반도체디스플레이기술학회지 제19권 제2호(2020년 6월) Journal of the Semiconductor & Display Technology, Vol. 19, No. 2. June 2020.
88
딥-러닝을 활용한 안드로이드 플랫폼에서의 이미지 시맨틱 분할 구현
이용환*· 김영섭**†
*원광대학교 디지털콘텐츠공학과 융복합창의연구소, **†단국대학교 전자전기공학부
Implementation of Image Semantic Segmentation on Android Device using Deep Learning
Yong-Hwan Lee
*and Youngseop Kim
**†*Dept. of Digital Contents, Institute of Convergence and Creativity, Wonkwang University,
**†Dept. of Electronics and Electrical Engineering, Dankook University
ABSTRACT
Image segmentation is the task of partitioning an image into multiple sets of pixels based on some characteristics.
The objective is to simplify the image into a representation that is more meaningful and easier to analyze. In this paper, we apply deep-learning to pre-train the learning model, and implement an algorithm that performs image segmentation in real time by extracting frames for the stream input from the Android device. Based on the open source of DeepLab-v3+ implemented in Tensorflow, some convolution filters are modified to improve real-time operation on the Android platform.
Key Words : Image Segmentation, Semantic Segmentation, Object Detection, Deep Learning, Tensorflow
1. 서 론1
인공지능(Artificial Intelligence)과 딥-러닝(Deep Learning) 방 법에 기반한 컴퓨터 비전(Computer Vision) 기술은 지난 10 년 동안 급격하게 발전하고 있으며, 이러한 기술은 최근 이미지 분류(Image Classification), 얼굴 인식(Face Recognition), 객체 식별(Object Identification), 비디오 분석(Video Analysis), 로봇(Robots) 및 자율 주행 자동차(Autonomous Vehicles)의 이 미지 처리와 같은 다양한 응용분야에 활용되고 있다[1].
다수의 컴퓨터 비전 작업에서는 이미지의 내용을 이해하 고 각 부분을 보다 쉽게 분석할 수 있도록 지능적인 이미 지 분할(Image Segmentation)이 필요하며, 최근의 이미지 분 할 기술은 컴퓨터 비전을 위한 딥-러닝 모델을 활용하여 이전에는 상상할 수도 없을 만큼의 높은 성능에서 어떤
†
E-mail: [email protected]
객체가 이미지의 각 픽셀로 표현되는지를 정확하게 이해 할 수 있다.
딥-러닝은 이미지를 구성하는 객체 클래스를 예측하기 위해 시각적 입력, 즉 다수의 이미지 또는 비디오 스트림 에서 패턴을 학습한다. 이미지 처리에 사용되는 주요 딥- 러닝 알고리즘은 CNN (Convolutional Neural Network), AlexNet, VCG, Inception 및 ResNet와 같은 특정 CNN 프레임워크가 있다. 컴퓨터 비전을 위한 딥-러닝 모델은 일반적으로 처 리 시간을 줄이기 위해 특수 그래픽 처리 장치인 GPU에 서 훈련 및 실행을 처리한다.
일반적으로, 이미지 분석은 3가지 수준으로 구분된다.
첫번째는 이미지 분류로, 전체 이미지를 사람, 동물, 야외 등 이미지 내에 존재한 객체에 초점을 맞춰 이미지를 구 분한다. 두번째는 이미지의 객체 인식으로, 이미지 내 존 재하는 객체를 감지하고, 객체 주위에 사각형을 표시하여 이미지 내의 위치까지도 구분한다. 세번째는 이미지 분할
딥-러닝을 활용한 안드로이드 플랫폼에서의 이미지 시맨틱 분할 구현
Journal of KSDT Vol. 19, No. 2, 2020 89
로, 이미지의 일부를 식별하고 해당 이미지에 포함된 객 체를 세분화하여 이해시킨다. 이러한 이미지 분할은 컴퓨 터 비전에서 중요한 역할을 차지하며, 시각적 입력을 단 순화하기 위해 입력된 이미지를 세그먼트(Segment)로 나 누는 작업을 포함하기 때문에, 객체 식별보다 복잡한 프 로세스를 거친다. 세그먼트는 객체 또는 객체의 일부를 나타내며, 특정 픽셀 집합으로 표시한다. Fig. 1은 이들 3가 지 분류의 정의를 그림으로 설명한다.
Fig. 1. Recognition problems related to generic object detec-
tion: (a) Image level object classification, (b) Bounding box level generic object detection, (c) Pixel-wise semantic segmentation, (d) Instance level semantic segmentation [2].본 논문에서는 딥-러닝을 적용하여 이미지 학습 모델 을 선행적으로 학습하고, 안드로이드 디바이스에서 입력 되는 스트림에 대해 프레임을 각출하여 실시간으로 이미 지 분할을 수행하는 알고리즘을 설계하고 이를 구현한다.
실시간 처리를 위해 실행시간 측면을 고려한 분할 성공 률을 실험적으로 측정하고 이를 평가한다.
본 논문의 구성은 다음과 같다. 2장에서 이미지 분할에 대한 기존 알고리즘과 딥-러닝 기반의 이미지 분할 기법 을 살펴보고, 3장에서 안드로이드 플랫폼에서 실시간으로 분할이 가능한 Tensorflow 기반의 이미지 분할 구조를 기 술하고, 이를 프로토타입으로 구현하여 검증하고, 4장에서 결론으로 마무리한다.
2. 이미지 분할 관련 기법들 2.1 기존의 이미지 분할 알고리즘
과거에 일반적으로 사용되었던 이미지 분할 알고리즘 들은 사용자의 개입, 전문적 지식이 요구되어, 딥-러닝 기 반 기술보다 효율성에서 떨어지는 단점이 있었다. 여기에
해당하는 부류는 주로 임계값, K-평균 군집화, 히스토그램 기반 이미지 분할, 엣지 검출 등의 알고리즘을 활용하였 다[3, 7]. 임계값 활용 기술은 이미지를 전경과 배경으로 나누고 지정된 임계값을 기준으로 픽셀을 두 레벨 중 하 나로 분리하여 객체를 분리한다. K-평균 군집화 알고리즘 은 데이터의 그룹을 식별하고 변수 K를 그룹 수로 나타 내어, 기능 유사성에 따라 각 데이터 픽셀을 그룹 중 하 나로 할당한다. 미리 정의된 그룹을 분석하지 않고 클러 스터링을 통해 유기적으로 그룹을 형성하여 처리속도를 향상시킨다. 히스토그램 기반 분할 방법에서는 히스토그 램을 사용하여 그레이 레벨을 기준으로 픽셀을 그룹화한 다. 배경이 복잡하지 않은 이미지는 객체와 배경으로 쉽 게 구분될 수 있다. 히스토그램 분포에 따라, 피크 값이 높으면 배경으로, 피크 값이 낮으면 주로 이미지 내의 객 체로 분류된다. 엣지 검출 방법은 밝기의 급격한 변화와 불연속성을 식별하여 엣지를 검출하고 불연속 점을 곡선 세그먼트로 배열시켜 분할한다.
2.2 딥-러닝 기반 이미지 분할 알고리즘 최근에는 딥-러닝 기술을 활용하는 연구가 지속적으로 발표되고 있으며, 이미지 분할에 사용되는 대표적인 딥- 러닝 구조는 Convolutional Neural Networks (CNN), Fully Convolutional Networks (FCN), DeepLab, SegNet, AlexNet 등이 있 다. CNN 기법에서는 CNN 입력으로 이미지 세그먼트를 받아, 픽셀에 레이블을 지정한다. CNN 은 전체 이미지를 한번에 처리할 수 없는 단점이 있으며, 전체 이미지 매핑 시에, 여러 픽셀의 작은 필터를 스캐닝하여, 처리 시간 측 면에서 단점이 있다. FCN 방식은 기존의 CNN이 갖는 입 력 크기 제어의 단점을 보완하면서 회선 레이어를 사용 하여 다양한 입력 크기를 처리하며, 향상된 실행 시간을 보인다. 최종 출력 레이어는 보다 큰 수용 필드를 가지며, 모든 픽셀을 분류하여 객체의 위치를 포함하여 이미지 컨텍스트를 결정한다. DeepLab는 신호 조각화를 제어하면 서 이미지 분할을 수행하여 처리하는 샘플 수와 데이터 양의 감소 효과를 얻는다. 또한 이미지 처리 기능을 서로 다른 스케일로 집계하는 다중 스케일 컨텍스트 기능 학 습을 지원하며, 기능 추출을 위해 ImageNet 에서 제공하는 사전 훈련된 ResNet를 사용한다. 이는 규칙적인 컨볼류션 보다는 확장된 형태를 갖으며, 각 컨볼류션의 다양한 팽 창률로 인해 ResNet 블록은 다중-스케일 상황정보 캡쳐가 가능하다. SegNet는 의미적 픽셀 단위 분할 기법이며, 딥 인코더와 디코더를 기반한 구조를 갖는다. 입력 이미지를 낮은 차원으로 인코딩하고 디코더의 방향 불일치 기능으 로 이미지를 복구하는 작업을 포함한다. 디코더 측면에서 세그먼트화 이미지를 생성한다. AlexNet 신경망 구조는 파
이용환 · 김영섭
반도체디스플레이기술학회지 제19권 제2호, 2020 90
라미터의 개수와 차원을 줄이는 계층을 가지며 완전 연 결 레이어(Fully Connected Layer) 에서 자세한 위치 정보를 잃게 되는 단점으로 시멘틱 세그멘테이션에는 적합하지 않다. 보완 방법으로 풀링과 완견 연결 레이어 제거, 일정 한 패딩 컨볼루션을 적용할 수 있으나, 메모리 문제와 계 산 비용 증가로 애플리케이션 적용성이 떨어진다.
3. 이미지 분할 구현
본 절에서는 Tensorflow에서 구현된 가장 성능이 우수한 최신 시맨틱 이미지 분할 모델인 DeepLab-v3+[9] 의 오픈 소스를 기반으로 개별화된 학습 모델을 구축하고 컨볼류 션 필터를 일부 수정하여 안드로이드 플랫폼에서 실시간 동작하도록 개선한다.
3.1 오픈소스 활용
오픈소스로 서버 측에서 제공되는 DeepLab 릴리스 버 전은 CNN 백본 아키텍쳐를 기반으로 DeepLab-v3+ 모델을 포함하고 있으며, Pascal VOC 2012 및 Cityscapes 벤치마크 시맨틱 세그멘테이션 작업에 대해, 사전에 훈련된 모델과 Tensorflow 교육 모델, 평가코드를 함께 제공하고 있다.
2015년 처음 구현하여 발표된 DeepLab 모델[4]는 CNN 기능 추출기와 객체 스케일 모델링을 개선하고, 상황 정보의 신 중한 동화, 개선된 교육 절차 및 강력한 HW, SW 지원을 통 해 DeepLab-v2로 개선하여 발표하였으며[5], DeepLab-v3와 DeepLab-v3+는 효과적인 디코더 모듈을 추가하여 객체 경 계에 따른 세그먼트화 결과를 세분화하여 확장하였다. 또 한 심층 분리(Depth-wise) 컨볼루션을 통해 공간 피라미드 풀링 및 디코더 모듈 적용을 통해 시멘틱 세그멘테이션을 보다 빠르게 처리되는 인코더-디코더 모듈을 구성하였다 [6]. Figure #은 본 연구에서 기초로 활용된 DeepLab-v3+ 기반 의 세그멘테이션 모듈 구성도이다. 일반적으로, 완전 연결
Fig. 2. Encoder-Decoder of semantic segmentation [2].
레이어에서의 위치 정보 손실과 메모리 부하 및 계산 비용 을 고려하여 다운-샘플링과 업-샘플링 형태를 구성하며, 통 상적으로 각각의 모듈을 인코더와 디코더를 명명한다.
3.2 수정 제시 모델
인코더를 통해 나온 특징맵은 일반적으로 원본 이미지 의 해상도보다 16배 작은 값을 가지며(output stride=16), 이 미지 디테일의 효과적인 복구를 위해 디코더에서 저급의 특징맵을 결합하여 처리한다. DeepLab-v3에서의 8x를 v3+
에서는 변형된 Xception를 인코더에 적용하여 분리된 컨 볼루션으로 변경하고 4x를 2단계로 나눠 적용한다. 본 연 구에서는 이러한 Xception 모델을 8x를 확대한 2단계 분리 컨볼루션 변화를 적용하고 마지막 블록에서 stride를 제거 하여 변경된 구조로 설계 구현한다. 디코더의 저급의 특 징맵에서는 1x1 Conv를 그대로 반영하며, 실험을 통해 채 널의 개수가 48일 때 가장 좋은 결과를 내어, 채널 수를 48로 사용한다.
3.3 학습 모델
학습 모델은 Supervised learning에 속하기 때문에 가중치 학습을 위해 각각의 학습 이미지에 정답 레이블을 할당 해야 한다. 정답 레이블은 각 객체의 클래스 레이블과 경 계 영역 표시 사각형을 쌍으로 구성되며, 이를 주석 (Annotation)이라 한다. 이미지에 주석을 할당하기 위해 파 이썬과 Pyqt 기반의 labelImg 툴을 사용하여, 제공되는 이 미지 데이터베이스와 레이블을 검증한다. 얼굴 인식 연구 에서 공용으로 많이 활용되는 Labelled Faces in the World (LFW) dataset을 기초하여 얼굴 이미지 학습 모델을 구축한 다[10]. LFW은 얼굴 검증 알고리즘의 성능 평가에서 많이 활용되는 데이터셋으로, 제한 없는 환경에서 얼굴 인식을 실험하기 위해 13,000여 개의 이미지와 이와 관련된 레이 블을 포함하며, 인터넷에서 수집되었다. labelImg를 통해 각각의 이미지와 레이블에 대한 검토를 데이터 정제화를 수행하였다.
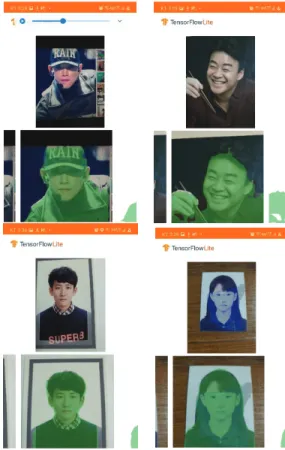
정제된 데이터를 대상으로 학습 모델을 구성하고 안드 로이드 스튜디오에서 임포트 패키지를 통해 프로토타입 프로젝트를 완성시킨다. 안드로이드 디바이스에서 직접 적 동작 검증을 위한 실험 결과 화면은 Fig. 3에 있다.
구현에 기초가 된 DeepLab-v3+ 모델은 성능적으로 output stride에 큰 영향을 받는 것으로 분석되며, 이미지 분류 및 객체 인식에서는 32 수준이여도 충분하지만, 디테일이 필 요한 이미지 분할에서는 이보다 작은 16 또는 8 수준으로 적용하는 것이 세그먼트 성능상 좋은 것으로 검토된다.
딥-러닝을 활용한 안드로이드 플랫폼에서의 이미지 시맨틱 분할 구현
Journal of KSDT Vol. 19, No. 2, 2020 91
Fig. 3. Screenshot of implementation running results.
4. 결 론
본 논문에서는 Tensorflow 기반의 이미지 시맨틱 분할 알고리즘을 구현하고 안드로이드 디바이스에서 실시간 분할 처리 동작을 실험적으로 검증하였다. 구현 알고리즘 은 기존의 오픈소스로 제공되는 DeepLab-v3+ 를 기초하여 Xception 분리 컨볼루션 모델에서 처리속도 개선을 위해 stride를 제거하고 확장된 콘볼루션 필터를 적용하여 기존 알고리즘을 변형하여 구현하였다. 또한 얼굴 인식에서 공 용적으로 널리 사용되는 데이터베이스를 기초하여 개별 학습 모델을 구축하여 적용하였다. 구현 알고리즘은 삼성 갤럭시 노트10에서 실험적으로 동작하였으며, 실시간 처 리 동작에 충분함을 실험적으로 검증하였다.
현재는 학습 모델 구축의 시간 단축을 위해, 얼굴 인식 연구분야의 공용 데이터셋을 활용하였고 사람 얼굴 중심 으로만 동작할 수 있는 구조이다. 향후로, 보다 범용성 높 은 개별 학습 데이터를 충분히 확보하여 구현 알고리즘 의 범용성을 높일 필요가 있으며, 분할 정밀도 측면에서 객체에 해당하는 정교한 경계를 그리는 visualization 향상 을 위한 노력이 필요하다.
감사의 글
본 연구는 2018년도 정부(미래창조과학부)의 재원으로 한국연구재단의 지원을 받아 수행된 기초연구사업임(과 제번호: 2018R1A2B6008255).
참고문헌
1. Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, Xindong Wu, “Object Detection with Deep Learning: A Review”, IEEE Transactions on Neural Networks and Learning Systems, 2019.
2. Li Liu, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu, Matti Peitikainen, “Deep Learning for Generic Object Detection:Asurvey”, International Journal of Computer Vision, vol.128, pp.261-318, 2020.
3. Yang Peng Zhu, Peng Li, “Survey on the Image Segmentation Algorithms”, Proceedings of the International Field Exploration and Developoment Conference, pp.475-488, 2017.
4. Liang-Chieh Chen, George Papandreou, Iasonas Kok- kinos, Kevin Murphy, and Alan L. Yuille, “Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs”, Proceeding of ICLR, 2015.
5. Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille, “Deeplab:
Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs”, Computer Vision and Pattern Recognition, 2017.
6. Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam, “Rethinking Atrous Convolution for Semantic Image Segmentation”, arXiv:1706.05587, 2017.
7. Rahul Basak, Surya Chakraborty, Satarupa Biswas,
“Image Segmentation Techniques: A Survey”, Com- puter Science, 2018.
8. Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam, “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation”, ECCV, 2018.
9. Website, https://github.com/tensorflow/models/tree/mas ter/research/deeplab, available on 2020.
10. Website, https://www.kaggle.com/jessicali9530/lfw-da taset, available on 2020.
접수일: 2020년 6월 23일, 심사일: 2020년 6월 24일, 게재확정일: 2020년 6월 24일
![Fig. 1. Recognition problems related to generic object detec- detec-tion: (a) Image level object classification, (b) Bounding box level generic object detection, (c) Pixel-wise semantic segmentation, (d) Instance level semantic segmentation [2]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4722781.510030/2.825.96.403.301.512/recognition-problems-classification-bounding-detection-segmentation-instance-segmentation.webp)
![Fig. 2. Encoder-Decoder of semantic segmentation [2].](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4722781.510030/3.825.93.405.788.969/fig-encoder-decoder-of-semantic-segmentation.webp)