1. 서론 1.1 연구배경 및 목표
최근 한반도에서 일어나고 있는 재해의 규모 및 유형 은 과거와 달리 다양화되고 있다[1]. 계절적으로 발생하 던 태풍 이외에도, 2016년 9월 12일 경상북도 경주시 남
빅 데이터를 이용한 재해 정보 지원에 관한 연구
신봉희1, 전혜경2*
1인천대학교 컴퓨터공학부, 2YM-나을텍
A Study on Disaster Information Support using Big Data
Bong-Hi Shin
1, Hye-Kyoung Jeon
2*1
Dept. of Computer Science & Engineering, Incheon National University
2
YM-NaeulTec
요 약 최근 우리나라에서 일어나고 있는 재해의 규모 및 유형은 과거와 달리 다양화되고 있다. 하지만 우리나라는 이러한 여러 재해를 예측하기 위한 다양한 정보지원체계를 구축하지 못하고 있다. 현재 많은 기관에서 관련정보를 제공하고 있다.
이들 정보는 주로 웹으로 제공되고 있지만 대부분 실시간정보가 아니다. 본 연구에서는 기관들이 제공하는 정보와 함께 좀 더 양질의 실시간 정보를 제공하기 위해서 빅데이터를 활용한 정보지원을 주목하게 되었다. 빅데이터는 실시간성을 갖는 많은 양의 정보가 있고, 이를 이용하여 사용자맞춤 서비스를 할 수 있다. 그 중에서 트위터나 페이스북 등의 SNS는 재난이 발생했을 때 새로운 정보수집매체로서 이용할 수 있다. 그러나 너무 많은 정보로부터 필요한 정보를 자세히 검색하는 것은 무척 어렵고, 직감적인 정보수집이 곤란하다는 문제가 있다. 이를 위해서 본 연구에서는 트위터를 이용한 정보지원시스템을 개발한다. 시스템은 트위터 해시태그를 이용하여 정보를 검색한다. 또한 직감적으로 정보를 파악할 수 있도록, 지도상에 정 보 매핑을 수행한다. 시스템의 평가를 위해, 정보추출, 매핑정도, 추천속도를 평가한다.
주제어 : 융합, 재해, 빅데이터, 트위터, 해시태그, 정보수집
Abstract
Recently, the size and type of disasters in Korea has been diversified. However, Korea has not been able to build various information support systems to predict these disasters.Many other organizations also provide relevant information. This information is mainly provided on the Web, but most of it is not real time information. In this study, we have paid attention to support information using big data to provide better quality real - time information together with information provided by institutions. Big data has a large amount of information with real-time property, and it can make customized service using it. Among them, SNS such as Twitter and Facebook can be used as a new information collection medium in case of disaster. However, it is very difficult to retrieve necessary information from too much information, and it is difficult to collect intuitive information. For this purpose, this study develops an information support system using Twitter. The system retrieves information using the Twitter hashtag.Also, information mapping is performed on the map so that intuitive information can be grasped. For system evaluation, information extraction, degree of mapping, and recommendation speed are evaluated.
Key Words :
Convergence, Big Data, Twitter, HashTag, Information Collection*This work was supported by the research grant Incheon National University in 2017.
*Corresponding Author : Hye-Kyoung Jeon([email protected]) Received June 11, 2018
Accepted August 20, 2018
Revised July 10, 2018 Published August 28, 2018
남서쪽 8km에서 발생한 규모 5.8의 큰 지진이 발생하였 다[2].
재해 발생 시 사람들이 가장 불안하게 여기는 것은 재 해에 대한 정보가 전혀 알려지지 않는 것이다. 재해 시에 과거와 현재 피해정도와 상황 등의 정보뿐만이 아니라 가족이나 지인의 안부에 대한 정보를 요구하게 된다[3].
하지만 우리나라는 이러한 여러 재해를 예측하기 위 한 다양한 정보지원체계를 구축하지 못하고 있다. 기상 청에서 기상특보, 지진, 태풍에 대한 정보를 제공한다. 한 국원자력안전기술원에서 방사선수치를 제공한다. 이외 에도 많은 기관에서 관련정보를 제공하고 있다. 이들 정 보는 주로 웹 포털로 제공되고 있지만 대부분 실시간정 보가 아니다. 본 연구에서는 기관들이 제공하는 정보와 함께 좀 더 양질의 실시간 정보를 제공하기 위해서 빅데 이터를 활용한 정보지원을 주목하게 되었다.
스마트폰의 급격한 보급과 페이스북, 트위터, 카카오 톡 등 다양한 정보채널의 등장으로 우리 주변에는 다양 하고 수많은 비정형 데이터들이 만들어지고 있다. 트위 터는 전세계 1억명의 이용자들이 하루 평균 2억 개의 트 윗을 발생시킨다. 오늘날 11억 인구가 SNS를 이용하고 있는데 2억 5000만 명이 매일 페이스북에 사진을 업로드 하고 있다. 이와 같이 스마트 기기의 보편화와 무선 인터 넷의 안정적인 사용이 데이터의 확산을 가속화 시키고 있다. 또 한 이러한 데이터들로 인해 데이터 트래픽이 급 증하고 있으며, 데이터의 크기와 형태가 다양하고 데이 터가 기하급수적으로 증가하는 빅데이터 시대에 접어들 고 있다. 글로벌 리서치 및 컨설팅 전문기업인 Gartner는 모바일 기기 전쟁, 하이브리드 IT 및 클라우드 컴퓨팅, 전략적 빅데이터 등 10대 기술이 향후 3년 동안 IT 업계 에 상당한 영향을 미칠 것이라고 발표했다[4].
빅데이터는 실시간성을 갖는 많은 양의 정보가 있고, 이를 이용하여 사용자맞춤 서비스를 할 수 있다. 그 중에 서 트위터나 페이스북 등의 SNS는 재난이 발생했을 때 새로운 정보수집매체로서 이용할 수 있다[5,6].
그러나 너무 많은 정보로부터 필요한 정보를 자세히 검색하는 것은 무척 어렵고 갱신되는 정보의 양과 빈도 수가 너무 크다. 그렇기 때문에 사용자는 수많은 정보를 검색하지 않고 사용자가 원하는 정보를 얻는 것은 굉장 히 어렵다. 또한 트위터의 정보는 기본적으로 문자정보 만 있기 때문에 자신의 위치정보와 대조가 어려워 피해 상황을 정확히 인식하는 것이 곤란하다.
본 연구에서는 트위터의 방대한 정보에서 사용자가 원하는 재해 정보만을 추출하는 시스템을 구축하고 시스 템의 유효성을 평가한다. 제안 시스템에서는 해시 태그 를 이용하여 재해 정보를 조사하고, 피해 정보를 지도상 에 매핑함으로써 사용자의 재해 정보 수집을 용이하게 한다.
2. 재해
재해의 사전적 정의로는 "재앙으로 인하여 입은 피 해," "재앙으로 말미암아 받는 피해로 지진, 태풍, 홍수, 가뭄, 해일, 화재, 전염병, 따위에 의하여 받게 되는 피해 이며, 자연적 요인 또는 인위적인 요인으로 말미암아 인 간 및 인간사회에 어떤 파괴력이 가해져 인명이나 사회 적 재산 등의 손실을 입힘으로써 그때까지 구축되어온 사회적 균형이 붕괴되는 일"이라고 정의되어 있다.[7]
본 논문에서는 재해분류 중 지진을 배경으로 연구하 였다. 한반도는 지진학적으로 판구조 운동으로 인한 국 지적 응력이 축적되어 지진이 발생할 수 있는 판 내부에 속하며 발생지진도 판 내부지진의 특성을 갖고 있다. 판 내부지진은 판 경계지진에 비하여 지진의 시공간 분포가 불규칙적이므로, 예측이 쉽지 않으며 지진발생 빈도가 낮고 우발적이라 할 수 있다. 하지만 최근 들어 울진 (2004, 규모 5.2), 오대산 (2007, 규모 4.5) 등 중규모 지진 활동이 한반도 지역에서 비교적 활발하였으며, 발생한 지진들은 주로 남동부 일대에 집중적으로 발생하였다.
최근 경북 경주 남남서 8 km 떨어진 지역에서 발생한 지 진 (경주지진, ‘16. 9. 13, 규모 5.8)은 지진계측이 시작된 1978년 이후 관측된 지진기록 중에서 가장 큰 규모의 지 진이다[8]. 지진과 같은 재해 발생 시 피해자 및 이재민들 에게 가장 중요한 것은 정보이다. 그러나 기존 정보 지원 은 피해자 및 이재민에 대한 정보 발신이며, 피해자가 정 보를 수집하는 것에 대한 정보 지원은 이루어지고 있지 않았다. 이에 대한 해결방안으로 사용자가 계속 정보 수 집을 할 수 있는 환경의 구축을 생각할 수 있다. 그 방법 으로 빅 데이터의 정보 지원 활용이 새로운 정보 지원으 로 주목받고 있다.
3. 빅데이터
3.1 빅데이터
빅 데이터는 다양한 정보의 모임이며, 거대한 데이터 집합 전체의 총칭으로 사용된다. 빅 데이터는 실시간성 을 가진 정보이며, 매일 대량으로 생성되는 정보이다[9].
따라서 인터넷 상에 존재하는 데이터는 기본적으로 모든 데이터가 빅 데이터로 정의 할 수 있게 된다. 이 같은 특 징을 가지고 있기 때문에 빅 데이터는 개인의 특징을 내 포하고 있으며, 개인에 특화된 지원 서비스에 이용되고 있다. 다음에 빅 데이터로 정의 할 수 있는 정보를 말한 다.
3.1.1 구매이력
구매 내역은 슈퍼 나 편의점 등의 상점에서 고객이 구 매한 정보를 기록으로 정리한 정보이다. 기본적으로 언 제, 어디서, 누가, 무엇을 구매했는지 파악하는 것이 가능 하다. 이 정보를 분석하여 가게마다의 인기 상품이나 고 객의 활동 시간 등을 파악하는 것이 가능하게 된다. 따라 서 고객이 방문 시간대에 고객이 자주 구입하는 상품을 제공하는 것으로, 보다 효율적으로 제품을 판매 할 수 있 게 된다[10].
3.1.2 위치정보
위치 정보는 지도상에서 사용자가 존재하는 위치를 나타내는 정보이다. 위치 정보는 사용자가 있는 위도와 경도, 해당 위치에 존재하는 시간으로 정의된다. 위치 정 보를 이용하여 특정 매장 부근에 접근한 경우에는 그 사 용자에게 쿠폰이나 유익한 정보를 제공하는 것이 가능하 게 되어, 보다 효율적인 고객유치가 가능하다. 또한 사용 자의 위치 정보와 비교하여 이용 가능한 대중교통을 추 천하는 일도 가능해진다.
3.1.3 SNS
SNS는 Social Networking Service의 약어이며, 커뮤 니티 형 Web 사이트의 총칭이다. SNS 자체는 빅 데이터 가 아니라 SNS에 투고, 발언되는 정보가 빅 데이터로 취급된다. 이러한 정보는 사용자의 생활에 밀접하고 이 정보를 분석하여 사용자의 취향을 파악하고 더 사용자에 특화된 Web 서비스를 제공 할 수 있게 된다[11].
이 중에서도 Twitter가 피해 시 정보 지원에 이용 될 수 있는 점이 주목 받고 있다.
3.2 트위터
Twitter와는 SNS의 하나이며 140 자 이내의 ‘트윗 '(tweet)이라 불리는 단문을 게시 할 수 있는 정보 서비 스이다 [12]. Twitter는 손쉽게 정보를 발신 할 수 있으 며, 무료로 휴대폰과 PC를 사용할 수 있기 때문에 최근 폭발적으로 이용자가 증가하고 있다. 다음에 Twitter의 특징적인 요소를 기술한다.
3.2.1 해시태그
해시 태그는 Twitter에서 이용되는 정보 분류용 태그 이다. 해시 태그를 트윗에 부여하는 것으로, 같은 해시 태 그 그룹으로 정보를 구성 할 수 있게 된다. 기본적으로 같은 정보는 같은 해시 태그를 부여하여 동일한 정보를 알기 쉽게 정리하는 것이 목적이다. 또한 해시 태그를 검 색하여 동일 그룹 정보를 검색 할 수 있게 된다.
3.2.2 트위터 API
Twitter API는 Twitter를 이용한 응용 프로그램을 개 발할 때 더 쉽게 Twitter를 사용할 수 있도록 하는 인터 페이스이다[13]. API는 Application Programming Interface의 약어이며, 응용 프로그램을 프로그래밍 하는 데 있어 프로그램의 수고를 생략하기 위해서 이용된다.
Twitter API는 무료이다.
4. 제안시스템
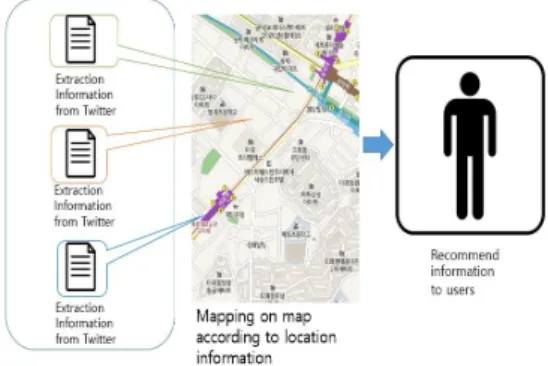
제안 시스템은 해시 태그를 사용하여 사용자에 맞는 재해 정보를 추천하고 추출한 위치 정보를 이용하여 매 핑 한다. 제안 시스템의 흐름을 Fig 1에 나타낸다.
Fig. 1. Flow of the proposed system
제안 시스템은 처음에 Twitter에서 취득한 정보에서 해시 태그 추출한다. 이 추출한 해시 태그를 이용하여 정 보를 감시하고 사용자에게 적합한 재해 정보를 추천한다.
다음은 조사 된 피해 정보에서 위치 정보를 추출한다. 이 추출 된 위치 정보를 지도에 비추어 일치하는 지도상의 위치에 재해 정보를 매핑 한다. 마지막으로 관찰한 재해 정보 및 매핑 한 재해 정보를 사용자에게 제공한다. 감시 와 매핑의 흐름에 대해서는 다음에 설명한다.
4.1 해시태그를 이용한 감시
해시 태그를 이용한 감시는 사용자가 정보를 검색 할 때 해시 태그가 서로 다르고 복잡하기 때문에 정보의 취 득이 곤란하다. 따라서 제안 된 시스템은 내용이 동일한 해시태그를 통일하고 사용자가 쉽게 정보를 얻을 수 있 도록 한다. 다음에서 해시 태그를 이용한 조사의 내용을 말한다.
4.1.1 정보조사의 흐름
해시 태그를 이용한 정보 조사의 흐름을 Fig 2에 나타 내었다.
Fig. 2. Flow of information investigation
제안 시스템은 우선 사용자가 원하는 정보에 대해 검 색한다. 그런 다음 정보를 포함 해시 태그 그룹에서 특징 어를 추출한다. 그리고 같은 특징어를 가진 해시태그 그 룹을 통일하고 새로운 그룹을 생성한다. 이것을 반복하 며 마지막으로 같은 특징어를 가진 해시 태그와 그 정보 를 사용자에게 추천한다. 이렇게 하면 사용자는 복잡한 조사를 할 필요 없이 원하는 정보를 가진 해시 태그와 정 보를 얻을 수 있게 된다.
4.1.2 특징어의 추출
특징어를 추출하기 위해 정보 필터링을 사용한다. 정 보 필터링하여 검색 정보에서 중요도가 높은 명사를 추 출하고 그 명사를 문장의 특징어로 사용한다. 해시 태그 그룹의 특징으로 그룹 내에서 가장 빈도가 높은 특징어 를 설정한다. 이때 검색 내용에 의해 특징어를 추출하는 방법이 다르다. 키워드로 정보 검색을 실시했을 경우, 검 색을 통해 추출된 피해 정보에서 해시 태그를 추출한다.
그리고 추출한 해시 태그마다 해시 태그 그룹의 특징어 를 추출한다.
해시 태그를 통한 정보 검색을 실시했을 경우, 그 해시 태그 그룹에서 특징어를 추출하고 추출된 특징어에 의해 키워드 검색을 수행한다. 그리고 검색된 다른 해시 태그 특징어를 추출하여 해시 태그를 통일한다.
4.1.3 해시태그의 통일
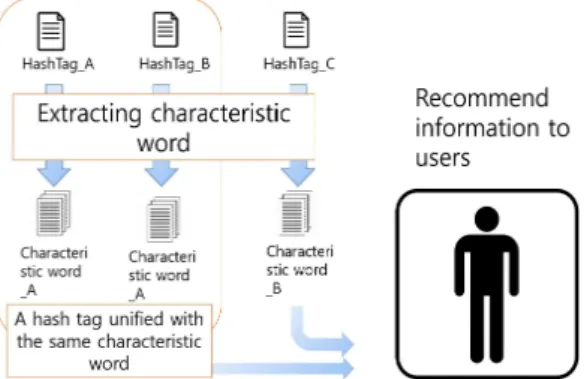
해시 태그 통일의 흐름을 Fig 3에 나타낸다.
Fig. 3. Unification of hash tag
Fig 3에서와 같이 동일한 특징어를 가진 해시 태그가 존재하는 경우, 그들을 동일한 그룹으로 통일한다. 다른 특징어를 가지는 경우 다른 그룹으로 통일하지 않는다.
그리고 해시 태그의 통일을 끝까지 반복해서 그룹화를 더 이상 할 수 없게 된 경우, 해시 태그의 통일을 종료한 다. 이렇게 하면 검색할 때 키워드와 동일한 그룹이 사용 자에게 추천되는 해시 태그 그룹이다.
4.2 매핑에 의한 가시화
사용자는 정보를 취득할 때, 재해 정보와 자신의 위치 정보와 대조가 어렵고, 피해 상황의 정확한 파악이 곤란
하다. 따라서 제안된 시스템은 재해 정보의 위치 정보를 이용하여 매핑을 수행하고 사용자가 쉽게 피해 상황을 파악할 수 있도록 한다. 다음에 해시 태그를 이용한 조사 의 내용을 기술한다.
4.2.1 매핑의 흐름
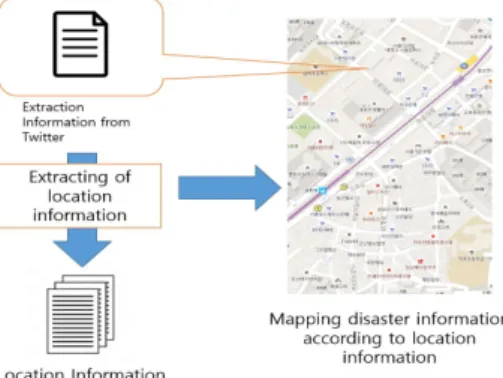
매핑 흐름을 Fig 4에 나타낸다.
Fig. 4. Flow of mapping
제안 시스템에서는 먼저 조사 정보로부터 위치 정보 를 추출한다. 이 위치 정보를 통해 사용자는 직관적으로 피해 상황 파악이 가능해진다. 다음에 매핑에서 각 항목 의 내용에 대해 기술한다.
4.2.2 위치정보의 추출
위치 정보를 추출을 위해 정보 필터링을 사용한다. 첫 째, 정보 필터링을 통해 글 내용에서 명사를 추출한다. 그 리고 추출한 명사와 사전에 준비한 지명 사전과 비교하 여 일치하는 명사를 그 피해 정보의 위치 정보로 추출한 다. GPS 위치 정보가 추가되는 경우, 그 위치 정보를 재 해 정보의 위치 정보로 추출한다. 그러나 정보에서 취득 한 위치 정보와 GPS 위치 정보가 다른 경우, GPS 위치 정보보다 정보에서 취득한 위치 정보를 중요시한다. 이 것은 정보 발신자가 피난 지점에서 피해 상황을 발신하 고 있거나 피해 지역 외부에서 정보 제공을 고려하기 때 문이다.
4.2.3 정보매핑
추출된 위치 정보를 바탕으로 지도와 일치하는 위치 에 정보 내용을 매핑한다. 매핑에 사용되는 지도 정보는
Google Map [14]의 API를 사용한다. 이때 사용자의 위치 정보에 가까운 피해 정보를 중심으로 매핑한다. 이것은 더 사용자에게 관련있는 재해 정보를 추천하다. 위치 정 보를 추출 할 수없는 피해 정보를 이용하지 않고 사용자 에게 정보를 추천하게 된다.
5. 평가 및 결론
5.1 평가환경 및 방법
제안 시스템은 사용자가 재해 정보를 쉽게 추출해서 서비스를 받는 것을 목적으로 한다. 따라서 제안된 시스 템에서는 추천 재해 정보 및 사용자가 원하는 재해 정보 의 일치율과 추천 재해 정보의 매핑의 일치율 및 재해 정 보 추천 속도에 대한 평가를 실시한다. 평가의 재해 정보 로 잡음 데이터, 해시 태그 데이터, 위치 정보 데이터, 세 가지 정보를 사용한다. 잡음 데이터는 재해 정보를 포함 하지 않거나 사용자가 원하는 재해 정보가 아닌 정보로 구성된 데이터 집합이다. 해시 태그 데이터는 사용자가 원하는 재해 정보이며, 해시 태그가 부여된 피해 정보로 구성 된 데이터 집합이다. 해시 태그 데이터는 위치 정보 를 유지하지 않도록 설정하고 있다. 초기 데이터량으로 잡음 데이터는 1000개, 해시 태그 데이터는 500개, 위치 정보 데이터는 500개로 한다. 대상 Twitter는 시간이 지 남마다 정보량이 방대해 진다. 따라서 평가에서도 그런 환경에 견딜 수 있는지를 검증 할 필요가 있다. 이번 평 가에서는 2 번째 이후의 조사 시 1 회당 500개의 잡음 데 이터를 정보로 제공한다.
5.2 평가환경 및 방법
Table 1과 Fig 5에 평가 결과를 나타낸다.
Table 1. Evaluation results 1
1st 2nd 3rd
Degree of matching
information 90% 88% 87%
Degree of mapping 88% 85% 84%
Speed of
recommanding 0.3 sec 0.4 sec 0.6 sec
Fig. 5. Evaluation results 1
평가 결과에서 제안된 시스템은 충분한 정확도를 가 지고, 사용자에게 재해 정보를 추천하는 것이 가능하다 고 할 수 있다. 횟수가 거듭될수록 수치가 떨어지는 이유 는 다음과 같다.
* 정보 일치도 하락
정보의 일치도의 저하는 잡음 데이터가 커진 것이 원 인이라고 생각한다. 잡음 데이터에서 추천 정보와 비슷 한 특징어를 추출하기 때문에 추천 정보에 잡음 데이터 가 섞여 버리고 있다. 이 문제를 해결하려면, 특징어 추출 정밀도를 올려 다른 정보와 충분한 차이가 잡히게 할 필 요가 있다. 그러나 그 차이를 너무 많이 하면 해시 태그 의 통일이 어려울 수 있기 때문에 균형 잡힌 특징어 추출 을 생각할 필요가 있다.
* 매핑 일치도의 하락
매핑의 일치도의 저하는 여러 위치 정보가 문장 내용 에서 추출되는 것이 원인이라고 생각된다. 여러 위치 정 보가 추출된 경우 사용자의 위치 정보에 가까운 위치 정 보를 중요시했기 때문에 문장 내용에 부합하지 않는 위 치 정보가 추출되어 버리는 경우가 존재한다. 따라서 위 치 정보도 글 내용에서 중요도를 결정하고 보다 정확하 게 위치 정보를 추출 할 필요가 있다. 또한 해시 태그에 의한 조사의 정확도가 떨어졌다하여 잡음 데이터가 섞인 것도 매핑의 정확성이 저하 된 원인으로 간주되기 때문 에 해시 태그에 의한 정보의 조사도 정확도를 향상시킬 필요가 있다.
* 추천속도의 저하
추천 속도의 저하는 검색 대상의 정보가 커진 것이 원 인이라고 생각한다. 시스템의 특성상 대상이 되는 모든 정보는 검색 할 필요가 있다. 이때 첫 번째로 검색한 가 운데 잡음 데이터로 판정해도 2번째 이후의 시스템에서 다시 피해 정보 확인하기 위함이다. 이 문제를 해결하려 면 일단 잡음 데이터로 판단한 경우에는 검색 대상에서 제외함으로써 불필요한 검색을 하지 않도록 할 필요가 있다.
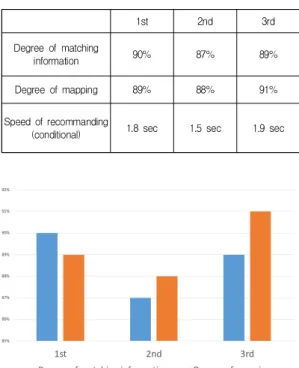
또한 Twitter에서 제안 시스템이 제대로 작동하는지 평가도 실시했다. Twitter에서 정보를 추출하는 수단으 로 Twitter API 중 하나 인 Search API을 이용했다. 이 API는 Twitter에서에서 조건에 맞는 정보를 검색하기 위해 사용된다. Table 2와 Fig. 5에 평가 결과를 나타낸 다.
Table 2. Evaluation results 2
1st 2nd 3rd
Degree of matching
information 90% 87% 89%
Degree of mapping 89% 88% 91%
Speed of recommanding
(conditional) 1.8 sec 1.5 sec 1.9 sec
Fig. 5. Evaluation results 2
평가 결과에서 제안된 시스템은 Twitter에서도 충분 한 정확도를 가지고, 사용자에게 재해 정보를 추천하는 것이 가능하다고 할 수 있다. 추천 정보와 매핑의 일치도 모두 높은 수준을 이 검색이 가능 해지고 있다. 그러나
추천 속도를 조건부로 해야 하는 문제가 생긴다. 그것은 Twitter에서 정보를 검색 할 때 한 번에 검색하는 정보량 이 너무 많이 것이 원인이다. Twitter는 과거의 발신 정 보도 대량으로 존재하고 있기 때문에 단순히 검색하는 것만으로는 방대한 정보량이 생긴다. 이번 평가는 추천 속도를 고려하여 일정수의 정보량을 검색하면 거기서 검 색을 종료하도록 했지만, 그래도 추천 속도의 저하를 초 래 버렸다. 이 문제를 해결하기 위해서는 향후보다 효율 적으로 정보를 검색하는 방법이 필요하다고 생각한다.
향후의 과제로서 검색의 효율성을 통한 속도 향상을 들 수 있다. Twitter에서 정보를 검색 할 경우 대량의 정 보를 한 번에 액세스하기 위해 일반 검색에서 추천 속도 에 큰 부담이 된다. 또한 Twitter API를 이용하는 경우, Twitter 대한 응답 횟수는 일정 수까지로 정해져있다. 따 라서 시스템이 정상적으로 작동하려면 검색 대상 나가는 시기를 지정하거나 정보 발신자의 지정 등에 의한 검색 의 효율성이 매우 중요하다.
본 연구에서는 트위터에서 방대한 정보에서 사용자가 원하는 재해 정보만을 추출하는 시스템을 구축하고 시스 템의 유효성을 평가한다. 제안 시스템에서는 해시 태그 를 이용하여 재해 정보를 조사하고, 피해 정보를 지도상 에 매핑함으로써 사용자의 재해 정보 수집을 용이하게 한다.
빅 데이터를 활용한 여러 분야 중 의료 분야의 예를 들어 보면 빅 데이터를 활용하면 미국 의료부문은 연간 3,300억 달러의 직간접적인 비용 절감 효과를 보일 것으 로 전망했다[15]. 특히 임상분야에서는 의료기관 별 진료 방법, 효능, 비용 데이터를 분석하여 보다 효과적인 진료 방법을 파악하고 환자 데이터의 온라인 플랫폼화로 의료 협회 간 데이터 공유로 치료 효과를 제고하며 공중보건 영역에선 전국의 의료 데이터를 연계하여 전염병 발생과 같은 긴박한 순간에 빠른 의사결정을 가능케 할 전망이 다[16,17]. 재난분야에서도 이와 유사한 효과를 얻을 것으 로 기대된다.
REFERENCES
[1] Y. Yoo & C. Yoon & H. Lee & J. Lee. (2011). A Study on Natural Disaster Damage and Response in Vulnerable Country.
THE JOURNAL OF APPLIED GEOGRAPHY, 29,
77-93.[2] S. H. Oh. & S. H. Shin. (2016). Correlation Analysis of Gyeongju Earthquake Waveform and Structural Damage Scale. JOURNAL OF THE ARCHITECTURAL
INSTITUTE OF KOREA Structure & Construction,
32(12), 33-44.[3] Y. Lee & C. H. Song & C. R. Park.(2016). A Study of Guidelines for Coverage in Dangerous Areas : The Case of Japan. Japanese Cultural Studies, 58, 227-252.
[4] J. B. Yi & C. K. Lee & K. J. Cha. (2015). An Analysis of IT Trends Using Tweet Data. Journal of Intelligence
and Information Systems, 21(1), 143-159.
[5] D. W. Kim. (2013). Big Data Use Cases of the Sector.
Dong-A University Business Research Center, 34,
39-52.[6] J. J. Hong. (2017). The Improvement Plans of Legal Framework and Regulations of IoT Healthcare Service.
KANGWON LAW REVIEW, 50, 801-837.
[7] O. H. Kwan, S. H. Nam, C. H. Lee.(2001). A Study on Practical Analyzing and Improving Disaster Management Organization of Korean Government,
Korea Institute of Fire Science and Engineering,
Volume 15, Issue 1, pp.127-138[8] S. H. Oh & S. H. Shin.(2016) Correlation Analysis of Gyeongju Earthquake Waveform and Structural Damage Scale,
JOURNAL OF THE ARCHITECTURAL INSTITUTE OF KOREA Structure & Construction,
32(12), 33-44.[9] E. Y. Lee & D. O. Park & I. O. Choi. (2014). Current Status of Educational Big Data Research. Proceedings
of the Korean Society of Computer Information Conference, 22(2), 175-176.
[10] S. Choi & Y. J. Hyun & N. G. Kim. (2015) Improving Performance of Recommendation Systems Using Topic Modeling. Journal of Intelligence and Information
Systems, 21(3) ,101-116.
[11] B. S. Kim. (2014). Analyzing SNS Users’ Knowledge Sharing Behaviors in a Big Data Era: A Privacy Calculus Model Perspective. The e-Business Studies, 15(1), 297-315.
[12] Twitter,2018/01/01,https://twitter.com/
[13] https://developers.google.com/maps/?hl=ko
[14] James M. & Michael C. (2011). Big data: The next frontier for innovation, competition, and productivity,
McKinsey Global Institute, pp. 1-36.
[15] Y. J. Yi & S. H. Lee & J. S. Yi. (2014). KB Kookmin Card`s Marketing Activities and Use of Big Data. Korea
Business Review, 18(1), 145-176.
[16] S. W. Kim.(2017). Value Model for Applications of Big
Data Analytics in Logistics,
Journal of Digital Convergence, 15(9), pp.167-178
[17] J. S. Han(2014). Utilization Outlook of Medical Big Data in the Cloud Environment,
Journal of Digital Convergence, 12(6), pp.341-347
신 봉 희(Shin, Bong Hi) [정회원]
▪1977년 : 인하대학교 전자공학과 공학사
▪1981년 : 인하대학교 전자공학과 공학석사
▪1995년 : 단국대학교 전자공학과 공학박사
▪2010년 ~ 현재 : 인천대학교 컴퓨터공학부 교수
▪관심분야 : 마이크프로 프로세서, 임베디드시스템, 사 물인터넷
▪E-Mail : [email protected]
전 혜 경(Jeon, Hye Kyoung) [정회원]
▪1995년 2월 : 인하대학교 일문과 (문학사)
▪1999년 8월 : 인하대학교 정보공 학과(공학석사)
▪2002년 9월 ~ 2005년 8월 : 인하 대학교 컴퓨터정보학과 박사수료
▪2009년 4월 ~ 2015년 2월 : 이스트림 선임연구원
▪2016년 3월 ~ 현재 : YM나을텍 선임연구원
▪관심분야 : 상황인식, 센서네트워크, 유비쿼터스, 사물 인터넷
▪E-Mail : [email protected]