http://dx.doi.org/10.5391/JKIIS.2015.25.2.191
PCA를 활용한 기업실적 예측변수 생성
Generating Firm's Performance Indicators by Applying PCA
이준혁*·김갑조*·박상성**·장동식*
†Joonhyuck Lee*, Gabjo Kim*, Sangsung Park**, and Dongsik Jang*
†*고려대학교 산업경영공학과, **고려대학교 지식재산학과
*Department of Industrial Management Engineering, Korea University
**Department of Intellectual Property, Korea University
이 논문은 BK21 플러스 사업(고려대학교, 제 조·물류분야에서의 빅데이터 운용 사업팀)으로 지원된 연구임.
이 논문은 2012년 정부(교육과학기술부)의 재원 으로 한국연구재단의 지원을 받아 수행된 연구 임.(한국연구재단-NRF-2010-0024163) This is an Open-Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://
creativecommons.org/licenses/by-nc/3.0) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
요 약
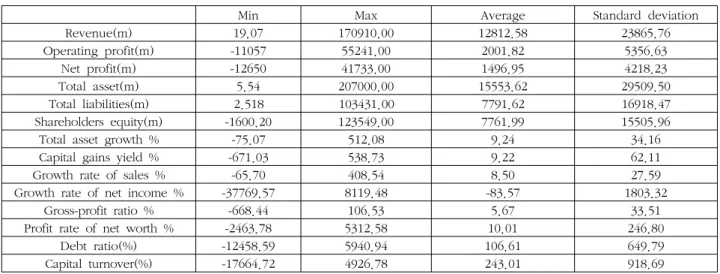
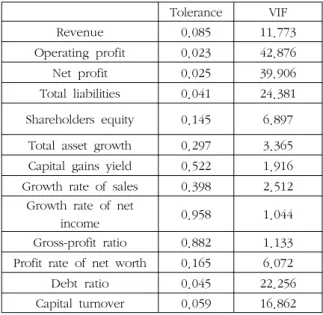
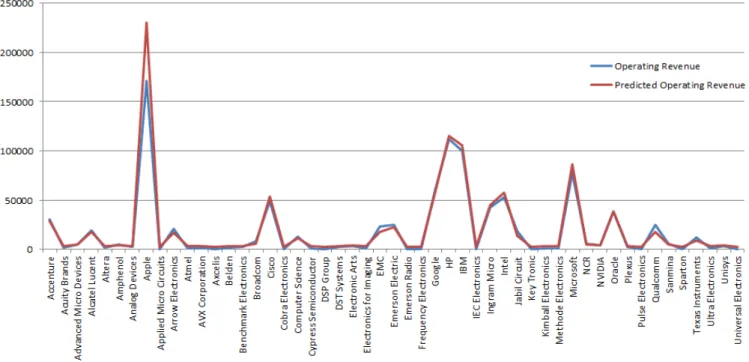
최근 기업의 실적 및 주가를 예측하기 위해 매출액증가율, 부채비율 등의 다양한 예측변수를 활용하여 정량적 인 예측방법을 활용하는 연구가 많이 이루어지고 있다. 기업실적 및 주가를 정량적 예측하기 위해 수많은 예측 변수들 중에서 모델구축을 위해 중요한 예측변수를 선정하는 것이 중요하다. 대부분의 기존연구들에서는 다양 한 알고리즘을 활용하여 예측변수들을 제거하는 방법을 사용하는 경우가 많았다. 이러한 경우 각 예측변수들이 가지는 많은 정보들이 제거되는 문제점이 존재한다. 이러한 문제점을 해결하기 위해 본 연구에서는 예측모델 구축을 위해 예측변수들을 제거하는 대신 각 변수들이 가지고 있는 정보를 병합하여 새로운 변수를 생성하는 대표적인 차원축소 방법인 주성분분석(PCA)을 활용하였다. 본 연구에서는 제안된 예측모델을 미국의 전자, 전 기기업의 재무정보를 활용하여 구축하고 예측성능을 실증적으로 분석해 보았다.
키워드 : 유전알고리즘, 인공신경망, 주성분분석, 실적예측, 예측모델
Abstract
There have been many studies on statistical forecasting on firm's performance and stock price by applying vari- ous financial indicators such as debt ratio and sales growth rate. Selecting predictors for constructing a prediction model among the various financial indicators is very important for precise prediction. Most of the previous stud- ies applied variable selection algorithms for selecting predictors. However, the variable selection algorithm is con- sidered to be at risk of eliminating certain amount of information from the indicators that were excluded from model construction. Therefore, we propose a firm's performance prediction model which principal component analysis is applied instead of the variable selection algorithm, in order to reduce dimensionality of input variables of the prediction model. In this study, we constructed the proposed prediction model by using financial data of American IT companies to empirically analyze prediction performance of the model.
Key Words : Genetic Algorithm, Artificial Neural Network, Principal Component Analysis, Performance Prediction, Prediction Model.
Received: Sep. 14, 2014 Revised : Sep. 28, 2014 Accepted: Jan. 5, 2015
†Corresponding author([email protected])