2018년 12월 보 고 서 번 호
전체부수
자율성장형 AI 핵심원천기술 연구
Core Technology Research for Self-Improving Artificial
Intelligence System
연차실적 보고서
과제유형 1. 기초미래선도형 ( ) 2. 공공인프라형 ( O ) 3. 산업화형 ( ) 대과제명 SW·콘텐츠 기초·원천기술 개발 세부과제명 자율성장형 AI 핵심원천기술 연구 세부과제 책임자 소속 및 부서 지능정보연구본부 음성지능연구그룹 직위 (직급) 책임연구원 성명 이윤근 총연구기간 2018년 1월 1일 부터 2025년 12월 31일 까지 ( 108 개월) 당해연도 연구기간 2018년 1월 1일 부터 2017년 12월 31일 까지 ( 12 개월) ( 1차년도) 총 연 구 비 정부출연금 58,776,000 천원 당 해 년 연 구 비 정부출연금 7,347,000 천원 민간부담금 천원 민간부담금 천원 계 58,776,000 천원 계 7,347,000 천원 참여인력(M/Y) 총 연 구 기 간 324 명 ( 171.97 M/Y) 당해연도 연구기간 43 명 ( 25 M/Y) 참여기관 기관명 연구책임자 기관명 연구책임자 참여연구기관 위탁연구기관 경북대학교 이민호 고려대학교 이종환 대전대학교 배창석 연세대학교 조성배 상명대학교 황민철 충북대학교 권오욱 키워드 (6~10 개) 자율성장형 AI, 복합모달 의미이해, 뉴럴 기억모델, 인터랙티브 성장, 사용자 감정인지, 행위인식, conversational AI, 딥러닝, 강화학습 정부출연금사업 연차평가 보고서를 제출합니다. 2018년 12월 일 세부과제책임자 : 이윤근 (인) 직 할 부 서 장 : 한동원 (인)한국전자통신연구원장 귀하
제 출 문
본 연구보고서는 주요사업인 "자율성장형 AI 핵심원천기술 연구
"의 결과로서, 본 과제에 참여한 아래의 연구팀이 작성한 것입니다.
2018년 12월
연구책임자 : 책임연구원 이윤근 (음성지능연구그룹)
연구참여자 : 책임연구원 정호영 (음성지능연구그룹)
책임연구원 송화전 (음성지능연구그룹)
책임연구원 정의석 (음성지능연구그룹)
선임연구원 김현우 (음성지능연구그룹)
책임연구원 박기영 (음성지능연구그룹)
책임연구원 박전규 (음성지능연구그룹)
책임기술원 강점자 (음성지능연구그룹)
책임연구원 강병옥 (음성지능연구그룹)
선임연구원 정 훈 (음성지능연구그룹)
선임연구원 오유리 (음성지능연구그룹)
선임연구원 이윤경 (음성지능연구그룹)
책임연구원 강동오 (스마트데이터연구그룹)
책임연구원 정준영 (스마트데이터연구그룹)
책임연구원 백의현 (스마트데이터연구그룹)
책임연구원 김기호 (스마트데이터연구그룹)
책임연구원 원종호 (스마트데이터연구그룹)
책임연구원 이전우 (시각지능연구그룹)
선임연구원 오성찬 (시각지능연구그룹)
책임연구원 박종렬 (시각지능연구그룹)
책임연구원 정영식 (시각지능연구그룹)
연 수 생 정재원 (시각지능연구그룹)
책임연구원 정현태 (SW 콘텐츠원천연구그룹)
책임연구원 김가규 (SW 콘텐츠원천연구그룹)
선임연구원 노경주 (SW 콘텐츠원천연구그룹)
연 구 원 정승은 (SW 콘텐츠원천연구그룹)
선임연구원 임지연 (SW 콘텐츠원천연구그룹)
책임연구원 신형철 (SW 콘텐츠원천연구그룹)
책임연구원 정희범 (SW 콘텐츠원천연구그룹)
책임연구원 김상훈 (음성지능연구그룹)
책임연구원 이영직 (음성지능연구그룹)
책임연구원 박 준 (음성지능연구그룹)
책임연구원 김승희 (음성지능연구그룹)
선임연구원 윤 승 (음성지능연구그룹)
연 구 원 김여정 (음성지능연구그룹)
선임연구원 최무열 (음성지능연구그룹)
연 수 생 이담허 (음성지능연구그룹)
책임연구원 김영길 (언어지능연구그룹)
책임연구원 최승권 (언어지능연구그룹)
책임연구원 김창현 (언어지능연구그룹)
책임연구원 권오욱 (언어지능연구그룹)
책임연구원 이기영 (언어지능연구그룹)
선임연구원 노윤형 (언어지능연구그룹)
선임연구원 황금하 (언어지능연구그룹)
요 약 문
Ⅰ. 제 목
자율성장형 AI 핵심원천기술 연구
Ⅱ. 연구목적 및 중요성
본 사업의 인공지능 원천기술 공유를 통해 IDX 추진에 기여하며
인공지능 산업 국제경쟁력을 강화에 기여하는 중요성을 가진다.
인공지능 기술은 4차 산업혁명을 위한 핵심 기술로서 글로벌 선도
기업은 새로운 부가가치를 창출할 수 있는 산업에 인공지능 기술을
빠르게 접목하고 있으며, 중국의 기업들이 발빠르게 이를 추격하고
있는 상태이다. 국내 인공지능의 경쟁력을 높이기 위해서는 초기
개발단계에 있는 자율성장형 인공지능 분야에 대한 핵심기술을
선점하는 것이 매우 중요하다. 인간의 문제해결 지식을 스스로
성장시키며 학습 데이터 자동증강, 소규모 데이터에 효율적인
인공지능 학습 알고리즘 확보 등이 향후 인공지능 경쟁력의 핵심이
될 것이다. 본 사업에서는 복합모달 (영상, 음향, 텍스트, 생체 등)
정보를 모달리티 협력 학습을 통해 휴먼모방형 자율성장 매커니즘과
인간의 감정 및 행위를 인식하는 기술을 결합하여 교감형 자율성장
에이전트 기술을 개발하고자 한다. 또한 실제 사용자의 공간적
제약없이 대화를 통한 자율성장 인공지능 기술을 서비스하기 위해
conversational AI 기술을 접목하는 것을 목표로 하고 있다.
Ⅲ. 연구내용 및 범위
자율성장 인공지능 요소기술 개발
-
텍스트 대상 문장 임베딩 기술
-
언어기반 인터랙션을 위한 질의 응답 기술
-
End-to-end 구조의 뉴럴 기억모델 기반 강화학습 기술
자율성장 인공지능 프로토타입 시스템 개발 (ver 0.5)
-
핵심기술의 검증을 위해 1단계(~2020) 목표로 ‘인터랙션
기반 성장형 패션 코디네이터’ 개발 예정이며, 당해년도는
v0.5를 개발함
영상기반 객체 특성정보 인식기술 개발
경험기반 감정모델링 요소기술 개발
-
생리반응 신호 기반 감정 인식 기술
-
자기참조(self-referential) 음성 특징 기반 감정 인식 기술
-
복합모달 감정 인식기 설계
경험기반 행동 데이터 분석 기술
-
저수준 행동 인식기
-
경험데이터 수집 테스트베드 및 DB 구축
-
핵심기술의 검증을 위해 1단계(~2020) 목표로 ‘수면장애
관련 일상행위 추론 시스템’ 개발 예정이며, 당해년도는
수면장애 검출을 위한 요소기술을 개발함
인지/감성 증강 기술 니즈 분석 및 서비스 조사
2018 평창동계올림픽 공식 8개국 자동통역서비스 성공적 실시
-
공식서비스 실시로 ‘지니톡’ 앱 다운로드 수 대폭
증가하여 총 120만 다운로드 기록
-
올림픽 기간중 20만건/일 사용 (올림픽전 4만건/일), 영어,
일본어, 중국어, 러시아 순으로 많이 활용
올림픽 이후 국내외 주요업체(KT, SKT, 중국 iFlytek) 대상
지니톡 사업화 활발
-
ETRI 연구소기업인 한컴인터프리에서 국내외 주요업체 및
호텔, 공공기관 등 대상 사업화 본격 추진
-
삼성 빅스비 개발자 데이에 지니톡 연동 베타 서비스 시연
(11/20)- 스마트폰, TV에서 시범서비스 추진
국내최초 10개 언어 다국어 음성인식 엔진 확보
-
금년 베트남어 음성인식 기술 개발로 향후 태국어 등
수요가 많은 동남아어 추가 확보에 기반 마련
국내 자동통역 분야 기술 선도 역할
-
Zero UI, on-line Topic LM은 자동통역 breakthrough 기술로
기술적 파급효과가 매우 클 것으로 예상됨
-
LSTM+Chain모델, 단말탑재 통역 기술은 국내최초 사례임
Ⅳ. 연구결과
- 핵심요소 기술 확보
뉴럴 메모리 모델과 강화학습 알고리즘이 상호작용하는
독자적인 뉴럴네트워크 모델
서브워드 임베딩 기반 skip-thought 문장 임베딩 고유 기술
확보
복합모달 정보 기반 인터랙션 응답 생성의 새로운 기술적 시도
절차지식과 언어 인터랙션 지식을 동시에 강화학습하는 고유
기술 확보
세계적 수준의 영상기반 객체 특성정보 인식 성능
복합 정보 인터랙션이 필요한 ‘패션 코디네이션’ 도메인에
대한 프로토타입 개발을 통해 요소기술 검증
개인 특성을 반영한 복합모달 융합 감정 인식 기술
-
HRV 특징 및 자기참조를 반영한 음성 특징 기반 감정
인식기 핵심 기술 확보
-
감정 반응과 행동/상황을 함께 고려한 복합모달 융합 감정
인식기 설계
고수준 행위 인식 기술
-
복합모달 라이프로그 데이터를 실생활 환경에서 장기간
수집 가능한 플랫폼 개발 및 DB 구축
-
저수준 행동과 상황으로부터 고수준 행위 추론 기술 설계
경험상황 모델링 및 추론 기술
-
사용자의 일상 행위 시퀀스/패턴 추론이 가능한 경험상황
모델 설계
- 사업화 실적
한컴인터프리
국제행사에
서버형
韓-8개
언어
자동통역서비스 사업화
韓-3개 언어 OTG 타입 오프라인형
자동통역 사업화 추진
중국 iFlytek과 단말탑재형 통역
12월말 제품 출시 예정
SKT AI 스피커 ‘NUGU’에 한중영일
통역기 탑재 계약 체결
인천 파라다이스 호텔 통역서비스
사업화 PoC 추진중
인천공항, 광주 박물관 등 공공기관
대상 통역로봇 사업화
KT
KT AI 스피커 ‘기가지니’에 지니톡
통역 기술 탑재
기가지니
기반
지니톡
영어
교육서비스 상용화 (핑크퐁)
호텔용 기가지니 영중일 서비스 제공
(을지로 노보텔)
Ⅴ. 연구개발결과의 활용계획
자율성장 인공지능 기술은 스스로 학습/성장하며 판단/예측이
가능한 차세대 핵심기술로써, 기존 언어처리, 시각처리, 음성
처리 기술의 한계를 극복하는 차세대 기반기술로 활용함
다양한 딥러닝 기반 인공지능 응용분야에 활용 가능한 공통 뉴
럴컴퓨팅 요소기술 및 휴먼지능처리 공통핵심기술을 국내산업
체에 제공하여 산업계 IDX 추진에 기여함
지능형 서비스의 경쟁력을 높일 수 있는 conversational AI 기
술을 산업체에 제공하여 대화형 지능형 신규 서비스 개발에 기
여함
Ⅵ. 기대성과 및 건의
자율성장형 인공지능 개발을 위한 핵심요소기술 개발을 통해
원천기술 확보와 다양한 지능형 에이전트 서비스 개발에 기여할
수 있을 것으로 기대됨
<별지 7>
목 차
제 1 장 서론 ... 21
제 1 절 연구목표 및 연구범위 ... 21
제 2 절 연구개발의 중요성 ... 23
제 2 장 본론 ... 25
제 1 절 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5 개발 ... 25
1. 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5 ... 26
2. 실증 서비스용 주요 개발 요소 ... 27
3. 실증 서비스용 프로토타입 시스템 v0.5 코디셋 결과 사례 ... 36
4. 실증 서비스용 프로토타입 시스템 v0.5 – Legacy 모드 결과 사례 ... 39
제 2 절 대화생성 모듈 ... 40
1. 문장임베딩 ... 40
가. 용어 정리 ... 40 나. 문장임베딩 연산과정 ... 41 다. 문장임베딩 학습 모델 ... 44 라. Evaluation ... 452. Language Interaction Encoder-Decoder 기술 ... 47
가. 언어 인터랙션 인코더 디코더 모델... 47
3. 의상코디 Language Interaction 및 코디지식 데이터셋 구축 ... 50
제 3 절 패션 코디네이션 지식 생성 모듈 ... 55
1. 인공지능 패션 코디네이터 설계 및 구현 ... 55
가. 개요 ... 55 나. 인공지능 패션 코디네이터 ... 55 다. 패션 코디네이션 지식 생성부 ... 56 라. AI 패션 코디네이션 지식 DB 구축... 65제 4 절 복합모달 지식베이스 구축 요소기술 개발 ... 71
1. 복합모달 데이터 지식구조 설계 ... 71
가. 복합모달 데이터 분류 ... 71 나. 복합모달 데이터 지식 구조 ... 732. 복합모달 기억모델 지식베이스 구축 기술 개발 ... 75
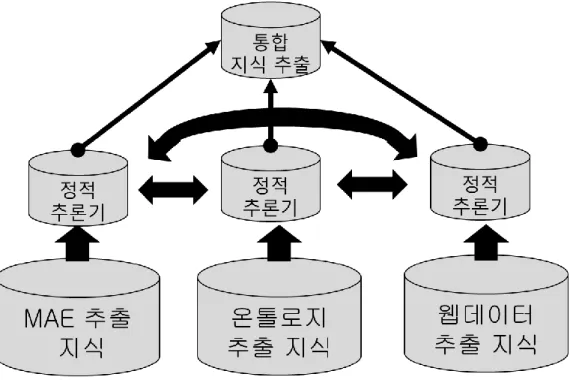
가. 정적 예측추론 기반 지식성장 엔진 설계 ... 75 나. 멀티모달 복합정보 복합 정보 추론 예측 기술 설계 ... 78 다. 복합 정보 장기지식기억모듈(지식베이스) 설계 ... 84 라. 텍스트 기반 지식 추출 기술 설계... 87 마. 패션 관련 지식 추출을 위한 학습 데이터 구성 ... 89 바. 영상 기반 지식 추출 기술 개발 ... 91제 5 절 휴먼이해 에이전트 기술 연구 ... 113
1. 생리반응/음성 신호 기반 감정 인식 기술 연구 ... 113
가. 생리반응 신호 기반 감정 인식 기술 ... 113 나. 음성 기반 감정 인식 기술 ... 129 다. 실생활 환경 동적 감성에 의한 생리반응 모델 연구 ... 1382. 복합정보 기반 행동/경험 인식 기술 연구... 146
가. 저수준 행동 인식 기술 ... 146 나. 복합모달 기반 행동/상황 인식 기술 ... 152 다. 경험데이터 수집을 위한 라이프로깅 테스트베드 구축 ... 1553. 사용자의 경험상황 모델링 기술 연구 ... 160
가. 일상행위 시퀀스 및 행위패턴 추론 기술 ... 160 나. 사용자 경험상황 시맨틱 네트워크 기반 패턴 분석 기술 ... 1724. 복합모달 감정 인식기 설계 ... 176
가. 입출력 특징 ... 177 나. 기능 블록 ... 1785. 인지/감성 증강 서비스 조사 연구 ... 181
가. 국내외 R&D 정책 및 기술개발 사례 분석 ... 181나. FGI(Focus Group Interview) 수행을 통한 니즈 조사 ... 185
다. 유망서비스 도출 ... 187
제 6 절 Conversational AI 기술 연구 ... 195
1. 평창동계올림픽 영역특화 통역엔진 개발 ... 195
가. 다국어 음성인식 영역 특화 ... 195 나. 8 개 언어 대상 자동통역 사용성 평가 ... 196 다. 올림픽 대회기간 동안 자동통역서비스 문제 대응 및 홍보 ... 1982. Zero UI 자동통역 핵심기술 개발 ... 200
가. Conversational 음성인식을 위한 topic 기반 언어모델링 기술 개 발 ... 200 나. Conversational Speech 발음현상 분석 및 발음생성 기술 개발 204제 3 장 연구개발결과의 활용 계획 ... 223
제 4 장 결론 ... 226
표목차
표 1. 서브워드 임베딩과 어절기반 포지션 인코딩을 이용한 문장 임베딩 연산 ... 42 표 2. 서브워드 임베딩 테이블 ... 43 표 3. 평가 결과 ... 46 표 4. 적용 기술에 따른 성능 개선 결과 ... 49 표 5. 패션 아이템의 항목 ... 58 표 6. 패션 아이템 특징의 예시 ... 58 표 7. 패션 아이템의 종류별 개수 ... 66 표 8. 감성특징의 분류체계 ... 69 표 9. 복합모달 데이터 분류 ... 72 표 10. 다계층 지식 표현 구조 ... 73 표 11. 복합모달 데이터 분류 ... 75 표 12. DeepFashion 아이템 연관 지식 추론 테스트 결과 ... 82 표 13. 비교 논문 목록 ... 101 표 14. 의복 분류 정확도 비교 ... 102 표 15. 속성 분류 성능 비교(top-3) ... 102 표 16. 속성 분류 성능 비교(top-5) ... 103 표 17. Predicate prediction 실험 결과 ... 111 표 18. Phrase detection 실험 결과 ... 112 표 19. Relationship detection 실험 결과... 112 표 20. 공간벡터 성능 검증실험 결과 ... 113표 21. 생리반응 기반 감정인식 기술 비교... 115 표 22. 4 분위 감정영역별 감정 분류 정확도... 128 표 23. 행동 데이터 수집 실험 프로토콜 ... 148 표 24. 대표적인 수면 설문 ... 162 표 25. 수면이상 관련 정성적 특징 정의 ... 164 표 26. 수면이상 관련 정량 특징 정의 ... 164 표 27. 대표적인 불면증 분류 - ICSD-2, ICD-10-CM, DSM-5 ... 167 표 28. 행위 시퀀스 결과 예시 ... 172 표 29. 입력 모달의 특징 및 복합모달 감정 인식기 결과 정의 ... 178 표 30. 영역특화 단어 DB 구축 예 ... 196 표 31. 영역특화 문장 DB 구축 예 ... 196 표 32. 통역사용 현황 ... 197 표 33. 사용 데이터 특징 ... 204 표 34. 영어 음성인식 성능 ... 207 표 35. 중국어 음성인식 성능 ... 207 표 36. 사용된 데이터 정보 ... 209 표 37. 데이터 및 파라미터별 최종 성능 ... 210 표 38. 영어 음성인식 성능 ... 213 표 39. 일본어 음성인식 성능 ... 213 표 40. 중국어 음성인식 성능 ... 213 표 41. Zero UI 사용성 평가... 219 표 42. 베트남어 인식 성능 ... 222
그림목차
그림 1. 자율성장형 인공지능 시스템 개념도... 22 그림 2. 휴먼 지식 습득 과정을 모방하는 자율성장 매커니즘 ... 23그림 3. 자율성장형 인공지능 구성도 ... 24 그림 4. 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5 구조도 ... 26 그림 5. 자율성장형 패션 코디네이터 프로토타입 시스템 구조도 ... 27 그림 6. 메시징 서버 화면 및 접속 일례 ... 28 그림 7. 사용자용 메신저 화면 및 일례 ... 29 그림 8. 코디용 메신저 화면 및 일례 ... 29 그림 9. 패션 태깅 에디터 화면 및 일례 ... 30 그림 10. 메타 데이터 에디터 화면 및 일례... 30 그림 11. 패션 코디셋 에디터 화면 및 일례... 31 그림 12. 패션 코디 검색기 화면 및 일례 ... 31 그림 13. 패션 아이템 박스 에디터 화면 및 일례 ... 32 그림 14. 실증 서비스 Baseline 0.5 – DB 수집용 구성 ... 33 그림 15. 메신저 포함 AI 코디네이터 화면 일례 ... 34 그림 16. 실증 서비스 Baseline 0.5 – 시연용 구성 ... 35 그림 17. 실증 서비스 Baseline 0.5 – 다중 코디/사용자 시연용 실제 화면 . 36 그림 18. 첫번째 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 ... 37 그림 19. 마지막 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 ... 37 그림 20. 첫번째 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 ... 38 그림 21. 마지막 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 ... 38 그림 22. Legacy 시스템의 결혼식 관련 코디셋 검색 결과 ... 39 그림 23. 패션 아이템의 메타데이터 샘플... 42 그림 24. 서브워드 임베딩과 스킵서트 문장임베딩 통합 모델 ... 44 그림 25. 언어 인터랙션 예제 ... 47 그림 26. 언어 인터랙션 Enc-Dec 아키텍쳐... 48 그림 27. 대화셋 샘플 ... 54 그림 28. 인공지능 패션 코디네이터의 구성도 ... 56
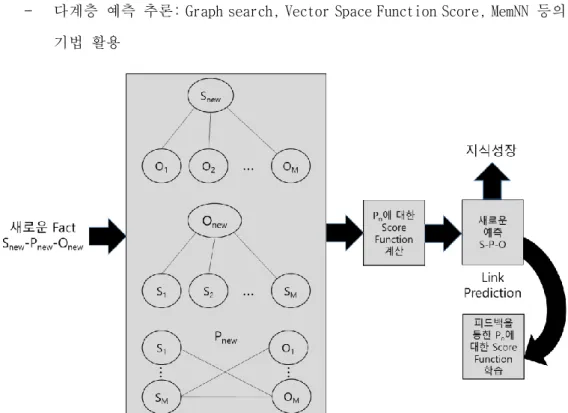
그림 29. 패션 코디네이션 지식 생성부의 구성도 ... 57 그림 30. 패션 아이템의 예시 ... 58 그림 31. 패션 코디네이션 지식 성장의 구성도 ... 63 그림 32. 500 셋의 인터랙션에 대한 성능 ... 65 그림 33. 2000 셋의 인터랙션에 대한 성능... 65 그림 34. 복수의 아이템을 선택하는 인터랙션에 대한 성능 ... 65 그림 35. 패션 아이템의 메타데이터 ... 67 그림 36. 패션 아이템의 종류(가디건)의 하위 항목들 예시 ... 68 그림 37. 패션 코디네이션의 예시 ... 70 그림 38. 정적 추론 예측을 통한 지식 성장 개념도 ... 76
그림 39. Key-Value Memory Network 를 이용한 지식베이스 QA 개념도 ... 77
그림 40. 멀티모달 관계 데이터의 임베딩을 통한 Link Prediction ... 78 그림 41. 단계적 정적 추론 기반 지식 추출... 79 그림 42. 병렬 정적 융합 추론의 개념도 ... 80 그림 43. 연관 지식 추론 API 개념도 ... 81 그림 44. 웹기반의 추론 결과 도식화 도구... 81 그림 45. DeepFashion 아이템 연관 지식 추론 테스트 결과 json ... 83 그림 46. 추론을 통한 패션 관련 멀티모달 지식 탐색 테스트 ... 84 그림 47. 기존의 장기지식 저장 모듈 설계안... 85 그림 48. 다수준 지식 멀티모달 데이터의 지식베이스 입력 ... 85 그림 49. MAE 를 위한 DataSource 스키마 설계 ... 86 그림 50. 지식 계층 통합 탐색, 예측 및 추론 기능 ... 86 그림 51. 텍스트 기반 지식 추출 블록도 ... 87
그림 52. Relation Detection Result ... 89
그림 53. MAE 의 제목에 대한 DeepFashion 아이템 키워드 매칭 결과 ... 90
그림 55. 영상기반 시각 속성정보 인식의 개요 ... 91 그림 56. 영상기반 시각 속성 인식 시스템... 92 그림 57. 기저 특징 추출 네트워크 ... 94 그림 58. 재귀적 특징 정제 네트워크 ... 95 그림 59. 특징정제 모듈 ... 96 그림 60. 특징 정제 과정 ... 97 그림 61. 시각주의의 예 ... 98 그림 62. 시각주의 기반 분류 네트워크 및 attention map ... 100 그림 63. 상의에 대한 의복 분류 및 속성 인식 결과 ... 105 그림 64. 하의에 대한 의복 분류 및 속성 인식 결과 ... 106 그림 65. 전신의복에 대한 의복 분류 및 속성 인식 결과 ... 107
그림 66. Visual Relationship Detection 모델 구조 ... 108
그림 67. Predicate predication, Phrase detection 및 Relationship detection ... 110
그림 68. Russell 모델 기반 목표 감정 정의 및 감정별 영상자극 ... 116 그림 69. 감정유발 자극에 의한 생리반응 신호 측정 실험 흐름도 ... 120 그림 70. 생리반응 신호 수집 실험 환경 ... 120 그림 71. 생리반응 특징 기반 감정인식기 구현 과정 ... 121 그림 72. RR 간격에서 NN 간격 추출 ... 122 그림 73. 생리반응 특징 기반 감정인식기 구조 ... 126 그림 74. 스크립트 평가자 오답 결과 ... 133 그림 75. 2-D A/V 감정모델기반 감정레이블 학습... 135
그림 76. 2-D A/V 모델 기반 SER ensemble 모델 ... 136
그림 77. (좌) 안드로이드 기반 심혈관 반응 측정 시스템 (우) PPG 신호 저 장 형식 ... 138
그림 78. 안드로이드 기반 주관 감성 평가 시스템 ... 139
그림 80. 쾌-불쾌 자극에 대한 카이제곱 검정 결과 ... 142 그림 81. 각성-이완 자극에 대한 카이제곱 검정 결과 ... 143 그림 82. 움직임 노이즈 알고리즘 흐름도 ... 143 그림 83. 움직임 노이즈 제거 결과 ... 144 그림 84. 기존 구축 라이프로깅 테스트베드... 148 그림 85. LSTM 네트워크 적용 저수준 행동 인식기 구조 ... 149 그림 86. 사용자의 행동 및 생리반응 신호 수집용 모바일 디바이스 앱 . 156 그림 87. 라이프로깅 테스트베드 구축 ... 157 그림 88. 경험상황 모델링 개념도 ... 161 그림 89. 클러스터 개수에 따른 DB-index 값 ... 165 그림 90. 클러스터별 수면효율성 box-plot ... 166 그림 91. 클러스터별 수면 중 각성횟수 box-plot ... 166 그림 92. 클러스터별 수면 중 각성시간 box-plot ... 166 그림 93. 클러스터별 실제 수면시간 box-plot ... 166 그림 94. 특징벡터별 특징들의 PCA coefficient 그래프 ... 170 그림 95. 사용자 경험상황 모델링을 위한 네트워크 구축 ... 172 그림 96. 사용자 경험상황 시맨틱 네트워크 구축을 위한 API 구조도 .... 174 그림 97. 시계열 모델링 그래프 데이터베이스 구조 ... 174 그림 98. 복합모달 감정인식기 구조 ... 177 그림 99. 생리신호 기반 복합모달리티(특징혼합) 감정인식기 ... 179 그림 100. 음성신호 기반 감정 인식기 ... 179 그림 101. 결정혼합 기능 블럭도 ... 180 그림 102. 2-D A/V 모델 기반 감정 레이블 매핑 ... 180 그림 103. FGI 수행을 통한 유망 서비스 도출 프로세스 ... 186 그림 104. FGI 수행과정 ... 187 그림 105. 후보 서비스 도출 ... 188
그림 106. 10 대 유망서비스 ... 189 그림 107. 치매예방과 예측의 서비스 구성 시나리오 ... 189 그림 108. AI 사회복지사의 서비스 구성 시나리오 ... 190 그림 109. 마음을 나누는 대화친구 서비스 구성 시나리오 ... 190 그림 110. 우울증 벗어나기 서비스 구성 시나리오 ... 191 그림 111. 불면증 개선과 숙면유도 서비스 구성 시나리오 ... 191 그림 112. 스타일링 어시턴트 서비스 구성 시나리오 ... 192 그림 113. 불안감 원인 파악과 경감 서비스 구성 시나리오 ... 192 그림 114. 감성맞춤형 음성 큐레이션 서비스 구성 시나리오 ... 193 그림 115. 배우자 언어 해석기 서비스 구성 시나리오 ... 194 그림 116. 스피치 도우미 서비스 구성 시나리오 ... 194 그림 117. 언어별 통역 사용성 평가 결과(5 점 만점의 MOS 평가. 한컴에 서 실시) ... 197 그림 118. CNBC 등 국내외 언론 보도 자료 ... 200 그림 119. 음성인식기에 Topic LM 이 반영된 구조 ... 201 그림 120. 키워드 인식 적용 구상도 ... 202 그림 121. 연속된 문장에서 유사도 계산을 위한 키워드매칭 ... 203 그림 122. 사용 데이터 발화 및 키워드간 유사도 계산 결과 ... 204 그림 123. 제주여행 데이터와 비교군 데이터의 키워드별 유사도 비교 ... 204 그림 124. Chain 구조를 갖는 LSTM 모델 학습 과정 ... 206 그림 125. 의문문 분류 구성도 ... 208 그림 126. Pitch 검출 과정 ... 209 그림 127. “여기가 아파요 (./?)”발화 종단지점의 평서형과 의문형 Pitch 및 1 차 기울기 결과 ... 210 그림 128. 반향음과 주변 잡음 ... 211 그림 129. 원거리 음향모델 구축 방식 ... 212
그림 130. Zero UI 기술 구성 및 요소기술 개선 ... 215 그림 131. 기존 스마트폰 통역대비 제안된 핸즈프리 통역의 사용자편의성 향상 ... 217 그림 132. NHK 기자와 통역상황 (좌), ISO 국제표준 승인 2017.8 월 보도자 료(우) ... 220 그림 133. 베트남어 phoneset 정의 ... 221
참고문헌
약어표
<부록>
제 1 장 서론
제1절 연구목표 및 연구범위
인공지능 기술은 현재 세계경제사회 전반에 혁신을 유발하는 4차 산업혁명을 위한 핵심 기술로서, 구글, 아마존, 페이스북, 애플 등 글로벌 기업은 새로운 부가가치를 창출할 수 있는 산업에 인공지능 기술을 빠르게 접목하고 있으며, 중국의 IT기업이 발빠르게 이를 추격하고 있는 상태이며, 국내업체와 기술 간격이 점점 더 벌어지고 있다. 따라서, 국내 인공지능의 경쟁력을 높이기 위해서는 초기 개발단계에 있는 자율성장형 인공지능 분야에 대한 핵심기술을 선점하는 것도 매우 중요하다. 학습 데이터 자동증강 및 소규모 데이터에 효율적인 인공지능 학습 알고리즘 확보가 향후 인공지능 경쟁력의 핵심이 될 것이며, 이를 통해 글로벌 기술 격차 해소를 단숨에 해결할 수 있다. 특히, 복합모달 (영상, 음향, 텍스트, 생체 등) 정보를 모달리티 협력 학습을 통해 동일 휴먼모방형 자율성장 매커니즘과 인간이 지식을 성장시키는 기억-집중-의미이해-인터랙션의 과정을 모방하여 스스로 지식성장하는 인공지능 매커니즘 개발함으로써 보다 경쟁력을 갖추게 될 것이다. 자율성장형 인공지능 연구를 통해 확보하려는 핵심 기술 및 시스템은 다양한 복합 모달리티의 정보를 이해하고 휴먼 전문가의 도메인의 문제해결 과정을 모방하여 문제해결을 위한 절차지식을 학습하며 사람과의 인터랙션을 통해 절차지식의 다양성을 증가시켜 지식을 스스로 성장하는 기술이다. 또한 사용자의 감정을 파악하고 행동과 감정의 연관성을 학습하여 사용자 상태 예측에 따른 서비스 제공 등을 가능하는게 하는 휴먼이해 기술을 접목하게 된다. 마지막으로 휴먼이해 기반의 자율성장 과정을 통한 도메인 문제해결 지식을 성장하여 실제 서비스에서 사용자 교감형 conversational 서비스를 제공하는 기술을 접목하게 된다. 주요 기술을 요약하면 아래와 같다. 복합모달리티 기반의 전문가의 문제해결 과정을 학습하고 사용자와의 인터랙션을 통해 문제해결 절차지식을 성장하는 자율성장 인공지능 기술 감정 및 행동의 휴먼 경험정보를 기억하여 사용자의 단기적/장기적 수면상태, 정서 등을 예측하여 서비스를 제공하는 휴먼이해 기술 사용자와의 대화를 통해 휴먼이해 기반의 자율성장 인공지능 서비스를 연도하는 conversational 인공지능 기술 자율성장형 인공지능 기술은 사용자 인터랙티브 기반 문제해결의 절차지식을 강화/수정할 수 있으며 개인 데이터를 기반으로 감정을 인지하여 기억모델 기반의 지속적 감정반응을 예측할 수 있어 개인 상태에 따른 지식 성장을 가능하게 하며 conversational 대화 인터랙션을 통해 인공지능 서비스의 사용자 편의성을 높일 수 있다. 시스템 개념도는 아래의 <그림 1>과 같다. 그림 1. 자율성장형 인공지능 시스템 개념도
제2절 연구개발의 중요성
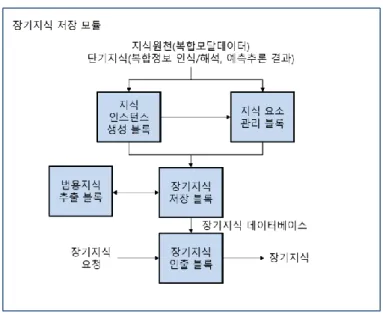
앞으로 자율적으로 데이터를 증강하여 자가학습 하며 선언적 지식을 넘어서 절차적 지식을 성장하는 인공지능 기술이 글로벌 선두기업 사이에서 치열하게 벌어질 것으로 예상되며. 현재 상용 서비스로 널리 사용되고 있는 단순한 음성명령 만으로 사용자 요구에 반응하는 인공지능 스피커로부터 인간과 더 자연스럽게 대화하고 감정을 교류할 수 있으며, 또한 음성뿐만 아니라 다양한 복합 모달 입력에 대해서도 정보를 전달해 줄 수 있는 인공지능 기술이 매우 중요해질 것이다. 이러한 구성이 가능한 인공지능 기술은 인간이 지식을 습득하는 과정을 최대한 모방하려는 방향으로 기술 개발이 이루어 질 것이며, 본 과제에서 설계하고 있는 자율 성장 매커니즘은 <그림 2>와 같이 구성될 수 있다. 즉, 데이터를 통해 확보한 지식을 기억공간에 임베딩하고 목표 도메인의 지식에 집중하여 문제해결 과정을 학습하는 과정을 통해 의미를 파악하여 문제해결 절차지식을 스스로 성장시키는 방식이며, 절차지식 성장 과정 이후 인터랙션을 통한 피드백에 따라 지식 강화 과정을 통해 자율 성장하는 매커니즘의 구조를 가지게 된다. 그림 2. 휴먼 지식 습득 과정을 모방하는 자율성장 매커니즘자율성장 기술을 통해 레이블 정보를 만들기 매우 어려운 문제해결 절차에 대한 지식을 학습할 수 있으며, 기존의 supervised 학습에서 다루지 못한 인공지능 시스템을 개발할 수 있다. 기존 Supervised 학습에서의 선언적 정보에 대한 학습을 넘어서 선언적 정보기반의 다양한 도메인의 문제해결 절차지식을 인터랙션을 통해 학습함으로써 차세대 인공지능 기술을 선도하는데 중요한 역할을 할 것으로 예상된다. 또한 자율성장 기술과 휴먼이해 기술을 접목하여 개인화된 문제해결 절차지식을 성장할 수 있으며, 개인의 감정 및 행동상태에 따른 문제해결 방ㅂ버을 예측하여 성장하는 서비스를 개발할 수 있다. 마지막으로 conversation 인공지능 기술을 통합함으로써 사용자와의 자연스러운 대화기반의 문제해결 절차지식을 사용자에게 서비스할 수 있는 시스템의 개발이 가능하다. 휴먼이해 기반의 자율성장 인공지능과 대화형 시스템으로 확장할 수 있는 conversational 인공지능 기술의 구조는 다음 <그림 3>과 같다. 그림 3. 자율성장형 인공지능 구성도
제 2 장 본론
자율성장 AI에 대한 테스트 베드를 구성하기 위해 성능검증용 자율성장형 패션 코디네이터 프로토타입 시스템을 개발하였다. 당해년도는 1단계 전체중 Baseline v0.5에 해당하며 기본이 되는 주요 기술들을 개발하고 이를 통합하여 실증서비스도 실시하도록 하였다. 먼저 프로토타입 시스템 v0.5 개발 및 실증 서비스에 대해 전반적으로 설명하고, 프로토타입 시스템을 구성하는 주요 기술인 대화생성 및 코디네이션 지식 생성에 대해 개발된 기술을 상세하게 서술한다.제1절 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5 개발
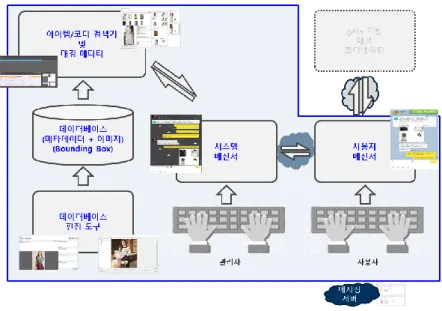
아래 (그림 4)과 같이 AI 패션코디네이터는 아래와 같이 구성되도록 개발하였다. 기본이 되는 형태는 메신저 통신 방식이다. 이를 위해 메시징 서버를 구성하였고 메시징 서버를 통해 다중 코디와 사용자간의 연결이 가능하도록 하였다. 또한 AI 코디네이터는 2가지 모드로 개발하였으며, Legacy 모드는 현재 일반적으로 사용되는 QA 시스템에 기반하여 개발을 하였고, 이는 개발한 메신저 방식이 제대로 동작하는지에 대한 검증용으로도 사용하였다. 또한 본 연구에서 개발한 자율성장시스템도 함께 동작하도록 하였으며, 사용자와의 Interaction을 통해 훈련된 모델을 사용하였다.그림 4. 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5 구조도
1. 자율성장형 패션 코디네이터 프로토타입 시스템 v0.5
당해년도에 개발한 프로토타입 시스템 v0.5 의 경우는 아래 (그림 5)의 전체 시 스템구조도에서 언어임베딩, 대화생성, 패션코디네이셔 지식 성장에 관련된 주요 기술을 개발하였다. 전체 시스템을 개발하는 것은 1 단계 목표이며 이는 사용자 리워드를 추정하고 이를 활용하여 모델을 지속적으로 성장시킬 수 있는 시스템 을 의미하며 본 연구의 최종 목적에 대한 가장 단순한 형태의 실증 시스템이다. 프로토타입 시스템 v0.5 의 경우에 대해 시연시스템의 경우는 언어임베딩과 패션 코디네이션 지식생성 부분을 통합하였고 대화생성에 대해서는 간단한 구조로 대 체하여 개발하였다.그림 5. 자율성장형 패션 코디네이터 프로토타입 시스템 구조도
2. 실증 서비스용 주요 개발 요소
프로토타입 시스템 v0.5 를 개발하기 위해서 필요한 주요 개발 요소는 DB 수집 과 시연에 공용으로 사용하는 부분인 메시징 서버, 메신저 등이다. DB 수집을 위해서 다양한 에디터를 개발하였고, 이를 활용하여 최대한 효율적이며, 실제 코 디 전문가가 코디를 추천하는 형태가 되도록 DB 를 수집하도록 하였다. 실제 시 연을 위해서는 메신저 기능이 포함된 AI 패션 코디네이터를 개발하였다. 세부 사항은 다음과 같다. 또한 각각의 프로그램들은 실제 DB 수집자와 사용자의 요 구사항를 최대한 반영하도록 하여 개발하였으며, 또한 개발후에도 지속적인 개 선 사항에 대해 대응하도록 하였다.
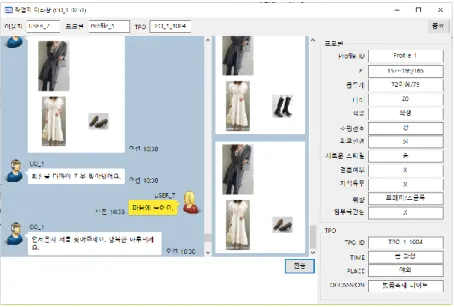
공용 개발 요소 - 메시징 서버 : 다중 코디 및 다중 사용자 동시 접속 지원그림 6. 메시징 서버 화면 및 접속 일례 이상의 (그림 6)에 나타난 것은 2 개의 코디가 접속되어 있고 또 한 2 명의 사용자가 동시 접속된 상황을 나타낸다. 또한 사용자 “김미나”는 코디 1(CO_1)과 연결되어 있고, “장미란”은 코디 2(CO_2)와 접속되어 있음을 나타낸다. - 메신저 : 코디용 / 사용자용 각각 개발 카톡형태의 메신저 방식으로 코디셋과 대화 수집
그림 7. 사용자용 메신저 화면 및 일례
사용자용 메신저는 사용자의 프로필과 현재 TPO 정보가 오른쪽에 나 타나며, 왼쪽의 창은 대화 이력이 있고 중간 창은 코디 이력을 나타 내였다.
코디용 메신저는 사용자의 프로필과 현재 TPO 정보를 위쪽에 배치하 였으며, 나머지는 사용자용 코디와 동일하다.
DB 수집용 개발 요소 - 패션 태깅 에디터 : 수집된 대화에 대한 태깅 정보 추가용 그림 9. 패션 태깅 에디터 화면 및 일례 - 메타 데이터 에디터 : 수집된 패션 아이템에 대한 메타 데이터 정보 추가용 그림 10. 메타 데이터 에디터 화면 및 일례 - 패션 코디셋 에디터 : 수집된 패션 아이템들의 조합을 통한 코디 셋 구성용그림 11. 패션 코디셋 에디터 화면 및 일례 - 패션 코디 검색기 : 메신저를 통한 대화 수집시 코디로 선정된 사용자가 패션 코디셋 에디터로 구성된 코디셋을 검색하는데 사 용. 그림 12. 패션 코디 검색기 화면 및 일례 - 패션 아이템 박스 에디터 : 수집된 패션 아이템들의 Boundary Box 설정용
그림 13. 패션 아이템 박스 에디터 화면 및 일례
DB 수집용 개발 요소들의 운영 방법 실증 서비스용 DB 수집을 위해 개발된 개발요소들을 조합하여 실제 DB 를 수집하는 절차를 나타내었다. 먼저 데이터베이스 편집도구인 패션 아이템 에디터와 코디셋 에 디터를 사용하여 메타데이터와 이미지로 구성된 데이터베이스를 구성한다. 그리고, 관련 대화를 수집하기 위해 메시징 서버 프로그램과 메 신저 프로그램 및 코디 검색기를 사용하여 실제 대화 DB 및 코 디셋의 변경 과정에 대한 내용을 수집하게 된다.그림 14. 실증 서비스 Baseline 0.5 – DB 수집용 구성
시연용 개발요소-
메신저 포함 AI 코디네이터 : 개발된 기술들을 통합하여 실제 사 용자 메신저와 통신을 통해 입력되는 요청에 대해 훈련되 코디셋 을 자동으로 출력하고 대화하는 기능을 수행그림 15. 메신저 포함 AI 코디네이터 화면 일례
DB 수집용 개발 요소들의 운영 방법실증 서비스용 DB 수집을 통해 수집된 데이터를 사용하여 모델 을 위해 개발된 개훈련을 수행하여 이를 기반하여 실제 서비스를 수행하는 절차를 나타내었다.
그림 16. 실증 서비스 Baseline 0.5 – 시연용 구성 아래 (그림 17)은 두명의 사용자가 두개의 AI 코디네이터와 각각 접속하여 시연이 수행되는 화면을 나타낸다. 메시징 서버에 2 개 의 코디가 Busy 상태에 있음을 알수 있으며, 작업자가 각각 연결 된 상태도 알수 있다. 2 개의 AI 코디네이터는 훈련량이 차이가 있 으며 동일한 입력에 대해 다른 결과를 보여준다. 사용자와 interaction 이 많은 데이터를 사용한 왼쪽 모델이 오른쪽 모델보다 더 적절한 코디셋을 추천해 주는 것을 알 수 있다.
그림 17. 실증 서비스 Baseline 0.5 – 다중 코디/사용자 시연용 실제 화면
3. 실증 서비스용 프로토타입 시스템 v0.5 코디셋 결과 사례
개발된 실증 서비스용 프로토타입 시스템 v0.5 를 사용하여 사용자와 실제 대화를 통해 얻는 코디셋 결과들에 대한 몇가지 사례에 대한 결과를 서술한다. 아래의 예 제 대화는 훈련 데이터에는 없는 임의의 문장들로 구성되어 있다.
결혼식장용 코디 추천 결혼식장에 어울리는 옷을 추천해주세요. 다른 것으로 보여주세요. 너무 화려한데요. 좀 더 세련된 것으로 부탁해요. 좀 더 단아한 것으로 부탁해요. 어울리는 부츠 추천해주세요. 너무 더워보여요. 외투를 좀 더 가벼운 색깔로 바꿔주세요. 신발을 바꿔주세요.첫번째 요청인 “결혼식장에 어울리는 옷을 추천해주세요.” 라는 첫번재 요청에 대 한 결과가 아래 (그림 18)와 같다. 왼쪽의 결과는 2000set 훈련 데이터를 사용하여 구성한 모델이고, 오른쪽 결과를 500set 훈련 데이터를 사용하여 구성한 모델의 결과이다. 본 결과에서는 500set이 적절한 아이템을 출력했다고 볼 수 있다.
그림 18. 첫번째 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 그러나, 대화가 진행됨에 따라 500set을 사용한 모델은 제대로 된 코디를 출력하지 못했고, 2000set의 경우는 사용자의 원하는 요청에 대해 적절하게 답변을 하였고 또한 최종 코디셋도 구성이 된 것을 알 수 있다. 그림 19. 마지막 요청에 대한 2000set 및 500set 훈련 모델 응답 결과
여름옷 코디 추천 시원한 여름옷 부탁해요. 시원한 색깔의 신발도 찾아주세요. 다른 것도 한번 보여주세요. 간단한 가디건은 어떨까요? 블라우스를 바꿔주세요. 그림 20. 첫번째 요청에 대한 2000set 및 500set 훈련 모델 응답 결과 그림 21. 마지막 요청에 대한 2000set 및 500set 훈련 모델 응답 결과4. 실증 서비스용 프로토타입 시스템 v0.5 – Legacy 모드 결과 사례
개발된 실증 서비스용 프로토타입 시스템 v0.5의 Legacy 모드를 사용하여 사용자 와 실제 대화를통해 얻는 코디셋 결과들에 대한 결혼식 사례에 대한 결과이다. 사 용 키워드는 “결혼식”이다. 결혼식장에 입을 옷을 총 3번 추천받았으며, 각각에 대해서는 전부 다른 구성이다. 또한 이러한 코디셋은 전문가들에 의해 미리 구성된 코디셋 중 결혼식이라는 키워 드를 가지는 코디셋 중 선택된 것이다. 따라서, 대화를 통해 코디셋을 변경하는 것 은 엄청난 데이터 태깅작업을 요하며, 이러한 방식을 벗어나고자 하는 것이 본 연 구의 목적이기도 하다. 또한 태깅이 적절하지 못하거나 오류가 있는 경우는 세번 째 결과처럼 적절하지 못한 코디셋을 제시할 수가 있다. 그림 22. Legacy 시스템의 결혼식 관련 코디셋 검색 결과제2절 대화생성 모듈
1. 문장임베딩 서브워드 임베딩을 이용한 문장 임베딩 기술에 대하여 제시한다. 이를 위해 어절 기반 포지션 인코딩을 도입하여 어절 구성 단어의 임베딩값 가중치를 문장 임베딩값 결정에 활용하는 방법을 제시한다. 이는 한국어와 같은 교착어에 백-오브-워드 방식의 문장 임베딩 접근 방법을 적용할 수 있게 한다. 또한, 스킵서트 문장 임베딩 학습 방법론을 서브워드 임베딩 기술과 통합하여 서브워드 임베딩을 학습할 때 문장 문맥 정보를 이용할 수 있게 한다. 여기서 제시하는 모델은 문장 임베딩을 고려한 추가적인 학습 패러미터를 최소화 하여, 대부분의 학습 결과가 서브워드 임베딩 패러미터에 누적되게 한다. 가. 용어 정리 ー 서브워드 임베딩 기존 워드 임베딩은 주어진 어휘 목록만을 한정하여 워드 임베딩 학습 진행 주어진 어휘를 서브 자질 집합으로 표현하고, 서브 자질에 대한 임베딩을 통해 워드 임베딩 학습하는 기술 -> 미등록어 문제 해결 ー 문장 임베딩 주어진 문장 목록에 대하여 각 문장별 벡터값을 결정 의미적 유사 문장은 벡터 공간상 거리가 가깝게 학습 단순한 문장 임베딩 값 계산은 문장 구성 단어 임베딩 값들의 평균값 ー Subword Emb. + Skip-thought Sentence Emb. 서브워드 임베딩 학습과 스킵서트 문장 임베딩 학습의 동시 학습 가능하게 제시 학습 대상 및 결과는 “서브워드 임베딩 테이블” 문장임베딩 연산 활용 또한, 교착어에 적용 가능한 어절기반 포지션 인코딩 제안 나. 문장임베딩 연산과정 (그림 23) 은 서브워드 임베딩을 이용한 문장 임베딩 연산 과정을 기술한다. 입력 문장은 (그림 23)의 전체 절차를 통해 문장 임베딩 결과로 변환된다. 문장 임베딩 값은 다차원 벡터 값으로 벡터 공간상에 유사한 의미의 문장들을 가깝게 하고, 이질적 문장들은 서로 거리가 멀게 한다. 즉, 워드 임베딩 기술이 유사한 의미의 단어들을 군집화 하게 한다면, 문장 임베딩 기술은 유사한 문장들을 군집화 가능하게 한다.
그림 23. 패션 아이템의 메타데이터 샘플 입력 문장은 먼저 토큰 분리 단계인 단어 분할 절차를 거친다. 여기서 결정된 단어들에 대하여 서브워드 추출 과정이 진행된다. 서브워드 추출 예제는 (표 1)의 서브워드 벡터 집합 컬럼에 기술되어 있다. “아이”라는 어휘에 대한 서브워드 집합은 문자 자질 기반 길이 2~3으로 제한 했을 때, { “<아”, “<아이”, “아이”, “아이>”, “이>” }가 된다. 여기서 “<”와 “>” 기호는 단어의 처음과 끝을 의미한다. 표 1. 서브워드 임베딩과 어절기반 포지션 인코딩을 이용한 문장 임베딩 연산 서브워드 추출이 문장 구성 어휘들에 대하여 결정되었을 때 (표 2)의 서브워드 임베딩 테이블을 이용한 단어 임베딩이 진행된다. 단어 임베딩은 구성 서브 워드 벡터의 합으로 결정된다. 서브워드 벡터는 학습된 (표 2)의 서브워드 임베딩 결과를 이용한다. 본 연구의 최종 목표는 바로 (표 2)의 서브워드 임베딩 벡터값을 기계학습과정을 통해 도출하는 것이다.
표 2. 서브워드 임베딩 테이블 단어임베딩 값 도출 이후, 어절 기반 포지션 인코딩을 통해 문장 임베딩을 위한 실질 형태소와 형식 형태소의 가중치를 다르게 결정하는 작업을 진행한다. 현대 영어의 경우 문장을 구성하는 어휘의 순서가 문장 의미 결정에 영향을 미친다. 영어는 언어유형학상 고립어로 분류되는데, 단어 임베딩의 합이나 평균으로 결정되는 백-오브-워드 (back of word) 방식의 문장 임베딩 기술은 구성 단어의 어순 변환을 반영할 수 없는 문제가 있다. 이에 도입된 기술이 포지션 인코딩 방식으로 문장의 단어 위치에 따라 고정 가중치 값을 문장 임베딩 연산 시 단어 임베딩 값 결정에 이용하는 접근 방법이다. 한국어와 같은 교착어의 경우, 어순이 비교적 자유로워 해당 접근 방법을 적용하기에는 문제가 있다. 따라서 본 연구는 어절을 구성하는 실질 형태소와 형식 형태소의 가중치 값에 차별화를 두는 접근 방법을 제시한다. - 한국어 어절 = { 실질형태소, 형식형태소1, 형식형태소2 … } - 어절 기반 포지션 인코딩 = { 1.0 , 1.0- , 1.0- , … }, 0 < < 1.0 한국어 어절 구성은 다양하다. 따라서, 첫번째 형태소를 실질형태소로 가정하고, 나머지는 형식 형태소로 가정한다. 포지션 인코딩은 실질형태소를 1.0으로 했을 때 나머지는 1.0- (0<<1.0)으로 고정한다. 이는 다수의
형식형태소를 대처하기 위한 접근 방법으로 경험적 실험으로 검증된 결과이다. 어절 기반 인코딩 예제는 (표 1)의 어절 기반 포지션 인코딩 컬럼에 기술되어 있다. 마지막으로 문장 임베딩 연산은 (표 1)의 마지막 행에 기술되어 있다. 워드의 임베딩 값과 포지션 인코딩 값을 곱하고 전체 문장에 대한 평균을 구하면 문장 임베딩 연산 과정이 종료 된다. 다. 문장임베딩 학습 모델 ー 문장임베딩은 전통적 skip-gram 모델을 sub-word 모델로 확장하고, 이를 기반으로 skip-thought 문장임베딩을 multi-task learning을 통해 학습한다.
ー 학습과정은 다음과 같은 우도를 최대화하는 접근 방법을 취한다. Tw개의 타겟 워드 wt에 대한 컨텍스트 워드 wc 예측 확률과 Ts개의 타겟 문장 sentt에 대한 컨텍스트 문장 sentn을 예측하는 확률의 합으로 우도는 구성된다. ー 서브워드 임베딩의 수식은 다음과 같다. ー 문장 임베딩 수식은 다음과 같다. 서브워드 임베딩과 동일 구조를 갖고 있다. ー 학습 대상 variables, 즉, 서브워드 임베딩 테이블 {ℱ𝑡 ℱ𝑐 ℱ𝑛}이 학습 결과이다, 여기서 단어/문장 임베딩 공통 테이블 ℱ𝑡 를 최종 결과로 이용할 수 있다. 라. Evaluation
ー 서브워드 임베딩 학습용 텍스트 DB들
(1) 의상 아이템 메타 데이터 (color, emotion, material, shape) (2) 전북대 구축 코디 대화셋 (1)+(2)를 이용한 ANN 기반 유사문장 추출: 14,756,742 문장 (1.2G) (3) 추가 코퍼스: 82cook (374M), interview (208M) (1)+(2)+(3) 후 colloc 기반 wst 진행 최종 : 1.9G 텍스트 코퍼스 ー 서브워드 임베딩 평가셋 WS353 한국어 평가셋 : {단어 1, 단어 2, 유사도 점수} WS353(sim) : 유사도 평가셋 WS353(rel) : 관계성 평가셋 상관계수 평가 sci.pearsonr() 이용 ー 문장임베딩용 학습 데이터
82cook (374M) : sentence chain 추출 (문맥 유사문장 triple) 6,011,252 sent pair 생성 (positive set)
ー 문장임베딩 평가 데이터 1k 문장 유사도 set (etri-2017 용역) ー 평가 결과 도메인 모델에 대한 실험결과는 다음과 같다. Pearson 상관계수 점수의 경우 0.4~0.7 수준이면 타당한 결과라 볼 수 있다. 평가셋 Pearson R. WS353 : sim 0.502 WS353 : rel 0.476 Sent1K 0.54 표 3. 평가 결과
2. Language Interaction Encoder-Decoder 기술 가. 언어 인터랙션 인코더 디코더 모델 ー 기본적인 구성은 언어인터랙션 로그 히스토리와 의상코디 메터 정보 셋을 입력으로 디코더에 전달 하고, 디코더는 코디 로봇의 답변을 생성한다. ー 다음 (그림 25)은 해당 예제를 기술하고 있다. 언어인터랙션 히스토리만 인코더에 전달되는 것으로 보이나, 메타데이터와 해당 타임의 언어언터랙션 히스토리는 통합되어 디코더에 전달된다. 그림 25. 언어 인터랙션 예제 ー 인코더-디코더 네트워크의 상세 도면은 다음과 같다. Bidirectional RNN으로 언어 인터랙션이 인코딩되고, 문장임베딩으로 메터 데이터가 인코딩된후
언어인터랙션을 이용하여 필터링되고, 이를 통합하여 디코더에 전달되는 내용을 기술 하고 있다. 언텐션은 각각의 입력 정보를 모두 이용하고, 디코더의 독립된 레이어와 연결된다. 그림 26. 언어 인터랙션 Enc-Dec 아키텍쳐 나. Evaluation ー 실험 데이터 입력(인코더)/출력(디코더) set: 16,736 인코더 어휘 : 6,396 디코더 어휘 : 342 ー 평가 Closed evaluation Epoch Correctness (N-D-S)/N
N = epoch당 디코더 총 word수 D = deletion err 수 S = substitution err 수 누적 적용 기술 Epoch Correctness • 입력 대화 히스토리 각 문장을 sentence embedding 후 RNN인코더 적용 45% • 입력 대화 히스토리 n개의 단어열로 변환 후 RNN인코더 적용 • Bidirectional dynamic RNN • FW, BW 각각 3layer RNN 51.4%
• 인코더 word embedding을 static으로 변환, 즉 trainable=False • Beam Search 디코더 적용 • 의상 메타 정보와 인코더 state결과에 FC layers 도입 58.8% • 의상 메타 정보에 meta-data filtering 도입 • RNN 디코더에 멀티 레이어 적용 • RNN 3layer디코더의 선행 2layer에 독립적인 attention1, attention2 적용 63.6% 표 4. 적용 기술에 따른 성능 개선 결과
3. 의상코디 Language Interaction 및 코디지식 데이터셋 구축 가. 당해년도 작업 내용 ー 진행 사항 데이터 구축 도구 전달 및 개선 : 의상 검색 도구, 코디용 채팅 도구, 유저용 채팅 도구, 태깅등 후처리 도구 코디 exp-res 표현 제약 작업 : 문형 제한 가이드라인 작성 코디 추천용 리워드 태깅 추가 변경 2,400셋 구축 완료 ー 대화 스크립트 구축을 위한 기본 사항 1. 참여자 역할 1.1 코디 1.1.1 코디는 이용자와 상황에 맞는 의상을 제안하는 AI이다. 1.1.2 코디는 AI이기 때문에 계절과 날씨를 이미 알고 있는 것으로 간주한다. 1.1.3 코디는 이용자(USER)에게 가상 이용자의 프로필 및 TPO를 학습시킨다. 1.1.4 코디는 ETRI에서 제공하는 프로그램을 사용하여 이용자에게 코디를 제안한다. 1.2 이용자(USER) 1.2.1 이용자는 TPO에 적절한 의상을 제안받기 위해 이 시스템을 사용하는 사람이다. 1.2.2 이용자는 코디가 제시하는 가상 이용자의 프로필을 학습한 후 대화에 참여한다. 1.2.3 이용자는 코디가 ‘AI기계’임을 인지하고 대화에 임한다. 이 때 사용하는 시스템은(코디 추천 시스템)은 단순 추천 서비스로 이용자가 선택한 옷의 구매를 돕거나 구매로의 연결을 유도하는 프로그램은 아니다. 1.2.4 이용자는 코디가 제안한 코디셋을 선택(추천 성공) 혹은 거절(추천 실패) 할 수 있다. 1.2.5 이용자는 ETRI에서 제공하는 프로그램을 사용하여 코디와 대화한다. 2. 코디셋 2.1 사전에 정해진 코디셋은 4개의 아이템(겉옷-상의-하의-신발)으로 구성된다. 다만, 원피스는 ‘하의’로 구분하며, 겉옷-원피스-신발, 총 3개의 아이템으로 구성될 수 있다. 2.2 의상을 설명하는 약어는 다음과 같다.
2.3 초기 코디셋은 random 조합에 의해 선정된 것으로 의류전문가가 평점을 부여한 것으로, 코디 초기 제안은 이에 기반하되, 이후 적합한 조합으로 개선해 나간다. 3. 성공과 거절 3.1 성공은 코디가 제안한 아이템 혹은 코디셋을 이용자가 만족한 경우를 말한다. 3.2 거절은 코디가 제안한 아이템 혹은 코디셋에 이용자가 불만족한 경우를 말한다. 3.2.1 거절은 아이템 혹은 코디셋 당 3회까지 할 수 있으며, 3회 이상 거절 할 시 그 아이템 혹은 코디셋에 대한 최종 거절로 간주한다. 3.3 성공과 거절은 제안하는 모든 아이템 혹은 코디셋에 대하여 발생할 수 있다. 4. 코디 제안(추천) 4.1 코디 제안은 이용자가 원하는 바에 따라 아이템 혹은 코디셋으로 할 수 있다. 4.1.1 (일반적으로) 처음 제안에서 이용자가 특정한 아이템을 찾지 않는다면 코디셋을 추천한다. ex. U: 해외 출장에 필요한 옷을 찾고 있어요. -> 코디셋 추천 U: 해외 출장에 입고 갈 블라우스가 필요해요. -> 블라우스 추천 4.2 제안하는 아이템 및 코디셋은 ETRI에서 제공한 것으로 한다. 4.3 코디 제안은 아이템의 설명(Description)을 기반으로 한다. 4.4 코디를 제안할 때에는 추천 이유를 함께 제시한다.(별첨 1, 20180913_문틀_정리_FINAL_정규식표현.xlsx 참고) ex. 글래머러스한 스타일이시니 몸에 붙는 니트는 어떠신가요? 4.5 코디는 최대한 코디셋(4개 혹은 3개의 아이템 셋)을 만들어 제공하는 것을 목표로 한다. 따라서 이용자가 하나의 아이템을 원하는 경우 추가 아이템을 제안하도록 한다. ー 대화 스크립트 구축을 위한 기능어 가이드라인 : 기능어는 대화 스트립트 각 발화당 태깅하는 것을 원칙으로 한다. 해당 가이드라인 샘플은 다음과 같다.
1. 기능어는 코디의 모든 발화에 태깅한다.
1.1 다만, 제안의 성공과 실패 여부에 따라 이용자의 일부 발화에 태깅할 수 있다.
2. 기능어는 발화가 내포하고 있는 기능에 의해 구분된다.
2.1 기능어는 발화의 기능에 따라 INTRO, SUGGEST, ASK, EXP_RES, CONFIRM, WAIT, HELP, NONE, SUCCESS, FAIL, CLOSING, ETC, 총 12개로 구성된다.
2.2 각 기능어는 정의, 예시, 특이사항, 하위기능어 등을 가지고 있다. 2.3 INTRO, FAIL, SUCCESS, CLOSING은 대화셋 하나에 한 번씩만 태깅한다. 2.4 기능어의 전체 구조는 다음과 같다. 3. 태깅 작업 시 하위기능어를 태그로 기입하되, 하위기능어가 없는 경우 기능어 자체를 태그로 기입한다. 3.1 기능어의 표기는 기능어명을 줄이지 않고 그대로 기입하는 것으로 한다. 다만, 차후 논의를 통하여 표기법을 통일하도록 한다. 4. 작업자가 판단할 때 해당 발화가 내포하는 기능어가 여러 개라고 여기는 경우 해당 기능어를 모두 태깅한다. 단, 도구의 기능어 박스 7개 중 앞 6개에만 태깅하도록 한다. ー 기능어 정의에 대한 간략한 기술은 다음과 같다. 1.INTRO ▸정의 -대화를 시작할 때 ▸예시 -어서오세요. 코디봇입니다. 어떤 옷을 찾으세요?
-안녕하세요. 코디봇입니다. 무엇을 도와드릴까요? 2.SUGGEST ▸정의 -이용자의 요구 사항이 구체적이지 않거나 특정 아이템을 요구하지 않은 경우에 코디가 스스로 무언가를 추천할 때 -여기에서 아이템이란 이용자가 해당 발화에서 언급하지 않았고, 코디가 추천하지 않았던 의상의 대분류나 중분류를 의미함 -일반적으로 사진 없이 추천함 3.ASK ▸정의 -이용자가 특정 아이템을 요구하고 이 아이템에 대한 세부정보를 물어볼 때 -추천 아이템의 색상, 무늬, 소재, 패턴 등 추천 아이템에 대한 세부정보를 물어보는 모든 발화 -일반적으로 사진 없이 물어봄 4. EXP_RES ▸정의 -일반적으로 의상 제안(사진 제시한 경우)후 추천 이유가 포함된 발화에 태깅함 -추천 아이템의 색상, 무늬, 소재, 패턴 등 추천 아이템에 대한 세부정보나 날씨, TPO 등을 추천 이유로 언급한 경우 5.CONFIRM ▸정의 -일반적으로 사진이 제안되기 전이나 후에 이용자의 의사를 묻거나 확인해주는 발화에 태깅함 ▸특이사항 -(ASK 계열과 충돌이 발생할 경우) 주로 이용자의 응답이 YES/NO와 같이 명확하게 나오는 경우에 태깅함 -이용자가 언급한 내용을 반복하거나 다른 말로 설명(rephrase)하는 경우에는 CONFIRM 계열로 태깅함. 6.WAIT ▸정의 -기다려달라고 요청 할 때 -이용자의 요청에 맞는 아이템 제안에 앞서 찾는 과정을 언급할 때 ▸예시 -잠시만 기다려주세요. -단색 원피스를 찾아볼게요. -네. 두꺼운 단가라 티셔츠를 찾아볼게요.
7. HELP ▸정의 - 코디봇 이용 방법을 설명할 때 ▸예시 -예를 들면 가디건, 자켓, 점퍼 등으로 대답하시면 됩니다. -셔츠, 블라우스, 티 등으로 답하시면 됩니다. 8. NONE ▸정의 -이용자가 요구하는 특정 아이템을 보유하고 있지 않을 때 ▸예시 -고객님, 슬리퍼 종류의 신발은 저희가 보유하고 있지 않습니다. -의류와 신발 외 잡화는 취급하지 않고 있습니다. -아쉽게도 아직 저희가 다루지 않고 있는 제품 종류입니다. 9. SUCCESS ▸정의 -이용자가 제안한 코디에 만족하여 이에 대하여 호응할 때 ▸예시 -만족스러우셨다니 다행입니다. -원하시는 옷을 찾아드려 저도 기쁩니다. 10. FAIL ▸정의 - 작성된 대화셋 샘플 중 일부는 다음과 같다. 그림 27. 대화셋 샘플
제3절 패션 코디네이션 지식 생성 모듈
1. 인공지능 패션 코디네이터 설계 및 구현
가. 개요
자율성장 인지컴퓨팅 기술은 스스로 지식을 학습하여 성장하고, 예측 및 추론이 가능한 차세대 인공지능 핵심 기술이다. 본 연구에서는 인간처럼 보고 듣고 생각하고 타인과의 상호 작용을 수행하여, 지식이 자율성장 되는 인공지능 에이전트를 개발한다. 이러한 기술은 스스로 학습하여 성장하는 전문가, 상담사 등 고품질 지식 서비스 시장 응용에 기여할 것으로 본다. 자율성장 인지컴퓨팅 기술의 성능을 검증하기 위한 테스트베드로, 패션 코디네이션 지식을 스스로 학습하여 성장하는 인공지능 패션 코디네이터 시스템을 개발한다. 인공지능 패션 에이전트는 대화 등의 언어 정보와 이미지 등의 시각 정보를 통해 사용자의 요구를 파악하고, 사용자에게 TPO(Time, Place, Occasion)에 맞는 스타일, 색상, 패턴 등의 시각정보를 제공하며, 사용자의 반응을 통해 내재적 보상을 추정함으로써 패션 코디네이션 지식을 스스로 학습하여 성장한다. 이러한 패션 코디네이션 지식은 사용자의 반응을 통해 강화 학습을 수행함으로써 획득한다. 정확한 패션 코디네이션의 지식을 생성하기 위해서는 과거 사용자의 요구사항 컨텍스트 정보와 패션 이력을 충분히 활용할 필요가 있지만, 명시적으로 메모리를 사용하지 않는 종래의 신경망 방법은 이러한 정보를 사용하는 데 한계가 있다. 더구나 종래의 방법은 희박한 TPO에 맞는 패션 코디네이션 지식 생성은 가능하지 않다. 따라서 본 연구에서는 정확한 패션 코디네이션 지식을 제공하기 위해 명시적 메모리를 사용한 신경망의 방법을 설계 및 구현을 한다.나. 인공지능 패션 코디네이터
(그림 28)은 인공지능 패션 코디네이터의 구성도이다. 역전파 알고리즘으로 단대단 학습을 하기 위해 언어 임베딩부를 제외한 모든 구성 요소들은 미분 가능하다. 언어 임베딩부는 언어로 표현된 질문과 과거 생성된 답변을 고정된 차원의 수치화된 벡터로 임베딩을 수행한다. 패션 코디네이션 지식 생성부는 상기 언어 임베딩부에서 획득한 임베딩 벡터를 입력으로 사용하여 명시적 메모리를 사용하는 심층 신경망을 통해 패션 코디네이션 지식을 생성한다. 대화 생성부는 심층 신경망의 입력으로 상기 패션 코디네이션 지식 생성부에서 획득한 패션 코디네이션과 상기 언어 임베딩부에서 획득한 임베딩 벡터를 사용하여, 패션 코디네이션을 구성하기 위한 추가적인 정보를 요청하거나 새로운 패션 코디네이션을 설명하는 답변을 생성한다. 패션 코디네이션 문 그림 28. 인공지능 패션 코디네이터의 구성도
다. 패션 코디네이션 지식 생성부
( 그림 29)는 패션 코디네이션 지식 생성부의 구성도이다. 종래의 기술과 달리명시적인 작업 메모리와 장기 메모리를 활용한다. 작업 메모리는 사용자의 요구사항을 추정하기 위해 과거의 질문과 답변을 기억하는 장소를 나타내고, 장기 메모리는 모든 패션 아이템의 특징들을 기억하는 장소를 나타낸다. 작업 메모리를 읽고 쓰는 신경망을 통해 사용자의 요구사항을 추정하고, 장기 메모리를 사용하는 심층 신경망을 통해 요구사항에 적합한 패션 코디네이션 지식을 제공한다. 패션 코디네이션 문과 과 의 임베딩 터 ( ) 그림 29. 패션 코디네이션 지식 생성부의 구성도
1) 정의
패션 코디네이션은 패션 아이템들의 조합으로 구성된다. 패션 아이템의 종류는 (표 5)처럼 착용하는 위치에 따른 항목으로 구분되고, 하나의 항목에는 복수의 패션 아이템 종류를 사용할 수 없다. 항목 패션 아이템의 종류 Outer 자켓, 점퍼, 코트, 가디건, 조끼 Top 니트, 스웨터, 셔츠, 블라우스 Bottom 치마, 바지, 원피스Shoe 신발 표 5. 패션 아이템의 항목 패션 아이템의 특징은 언어로 표현된 설명을 상기 언어 임베딩부와 동일한 방법으로 임베딩을 수행함으로써 사전에 획득한다. 패션 아이템의 특징으로 형태특징, 소재특징, 색채특징, 감성특징을 사용한다. (표 6)는 (그림 30)의 패션 아이템에 대한 4개의 특징을 기술한 예시이다. 그림 30. 패션 아이템의 예시 형태 특징 단추 여밈의 전체 오픈형, 손목까지 내려오는 일자형 소매, 여유로운 핏, 어깨에서 허리까지 세로 절개에 풍성한 러플 장식 소재 특징 면 100%, 구김이 가기 쉬운 색채 특징 시원해 보이는 소라색 감성 특징 여성스러운, 페미닌한, 세련된, 사랑스러운, 깔끔한 표 6. 패션 아이템 특징의 예시