문장에 따른 임의성(randomness)이 각각 발생한다고 생각하 여 임의효과모형을 이용해 분석한다(Ribeiro et al, 2011). µij를 i 평가자가 j
점수 내용
5 매우 좋음(Excellent) 4 좋음(Good) 3 보통(Fair) 2 나쁨(poor) 1 매우 나쁨(Bad) 표 2.1: MOS 점수 부여 기준
문장에 대해 부여한 점수라고 하면 모형은 다음과 같다.
µij =µ+αi+βj +ε, i= 1,2,· · · ,19, j = 1,2,· · · ,50 (2.7) 여기서
αi∼N(0, σi2), βj∼N(0, σj2), ε∼N(0, σε2)
α는 평가자의 기호에 의한 변동을 의미하며 평균이 0 분산이 σi2이며 β는 문장에 차이에 의한 변동을, 그리고 ε은 모형의 불확실성을 나타낸다. 각각의 변수들은 서로 독립이라 상호작용은 없을 것으로 가정한다. 이때 평가한 점수 는 각각의 알고리즘별로MOS점수를 추정하는데사용하며 우리가 알고자하는 추정량은,
ˆ µ= 1
i×j
19
X
i=1 50
X
j=1
µij
var(ˆµ) = σˆ2i 19+
σˆ2j 50+
σˆ2 19×50
µ의ˆ 95%신뢰구간을 추정하기위해서 t분포를따른다는 가정하에신뢰구간 은,
ˆ
µ−t0.25,dfSE(ˆc µ),µˆ+t0.25,dfSE(ˆc µ)
으로 구할수 있다. 이때 자유도 df는 계산의 편의성과 보수적인 결과를 얻을 수 있도록 min(i, j)−1을 적용한다.
또한식2.7으로표현된모형에서 문장과평가자를임의효과(random effect) 로 가정한것이 효과적인지 확인하기 위해 임의효과를 1개씩 제거한 모형과 가 능도비검정(likelihood ratio test)을 통해서 적절성을 평가한다.
제 3 장 분석 결과
Tacotron2를WaveNet과Griffin-Lim 알고리즘을 결합한모형을 파이썬으로 구 현하였으며 실험결과의 분석은 R을 이용했다. MOS측정결과 Griffin-Lim 반복 알고리즘이 µ의ˆ 추정치가 더 높았으며 이는 기존의 Tacotron을 이용한 연구결 과와 상반된다.
Vocoder µ의ˆ 신뢰구간
Tacotron2 + WaveNet 3.519±0.346 Tacotron2 + Griffin-Lim 알고리즘 3.935±0.294(Good)
표 3.1: Griffin-Lim 알고리즘과 WaveNet vocoder의 MOS점수 추정 결과 이같은 결과는데이터의 불완전함으로 인해서신경망 기반의vocoder가 잘
작동하지 않았다는 것과 더불어 기존의 고전적인 방식으로 알려진 griffin-Lim
알고리즘이데이터의상태(녹음된음질이좋든나쁘든)에관계없이어느정도로 좋은 성능을 발휘 할 수 있다는 ‘강건성’(Robustness)을 유추할 수있다.
문장과 평가자를 임의효과로 모형에 반영했을 때 얼마나 유효한지 확인하 기 위해 각각의 변수를 제거한 모형과 가능도비검정을 통해 비교한 결과는 표 3.2에 정리되어 있다. 각각 ID(평가자), sentence(문장)을 제거한 모형의 AIC
제거된변수 모수 개수 logLik AIC LRT p-value
None 4 -1177.6 2363.1 - -
ID 3 -1346.1 2698.1 337.04 2.2e−16
setence 3 -1261.6 2529.3 168.15 2.2e−16 표 3.2: Griffin-Lim 알고리즘 모형의 Likelihood-ratio-test 결과
를 비교해보면 그 크기가 커진것을 확인 할 수 있다. 일반적으로 AIC가 작은
모형을 선호할 뿐만 아니라 p-value도 매우 작은 값을 가져서 문장과 평가자가
임의효과로 유의미한 변수임을 확인 할 수 있다.
제 1 절 데이터의 불완전성
Youtube에 업로드 되어 있는 김정은의 신년사는 차음이 된 정교한 실험실에서
녹화된 음성이 아니다. 강당이나 넓은 공간에서 마이크를 통해 울리는 음성이 녹음된 듯한연설문으로소리의울림이그대로담겨져있다. WaveNet과Griffin-
Lim 알고리즘둘 다동일한데이터로 학습을하지만 WaveNet의합성된음성은
마치 녹음된 소리의 울림까지 그대로 재현하여 원본보다 듣기 거북한 음성을 만들어 낸다.
또한 2013∼2015년 신년사와 2017∼2019년 사이의 신년사에서 김정은의 목
소리에 변화가 생긴것도 이러한 결과에 영향을 일부 미친 것으로 보인다. 앞선 시기에서의 목소리는 또렷하고 명확하게 들리는 반면 후기의 김정은 목소리는 가래가 끓는듯한 소리가 심하다. 급격한 체중 증가와 그로인한 건강상의 문제, 흡연등의 다양한 원인으로 목소리가 변화되었다고 밖에 생각할 수 없고 그로 인해 마치 한 개의 데이터셋에 2명의 목소리가 포함되는 효과로 학습에영향을 준 것으로 보인다.
음성합성의 목표인 김정은의 목소리를 만들기 위해 부족한 데이터셋을 보
그림 3.1: Tacotron2로 생성한 음성의 인코더 - 디코더 그래프
완하기 위해 3명의 화자를 추가하였다. 그러나 근본적으로 김정은의 목소리는
신년사라는 특수한 형식을 가진 연설문이 전부이고, 그마저도 매년 비슷한 내 용을 다룬다는 점에서 양질의 데이터가 부족하다고 할 수 있다. 그림 3.1에서 보는것처럼 위의 문장은 인코더 timestep을 따라서 디코더 출력이 자연스럽게 이루어졌는데 ’우리 민족 운명은 우리 스스로 결정한다.’는 실제로 김정은이 발 언한문장중 하나이며합성된음성도매우자연스러웠다.그러나아래의문장은
인코더 timestep 후반부 ’사랑합니다’부분의 디코더 출력이 시각적으로 흐릿한
것에서도 알 수 있듯 합성이 잘 이루어지지 않아 끝을 얼버무리게 된다. ’나는 그대를 사랑합니다’와 같은 문장은신년사에서는 전혀 등장하지 않는문장으로 이러한 텍스트를 합성하면 발음이나 톤이 어색한 음성이 종종 생성되었다.
그리고 표 3.1에서 보는것처럼 데이터의 불완전성에 비해 Griffin-Lim 알고
리즘은비교적MOS점수가높을뿐만아니라점수편차가WaveNet의점수편차
보다작은것을알수있다.이는앞서vocoder부분에서 소개했듯이Griffin-Lim 은반복적알고리즘을 이용하고반복을할수록계속해서distance measure가줄
어 드는 것이 증명이 되 있는 반면에 WaveNet은 신경망 기반으로서 데이터의
양과 질이 충분하지 않을 때에는 변동성이 크고 불안정함을 알 수 있다.
제 2 절 발전방향
이번 연구에 대한 성과를 확대하기 위해서 3가지의 발전방향을 모색해보았다.
우선 군사적 목적으로 활용하기 위해서는 더욱 안정적인 모형을 구현해야 될 것이며그에따라더욱방대하면서높은품질의북한말데이터셋을확보해야 할 것이다.일단한번대량의데이터셋으로학습이 이루어지고나면새로운화자의 음성합성이 필요할 경우에는적은 양의 데이터로도기존 모형을 이용한화자적 응(speaker adaptation)을통해높은수준의 음성합성을할수있으므로대용량, 고품질의 데이터셋을 갖추는 것이 중요하다고 할 수 있다.
계산상의 문제로 인해 학습 데이터는 10초 내외의 짧은 문장으로 분리된다.
이로인한 문제점은 한번에 긴 텍스트를 합성할 수 없다는 것이다. 실제로 한
문단 길이의 텍스트를 합성하려고 시도하면 10초 이후부터는 합성이 이루어지 지 않아 발음이 되지 않는 현상이 발생한다. 적의 통신망을 교란하거나 선전을 목적으로하는 짧은문장을만들어야되는경우에는문제가되지않으나비교적 긴 문장을 신속하게 만들어야 되는 상황에서는 짧은 문장을 여러번 나누어 합 성하는 것이 비효율 적이기 때문에 이를 개선하기 위한 방법에 대해서도 발전 시킬 필요가 있다.
마지막으로 최적의 조절모수(Hyperparameter)설정이다. 조절모수 최적화 딥러닝 분야에서 중요한개념인데 그 이유는너무나 많은 조절모수가존재하기 때문에 이들 모두의 최적화된 값을 찾아내는 것이 어려운 문제이기 때문이다.
Tacotron2를 이용한 한국어 음성합성 모형과 그에 맞는 조절모수에 대한 선
행연구는 존재하며 이를 더 발전시키면 더욱 자연스러운 음성합성 모형으로 발전시킬 수 있을 것이다(임주원 et al, 2018). 추가로 최적의 조절모수뿐만 아 니라 더욱 빠르고 가벼운 모형에 대한 최적화까지 이루어 진다면 실전에서의 활용가치는 더욱 높아질 것이다.
제 4 장 결 론
이 논문에서 북한말에 대한 음성합성과 군사적 분야의 적용에 대한 가능성을 탐색해보았다. 음성합성은 딥러닝에서 가장활발한발전이 이루어지고 있는 분 야로 앞으로도 발전 가능성이 상당하다. 특히 이를 군사적 부분에 적용함에 있 어서, 음성합성을 통해 가짜정보를 유포하여 지휘통제를 교란하거나 마비시킬 수 있다. 안정화 작전을 수행하는 경우에는 반군이나 잔존하는 무장세력의 위 협으로부터 인적, 경제적 비용의 손실을 최소화 하기 위해 음성합성 모형으로 실시간으로 필요한 멘트를 만들어 내고 이를무인차량에 스피커를 장착하여 선 전을 하면 보다 안전하게 작전을 수행할 수 있다. 워리어 플랫폼과 연계하여 기도비닉을 유지해야 하는 상황에서 C4I체제를 유지하기 위한 음성안내 시스 템을 개발하여 여기에 음성합성모형을 탑재하면, 개별 전투요원이디스플레이 창을 확인함으로 인해 적에게 노출될 위험 없이 이어폰을 통해 합성된 음성의 안내를 받아 위험지역에서 벗어나거나 작전수행에 대한 보조를 받을 수 있을 것이다.
이를실현가능하게하기위해서방대한데이터셋을확보하고,빠르고효율적 인학습을 위한조절모수최적화,다양한길이의문장,다양한형식의텍스트에도 안정적으로 합성할 수 있는 모형에 대한 연구가 수반되어야 할 것이다.
Reference
임주원, 배우근,김휘수,김영수,이명우,황영태(2018). Tacotron2기반한국어 음성합성모델개발과한국어에맞는Hyper-parameter탐색.한국정보과학회 학술발표논문집, 1836-1838.
United States Air Force (1999). Air Force Doctrine Document 2-5.3 : Psycho- logical Operations
Chorowski, J. K., Bahdanau, D., Serdyuk, D., Cho, K., and Bengio, Y. (2015).
Attention-based models for speech recognition.In Advances in neural infor- mation processing systems.28. 577-585.
Griffin, D. and Lim, J. (1984). Signal estimation from modified short-time Fourier transform.IEEE Transactions on Acoustics, Speech, and Signal Pro- cessing, 32(2), 236-243.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770-778.
Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalch- brenner, N., Senior, A., and Kavukcuoglu, K. (2016). WaveNet: A generative
model for raw audio. Retrieved from http://arxiv.org/abs/1609.03499 [Computing Research Repository] ‘
Ribeiro, F., Florˆencio, D., Zhang, C. and Seltzer, M. (2011). Crowdmos: An approach for crowdsourcing mean opinion score studies. In 2011 IEEE in- ternational conference on acoustics, speech and signal processing (ICASSP), 2416-2419.
J. Shen, R. Pang, R. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y.
Zhang, Y. Wang, R. Skerry-Ryan, R. Saurous, Y. Agiomyrgiannakis, and Y.
Wu (2018, April). Natural tts synthesis by conditioning wavenet on mel spec- trogram predictions. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),4779-4783
Standard, F. (1996). Telecommunications: Glossary of telecommunication terms. Retrieved January, 15.(2004), 69-72.
Stevens, S. S., Volkmann, J., and Newman, E. B. (1937). A scale for the mea- surement of the psychological magnitude pitch.The Journal of the Acoustical Society of America, 8(3), 185-190.
Union, I. T. (2006). Itu-t recommendation p. 800.1: Mean opinion score (mos) terminology.International Telecommunication Union, Tech. Rep.
Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, Q. Le, Y. Agiomyrgiannakis, R. Clark, and R.
A. Saurous (2017). Tacotron: Towards end-to-end speech synthesis. in Proc Interspeech, 4006-4010
Abstract
In this paper, we study North Korean speech synthesis using a speech syn- thesis model to explore the possibility of applying speech synthesis technology using deep learning to military operations. Mel-spectrogram was created using Tacotron2 as a speech synthesis model, and Mel-spectrogram was converted to audio using Griffin-Lim algorithm and WaveNet with vocoder. For com- parison of the two algorithms, 50 given sentences were converted using each algorithm. After making 100 voices, they were played to 19 adult men and women, and individual scores were analyzed using a random effect model. The voice generated by the Griffin-Lim algorithm showed the superiority, and by obtaining additional high-quality data and optimizing the adjustment parame- ters, it could be developed to a level that can be practically applied to military operations.
Keywords : Tacotron2, MOS(Mean opinion score), Griffin-Lim, WaveNet, TTS(Text-to-speech)
Student Number : 2019-25241
부록 A
분석 R코드
set.seed(1012)
a <- sample(1:100,50) b <- 1:100
w <- sample(b[-a],50)
####library 호출####
library(’merTools’) library(’lme4’) library(’lmerTest’)
result_data <- read.csv(’result_data.csv’, header = TRUE) ###실험 결 과 호출
result_data <- result_data[,1:4]
###G-L과 WaveNet 구분을 위한 더미변수 추가 result_data[w,4] <- 1
result_data[a,4] <- 0 k = 1:18
for(i in k){
result_data[(100*i+1):(100*(i+1)),4] <- result_data[1:100,4]
}
cn <- c(’ID’,’sentence’,’score’,’model’) colnames(result_data) <- cn
result_data[,4] <- as.factor(result_data[,4])
####Random effect model 분석####
a_data <- lmer(score ~ (1|ID) + (1|sentence) + (1|model),data = result_data)
##model을 random effect로 고려한 모델
b_data <- lmer(score ~ (1|ID) + (1|sentence) + model, data = result_data)
##model을 fixed effect로 고려한 모델 summary(a_data)
summary(b_data) rand(a_data) rand(b_data)
####model 변수를 고려하지 않고 알고리즘별로 데이터를 분리하여 Mu hat 계 산####
result_data <- read.csv(’result_data.csv’, header = TRUE) ###실험 결 과 호출
result_data <- result_data[,1:3]
k = 1:19 ; m = 1:100
####WaveNet, Griffin-Lim 알고리즘 각각의 실험결과를 분리####
wn_result <- data.frame(matrix(nrow = 950 , ncol = 3)) gl_result <- data.frame(matrix(nrow = 950, ncol = 3)) u=1
for(i in k){
process_data <- subset(x=result_data, ID == i) m = 1
for(j in w){
wn_result[50*(u-1) + m,] <- process_data[j,]
wn_result[50*(u-1) + m,2] <- m m <- m + 1
} m = 1
for(z in a){
gl_result[50*(u-1) + m,] <- process_data[z,]
gl_result[50*(u-1) + m,2] <- m m <- m + 1}
u <- u+1 }
cn <- c(’ID’,’sentence’,’score’)
colnames(gl_result) <- cn ; colnames(wn_result) <- cn
####Random effect model 분석####
wavenet_crossed <- lmer(score ~ (1|ID) + (1|sentence),data = wn_result) gl_crossed <- lmer(score ~ (1|ID) + (1|sentence),data = gl_result) fixed_model <- lm(score ~ ID + sentence,data = gl_result)
summary(wavenet_crossed) summary(gl_crossed) rand(wavenet_crossed) rand(gl_crossed)
####Confience interval 계산####
confint(wavenet_crossed) confint(gl_crossed)