Wood Classification of Japanese Fagaceae using Partial Sample Area and Convolutional Neural Networks
13
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
(12)
(13)
수치

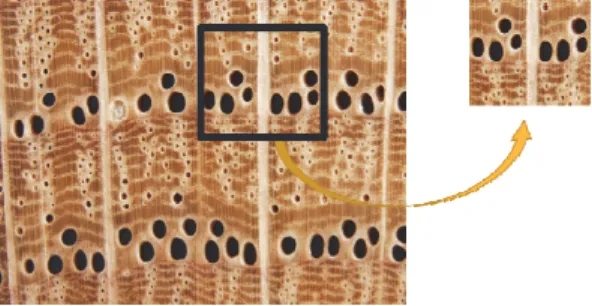
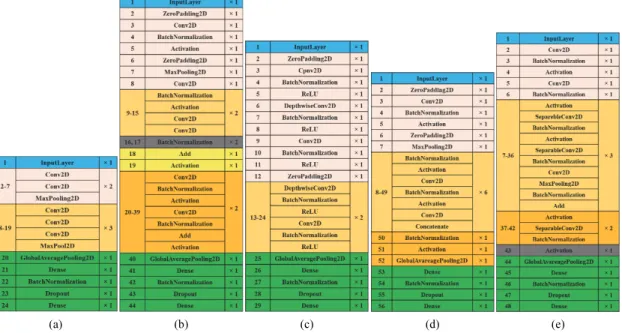

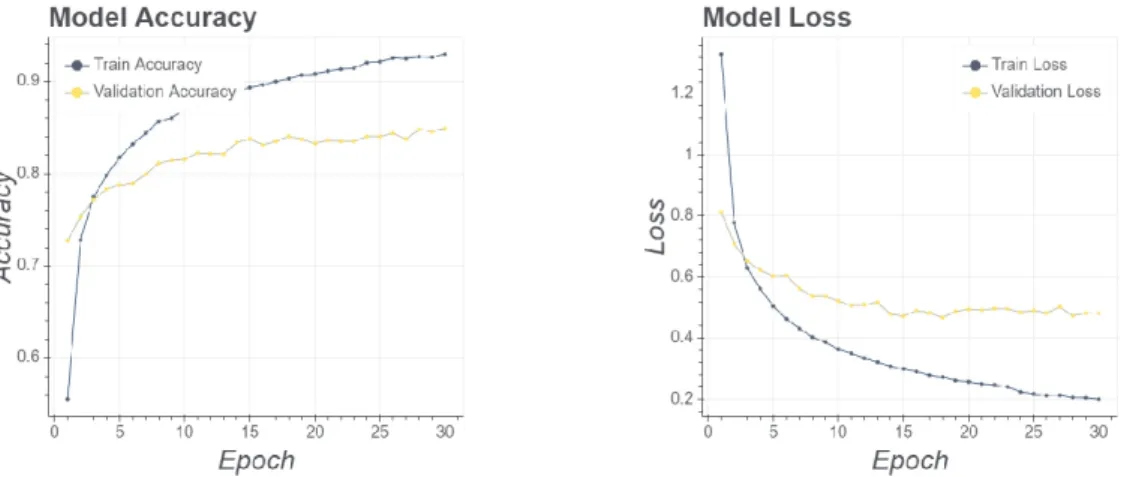
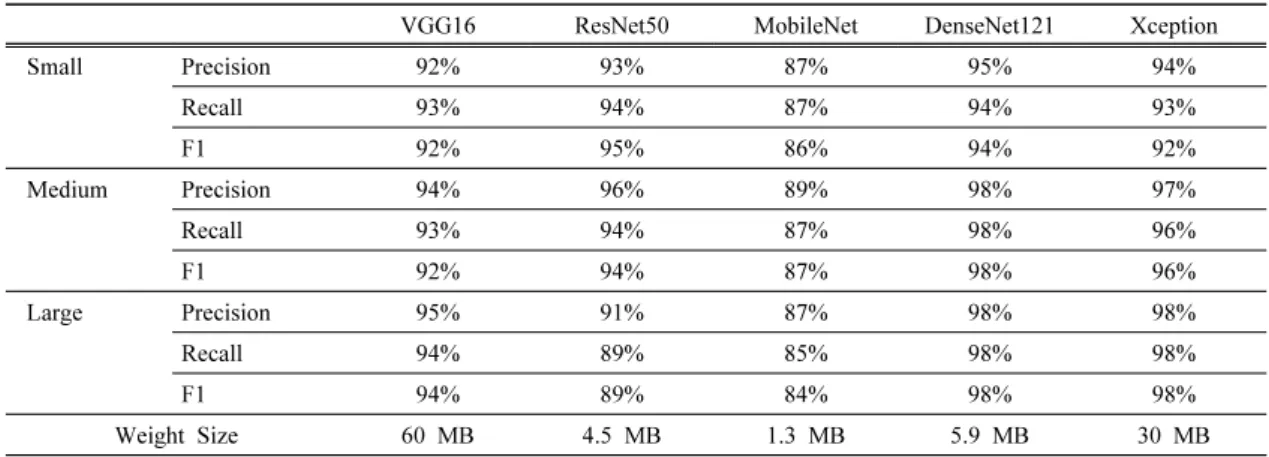
+4

관련 문서
• Pathology.. 출처: American Joint Committee on Cancer staging system for thyroid cancers using the TNM classification. Harrison 18 th Edition.. Postsurgical hypoparathyroidism.
웹 표준을 지원하는 플랫폼에서 큰 수정없이 실행 가능함 패키징을 통해 다양한 기기를 위한 앱을 작성할 수 있음 네이티브 앱과
각 브랜드의 강점과 약점이 서로 상충되는 경우, 각 브랜드에 있어서 어떤 속 성의 약점을 다른 속성의 강점에 의해 보완하여 전반적인 평가를 내리는 것.
The key issue is whether HTS can be defined as the 6th generation of violent extremism. That is, whether it will first safely settle as a locally embedded group
The “Asset Allocation” portfolio assumes the following weights: 25% in the S&P 500, 10% in the Russell 2000, 15% in the MSCI EAFE, 5% in the MSCI EME, 25% in the
1 John Owen, Justification by Faith Alone, in The Works of John Owen, ed. John Bolt, trans. Scott Clark, "Do This and Live: Christ's Active Obedience as the
The sample group that satisfied the 10% capital adequacy ratio, the sample company that achieved the net income of 2 billion standard requirement, the
The number of the sample apartment houses is 949, the sale price was determined as the subordinate variables and the characteristics of structure,
