저작자표시-동일조건변경허락 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게
l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. l 이차적 저작물을 작성할 수 있습니다.
l 이 저작물을 영리 목적으로 이용할 수 있습니다. 다음과 같은 조건을 따라야 합니다:
l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다.
l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다.
저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다.
Disclaimer
저작자표시. 귀하는 원저작자를 표시하여야 합니다.
동일조건변경허락. 귀하가 이 저작물을 개작, 변형 또는 가공했을 경우 에는, 이 저작물과 동일한 이용허락조건하에서만 배포할 수 있습니다.
공학석사학위논문
다중주기 시뮬링크 모델에 대한 고정 우선순위 스케쥴링
Fixed-priority Scheduling for Multirate Simulink Models
2014 년 2 월
서울대학교 대학원
전기·컴퓨터 공학부
오 유 연
위 원 장 : 하 순 회 (인) 부위원장 : 이 창 건 (인) 위 원 : 장 래 혁 (인)
다중주기 시뮬링크 모델에 대한 고정 우선순위 스케쥴링
Fixed-priority Scheduling for Multirate Simulink Models
지도교수 이 창 건
이 논문을 공학석사학위논문으로 제출함
2014 년 1 월
서울대학교 대학원
전기·컴퓨터 공학부
오 유 연
오유연의 석사학위논문을 인준함
2013 년 12 월
i
요약
시뮬링크(Simulink)는 산업계에서 가장 널리 쓰이고 있는 모델 기반 설계 및 시뮬레이션 도구이다. 특히 자동차 산업과 항공 산업 에서 각종 전자제어장치(Electronic Control Unit)를 설계하는데 시 뮬링크 도구를 널리 사용하고 있다. 시뮬링크 모델은 임베디드 코더 (Embedded Coder) 프로그램에 의해 실제 하드웨어에서 수행가능 한 C/C++ 코드로 변환된다. 각 시뮬링크 블록들은 고유의 주기를 가지는 주기적 태스크로 바뀌게 되고 RM(Rate Monotonic) 스케쥴 링 방법으로 수행된다. 이 과정에서 시뮬레이션 행태와 실제 하드웨 어 수행 행태가 달라지게 된다.
본 논문에서는 각 블록마다 다른 주기를 가지는 시뮬링크 모델을 최대한 시뮬레이션과 가깝게 고정 우선순위 스케쥴링 하는 방법을 제안한다. 먼저 시뮬링크 모델을 각각의 의존관계를 기술하여 DAG(Directed Acyclic Graph) 모델로 바꾼다. 그리고 각 블록의 의존관계를 고려하여 고정된 우선순위를 가지는 주기적 태스크 모 델로 변환한다. 또, 그러한 방법 중에 최적의 스케쥴링 방법을 찾아 내는 방법을 제안한다.
위의 방법을 적용함으로써, 다양한 주기를 가지는 시뮬링크 모델 의 시뮬레이션 규칙을 실제 하드웨어 실행에서도 똑같이 적용할 수 있다. 이로써 시뮬링크 모델의 시뮬레이션 결과와 실제 하드웨어 동 작 결과의 차이를 줄이고 시뮬링크 모델 검증 단계에서의 시간과
ii 비용을 아낄 수 있다.
주요어 : 시뮬링크, 고정 우선순위, 주기 태스크
학 번 : 2012-20809
iii
목차
요약 i
목차 iii
그림 목차 v
제 1 장 서론 1
1.1 연구 배경 1
1.2 연구 내용 3
1.3 본문의 구성 5
제 2 장 관련 연구 6
2.1 버퍼링 6
2.2 주기변환 블록 9
제 3 장 시뮬링크 모델 11
3.1 시뮬링크 모델 11
3.2 시뮬레이션 13
3.3 코드 생성 및 실행 15
3.4 시뮬레이션과 하드웨어 동작간의 차이 17
iv
제 4 장 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정 19
4.1 용어, 가정 및 조건 19
4.2 시뮬레이션 규칙 정의 20
4.3 시뮬레이션 규칙을 따르는 고정 우선순위 배정 24
제 5 장 최적의 고정 우선순위 배정 26
5.1 최적의 고정 우선순위 배정 26
5.2 증명 29
제 6 장 결론 및 향후과제 31
6.1 결론 31
6.2 향후 과제 32
참고문헌 33
v
그림 목차
그림 1 데이터 무결성(Data Integrity) 깨짐 ... 6 그림 2 데이터 무결성 보장을 위한 버퍼링... 7 그림 3 주기변환 블록... 9 그림 4 주기변환 블록이 필요한 경우와 필요하지 않은 경우 ... 10 그림 5 자동차 엔진 제어 시뮬링크 모델 ... 11 그림 6 시뮬레이션 결과 그래프 ... 13 그림 7 시뮬레이션 수행 행태 ... 14 그림 8 하드웨어에서의 수행 행태 ... 15 그림 9 시뮬레이션과 하드웨어 수행과의 차이 ... 17 그림 10 만족하기 어려운 시뮬레이션 규칙 ... 20 그림 11 시뮬레이션 규칙을 만족하는 경우 ... 22 그림 12 하나 이상의 우선순위 배정 방법 ... 24 그림 13 최소 주기 블록과 부모 블록 집합(PS) ... 27 그림 14 다음 최소주기 블록과 부모 블록 집합 ... 28 그림 15 임의 우선순위 배정을 최적 우선순위로 변환 ... 29
1
제 1 장 서론
1.1 연구 배경
시뮬링크는 산업계에서 가장 널리 쓰이고 있는 모델 기반 설계 및 시뮬레이션 도구이다. 공학, 순수 과학, 금융, 수학 등의 분야에서 연구 및 개발 목적으로 사용되고 있으면 전세계적으로 100 만명 이상의 연구원들이 사용하고 있다. 특히 자동차 산업과 항공 산업에서 각종 전자제어장치(Electronic Control Unit)를 설계하는데 시뮬링크 도구를 널리 사용하고 있다.
시뮬링크 모델의 개발 과정은 크게 모델 디자인, 모델 시뮬레이션, 자동 코드 생성, HiLS(Hardware-in-the-Loop Simulation) 단계로 나누어져 있다. 첫째, 개발자는 주어진 시뮬링크 블록 집합을 이용해 전체 모델을 설계한다. 둘째, 개발용 PC 위에서 시뮬링크 모델을 시뮬레이션 해보고 모델을 수정한다. 셋째, 시뮬링크의 자동 코드 생성 기능을 이용해 C/C++ 코드를 생성한다. 넷째, 생성된 C/C++ 코드를 실제 하드웨어에 탑재해서 시뮬레이션 및 검증한다.
시뮬링크 모델 개발 과정의 문제점은 PC 위에서의 시뮬레이션 결과와 실제 하드웨어에서의 동작이 다를 수 있다는 점이다.
시뮬레이션에서는 각 블록의 실제 실행시간이나 신호 전달시간을
2
고려하지 않고(Zero-execution time semantics) 각 블록들을 순차적으로 실행하여 그 결과를 보여준다. 반면에 실제 구현에서는 블록들을 여러 개의 주기적 태스크로 변환하여 실행하고 각 태스크를 수행하는데 시간이 걸리기 때문에 그 수행 행태가 많이 달라지게 된다. 또 실제 구현에서 쓰는 RM 스케쥴링 방식은 블록 간의 의존관계를 무시하고 주기 순서대로 스케쥴링 하기 때문에 시간적인 행태가 더욱 달라질 수 있다.
이에 본 논문에서는 위의 문제를 해결하기 위해 시뮬링크 모델 구현에서도 시뮬레이션과 같은 수행 행태를 보이도록 하는 방법을 제안한다.
3
1.2 연구 내용
시뮬링크 모델의 각 블록은 고유의 주기(Sample Time)를 가지고 있으며, 블록 사이에는 신호를 통해 서로 데이터를 주고 받는다. 모델 시뮬레이션 단계에서는 의존 관계에 따라 전체 블록을 일렬로 정렬해 놓고 각 기본 주기(Base Rate)마다 해당하는 블록을 수행함으로써 시뮬레이션 결과를 이끌어 낸다.
이 과정은 실제 수행시간이나 신호 전달 시간을 무시하고(Zero-execution time semantics) 가상의 시간상에서 이루어지게 된다.
모델 시뮬레이션 단계 이후에는 자동 코드 변환과정을 거치게 되는데 이 과정에서 각 시뮬링크 블록들은 고정 우선순위를 가지는 주기적 태스크 모델로 변환된다. 각 시뮬링크 블록은 원래 주기(Sample Time)와 같은 주기를 가지게 되며, 내부적으로는 RM(Rate Monotonic) 스케쥴링 방법으로 동작하게 된다[1,2,3].
RM 스케쥴링 방법은 각 태스크의 우선순위를 각 태스크의 주기가 짧은 순서대로 정하는 방법이다. RM 스케쥴링은 각 태스크의 의존 관계를 무시하기 때문에 의존관계 순서대로 수행하는 시뮬레이션 결과와 다른 행태를 보일 수 있다. 또 종단 간의 지연시간(End-to-end Delay)이 길어지게 되고, 태스크
4
간의 선점 효과로 인해 데이터 무결성이 깨질 수도 있다.
그럼으로써 전체 시스템 분석 및 검증이 더 힘들어진다.
이런 문제를 해결하기 위해 본 논문에서는 각 블록 간의 의존관계를 기반으로 우선순위를 정하는 방법을 제안한다. 먼저 시뮬링크 모델을 각각의 의존관계를 기술하여 DAG(Directed Acyclic Graph) 모델로 바꾼다. 그리고 각 노드의 의존관계와 주기를 기반으로 고정 우선순위를 가지는 주기적 태스크 모델로 바꾼다. 이때 의존관계를 기반으로 우선순위를 정하기 때문에 데이터를 받는 보내는 블록과 받는 블록의 실행순서가 뒤바뀌지 않고, 종단 간의 지연(End-to-end Delay)도 최소화할 수 있다.
이로써 시뮬링크 모델의 시뮬레이션 결과와 실제 하드웨어 수행결과의 차이를 줄일 수 있다. 그러므로 시뮬링크 모델 개발과 검증에 걸리는 시간과 노력을 아낄 수 있다.
5
1.3 본문의 구성
본 논문은 다음과 같이 구성되어 있다. 2 장에서는 시뮬링크 모델에 관한 기존 연구와 그 한계를 설명하고, 이 논문의 기여에 대해 기술한다. 3 장에서는 시뮬링크 모델의 시뮬레이션과 기존 구현에 대해 설명하고 그 문제점을 분석한다. 4 장에서는 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정 방법을 정의한다. 5 장에서는 최적의 고정 우선순위 배정 방법과 그 스케쥴링에 대해 설명하고 마지막으로 6 장에서는 결론을 짓고 후속연구를 기대함으로써 본 논문을 마무리한다.
6
제 2 장 관련 연구
2.1 버퍼링
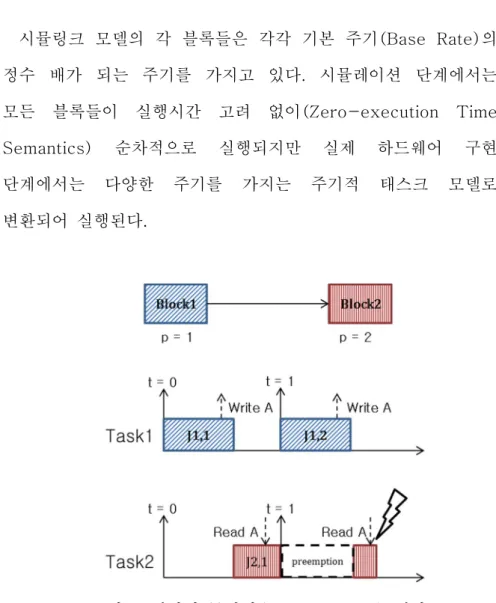
시뮬링크 모델의 각 블록들은 각각 기본 주기(Base Rate)의 정수 배가 되는 주기를 가지고 있다. 시뮬레이션 단계에서는 모든 블록들이 실행시간 고려 없이(Zero-execution Time Semantics) 순차적으로 실행되지만 실제 하드웨어 구현 단계에서는 다양한 주기를 가지는 주기적 태스크 모델로 변환되어 실행된다.
그림 1 데이터 무결성(Data Integrity) 깨짐
7
태스크들이 다른 주기를 가지고 실행됨으로써 데이터 무결성(Data Integrity) 문제가 생기게 된다. 예를 들어 시뮬링크 블록 1 과 2 가 있고, 블록 1 의 주기(Period)는 1, 블록 2 의 주기는 2 라고 하자[그림 1]. 블록 1 은 A 값을 쓰고, 블록 2 는 A 값을 읽는다. 주기가 긴 블록 2 는 블록 1 에 의해 선점 당하고 그 사이에 블록 1 이 A 값을 쓸 수 있다. 이런 상황에서는 블록 2 가 읽어 들이는 A 값이 실행 중간에 바뀌게 되고 그러므로 블록 2 의 데이터 무결성이 깨어지게 된다.
이런 경우 버퍼링 기법을 사용하면 문제를 해결할 수 있다[그림 2]. 주기가 다른 블록과 블록 사이에 의존관계가 있다면 2 개의 버퍼를 두어 하나는 읽기용으로 나머지 하나는 쓰기용으로 사용한다. 그리고 데이터 교환이 필요할 때만 버퍼를 바꾸어서 사용하면 된다.
그림 2 데이터 무결성 보장을 위한 버퍼링
8
기존 연구들은 버퍼링 규약을 정의하고 고정 우선순위(Fixed-priority) 스케쥴링 및 동적 우선순위(Dynamic-priority) 스케쥴링에 따른 버퍼링 방법을 소개하였다. 그리고 주어진 시뮬링크 모델에 따라 필요한 버퍼의 개수를 계산하고, 버퍼를 재사용함으로써 버퍼의 개수를 최소화하였다[4,5,6,7,8].
9
2.2 주기변환 블록
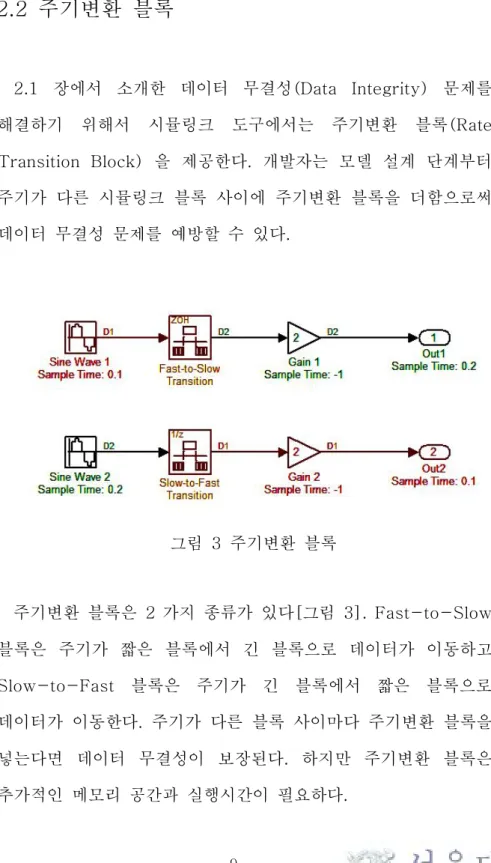
2.1 장에서 소개한 데이터 무결성(Data Integrity) 문제를 해결하기 위해서 시뮬링크 도구에서는 주기변환 블록(Rate Transition Block) 을 제공한다. 개발자는 모델 설계 단계부터 주기가 다른 시뮬링크 블록 사이에 주기변환 블록을 더함으로써 데이터 무결성 문제를 예방할 수 있다.
그림 3 주기변환 블록
주기변환 블록은 2 가지 종류가 있다[그림 3]. Fast-to-Slow 블록은 주기가 짧은 블록에서 긴 블록으로 데이터가 이동하고 Slow-to-Fast 블록은 주기가 긴 블록에서 짧은 블록으로 데이터가 이동한다. 주기가 다른 블록 사이마다 주기변환 블록을 넣는다면 데이터 무결성이 보장된다. 하지만 주기변환 블록은 추가적인 메모리 공간과 실행시간이 필요하다.
10
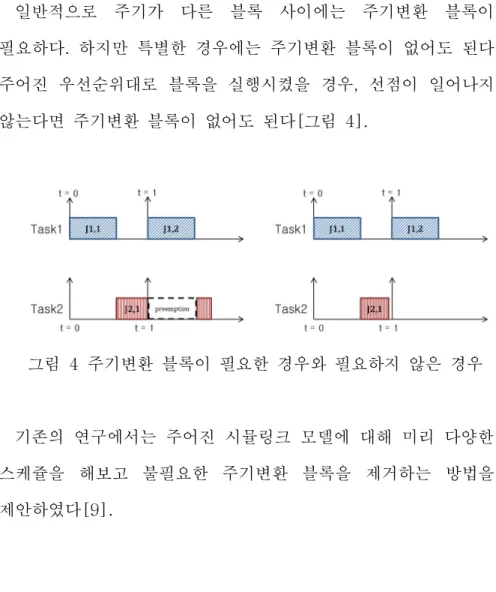
일반적으로 주기가 다른 블록 사이에는 주기변환 블록이 필요하다. 하지만 특별한 경우에는 주기변환 블록이 없어도 된다.
주어진 우선순위대로 블록을 실행시켰을 경우, 선점이 일어나지 않는다면 주기변환 블록이 없어도 된다[그림 4].
그림 4 주기변환 블록이 필요한 경우와 필요하지 않은 경우
기존의 연구에서는 주어진 시뮬링크 모델에 대해 미리 다양한 스케쥴을 해보고 불필요한 주기변환 블록을 제거하는 방법을 제안하였다[9].
11
제 3 장 시뮬링크 모델
3.1 시뮬링크 모델
시뮬링크 블록은 검은색 상자로 나타내며, 주어진 입력에 대해 연산을 수행하고 출력을 내보낸다. 각 블록은 기본 주기의 정수배인 주기(Sample Time)를 가지고 동작한다. 블록 사이에는 신호를 통해 서로 데이터를 주고 받는데 이것은 보통 화살표로 표시한다. 데이터를 보내는 블록은 Source 블록이라고 하고 데이터를 받는 블록은 Sink 블록이라 한다. 이런 경우, 블록 사이에는 의존관계(Precedence Relation)가 있다고 한다.
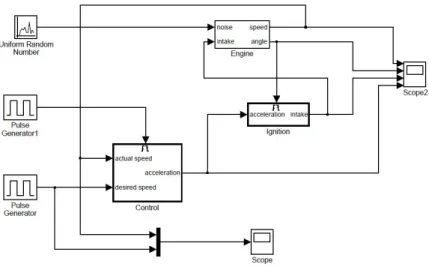
그림 5 자동차 엔진 제어 시뮬링크 모델
12
예를 들어, [그림 5]에 있는 Ignition 블록은 Control 블록으로부터 Acceleration 신호를 받는다. 그리므로 Control 블록은 Source 블록이 되고 Ignition 블록은 Sink 블록이 된다.
이것을 ‘Control 블록 -> Ignition 블록’ 이라고 표시할 수도 있다.
시뮬링크 모델 개발자는 자기가 원하는 블록을 추가하고 블록을 서로 연결함으로써 쉽게 전체 시스템을 디자인할 수 있다.
13
3.2 시뮬레이션
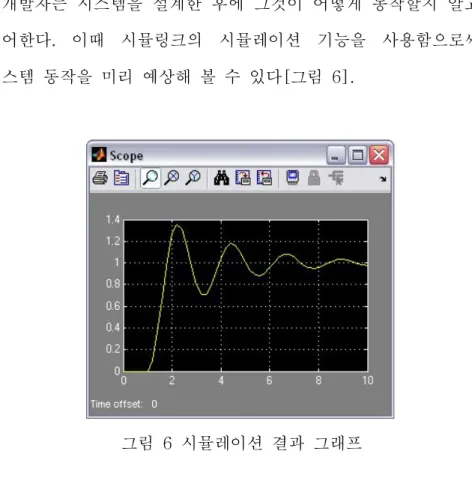
개발자는 시스템을 설계한 후에 그것이 어떻게 동작할지 알고 싶어한다. 이때 시뮬링크의 시뮬레이션 기능을 사용함으로써 시스템 동작을 미리 예상해 볼 수 있다[그림 6].
그림 6 시뮬레이션 결과 그래프
시뮬레이션은 실제 하드웨어가 아닌 PC 상에서 이루어지며, 각 블록의 실행시간이나 신호처리 시간이 무시된다. 그리고 시뮬레이션에 걸리는 시간과 실제 실행시간은 아무 관계가 없다.
예를 들면 [그림 5]과 같은 시뮬링크 모델이 있을 때, 각 블록은 아래와 같은 형태로 시뮬레이션 된다.
14
그림 7 시뮬레이션 수행 행태
먼저 각 블록은 의존관계에 따라 일렬로 정렬된다. 위에서는 Block1 -> Block2 -> Block3 순서대로 정렬된다([그림 7]의 위쪽 그림). 각 시각(t)마다 정렬된 블록 리스트의 앞에서부터 뒤로 해당 블록이 실행되어야 하는지 검사한다. 시각(t)이 0 일 때는 모든 블록이 실행되어야 하고, 그 외의 시각에서는 시각이 해당 블록 주기의 정수배일 때만 실행되어야 한다. 위의 예에서는 시각이 1 일 때, 주기가 1 인 블록 2 만 실행하고 시각이 2 일 때, 블록 1 과 2 만 실행한다. 물론 이때도 일렬로 정렬된 순서를 따라야 한다.
15
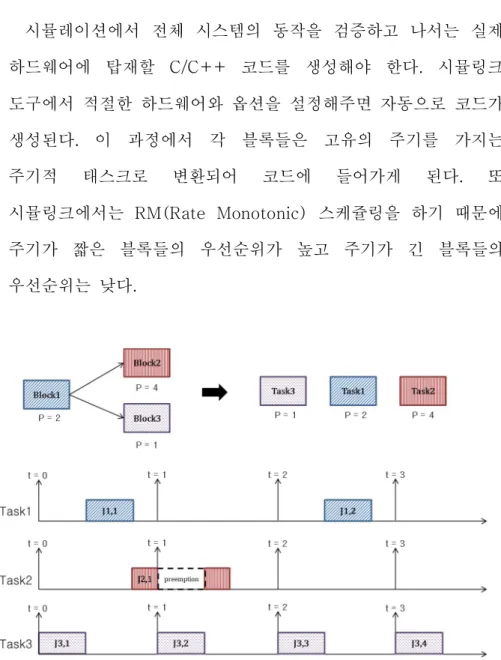
3.3 코드 생성 및 실행
시뮬레이션에서 전체 시스템의 동작을 검증하고 나서는 실제 하드웨어에 탑재할 C/C++ 코드를 생성해야 한다. 시뮬링크 도구에서 적절한 하드웨어와 옵션을 설정해주면 자동으로 코드가 생성된다. 이 과정에서 각 블록들은 고유의 주기를 가지는 주기적 태스크로 변환되어 코드에 들어가게 된다. 또 시뮬링크에서는 RM(Rate Monotonic) 스케쥴링을 하기 때문에 주기가 짧은 블록들의 우선순위가 높고 주기가 긴 블록들의 우선순위는 낮다.
그림 8 하드웨어에서의 수행 행태
16
[그림 7]과 같은 시뮬링크 모델을 실제 하드웨어에서 실행한다고 하면 [그림 8]과 같은 수행 행태를 보인다. 블록 1 은 주기 2, 블록 2 는 주기 1, 블록 3 은 주기 4 를 갖는 주기적 태스크 모델로 변환되고, 태스크 간의 우선순위는 주기가 짧은 순서대로 주어진다. 시뮬레이션과는 다르게 실제 실행 시간이 걸리기 때문에 우선순위가 낮은 태스크 2 와 3 은 태스크 1 에 의해 선점되어 실행이 지연되는 것을 볼 수 있다.
17
3.4 시뮬레이션과 하드웨어 동작간의 차이
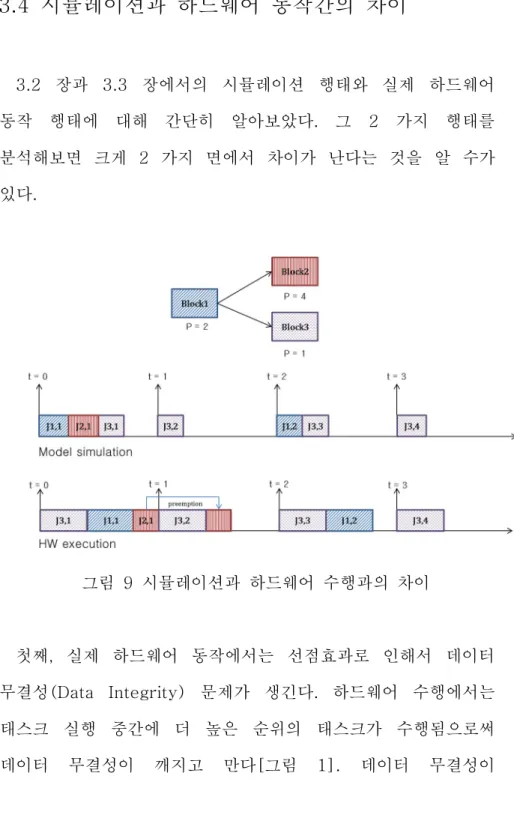
3.2 장과 3.3 장에서의 시뮬레이션 행태와 실제 하드웨어 동작 행태에 대해 간단히 알아보았다. 그 2 가지 행태를 분석해보면 크게 2 가지 면에서 차이가 난다는 것을 알 수가 있다.
그림 9 시뮬레이션과 하드웨어 수행과의 차이
첫째, 실제 하드웨어 동작에서는 선점효과로 인해서 데이터 무결성(Data Integrity) 문제가 생긴다. 하드웨어 수행에서는 태스크 실행 중간에 더 높은 순위의 태스크가 수행됨으로써 데이터 무결성이 깨지고 만다[그림 1]. 데이터 무결성이
18
깨짐으로써 연산 결과가 기대했던 값이랑 달라지게 된다. 이 문제는 2.1 장에서 제안된 버퍼링 기법이나 2.2 장에서 제안된 주기변환 블록을 사용함으로써 해결할 수 있다.
둘째, 실제 하드웨어 동작에서는 RM 스케쥴링을 사용하므로 블록 간의 실행 순서가 뒤바뀌게 된다. 시뮬레이션에서는 의존관계를 유지하면서 실행을 했지만 RM 스케쥴링에서는 의존관계를 무시하고 주기 순서대로 우선순위를 배정하기 때문에 실행 순서가 바뀌게 된다. 예를 들어, [그림 9]에서 시뮬레이션은 항상 블록 1,2,3 의 순서대로 실행되지만 실제 수행에서는 블록 2,1,3 의 순서대로 수행된다. 그러므로 시뮬레이션의 결과와 실제 수행행태가 달라지게 된다. 또, 블록의 실행순서가 바뀜으로써 종단 간의 지연(End-to-end Delay)는 더 길어지게 되고 이것은 시스템의 반응성을 떨어뜨리게 된다. 블록 간의 실행 순서를 보장하려면 RM 스케쥴링이 아닌 다른 우선순위 배정 방법이 필요하다.
19
제 4 장 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정
4.1 용어, 가정 및 조건
주어진 시뮬링크 모델은 N 개의 시뮬링크 블록으로 구성되어 있다. 각 블록은 주기를 가지고 있으며, 블록 사이에는 의존 관계가 존재한다. 각 블록은 해당하는 태스크가 있으며 태스크의 주기는 원래 블록의 주기와 같다. 태스크의 실행시간은 알 수 없으며, 우리가 자유롭게 조절할 수 있는 것은 오직 태스크의 우선순위뿐이다. 또, 우선순위가 같은 태스크는 존재하지 않는다.
실제 하드웨어에서 시뮬링크 코드가 수행될 때에는 이 우선순위에 따라서 스케쥴링된다.
l Bi 는 i 번째 블록을 나타낸다.
l Ti 는 Bi 에 해당하는 태스크를 나타낸다.
l Pi 는 Ti 의 주기를 나타낸다.
l Ji,j 는 Ti 의 j 번째 작업을 나타낸다.
l Ti 와 Tj 사이에 의존 관계가 있으면 Ti -> Tj 로 나타낸다.
l Ti 가 Tj 보다 우선순위가 높다면 Ti > Tj 로 나타낸다.
l 모든 태스크의 주기와 기한(Deadline)은 같다.
20
4.2 시뮬레이션 규칙 정의
먼저 수학적으로 시뮬레이션 규칙을 명확하게 정의하기 전에 시뮬레이션 규칙을 만족한다는 것에 대해 생각해보자.
시뮬레이션의 행태와 실제 하드웨어에서의 수행 행태가 같으면 같을수록 시뮬레이션 규칙을 더 잘 만족한다고 말할 수 있다.
그림 10 만족하기 어려운 시뮬레이션 규칙
만약에 각 시각(Time Step)마다 시뮬레이션에서의 출력값과 실제 하드웨어에서의 출력값이 완전히 같다면 시뮬레이션 규칙을 완벽히 만족한다고 말할 수 있다. 하지만 이렇게 되려면 시각 0 과 1 사이에 모든 블록의 실행이 끝나야만 한다. 왜냐하면
21
시뮬레이션에서는 실행시간이 모두 0 이기 때문에 시각 1 에 모든 블록의 실행이 끝나기 때문이다[그림 10]. 하지만 실제 하드웨어 수행에서도 이것을 만족하는 경우는 매우 드물기 때문에 이것을 시뮬레이션 규칙으로 삼기는 힘들다.
다음으로는 시뮬레이션에서의 출력값과 실제 하드웨어에서의 출력값이 같아야 한다는 것을 시뮬레이션 규칙으로 삼을 수 있다.
앞에서의 시뮬레이션 규칙과는 다르게 각 시각을 정확하게 지켜서 출력값을 내놓을 필요는 없다. 시뮬레이션과 실제 하드웨어 수행에서의 출력값을 같게 하려면 몇가지 조건을 만족해야 한다.
첫째, 시뮬레이션에서 블록 사이의 의존관계를 감안하여 태스크 실행순서를 정하는 것처럼 실제 하드웨어 수행에서도 태스크 사이의 의존관계를 고려해서 태스크 우선순위를 정해야 한다. 기존의 RM 스케쥴링 방식을 사용하면 블록 사이의 의존관계를 고려하지 않으므로 각 태스크 작업의 순서가 달라지게 된다. 그러므로 태스크 우선순위를 정할 때에는 블록 사이의 의존관계가 그대로 지켜지도록 해야한다.
둘째, 각 태스크의 기한(Deadline)까지 태스크 수행이 끝나야 한다. 이것은 스케쥴 가능성 테스트를 통해 그 여부를 알 수 있다. 스케쥴 가능성 테스트를 통과한다면 당연히 둘째 조건도 만족한다.
22
셋째, 선점(Preemption)이 일어나는 경우 버퍼링 기법을 통해 데이터 무결성을 보장해야 한다. 선점이 일어난다면 데이터 무결성이 깨질 수 있기 때문에 별도의 버퍼를 사용하여 출력값을 저장해야 한다. 버퍼링 기법은 이미 그 구현이 다른 연구에 자세히 기술되어 있다..
그림 11 시뮬레이션 규칙을 만족하는 경우
예를 들어, [그림 11]에서 빨간 J2,1 블록은 시뮬레이션에서는 시각 1 에 결과가 나오고 실제 하드웨어 수행에서는 시각 2 에 결과가 나온다. 하지만 실제 하드웨어 수행에서도 블록 사이의 의존관계 B1->B2, B1->B3 를 모두 만족시킨다. 또, 태스크의 기한을 모두 만족한다. 그리고 버퍼링 기법은 이미 구현되어 있어서 데이터 무결성이 보존된다고 가정하자. 그러면 실제
23
하드웨어 수행에서도 시뮬레이션 규칙이 지켜진다고 말할 수 있다.
24
4.3 시뮬레이션 규칙을 따르는 고정 우선순위 배정
4.1 장에서 언급한 시뮬레이션 규칙을 만족하는 고정 우선순위 배정은 찾아보자. Ti -> Tj 라는 의존관계가 있다면 Ti > Tj 를 만족하는 우선순위를 배정함으로써 시뮬레이션 규칙을 만족시킬 수 있다. Ti 의 우선순위가 Tj 보다 높기 때문에 모든 시각 t 에 대해 먼저 시작된
, 의 실행순서가 ,
을 앞선다.
그러므로 시뮬레이션 규칙을 만족시킬 수 있다.
시뮬레이션 규칙을 만족시키는 고정 우선순위 배정방법은 여러 개가 존재한다. 예를 들어, 아래의 [그림 12]과 같은 시뮬링크 모델에서는 블록 사이의 의존관계를 만족시키는 우선순위 배정 방법이 2 개 존재한다. 블록 사이의 의존관계가 복잡해질수록 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정방법은 기하급수적으로 늘어난다.
그림 12 하나 이상의 우선순위 배정 방법
25
위의 방법을 주어진 시뮬링크 모델에 적용한다면 시뮬레이션 규칙을 따르는 고정 우선순위 배정을 하나 찾을 수 있다. 주어진 전체 시뮬링크 태스크 집합 A = {T1, T2, … , TN}, 아직 우선순위가 정해지지 않은 태스크 집합 U = A, 이미 우선순위가 정해진 태스크 집합 C = ∅ 이 있다고 하자. 먼저 집합 U 중에 입력값이 모두 준비된, 다시 말하면 Source 블록이 아닌 태스크를 찾는다. 찾은 태스크가 여러 개일 경우 그 중에 어떤 태스크를 선택하든지 상관이 없다. 찾은 태스크를 Ti 라고 한다면 Ti 최고 우선순위를 배정 받고 U = A – { Ti }, C = C
∪ { Ti } 가 된다. 그리고 Ti 에서 나가는 모든 의존관계는 제거한다. 이런 방법을 반복해서 태스크를 찾을 때마다 그 다음 우선순위를 배정하고 태스크를 U 에서 제거해 나가면 시뮬레이션 규칙을 지키는 우선순위 배정 방법을 하나 찾을 수 있다.
위의 방법대로 우선순위를 정한다면 시뮬레이션 규칙을 만족시키면서 실제 하드웨어에서 수행시킬 수 있다. 하지만 의존관계만을 생각해서 우선순위를 정한다면 스케쥴 불가능한 우선순위 배정을 할 수도 있다(시뮬레이션 규칙을 만족시키는 우선순위 배정의 경우의 수는 매우 많다). 그러므로 블록 사이의 의존관계 뿐만 아니라 주기까지 고려해야만 스케쥴 성공 가능성을 더 높일 수 있다.
26
제 5 장 최적의 고정 우선순위 배정
5.1 최적의 고정 우선순위 배정
4 장에서는 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정방법을 살펴보았다. 시뮬레이션 규칙을 만족하는 고정 우선순위 배정 방법은 무수히 많지만 그 중에는 스케쥴이 불가능한 방법도 있을 수 있다. 그러므로 시뮬레이션 규칙을 만족시키는 고정 우선순위 배정방법 중에 가장 스케쥴 가능성이 높은 최적의 방법을 찾아내어 실제 하드웨어에서 수행하는 것이 가장 합리적이다. 앞으로 시뮬레이션 규칙을 만족하는 우선순위 배정 방법 중에 최적의 우선순위 배정방법을 설명한다.
고정 우선순위 배정에서 최적의 스케쥴링 방법은 주기가 짧은 순서대로 우선순위를 배정하는 RM 스케쥴링 방법이다. 기본적인 접근방법은 블록 사이의 의존관계를 지키면서 주기가 짧은 태스크들에게 더 높은 우선순위를 배정하는 것이다.
27
그림 13 최소 주기 블록과 부모 블록 집합(PS)
먼저 주어진 시뮬링크 모델에서 최소주기를 가지는 블록을 찾는다. 그러면 그 블록에서 들어오는 의존관계(Incoming Dependency)가 있는 모든 부모 블록과 해당 블록으로 이루어진 블록 집합 MP 을 구할 수 있다. 예를 들어 [그림 13]와 같은 주기와 의존관계를 가진 시뮬링크 모델이 주어진다면 최소주기를 갖는 블록은 Block4(P=1)이다. 그리고 그에 따른 부모 블록 집합 PS1 = {Block1, Block2, Block4} 이다. 그러면 이 부모 블록 집합의 블록들에게 가장 높은 우선순위를 배정한다(T1 >
T2 > T4).
28
그림 14 다음 최소주기 블록과 부모 블록 집합
다음으로는 우선순위가 배정되지 않은 블록 중에 가장 주기가 짧은 블록(Block5)을 찾고 이 블록의 부모 블록 집합(PS2)을 찾는다. 이전 단계와 마찬가지로 부모 블록 집합의 블록들에게 그 다음 우선순위를 배정한다(T3 > T5)[그림 14]. 마지막으로 Task6 에게 우선순위를 배정하면 된다(T1 > T2 > T4 > T3 > T5
> T6).
모든 태스크의 우선순위를 배정할 때까지 위의 방법을 반복하면 시뮬레이션 규칙을 만족함과 동시에 가장 스케쥴 가능성이 높은 최적의 우선순위 배정을 찾을 수 있다.
29
5.2 증명
5.1 장에서 기술한 우선순위 배정이 최적이라는 것을 증명하기 위해 다음과 같은 증명방법을 사용한다. 먼저 임의의 스케쥴 가능한 우선순위 배정 A 가 존재한다고 가정하자. 그리고 5.1 장에서 기술한 우선순위 배정을 B 라고 하자. 어떠한 경우에도 A 를 B 로 변환할 수 있으면 5.1 장에서 기술한 우선순위 배정방법 B 가 최적의 우선순위 배정이 된다.
그림 15 임의 우선순위 배정을 최적 우선순위로 변환
시뮬레이션 규칙을 지키면서 모든 태스크의 기한을 준수하는 우선순위 배정 A 가 있다고 가정하자. 최소주기 블록 TM이 있고, 그 태스크 작업들을 JM, 그 기한(Deadline)을 DM 이라고 하자.
TM 의 부모 블록 집합을 PS 라고 하고, 그 중에 가장 짧은
30
기한을 DPS 라고 하자. 또, TM 보다 우선순위가 높은 블록 중에 부모 블록 집합에 포함되지 않는 나머지 블록 집합을 O 라고 하고 그 중에 가장 짧은 기한을 DO라고 하자.
이때 나머지 블록 집합 O 에 들어있는 블록의 우선순위를 TM
보다 낮게 조정한다[그림 15]. 그러면 최소주기 블록 TM 과 그 부모 블록 집합 PS 는 왼쪽으로(높은 우선순위) 이동하게 되고, 나머지 블록 집합 O 는 오른쪽으로(낮은 우선순위)로 이동하게 된다. 이 경우에 우선순위가 높아지는 최소주기 블록 MT 와 그 부모 블록 집합 PS 는 당연히 스케쥴 가능하다. 또, 우선순위가 낮아지는 나머지 블록 집합 O 도 DM기한을 넘기지 않기 때문에 이것 또한 스케쥴 가능하다.
이 방법을 반복적으로 다음 최소주기 블록에도 똑같이 적용한다면 임의의 우선순위 배정 A 는 결국 5.1 장의 우선순위 배정 B 로 변환된다. 다시 말하면 스케쥴 가능한 임의의 우선순위 배정 A 가 존재한다면 우선순위 배정 B 도 역시 스케쥴 가능하다.
그러므로 5.1 장의 우선순위 배정방법이 스케쥴 가능성이 가장 높은 최적의 우선순위 배정이다.
31
제 6 장 결론 및 향후과제
6.1 결론
시뮬링크 모델의 시뮬레이션과 실제 하드웨어 수행 행태는 많은 차이가 있다. 이는 시뮬레이션 규칙과 실제 하드웨어 수행 방식의 차이에서 비롯된다. 실제 하드웨어 수행에서는 의존관계를 지키지 않는 RM 스케쥴링과 선점효과 때문에 시뮬레이션 결과와 많이 다른 수행 행태를 보인다. 본 논문에서는 실제 하드웨어 수행에서도 시뮬레이션 규칙을 최대한 지키기 위해 새로운 고정 우선순위 배정 방법을 제안했다.
제안한 고정 우선순위 배정방법을 사용한다면 기존의 RM 스케쥴링 방법보다 보다 시뮬레이션에 가까운 하드웨어 수행결과를 얻을 수 있다. 하지만 RM 스케쥴링보다 시스템 활용도(Utilization)이 낮기 때문에 스케쥴이 실패할 가능성도 존재한다. 본 논문에서는 스케쥴 가능성을 높이기보다는 시뮬레이션과 최대한 가까운 하드웨어 수행을 보장하면서 가능한 스케쥴 가능성을 높이는 우선순위 배정을 제안하였다.
32
6.2 향후 과제
본 논문에서 제안한 고정 우선순위 배정 방법은 시뮬레이션 규칙을 만족시키지만 전체 시스템의 활용도(Utilization)을 떨어뜨린다. 그리고 실행시간에 대한 고려가 없기 때문에 최적의 우선순위 배정을 하여도 실제 하드웨어에서 실행할 때에는 스케쥴 불가능한 경우가 생긴다.
미리 프로파일링을 수행해서 실행시간에 대한 정보가 있다면 스케쥴 가능성 테스트를 할 수가 있고, 개발자에게 좀 더 많은 정보를 줄 수가 있다. 스케쥴이 불가능하다면 특정 블록의 주기를 낮추도록 개발자에게 조언을 줄 수도 있을 것이다.
반면에 스케쥴이 가능하다면 특정 블록의 주기를 올리도록 하는 방법도 있다. 다시 말하면, 개발자에게 좀 더 많은 선택을 제공하는 시뮬레이션 및 개발 도구를 만들 수도 있을 것이다. 또, 스케쥴 가능성과 시뮬레이션 규칙을 지키는 것의 Trade-off 관계를 좀 더 명확하게 밝히는 것도 필요하다.
33
참고문헌
[1] Kirner, Raimund, et al. "Fully automatic worst-case execution time analysis for Matlab/Simulink models." Real-Time Systems, 2002. Proceedings. 14th Euromicro Conference on. IEEE, 2002.
[2] Scaife, Norman, and Paul Caspi. "Integrating model-based design and preemptive scheduling in mixed time-and event- triggered systems." Real-Time Systems, 2004. ECRTS 2004.
Proceedings. 16th Euromicro Conference on. IEEE, 2004.
[3] Baleani, Massimo, et al. "Efficient embedded software design with synchronous models." Proceedings of the 5th ACM international conference on Embedded software. ACM, 2005.
[4] Tripakis, Stavros, et al. "Semantics-preserving and memory- efficient implementation of inter-task communication on static- priority or EDF schedulers." Proceedings of the 5th ACM international conference on Embedded software. ACM, 2005.
[5] Sofronis, Christos, Stavros Tripakis, and Paul Caspi. "A memory-optimal buffering protocol for preservation of synchronous semantics under preemptive scheduling."
Proceedings of the 6th ACM & IEEE International conference on Embedded software. ACM, 2006.
[6] Di Natale, Marco. "Optimizing the multitask implementation of multirate Simulink models." Real-Time and Embedded Technology and Applications Symposium, 2006. Proceedings of the 12th IEEE. IEEE, 2006.
34
[7] Sangiovanni-Vincentelli, Alberto, and Marco Di Natale.
"Embedded system design for automotive applications." Computer 40.10 (2007): 42-51.
[8] Natale, Marco Di, and Valerio Pappalardo. "Buffer optimization in multitask implementations of simulink models."
ACM Transactions on Embedded Computing Systems (TECS) 7.3 (2008): 23.
[9] Di Natale, Marco, et al. "Synthesis of multitask implementations of simulink models with minimum delays."
Industrial Informatics, IEEE Transactions on 6.4 (2010): 637-651.
35
Abstract
Fixed-priority Scheduling for Multirate Simulink Models
Yuyeon Oh School of Computer Science Engineering
College of Engineering The Graduate School Seoul National University
Simulink is model-based design and simulation tool. It is most widely used in industry. Particularly in the automotive industry and the aerospace industry, it is used for designing various electronic control devices. A Simulink model is transformed into C/C++ codes which can be executed at an actual HW by Embedded Coder tool. Each Simulink block is converted into an inherent periodic task. By default, all these tasks are executed on RM scheduling policy. In the process, the simulation behavior and the actual HW execution behavior are getting different.
36
This paper proposes a new fixed-priority assignment for multirate Simulink models which behaves like simulation. First, a Simulink model is converted into a DAG(Directed Acyclic Graph) considering all dependencies between blocks. Next, the DAG is converted into periodic tasks. Finally, each task is assigned its own fixed-priority to maximize its schedulability.
By applying the above method, Simulink simulation semantics are preserved at actual HW execution. So the difference between simulation results and actual HW execution results can be reduced. And we can save time and costs in Simulink model validation stage.
Keywords : Simulink, Fixed-priority, Periodic Task Student number : 2012-20809