개인화된 소프트웨어 교육을 위한 콘텐츠 추천 기법
김완섭
숭실대학교 베어드교양대학 부교수
Content Recommendation Techniques for Personalized Software Education
Wan-Seop Kim
Associate Professor, Baird University College, Soongsil University
요 약 최근 소프트웨어 교육이 4차 산업혁명의 핵심요소로 강조되고 있으며, 이러한 시대적 요구에 따라 많은 대학들 이 전교생을 대상으로 하는 소프트웨어 교육을 강화하고 있다. 전교생을 대상으로 하는 SW교육 도입을 위해 온라인 콘텐츠의 활용은 효과적인 방안이라고 할 수 있다. 그러나 일률적인 온라인 콘텐츠의 제공은 학생들의 개별적인 특성(전 공, 흥미, 이해력, 관심분야 등)을 고려하지 못하는 한계를 갖는다. 본 연구에서는 불리언 형태의 시청이력 데이터 환경 에서 콘텐츠 간의 방향성 있는 유사도를 활용하는 추천 기법을 제안한다. 연관규칙 분석의 확신도를 유사도 값으로 활용 하는 새로운 아이템기반 추천 수식을 제안하여 국내의 실제 유료 콘텐츠 사이트의 데이터에 적용하였다. 실험 결과 코사 인, 자카드 등의 전통적인 유사도 방식을 기반으로 하는 협력적 추천방식을 사용할 때 보다 추천 정확도가 향상됨을 확인할 수 있었다.
주제어 : 소프트웨어 교육, 비전공자 코딩교육, 개인화 추천, 협업 필터링, 아이템 기반 추천
Abstract Recently, software education has been emphasized as a key element of the fourth industrial revolution. Many universities are strengthening the software education for all students according to the needs of the times. The use of online content is an effective way to introduce SW education for all students. However, the provision of uniform online contents has limitations in that it does not consider individual characteristics(major, sw interest, comprehension, interests, etc.) of students. In this study, we propose a recommendation method that utilizes the directional similarity between contents in the boolean view history data environment. We propose a new item-based recommendation formula that uses the confidence value of association rule analysis as the similarity level and apply it to the data of domestic paid contents site. Experimental results show that the recommendation accuracy is improved than when using the traditional collaborative recommendation using cosine or jaccard for similarity measurements.
Key Words : Software education, Coding education for non-major, Personalized recommendation, Collaborative filtering, Item-based recommendation
*Corresponding Author : Wan-Seop Kim([email protected])
Received July 2, 2019 Revised July 24, 2019
Accepted August 20, 2019 Published August 28, 2019
1. 서론
소프트웨어는 4차 산업혁명의 핵심 중 하나로 강조되 고 있다. 소프트웨어는 IT분야 뿐 아니라 사회 대부분의 분야에 적용되고 있으며 갈수록 소프트웨어 분야와 다른 분야의 융합이 요구되고 있다. 이러한 시대적 요구에 따 라 소프트웨어 교육이 초중고 및 대학교육에서 활발히 도입되고 있다. 특히 대학에서는 비전공자를 포함하는 신 입생 전체를 대상으로 하는 소프트웨어 교육을 도입하고 있다[1-4]. 신입생 전체를 대상으로 대규모 강의를 현실 적으로 운영하기 위하여 온라인 수업의 도입은 하나의 효과적인 방안이 될 수 있다. 대학에서 소프트웨어 및 컴 퓨팅 사고력 교육을 교양필수로 하여 온라인 혹은 온라 인과 오프라인을 혼합한 블렌디드 수업으로 개설하는 사 례들이 있다[4, 5]. 그 외에도 최근 소프트웨어 학습에 관 련된 온라인 강의 콘텐츠는 다양한 채널을 통해 활발히 개발되고 있다. K-OCW, K-MOOC 등의 국가주도형 사업을 통해 개발된 콘텐츠와 코세라 및 Youtube 등의 기업과 개인이 제공하는 질 높은 소프트웨어 교육 동영 상 콘텐츠들이 확대 생산되고 있다.
대학의 신입생들은 대학의 정규과목을 통해 개발된 소 프트웨어 교육 콘텐츠와 그 외에 다양한 채널을 통해 개 발되고 공개된 콘텐츠들은 접할 수 있는 환경이 되었다.
그러나 소프트웨어 분야에 대한 공부를 이제 막 시작하 는 신입생, 초보자들이 스스로 자신의 수준과 특성에 적 합한 콘텐츠를 선별하여 학습하는 것은 현실적으로 불가 능하다. 따라서 수많은 콘텐츠 중에서 각 학생에게 적합 한 콘텐츠를 필터링하여 제공해주는 개인화된 소프트웨 어 교육 시스템의 제공은 신입생 소프트웨어 교육의 효 과를 향상시키는 효과를 기대할 수 있다[6,7].
대학에서 전교생을 대상으로 하는 소프트웨어 교육을 운영할 때 학생의 특성에 맞춘 교육을 하는 것은 중요하 다. 학생들은 소속대학, 학과 등의 전공적 특성과 개인의 관심분야, 소프트웨어에 대한 흥미도, 프로그래밍에 대한 이해도, 현재 수준 등의 다양한 특성을 갖는다. 따라서 현 실적으로 특성이 다양한 학생들의 필요에 맞는 교육을 제공하는 것은 어려운 문제이다. IT전공자와 IT비전공자 의 두 개의 특성으로 이분화하거나 단과대 별로 세분화 할 수 있으나 이러한 방식도 학생들의 특성에 맞는 교육 을 제공하기 어려운 한계가 있다. 개인화된 온라인 콘텐 츠 제공 시스템의 구축과 활용은 이러한 문제를 해결하 는 하나의 방안이 될 수 있다.
지넷 윙(2006)은 컴퓨팅적 사고 교육의 핵심은 단지
프로그래밍 기술에 있지 않고 컴퓨터과학과 소프트웨어 기술을 현실 문제해결에 적용하는데 있다고 강조하였다 [8]. 이러한 취지에서 대학생들에 대한 소프트웨어 교육 의 목적은 프로그래밍(코딩) 기법 자체보다 스스로 문제 를 인식하고 정의하고 해결해가는 창의력과 주도적 문제 해결 능력에 두어야 한다. 따라서 획일화되고 일방적인 교육방식은 이러한 소프트웨어 교육의 취지에 맞지 않다.
본 연구는 학생들 스스로가 자신의 전공, 수준, 흥미에 맞 는 콘텐츠들을 스스로 탐색하며 주도적으로 학습할 수 있는 환경을 제공하는 것에 대한 것이다.
본 연구에서는 개인화된 SW교육 시스템 구축을 위한 연구로써 이에 적합한 추천 알고리즘을 개발하고 제안하 는 데에 목적이 있다. 특히 사용자들의 명시적인 선호도 데이터가 확보되지 않고 시청 데이터만 확보되는 불리언 데이터 환경에 적합한 추천 알고리즘을 제안한다. 제안하 는 추천 알고리즘의 효율을 검정하기 위하여 국내 영화 사이트의 실제 영화 시청(구매) 데이터를 사용하였다. 연 구용 데이터가 아니라 실제 운영 데이터라는 점에서 추 천 알고리즘의 효율을 판단하는 데 의미가 있는 실험으 로 평가될 수 있다.
본 연구의 2장에서는 기존의 추천 방식에 대한 연구와 한계점을 정리한다. 3장에서는 본 연구에서 제안하는 콘 텐츠 간의 유사도를 측정하는 방식과 추천 결과를 계산 하는 수식을 설명한다. 4장에서는 실험을 통해 제안하는 추천 방법의 효율을 설명하고, 5장에서 연구를 정리한다.
2. 관련연구
2.1 개인화 추천 서비스의 적용
개인화된 콘텐츠 추천은 인터넷을 통한 전자상거래 및 문서검색 등이 시작된 1990년대 중반부터 시작하여 현 재까지 다양한 연구들이 진행되어져왔다[8-12]. 특히 최 근에는 과거에 비해 다양한 분야에서 콘텐츠가 폭발적으 로 생산되고 있어 개인화된 추천 서비스의 필요성은 더 욱 커지고 있다[11]. 개인화 추천이란 특정 사용자에게 그의 프로파일 정보, 과거 활동이력 및 추천 대상이 되는 콘텐츠에 대한 정보를 활용하여 각 사용자에게 적합한 콘텐츠를 선별(filtering)하여 제시해주는 서비스이다.
개인화된 콘텐츠 추천 시스템은 교육 및 연구 분야에 적용할 경우 학업의 성취도를 향상시킬 수 있는 방안이 될 수 있다[14,15]. 그러나 상품의 판매를 통한 수익을
목적으로 하는 상용화 시스템에서는 개인화 서비스의 적 용이 많이 이루어진 반면, 현재까지 교육/연구 분야에서 개인화 시스템을 제공하는 연구 및 사례는 찾기 힘들다 [11, 13]. 김도균(2017) 및 한희준, 최윤수, 최성필 (2018)은 연구 분야에서 과학기술 문서 정보 검색을 개 인화하는 방안을 연구하였다[14,15].
그러나 SW교육 분야에서는 문서보다 영상 콘텐츠를 활용한 교육이 대학교 신입생들에게 효과적이므로 영상 콘텐츠 중심의 개인화된 추천 시스템 개발에 대한 연구 가 요구된다. 성은모, 채유정, 이성혜(2018)는 SW교육분 야에서 학습자들의 자기주도적인 학습을 위한 학습자 유 형을 분류하는 연구를 실시하였다[16]. 교육 분야에서 개 인화된 학습코스를 추천하는 연구사례도 있다[22].
물론 유튜브 등의 상용화된 시스템에 자체에도 개인화 된 시스템이 적용되고 있으나 유튜브는 지나치게 많은 범주의 영상들이 제공되고 있어 소프트웨어 교육 목적으 로는 적합하지 못하다. 또한 학생들의 학업을 방해할 수 있는 흥미 위주의 수많은 콘텐츠들이 학습에 부정적인 영 향을 줄 수 있기 때문에 소프트웨어 교육 영역을 범주로 하는 콘텐츠 추천 시스템에 대한 연구와 도입이 필요하다.
2.2 협력적 추천 알고리즘
추천 서비스를 위한 기법은 크게 내용 기반 (Content-based) 추천, 협력적 여과(Collaborative filtering) 추천, 규칙 기반(Rule-based) 추천, 인구통계 (Demographic-based) 추천 등으로 구분될 수 있다.
물론 이 분류는 상호배반적으로 명확하게 구분되지 않으며 전반적인 추천방식에 대한 분류이므로 실제적 인 적용에서는 여러 추천방식이 함께 사용될 수 있다. 그 리고 각 추천 방법은 장점과 더불어 한계점을 갖기 때문에 한 가지 방식을 사용하기보다는 두 가지 이상의 방식을 혼 합하는 하이브리드 추천(Hybrid recommendation) 방 식을 사용하는 것이 일반적이다.
여러 가지 개인화 추천방식 중에서 협력적 여과(CF:
Collaborative filtering)에 의한 추천은 현재 대부분의 추천 시스템에서 핵심적으로 활용되는 알고리즘이다[17, 18]. 협력적 추천은 사용자의 프로파일 정보, 콘텐츠의 프 로파일 정보를 필요로 하지 않으며, 사용자의 콘텐츠에 대 한 선호도(rating) 정보만을 사용하여 상당히 만족도가 높 은 추천 결과를 제시한다는 점에서 장점이 있다. 협력적 추천 알고리즘은 아마존닷컴(Amazon), 넷플릭스 (Netflix) 및 국내의 대부분의 뉴스 추천, 영화 추천, 음악
추천, 쇼핑몰의 상품 추천 서비스에서 핵심적으로 적용되 고 있다[9,10,23-25].
협력적 추천 기법은 기본적으로 사용자가 부여한 콘텐 츠에 대한 선호도를 활용하여, 특정 사용자와 다른 사용 자의 유사도를 측정하고 유사한 사용자들을 찾아 그들이 공통적으로 선호하는 콘텐츠를 추천해주는 것을 기본 개 념으로 한다. 이러한 기본적인 협력적 추천 방식을 사용 자 기반(User-based) 협력적 추천이라고 한다. 사용자 간의 유사도를 측정하기 위하여 각 사용자를 그들이 부 여한 선호도 값을 기준으로 벡터로 표현한 후 벡터 간의 코사인(Cosine) 수식을 적용하거나 피어슨(Pearson) 상 관계수를 사용하는 방식이 대표적으로 사용된다[17].
협력적 추천에서 사용자 간의 유사도를 계산하는 방식 의 선택은 추천 결과에 주요한 영향을 끼친다[10,17]. 일 반적으로 두 사용자 A, B에 대하여 Cosine 유사도 수식 과 Pearson 상관계수 계산식은 아래와 같다.
∥∥×∥∥
∙
(식1)
∈
×∈
∈
×
(식2)
사용자 기반의 협력적 추천을 위한 기본적인 선호도 예측 수식은 아래와 같다. 사용자 a에 대하여, 콘텐츠 i에 대한 선호도 예측값 를 구하는 수식이다. 이웃 사 용자를 n명으로 설정했을 때 u는 a에 대한 각 이웃사 용자를 의미하며 는 사용자 a와 이웃 사용자 u와 의 유사도 값이다. 는 이웃 사용자 u가 아이템 i에 대하여 부여한 선호도(rating)값이다. 즉, 이웃 사용 자들과의 유사도를 가중치(weight)로 적용하여 그들 이 입력한 선호도 값을 가중치 평균을 구하는 수식이 다.
×
(식3)
위 수식은 사용자들이 선호도를 부여할 때 사용자 별 로 갖고 있는 후한 점수를 주는 성향, 박한 점수를 주는 성향을 반영하지 못한다. 따라서 이러한 사용자의 성향을 반영하도록 수정한 수식은 아래와 같다. 이 수식에서
는 사용자 a가 부여한 평점의 평균이고, 는 a의 이웃 사용자 u가 부여한 평점의 평균이다.
×
(식4)
사용자 기반의 협력적 추천은 사용자가 많아질 경우 시간효율이 떨어지는 문제와 사용 이력이 적은 고객에 대하여 적절한 추천을 제공하지 못하는 문제가 발생한다.
따라서 이러한 문제를 개선하기 위하여 아이템 기반 협 력적 추천이 활용될 수 있다. 아이템 기반 협력적 추천은 아이템(상품, 콘텐츠)을 간의 유사도를 계산한 후 사용자 가 구매/시청한 아이템들에 대하여 유사도가 높은 아이 템을 추천하는 방식이다. 많은 연구에서 아이템 기반 협 력적 추천이 사용자 기반 협력적 추천보다 추천의 효율 이 좋은 것으로 나타난다.
개인화 추천을 위해 협력적 추천 뿐 아니라 데이터마 이닝 분야의 연관규칙 분석도 적용될 수 있다[19, 20].
본 연구에서는 연관규칙을 협력적 추천에서 유사도 측정 의 방식으로 적용하는 방식을 제안할 것이다.
2.3 SW교육 환경에서의 적용 한계점
기본적인 협력적 추천 알고리즘의 첫 번째 한계는 실 제 서비스되는 환경에서는 선호도 데이터를 획득하기 어 려운 점이다. 협력적 추천 알고리즘이 적용되려면 사용자 의 아이템에 대한 선호도 데이터가 확보되어야 한다. 그 러나 대학의 소프트웨어 콘텐츠 시스템에서 사용자(학생) 에게 강의영상 각각에 대한 선호도를 입력받는 것은 쉽 지 않다. 따라서 영상 콘텐츠에 대한 시청/미시청의 여부 에 대한 불리언 정보만을 활용하여 협력적 추천을 적용 하는 방식이 필요하다.
두 번째 한계는 시청 이력이 많지 않은 사용자들에 대 한 콘텐츠 추천에 대한 문제이다. 협력적 추천은 기본적 으로 유사한 특성의 사용자들을 찾아 그들이 공통적으로
선호하는 혹은 시청한 콘텐츠를 추천하는 것이다. 따라서 시청이력이 없거나 적은 사용자들에 대해서는 적절한 추 천을 제공할 수 없는 한계가 있다. 대학의 소프트웨어 교 육영상 추천 시스템의 경우 신입생들에게 적절한 콘텐츠 를 추천해주는 것이 목적인데 신입생들의 경우 시청이력 이 충분하지 못하므로 협력적 추천은 적절한 추천을 제 공할 수 없는 한계가 있다.
세 번째로 협력적 여과에 의한 개인화 추천 서비스는 개인정보 보호, 즉 프라이버시 영역에서 문제가 발생할 여지가 있다[21]. 협력적 추천은 기본적으로 각 사용자의 시청이력 정보를 저장해야 한다. 또한 사용자는 자신의 개인적 성향을 명확하게 드러내는데 귀찮아하는 경향이 있게 때문에 선호도 데이터를 확보하기 어렵다.
협업 필터링(Collaborative filtering)은 개인화 추천 에 매우 유용하게 활용될 수 있는 기법이다[9-11]. 협업 필터링 추천에 관련된 연구에서는 Each Movie, Movie Lens 등의 선호도(rating) 값을 기반으로 추천의 효율을 제시하고 있다. 그러나 실제 서비스 환경에서 신뢰할 수 있는 충분한 선호도 데이터를 확보하는 것은 쉽지 않다.
실제 서비스 환경에서는 해당 콘텐츠를 이용하거나 구매 한 내역의 데이터가 일반적으로 획득되며 활용이 가능하 다. 본 연구에서 관심을 두고 있는 개인화 소프트웨어 교 육 시스템의 경우에도 마찬가지로 사용자에게 시청한 콘 텐츠의 선호도를 명시적으로 요구하고 그 정보를 획득하 기는 쉽지 않다. 따라서 본 연구에서는 불리언(boolean) 데이터에 적합한 협력적 추천 알고리즘을 제안한다. 여기 서, 불리언 데이터란 콘텐츠에 대한 시청/미시청, 구매/
미구매 등의 데이터를 의미한다. 구매/시청 횟수를 사용 하는 방안도 있지만 구매 횟수는 콘텐츠의 특성에 따라 좌우되는 요인이 크기 때문에 일반화하여 적용할 수 있 는 불리언 데이터의 초점을 둘 것이다.
3. 시청이력 데이터 기반의 추천 방식
3.1 유사도 계산 방식
본 연구에서는 불리언 데이터에 적합한 아이템 기반의 협력적 추천 알고리즘을 제안한다. 여기서 불리언 데이터 란 교육영상 콘텐츠에 대한 시청/미시청에 대한 학생의 시청 이력 데이터를 의미한다.
기본적인 협력적 추천의 수식은 선호도 데이터를 기반 으로 하여 벡터를 구성한 후 벡터 간의 코사인 유사도 혹
은 피어슨 상관계수 등의 유사도 계산 방식을 사용하여 아이템 간의 유사도를 측정한다. 그러나 불리언 데이터에 대해서는 이러한 방식의 적용이 적합하지 않은 한계가 있 다[12]. 따라서 불리안 데이터에 적합한 유사도 측정 방식 으로 타니모토 계수(Tanimoto coefficient)가 활용될 수 있다. 타니모토 계수는 아래의 식으로 표현된다[17].
(식5)
이 수식에서 콘텐츠 A와 B의 유사도를 구하는 수식으 로, a는 콘텐츠 A를 시청한 사용자의 수이고, b는 콘텐츠 B를 시청한 사용자의 수이며, c는 콘텐츠 A와 B를 모두 시청한 사용자의 수이다. 즉, 타니모토 계수 공식은 두 사 용자(시청자)가 공통으로 시청한 콘텐츠가 많을수록 높 은 유사도를 갖는 원리이다. 이와 비슷한 개념의 공식으 로 자카드 계수(Jaccard coefficient)가 사용되기도 한 다. 자카드 공식은 아래와 같다[17].
∪
∩
(식6)
위 수식에서 두 사용자 A, B는 두 사용자에 대한 집합 표현이며 교집합의 원소의 수를 합집합의 원소의 수로 나 눈 것이다. 즉 교집합의 개수가 많을수록 1에 가까운 수로 표현되고 교집합이 없을수록 0에 가까운 수로 표시된다.
코사인, 피어슨 상관계수 그리고 토니모토, 자카드 유 사도 계산식의 경우 방향성의 정보를 표현하지 못하는 한계가 있다. 사용자 간의 유사도를 측정할 경우에는 방 향성이 의미가 없으나 콘텐츠 간의 유사도를 측정할 경 우에는 방향성 정보가 유의미하기 때문에 유사도 측정값 이 방향성을 포함하지 못할 경우 추천 정확도에 영향을 미칠 수 있다. 본 연구에서는 영상 콘텐츠 간의 방향성의 정보를 포함할 수 있는 유사도 방식을 적용할 경우 추천 의 효율에 긍정적인 영향을 줄 것으로 판단하고 다양한 유사도 방식을 비교 분석하고자 한다.
따라서 본 연구에서는 데이터마이닝의 연관규칙 분석 기법에서 사용하는 확신도(Confidence) 수치를 유사도 로 사용하는 방식을 제안한다. 기본적인 연관규칙 분석에 서 확신도(Confidence) 수치는 아래의 의미를 갖는다.
연관규칙 분석은 장바구니 분석으로도 불리는데 장바구
니에 한 번에 함께 구매되는 상품들을 분석하여 상품들 간의 연관성의 정도를 찾아내는 분석기법이다. 확신도는 (식7)으로 계산된다.
∩
(식7)
상품 A가 구매된 조건 하에서 상품 A와 B가 함께 구 매되는 조건부 확률을 의미하는 수식이다. 상품 A를 구 매한 고객이 상품 B를 구매할 확률을 의미한다. 신뢰도 (Confidence) 값의 범위는 0부터 1이며, 1이면 동시에 구매할 확률이 100%로 가장 높은 규칙이며, 0이면 동시 에 구매할 확률이 가장 낮은 규칙이다. 즉, 이렇게 산출되 는 신뢰도 값은 두 상품 간의 유사도 값으로 사용될 수 있다. 본 연구에서는 확신도(Confidence) 수치를 유사 도로 사용하는 방식을 제안한다. 기본적인 장바구니 분석 에서는 하나의 장바구니에서의 동시에 구매하는 경우를 계산하지만 본 동시성을 고려하지 않고 사용자의 가입 후 전체 이용 기간에서의 시청 여부만을 활용한다.
∩ (식8)
위 식에서 는 콘텐츠 A를 시청한 사용 자의 수이고, ∩는 콘텐츠 A와 B를 모두 시청한 사용자의 수이다. 이 유사도 계산식의 경우
≠ 인 A, B 간의 방향성이 반 영된 유사도가 생성된다. 이를 사용하면 기존의 유사 도 계산식에서 얻을 수 없었던 방향성 정보를 반영하 게 됨으로써 더욱 의미 있는 추천 결과, 즉 추천 정확 도의 향상을 기대할 수 있다.
3.2 Top-N 추천 알고리즘
본 절에서는 시청 가능성이 높은 상위 N개의 콘텐츠 를 추천하는 알고리즘을 제안한다. 본 연구에서는 확신도 를 통하여 얻은 두 콘텐츠 간의 유사도 계산 결과를 토대 로 하여 사용자에게 아직 시청(구매)하지 않은 콘텐츠에 대한 선호 예측값을 계산하는 아래 수식을 제안한다.
∈
(식9) 위 수식에서 S는 사용자 u가 시청한 콘텐츠의 집합을 의미한다. 위 식에서 는 사용자 u의 콘텐츠 c에 대한 시청에 대한 예측 값이다. confidence(i, c)는 사 용자가 기존에 시청한 콘텐츠 i와 추천 대상 콘텐츠 c 간의 확신도 값이다. N은 사용자 u가 시청한 모든 콘 텐츠의 개수이다. 계산수식에서 확신도(confidence) 에 의한 유사도 값을 제곱하여 누적 합을 계산하였는 데, 제곱을 한 의미는 작은 값보다 큰 값에 대한 가중 치를 높이기 위함이다. Pu,c의 값의 범위는 0에서 1 사이의 값이다.
본 연구의 협력적 추천 실험에서는 사용자(user), 콘 텐츠(content), 시청(view) 여부 정보를 사용한다.
Table 1은 훈련데이터, Table 2는 예측데이터에 대한 예시이다. 훈련, 예측데이터는 사용자(user)를 기준으로 분리한다. 예측데이터에서는 시청/미시청 여부를 ‘?’와 같이 숨긴 후 추천을 적용하여 정확도를 평가한다.
content1 content2 content3 content4
user1 view view view
user2 view view
user3 view view
user4 view
Table 1. training data example for recommendation
content1 content2 content3 content4
user5 view ? ?
user6 view ? ?
user7 view view ? ?
Table 2. prediction data example for recommendation
일반적으로 추천 알고리즘의 검증 실험에서는 사용자 를 기준으로 훈련데이터와 예측데이터를 80%, 20% 등 의 비율 기준으로 분할한다. 훈련용 데이터를 사용하여 사용자 간 혹은 아이템 간의 유사도를 측정한다. 훈련용 데이터를 사용하여 획득된 유사도 정보에 예상 선호도 계산 수식을 적용하여 예측용 데이터의 고객들에 대하여 추천을 적용한다. 예측용 데이터에서 사용자가 시청한 일 부 콘텐츠만을 활용하여 ‘?’에 해당하는 예상 선호도를 예측한 후 예상 선호도가 높은 상위 N개의 콘텐츠를 추
천한다.
4. 실험과 검증
4.1 평가의 방법
본 연구의 실험에서는 유료로 서비스되는 상용화된 온 라인 영화시청 서비스에서 데이터를 사용하였다. 수집된 데이터에 포함된 사용자(고객)의 수는 25,419명이며, 제 공된 콘텐츠(영화)의 수는 489개, 거래 건수는 55,407건 이다. 본 데이터의 정보는 사용자가 특정 영화를 유료로 구매한 내역이다. 많은 연구에서 활용되는 데이터는 실험 을 목적으로 수집된 데이터이므로 그 신뢰성이 부족할 수 있으나 본 실험의 데이터는 실제로 고객들에 의해 유 료로 구매되어 시청된 데이터이므로 신뢰성이 상대적으 로 높다고 볼 수 있다.
일반적으로 실제 데이터의 경우 희소성이 매우 강한 것이 일반적이다. 따라서 많은 연구 실험에서 일정 수준 이상의 시청 기록을 가진 사용자들을 선별하여 이들을 대상으로 실험을 하기도 한다. 그러나 본 연구의 목적은 희소성을 갖는 불리언 데이터에서의 추천 정확도의 향상 이 목적이므로 획득한 데이터를 선별하지 않고 그대로 사용하였다.
보통 개인화 추천 실험에서는 훈련데이터와 예측데이 터를 비율 단위로 구분한다. 그러나 본 연구에서 사용한 데이터는 희소성이 매우 높아 5개의 미만의 영상만을 구 매한 사용자가 대부분이므로 단순히 비율만으로 구분할 경우 올바르게 추천했음에도 추천 정확도가 0에 가깝게 측정되는 문제가 있다. 따라서 따라서 본 연구에서는 구 매(시청) 콘텐츠의 개수가 20개 이상인 사용자들을 예측 데이터로 사용하고 나머지 고객들의 데이터는 훈련데이 터로 사용하였다.
개인화 추천 연구에 대한 실험에서 시청 자료가 일정 수준에 미치지 못하는 사용자의 데이터는 제외하고 실험 하는 경우가 많다. 이러한 실험 방식의 경우 실험 결과의 수치를 향상하는 결과를 가져오나 현실의 시스템에서 많 은 부분을 차지하는 희소 데이터에 대한 올바른 평가를 왜곡할 수 있는 문제가 있다. 시청 이력이 많지 않은 고 객이 대부분을 차지하는 현실의 실정을 반영하기 위해서 는 이들 데이터를 정제하지 않고 그대로 적용하는 것이 필요하다. 따라서 본 연구의 실험에서는 시청 이력의 개 수로 정제하지 않고 수집한 전체 데이터에 대하여 실험 을 진행하였다.
제안하는 추천 수식과 알고리즘의 향상 정도를 검증하 기 위한 실험 척도로는 정확도(Precision), 재현율(Recall) 그리고 이 두 수치를 공통으로 평가하는 F1-value 수치 (수식10)를 사용하였다.
(식10)
4.2 유사도 방법에 따른 정확도 비교
기본적인 협력적 추천을 적용할 때 유사도 방식에 따 른 추천 효율을 비교하기 위해 유사도를 Confidence, Jaccard, Cosine 방식으로 적용하여 실험하였다. 이 실 험에서 Top-N 수치는 10개로 고정한 후 적용하였다.
Table 3은 각 방식에 따른 Precision, Recall, F1-value의 수치를 보여준다. Cosine 방식이 Jaccard, Cosine 방식보다 높은 수치를 나타냄을 확인할 수 있다.
n Precision Recall F1-value
Confidence 0.221 0.238 0.230
Jaccard 0.180 0.204 0.197
Cosine 0.182 0.195 0.189
Table 3. Results of changing similarity methods
Fig. 1. Comparison of F1 by similarity method
4.3 top-N 수치 변화에 따른 정확도 비교
Cosine 유사도 방식을 활용하는 협력적 추천 방식의 성능을 자세히 평가하기 위하여 Top-N의 수치를 변경 하면서 precision, reall. F1-value를 측정하였다.
n Precision Recall F1-value
5 0.281 0.155 0.201
10 0.221 0.238 0.230
20 0.159 0.341 0.218
30 0.135 0.431 0.206
40 0.117 0.490 0.190
50 0.103 0.535 0.174
Table 4. Results of changing the top-N value in the confidence similarity method
Fig. 2. Experiments based on top-n using confidence similarity
n Precision Recall F1-value
5 0.248 0.135 0.175
10 0.180 0.204 0.197
20 0.144 0.302 0.196
30 0.123 0.385 0.187
40 0.111 0.460 0.179
50 0.100 0.519 0.169
Table 5. Results of changing the top-N value in the jaccard similarity method
Fig. 3. Experiments based on top-n using jaccard similarity method
n Precision Recall F1-value
5 0.226 0.119 0,156
10 0.182 0.195 0.189
20 0.141 0.296 0.192
30 0.121 0.379 0.184
40 0.109 0.452 0.177
50 0.100 0.514 0.168
Table 6. Result of changing the top-N value in the cosine similarity method
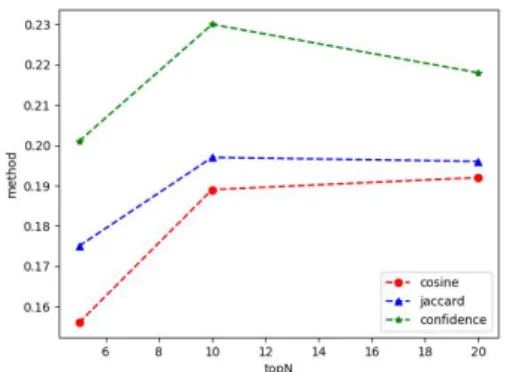
본 실험의 최종적인 결과를 비교하기 위하여 아래와 같이 Top-N이 값이 5, 10, 20, 30, 40, 50일 때의 경우 에 대하여 Precision, Recall, F1-value의 값을 최종적 으로 정리하였다.
Table 7에서 F1-value 값을 Fig 4의 그래프로 비교 표시하였다. 위 분석 결과를 통해 협력적 추천을 적용하 는 경우 Cosine 또는 Jaccard 방식보다 Confidence 방식을 사용하는 것이 추천 정확도가 상대적으로 높음을 확인할 수 있었다. Confidence 방식이 상품의 특성 간 의 방향성을 반영할 수 있는 장점이 반영된 것으로 이해 된다.
n method Precision Recall F1-value
5
Confidence 0.281 0.155 0.201
Jaccard 0.248 0.135 0.175
Cosine 0.226 0.119 0,156
10
Confidence 0.221 0.238 0.230
Jaccard 0.180 0.204 0.197
Cosine 0.182 0.195 0.189
20
Confidence 0.159 0.341 0.218
Jaccard 0.144 0.302 0.196
Cosine 0.141 0.296 0.192
30
Confidence 0.135 0.431 0.206
Jaccard 0.123 0.385 0.187
Cosine 0.121 0.379 0.184
40
Confidence 0.117 0.490 0.190
Jaccard 0.111 0.460 0.179
Cosine 0.109 0.452 0.177
50
Confidence 0.103 0.535 0.174
Jaccard 0.100 0.519 0.169
Cosine 0.100 0.514 0.168
Table 7. Comparison by similarity method
Fig. 4. Comparison of F1 by similarity methods
5. 정리 및 향후 연구
많은 대학들이 전교생을 대상으로 하는 소프트웨어 교 육을 확대하는 추세이다. 신입생 전체를 대상으로 하는 소프트웨어 교육을 위해 대형강의 방식 혹은 온라인 강 의를 활용하는 방식이 활용될 수 있다. 본 연구에서는 온 라인 강의를 적용함에 있어 개인화된 콘텐츠 추천 시스 템의 추천 방식을 제안하였다.
본 연구의 목적은 선호도(rating) 정보가 수집되지 않 고 단지 시청/미시청의 불리안 정보만 수집된 상황에서 의 아이템 기반 협력적 추천의 정확도를 높이기 위한 것 이다. 아이템 기반 협력적 추천에서 아이템 간의 유사도 를 계산하기 위하여 Cosine, Correlation 수식이 일반적 으로 사용된다. 그러나 불리안 데이터에서는 위 수식의 적 용이 기본적으로 불가하므로 Jaccard, Tanimoto 방식, 또는 보정된 Cosine 유사도 방식 등이 사용될 수 있다.
본 연구는 아이템 기반 협력적 추천 과정에서 아이템 간의 유사도를 계산하는 방식에 대한 것이다. 기존의 연 구들에서 대부분 Cosine, Jaccard, Tanimoto 방식을 사용하고 있으나 이들 유사도 방식은 비교 대상 간의 방 향성을 정보를 반영하지 못하는 한계가 있다. 따라서 본 연구에서는 Confidence 방식을 제안하였다. 실험 결과 제안하는 방식이 기존의 방식보다 향상된 추천 효율을 나타냄을 확인할 수 있었다.
본 연구에서는 개인화된 선호도 정보가 축적되지 않고 시청여부 정보, 즉 불리안 데이터 환경에 적합한 협력적 추천 기법을 제안하였다. 다만 아직 추천 시스템은 개발 되지 않은 상태이므로 유료 영화 사이트로부터 획득한 영화시청(구매) 데이터를 활용하였다. 향후 연구로는 전 교생을 대상으로 하는 개인화된 온라인 강의 시스템을 실제로 구현하여 제안한 알고리즘을 적용하는 것이다.
REFERENCES
[1] G. J. Park & Y. J. Choi. (2018). Exploratory study on the direction of software education for the non-major undergraduate students. Journal of Education &
Culture, 24(4),273-292.
DOI : 10.24159/joec.2018.24.4.273
[2] K. M. Lee. (2019). Computational Thinking Education Teaching Method Research for Non-Major Subjects.
Korean Journal of General Education, 13(1),321-343.
[3] J. E. Nah. (2017). Software Education Needs Analysis in Liberal Arts. Korean Journal of General Education, 11(3),63-89.
[4] W. S. Kim. (2017). A Study on establishing software essential courses for non-specialists. The Korean Association of General Education Conference, 110-115.
[5] K. M. Kim, H. S. Kim. (2017). A Study on Customized Software Education method using Flipped Learning in the Digital Age. Journal of Digital Convergence, 15(7), 55-64.
DOI : 10.14400/JDC.2017.15.7.55
[6] Y. J. Ahn. (2015). A Study on The Improvement of Computer Programming Ability for The Learners Participated in Custom Learning Programs. The Korean Society Of Computer And Information Conference, 23(1),295-296.
[7] S. H. Kim, S. M. Lim & S. S. Song. (2015). Analysis about User Log for Development of Online SW Education Platform in Korea. The Korean Association Of Computer Education Symposium, 63-67.
[8] Wing M. Jeannette. (2006). Computational Thinking, Communications of the ACM, 49(3),33-35.
DOI : 10.1145/1118178.1118215
[9] S. H. Kim, B. H. Oh, M. J. Kim & J. H. Yang. (2012).
A Movie Recommendation Algorithm Combining Collaborative Filtering and Content Information.
Journal of KISS : Software and Applications, 39(4), 261-268.
[10] S. J. Lee(2018). A New Similarity Measure using Fuzzy Logic for User-based Collaborative Filtering. The Journal of Korean Association of Computer Education, 21(5),61-68.
DOI : 10.32431/kace.2018.21.5.006
[11] Y. S. Kim. (2012). Research Trend of Recommendation System for Personalization Service. ie Magazine, 19(1), 37-42.
[12] B. C. Kim & S. Y. Lee. (2018). Used Textbook Trading Platform to Recommend University Textbooks. Journal of Digital Convergence, 16(4), 329-334.
DOI : 10.14400/JDC.2018.16.4.329
[13] S. H. Han, Y. H. Oh & H. J. Kim. (2013). Personalized TV Program Recommendation in VOD Service Platform Using Collaborative Filtering. JOURNAL OF
BROADCAST ENGINEERING, 18(1),88-97.
DOI : 10.5909/JBE.2013.18.1.88
[14] D. K. Kim. (2017). Personal Recommendation Service Design Through Big Data Analysis on Science Technology Information Service Platform. The Korean Biblia Society For Library And Information Science, 28(4), 501-518.
DOI : 10.14699/kbiblia.2017.28.4.501
[15] H. J. Han, Y. S. Choi & S. P. Choi. (2018). A Study on Personalization of Science and Technology Information by User Interest Tracking Technique.
JOURNAL OF THE KOREAN SOCIETY FOR LIBRARY AND INFORMATION SCIENCE, 52(3),5-33.
DOI : 10.4275/KSLIS.2018.52.3.005
[16] E. M. Sung, Y. J. Chae & S. H. Lee. (2018). Analysis of Types and Characteristics of Self-Directed Learning of Learners in Online Software Education. The Journal of Korean Association of Computer Education, 22(1), 31-46.
DOI : 10.32431/kace.2019.22.1.004
[17] Suresh K. Gorakala & Michele Usuelli. (2015). Building a Recommendation System with R, Acorn Publishing.
[18] S. J. Lee. (2016). Collaborative filtering system examples and issues. A Journal of Education, 36(1), 1-22.
DOI : 10.25020/je.2016.36.1.1
[19] Y. Kim. (2012). A Study on Design and Implementation of Personalized Information Recommendation System based on Apriori Algorithm.
The Korean Biblia Society For Library And Information Science, 23(4),283-308.
[20] J. S. Han. (2013). Intelligent Recommendation Processor Simulation using Association Relationship.
Journal of Digital Convergence, 11(12), 431-438.
DOI : 10.14400/JDPM.2013.11.12.431
[21] S. K. Kim. (2014). A Study of the Personalization Service and Privacy Paradox in the Big Data Era.
Journal of the Korean Cadastre Information Association, 16(2), 193-207.
[22] J. W. Han, J. C. Jo & H. S. Lim. (2018). Development of Personalized Learning Course Recommendation Model for ITS. Journal of the Korea Convergence Society, 9(10), 21-28.
DOI : 10.15207/JKCS.2018.9.10.021
[23] S. H. Ju, M. Y. Song & B. K. Kim. (2018). The Effect of Personal trait on Perceived Value and Recommendation Intention : Focus on one-person media contents. Journal of the Korea Convergence Society, 9(12), 159-167.
DOI : 10.15207/JKCS.2018.9.12.159
[24] S. J. Park, Y. M. Kim & J. J. Ahn. (2019). Development of Product Recommender System using Collaborative Filtering and Stacking Model. Journal of Convergence for Information Technology, 9(6), 83-90.
DOI : 10.22156/CS4SMB.2019.9.6.083
[25] J. S. Kang, J. W. Baek & K. Y. Chung. (2019).
Multimodal Media Content Classification using Keyword Weighting for Recommendation. Journal of Convergence for Information Technology, 9(5), 1-6.
DOI : 10.22156/CS4SMB.2019.9.5.001
김 완 섭(Wan-Seop Kim) [종신회원]
․ 2000년 2월 : 숭실대학교 컴퓨터학부 (공학사)
․ 2003년 8월 : 숭실대학교 컴퓨터학부 (공학석사)
․ 2006년 8월 : 숭실대학교 컴퓨터학부 (박사수료)
․ 2007년 3월 ~ 현재 : 숭실대학교 베어 드교양대학 교수
․ 관심분야 : 소프트웨어 교육, 인공지능, 개인화 추천
․ E-Mail : [email protected]