콜센터 데이터 분석을 위한 OLAP 구현
백경민, 양우석, 이원석 연세대학교 컴퓨터 과학과
OLAP Implementation for Call center data
analysis
Kyung min Baek, Woo Sock Yang, Won Suk Lee Dept. of Computer Science, Yonsei University
E-mail : [email protected] [email protected] [email protected] 요 약 데이터가 기하급수적으로 생성되는 데이터스트림 환경에서 데이터를 처리하고 분석하 는 방법에 대한 많은 연구가 진행 중에 있다. 본 논문에서는 데이터스트림의 한 예인 콜 센터 데이터를 분석하기 위한 OLAP 구현에 대하여 기술한다. 제안하는 OLAP 시스템은 데이터스트림 환경에 적용할 수 있게 하여 유연한 분석을 가능하게 해준다.
1. 서론
데이터의 양이 기하급수적으로 증가함에 따라 데이터로부터 유용한 정보를 관리 및 추출하기 위 한 데이터웨어하우징 및 분석 기법에 대한 요구가 증대되고 있다. 특히 최근 유비쿼터스 시대로 진입 함에 따라 데이터스트림 환경에 대한 연구가 주목 을 받고 있다. 데이터스트림은 기존의 데이터웨어 하우스에 저장되었던 데이터들과는 성질이 매우 다르기 때문에 이를 처리하기 위해 새로운 기법들 이 요구된다. 따라서 주기적으로 업데이트를 실행 하는 데이터웨어하우스와 기존 DBMS로는 데이터 스트림을 처리하는 데에 한계가 있다. 데이터스트림의 대표적인 예로는 센서 데이터, 네 트워크 트래픽 데이터, 콜센터 데이터 등을 들 수 있다. 그 중에서 콜센터 데이터는 정부기관에서 인 터넷 쇼핑몰에 이르기까지 콜센터를 운영하는 모 이 논문은 2010년도 정부(교육과학기술부)의 재원 으로 한국연구재단의 지원을 받아 수행된 연구임 (No.2010-0008007) 든 곳에서 발생할 수 있다. 이런 콜센터 데이터를 분석하는 것은 이용자들에게 보다 나은 서비스를 제공하는데 유용하게 활용될 수 있다. 본 논문에서 는 스트림 형태의 콜센터 데이터를 처리 및 분석 할 수 있는 OLAP 시스템의 구현에 대해 논의하고 자 한다. 논문의 구성은 다음과 같다. 2장에서 OLAP과 관 련된 이전의 연구 및 개념을 살펴본다. 3장에서는 콜센터 데이터 분석을 OLAP에 적용한 필요성에 대해 설명한다. 4장에서는 제안하는 시스템을 적용 하여 콜센터 데이터 분석을 수행하는 방법을 설명 한다. 5장에서는 결론을 기술한다.2. OLAP과 스트림큐브
OLAP은 데이터웨어하우스에 저장된 데이터를 사 용자가 분석에 용이하도록 효과적으로 보여주기 위한 도구이다.[1] 일반적으로 데이터웨어하우스는 스타 스키마(Star-Schema) 구조를 통해 관리된다. 스타 스키마 구조는 사실(Fact) 테이블과 차원-275-표 1 자동차 판매 정보 예시 그림 1 데이터 큐브 (A1, *, C1) (A1, *, C2) (A1, *, C2) (A1, *, C2) (A1, B1, C2) (A1, B2, C1) (A2, *, C2)(A2, B1, C1)
(A1, B2, C2) (A2, B1, C2)A2, B2, C1)
(A2, B2, C2) m-layer o-layer 그림 2 스트림 큐브 (Dimension) 테이블로 이루어진다. 표 1은 OLAP 에서 사용하는 사실과 차원에 대한 개념을 설명하 기 위한 자동차 판매 정보 예시이다. 분석의 대상 이 되는 속성 ‘Company’, ‘Region’, ‘Color’가 차원 에 해당하고 집계가 가능한 값인 속성 ‘Sales’가 사 실에 해당한다.
즉, 사실 테이블에는 분석의 대상이 되는 데이터들 이 저장되며, 이 데이터들은 차원별로 SUM, AVG, MIN, MAX 등의 집계함수를 이용하여 분석 에 활용된다.
일반적으로 OLAP은 데이터 큐브 구조를 사용한 다.[2] 그림 1은 ‘Company’, ‘Region’, ‘Color’ 이렇 게 세 개의 차원 테이블을 가진 데이터 큐브의 예 를 나타내었다.
각 정점은 요약된 데이터를 나타내며 이를 큐보 이드라고 부른다. 정점 큐보이드는 모든 차원에 대 하여 요약한 경우이고, 1차원 큐보이드의 세 정점 은 각각 (Region, Color), (Company, Color), (Company, Region) 만으로 집계한 결과를 나타낸 다. 2차원 큐보이드의 세 정점은 각각 (Color), (Region), (Company) 만으로 집계한 결과를 나타 낸다. 차원의 개수가 많아지고 각 차원의 도메인의 범위가 커질수록 데이터 큐브를 유지하기 위한 저 장 공간이 커지게 되고 사용자 질의 응답시간도 늘어나게 된다. 특히 데이터를 물리적으로 디스크 공간에 저장함으로써 입출력 연산에 많은 시간이 요구되므로 실시간으로 빠르게 운영되어야 하는 데이터스트림 환경에는 부적합하다. 데이터스트림 환경에서의 OLAP에 관한 연구로는 스트림 큐브가 있다.[3] 그림 2는 스트림 큐브 구조를 나타낸 것이다. 데이 터스트림 환경에서는 빠른 응답을 위해서 모든 연 산이 메모리 공간 안에서 처리되어야 한다. 이를 위해 스트림 큐브는 다음과 같은 특징을 가지고 있다. 1) 과거의 데이터는 요약해서 저장하고, 최근에 발 생한 데이터는 그대로 저장 2) 관찰 계층(o-layer)과 최소 관심 계층(m-layer) 을 지정하여 두 계층 사이를 관심 영역으로 설 정 3) 관심 영역을 벗어나는 큐보이드는 저장하지 않 음 4) 통계적으로 가장 많은 질의가 발생하는 경로에 대해서만 상세 정보를 저장 이와 같은 방식으로 주어진 메모리 내에서 사용 자가 필요로 하는 정보를 빠르게 제공할 수 있다.
3. 콜센터 데이터 분석
정부 기관에서부터 학교, 인터넷 쇼핑몰에 이르기 까지 직접적인 통화를 통해 상담이 필요한 곳에서 는 모두 콜센터를 운영하고 있다. 콜센터 서비스는-276-표 2 콜센터 데이터의 예 편의를 위해 제공되는 것이지만, 현재 다음과 같은 문제점이 있다. 1) 상담, 요청 증가에 따른 고객 대기 시간 증가 2) 상담 요원의 업무량 증가로 인한 고객응대의 질 저하 3) 늘어나는 콜 량과 과도한 업무증가로 인한 상담 원 이직률 증가 4) 불만 증가 및 서비스의 질 저하에 따른 회사 이 미지의 하락 콜센터 데이터를 OLAP 시스템에 적용하여 분석 하면 위의 문제점을 해결하는데 도움이 될 수 있 다. 분석 결과를 효율적인 관리 운영 및 자원 분배 에 이용하면 콜센터 서비스의 질적 향상을 이룰 수 있으며 나아가 회사 및 단체의 이미지 향상에 도움이 될 것이다.
OLAP 시스템에는 Roll-up, Drill-down 연산이 사용된다.[4] Roll-up 연산은 차원의 계층 구조를 한 단계 상승시키거나 차원을 감소시키면서 데이 터 큐브의 집계 연산을 수행한다. Drill-down 연산 은 차원을 추가시키면서 데이터의 상세 단계를 탐 색하는 것이다. 이런 연산들 중에서 Roll-up과 Drill-down 연산을 적용함으로써 콜 센터 데이터 에 대한 분석 결과를 도출하였다.
4. OLAP 시스템 구현
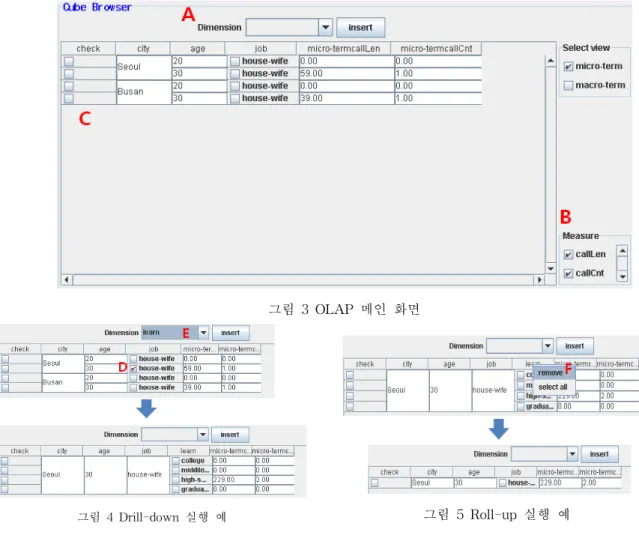
본 구현 시스템은 기존에 수집되었던 콜센터 데이 터에 대한 분석 결과를 도출하였다. 표 2는 콜센터 데이터의 한 예이다. 이보다 많은 필드가 생성될 수 있지만, 본 논문에서 제안한 시 스템은 표 2와 같이 8개의 필드만을 사용한다. call_len는 통화시간을 나타내고 call_cnt는 통화횟 수를 나타낸다. 이 두 필드들을 측정치로 사용하였 다. 나머지 6개의 필드들은 차원 속성으로 사용된 다. city는 콜센터 이용자가 거주하는 도시 이름을 나타내고 job은 이용자의 직업을 나타낸다. contents는 콜센터 이용자가 통화를 한 목적을 나 타낸다. manager는 전화를 받은 상담원의 이름을 나타낸다. learn은 콜센터 이용자의 학력을 나타낸 다. 제안하는 OLAP 시스템은 그림 3과 같이 구성된 다. 그림 3의 A에서 차원을 선택하고 B에서 측정 치 값을 선택한다. 선택한 차원은 C에서 컬럼 별 로 나열된다. 각 차원들은 내부적으로 트리 구조로 관리된다. 그림 3은 현재 Seoul, Busan 에 거주하 는 콜센터 이용자들 중에서 20, 30대의 주부의 통 화시간과 통화횟수를 나타낸 것이다. 그림 4는 Drill-down 연산의 수행 과정을 보이고 있다 Drill-down을 수행하기 위해서는 D 처럼 차 원을 선택하고 E에서 확장하려는 차원을 선택함으 로써 Drill-down된 결과를 얻을 수 있다. 그림 5은 Roll-up 연산의 수행 과정을 보이고 있 다. Roll-up을 수행하기 위해서는 F 처럼 차원에서 remove를 선택하여 Roll-up된 결과를 얻을 수 있 다. 그림 4에서 Drill-down 이후의 합산 결과가 이 전과 차이가 나는 것은 실시간으로 들어오는 데이 터를 처리하면서 OLAP 연산을 수행하기 때문이 다. 제안하는 OLAP 시스템은 콜센터 이용자의 나이, 직업, 학업, 거주지 등의 차원을 임의로 선택할 수 있기 때문에 보다 간편하게 작업이 가능하며, 데이 터스트림이 입력됨에 따라 즉시 처리 및 분석 결 과를 갱신시킨다. 이에 따라 사용자는 현재의 입력 데이터에 따른 변화를 빠르게 인식할 수 있다. 본 시스템은 콜센터 데이터에 국한되어 있지만 입력 데이터의 형식을 바꿀 경우 네트워크 트래픽 분석뿐만 아니라 센서 네트워크 등의 다양한 데이 터 스트림으로의 확장 및 적용이 가능해진다.-277-그림 3 OLAP 메인 화면 그림 4 Drill-down 실행 예 그림 5 Roll-up 실행 예
5. 결론
콜센터 데이터뿐만 아니라 네트워크 트래픽 데이 터, 센서 데이터와 같은 데이터스트림 환경에서의 데이터 분석에 대한 연구가 현재 진행 중이다. 본 논문에서는 기존의 정적인 데이터 관리를 위한 데 이터웨어하우스에서의 OLAP을 데이터스트림 환경 에서의 콜센터 데이터에 적용하는 방법에 대해 기 술하고, 이를 구현한 시스템의 특성을 설명하였다. 제안한 OLAP 시스템은 데이터스트림을 메모리 공 간 내에서 처리함으로써 사용자의 질의에 대해서 빠르게 처리할 수 있고 기존의 OLAP 시스템에서 제공하는 연산들을 지원함으로써 분석 활용도를 높였다.[참고문헌]
[1] The OLAP Council, "MD-AIP" the OLAP
Application Program Interface Version 0.5 Specification", 1996
[2] S. Chaudhuri and U. Dayal, "An overview of data warehousing and OLAP technology" SIGMOD Record, vol.26, page 65-74, 1997
[3] Jiawei Han, Yixin Chen, Guozhu Dong, Jian Pei, Benjamin W. Wah, Jianyong Wang, Y. Dora Cai, "Stream Cube : An Architecture for Multi-Dimensional Analysis of Data Streams", Distributed and Parallel Databases 18, page 173-197, 2005
[4] J. Gray, S.Chaudhuri, A.Bosworth, A.Layman, D.Reichart, M.Venkatrao, "Data Cube : A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals", Data Mining and Knowledge Discovery 1, page 29-53, 1997