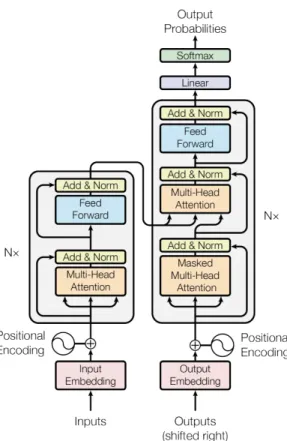
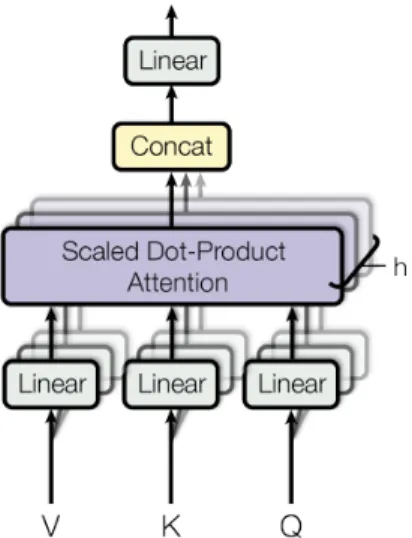
1. 서 론
언어모델의 연구는 언어학자가 정의한 규칙을 근거로 한 문법 기반 언어모델과 언어의 사용성에 대한 통계를 기반으로 한 통 계적 언어모델로 구성된다. 문법 기반 언어모델은 형태소분석, 구분분석 등을 위한 문법을 개발하는 것이고 통계적 기반 언어모 델은 매 단어의 사용성에 대한 통계를 구하고 그것을 bigram, trigram 등으로 구성되는 n-gram으로 표현하는 것이다. 최근에 신 경망 기술의 발달로 인해 신경망을 이용해서 언어모델을 구현하는 방식이 다양하게 제안되고 있다. 신경망을 활용한 언어모델 방식은 전통적인 feed forwad 신경망을 이용한 언어모델, LSTM(Long Short-Term Memory) 기반의 언어모델이 사용되고 있
다
[1,2]. 특히 전통적인 통계기반 언어모델
[3]과 신경망 기반의 언어모델의 비교 연구가 수행되었으며 LSTM 기반의 언어모델의
우수함이 증명되었다
[4].
Research Article, pISSN : 2287-8920
https://doi.org/10.22716/sckt.2020.8.4.033
Attention에 기반한 한국어 언어모델 연구
이선정
11국립인천대학교 컴퓨터공학부 교수
A Study on Korean Language Model Based on Attention
Sunjeong Lee
11Professor, Incheon National University
1