A Strategy Study on Sensitive Information Filtering for Personal Information Protect in Big Data Analyze
1)
전체 글
1)
수치
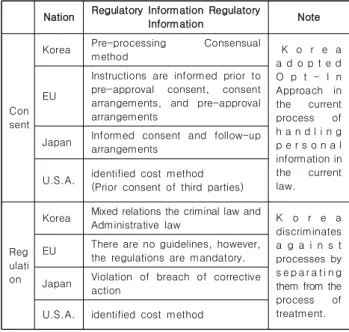

관련 문서
processes and tools required to transform enterprise data into information, information into knowledge that can be used to enhance decision-making and to create actionable
• Connect to information (products: information server; data pub-lisher). • Understand information (data architect,
∙ Always turn off the power supply and unplug the power cord from the power outlet before installing or removing any computer component.. ∙ Keep this user guide
4. In order to facilitate resolution of the issues raised, take appropriate steps to protect sensitive business and other information and the interests of other
sensitive files (DLP alert) Unusual logon access Ransomware Activity.
협업 필터링(collaborative filtering)은 많은 사용자들 로부터 얻은 기호정보(taste information)에 따라 사용자들의 관심사들을 자동적으로 예측하게
⚫ User-level tools cannot monitor kernel level performance issues.. Performance
Manipulation of protein’s amino acid sequence to change its function or properties.