SW컴퓨팅산업원천기술개발
예지형 시각 지능 원천 기술 개발
Development of Predictive Visual Intelligence Technology
포항공과대학교 산학협력단
정보통신기술진흥센터
목 차
Ⅰ. 해당 연도 추진 현황 ··· 1
Ⅰ-1. 기술개발 추진 일정 ··· 1
Ⅰ-2. 해당 연도 추진 실적 ··· 6
Ⅰ-3. 방치/도난 객체 검출을 통한 정확한 비정상/의심 상황 예측 기술 개발(1.1세부 포항공대) ··· 22
Ⅰ-4. 객체 행동 분석을 통한 비정상/의심 상황 예측 기술 (1.2 세부 고려대) ··· 34
Ⅰ-5. 객체 흐름 분석을 통한 비정상/의심 상황 예측 기술 (1.3 세부 서울대) ··· 40
Ⅰ-6. 맥락 정보를 활용한 의미론적 영상 분할 기술 연구 (2.1 세부 서울대) ··· 44
Ⅰ-7. 딥 러닝의 적용을 통한 알고리즘 확장 (2.2 세부 포항공대) ··· 46
Ⅰ-8. 객체 및 장면 모델링을 위한 외형 학습 기술 개발 (2.3 세부 연세대학교) ··· 50
Ⅰ-9. 지능형 관제 시스템 통합 및 최적화 (사업화) ((주)파슨텍) ··· 57
Ⅱ. 기술 개발 결과 ··· 70
Ⅱ-1. 국내 및 국외 발표 ··· 70
Ⅱ-2. 국내 출원 및 등록 ··· 73
Ⅱ-3. 기술 이전 ··· 73
Ⅱ-4. 기술 성능 ··· 73
Ⅱ-5. 신규 고용 실적 ··· 74
Ⅲ. 결론 및 차년도 계획 ··· 75
Ⅲ-1. 결론 ··· 75
Ⅲ-2. 차년도 추진 목표 ··· 77
Ⅲ-3. 차년도 기술 개발 추진 일정 ··· 82
Ⅳ. 사업비 사용 현황 ··· 86
Ⅳ. 기업 재무건전성 현황 ··· 90
Ⅵ. 자체보안관리진단표 ··· 94
Ⅶ. 유형적 발생품(연구시설, 연구장비 등) 구입 및 관리 현황 ··· 98
Ⅰ. 해당 연도 추진 현황
Ⅰ-1 기술개발 추진 일정
1) 방치/도난 객체 검출을 통한 비정상/의심 상황 예측 기술 (1.1 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1 2차년도 계획 수립
및 자료조사 100%
2 계층적 유한 상태
기계 설계 100%
3 학습 데이터 수집 및
유한 상태 기계 학습 100%
4 주기/비주기적 배경
갱신 기법 연구 100%
5 배경 변화에 강인한
장소 분류 기술 개발 100%
6 상황 예측 기술
정교화 100%
당초계획 개발내용
2) 객체 행동 분석을 통한 비정상/의심 상황 예측 기술 (1.2 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1 2차년도 계획 수립
및 자료조사 100%
2
객체 검출 및 관심객체 선정방법
연구 100%
3 다중 객체간 관계
모델링 방법 연구 100%
4 다중 객체 관계 기반
상황 예측기술 개발 100%
5 성능평가 및 실험 100%
6 2차년도 산출물 및
일반화 100%
당초계획 개발내용
3) 객체 행동 분석을 통한 비정상/의심 상황 예측 기술 (1.3 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
4 5 6 7 8 9 10 11 12 1 2 3 (%)
1 계획수립 및
자료조사 100%
2
공간적 상호관계 이해를 위한 모델
개발 시간적 상호관계 이해를 위한 모델
개발
100%
3 시공간적 상호관계
통합 모델 개발 100%
4
시공간 상호관계를 이용한 상황 예측
알고리듬 개발 시공간 상호관계를
이용한 이상행동 탐지 알고리즘 개발
100%
5 성능평가 및 실험 100%
6 2차년도 산출물
통합 및 일반화 100%
당초계획 개발내용
4) 맥락 정보를 활용한 의미론적 영상 분할 기술 연구 (2.1 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1
영상의 맥락 정보를 활용한 의미론적 영상 분할 알고리즘
개발
100%
5) 딥 러닝의 적용을 통한 알고리즘 확장 (2.2 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1 딥 러닝 적용을 통한
알고리즘 확장 100%
2 앙상블 학습 도입을
통한 병렬 결합 100%
6) 객체 및 장면 모델링을 위한 외형 학습 기술 개발 (2.3 세부)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1 계획 수립 및 관련
기술 조사 100%
2
딥러닝 학습 알고리즘 설게 및
검증 100%
3
벤치마크 데이터베이스 성능
시험 및 문제점 보완 100%
4
신뢰도 기반 온라인 외형 데이터 추출 및
분류 기법 설계
100%
5
온라인 외형 학습 기반 객체 추적 기술
평가
100%
당초계획 개발내용
7) 지능형 관제 시스템 통합 및 최적화 (사업화)
일련
번호 개발 내용 추진 일정(개월) 달성도
1 2 3 4 5 6 7 8 9 10 11 12 (%)
1
상황인식용 비디오 데이터메이스 모델의
보완 및 재구축 100%
2
상황인식 S/W테스트를 위한 테스트베드 조사 및
분석 보완
100%
3
상황인식 S/W테스트를 위한 테스트베드 확장적용
(Prototype)
90%
당초계획 개발내용
계획 추진실적
방 치 / 도 난 객체 검출 을 통한 비 정 상 / 의 심 상황 예측 기술
(포항공대)
l 계획 수립 및 자 료조사
l 최신 기술 연구 동향 조사 및 분석
1. 논문 동향 : 국제 저널 및 학회 (PAMI, CVPR, ICCV, AVSS, Sensors, CVPR, ICCV, MVA 등)
2. 기업 동향 : 국내외 기업 (IBM, ObjectVideo, 하이트론 시스템즈 등)
3. 방치/도난 객체 검출 기술 활용 계획 수립 : 이동 카메라 기반 객체 검출 및 드론 기반의 차량 검출 기술을 이용한 방치/도난 상황 예측에 응용
l 계층적 유한 상 태 기계 설계 l 학습 데이터 수
집 및 유한 상태 기계 학습
l 계층적 유한 상태 기계 (FSM) 설계
1. 3단계 처리과정으로 구성된 방치/도난 객체 검출 알고리즘의 고 도화
그림 1. 방치/도난 객체 검출 과정 개요
2. 픽셀/영역/이벤트 상태 및 상태 전이 정의 가. 총 9개의 상태 및 20개의 상태 전이 존재
나. 상태 전이는 오프라인으로 찾아진 최적 임계치 값들을 통해 결정됨
3. 픽셀/영역/이벤트 특징 정의 : intensity, time duration, area, motion, shape, color, edge 중 각 레벨에 적합한 특징 실험 및 파라미터 튜닝
l 테스트 데이터베이스 (DB) 내용 및 수준 (검증 활동)
1. 테스트 DB 내용 : PETS2006, AVSS2007(i-LIDS), CAVIA, ObjectVideo DB, 자체 수집 DB
2. 테스트 DB 수준 : 22개 동영상, 62개의 방치 또는 도난 객체 이 벤트 존재, 가려짐/조도변화/혼잡도 난이도에 따라 상/중/하로 구 분
3. 상태 전이를 위한 최적 임계값 결정 및 성능 평가 기준 수립 가. 임계값 결정 : 자체 수집된 DB 상에서 배경/전경/정지 영역
각각의 특징 값 추출(Ground-truth 참고) 및 통계적 최적 임 계값 결정
Ⅰ-2 해당 연도 추진 실적
1) 방치/도난 객체 검출을 통한 비정상/의심 상황 예측 기술 (1.1 세부)
나. 성능 평가 기준 : TCA(True Classification Accuray), FCR(False Classification Ratio)
l 자체점검 시나리오 및 결과 (검증 활동)
1. 테스트 DB에서 TCA 66%, FCR 54% 성능 확보 2. 기존 픽셀 기반 기술 대비 환경 조건 변화에 강인함
그림 2. 방치/도난 객체 검출 결과 예시 l 연구결과 완성도 (목표달성 및 질적 수준)
1. 1단계 2차년도 목표 성능 대비 TCA 100% 달성
2. 세계 수준 (ObjectVideo) 대비 TCA 11% 향상, FCR 12% 감소
l 이동 카메라 움 직임 보상 기술 설계
l 이동 카메라 기 반 동적 객체 검 출 기술 설계
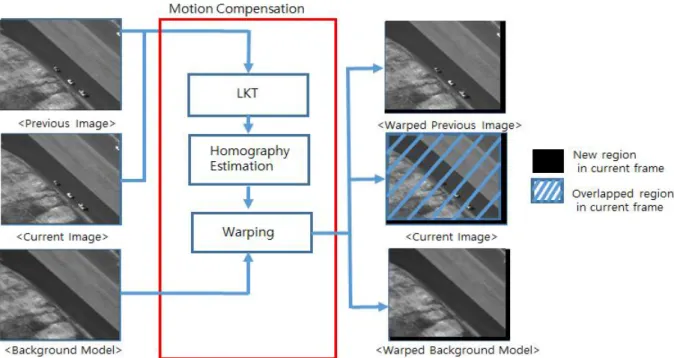
l 이동(드론) 카메라 움직임 보상 기술 개발 1. Optical flow 기반 움직임 보상 기술 설계
그림 5. 이동(드론) 카메라 움직임 보상 과정 개요 1.
2. 이동 카메라의 motion model 생성
가. 현재 프레임과 전 프레임간의 Hierarchical LKT으로 optical flow 계산
나. RANSAC으로 이동 카메라의 optical flow과 객체의 optical flow 구분
다. 이동(드론) 카메라의 optical flow으로 projective motion model 생성
3. Warping을 통해 이동(드론) 카메라의 움직임 보상 가. Nearest neighbor interpolation 이용
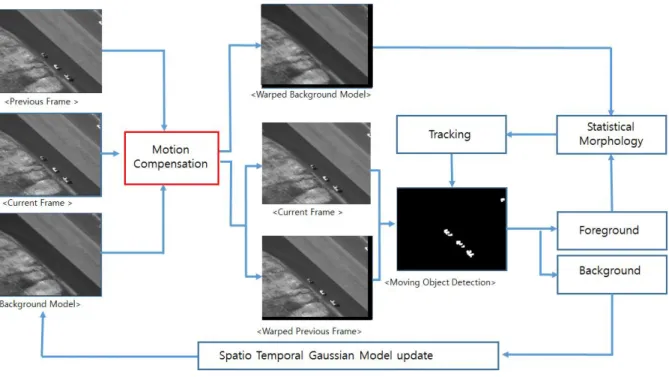
그림 6. 카메라 움직임 보상 및 이동 객체 검출 알고리즘 l 이동(드론) 카메라 기반 동적 객체 검출
1. 이동(드론) 카메라 기반 동적 객체 검출 기술 설계
그림 2. 이동(드론) 카메라 기반 동적 객체 검출 개요 2. 이동(드론) 카메라 움직임 보상
가. 전 프레임과 background model에 이동(드론) 카메라 움직임 보상
3. Spatial temporal background modeling
가. Gaussian distribution에는 mean, variance과 age를 이용 나. 현재 프레임의 화소와 그 화소 주변의 background models을
중 distance가 작은 background model을 업데이트 다. Age에 따른 가중치맵 생성
4. Frame differencing으로 동적 객체를 부분적으로 검출
5. Background model을 statistical morphology에 이용해 동적 객체를 전체적으로 검출
l 드론 영상 기반 의 차량 검출을 이용한 방치 검 출 및 예측 기술 설계
l 이동(드론) 카메 라 기반의 차량 검출 기술 개발
l 드론을 활용한 차량 Database 수집 및 테스트 베드 구축
그림 7. 차량 DB 및 실험을 위한 테스트 베드 구축 l 이동(드론) 카메라 기반의 차량 검출 기술 개발
1. 외형 변화에 강인한 G-ORF (Gradient based order Relation Feature)로컬 특징 추출 기술 연구
가. 분류 성능이 좋은 base feature(SURF)로부터 2개의 떨어진 윈 도우에서 특징을 추출하고, 추출된 구성 원소들간의 대소관계 를 비교하여 특징을 추출
나. 룩업테이블 기반의 설계로 높은 분류 성능을 갖고, 빠른 속도 로 추출 가능한 특징 구조를 설계
다. 영상 기울기 기반의 특징으로 포즈 변화에 강인함 2. 포즈 분류를 위한 포즈 분류기 학습 기법 및 모델 연구
가. 빠르고 강인한 룩업 테이블 기반의 Boosting 학습 방법 연구 나. weighted LDA 기반의 강인한 분류 성능을 갖는 포즈 분류 및
차량 검출기 개발
그림 8. G-ORF(Gradient based order Relation Feature)의 구조
계획 추진실적
객체 행동 분석을 통 한 비정상/
의심 상황 예측 기술 (고려대)
l 계획 수립 및 자 료조사
l 테스트 데이터 수집
l 계획 수립 및 자료조사
1. 논문 : 국제 저널 및 학회 (PAMI, CVPR, ICCV, ICPR, AVSS 등) 2. 기관 : 해외 기업 및 학교 (IBM, Kitware, Stanford Univ. CMU,
UCR 등)
l 테스트 데이터베이스 (DB) 수집
1. 테스트 DB 내용 : UT-Interaction, KU 이상행동 데이터셋, MIT Parking Lot Trajectory Dataset 수집
2. 테스트 DB 수준 : 구분된 개별의 단순행동 및 장시간에 걸쳐 발 생하는 복잡한 행동으로 구성, 길이/환경변화/행동 복잡도에 따라 구분
3. 성능평가 방법 및 기준:
가. 전체 입력영상 중 정확하게 인식한 영상의 비율
나. 영상의 일정 시점 이후 발생하는 이상행동 예측 정확도
l 다중 객체간 단 위행동 추출 및 인식방법
l 장면 정보 추출 을 위한 궤적 기 반 공간 분할 기 술 개발
그림 9. 정상/비정상 궤적에 대한 정성적 예시 l 다중 객체간 단위행동 추출 및 인식방법
1. 연속된 영상에서의 다중 객체간 발생하는 행동에 대하여 각각의 의미를 갖는 단위 행동들을 정상적으로 추출하는지 확인
2. KU 이상행동 데이터셋에서의 전체 프레임중 정확하게 추출한 프 레임의 비율을 측정하여 그 성능을 평가
l 장면 정보 추출을 위한 궤적 기반 공간 분할 기술 개발
1. 사람의 움직임 궤적의 유사도에 기반하여 비디오 장면을 작은 영 역으로 분할하고, 이로부터 행동 구조 모델을 학습
2. 학습 및 분류된 궤적이 실제 움직임을 반영하는지 정성적 확인 3. MIT parking lot trajectory dataset에서의 행동인식 정확도 계산
l 다중 객체 간 관 계 기반 상황 예 측 기술 개발 l 상황 예측 기술
개발 및 성능 평 가
l 다중 객체간 관계 기반 상황 예측 기술 개발
1. KU 이상행동 DB에서 일정 시점 이후 이상행동의 발생여부를 확 인
2. 비정상 정도 함수값 기반의 미래 비정상 상황 발생확률 측정 l 자체점검 시나리오 및 결과 (검증 활동)
1. 각 영상 내 이상해동 Groundtruth 제작 및 작업 평가 진행 2. 테스트 DB에서 평균 정밀도 81% 달성 / 평균 재현율 72% 성능 2) 객체 행동 분석을 통한 비정상/의심 상황 예측 기술 (1.2 세부)
3. 최적 성능 구간에서 인식 정확도 88.28% 달성 l 연구결과 완성도 (목표달성 및 질적 수준)
1. 1단계 2차년도 목표 성능 대비 100% 달성 2. 세계 수준 대비 정밀도 12%, 재현율 9% 향상
계획 추진실적
객체 흐름 분석을 통 한 비정상/
의심 상황 예측 기술 (서울대)
l 계획수립 및 자 료조사
l 자연어 처리 모 델조사 및 분석
l 기존 기술 동향 조사 (논문, 기업)
1. 논문 동향 : 국제 저널 및 학회 (PAMI, CVPR, ICCV, AVSS 등) 2. 기업 동향 : 국내외 기업 (S1, 한화 테크윈, 삼성 SDS 등) l 자연어 처리 모델 조사 및 분석
1. Parametric 계열 자연어 처리 알고리즘 조사 (LDA, PLSI)
2. Nonparametric 계열 자연어 처리 알고리즘 조사(HDP, nCRP, nHDP)
3. 국제 저널 및 학회에 출원된 자연어 처리 알고리즘 응용 알고리 즘 조사
l 시각정보에 적합 한 자연어 처리 모델 수정
l 자연어 처리 모델 수정
1. 궤적 학습에 적합하도록 모델 수정 2. 단어 단위에서 궤적 단위로 모델 변경
3. 모델의 주제의 등장 빈도 동시 학습 가능하도록 새로운 모델 제 안
그림 10. 자연어 처리 모델 프레임 워 크
l 상황 예측 기술 개발 및 성능 평 가
l 이상행동 탐지 알고리즘 개발
l 이상행동 검출을 위한 시공간적 패턴 분석 알고리즘 개발 1. 영상 내 주요한 움직임 패턴을 학습
2. 영상 내 주요한 움직임 패턴들을 주로 나타나는 시간에 대하여 결합
가. 15-20개의 움직임 패턴 추출
나. 3-4개의 패턴 그룹으로 시간적 결합 표현
그림 11. 상황 예측 및 이상행동 예측 알고리즘 프레임워크
3. 패턴 별로 이상행동 및 상황 예측 알고리즘 개발 4. 연구결과 완성도 (목표달성 및 질적 수준)
가. 2단계 2차년도 목표 성능 대비 TCA 100% 달성 3) 객체 흐름 분석을 통한 비정상/의심 상황 예측 기술 (1.3 세부)
계획 추진실적
맥락 정보 를 활용한 의 미 론 적 영상 분할 기술 연구 (서울대)
l 계획 수립 및 자 료 조사
l 맥락 정보 기반 물체 인식 기법 조사 및 분석
l 기존 기술 동향 조사(논문 및 기관)
1. 논문 동향 : 국제 저널 및 학회 (PAMI, CVPR, ICCV, arXiv 등) 2. 기관 동향 : 국내외 기업 및 학교 (TTI, CMU, UCB 등)
l 기존 맥락 정보 기반 물체 인식 기법 조사 및 분석
l 2. 맥락 정보 기 반 물체 인식 기 법 개발
l 3. 테스트 데이 터베이스 구축
l 맥락 정보 기반 의미론적 영상 분할 기법 개발
1. 맥락 정보 기반의 의미론적 영상 분할 기반 프레임워크 구축 (딥 러닝 신경망 기반)
2. 다양한 물체 범주 사이의 맥락 정보를 동시 발생 빈도를 통해 학 습
3. 불완전한 학습으로 인한 적응형 방식으로 오차를 보정 l 맥락 정보 기반 희소 물체 인식 기법 개발
1. 물체 인식기 (object detector)를 이용해 영상에 존재할 수 있는 객체 후보 선별
2. 인식된 각각의 객체가 영상의 맥락 상에서 희소 물체인지 여부를 판별
3. 각각의 영상 범주 (실내, 야외 등) 에 맞는 표준적인 물체 배치를 학습하여 맥락 정보로 활용
그림 12. 맥락 정보 기반 희소 객체 인식 개요
l 테스트 데이터베이스 내용 및 수준
1. 테스트 DB 내용: MIT LabelME를 이용하여 자체 제작
2. 테스트 DB에서 희소 물체 state-of-the-art 대비 성능 향상 확인
4) 맥락 정보를 활용한 의미론적 영상 분할 기술 연구(2.1 세부)
계획 추진실적
딥 러닝의 적용을 통 한 알고리 즘 확장 및 앙상블 학 습 도입을 통한 예측 모델의 병 렬 결합 (포항공대)
l 예지형 시각 지 능을 위한 딥 러 닝 프레임워크 확립
l 다양한 문제 해 결 및 보다 정확 한 상황 표현을 위한 딥 러닝 기 반의 표현 방법 학습
l Deconvolution Network를 통한 픽셀 단위의 물체 검출 알고리즘 설계
1. Deconvolution layer 및 unpooling layer의 도입을 통하여 기존 알 고리즘 대비 보다 픽셀 단위에서 정확한 물체 검출
그림 13. 제안된 Deconvolution Network 구조
l DecoupledNet를 통한 적은 데이터로 학습 가능한 물체 검출 알고 리즘 설계
1. 이종 데이터를 활용 가능한 물체 분할 알고리즘 설계
2. 이미지 단위의 데이터를 활용하여 학습시 필요한 픽셀 단위의 분 할 영상 감소
그림 14. 적은 데이터를 학습하기 위한 DecoupledNet 구조 l 연구결과 완성도 (목표달성 및 질적 수준)
1. Deconvolution Network: PASCAL VOC challenge에서 mAP (Mean Average Precision) 72.5%의 성능 달성
2. DecoupledNet: PASCAL VOC challenge에서 물체 종류마다 25장 의 학습 데이터 제공 시 mAP 62.5% 달성(기존 알고리즘은 물체 종류마다 약 500장 이상의 학습 데이터 제공)
l 서로 다른 특징 을 지닌 복수의 예측 모델 결합 을 통해 단일 모 델 대비 예측 성 능이 높은 예측 알고리즘 개발 l 딥 러닝 아키텍
쳐에 적용하여, 서로 다른 성질 을 지닌 딥 네트 워크 모델을 결 합
l 주변 환경 인식 및 행동 예측 알고리즘 개발
1. 스테레오 카메라로 주변 환경을 정확히 인식 할 수 있도록 패턴 이 없는 환경에 뚜렷한 패턴을 만드는 알고리즘 설계
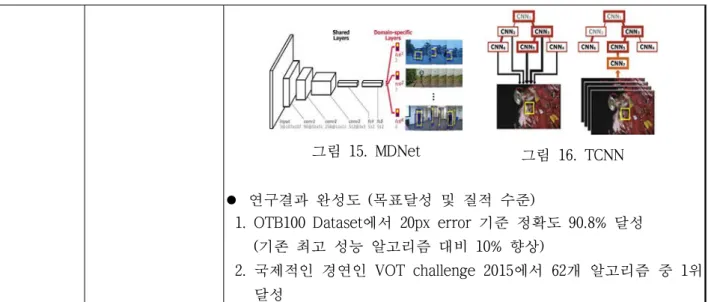
l Multi-domain CNN을 통한 물체 추적 알고리즘 MDNet 개발
1. 여러 학습 시퀀스로부터 공통된 특성을 학습한 레이어 (shared layer) 및 타겟 시퀀스에 특정한 레이어로 구성된 네트워크 설계 l 복수의 CNN을 통한 물체 추적 알고리즘 TCNN 개발
1. 실시간으로 변하는 추적 물체의 외형 모델을 효과적으로 유지할 수 있도록 서로 다른 시계열 데이터로부터 학습된 복수의 CNN 을 결합하는 물체 추적 알고리즘 설계
5) 딥 러닝의 적용을 통한 알고리즘 확장 (2.2 세부)
그림 15. MDNet
그림 16. TCNN
l 연구결과 완성도 (목표달성 및 질적 수준)
1. OTB100 Dataset에서 20px error 기준 정확도 90.8% 달성 (기존 최고 성능 알고리즘 대비 10% 향상)
2. 국제적인 경연인 VOT challenge 2015에서 62개 알고리즘 중 1위 달성
계획 추진실적
객체 및 장 면 모델링 을 위한 외 형 학습 기 술 개발 (연세대)
l 게획 수립 및 기 술 조사
l 딥러닝 모델 설 계
l 데이터 수집 계 획
l 계획 수립 및 기술 조사
1. 딥러닝 관련 최신 기술 동향 파악 및 자료 조사. 관련 학회 및 저널의 최신 논문 조사(CVPR, ICCV, ECCV, NIPS, TPAMI, 등). 조 사된 내용을 바탕으로 차후 계획인 모델 설계 및 실험 진행.
l 딥러닝 모델 설계
1. 다양한 최신 논문을 통해 여러 가지 문제에서 잘 동작하는 것이 검증된 Alexnet의 네트워크 구조와 흡사한 구조를 본 문제에 더 욱 적합하도록 수정하여 사용
l 데이터 수집 계획
1. 직접 데이터셋을 수집하여 제작하기 보다는 다른 알고리즘과 공 평한 비교를 위해 공개된 벤치마크 조명색 예측 검증 데이터셋 사용
가. Gelher-Shi 데이터셋: 고화질의 DSLR 원본 RAW를 제공 나. SFU GrayBall 데이터셋: 비교적 저화질의 RAW가 아닌 카메라
프로세싱이 된 영상을 제공. 하지만 더 많은 데이터량을 제공
l 딥러닝 학습 알 고리즘 설계 및 검증
l 조명 예측 모델 학습
l 딥러닝 학습 알고리즘 설계 및 검증
1. 딥러닝을 이용하여 조명색 예측 문제를 해결하기 위해 새로운 접 근법 도입. 기존의 관점인 카메라 컬러스페이스에서의 회기문제 로 접근하는 대신, 조명색 분류문제로 재해석하여 진행. 알고리 즘을 요약하면 다음과 같음:
가. 데이터셋에 존재하는 조명을 군집화 알고리즘을 통해 조명 종 류 분류
나. 앞서 설계한 CNN을 1)과정에서 얻어낸 조명 종류를 자동 분 류하도록 학습
다. 더욱 정확한 예측을 위해, 결과 확률 분포를 통한 기댓값 게 산으로 하나의 조명색 예측
l self-calibration 을 통한 객체 외 형 교정 수행
l 영상에서 추출할수 있는 정보 (보행자 height, lines)를 통해 self calibration을 수행
l 수행된 calibration 정보를 활용하여 관심 객체 영상의 왜곡을 보 정
6) 객체 및 장면 모델링을 위한 외형 학습 기술 개발 (2.3 세부)
그림 17. 보행자 height 추출 결과
그림 18. 2차원 공간에 사영된 3차원 공간 정 보
1. 해당 정보를 통해 3개의 직교하는 소실점을 추출한뒤, camera calibration 수행. 3차원 공간과 2차원 이미지 공간간의 관계 정의 가능
그림 19. 외형 보정된 객체 영역
2. 얻어진 calibration 정보를 통해 위와 같이 영상 왜곡을 보정결과 를 얻을 수 있었음. 해당 보정결과를 이용하면, 보다 좋은 성능 의 객체 추적결과를 얻을 수 있을 것으로 기대 됨.
l 신뢰도 기반 온 라인 외형 데이 터 추출/ 분류 기법 설계
l 추적 신뢰도 기반 온라인 외형 학습 개발 1. 추적 신뢰도의 정의
가. 추적 신뢰도는 객체의 외형정보, 추적 시간, 객체 검출기의 성능 등을 고려하여 다음과 같이 종합적으로 정의
그림 20. 제안된 신뢰도에 따른 온라인 외형 추출
나. 위의 예시와 같이, 제안된 신뢰도를 통해, 객체 추적을 위한 객체 외형 학습에 사용하기에 부적절한 데이터를 제외할 수 있음.
다. 제안된 추적 신뢰도를 통해 온라인 외형 데이터를 각 실험 시 퀀스에 따라 선별적으로 추출.
l I n c r e m e n t a l LDA를 이용한 온라인 객체 외 형 모델 학습
l 신뢰도 기반으로 얻어진 학습 샘플들을 이용하여 서로다른 관심 객체가 가장 잘 분별 될 수 있는 LDA 부분 공간을 학습.
l Online 동작을 보장하기 위해, Incremental LDA 기법을 활용
그림 19. Incremental LDA 기법을 이용한 온라인 외형 학습
l 위와 같은 부분공간 학습 결과를 얻었으며, 해당 부분공간을 이용 한 객체 추적에 대한 성능평가를 수행함.
l 온라인 외형 학 습 기반 객체 추 적 기술 평가
l 신뢰도 기반 온라인 외형 학습 객체 추적 기술 성능 평가 1. 테스트 DB 내용 : PETS, ETHMS, CAVIAR
2. 검증 절차
가. 신뢰도 기반 Incremental LDA 학습
나. 학습 결과를 바탕으로 다중 객체 추적 수행 다. 결과 값과 추적 진리 값 비교
3. 성능 평가 기준 : 객체 추적 정밀도/ 객체 추적 정확도 4. 성능 평가 목표 : 객체 추적 정밀도 55% 이상
객체 추적 정확도 40% 이상
5. 성능 평가 결과 : 객체 추적 정밀도 77.92%
객체 추적 정확도 68.55%
계획 추진실적
지능형 관 제 시스템 통합 및 최 적화
((주)파슨텍)
상황 인식용 비 디오 데이타베이 스 모델의 보완 및 재구축
l 1차년도 결과물에 특이사항 없음
상황인식 S/W테 스트를 위한 테 스트베드 조사분 석 보완
l 기존 파슨텍의 제품인 SmartCops를 향후 사업화를 위한 확장방안 분석
l 2차년도에는 종합관제 시스템의 UI변경 및 기능정비를 통하여 Pototype의 성능 및 사용자 편의성 증대 방안 수립
상황인식 S/W테 스트를 위한 테 스트베드 확장 적용
그림 22. 테이블 구조도 l 기존 DB모델 활용
l 기존 파슨텍의 제품인 SmartCops의 UI개선
l 기존 파슨텍의 제품인 SmartCops의 기능 개선 적용
그림 23. 개선 UI 예시
그림 24. 적용 결과물
7) 지능형 관제 시스템 통합 및 최적화 (사업화)
평가 항목 (주요성능
Spec)
단 위
전체 항목 에서 차지하
는 비중)
(%)
세계최고 수준 보유국/
보유기업 ( / )
연구개발 전 국내수준
성능 수치
평가 방법
성능수준 성능수준
2차년도 목표 수치
(2015년)
2차년도 도달 수치
(2015년) 1.비정상/의심
상황 예측 정 확도
% 14 없음 없음 60 66
수요기업 평가 (StradVision)
2.비정상/의심 상황 응답 속 도의 일관성
% 13 없음 없음 ±40 ±40
수요기업 평가 (StradVision)
1.비정상/의심 상황 예측 정 확도
% 14 미국/
65% 없음 65 67
수요기업 평가 (StradVision) 2.비정상/의심
상황 응답 속 도의 일관성
% 13 없음 없음 ±35 ±35
수요기업 평가 (StradVision) 1.비정상/의심
상황 예측 정 확도
% 14 없음 없음 65 65
수요기업 평가 (StradVision)
2.비정상/의심 상황 응답 속 도의 일관성
% 13 없음 없음 ±35 ±35
수요기업 평가 (StradVision)
1.객체 추적
정확도 % 10 없음 없음 40 68.55
PETS/ETHMS/
CAVIAR 성능 평균치 2. 객체 추적
정밀도 % 9 없음 없음 55 77.92
PETS/ETHMS/
CAVIAR 성능 평균치
Ⅰ-3 방치/도난 객체 검출을 통한 정확한 비정상/의심 상황 예측 기술 개발 (1.1 세부)
1. 방치/도난 객체 검출 기술의 고도화 가. Pixel Layer
1) 모든 Pixel에 대해 FSM 의 상태 전이를 통해 분석 및 처리 2) 3개의 상태(background, foreground, static)으로 구성 3) 7개의 가능한 상태 이동 구성
4) 상태 전이 (State transition)에 x 개의 특징(feature)가 사용됨
5) Intensity Feature : distance-based confidence value ′, probability-based confidence value ′, 그리고 similarity-based confidence value ′를 이용하여 모델링, 0과 1사이로 정규화되며 배경 정보와 차이가 많이 날수록 값이 커짐
6) Distance-based confidence value ′ : pixel X의 intensity와 평균 intensity의 차이에 대한 Confidence
′
∈
7) Probability-based confidence value ′는 주변 neighborhood 픽셀의 상태 (background, foreground, static)를 이용해 확률을 계산
′
∀ |
∀
∈
8) Similarity-based confidence value ′은 기존의 픽셀과 평균을 이용해서 현재 픽셀 값과 배경 값의 유사도를 계산
′ ∈
9) Time duration feature은 전경 픽셀로 구분된 픽셀의 누적 frame 수를 구하여 정지 픽셀 구분
×m in
′
′ ′
나. Region Layer
1) 정지 상태인 pixel을 하나의 영역으로 묶어서 처리
2) 3개의 상태 (background, foreground, static 상태)로 구성 3) 8개의 상태 천이로 구성
4) Feature로는 area feature, intensity features (dissimilarity, stability), motion features (degree of overlap, degree of area change, degree of position change), shape features (degree of unevenness, degree of symmetry, degree of filling), time duration feature들이 사용됨
5) Area feature: 각 영역의 픽셀 개수로 정의
6) Intensity dissimilarity: chi-square distance로 계산되며, 배경과 물체의 intensity histogram 간의 차이가 크면 큰 값을 가짐
∈ .
7) Intensity stability : 지난 T frame 동안의 영역 내 픽셀 값들의 variance를 의미함
×
∀∈
∈ .
8) Degree of overlap : 한 영역의 bounding box와 전경 영역의 bounding box 간의 겹친 비율을 계산함. 만약에 두 개의 bounding box의 겹친 비율이 크면 하나의 새로운 bounding box으로 만들기 위함
∈ .
9) Degree of area change : 한 영역의 bounding box 면적의 변화를 계산함
max
min
∈ .
10) Degree of position change: 한 영역의 bounding box의 중점의 변화를 계산함
maxmax
∆
max
∆
∈ .
11) 위 세 개의 Motion feature들은 움직임이 적을수록 작은 값을 가지며, 세 개의 motion features의 값들이 작으면 정지 영역으로 정의됨
그림 25. 세 가지 shape features
12) Degree of unevenness : 한 영역의 외곽선의 복잡도를 의미하며, 그림 xx와 같이 외곽선을 등간격으로 나눈 후, 중점과 각 점 간의 길이 및 각도 변화율로 측정됨
max
max
∈
13) Degree of symmetry : 한 bounding box의 좌우 및 상하간의 겹치는 면적을 계산 함
max
∩
max
∩ ∈ .
14) Degree of filling : 한 영역의 bounding box와 그 영역의 면적과의 비율로 정의됨
′
∈ .
15) Shape features의 값들은 모양의 복잡도가 적을수록 큰 값을 가지며, 일반적으로 사람은 shape features의 값들이 작고, 방치 물체는 값들이 큼.
16) Time duration features: 최종 정지 영역을 계산하기 위해 정지 후보 영역으로 구분된 누
적 frame을 계산함
×m in
′ ,
′ ′ .
17) Static region은 많은 frame 동안 픽셀 intensity variance가 낮고, 특정한 픽셀 지역에 motion이 없으며, simple region boundary contour을 갖고 있음
다. Event Layer
1) 최종 정지 영역들에 대해서 처리
2) 3개의 상태 (withheld, abandoned, removed state)로 구성 3) 5개의 상태 천이로 구성
4) Features으로는 color feature (difference of color richness)와 edge feature (differen ce of edge strength)가 있음
5) Difference of color richness : 정지 영역의 칼라 정보의 다양성을 나타내며, 일반 적으로 배경이 동일한 색상을 가진다고 가정한다면, 양의 값은 방치 물체로 구분되고 음 의 값은 도난 물체로 구분됨
max
∈ ,
.
6) Difference of edge strength : 입력 영상과 배경 영상에서 한 영역의 해당하는 edge strength의 차로 정의되며, 양의 값은 방치 물체로 구분되고 음의 값은 도난 물체로 구분됨
max
∈ .
그림 26. 방치/도난 객체 검출에 사용되는 FSM
이와 같이 방치/도난 객체 검출기는 Pixel Layer를 통해 전경, 배경 그리고 정지 Pixel을 구분 하고 Region Layer에서는 구분된 Pixel을 묶어, 전경, 배경, 그리고 정지 영역으로 구분한다. 마 지막으로 Event Layer는 최종 정지 영역이 보류, 방치, 그리고 도난 이벤트로 구분되어진다.
7) 무단 방치 및 도난 물체 검출 평가 및 성능
기본 평가 지수 ARO : Abandoned or Removed Object, 즉 무단 방치 및 도난 물체)
TP(True Positive) : 실제 ARO 이면서 실험 결과도 ARO 인 물체 개수
TN(True Negative) : 실제 ARO 가 아니면서 실험 결과도 ARO 가 아닌 물체 개수
FP(False Positive) : 실제 ARO 가 아닌데 실험 결과가 ARO 인 물체 개수
FN(False Negative) : 실제 ARO 인데 실험 결과가 ARO 가 아닌 물체 개수
가) Pixel-layer
- Precision: True Positive/(True Positive+False Positive) - Recall; True Positive/(True Positive+False Negative) - Precision 83%, Recall 93% 달성, 오검출 감소
나) Region-layer
- True Detection Accuracy: True Positive/(True Positive+False Negative) - False Classification Ratio: False Positive/(True Positive+False Positive) - TDA 68%, FCR 54% 달성
다) Event-layer
- Static Region Discrimination Accuracy: True Positive/Ground Truth - SRDA 100% 달성
2. 이동 카메라 기반의 이동 객체 검출 기술 개발 가. Optical flow 기반 움직임 보상 기술 설계
1) 이동 카메라의 움직임 보상
그림 27. 이동(드론) 카메라 움직임 보상 과정 개요
이동(드론) 카메라의 motion model 생성
가) 현재 프레임과 전 프레임간의 Hierarchical LKT으로 optical flow 계산
나) RANSAC으로 이동(드론) 카메라의 optical flow과 동적 객체의 optical flow 구분 다) 이동(드론) 카메라의 optical flow으로 projective motion model 생성
Warping을 통해 이동(드론) 카메라 움직임 보상 가) Nearest neighbor interpolation 이용
나) 동적 객체 검출에 사용되는 전 프레임과 background model에 현재 프레임과 전 프레임 으로 구한 projective motion model을 이용해서 이동(드론) 카메라 움직임 보상
이동(드론) 카메라 기반 동적 객체 검출 기술 설계
그림 28. 이동(드론) 카메라 기반 동적 객체 검출 과정 개요
가) 이동(드론) 카메라의 움직임 보상 기술을 전 프레임과 background model에 적용 나) 이동(드론) 카메라의 움직임 보상이 된 전 프레임과 현재 프레임으로 움직이는 객체를
부분적으로 검출
다) 이동(드론) 카메라의 움직임 보상이 된 background model을 statistical morphology에 이 용해 동적 객체를 전체적으로 검출
라) Foreground으로 분류된 화소들은 tracking을 통해 연속으로 검출되는 foreground 영역 만을 true foreground으로 인정
마) Background으로 분류된 화소들은 spatial temporal background model 업데이트에 이용
나. Spatial temporal background model
1) 이동 카메라 움직임 보상을 보충하기 위해 spatial temporal background model 이용 2) Gaussian distribution은 mean, variance, age으로 구성
3) Age을 이용해서 weight map 생성
4) 현재 프레임과 이동 카메라 움직임을 보상한 background model의 주변 화소들을 비교해 서 현재 프레임의 각 화소의 corresponding background model을 찾음
∈
arg
5) 현재 프레임의 화소와 각 화소의 corresponding background model을 이용해서 spatial temporal background model 업데이트
∙
∙
∙
∙
6) 업데이트된 corresponding background model의 age 증가
다. Statistical morphology
1) Foreground으로부터 일정 간격을 가진 주변 화소를 foreground candidate으로 지정 2) Foreground candidate 화소의 foreground일 수 있는 확률을 계산해 threshold 이상이면
foreground candidate을 foreground으로 지정
→ i f log
for
exp
for ∀
exp
for ∀
라. Tracking
1) 연속으로 5번 이상 foreground 영역으로 검출된 foreground 영역만을 true foreground 영 역으로 검출
2) Overlapping ratio, size, intensity의 feature를 사용해 tracking함
3. 이동(드론) 카메라 기반의 차량 검출 기술 개발 가. G-ORF Feature 기반의 특징 추출 기술 개발
1) LBP, MCT, Ferns같은binary coded feature들은 심플하고 빠른 장점이 있지만, 떨어져 있 는 특징을 표현하지 못한다거나, 완벽한 대소 관계를 표현하지 못하여 분류성능이 떨어지 는 단점이 있음.
2) 분류 성능이 좋은 base feature (SURF)로부터 2개의 떨어진 윈도우에서 특징을 추출하고, 추출된 구성 원소들간의 완벽한 대소 관계를 표현할 수 있는 G-ORF (Gradient based order Relation Feature)를 개발함.
3) 또한 단순히 코드로 룩업테이블의 confidence값을 참조하는 방법은 분류성능을 떨어뜨리 는 단점이 있기 때문에, 룩업 테이블에 wLDA로 학습된linear classifierr를 저장하고, 이를 이용해 같은 코드에 속하는 학습샘플을 다시 한번 재 분류해 뛰어난 분류 성능을 얻을 수 있도록 설계함.
4) ORF의 정의
Base feature로부터 추출된 K개의 원소는 다음 식에 의해 long code로 변환
여기서 q와 q hat은 원소의 비교 순서를 나타내는 sequence vector로 다음 조건을 만족 한다.
예를 들어 K=5일 때 q와 q hat은 다음과 같다.
Long code는 원소들의 모든 가능한 pair로부터 대소관계를 비교한 후 이를 bit string으 로 나타내어 생성되며 0~2^{ } 값을 갖는다.
Long code는 너무 큰 범위의 값을 가져서 룩업테이블을 구성하기 힘들기 때문에 Encoding map을 통하여 코드 수를 줄인 Short code로 변환한다.
8개의 원소를 갖는 ORF는 8!의 코드 개수를 갖기 때문에 룩업 테이블의 크기가 너무 커 지므로, 원소를 4개식 묶어서 각각의 ORF를 만들고 이를 다음과 같이 합쳐서 ORF4x4 로 정의한다.
인코딩 맵의 생성 알고리즘은 다음과 같다.
5) G-ORF 추출 방법
주어진 이미지에서 SURF컴포넌트로 구성된 base feature를 생성한다. Base feature는 5x5로컬 윈도우 내에서 SURF 컴포넌트를 추출하여 이를 하나의 픽셀로 갖는 4채널 이 미지를 생성하여 얻어진다. 이때 integral 이미지를 사용해서 5x5 윈도우 내의 그래디언 트 성분의 합을 빠르게 계산한다.
그림 35 G-ORF의 생성 구조
와 의 두 위치에서 추출된 SURF descriptor는 다음과 같이 4개의 그래디언트 합의 성분으로 이루어져 있으며 그 중, 두 개는 pure sum, 나머지 두 개는 absolute sum이다.
대소 관계 비교를 위해 pure sum은 pure sum끼리, absolute sum은 absolute sum끼리 묶 어주게 되면 다음과 같은 pure sum vector x1과 absolute sum vector x2를 얻는다.
최종 G-ORF 코드는 ORF 4x4 크기의 (x1,x2)로 얻어진다.
나. G-ORF 를 이용한 차량 학습 및 포즈 분류
1) N개의 학습 샘플에 대하여 G-ORF channel로 변환된 학습샘플 및 레이블의 셋을 정의하 고 각 샘플의 t번째 부스팅 라운드에서의 weight를 다음과 같이 정의함.
,
2) 룩업테이블의 bin b에서 가장 좋은 분류성능을 나타내는 feature 는 다음과 같이 구해짐.
Where,
3) wLDA학습을 위해 bin b에 떨어진 학습 데이터를 클래스 레이블에 따라 두 개의 set으로 나눔
여기서 는 G-ORF의 구성요소(8개)를 나타내는 벡터임.
4) 다음 식을 이용해 bin b에 떨어지는 샘플들을 최적 분류하는 projection vector와 threshold를 구함.
5) 4)의 wLDA결과로 얻어진 projection vector와 threshold로 부터 t번째 부스팅 라운드의 bin b에 해당하는 샘플들을 잘 분류하는 linear classifier는 다음과 같이 구해짐.
6) t번째 weak classifier가 G-ORF코드 b에 대해 내놓는 weak hypothesis는 RealBoost를 이용 해 다음과 같이 구할 수 있음.
7) 임의의 샘플 x에 대해 이를 분류하는 weak classifier ht는 다음과 같이 5)에서의 confidence 값들과 wLDA로 구한 linear classifier를 이용해서 다음과 같이 구해짐.
다. 드론 영상에서의 차량 검출 기술 개발의 정성적 결과
그림 36. 드론 기반의 Top-view 차량 검출 및 포즈 추정 결과
Ⅰ-4 객체 행동 분석을 통한 비정상/의심 상황 예측 기술 (1.2 세부)
본 과제에서는 다중 이미지/영상 기반의 공간 상황을 이해하고 발생할 수 있는 상황을 미리 예 측할 수 있는 예지형 시각 지능 원천기술을 개발하고자 한다. 이를 달성하기 위하여 2차년도에는
"저해상도 영상 기반 실시간 객체 행동 분석을 통한 정확한 비정상/의심 상황 예측 기술 개발"을 목표로 삼고, 이를 위한 프레임워크 설계 및 필요 기술 개발을 진행한다.
1. 실시간 행동 분석에 기반한 비정상/의심 상황 예측 기술 개발
가. 단위 행동 추출 및 인식 기법 – Human action 및 Activity 의 발생 감지 및 단위 추출 나. 장면정보 추출 및 분석 – 영상 분석을 통하여 각 영역에서의 행동 정보 검출
다. 다중 객체간 관계 기반 상황 예측 기술 개발 – 단위 행동과 장면 정보를 이용한 시퀀스 라. 모델링을 통하여 발생 가능한 이벤트에 대하여 추론
그림 37. 영상 내 행동의 계층적 분석 및 정의
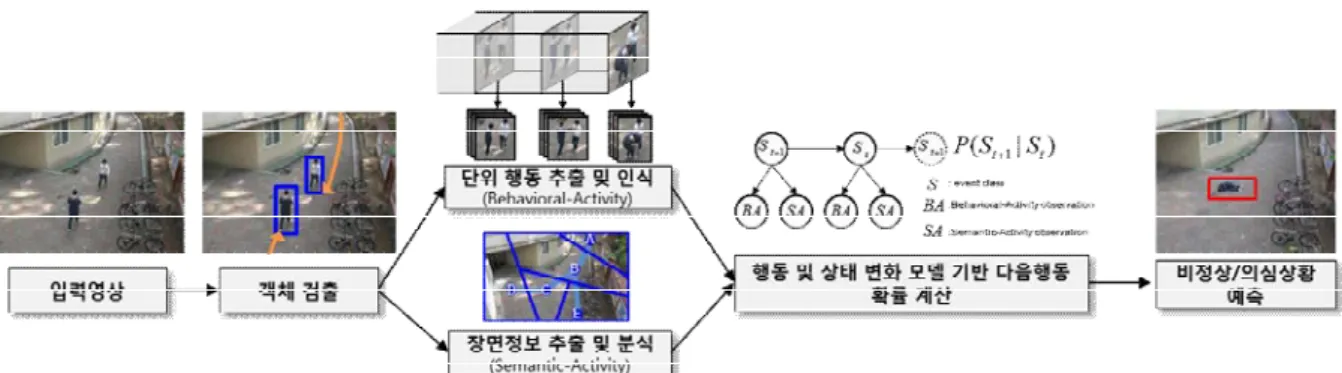
1) 입력 영상에서의 객체 행동 분석 및 인식을 위하여, 먼저 입력 영상으로부터 각각의 휴먼 객체에 대하여 관심 영역을 설정한다. 설정된 관심영역으로부터 추출된 영상에 대하여 3D convolutional neural network를 이용하여 특징을 추출하고, 이를 이용하여 "단위 행동 추출 및 인식"을 수행한다. 이와 동시에 궤적기반의 장면정보를 추출하고, 이를 융합하여 미래의 이상행동 발생 가능성을 측정한다. 행동 분석에 기반한 비정상/의심 상황 예측을 달성하기 위하여 필요한 프레임워크를 구성하는 필요 기술의 세부 내용은 아래와 같다.
비정상/의심 상황 예측을 위한 프레임워크
가) 다중 객체간 관계 기반의 비정상/의심 상황 예측을 위한 프레임워크를 제안한다. 입력 영상에서의 비정상/의심 상황 예측을 위하여, 먼저 입력 영상으로부터 객체를 검출하고, 검출된 각 객체의 영상정보를 "단위 행동 추출 및 인식"을수행하여 Behavioral-activity 의 sequence를생성한다. 또한 이와 별개로, 각 객체의 움직임 궤적 정보에 기반하여 "장 면정보 추출 및분석"을 수행한다. 두 가지 추출된 정보를 이용하여, 현재 시점까지 관찰 된 행동 정보에 기반하여 다음 발생할 비정상/의심상황 예측을 위한 행동간의 시간적 상관관계를 분석하여 "다중 객체간 관계 기반 상황 예측"을수행한다. 이러한 예측의 결 과를 종합하여 최종적으로 미래의 비정상/의심 상황 발생 가능성을 측정한다.
그림 38. 비정상/의심 상황 예측을 위한 프레임워크
비정상 정도 측정을 위한 비정상 정도 함수
가) 단위 행동의 추출 및 분석 결과와 궤적 기반의 장면정보 분석 결과를 융합하여, 현재 시 점 이후에 비정상 행동이 발생할 확률을 측정한다. 영상 분석결과에 따르면, 특정 행동 들은 전체 데이터에서 적은 비중을 차지하며 나타난다. 특히 비정상 행동이 발생하는 상황에서 나타나는 특정 행동들이 전체 데이터에서 차지하는 비율이 매우 적다. 이러한 특성을 바탕으로 전체 데이터에서 각 행동의 구성 비율을 측정하고, 이를 활용하여 이 상 정도를 측정한다.
나) 이전의 장면정보 및 단위 행동 인식 결과로부터 발생하는 오분류로 인한 손실 최소화를 위하여, 단위 행동 추출 및 인식을 통해 분할된 영상의 최근 Dt 길이 만큼의 관측 결과 를 활용한다. 스코어 계산을 위한 수식은 아래와 같다.
* (1 j) j j,
j t t
A p sc cn
y y
cm
= -D
=
å
- =다) 위 수식에서
p
j와sc
j는 각각, 단위 행동 인식 결과인 activity context와 장면정보 분 석 결과인 scene context를 나타낸다.cn
과cm
은 각 행동 클래스가 나타난 state의 숫 자와, 전체 state의 개수를 나타낸다. 이상행동은 특정 행동의 이전에 나타나는 전조적 성격을 가지는 행동의 감지와, 각 행동의 발생 위치를 조합하여 미래에 특정 이상행동 이 발생 할 것을 예측 할 수 있다. 3차원 콘볼루션 신경망을 이용한 인간 행동의 특징 추출
가) 영상으로부터 유의미한 외형과 움직임 정보를 특징으로 구성하기 위해 각 사람의 영상 으로부터 3차원 콘볼루션 신경망을 통해 외형과 움직임 정보를 추출하고 결합하여 행동 을 나타내는 특징을 구성한다.
나) 입력영상 와 각 사람 의 관심영역(regions of interest)으로부터 128 x 128(높이 x 너비) 크기의 정규화된 영상 생성한다. 그리고 고정된 길이 로 분할하여 개의 영상 클 립 을 생성한다. 분할 단위 는 16프레임으로 설정한다. 각각의 영상 클립을 3차원 콘볼루션 신경망의 입력으로 사용한다.
다) 특징의 추출을 위해 3차원 콘볼루션 신경망을 기반하여 네트워크를 구성하였다. 그리고 부족한 샘플(sample) 수 문제를 극복하기 위해 스포츠 1m 데이터셋에서 사전학습 된 (pre-trained) 모델에서 미세 조정(fine tuning)을 수행한다. 16x128x128(프레임x높이x너
비) 크기의 정규화된 영상 에서 jittering을 적용하여 16x112x112(프레임x높이x너비) 영 상을 생성하여 사용한다.
라) 3차원 콘볼루션 신경망을 학습한 뒤, 특징의 추출은 후 fc7 계층의 활성(activation) 값을 사용한다. 시간 에서 사람 에 해당하는 특징은 로 표현한다. 같은 시간상에 나타나 는 모든 사람의 특징에 평균 풀링과 L2-정규화를 하여 최종적인 특징 를 획득한다. 수 식은 다음과 같다.
그림 39. 3차원 콘볼루션 신경망을 이용한 인간 행동의 특징 추출 예
2) 단위행동 추출 및 인식
인간의 단위 행동 추출과 인식은 n개의 연속적인 특징 을 이용하여 m
개의 분할된 영역 과 분할된 영역의 클래스 레이블 을
찾음으로써 수행할 수 있다. 분류 점수는 로 정의하고 분할 가 클래스 레이블 에 속할 우도(likelihood)을 의미한다. 행동의 다양한 시간적 길이를 다루는 분류기를 학습하기 위해 고려하는 분할의 시간 범위는 이고 은 32프레임, 는 128프레임으로 지정한다. 총 4개의 분류기를 32, 64, 96, 그리고 128프레임 단위로 학 습한다. 분할 단위 가 16프레임이기 때문에 2, 4, 6, 그리고 8개의 단위로 분류 점 수를 계산한다. 분류기의 학습과 분류 점수의 계산은 다중 클래스 Support Vector Machine(SVM)을 이용한다. 시간 분할 및 인식을 위해 설정한 목적함수는 다음과 같다.
목적함수의 값을 최대화 한다면 최적의 시간 분할 및 인식을 수행할 수 있다. 연속적인 입력을 다루기 위해 하위 문제로 나눈 목적함수를 구성하여 순차적으로 단위 행동 추출 과 인식을 할 수 있게 하였다. 시간위치 에서 특징 이 주어졌을 때, 하위 문제로 분할된 목적함수 는 다음과 같다.
식 (2)에서 는 으로 정의되며, 시간위치 와 시간범위 에서 특징의 최적의 분류 점수를 얻기 위해 사용한다.
그림 40. 단위행동 추출 및 인식을 위한 전체 흐름도
3) 평가 방법
KU 데이터셋은 단위행동 추출 및 인식 모듈의 성능평가를 위해 사용된다.
KU 데이터셋에서 추출 및 인식할 대상 행동의 종류는 5개의 단위행동 클래스(Null, Walk, Quarrel, Violence, Drag)로 구성되어 있다.
평가방법: KU Dataset에 대하여 행동의 인식과 발생한 시간적 영역을 찾아 Ground truth와 비교하여 성능 측정
인식률 측정 방법: Grounth truth와 일치하는 단위행동 추출 및 인식 결과의 비율
단위 행동 추출 및 인식의 정밀도(Precision)와 재현율(Recall) 측정
4) 평가 결과
단위행동 추출 및 인식 방법: 평균 정밀도 81% 달성 / 평균 재현율 72% 달성
그림 41. KU dataset에서의 단위행동 추출 및 인식의 정밀도(P)와 재현율(R)
그림 42. KU dataset에서의 단위행동 추출 및 인식 결과 confusion matrix
1) 장면 정보 추출을 위한 궤적 기반 공간 분할 기술
가) 사람 객체의 궤적 정보로부터 장면 정보를 추출하는 프레임워크를 제안한다. 제안한 프레 임워크는 궤적들의 유사도를 기반으로 비디오 장면을 작은 영역들로 분할하는 과정과 분 할된 영역들을 이용하여 궤적들로부터 행동 구조 모델을 학습하는 과정으로 구성된다. 행
동 구조 모델은 행상 행동 궤적들을 이용하여 학습되며, 이를 이용하여 각 궤적에 대해 테 스트를 수행하여, 정상 행동과 차이가 큰 궤적들을 이상 행동으로 판단 할 수 있다.
그림 43. 이상 행동 판단을 위한 구조도
2. 궤적 정보를 이용한 비디오 장면 분할
가. 장면 내의 각 픽셀에 대하여 궤적이 지나가는 횟수의 누적 값을 계산한다. 픽셀의 누적 값 을 이용하여, 전체 픽셀들에 대해 장면 분할을 위한 Spectral clustering을 수행한다. 각각의 픽셀들은 이 과정에서 하나의 그래프 노드로 표현되며, 누적 값의 유사도, 즉 장면 내에서 해당 장소의 중요도를 이용하여 픽셀들을 군집화 하게 된다. Spectral clustering 수행 후에 는 미리 정의된 k 개의 군집 숫자만큼 비디오의 영역이 분할된다. 분할된 영역들을 이용하 여 궤적들이 영역들을 지나갈 때 발생 하는 영역 간의 전이 확률을 계산 할 수 있다.
그림 44. 영역 간 전이 활률 계산 모델
나. 장면 분할 기반의 정상 행동 모델링 및 정상/비정상 궤적 인식
1) 본 과정에서는 분할 영역과 전이 확률을 이용하여, 정상 행동을 모델링 하고, 그에 따른 정상 행동 표현들을 대표할 수 있는 정상 행동 쿼리를 생성한다. 먼저, 각 궤적들을 궤적 시퀀스로 변환한다. 앞선 단계에서 도출한 분할 영역들에서 주어진 궤적이 개의 분할 영역을 통과한다면, 궤적 시퀀스는 다음과 같이 표현 가능하다, =< >. 전체 궤적 시퀀스에 대하여 행동 시퀀스들을 유사도 기준으로 군집화하고, 앞서 계산된 전이 확률을 이용하여, 정상 행동에 대한 쿼리들을 생성한다. 최종적으로 대상 궤적의 시퀀스 와 각 쿼리에서 학습된 시퀀스 사이의 유사도를 동적-프로그래밍 기반 기법으로 계산함 으로써, 현재 장면에서 발생한 행동이 정상 행동인지 아닌지를 확률적으로 판단할 수 있 다.
그림 45. 정상 행동 판단 계산 모델
2) 장면 정보 추출을 위한 궤적 기반 공간 분할 기술
MIT Parking Lot Trajectory Dataset은 단일 고정 카메라 환경에서 궤적 정보를 기반한 알고리즘을 평가하기 위해 사용된다.
본 데이터셋은 총 40,000개의 궤적으로 구성되어 있으며, 600,000 만개의 시-공간 픽셀 들로 구성되어 있다.
비정상 행동을 대상으로는 Groundtruth가 존재하지 않음으로, 별도로 Groundtruth를 작 성하여 테스트를 수행하였다.
Groundtruth 작성 시, 장면 상에서 탐지 실패나 잘못된 이동 경로에 의하여 생성된 궤 적들을 비정상적인 궤적이라고 정의하였다.
3) 평가방법
MIT Parking Lot Trajectory Dataset에 대하여, 분할 영역 수에 따른 정상 궤적 인식 성 능을 측정
전체 입력 궤적 중 대한 정상/비정상 궤적 인식 정확도
Precision과 Recall의 비율을 고려한 테스트 정확도, F1 score, 계산
4) 평가결과
클러스터 수에 대한 최적 성능 구간에서 인식 정확도 88.28% 달성
F1 score를 계산 하였을때, 테스트 정확도 92.4% 달성
그림 46. 클러스터 수의 변화에 따른 Precision, Recall, Accuracy 측정 결과
Ⅰ-5 객체 흐름 분석을 통한 비정상/의심 상황 예측 기술 (1.3 세부)
1. 계획 수립 및 자료조사
가. 기존 기술 동향 조사 (논문, 기업)
1) 논문 동향 : 국제 저널 및 학회 (CVPR, ICCV, ICPR, AVSS 등) 2) 기업 동향 : 국내외 기업 (S1, 삼성 SDS, 한화 테크윈 등)
2. 검증을 위한 데이터 셋 수집
가. 테스트 데이터 셋 내용 및 수준 (검증 활동)
1) 테스트 데이터 셋 내용 : MIT CrossRoad, QMUL CrossRoad, WI(자체제작)
2) 테스트 데이터 셋 수준 : 다양한 형태의 사거리 영상, 2차선- 8차선의 실제 교통상황 영 상
3. 자연어 처리 모델 조사 및 분석
가. Latent Dirichlet Allocation 모델 구조 분석 및 C++ 라이브러리화 1) David Blei 등 선진 연구자들의 연구 동향 분석
그림 47. Latent Dirichlet Allocation mode
나. 시각 정보에 적합한 자연어 처리 모델 수정
1) 자연어 처리 모델로 분류한 주제들이 실제 거리 영상의 교통흐름을 반영하는지 정성적 확인하였다. 사거리 영상에서는 직진, 좌회전, 우회전 등의 여러 교통 흐름이 존재하는데 이러한 여러 흐름을 비교사적인 방법을 이용하여 자동으로 구현해 내는데 성공하였다. 각 각의 군집된 패턴들은 교통 흐름 내의 대표적인 움직임 흐름과 일치하였고, 아래 그림은 그 예시를 보이고 있다.
그림 48. QMUL 영상에 대해 분류한 각 주제들
그림 49 . 시간 대 별로 분류된 주제 결과
2) 이러한 학습된 주제들을 발생한 시간대에 맞추어 그룹을 만들 수 있다. 이는 상위 이상행 동(신호 위반) 등을 찾는 데 필요하며, 미래 위치 예측에는 필수적이다. 2차년도 연구에서 는 해당 기능을 추가한 알고리즘을 추가 개발, 각각의 주제들을 등장 시간 별로 분류하였 다. 이러한 주제 분류 결과를 바탕으로 영상 내 물체의 미래 위치를 예측할 수 있었으며 그림 47에서 정성적인 결과를 확인할 수 있다.
3) 연구결과 완성도 (목표 달성 및 질적 수준)
교통상황 테스트 데이터 셋 (4/4)에서 분류된 주제들이 교통흐름과 일치함 확인하였다.
상용되는 QMUL1, QMUL2, MIT 데이터셋과 직접 촬영한 WI 데이터셋을 통해 학습된 패 턴들이 교통상황 내의 주도적인 흐름을 반영하는 것을 확인하였다.
정량평가를 위한 주제별 궤적 clustering 성능 테스트에서는 97.8% 달성, 학습된 패턴들 이 물체 내 움직임들을 분류하는데 유의미한 척도가 될 수 있음을 확인하였다.
그룹 평가를 위하여 QMUL1, 자체 제작한 WI 데이터 셋을 사용, 정성적인 결과(그림 8) 를 확인하였다.
다. 상황 예측 및 이상행동 탐지 알고리즘 개발
1) 확장된 자연어 처리 모델을 응용한 상황 예측 알고리즘 개발
당해 년도 새로 제안된 모델을 바탕으로 미래 위치 예측 기술을 개발하였다.
그림 50. 미래 위치 예측 정성 결과
2) 연구결과 완성도 (목표달성 및 질적 수준)
비교 실험 결과를 이용, 주제 학습 정확도와 예측 정확도 모두 2년차 기준치를 상회하 여 달성하였음을 보였다.
다른 Baseline 알고리즘 학습 결과 뿐 아니라 사람이 직접 예측한 결과보다도 평균 error가 적음을 확인할 수 있다.
주제 학습 정확도는 clustering 정확도(%), 예측 경로는 ground truth와의 Modified Hausdorff Distance, Euclidean Distance로 측정하였다.
그림 51. 정량 평가 결과
라. 이상행동 탐지 알고리즘 개발