LVLN : A Landmark-Based Deep Neural Network Model for Vision-and-Language Navigation
12
0
0
전체 글
(2) 380. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). 이해함으로써, 에이전트 스스로 목적지까지 이동(navigate)해 야 하는 문제이다. 이 문제는 에이전트의 영상 및 자연어 이 해 능력뿐만 아니라, 상황 추론과 행동 계획 능력도 함께 요. 나 장소를 입력 영상에서 탐지하고 이 정보를 직접 이용하려 는 노력은 없었다. 본 논문에서는 시각-언어 이동(VLN) 문제를 위한 새로운. 구한다. Fig. 1은 다양한 3차원 건물의 실사 영상(photo-realistic image)들을 제공하는 Matterport3D 시뮬레이터[6]와 Room-. 심층 신경망 모델인 LVLN(Landmark-based VLN)을 제안한 다. LVLN 모델에서는 자연어 지시의 언어적 특징과 입력 영 상 전체의 시각적 특징들 외에, 자연어 지시에서 언급하는 주. to-Room (R2R) 벤치마크 데이터 집합[5]을 이용한 시각-언 어 이동(VLN) 작업의 한 예를 보여주고 있다. 그림의 상단과 같이 연속된 자연어 지시가 주어지면, 에이전트는 그림의 하. 요 장소와 랜드마크 물체들을 입력 영상에서 탐지해내고 이 정보들을 추가적으로 이용한다. 특히 이때 맥락 정보 기반의 주의 집중(context-based attention) 메커니즘을 통해, 자연어. 단과 같이 자신의 카메라에 입력되는 영상을 토대로 매순간 적절한 자신의 행동을 결정해 실행함으로써 목적지까지 도달 해야 한다.. 지시 내 각 개체(entity)와 영상 내 각 관심 영역(ROI), 그리고 영상에서 탐지된 개별 물체(object) 및 장소(place) 간의 연관 성과 일치성을 높일 수 있도록 설계하였다. 또한, LVLN 모델에 서는 에이전트의 목표 도달 가능성을 향상시키기 위해, 목표를 향한 실질적인 접근을 점검할 수 있는 진척 점검기(progress monitor) 모듈도 포함하고 있다. 끝으로, 본 논문에서 제안하는 LVLN 모델의 성능을 분석하기 위해 Matterport3D 시뮬레이 터 [6]와 Room-to-Room (R2R) 벤치마크 데이터 집합[5]을 이 용한 다양한 실험들을 수행하고, 그 결과들을 소개한다.. 2. 관련 연구 2.1 시각-언어 이동. Fig. 1. Example of Vision-and-Language Navigation (VLN) Task with Landmark Detection. 일반적으로 에이전트에게 주어지는 자연어 지시는 “Walk straight past the kitchen and turn left. ...., and stop in front of the doorway.”와 같이 실내의 주요 랜드마크(landmark) 들에 기초한 고수준의 이동 계획(high-level navigation plan) 일 뿐, 에이전트가 직접 실행할 수 있는 구체적인 저수준의 행동(low-level action)들이 아니다. 따라서 에이전트는 고수 준의 자연어 지시를 입력 영상과 연관 지어 이해(visual grounding)해야 할 뿐만 아니라, 자연어 지시에 직접 언급되 어 있지 않은 세부적인 상황 정보들을 영상으로부터 추출해 내고 이를 토대로 자신이 수행할 구제적인 행동들을 계획 (planning)해야 한다. Fig. 1의 예에서 보듯이, 시각-언어 이동(VLN) 작업에서 에이전트가 자연어 지시와 입력 영상을 서로 연관 지어 이해 하기 위해서는 자연어 지시에서 언급하는 “kitchen”, “dining table”, “doorway”와 같이 랜드마크 역할을 해줄 수 있는 특 정 장소(place)나 물체(object)들을 입력 영상에서 인식해내는 것이 매우 중요하다. 시각과 언어 기반의 이동(VLN)에 관한 여러 선행 연구[5, 7-12]들이 존재하였으나, 앞선 선행 연구들 에서는 합성곱 신경망(CNN)을 통해 추출하는 입력 영상 전 체의 시각적 특징(visual feature)들과 순환 신경망(RNN)을 통해 추출하는 자연어 지시의 언어적 특징(linguistic feature) 들만을 이용할 뿐, 자연어 지시에서 언급하는 랜드마크 물체. 본 논문에서 다룰 시각-언어 이동(Vision-and-Language Navigation) 문제는 [5]의 연구에서 처음 제안되었다. 이 연 구에서는 시각-언어 이동 문제를 위한 기본적인 심층 신경망 모델도 제시하였다. 이 모델은 순환 신경망(recurrent neural network)의 하나인 LSTM(LongTerm Memory Network)을 기초로, 단어들의 시퀀스(word sequence)로 표현되는 자연어 지시를 입력하여 이동 행동들의 시퀀스(action sequence)를 출력하는 Seq2Seq 구조를 가지고 있다. 한편, [7, 8]의 연구에 서는 시각-언어 이동(VLN) 문제를 위한 행동 정책 학습에 환경 특성을 더 잘 반영할 수 있도록, 미래 예측 이 가능한 환경 모델(environment model)과 이것을 활용한 혼합 강화 학습(hybrid reinforcement learning) 기술을 적용하였다. [9] 연구에서는 시각-언어 이동(VLN) 문제를 위한 발화자-수행 자(Speaker-Follower) 모델을 제안하였다. 발화자 모듈은 에 이전트의 이동 경로(trajectory)을 입력받아 이것을 자연어 지 시로 변환해주는 역할을 수행하고, 반면에 수행자 모듈은 이 와는 반대로 자연어 지시를 입력받아 이 지시에 따라 목표에 도달하기 위한 에이전트의 이동 경로를 생성하는 역할을 수 행한다. 이 모델에서는 수행자 모듈의 부족한 학습 데이터를 확장하기 위해 발화자 모듈을 활용할 뿐만 아니라, 수행자 모 듈이 생성하는 이동 경로 후보들의 품질을 평가하는데도 발 화자 모듈을 활용하였다. [10]의 연구에서는 자연어 지시에 따라 이동 중인 에이전트가 실제로 얼마나 목표에 가까워지 고 있는 지 점검할 수 있는 진척 점검기(progress monitor) 모듈 추가를 제안하기도 하였다. 또한, [11. 12]와 같은 후속 연구들에서는 시각-언어 이동(VLN) 문제를 일종의 그래프 탐색(graph search) 문제로 간주하여, 진척 점검기를 기반으.
(3) LVLN : 시각-언어 이동을 위한 랜드마크 기반의 심층 신경망 모델 381. 로 어느 방향으로 전향 탐색(forward search)을 계속할 지, 아니면 역 추적(bactkrack)을 수행할 지를 결정함으로써, VLN 에이전트의 성능 개선을 시도하기도 하였다. 하지만, 앞. 마스킹 기능을 추가한 Mask R-CNN[24] 등이 두-단계 탐지 기들에 속한다. 한편, 단-단계 물체 탐지기들은 별도로 물체 후보 영역을. 서 소개한 대부분의 선행 연구들에서는 에이전트의 행동 결 정을 위해 자연어 지시에서 언급하는 장소나 랜드마크 물체 들을 영상에서 탐지해내고 이 정보를 직접 활용해보려는 시. 제안하는 단계는 없고, 대신 일정한 크기와 기준 위치에 따라 나눈 영상 영역들에 대해 곧바로 물체 분류 단계를 적용한다. 이와 같은 단-단계 물체 탐지기들은 두-단계 탐지기들에 비. 도는 없었다.. 해 탐지 성능은 상대적으로 낮으나 탐지 속도가 매우 빠르기 때문에 실시간 응용에 많이 이용되고 있다. YOLO[25](You Only Look Once), SSD[26](Single Shot Detector) 등이 단-. 2.2 장소 인식 입력 영상을 분석해 장소를 인식해내는 영상 기반 장소 인 식 기술은 에이전트의 자율 이동을 위한 핵심 기술이다. 특히 실내 환경에서의 장소 인식(indoor place recognition)은 서비 스 로봇과 같은 자율 이동체의 실내 지도 작성(mapping)과 위치 추정(localization)에 필수적으로 요구되는 기술로서, 오 랫동안 연구되어 왔다. 실내 장소 인식 알고리즘이나 모델은 복잡하고 가변적인 환경에서도 높은 인식 정확성이 요구되 면서, 동시에 실시간 응용들을 위해 빠른 인식 속도도 함께 요구된다. 하지만 이직까지 실내 장소 인식 기술은 조명 (illumination), 겹침(occlusion), 복잡한 배경(complex background), 영상 노이즈(image noise) 등 다양한 현실적인 요인 들로 인해 매우 도전적인 연구 주제로 남아 있다. [13]과 같은 선행 연구들에서는 빠르고 정확한 장소 인식 을 위해 다양한 형태의 CNN 기반 딥러닝 모델들을 제안했 다. 하지만, 이 모델들은 입력 영상 전체로부터 추출한 시각 특징을 모두 사용하여 장소를 인식하려함으로써, 특정 장소. 단계 물체 탐지기들에 속한다. 최근에는 YOLO v2[27], YOLO v3[28] 등이 연속해서 소개되면서, 탐지 속도뿐만 아 니라 탐지 성능 면에서도 많은 개선이 이루어지고 있다.. 3. 시각-언어 이동 3.1 문제 정의 본 논문에서 제안하는 모델은 현재 EvalAI를 통해 진행 중인 국제 VLN Challenge에서 정의하고 있는 방식의 시각언어 이동(VLN) 작업을 가정한다. 이 VLN Challenge에서는 에이전트에게 직접 목표 지점을 알려주는 대신 고수준의 이 동 계획인 자연어 지시를 제공하고, 에이전트로 하여금 이 자 연어 지시와 실시간 입력 영상에 따라 자율적으로 이동하게 한 후, 얼마나 목표 지점에 가까이 성공적으로 도달하였는지 를 평가한다.. 인식에 있어 중요한 단서가 될 수 있는 부분 특징들을 정확 히 잡아내지 못하는 한계성이 있었다. 따라서 [14, 15]와 같은 선행 연구들은 [13]과는 달리 영상 내부에서 장소 구별에 도 움이 되는 특정 물체를 포착하거나, 일부 영상 패턴들을 학습 하는 것에 초점을 맞추었다. 이를 위하여 GoogleNet[16], VGG16[17], ResNet-152[18]와 같은 CNN 모델들을 물체 인 식을 위한 ImageNet[19] 데이터 집합으로 선행 학습시킨 후, 다시 NYUv2[20], Places[15]와 같은 장소 인식 데이터 집합 으로 추가 학습시켜 활용하는 방식들이 제안되었다. 이러한 방법들은 입력 영상에서 장소 인식에 큰 단서가 될 수 있는 장소 별 부분 영상 특징들과 물체 특징들을 효과적으로 학습 할 수 있다는 장점이 존재한다. 2.3 물체 탐지 최근 선행 연구들을 통해 소개된 합성곱 신경망(Convolutional Neural Network, CNN) 기반의 물체 탐지기들은 크 게 두-단계 탐지기(two-phase detector)들과 단-단계 탐지기 (single-phase detector)들로 나눌 수 있다. R-CNN[21](Regions with CNNs) 계열로도 불리는 두-단계 탐지기들은 영. Fig. 2. Example of VLN Environment. VLN Challenge의 시각-언어 이동 작업은 Fig. 2와 같이. 상 내의 물체 후보 영역들을 제안하는 단계와 각 후보 영역 으로부터 추출한 시각 특징들을 토대로 해당 영역의 물체를 분류하고 영역을 재조정하는 단계를 거친다. 이와 같은 두-. 실사 영상(photo-realistic image)을 제공하는 3차원 실내 시. 단계 물체 탐지기들은 단-단계 탐지기들에 비해 상대적으로 탐지 성능은 높은 반면, 탐지 속도가 느린 단점이 있다. R-CNN[21], Fast-RCNN[22], Faster R-CNN[23]과 이미지. 위상 지도(topological map)가 그려져 있다. 즉, 이 지도는 실. 뮬레이션 환경인 Matterport3D에서 수행된다. 에이전트가 활 동하는 실내 공간에는 Fig. 2의 하단과 같이 그래프 형태의 내 공간의 특정 지점들을 나타내는 노드(node)들과 직접 이 동 접근이 가능한 두 인접 노드를 잇는 간선(edge)들로 구성.
(4) 382. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). Fig. 3. Architecture of LVLN Model. 된다. 예컨대, Fig. 2의 예에서 노란색 점과 선들은 에이전트. 360°를 수평으로 30°씩 나눈 12개의 수평 방향 영역들과 이들 각. 가 이동할 수 있는 공간상의 경로들을 보여주는 위상 지도를. 각을 다시 3개의 상하 고도로 나눈 수직 방향 영역들을 종합하 여, 총 36개의 부분 영상들로 구성. .. 나타낸다. 그리고 그 위에 놓인 빨간색 별표는 시작 지점 (starting point)을, 파란색 선은 목표 지점까지의 최적 경로 (optimal path)를 각각 나타낸다. 하지만, 에이전트에게는 이 와 같은 그래프 형태의 위상 지도가 직접 제공되지는 않고,. - 행동(Action): at 매 순간 에이전트는 입력 파노라마 영상을 구성하는 총 36. 환경을 포착한 360° 파노라마 영상(panorama image)이 대신. 개의 부분 영상들 중 하나를 선택하여, 그것에 해당하는 방향 영역으로 이동. 따라서 ∈ , , 이때 각. 주어진다. 이 파노라마 영상은 Fig. 2의 상단과 같이 수평과. 는 부분 영상 에 해당하는 방향 영역으로 향하는 이동. 수직으로 균등히 분할된 총 36개의 부분 영상들로 나뉜다. 에. 행동을 나타냄.. 다만 Fig. 2의 상단과 같이 현재 위치에서 에이전트의 주변. 이전트는 매순간 이러한 파노라마 입력 영상으로부터 실내 환경의 배치와 자신의 현재 위치를 추정하고, 파노라마 영상 을 구성하는 36개의 부분 영상들 중 하나를 선택하여 그쪽 방향으로 향하는 행동을 수행한다. 이때 에이전트가 선택한. - 상태 전이(State Transition): T 상태 에서 에이전트가 실행한 행동 ∈ 는 새로운 상 태 로 상태 전이를 유발함. 즉 .. 행동의 결과는 해당 방향으로 놓인 위상 지도상 가장 근접한. - 에피소드(Episode): E. 노드로 에이전트의 위치 변경이 이루어지는 것이다. 따라서 본 논문에서 가정하는 시각-언어 이동(VLN) 문제는 아래와. 하나의 에피소드 E는 초기 상태에서 시작하여 에이전트가 수행하는 일련의 행동 시퀀스 를 나. 같이 정의할 수 있다.. 타냄, 에피소드 E를 구성하는 각 행동 의 실행은 다음 상태. - 지시(Instruction): I. 로의 변경과 새로운 관찰 의 입력을 발생시킴.. 단어들의 시퀀스인 자연어 지시 , . - 상태(State): st 시각-언어 이동 문제를 구성하는 각 상태(state) 는 에이 전트의 실시간 위치 정보로 표현. 즉 , 이때 는 에이전트가 놓여있는 지점의 3차원 위치(position)를, 는 에이전트가 향하고 있는 수평 방향(heading)을, 는 수직. - 작업 평가(Evaluation): 에피소드 E가 완료된 상태에서 도달 지점과 목표 지점과 의 거리를 계산, 두 지점 간의 차이가 3미터 이내인 경우, 작 업 성공으로 판단. 3.2 제안 모델 Fig. 3은 본 논문에서 제안하는 심층 신경망 모델인 LVLN. 방향인 고도(elevation)를 각각 나타냄. 초기 상태는 와 같이, 에이전트의 시작 위치로 주어짐.. 의 전체 구조도를 나타낸다. LVLN 모델은 초기에 자연어 지. - 관찰(Observation): Ot. 으로부터 현재 실행할 행동 를 결정하는 과정을 반복해. 시 를 입력한 후, 매 시간() 입력 영상 과 직전 행동. 매 순간 에이전트에게 주어지는 입력은 그 상태 의 현재 위. 야 한다. LVLN 모델에서는 이 과정을 입력 시퀀스로부터. 치에서 취득한 360° 파노라마 영상 , 파노라마 영상 는. 출력 시퀀스를 생성하는 문제로 간주하여, 중심 모듈로 순환.
(5) LVLN : 시각-언어 이동을 위한 랜드마크 기반의 심층 신경망 모델 383. 신경망(recurrent neural network)의 하나인 LSTM(Long. 이 때, 는 자연어 지시 내의 현재까지 실행한 단. Short-Term Memory)을 채용하였다. 그리고 LVLN 모델은. 어() 위치 정보(Positional Encoding)를 나타내며, 은. LSTM을 중심으로 크게 (a)자연어 지시 와 입력 영상 직전 행동 등의 입력으로부터 행동 결정에 필요한 멀티 모달 특징 벡터를 얻어내는 인코더(Encoder) 부분과 (b) 멀티 모달 특징 벡터를 토대로 현재 실행할 행동 를 결정하는 디. 자연어 지시 내의 번째 단어와 간의 상관관계를 계산한 값이다. 그리고 는 지시 특징 에 적용할 주의 집중 가중치를 나타낸다.. 코더(Decoder) 부분으로 나뉜다. 그리고 인코더 부분은 다시 (3). 각각의 입력으로부터 특징을 추출하는 특징 추출 모듈(feature extraction module)들과 추출된 특징들에 주의 집중을 적용하 는 주의 집중 모듈(attention module)들로 구성된다. 지시 인코더(Instruction Encoder)에서는 자연어 지시 (instruction)를 순환 신경망(LSTM)을 통해 인코딩하고, 지 시의 어느 부분까지 현재 수행하였는지 추적할 수 있도록 단. 한편 시각 특징(visual feature)의 주의 집중 계산 과정은 지 시 특징의 경우와 유사한 Equation (3)과 같다. 여기서 함수 는 하나의 다층 신경망(MLP, Multi-Layer Perceptron)으로 구. 어의 위치 정보(Positional Encoding, PE)를 추가하여 지시. 현되며, 는 시각 특징 에 적용할 주의 집중 가중치를. 특징 을 만들게 된다.. 나타낸다. 물체와 장소 특징의 주의 집중 과정도 앞선 시각 특. 영상 특징 추출기(Visual Feature Extractor)에서는 대표적. 징과 유사한 방식으로, Equation (4)와 같이 직전 은닉상태. 인 합성 곱 신경망(CNN)인 ResNet-152를 이용하여 입력 파. 와 현재의 랜드마크 특징 을 이용. 노라마 영상 으로부터 시각 특징 을 추출해낸다. 그. 하여 주의 집중(soft-attention)을 수행한다.. 리고 파노라마 영상에 관한 시각 특징 은 Equation (1) 과 같이, 각 부분 영상에서 추출한 시각 특징들을 서로 연결. (4). (concatenation)하여 만든다. (1). , 시각 이와 같이 주의 집중 과정을 거친 지시 특징 , 물체 특징 , 장소 특징 들은 직전에 특징 . 또한, 이 영상 특징 은 물체 탐지 네트워크(Object Detection Network, ODN)와 장소 인식 네트워크(Place Recognition Network, PRN)의 입력으로도 제공되어, 입력 파노라마 영상에 포함된 특정 장소들과 물체들을 나타내는 물체 특징 과 장소 특징 을 추출한다. 물체 탐지. 수행한 행동을 나타내는 행동 특징 과 함께 통합되어 하나의 멀티 모달 특징 벡터 를 생성한다. 그리고 이것은 순환 신경망 LSTM의 입력으로 주어져 Equation (5)과 같이 새로운 은닉 상태 를 생성하게 된다.. 및 장소 인식 네트워크에 관해서는 3.3절에서 자세히 설명한 다. 마지막으로 직전 시간( )에 수행했던 행동 도 인. (5). 코딩하여, 행동 특징 을 생성한다. LVLN 모델은 매 시간마다 올바른 행동 를 결정하기 위. 순환신경망인 LSTM의 셀 상태(cell state) 와 직전의 은. 해서는 자연어 지시 중 어떤 부분에 집중해야 하는지, 입력. 과 지시 특징의 닉 상태 는 주의 집중된 시각 특징 . 영상 의 어떤 영역에 집중해야 하는지를 명확히 해야 한. 주의 집중 가중치( )과 함께 진척 점검기의 입력으로 이. 다. 따라서 Fig. 3과 같이 주의 집중(Attention) 단계에서는. 용되며, 이 과정에서 나온 행동 스코어 는 모델을 최적화. 그동안의 작업 맥락 정보를 나타내는 순환신경망 LSTM의. 하는 손실값(Loss)를 구하는 과정에 활용된다.. 직전 은닉 상태( )를 사용하여 각 특징마다 soft-attention 기법을 적용한 주의 집중된 특징들을 생성한다. 특히, LVLN 모델에서는 자연어 지시에서 언급하는 물체와 장소에 주목하 기 위하여 물체 특징과 장소 특징에도 주의 집중 메커니즘을. 마지막으로, 행동 디코더는 자연어 지시 I내에서 현재 과 입력 영 주목해야할 부분을 나타내는 지시 특징 상에 대한 시각 특징 , 그리고 맥락 정보를 나타내. 적용시켰다. 지시 특징(instruction feature)의 주의 집중 계산. 는 은닉 상태 를 토대로 현재 수행할 행동 를 결정. 은 Equation (2)와 같다.. 한다. 행동 디코더는 선형 계층(Linear Layer)과 소프트 맥스(softmax) 계층으로 구성되며, 행동 를 결정하는 (2). 과정은 Equation (6)와 같다. 이 식에서 는 현재 수행 가능한 각 행동에 대한 평가치를 나타낸다..
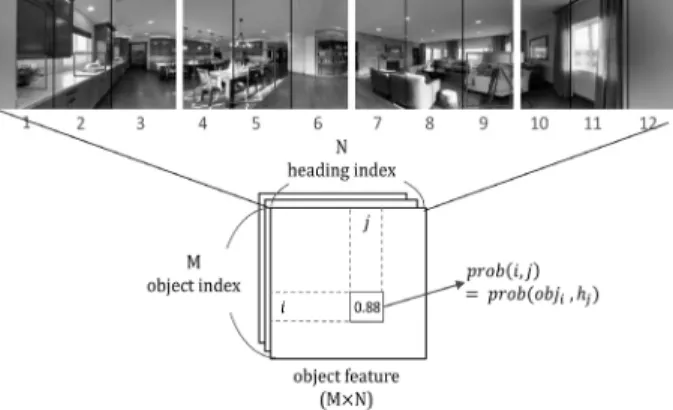
(6) 384. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). (6). 트워크와 유사한 방식으로 입력 파노라마 영상을 수평으로 단위로 나눈 4개의 부분 영상들에서 다양한 장소들을 탐지 해낸다. 그리고 탐지된 장소(place)의 색인번호 , 탐지 방향. 따라서 행동 디코더는 현재 수행 가능한 행동들 중 가장 높은 평가치를 갖는 행동을 선택한다.. (heading) , 탐지 확률 값(probability)들을 토대로 Equation (8)과 같이 장소 특징 행렬 을 생성한다.. 3.3 물체 및 장소 탐지 LVLN 모델의 물체 탐지 네트워크(ODN)에서는 앞서 2장 에 언급했던 것처럼 빠른 실시간 처리가 요구되므로, 대표적 인 단-단계 물체 탐지기인 YOLO v3를 사용한다. 그리고 Equation (7)과 같이, 하나의 파노라마 영상을 단위로 분 할한 4개의 부분 영상 각각에서 탐지된 물체(object)의 종류 와 탐지 방향(heading) , 그리고 탐지 확률(probability). Fig. 5. Place Recognition Network (PRN). 를 생성한다. 을 기초로 물체 특징 행렬 . (8) (7) 이렇게 생성된 물체 특징 과 장소 특징 도 자연어 이때 방향 는 파노라마 영상을 씩 수평으로 나눈 총 12개의 방향 영역들 중 하나가 된다. 따라서 × 크기의 행렬(matrix)로 표현되는 물체 특징 에. 는 각 물체의 탐지 신뢰도를 나타내는 확률 값(probability)들 을 포함한다.. 지시에서 언급한 물체 혹은 장소와의 연관성을 높이기 위해, 맥락 정보 기반의 주의 집중 단계를 거친다. 3.4 진척 점검 제안 모델인 LVLN에서는 에이전트가 3차원 실내 환경에 서 자연어 지시와 입력 영상에 의존하여 자율이동을 계속 하 는 동안, 실질적으로 목표 지점에 접근하는지 판단할 수 있는 진척 점검기를 채택하였다. Fig. 3에서 보듯이, 진척 점검기에 는 직전 상태의 상황 정보를 나타내는 순환 신경망(LSTM) 의 직전 은닉 상태( ), 현재의 셀 상태( ) 정보, 주의 집 ), 지시어의 주의 집중 가중치( ) 중된 시각 특징( 등을 입력으로 이용한다. 이러한 입력들을 토대로, 진척 점검 기의 내부 은닉 상태( )와 평가 점수( )를 Equation (9). 와 같이 각각 계산한다.. (9). Fig. 4. Object Feature Matrix . Fig. 4를 예로 들면, 첫 번째 부분 영상에서 물체 색인번호. 이 식에서 ⊗은 행렬의 요소 곱(element-wise product) 연. 가 5인 sink가 2번 방향 영역에서 탐지되었으므로, 이 때 물. 산을, 는 시그모이드(Sigmoid) 함수를 각각 나타낸다.. 체 특징 행렬. . 내 (5, 2) 지점의 특징 값은 해당 물체의 탐. 지 신뢰도를 나타내는 확률값 0.88이 된다. 장소 인식 네트워크 (PRN)는 Fig. 5와 같은 구조의 합성곱. LVLN 모델에서는 진척 점검 과정에서 생성된 을 모델 학습 단계에서 이용하기 위해, Equation (10)과 같은 손실 함 수 를 정의하였다.. 신경망(CNN)으로 구성된다. 이 네트워크는 Places[15] 데이 터 집합으로 미리 사전 학습시킨 장면 인식 네트워크를. (10). Matterport3D 환경에서 수집한 새로운 장소별 영상 데이터들 로 재-학습시켜 사용한다. 이 네트워크에서도 물체 탐지 네. 이 손실 함수 는 크게 (1) 행동 결정에 대한 크로스-.
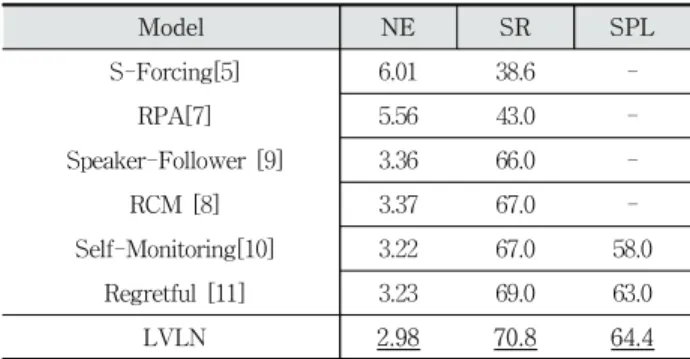
(7) LVLN : 시각-언어 이동을 위한 랜드마크 기반의 심층 신경망 모델 385. . 엔트로피 손실(cross-entropy loss) 부분인. . . log 과. (2) 진척 점검기의 평균 제곱오차 손실(mean squared error . loss) 부분인. . . 로. 구성된다. 그리고 문제의 특. 험들을 진행하였다. 실험에서 사용할 시각-언어 이동(VLN) 작업의 성능 평가 척도들은 이미 선행 연구들에서 많이 이용 한 NE(Navigation Error), SR(Success Rate), SPL(Success rate weighted by Path Length) 등이다. 성능 평가 척도 중 NE는 목표 지점과 최종 도달 지점간의 평균 거리(m, 미터 단. 성에 맞게 계수 를 조절함으로써, 이 두 가지 손실들의 결. 위)를 나타내며, SR은 목표 지점까지 도달 비율인 작업 성공률. 합 비율을 조정할 수 있다. 크로스 엔트로피 손실 계산에 사. (%)을 의미한다. 한편, SPL은 SR과는 달리, 이동 경로 길이에. 용된. 는. 시간의 정답 동작(ground truth action)을, . 는 수행 대상 동작( )에 대한 에이전트의 평가 확률 값을 각 각 나타낸다. 한편, 평균 제곱오차 손실에 사용된 는 에이 전트의 현재 위치와 목표 지점간의 거리를 정규화한 값을, 는 Equation (9)에 따라 계산한 진척 평가 점수를 각각 나타낸다.. 따라 가중치를 부여한 성공률(%)을 나타낸다. 따라서 NE는 낮 을수록, SR과 SPL은 높을수록 더 좋은 성능을 나타낸다. 첫 번째 실험은 선행 연구들과는 달리 입력 영상에서 추출 한 물체 특징과 장소 특징을 추가로 이용하는 LVLN 모델의 성능 개선 효과를 입증하기 위한 실험이다. 이러한 실험 목적 을 위해, Table 1과 같이 다양한 조합의 특징들을 이용하여 는 주 성능을 비교해보았다. Table 1에서 (IV) 과 시각 특징 만을 사 의 집중된 자연어 지시 특징 . 4. 구현 및 실험. 는 여기에 주의 집 용한 경우를, (IVO) . 4.1 데이터 집합과 실험 환경. 만을 추가로 사용한 경우를, (IVP) 중된 물체 특징 . Matterport3D 3차원 시뮬레이션 환경[6]과 AMT(Amazon. 는 주의 집중된 장소 특징 만을 추. Mechanical Turk)를 통해 수집된 Room-to-Room (R2R) 데 이터 집합을 이용해, 본 논문에서 제안한 심층 신경망 모델인. 가로 사용한 경우를 각각 나타낸다. 이들에 반해, (IVop) 는 물체 특징 과 장소 특징. LVLN을 학습하였다. R2R 데이터 집합은 Matterport3D 시뮬. 을 모두 추가 사용하되 주의 집중을 적용하지 않은 경우. 레이션 환경에서 임의의 한 시작 지점에서 목표 지점까지 도. 는 본 논문의 LVLN 를, (IVOP). 달하는 최단 경로를 구하고, 이 경로를 인간이 환경 내의 랜드 마크들을 이용해 자연어로 설명하는 서로 다른 자연어 지시를. 과 장소 특징 모델과 같이 주의 집중된 물체 특징 . 3개씩 만든 데이터 집합이다. 그리고 각 지시는 1개~3개의 연. 을 모두 추가 사용한 경우를 각각 나타낸다.. 속된 지시 문장들로 구성되어 있다. R2R 데이터 집합 내 학습 데이터와 테스트 데이터의 구성 비율은 약 2 : 1 정도이다.. Table 1. Performance Comparison Depending on Different Features. 본 논문에 사용된 장소 인식 네트워크(PRN)는 Places365. NE. SR. SPL. . 3.22. 67.0. 58.0. 상 데이터들로 재-학습시킨 신경망 모델이다. 학습 과정에서. (IVO) . 3.17. 69.7. 62.7. 학습률(Learning Rate)은 0.1로 설정하였으며, 최적화 함수. (IVP) . 3.07. 69.9. 62.6. (Optimizer)로는 SGD(Stochastic Gradient Descent)를 사용. (IVop). 3.03. 68.9. 63.3. (IVOP). 2.98. 70.8. 64.4. 데이터 집합으로 미리 학습된 ResNet-152 기반의 장면 분류 네트워크를 Matterport3D 환경에서 취득한 새로운 장소별 영. 하였다. 물체 탐지 네트워크(ODN) 역시 대규모 COCO 벤치 마크 데이터 집합[29]을 통해 미리 훈련된 물체 탐지 모델을. Features (IV). Matterport3D 환경에서 취득한 새로운 물체 영상 데이터들로 재-학습시킨 신경망 모델이다. LVLN 모델의 구현을 위해서. Table 1의 결과를 살펴보면, 물체 특징 또는 장소 특징을. 는 딥러닝 라이브러리인 Pytorch를 이용하였고, 성능 평가 실. 추가로 이용한 IVO, IVP, IVOP의 세 가지 경우 모두가, 기존. 험들은 Geforce GTX 1080ti GPU가 탑재된 하드웨어와. 연구들과 같이 단순히 자연어 지시 특징과 시각 특징만을 이. Ubuntu 16.04 LTS 환경에서 수행하였다.. 용한 IV 경우에 비해 SR과 NE, SPL측면에서 모두 성능이 향상되었음을 알 수 있다. 이들 중에서도 본 논문에서 제안하. 4.2 실험. 는 LVLN 모델과 같이 물체 특징과 장소 특징을 모두 추가. 본 논문에서는 (1) LVLN 모델에서 채용하고 있는 새로운. 이용한 IVOP의 경우가 비교 대상들 중 가장 높은 성능을 보. 장소 및 랜드마크 물체 특징의 효과와 (2) 기존의 다른 VLN. 여주었다. 이러한 결과는 앞서 본 논문에서 예상한 바와 같이. 모델들과의 비교를 통해 LVLN 모델의 우수성을 입증하는 실. VLN 문제에서는 물체 특징, 장소 특징 둘 중 어느 하나만 추.
(8) 386. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). 가 사용하는 것으로도 성능 향상이 가능하다는 것을 입증한. 세 번째 실험은 본 논문에서 제안한 LVLN 모델과 기존 연. 다. 하지만, 주의 집중(attention)을 적용하지 않은 물체 특징. 구에서 제안된 총 5 가지의 서로 다른 모델들과의 성능을 비교. 과 장소 특징을 모두 추가 이용한 IVop의 경우, 오히려 IVO,. 하는 실험이다. S-Forcing 모델은 기존 연구[5]에서 시도한 모. IVP의 경우보다 전체 성공률 측면에서 더 낮은 성능을 보이. 델로서, 데이터 기반의 감독 학습 과정 중 샘플링 기법을 추가. 고 있다. 이러한 실험 결과는 주의 집중을 통해 자연어 지시. 하여 최종 경로를 후보 경로 집합 중 결정하도록 한 모델이다.. 에서 언급하는 랜드마크들과 입력 영상에서 찾은 물체 혹은. RPA, Speaker-Follower, Self-Monitoring, RCM 등의 모델은. 장소 간의 일치성을 높이려는 LVLN 모델의 접근 방식이 매. 이전의 선행 연구[7-11]에서 제안한 모델들을 나타낸다.. 우 효과적임을 재확인시켜 준다.. Table 2의 실험 결과에서, 본 논문에서 제안한 LVLN 모. 한편, 본 논문에서는 IV와 IVOP 특징 집합에 대해, 학습. 델이 비교 대상인 기존 모델들에 비해 모든 척도 면에서 가. 진척에 따른 평균 작업 성공률 SR과 경로 길이 가중 성공률. 장 높은 성능을 보였다는 것을 알 수 있다. 이것은 시각-언어. SPL의 변화 추이를 비교해보았다. Fig. 6은 이러한 실험 결. 이동(VLN) 문제의 특성상, 자연어 지시에서 언급한 랜드마. 과를 보여준다. Fig. 6A는 학습 반복횟수(epoch)의 증가에 따. 크 역할을 하는 물체와 장소에 대한 영상 인식이 작업 성능. 른 평균 작업 성공률 SR을 비교한 그래프이며, Fig. 6B는 경. 개선에 매우 중요한 요소가 될 수 있음을 다시 확인시켜 주. 로 길이 가중 성공률 SPL을 비교한 그래프이다. Fig. 6A와. 는 결과로 볼 수 있다. 따라서 이와 같은 실험 결과들을 바탕. Fig. 6B의 실험 결과를 살펴보면, 두 가지 성능 척도 모두에. 으로, 본 논문에서 제안하는 새로운 심층 신경망 모델인. 서 IVOP모델이 IV모델보다 더 빠른 성공률 증가 추세를 보. LVLN의 우수성과 높은 성능을 확인할 수 있었다.. 인 것을 확인할 수 있다. 이와 같은 실험 결과는 앞선 Table 1의 결과와 더불어, 자연어 지시에서 언급하는 랜드마크 물체. Table 2. Performance Comparison with the State-of-art Models. 와 장소를 탐지해 행동 결정에 추가적으로 활용하는 IVOP. Model. NE. SR. SPL. 특징 방식의 LVLN 모델이 IV 특징만을 이용하는 기존 모델. S-Forcing[5]. 6.01. 38.6. -. RPA[7]. 5.56. 43.0. -. Speaker-Follower [9]. 3.36. 66.0. -. RCM [8]. 3.37. 67.0. -. 들에 비해 뚜렷한 성능 개선 효과가 있음을 확인시켜준다.. Self-Monitoring[10]. 3.22. 67.0. 58.0. Regretful [11]. 3.23. 69.0. 63.0. LVLN. 2.98. 70.8. 64.4. 본 논문에서는 위에서 설명한 정량적 실험들 외에, LVLN 모델의 정성적 성능 분석을 위해 LVLN 모델이 수행한 실제 작업 사례들을 살펴보았다. Fig. 7과 Fig. 8은 LVLN 모델이 실행한 작업들 중 서로 다른 대표 사례들을 각각 나타낸다. 그림 상단에 표시된 자연어 지시 중 파란색으로 표시된 부분 은 장소를, 초록색은 랜드마크 물체를 나타낸다. 그리고 그림 의 하단에는 입력 영상과 에이전트의 이동 방향을 빨간색 화 살표로 나타내었다. Fig. 7의 경우는 자연어 지시에서 장소와 랜드마크 물체를 모두 명시하고 있으며, 영상에서도 이들에 해당하는 영역들을 정확히 탐지해 행동 선택에 모두 활용한 사례이다. 이러한 경우에 LVLN 모델은 목표 지점까지 비교 적 짧은 경로로 성공적으로 도달할 수 있었다. 또한, Fig. 8의 경우는 자연어 지시에 비록 랜드마크 물체만 명시되어 있으 나, 영상에서 해당 물체 영역을 정확히 찾아 행동 결정에 활 용한 사례이다. 이 경우에도 LVLN 모델은 물체 특징만으로 도 상당히 효율적인 탐색을 통해 목표 지점에 도달한 것을 알 수 있다. 이와 같이 벤치마크 데이터 집합인 R2R에 포함 된 다수의 작업들에서 본 논문에서 제안한 LVLN 모델은 기 Fig. 6. Comparison of IV with IVOP in Terms of SR and SPL. 존 모델들에 비해 매우 우수한 작업 성능을 보여주었다..
(9) LVLN : 시각-언어 이동을 위한 랜드마크 기반의 심층 신경망 모델 387. Fig. 7. The First Navigation Example Guided with the LVLN Model.
(10) 388. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). Fig. 8. The Second Navigation Example Guided with the LVLN Model.
(11) LVLN : 시각-언어 이동을 위한 랜드마크 기반의 심층 신경망 모델 389. Learning for Planned-Ahead Vision-and-Language Navi-. 5. 결 론. gation,” in Proceedings of the European Conference on. 본 논문에서는 시각과 언어 기반의 이동(VLN) 문제를 위 한 새로운 심층 신경망 모델을 제시하였다. 본 논문에서 제안 한 LVLN 모델에서는 입력 영상에서 합성곱 신경망을 통해 추출한 전체 입력 영상 특징과 자연어 지시에서 순환 신경망 을 통해 추출한 언어적 특징 외에, 자연어 지시에서 언급하는 랜드마크 정보들을 별도로 탐지하고, 이들을 행동 선택을 위 한 특징벡터로 설계하여 이용하였다. 이 때 사용된 랜드마크 정보로는 특정 물체와 장소들로 각 각 이들을 위한 물체 탐지 네트워크, 장소 인식 네트워크를 추가 설계하여 활용하였다. 또한, 본 논문에서는 여러 랜드마 크 정보들 중 현재 진행 상황과 자연어 지시에 맞춰 특정 정 보에 집중할 수 있도록 주의 집중 단계를 설계하였고, 진척 점검 모듈을 채용하여 진척도를 점검할 수 있도록 하였다. 이 러한 통합 모델을 벤치마크 데이터 집합을 이용한 실험들을 통해 본 논문에서 제안한 모델의 높은 성능과 효과를 확인할 수 있었다. 하지만 현재의 LVLN 모델은 자연어 지시 문장 중에 특별히 랜드마크 물체나 장소가 포함되지 않은 경우에 는 이동 방향을 정확히 결정하지 못하는 경우도 가끔씩 발생 한다. 따라서 향후 연구에서는 기존 LVLN 모델의 안정화와 더불어 이러한 문제점들을 보완하여 추가적인 성능 개선을 시도해볼 계획이다.. References [1] A. Agrawal, J. and Lu, S. Antol, et al., "VQA: Visual Question Answering," in Proceedings of the International Conference on Computer Vision(ICCV), pp.2425-2433, 2015.. Computer Vision(ECCV), pp.696-711, 2018. [8] X. Wang, Q. Huang, and A. Celikyilmaz, et al., “Reinforced Cross-Modal. Matching. and. Self-Supervised. Imitation. Learning for Vision-Language Navigation,” in Proceedings of the Conference on Computer Vision and Pattern Recognition(CVPR), 2019. [9] D. Fried, R. Hu, and A. Rohrbach, et al., “Speaker-Follower Models for Vision-and-Language Navigation,” in Proceedings of the Conference on Neural Information Processing Systems(NIPS), Vol.28, 2018. [10] C. Ma, J. Lu, Z. and Z. wu, et al., “Self-Monitoring Navigation Agent via Auxiliary Progress Estimation,” in Proceedings of the International Conference on Learning Representations (ICLR), 2019. [11] C. Ma, Z. Wu, and G. Alregib, et al., “The Regretful Agent: Heuristic-Aided Navigation through Progress Estimation,” in Proceedings of the Conference on Computer Vision and Pattern Recognition(CVPR), 2019. [12] L. Ke, X. Li, and Y. Bisk, et al., “Tactical Rewind: SelfCorrection via Backtracking in Vision-and-Language Navigation,” in Proceedings of the Conference on Computer Vision and Pattern Recognition(CVPR), 2019. [13] K. Wang, X. Long, and R. Li, et al., “A Discriminative Algorithm for Indoor Place Recognition based on Clustering of Features and Images,” International Journal of Automation and Computing, Vol.14, pp.407-419, 2017. [14] A. Hanni, S. Chickerur, and I. Bidari, “Deep learning. [2] A. Das, S. Kottur, and K. Gupta, et al., “Visual Dialog,” in. Framework for Scene based Indoor Location Recognition,”. Proceedings of the IEEE Conference on Computer Vision. in Proceedings of the International Conference on Technol-. and Pattern Recognition (CVPR), 2017.. ogical Advancements in Power and Energy (TAP Energy),. [3] A. Das, S. Kottur, and K. Gupta, et al., “Embodied Question. IEEE, 2017.. Answering,” in Proceedings of the IEEE Conference on. [15] B. Zhou, A. Lapedriza and A. Khosla, et al., “Places: A 10. Computer Vision and Pattern Recognition (CVPR), Vol.5.. million Image Database for Scene Recognition,” IEEE. 2018.. Transactions on Pattern Analysis and Machine Intelligence,. [4] D. Gordon, A. Kembhavi, and M. Rastegari, et al., “IQA:. Vol.40, pp.1452-1464, 2017.. Visual Question Answering in Interactive Environments,” in. [16] C. Szegedy, W. Liu, and Y. Jia, et al., “Going Deeper with. Proceedings of the IEEE Conference on Computer Vision. Convolutions,” in Proceedings. of the IEEE Conference on. and Pattern Recognition (CVPR), 2018. [5] P. Anderson, Q. Wu, and D. Teney, et al., “Vision-and-. Computer Vision and Pattern Recognition(CVPR), pp.1-9, 2015.. Language Navigation: Interpreting Visually-grounded Navi-. [17] K. Simonyan, and A. Zisserman, “Very Deep Convolutional. gation Instructions in Real Environments,” in Proceedings of. Networks for Large-Scale Image Recognition,” in Pro-. the Conference on Computer Vision and Pattern Recogni-. ceedings of the International Conference on Learning. tion(CVPR), 2018.. Representations(ICLR), 2015.. [6] A. Chang, A. Dai, and T. Funkhouser, et al., “Matterport3D:. [18] K. He, X. Zhang, and S. Ren, et al., “Deep Residual Learning. Learning from RGB-D Data in Indoor Environments,” in. for Image Recognition,” in Proceedings of the IEEE. Proceedings of the International Conference on 3D Vision,. Conference on Computer Vision and Pattern Recognition. Vol.5, 2017.. (CVPR), pp.770-778, 2016.. [7] X. Wang, W. Xiong, and H. Wang, et al., “Look Before You. [19] J. Deng, W. Dong, and R. Socher, et al., “ImageNet:A. Leap: Bridging Model-Free and Model-Based Reinforcement. Large-Scale Hierarchical Image Database,” in Proceedings.
(12) 390. 정보처리학회논문지/소프트웨어 및 데이터 공학 제8권 제9호(2019. 9). of the Conference on Neural Information Processing Systems(NIPS), 2009. [20] N. Silberman, D. Hoiem, and P. Kohli, et al., “Indoor. Computer Vision and Pattern Recognition(CVPR), 2017. [28] J. Redmon, and A. Farhadi, “YOLOv3: An Incremental Improvement,” arXiv preprint arXiv:1804.02767, 2018.. Segmentation and Support Inference from RGBD Images,”. [29] T.-Y. Lin, M. Maire, and S. Belongie, et al., “Microsoft. in Proceedings of the European Conference on Computer. COCO: Common Objects in Context,” in Proceedings of the. Vision(ECCV), pp.746-760, 2012.. European Conference on Computer Vision(ECCV). vol 13,. [21] R. Grishick, J. Donahue, and T. Darrell, et al., “Rich Feature. pp.740-755, 2014.. Hierarchies for Accurate Oobject Detection and Semantic Segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2014. [22] R. Girshick, “Fast R-CNN,” in Proceedings of the IEEE. 황 지 수. International Conference on Computer Vision(ICCV), 2015.. https://orcid.org/0000-0002-9522-3981. [23] S. Ren, K. He, and R. Girshick, et al., “Faster R-CNN:. e-mail : [email protected]. Towards Real-Time Object Detection with Region Proposal. 2019년 경기대학교 컴퓨터과학과(학사). Networks,” in Proceedings of the Conference on Neural. 2019년~현 재 경기대학교 컴퓨터과학과. Information Processing Systems(NIPS), 2015. [24] K. He, G. Gkioxari, and P. Dollar, “Mask R-CNN,” in. 석사과정 관심분야 : 인공지능, 컴퓨터비전, 로봇지능. Proceedings of the IEEE International Conference on Computer Vision(ICCV), 2017. [25] J. Redmon, S. Divvala, and R. Girshick, et al., “You Only Look Once: Unified, Real-Time Object Detection,” in. 김 인 철. Proceedings of the IEEE Conference on Computer Vision. http://orcid.org/0000-0002-5754-133X. and Pattern Recognition(CVPR). 2016.. e-mail : [email protected]. [26] W. Liu, D. Anguelov, and D. Erhan, et al., “Ssd: Single Shot. 1985년 서울대학교 수학과(이학사). Multibox Detector,” in Proceedings of European Conference. 1987년 서울대학교 전산과학과(이학석사). on Ccomputer Vision(ECCV), pp.21-37, Springer, Cham.. 1995년 서울대학교 전산과학과(이학박사). 2016.. 1996년~현 재 경기대학교 컴퓨터과학과. [27] J. Redmon, and A. Farhadi, “YOLO9000: Better, Faster, Stronger,” in Proceedings of the IEEE Conference on. 교수 관심분야 : 인공지능, 기계학습.
(13)
수치
![Fig. 1은 다양한 3차원 건물의 실사 영상(photo-realistic image)들을 제공하는 Matterport3D 시뮬레이터[6]와 Room- to-Room (R2R) 벤치마크 데이터 집합[5]을 이용한 시각-언 어 이동(VLN) 작업의 한 예를 보여주고 있다](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5254275.629804/2.918.100.442.465.655/다양한-건물의-realistic-제공하는-matterport-시뮬레이터-벤치마크-보여주고.webp)


+4


관련 문서
◦ 사회의 의사결정이 한사람에 의해 결정되는 독재자제도하에서는 집단의사결정을 위해 동의가 요구되는 다른 사회구성원은 존재하지 않아 지불해야하는 의사결정비용이
실험값을 얻는 과정에서 그 값을 얻지 못하는 경우 빈칸으로 된 부분을 말한다 (SPSS 에서는 빈칸으로 비워두면 자동으로 결측값으로 인정한다).. SPSS에서는 숫자는 오른쪽
차동 입력 변화에 따라서 변화하는 차동 입력 변화에 따라서 변화하는 바이어스 전류 측정하여 결정. 동상 입력
왼쪽 마우스를 클릭하면 출력하던 것이 멈췄을 때, WM_LBUTTONDOWN 메시지 처 리를 하는 곳으로 메시지 제어권을 보내주므로
그러나 인간의 언어는 현 재는 물론 과거나 먼 미래에 대한 의사 소통도 가능하다.. 그리고 동물의 언어 와 인간의 언어는 정보 축적
자기소개서는 원서접수 사이트를 통해 온라인으로 입력/제출바랍니다.... 자기소개서는 원서접수 사이트를 통해
어숙권의 글에서 정작 문제가 되는 것은 《해동명적》에 실린 박경의 필적이 과연 박경의 글씨인지, 아니면 신자건의 글씨인지 하는 점이다.. 신자건은 《해동명적》에
시간에 종속되는 통행 속도의 특 성을 반영하기 위해 적용되었던 시계열 분석 기법인 Autoregressive Integrated Moving Average(ARIMA)와 순환 신경망(Recurrent
