최근 산업계 전반에 걸쳐 데이터 활용을 기반으로 경제적, 기술적 성과를 더 높은 수준으로 끌 어올리고자 하는 노력이 이어지고 있다. 4차 산업혁명으로 불리는 이러한 변화는 정보/통신기술의 발전을 통한 데이터의 증가, GPU등의 계산 하드웨어 발전, 그리고 2016년 알파고로 대표되는 새로 운 딥러닝 알고리즘들의 개발등을 통해 그 가능성을 높여왔다. International Data Corporation의 보 고서에 따르면, 데이터의 축적 속도는 매년 증가하고 있으며 2025년 기준 축적될 데이터의 추정치 는 175제타바이트로 2018년 대비 5배 이상의 양적 성장을 보일 것으로 예상된다고 한다.
이러한 데이터의 홍수 속에서, 전 세계의 모든 국가 및 주요 산업 분야들은 각자의 상황에 맞는 데이터 활용 기술 개발에 나서고 있다. 우리나라 제조산업의 큰 축을 담당하고 있는 화학공학분야 에서도 역시 인공지능을 활용한 데이터 활용 기술들이 주목받고 있는데, 기존 화학공학의 핵심 아 이디어인 공정/소재/나노기술과 데이터를 활용하는 인공지능 신기술의 융합이 화학공학의 사회적 난제인 에너지/환경 분야 문제해결에 도움이 될 것으로 기대하고 있다.
본 특별기획에서는 국내외 화학공학 분야에서 인공지능 기술이 도입된 사례로 (1) 화학 공정 운 전 및 신물질 탐색을 위한 강화학습 알고리즘, (2) 고성능 금속유기골격체의 개발을 위한 빅데이터/
기계학습과 분자모델링의 융합연구, 그리고 (3) 시간/공간 복잡도가 커지는 화학/생물공학 데이터 분석을 위한 머신러닝 적용에 관한 내용을 설명하고자 한다.
인공지능 기술과 화학공학
김지한 KAIST [email protected]
특 별 기 획 ( I )
최근 사물인터넷(IoT), 인공지능(AI), 빅데이터 (Big data) 등 첨단 정보통신기술의 발전은 사회·경 제 전반에 혁신적인 변화를 가져오고 있으며, 화학 산업에서도 이를 융합하여 공정을 고도화하려는 시 도가 국내외적으로 활발히 이뤄지고 있다. 특별히 2016년 알파고의 등장 이후, 인공지능 기술 중 강화 학습이 널리 알려지게 되면서 이를 바둑을 넘어 다 양한 산업 분야에 적용하기 위한 연구가 본격화되었 고, 최근 화학 산업에서도 이를 활용하여 공정의 여 러 의사결정들을 최적화하기 위한 연구들이 수행되 고 있다. 본 고에서는 강화학습에 대해 개괄적으로 소개하고, 화학 공정 및 신물질 탐색에의 활용 사례 와 향후 연구방향에 대해 서술하고자 한다.
1. 강화학습
강화학습(Reinforcement Learning, RL)은 인공 지 능의 한 분야로, 에이전트(Agent)가 환경과의 상호 작용을 통해 목적을 달성하기위한 최적의 행동 정 책을 스스로 학습하는 방법이다. 에이전트가 행동 (Action, at)을 취하면 환경에서의 상태(State, st)가 변 화하는데(예. 로봇 위치의 이동), 이를 수식으로 나 타낸 것을 상태변환함수(State transition function) 또 는 상태변환확률(State transition probability)이라고 부 른다. 그리고 다음 상태와 그에 대한 보상(Reward, rt) 이 에이전트에게 주어진다(그림 1 참조). 에이전트는 주어진 상태와 보상으로 학습한 정보를 기반하여 다 음 행동을 결정한다. 에이전트의 학습 목표는 가치 함수(Value function)라 불리는 미래 보상의 합에 대 한 기대값을 최대화하는 최적 정책(Policy)을 학습하
는 것이다. 여기서 정책이란, 현재 상태에서 선택할 행동의 확률분포 또는 행동 값을 의미한다.
에이전트는 환경과 상호작용을 하면서 시행착 오법(Trial-and-error)를 통해 점차적으로 정책을 업데이트한다. 가장 기본적인 방법은 동적 계획법 (Dynamic prograaming)을 이용하는 방법, 몬테 카 를로(Monte Carlo)방법과 시간차 학습(Temporal difference)방법이 있다[1]. 동적 계획법은 환경에 대 한 완벽한 정보를 가지고 있을 때에 적용 가능하 며, 문제의 차원이 커질 경우 차원의 저주(Curse of dimensionality)에 빠지게 된다. 몬테 카를로 방법 은 환경의 모델을 몰라도 여러 에피소드를 통해 얻 은 보상을 통해 가치함수 값을 추정하여 점차적으로 참 가치함수를 얻어 이를 기반으로 최적 정책을 찾 아낸다. 하지만 이 방법은 가치함수를 업데이트 하 기 위해 하나의 에피소드가 종료될 때까지 기다려 야 하며, 에피소드의 길이가 길거나 무한한 경우에 는 적합하지 않다. 시간차 학습 방법은 부트스트랩 (Bootstrap)을 통해 가치함수의 업데이트가 실시간 으로 이루어진다. 이 학습 방법 중 행동 가치 함수
화학 공정 운전 및 신물질 탐색을 위한 강화학습 알고리즘
변하은
1, 유하은
1, 천무진
1, 이재형
1*1
KAIST 생명화학공학과
*[email protected]
그림 1. 강화학습 에이전트와 환경의 상호작용.
(Q-function)을 학습하고 탐욕 정책을 사용하는 방 법이 SARSA이고, on-policy에서 발생할 수 있는 문 제를 해결한 것이 Q-러닝(Q-learning) 방법이다. 또 한 상태 공간의 크기가 커지면 가치 함수 계산이 어 려워지는데, 이를 심층인공신경망을 통해 근사하여 매우 큰 상태 공간에서도 학습이 가능하도록 한 것 이 Deep-SARSA와 Deep Q-learning (DQN)이다. 반 면 가치 함수를 토대로 학습하지 않고, 상태에 따라 바로 행동을 선택하도록 정책을 학습하는 정책 기 반 강화학습(Policy-based RL) 방법이 있다. 그리고 가치함수와 정책함수를 함께 학습하는 액터-크리틱 (Actor-critic) 방법론이 있으며, 다양한 환경에서의 학습을 통해 발전시킨 방법으로 A3C(Asynchronous advantage actor-critic) 방법이 존재한다[2].
2. 공정 운전을 위한 강화학습
강화학습은 로봇, 컴퓨터 게임, 온라인 광고 등 다 양한 분야에서 주목할 만한 성과를 보이고 있다. 공 정 운전 분야에서는 2000년대 초, 근사 동적 계획법 (Approximate dynamic programming, ADP)라는 이름 으로 강화학습 적용에 대한 연구가 이루어졌다[3].
그리고 복잡한 화학 공정 제어를 위해 연속 시간 비 선형 시스템 최적 제어를 위한 강화학습 방법론들이 제안되었다. 최근에는 기존의 모델 예측 제어 또는 모델 기반 강화학습의 한계를 극복하기 위한 데이터 기반의 강화학습 방법론들이 적용되었다. 대표적으 로 Lee의 논문에서는 입력-출력 데이터를 사용하여 근사 모델을 학습하고 이를 이용해 제어기 에이전트 를 학습시키는 방법을 제안했다[4].
본 연구팀은 회분식 공정 제어를 위한 강화학습 알고리즘 및 단계 구분 전략을 제안했다[5]. 회분식 공정은 고분자와 같이 낮은 용량의 고부가가치 제품 생산에 널리 사용되는 방법으로, 안전하고 경제적인 방법으로 제품의 최종 품질을 만족시키기 위한 운전 을 필요로 한다. 하지만, 비정상(Non-stationary) 운 전이 필요하며, 비선형 역학을 보이고, 경로 및 최종 제약 조건의 존재와 같은 고유한 특성으로 인해 제
어에 어려움이 있다. 기존에 회분식 공정 제어를 위 해 가장 널리 사용되는 제어 방법은 비선형 모델 예 측 제어(Nonlinear model predictive control, NMPC)이 다. 하지만 이 방법은 모델을 기반으로 하기 때문에 모델에러나 불확실성이 큰 경우 만족스럽지 못한 성 능을 보일 수 있다. 강화학습은 모사 또는 실제 운전 데이터를 활용하여 데이터를 통해 불확실성에 대해 서도 학습할 수 있어 이 문제를 해결하기위한 대안 이 될 수 있다. 하지만 강화학습을 회분식 공정 제어 에 효과적으로 적용하기 위해서는 보상 함수의 디자 인과 공정의 특성을 반영한 학습 방법이 필요하다.
따라서 본 연구팀은 생산성과 제약식을 반영한 보상 함수를 디자인하고, 기존의 Deep deterministic policy gradient (DDPG) 알고리즘을 몬테 카를로 방식으로 수정하여 보다 안정적이고 효과적인 학습이 가능하 도록 하였다. 그리고 제안한 방법을 폴리올 생산 회 분식 공정 문제에 적용하여 그 성능을 입증하였다.
3. 신물질 탐색을 위한 강화학습
원하는 성질을 갖는 새로운 물질 혹은 소재를 개 발하는 것은 공정에서 매우 중요하지만 어려운 문 제로, 일반적으로 많은 시간과 비용이 요구된다. 따 라서 신물질 탐색에 드는 시간과 비용을 줄이기 위 한 지능적인 탐색 전략이 필요하며, 다양한 화학, 의료, 재료 분야에서 기계학습 기법을 접목시키려 는 시도들이 이뤄지고 있다. 효율적인 물질 탐색 에 널리 적용되는 기계학습 기반의 방법론으로 베 이지안 최적화가 있다. 베이지안 최적화(Bayesian optimization)는 전역 최적화(Global optimization) 기 법으로, 함수의 평가에 많은 시간과 비용이 요구될 때 주로 사용된다. 이 방법은 가지고 있는 데이터를 기반으로 목적함수를 추정하는 기계학습 모델을 만 들고 모델 추정값의 평균과 분산을 활용하여 최적 의 다음 실험 조건을 추천한다. 이 때, 차기 실험 조 건을 선정하기 위한 기준으로 획득 함수(Acquisition function)를 사용하며, 이는 이전에 실험해보지 않 은 영역을 탐색해보는 것(탐험)과 현재 모델이 예측
특 별 기 획 ( I )
하기로 원하는 물성에 가장 가까울 것 같은 영역을 탐색해보는 것(탐사), 즉 탐험과 탐사의 균형을 이 루도록 하는 형태를 가진다. 베이지안 최적화는 실 험과 추천을 반복적으로 수행하는 방식으로 사용 되며 이를 통해 실험 횟수를 최소화하는 것을 목표 로 한다. 베이지안 최적화는 유기-무기 분자, 합금, 광전 소재, 고분자 등 다양한 물질 탐색 문제에 활 용되어 그 성능을 입증하고 있다[6-8]. 그 예시로, Xue 연구 그룹은 낮은 온도 이격을 갖는 기억 형상 합금 탐색 문제에 베이지안 최적화를 적용하여 대 략 80만개의 조성 후보군 중 36개의 새로운 조성을 테스트하였으며, 기존 데이터에 있던 22개의 조성 보다 더 낮은 온도 이격을 갖는 조성 14개를 찾는데 성공하였다[6].
한편, 일반적으로 베이지안 최적화에서 사용하 는 획득 함수는 분석적으로 얻어진 형태가 아닌 경 험적으로 얻어진 형태이며, 미래의 의사결정들에 대한 영향을 고려하지 않고 현재의 결정만을 고려 하는 One-step optimal 형태로 짧은 시야로 의사결 정을 한다는 한계가 존재한다. 미래의 의사결정들 까지 고려하여 장기적으로 최적인 의사결정 문제 의 해를 분석적으로 구하는 방법으로는 확률적 동 적 계획법(Stochastic dynamic programming)이 있다.
하지만 이 방법은 실제 규모의 문제에서 계산이 거 의 불가능하며 근사적으로 접근하여 풀어야 한다.
이를 위해, 강화학습을 접목하여 효율적으로 확률
적 동적 계획법을 근사하면서도 미래를 내다보는 Multi-step ahead 의사결정을 통해 기존 베이지안 최 적화보다 더 최적에 가까운 탐험과 탐사를 수행하 는 방법을 제안할 수 있다. 이는 결과적으로 더 적 은 시간과 비용으로 원하는 목적(원하는 성질을 가 지는 물질 탐색)을 달성할 수 있게 한다. 하지만 아 직 이러한 방법을 물질 탐색에 적용한 사례 연구는 거의 수행된 적이 없다.
최근 Zhou 연구 그룹은 심층 강화학습을 미세 액적 반응 최적화 문제에 도입하여 수율을 최대화 하는 반응 조건을 최소한의 실험으로 찾기 위한 연 구를 수행하였다[9]. 그 결과 제안한 방법은 30분만 에 최적 반응 조건을 찾는 것을 확인할 수 있었다.
Sanchez-Lengeling 연구 그룹은 분자 설계 문제에 생성적 적대 신경망(Generative adversarial network, GAN)과 강화학습을 결합한 탐색 방법인 ORGANIC 을 제안하였다[10]. 제안한 방법은 GAN으로 새로운 분자 구조를 생성하면 생성된 분자 구조가 설정한 목표에 근접한지 여부에 따라 보상을 주는 방식으로 강화학습을 사용한다 (그림 2 참조). 이는 신약 개발 및 광전 소재 설계 문제에 적용되어 기존 유전 알고 리즘(Genetic algorithm)보다 좋은 성능을 보였다. 이 처럼 강화학습은 새로운 분자 구조, 새로운 조성을 찾는 문제에 효과적으로 적용되고 있으며, 베이지안 최적화 및 GAN과 같은 기존 방법들과 결합될 때 더 큰 시너지를 낼 것으로 기대된다.
그림 2. ORGANIC 알고리즘 개요도[10].
4. 맺음말
강화학습은 시스템과의 상호작용을 통해 얻어진 데이터를 기반으로 최적의 의사결정 전략을 제안한 다. 이는 소재 개발부터 운전 조건 결정까지 공정의 여러 의사결정 전략을 개선하기 위해 다방면으로 활 용될 수 있는 잠재성을 지닌다. 본 고에서는 공정 의 사결정에서의 강화학습의 활용 사례를 소개하였다.
학계 및 산업계에서 강화학습을 기존 방법들과의 상 보적으로 활용하는 연구가 활발해져서 그 잠재성이 성공적으로 실현되기를 희망한다.
참고문헌
[1] Sutton, R.S., Barto, A.G., 2018. Reinforcement Learning: An Introduction. The MIT Press.
[2] Shin, J., Badgwell, T.A., Liu, K.H., Lee, J.H., 2019.
Reinforcement learning-overview of recent progress and implications for process control. Computers &
Chemical Engineering 127, 282-294.
[3] Lee, J. M., Lee, J. H., 2004. Approximate dynamic programming strategies and their applicability for process control: A review and future directions.
International Journal of Control, Automation, and Systems, 2(3), 263-278.
[4] Lee, J.M., Lee, J.H., 2005. Approximate dynamic
programming-based approaches for input-output data- driven control of nonlinear processes. Automatica 41 (7), 1281–1288.
[5] Yoo, H., Kim, B., Kim, J. W., Lee, J. H., 2021.
Reinforcement learning based optimal control of batch processes using Monte-Carlo deep deterministic policy gradient with phase segmentation. Computers &
Chemical Engineering 144, 107133.
[6] Xue, D., Balachandran, P.V., Hogden, J., Theiler, J., Xue, D. and Lookman, T., 2016. Accelerated search for materials with targeted properties by adaptive design.
Nature communications, 7(1), pp.1-9.
[7] Balachandran, P.V., Kowalski, B., Sehirlioglu, A. and Lookman, T., 2018. Experimental search for high- temperature ferroelectric perovskites guided by two- step machine learning. Nature communications, 9(1), pp.1-9.
[8] Pruksawan, S., Lambard, G., Samitsu, S., Sodeyama, K. and Naito, M., 2019. Prediction and optimization of epoxy adhesive strength from a small dataset through active learning. Science and technology of advanced materials, 20(1), pp.1010-1021.
[9] Zhou, Z., Li, X. and Zare, R.N., 2017. Optimizing chemical reactions with deep reinforcement learning.
ACS central science, 3(12), pp.1337-1344.
[10] Sanchez-Lengeling, B., Outeiral, C., Guimaraes, G.L.
and Aspuru-Guzik, A., 2017. Optimizing distributions over molecular space. An objective-reinforced generative adversarial network for inverse-design chemistry (ORGANIC). ChemRxiv, 2017.
고성능 금속유기골격체의 개발을 위한 빅데이터/기계학습과 분자모델링의 융합연구
이용진 인하대학교 화학공학과 [email protected]
1. 서론
나노 다공성 소재 (Nanoporous materials)는 일반 적으로 100 nm 미만 크기의 규칙적인 혹은 무질서 한 배열의 기공구조를 가지는 다공성 재료이다. 나 노다공성 소재는 구성 성분들의 화학적 요소와 특성 에 따라 여러 종류가 존재하는데, 대표적으로는 제 올라이트(Zeolite), 공유결합성유기골격체(Covalent
organic framework, COF), 그리고 유기금속골격체 (Metal-organic framework, MOF)등이 있다. (그림 1)
이중, MOF는 금속 이온 또는 산소원자와 연결된 금속이온 클러스터와 유기리간드의 배위결합으로 형성되는 결정성 소재로, 상업적으로 응용이 많이 되는 대표적 나노 다공성 소재인 제올라이트와 비교 하였을 때 고표면적, 기공크기 외에도 표면화학적특
특 별 기 획 ( II )
성 등 여러가지 장점들을 가지고 있다. 더나아가 금 속이온 클러스터와 유기리간드를 다양하게 조합하 여 광범위한 물리적/화학적 특성들을 가지는 구조를 만들 수 있기 때문에, MOF는 응용 분야에 맞춤형 설 계가 가능한 이상적인 재료로 가스 분리 및 저장, 촉 매, 센서 등 다양한 응용분야에서 주목을 받고 있다.
(그림 1)
그러나 뛰어난 화학적 자유도라는 장점은 한편으
로는 새로운 MOF를 개발하는 실제적인 측면에서는 큰 도전과제가 되기도 하는데, 바로 MOF 구조의 방 대한 화학적 가능성 중에서, 적은 부분만을 현실적 으로 합성/시험할 수 있기 때문이다. 이는 MOF 연구 뿐만 아니라, 원하는 응용분야에 적합한 고성능 소 재를 개발함에 있어서 우리가 겪게 되는 흔한 도전 중 하나로, 방대한 재료 공간 (Material space)에서 최 적의 속성을 가진 재료를 효율적으로 탐색하는 새로
그림 1. 나노다공성 소재의 종류와 주요 응용분야.
그림 2. 재료의 직접설계와 역설계 전략 비교.
운 전산 모사 방법의 개발이 하나의 해결방안이 될 수 있다. 이러한 관점에서 주목받는 전산모사 방법 이 소위 "재료의 역설계 (Inverse design of materials)”
전략이다. (그림 2) 재료를 먼저 합성하고, 그 후에 물성측정을 통해 적합한 응용분야를 찾는 “재료의 직접설계(Direct design of materials)”와 달리, 역설계 는 원하는 물성값을 먼저 설정하고, 재료를 맞춤형 으로 설계/최적화하는 접근법으로, MOF의 방대한 재료공간으로부터 최적의 재료를 식별하는 과정의 시행착오를 줄이고, 재료의 합성에 드는 비용과 시 간을 절약할 수 있다.
재료의 역설계 전략이 소재의 개발에 효과적으로 적용되기 위해서는 화학적 구조와 재료의 물성값을 연결하는 복잡한 상호작용 및 숨겨진 패턴의 해석 과, 방대한 양의 재료 데이터베이스를 생성하고 처 리할 수 있는 전산 플랫폼의 구축이 필요하다. 이러 한 이슈는 최근 빠르게 성장하는 인공 지능과 빅데 이터 방법론을 통해 해결되고 있으며, 관련 컴퓨터 기술 및 고속 대량 실험 장비의 발전과 연계되어, 화 학, 화학공학 및 에너지 관련 재료 등 다양한 분야에 역설계 전략이 적용되고 있다. 본고에서는 이중 최 근 MOF 분야에 적용된 재료의 역설계 전략 기술과 연구 현황을 소개하고자 한다.
2. 재료의 역설계 방법론
재료의 역설계를 위한 첫 번째 접근법은, 일종의
‘Data-driven discovery’로 기존 화학구조들로부터 얻 어진 구조와 물성 데이터들을 분석하여 얻어진 구 조-물성간의 트렌드를 바탕으로 아직 물성 검증이 안 된 방대한 양의 후보군들로부터 유망한 구조들 을 찾아내는 ‘가상스크리닝(High throughput virtual screening, HTVS)’이다. HTVS를 위한 핵심 요소는, 화학적 구조와 물성을 관계지어주는 정확한 기술어 (Descriptor)의 개발이다. 기술어는 재료들을 인식하 고, 쉽게 얻을 수 있는 재료의 정보로부터 응용분야 의 성능물성을 측정 없이 예측하게 하는 일종의 재 료 지문(Fingerprint)의 역할을 하는 것으로, 스크리
닝 기법의 성공을 위한 핵심적인 요소가 된다.
두 번째 재료의 역설계 방법은 ‘Functionality- driven discovery’로, 재료의 기능성 공간(Functionality space)에서 물성의 변화 추세와 방향 및 곡률을 탐색 하여, 원하는 성능물성을 만족하도록 화학구조를 최 적화하는 방법이다. 이러한 방법은 원하는 물성을 가진 화학구조를 찾는 과정에서 일반적으로 HTVS 보다 적은 수의 구조를 테스트하게 되는 장점이 있 는 일종의 ‘맞춤형 설계(Tailor-made design)’전략이라 고 할 수 있다.
3. 재료의 역설계 전략을 통한 고성능 나노다공성 소재의 개발 연구
3.1. 빅 데 이 터 기 반 재 료 지 문 의 개 발 과 나노다공성 소재 데이터베이스의 HTVS 나노 다공성 물질의 여러 응용분야들에서 재료의 성능을 결정하는 가장 주요한 요인으로 들 수 있는 것이 화학적 조성과 더불어 바로 기공구조이다. 예 를 들어 이산화탄소 포집 또는 메탄 저장과 같은 응 용 분야에서, 기공구조를 조정하는 것만으로도 나노 다공성 물질의 성능은 크게 향상 될 수 있다. 따라서 이러한 응용분야의 고성능 나노 다공성 물질을 연구 함에 있어서, 최적의 기공 구조를 식별하고 이 정보 를 사용하여 유사한 재료를 찾을 수 있는 기술어를 개발하는 것이 중요하다. 기술어를 개발하려는 일반 적인 접근법은 기공구조의 물성값들을 이용하는 것 이었는데, 개별적으로 수치화된 값들로는 재료의 복 잡한 화학적 및 물리적 특징에 대한 충분한 정보를 담아내기 어렵다는 문제점이 존재한다. 이를 해결할 수 있는 방법으로 제안되는 것이 빅데이터 분석을 기술어 개발에 활용하는 것이다.
필자는 이전 연구에서 기공 구조의 형태를 얼굴 인식기술처럼 인식하는 빅데이터 기반 재료지문을 개발하였다.(Nat. Commun., 2017, 8, 15396) 기공 구 조의 물성값들은 기공 구조에 대한 전체 정보 중 일 부를 수치화한 것으로, 그 과정에서 정보의 손실이 발생할 수 밖에 없는데 반해, 기공 구조의 형태는 그
특 별 기 획 ( II )
러한 손실이 없는 원데이터(Raw data)라고 볼 수 있 다. 기공구조 형태의 인식을 위해 토폴로지 데이터 분석(Topological data analysis, TDA)이 도입 되었는 데, TDA는 의학, 사회, 재료공학 등 다양한 분야에서 복잡하고 방대한 데이터들간의 상관관계나 중요한 특성들을 밝혀내기 위해 널리 이용되는 빅데이터 분 석방법 중 하나이다. TDA를 통해 기공구조의 형태 에 대한 정보를 바코드 형태로 얻었고, 바코드가 기 공 구조들 간의 유사성을 정량화하고 구분할 수 있 는 나노다공성 소재에 대한 기술어로 사용될 수 있 음을 검증하였다. 방대한 나노다공성 소재의 데이터 베이스로부터 실험적으로 밝혀진 고성능의 구조와 가장 유사한 구조들을 개발된 바코드를 기술어로 사 용하여 찾는 스크리닝을 통해, 추가적인 고성능 구 조들을 높은 성공확률로 밝혀낼 수 있었다. 또한, 메 탄 저장 응용분야를 예로, 빅데이터맵 분석을 통해 나노 다공성 물질들이 위상적으로 구별되는 여러 타 입으로 나눌 수 있음을 보여주었고, 그렇게 구별된 타입들은 고성능 구조를 설계하기 위해 서로 다른
최적화 전략을 필요로 한다는 것을 밝힐 수 있었다.
(그림 3)
나노다공성 소재의 물성(특히 성능물성)은 실험 적으로도 시뮬레이션으로도 측정 혹은 예측에 많은 비용과 시간이 소모되는 정보들이다. 따라서, 필자 는 그림 4에서 보이는 것과 같이 성능물성을 보다 효 율적으로 예측할 수 있는 기계학습 기반 전산플랫폼 을 개발하였다.(J. Chem. Inf. Model. 2019, 59, 4636- 4644) 이 플랫폼은 나노다공성 소재에 대해 가장 손 쉽게 얻을 수 있는 정보인 화학구조를 입력값으로 받아서, 기공 구조를 인식하는 바코드를 생성한 후, 바코드에 기반한 두 가지 형태의 기술어에 대한 기 계학습으로 구조/성능 물성을 빠르게 예측하게 된 다. 첫번째 기술어는 전체 나노다공성소재 데이터베 이스로부터 선택된 대표 세트에 대한 입력된 소재의 바코드 기반 거리의 벡터집합, 두 번째 기술어는 각 바코드로부터 추출된 가장 핵심적인 정보들의 조합 으로 얻어졌다. 선택된 트레이닝세트에 대해서 기술 어들과 성능물성간의 관계를 예측모델이 학습하게
그림 3. 빅데이터 기반 나노다공성 재료지문의 개발과 HTVS연구.
한 후, 새로 입력된 나노다공성소재의 구조/성능 물 성을 예측하였는데, 분석 결과 두 기술어를 이용하 여 MOF의 구조/성능 물성이 높은 정확도로 그리고 높은 효율성으로 예측됨을 확인하였다.
3.2. 응용분야에 특화된 고성능 MOFs를 맞춤형 설계하는 연구
HTVS는 효과적인 역설계 전략이지만, 많은 컴퓨 터 리소스를 투자하여 스크리닝을 위해 준비된 DB 의 크기에 비해, 얻어지는 고성능 소재는 일부이고
그림 5. 응용분야에 특화된 고성능 MOF를 맞춤형 설계하는 전산 플랫폼.
그림 4. 기계학습 기반 나노다공성 소재 물성 예측 플랫폼과 MOF의 물성 예측에 대한 결과.
특 별 기 획 ( II )
대부분의 구조는 원하는 응용분야와 무관한 저성능 소재라는 점은 스크리닝 기법의 효율성에 의문을 불 러올 수 있다. 이러한 측면에서, HTVS의 대안이 될 수 있는 것이 응용 분야에 따라 유망한 재료를 맞춤 형으로 생성하는 전산모사 플랫폼이다. 이러한 플랫 폼이 중요한 또 다른 이유는, 유망한 소재는 응용 분 야에 대한 성능 물성만으로 판단되지 않고, 압력, 온 도, 가스 조성 및 습도와 같은 적용 환경에 따라 재료 의 구조 및 화학적 특성에서 다양한 요구 사항을 만 족시켜야 하기 때문이다. 따라서, 새로운 재료의 개 발이 다중목적함수(Multi-objective) 문제라는 점을 고려할 때, 방대한 재료 공간에서 성능 물성을 포함 한 다양한 요구 조건을 충족하는 최적의 구조를 탐 색하며 재료를 커스터마이즈(Customize) 할 수 있는 계산 플랫폼이 중요할 수 있다.
필자는 최근 연구를 통해 원하는 대상 응용 분야에 특화된 금속 유기 골격체(Metal organic framework)의 맞춤형 설계를 위한 새로운 전산 모사 플랫폼을 그림 5에서 보여지는 것과 같이 몬테카를 로 트리 탐색(Monte Carlo tree search, MCTS)과 순환 신경망(Recurrent neural network, RNN)을 결합하여 개발하였다.(ACS Appl. Mater. Interfaces, 2020, 12, 734) 필자가 개발한 전산 플랫폼은 알파고에서 사용 된 경험적 탐색 알고리즘인 MCTS을 통해서, 주어진
조건(금속이온 클러스터, 토폴로지 정보)에 대한 최 적의 유기물 리간드를 방대한 유기물 탐색공간에서 탐색하게 된다. 본래의 MCTS가 무작위 표본추출(몬 테카를로 방법)을 통해 최적의 전략을 탐색하는 반 면, 인공신경망의 한 종류인 순환신경망(RNN)을 통 합하고, RNN을 유기물 데이터베이스에 학습함으 로써, 현재의 조합(화학구조)로부터 MCTS의 그 다 음 선택(결합될 원자)을 무작위표본추출이 아닌, 기 존 유기물 정보를 기반하여 선택함으로써 실험적으 로 구현가능성이 높은 화학구조의 설계 확률을 높 이게 된다. 만들어진 구조에 대해 분자 모델링을 통 해 처음 설정한 목표 값들에 대한 성능을 만족하는 지 검증을 하게 되고, 다시 그 정보를 역전파의 과정 을 통해 MCTS에 제공하고 다시 새로운 구조를 설계 하는 반복적인 학습 과정을 통해 최종적으로 초기 목표 값에 적합하면서도 실험적으로 합성 가능성이 높은 분자 구조를 디자인 할 수 있게 된다. 메탄 저 장 및 이산화탄소 포집 응용분야에 대한 사례 연구 (ACS Sustain. Chem. Eng., 2021, 9, 2872)를 통해, 이 러한 전산모사 플랫폼이 유망하고 새로운 금속 유기 골격체를 설계하는데 성공적이고 효율적임을 입증 하였다.(그림 6) 이전 연구들에서는 금속 유기 골격 체의 두 가지 응용분야에 대해서만 테스트를 하였지 만, 필자의 전산모사플랫폼은 원하는 응용분야에 대
그림 6. 맞춤형 MOF설계 전산 플랫폼을 이용한 메탄저장 및 이산화탄소 포집용 고성능 소재 개발 연구 결과.
한 성능 물성에 따라 알고리즘 상의 목적 함수만 변 경하면 다른 응용분야에도 쉽게 적용될 수 있는 높 은 확장성을 가지고 있어, 앞으로 다양한 소재의 개 발에 활용될 수 있을 것으로 기대된다.
4. 맺음말
MOF는 응용분야/요구 조건에 따른 맞춤형 개발 이 가능하다는 점뿐만 아니라, 금속, 무기소재, 고 분자 등 다른 소재와의 복합화도 가능하다는 점에 서 다양한 분야에서 그 응용이 주목을 받고 있다. 하 지만, 뛰어난 화학적 자유도는 한편으로는 광범위한 소재의 탐색범위라는 과제도 준다는 면에서, 기계학
습 및 빅데이터를 활용한 고성능 MOF의 역설계 연 구의 전망은 밝다고 할 수 있겠다. 게다가 여러 소재 연구들처럼 MOF개발에 기계학습 및 빅데이터 기술 을 응용하는 것이 새로운 연구 패러다임으로 초기단 계라는 점을 고려하면, 관련 기술들이 앞으로 우리 에게 제공할 소재연구에서의 발전과 영향력에 기대 를 가지게 된다. 물론, 기계학습 및 빅데이터 기술이 화학공학의 소재개발 문제에 대한 만능 열쇠가 될 수는 없겠지만, 실험, 전산모사와 더불어 하나의 연 구 도구/방법론으로 필수적인 항목이 될 수 있다는 점에서, 학계 및 연구, 산업계에서 관련 연구에 많은 관심을 가지기를 희망한다.
시간·공간 복잡도가 커지는 화학·생물공학 데이터 분석을 위한 머신러닝 적용
김재형
1, 박서정
1, 김동혁
1,*울산과학기술원 에너지화학공학과 [email protected]
1990년대 인간 게놈프로젝트에서 촉발된 DNA 염기서열 분석 기술 개발의 여파로 생명체와 바이 오촉매 연구에 근간이 되는 염기서열 분석 비용과 시간이 문자의미대로 기하급수적으로 낮아졌다. 그 결과 필연적으로 분석의 대상이 되는 데이터의 시 간·공간 복잡도(Time&space complexity)가 커져, 데이터 생산이 아닌 데이터 분석이 전체 연구개발 과정의 병목 지점이 되고 있다. 비용으로 직접 환산 되는 연구개발 기간과 인력 및 분석의 질을 높이고 자 컴퓨터공학 분야에서 주로 논의되었던 머신러닝 기법들이 바이오/생물공학 그리고 화학공학을 포함 한 여러 분야에 접목이 시도되고 있다. 울산과학기 술원(UNIST) 시스템생물학 머신러닝 실험실에서는 생물공학과 화학공학 분야에 머신러닝 기법들을 적
용하고 있으며, 그중 몇 가지 연구 내용을 소개하고 자 한다.
1. 인공지능을 활용한 단백질 구조 예측
단백질은 체내에서 수많은 필수 생체 기능을 수 행하는 유기물질이다. 수많은 단백질 중, 현재 주목 받고 있는 효소는 기질에 특이적으로 작용하여 화학 반응을 유도하는 촉매 단백질로서 높은 활성 및 상 온/상압 조건에서의 반응과 같은 특징을 지니고 있 다. 이는 온도, 압력과 매우 긴밀한 연관이 있는 화학 공정에서의 촉매와는 다르게, 생물 체내에서 공정이 진행되기 때문에 인공생물체의 배양만으로 충분히 상업적으로 활용할 수 있다.
하지만 현재 상업적으로 생산되고 있는 효소는
특 별 기 획 ( III )
자연계에 존재하는 효소에 비해 현저히 적으며 효 소의 구조적 특성과 관련이 깊다. 따라서 효소의 구 조적 특성을 이해하는 데 소비되는 인적, 시간적 자 원을 절약하고자 효소의 구조를 예측하는 인공지 능 기반 프로그램이 개발되고 있다. 그중에서도 단 백질 구조 예측 대회(Critical assessment of structure prediction) 13에서 뛰어난 성과를 거둔 알파폴드 (Alphafold)가 연구되고 있다. 알파폴드가 뛰어난 성 과를 거두었지만, 대략적인 알고리즘만 공개되었을 뿐 연구에 활용할 수 있을 정도로 자세히 공개되어 있지 않아 수많은 연구자가 이를 재현하기 위해 노 력하고 있다.
공개된 알파폴드 알고리즘은 크게 세 단계로, 특 징 추출 단계, 거리 및 각도예측 단계, 마지막으로 포 텐셜 함수를 활용한 구조 예측이다. 특징 추출 단계
는 단백질 정보은행 데이터베이스(Protein data bank, PDB)를 통해 학습시킨 신경망을 활용하기 위해 예 측하고자 하는 단백질 아미노산 서열의 규칙 및 특 징을 추출하는 작업이다. 필수적으로 사용된 특징 은 총 15개로, 아미노산의 서열 데이터뿐만 아니라 각 잔기별 분포 확률과 같은 통계적인 내용이 포함 된다. 또한 PSI-BLAST와 HHBlits라는 다중 서열 정 렬 프로그램을 활용하여 목표 단백질과 유사한 서 열을 지닌 데이터베이스의 단백질을 선정하여 정렬 을 통해 규칙을 찾아 데이터를 확보할 수 있다. 그 후, 기계학습에 사용되는 Python의 모듈 중 하나인 tensorflow에 활용하기 위해 tfrec라는 데이터 파일을 사용하여 pytorch에 비해 압도적인 속도를 확보할 수 있다.
두 번째 단계인 거리 및 각도예측 단계에서는 Deep neural network(DNN)를 활용하여 출력 네트 워크를 통해 Distogram, Torsions, 그리고 Secondary structure를 예측할 수 있다. 이 모델의 Distogram은 2~22Å 사이의 거리를 0.5Å 간격으로 총 40개의 bins로 나누었으며, 완전 연결 네트워크를 연결하여 Distogram을 예측하고 다중작업 학습으로 Torsions, 그리고 Secondary structure도 예측하였다.
단백질 구조 예측의 마지막 단계는 포텐셜 함수 를 통한 구조 예측이다. 3차 구조의 예측에 Rosetta 프로그램이 사용되었으며, 이 프로그램을 통해 수많 은 단백질 구조들이 생성된다. 그중 가장 안정적인
그림 1. 기하급수적으로 낮아지는 DNA 분석 가격.
그림 2. 알파폴드 알고리즘 모식도.
단백질 구조를 확보하고자 다른 DNN을 학습하였다.
이를 반복 시행하여 가장 안정적인 단백질 모델을 선정하여 결과로 출력하였다.
단백질 모델에는 Template-based modelling(TBM), Free modelling(FM)으로 나뉠 수 있다. TBM은 유사 한 서열을 지닌 단백질의 구조가 공개된 상태인 경 우의 모델링을 의미하며 FM은 아무 정보가 없는 상 태에서 서열만 주어졌을 때의 모델링이다. FM의 경 우 참고할 만한 데이터가 없으므로 TBM의 경우보 다 무척 복잡하지만 구조 부분 어셈블리(Fragment assembly)를 통해 정확도를 높이는 방법을 채택하였 지만, 여전히 TBM과 비교해 상대적으로 낮은 정확 도를 보여 수많은 연구자가 새로운 알고리즘을 개발 하고 있다.
2020년에 공개된 논문에 거리예측 및 각도예측 단 계의 소스 코드만 공개되어 수많은 연구자가 구현하 고자 노력하는 중에, CASP 14에서 Alphafoldv2가 새 롭게 등장하여 또다시 1등을 거두었다. 이러한 연구 를 통해 단백질 폴딩 문제가 해결될 수 있을 것으로 예상하며 본 연구 이전에 단백질의 실험 구조 데이 터가 충분히 확보되어야 한다고 생각한다. 본 연구 를 통해 단백질공학, 신약개발 등의 분야에서 충분 히 두드러지는 성과를 기대할 수 있을 것으로 예상 한다.
2. 공정/소재 개발에 적용 가능한 베이지안 최적화
최근 첨단 산업의 급격한 발달에 따른 대용량 전 력 저장의 필요성이 대두됨으로써, 높은 에너지 밀 도를 가지며 긴 수명 특성을 갖는 이차전지 전극 소 재 개발을 위한 연구들이 활발히 이루어지고 있다.
그중에서도 시간적, 비용적 효율 증대를 위해 머신 러닝을 이용한 연구들이 주목받고 있는데, 본 고에 서는 원하는 효율을 갖는 전극 조성을 예측하는 ‘베 이지안 최적화’ 기법에 관해 소개하고자 한다.
Step 1. 목적함수 추정
최적화(Optimization) 기법은 형태가 정해져 있 지 않은 미지의 목적함수(Objective function) f(x) 의 Maximum value 혹은 Minimum value를 갖는 변 수 조합 결정 알고리즘이다. 대표적인 최적화 기법 인 베이지안 최적화(Bayesian optimization, B.O)는 Gaussian process를 이용하여 현재까지 얻은 데이터 (Observed points, 입력값-함숫값) 기반의 목적함수를 확률적으로 추정한다.
시간적, 공간적 복잡도가 매우 큰 실험의 경우 그 조건을 연속적으로 바꾸어가며 결과를 얻는 데 한계 가 있다. 본 기법을 통해 지금까지 얻은 실험데이터 를 기반으로 요구되는 실험 결과인 목적함수를 추정 할 수 있다.
그림 3. T0955 샘플의 디스토그램.
그림 4. 주형(파란색) 및 예측된(초록색) 단백질 구조.
특 별 기 획 ( III )
Step 2. Candidates 제안
추정한 목적함수를 기반으로 Acquisition function 을 이용하여 다음 관측 지점을 제안한다. 제안된 Candidates 조건에서 실험을 수행한 뒤, 그 실험 결과 를 함숫값으로 본 모델에 업데이트하는 과정을 반복 하여 요구되는 성능의 최적해를 찾을 수 있다.
LiMnO 삼원계 전극의 조성별 band gap 최적화 본 연구팀은 BO를 이용해 이차전지 성능 최적 화를 진행하였다. 리튬전지의 대표적인 Cathode 인 LiMnO 삼원계 화합물을 최적화했다. 이를 위해 Material project의 LiMnO 데이터를 이용하였고, 각 조성에 따른 Band gap을 최적화함으로써, 최적 해인 Li의 질량비(Weight fraction)를 탐색하였다. 그 결과 4~5번의 탐색 만에 최대 Band gap을 갖는 LiMnO 조 성을 찾을 수 있었다.
또한, 본 연구팀에서는 이를 단순한 전지 조성뿐 아닌 실험 외부 조건으로 확장함으로써, 각 조건에 서 배터리 용량과 수명 특성 측면 모두 최적의 성능 을 갖는 조건을 찾는 연구를 진행 중이다.
베이지안 최적화의 방향성
본 알고리즘은 실험 설계과정에서 또한 효율적으 로 사용될 수 있다. 예를 들어 소재의 조성, 온도와 pH등 실험 결과에 직간접적으로 영향을 미칠 수 있 는 외부 조건을 제어할 수 있습니다.
Abigail G. Doyle 연구팀은 베이지안 최적화를 화 학 합성의 한 도구로 제안했다. 50명의 학계 및 산업 계의 전문 화학자와 베이지안 최적화 모델의 반응 최적화 게임 결과, B.O가 평균적으로 인간 전문가 보다 우수하게 최적의 수율을 갖는 조건을 찾는 것 을 확인하였다. 이처럼 B.O를 이용한 실험 조건 및 조성 최적화는 더욱 효율적인 실험 설계를 가능하게 하며, 다양한 조건을 갖는 여러 실험 분야에 적용할 수 있다.
3. 신규소재 기반 이미지 데이터 머신러닝 분석
최근 인공지능은 빅데이터와 딥러닝을 이용하여 놀라운 성능을 보인다. 특히, 스스로 학습할 수 있는
그림 5. 베이지안 최적화 알고리즘 및 Li weight fraction에 따른 LiMnO band gap 최적화.
능력을 컴퓨터에 부여한 머신러닝(Machine learning) 은 컴퓨터 과학을 포함한 광범위한 분야에서 활용되 고 있는데, 물질의 조성, 성질, 구조의 변화를 다루는 화학 분야에서도 머신러닝을 이용한 다양한 화학 분 석법에 대한 연구가 활발히 진행되고 있다.
이번 연구에서는 컴퓨터에 시각을 부여하여 디 지털 이미지와 동영상을 분석하는 컴퓨터 비전 (Computer vision)을 고분자 센서 이미지 분석에 적용 하였으며, 이를 통해 유의미한 소재 특성을 분석하 는 방법에 관해 소개하고자 한다.
Sensor Image and OpenCV
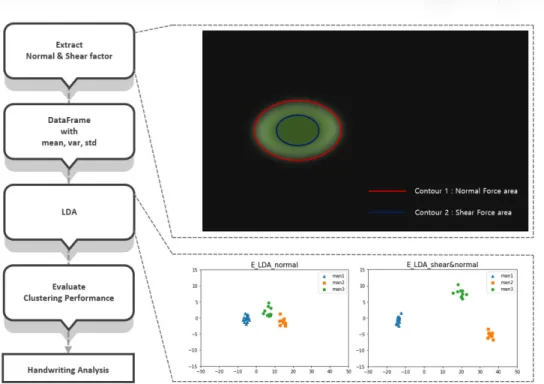
OpenCV (Open source computer vision)는 실시간 이미지 프로세싱을 목적으로 한 파이썬 라이브러리 이다. 본 연구팀에서 분석한 촉각센서(Tactile sensor) 이미지 데이터는 가해지는 힘에 비례하는 IR 세기 로 검출되는데, 그 불분명한 경계 영역을 검출하기 위해 OpenCV의 Contour 기법을 사용하였다. 이때, Threshold 조정을 통해 센서 이미지로부터 Normal force 및 Shear force 영역과 각 특성을 나타내는 요소
를 추출하였으며, 그 결과 센서에 가해지는 힘의 패 턴을 특정하였다.
Handwriting Analysis and LDA
센서 이미지 데이터로부터 추출한 Normal, Shear force 요소들은 실시간으로 바뀌는 힘의 세기와 방 향을 나타낼 수 있는 장점이 있다. 본 연구팀은 선형 판별 분석법(LDA, Linear discriminant analysis)을 이 용하여 이러한 요소를 이용한 필적감정(Handwriting analysis) 시스템을 구현하였다.
본 시스템은 크게 두 단계로 구성되어 있다. 3명 의 사람이 각각 작성한 필체 동영상의 각 프레임에 서 Normal, Shear force 요소를 추출하는 단계와 그 평균(Mean, winsorized mean), 분산, 표준편차를 계산 하여 변화 양상을 수치화하는 단계이다. 이를 이용 하여 선형 판별 분석한 결과 세명의 필체를 성공적 으로 분류하였다.
본 연구에서는 요소별 클러스터링 성능 평가를 진행함으로써 보다 높은 성능의 시스템을 구현할 수 있었다.
그림 6. Handwriting analysis 알고리즘 및 알파벳 'e' 선형판별분석.
특 별 기 획 ( III )
Braille Translation System
본 연구팀은, 촉각센서 소재의 다른 적용 분야로 실시간 점자 인식 시스템을 구현하였다. 앞서와 같이 OpenCV를 이용하여 점자 영역을 추출한 뒤, 각 점들 의 중심점을 좌표화 했다. 해당 좌표를 점자 필순법 에 착안한 아이디 코드로 변환한 뒤, 이에 해당하는 알파벳을 읽어 들임으로써, 센서에 찍히는 점자의 실시간 음성 번역 시스템을 구현하였다. 머신러닝을 통해 분석한 소재 특성에 다시 머신러닝을 적용하여 응용 시스템을 구현함으로써 다방면으로의 소재 활 용 가능성을 확인하였다.
4. 미생물 촉매의 전사조절 분석용 딥러닝 ChIP-exo 기법
본 연구실에서 주로 진행하는 박테리아의 유전자 발현 조절의 경우, 유전체 전체에서의 DNA 결합을 동정하는 것이 중요하다. 크로마틴 면역 침강법은 단백질과 DNA의 상호작용을 생체 내에서 확인하는 가장 흔한 방법이다. 이는 특정 항체와 Formaldehyde 를 활용하여 침전시킨 DNA를 정제하여 얻어내는 방 법이다. 이 DNA를 Microarray (ChIP-chip) 또는 Deep
sequencing (ChIP-seq)을 통해 관측해왔다. 더 나아가 서, ChIP-seq을 개량한 ChIP-exo는 핵산 말단 가수 분해효소를 사용하여 DNA-protein의 결합 경계까지 분해하여 해상도를 높인 실험 기법이다.
기존 ChIP-exo 데이터 분석은 시퀀싱된 데이터를 참조 서열(Reference genome)에 정렬하여 진행하였 다. 그 과정에서 필요한 데이터를 선정하는 큐레이 션 작업은 필수적이다. 하지만 큐레이션을 돕는 여 러 가지 프로그램 중 ChIP-seq 데이터를 위한 프로 그램은 많지만, High-resolution ChIP-exo 데이터의 경우 최적화가 되지 않아 적용하기에 어려움이 있 다. 또한, MACE라는 프로그램은 ChIP-exo 데이터 에 사용되지만, 포유류와 효모에 대해서 평가되었기 때문에 박테리아의 데이터, 예를 들어 몇몇 대장균 의 RpoN ChIP-exo 데이터의 피크에서 거짓 양성이 존재함을 확인했다.
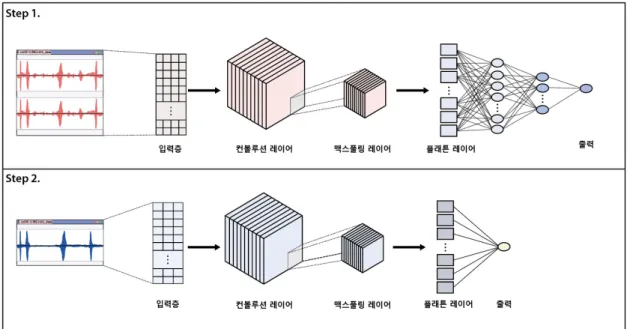
이를 해결하기 위해 Deep-learning based investigation of ChIP-Exo Reads(DICER)를 개발하였다. DICER는 데이터의 노이즈를 줄이는 첫 단계와 마지막 피크를 호출하는 단계로 총 두 단계로 이루어져 있다.
본 연구는 딥러닝을 큐레이션 과정을 수동으로
그림 7. DICER의 알고리즘 모식도.
진행하는 방식을 모방하여 진행되어 졌다. 두 개의 생물학적으로 동등하게 진행된 실험 샘플의 데이터 를 통해 거짓 양성을 제거하는 수동 큐레이션과 같 이 실제 피크는 신호-노이즈 비율의 감소에 따른 신 호의 증가에 따라 인식된다.
DICER를 학습 및 평가하기 위해 MACE를 통해 큐레이션 된 RpoN ChIP-exo 데이터와 원시 RpoN ChIP-exo 데이터를 사용하였다. 또한, 데이터의 80%
를 학습 세트로, 20%를 검증 세트로 진행하여 첫 번 째 신경망의 학습을 진행하고 100회 진행하였다.
Step 1과 Step 2의 신경망에서 볼 수 있듯이, 두 신 경망은 입력 층, 컨볼루션 층, 맥스풀링 층, 플래튼 층과 출력 층으로 구성되며 각 매개 변수들은 반복 시행 과정에 의해 결정되어 졌다. 이와 같은 과정을 통해 전체 정확도가 약 99%인 신경망을 생성할 수 있다.
기존 사용되던 MACE 프로그램과 비교하기 위해 모티프 추정 프로그램인 MEME를 사용하였다. 그 결과, DICER에서는 RpoN 결합 모티프가 모든 피크 에서 발견되었지만, MACE와 MACE elite의 경우, 매 우 적은 수가 발견되었다. 따라서 RpoN의 ChIP-exo 데이터를 제공하여 얻어낸 RpoN 결합 모티프 통해, 충분히 많은 학습 데이터를 줬을 때, 다른 DNA 결합 단백질에서도 적용할 수 있을 것으로 예상한다.
하지만 다른 프로그램보다 압도적인 성능에도 불 구하고, 학습 데이터의 한계가 존재한다. 이 분석은 신호-노이즈 비율에 큰 영향을 받기 때문에 시퀀싱 된 데이터의 품질, 그리고 참조 서열과의 정렬 정확 도에 따라 차이가 발생한다. 기계학습의 특성상 학
습 데이터의 정확도와 양은 결과의 신뢰도와 매우 높은 연관성을 보이기 때문에 신경망의 개선뿐만 아 니라 학습 데이터의 개선 및 데이터베이스 확보를 하여 더욱 정확한 결과를 보여주는 프로그램을 디자 인하고자 한다.
5. 요약 및 결론
생물공학/화학공학 분야를 포함하여 거의 모든 연구개발 분야에서 데이터 생산 비용과 기간이 줄 어드는 데이터 르네상스 시대를 맞이하고 있다. 동 시에 시간·공간 복잡도가 커지는 데이터를 다룰 수 있는 해당 도메인의 연구개발과 인력양성이 활발히 진행되고 있으며, 따라서 머신러닝 기술의 적용은 선택이 아닌 필수에 가까운 일이 되고 있다. 현재는 축적된 데이터가 상대적으로 많은 이미지/텍스트/음 성 및 바이오 데이터에서 활발히 연구되고 있지만, 차차 화학공학 등의 분야로 그 불길이 퍼져나갈 것 으로 예상한다.