水 工 學
大 韓 土 木 學 會 論 文 集第26卷 第4B 號·2006年 7月 pp. 389 ~ 398
강우-유출 예측모형 개발을 위한 자기조직화 이론의 적용
Application of Self-Organizing Map Theory for the Development of Rainfall-Runoff Prediction Model
박성천*·진영훈**·김용구***
Park, Sung Chun · Jin, Young Hoon · Kim, Yong Gu
···
Abstract
The present study compositely applied the self-organizing map (SOM), which is a kind of artificial neural networks (ANNs), and the back propagation algorithm (BPA) for the rainfall-runoff prediction model taking account of the irregular variation of the spatiotemporal distribution of rainfall. To solve the problems from the previous studies on ANNs, such as the overesti- mation of low flow during the dry season, the underestimation of runoff during the flood season and the persistence phe- nomenon, in which the predicted values continuously represent the preceding runoffs, we introduced SOM theory for the preprocessing in the prediction model. The theory is known that it has the pattern classification ability. The method proposed in the present research initially includes the classification of the rainfall-runoff relationship using SOM and the construction of the respective models according to the classification by SOM. The individually constructed models used the data corresponding to the respectively classified patterns for the runoff prediction. Consequently, the method proposed in the present study resulted in the better prediction ability of runoff than that of the past research using the usual application of ANNs and, in addition, there were no such problems of the under/over-estimation of runoff and the persistence.
Keywords :
rainfall-runoff model, self-organizing map, preprocessing, back propagation algorithm, persistence phenomenon···
요 지
본 연구에서는 강우의 시·공간적 분포의 불규칙한 변동성을 고려한 강우 - 유출예측모형을 위해 인공신경망 (Artificial Neural Networks: ANNs) 의 기법의 일종인 자기조직화 (Self Organizing Map: SOM) 이론과 역전파 학습 알고리즘 (Back
Propagation Algorithm: BPA 을 복합적으로 이용하였다 . 기존의 인공신경망 연구에서 야기된 저·갈수기의 유출량에 대한 과
대평가 , 홍수기의 유출량에 대한 과소평가 , 예측값이 연속적으로 선행 유출량을 나타내는 Persistence 현상을 해결하기 위하
여 패턴분류 성능을 지닌 SOM 이론을 예측모형의 전처리 과정으로 이용하였다 . 먼저 , 본 연구에서 제안한 방법은 SOM 에
의해 강우 - 유출 관계를 분류하고 , SOM 에 의한 분류에 따라 각각의 모형을 구성한다 . 개별적으로 구축된 모형은 유출량의
예측을 위해 각각의 양상에 따라 분류된 자료를 이용한다 . 결과적으로 본 연구에서 제안한 방법은 과거의 인공신경망의 일
반적인 적용에 의한 결과보다 더 나은 예측능력을 보여주었으며 , 더불어 유출량의 과소 및 과대추정과 Persistence 현상과 같은 문제점이 나타나지 않았다 .
핵심용어 : 강우 - 유출모형 , 자기조직화 이론 , 전처리 과정 , 역전파 학습알고리즘 , Persistence 현상
···
1. 서 론
강한 비선형성의 경향을 보이고 있는 강우-유출간의 관계 를 모형화하기 위한 연구는 다양한 방법론으로 적용되어 활 발히 연구되고 있다. 그 중에서 인공신경망을 이용하여 강우 -유출간의 관계를 모형화하기 위한 대부분의 연구들은 역전 파 학습 알고리즘을 이용하였다. 이는 강한 비선형성을 나타 내는 입·출력간의 관계를 나타내는데 탁월한 성능을 보이 고 있는 것으로 알려져 있으며, 또한 자료들의 급격한 변화
에 대한 뛰어난 적응성을 보여주고 있다. 이러한 인공신경망 의 장점들은 다른 모형들과의 비교에서 우수한 예측력을 보 여주는 것으로 평가받고 있다. 적용 예를 살펴보면 김주환 (1993)은 일유출량 및 시유출량의 예측에 있어 국내의 평창 강 유역에 대한 신경망의 적용에 대한 연구 결과를 발표하 였고, 이관수 등(2000)은 인공신경망의 이론의 BP 알고리즘 을 적용한 영산강의 유출량을 예측하였고, Coulibaly 등 (2000)은 신경망의 BP 학습알고리즘을 이용, 저수지 일 유 입량을 예측하는데 적용하여 ARMAX 등의 타 방법과 비교 *
정회원·교신저자·동신대학교토목공학과교수·공학박사(E-mail : [email protected])
**
정회원·동신대학교토목공학과연구원·공학박사(E-mail : [email protected])
***
정회원·한국건설기술연구원수자원연구부연구원·공학박사(E-mail : [email protected])
하였으며 , Luk 등 (2000) 은 강우예측을 위해 인공신경망을 적용하였으며 , 이들은 우수한 예측력을 보여주었다 .
그러나 지금까지 적용되어진 기존의 인공신경망을 이용한 대부분의 연구들은 강우 - 유출해석에 있어 다양한 강우사상을 반영하는데 미진할 뿐만 아니라 , 예측의 대상인 유출량의 경 우 저·갈수기의 자료에 대해서는 과대평가의 경향이 나타 나며 , 홍수기의 자료에 대해서는 과소평가되는 경향이 있다 .
또한 인공신경망 모형의 구축에 있어 예측 대상자료인 유출 량의 선행값을 이용할 경우 그 예측값이 선행 유출량의 지
속성을 갖는 Persistence 현상이 유발된다 . 또한 강우 - 유출관
계를 규명하기 위한 대부분의 연구들이 홍수기의 강우 및 유출 자료를 이용하기 때문에 개발된 예측모형이 홍수사상 에 한정되는 한계를 보여주고 있다 .
이에 본 연구에서는 기존의 인공신경망 연구에서 야기된 현상들을 해결하기 위하여 탁월한 패턴분류 성능을 지닌 자 기조직화 이론을 도입하여 자료의 전처리 과정으로 이용하 였다 . 인공신경망 이론은 예측뿐만이 아니라 대상자료들의 양 상을 분류하여 그 특성을 분석하는 데에도 이용되고 있다 . 본 연구에서 적용한 자기조직화 이론의 적용 예를 살펴보면 김
용구 등 (2006) 은 자기조직화 이론을 도입하여 영산강 나주지
점의 강우 - 유출특성을 분석하였고 , Hsu 등 (2002) 은 Self- Organizing Liner Output map(SOLO) 을 이용하여 강우 - 유 출패턴을 구분하였고 , Garcia 등 (2004) 은 입력패턴의 분류를
위해 K-means 알고리즘을 이용하여 하수처리모니터링에 적
용하였다 .
자기조직화 이론을 강우 - 유출 예측모형의 전처리 과정으로 도입한 본 연구의 방법과 지금까지 적용되어진 기존의 방법 을 비교·검토하기 위하여 대상지점으로 영산강 유역을 대 표하는 나주지점을 선정하였다 . 나주지점의 유출량을 예측하 기 위하여 대상지점에 영향을 미치는 광주 , 능주 , 동곡지점 의 강우자료를 이용하여 강우 - 유출관계를 모형화하기 위해
본 연구에서 제안한 모형과 기존의 인공신경망 모형을 이용 하여 홍수 예·경보발령을 위해 필요한 선행예보 최소시간 인 3 시간 후의 유출량을 예측하여 그 결과를 비교하였다 .
2. SOM(Self-Organizing Map)의 기본이론2.1 개요
SOM 은 다차원의 자료를 2 차원으로 사상 (mapping) 시켜주
는 신경회로망의 한가지로써 , 클러스터링을 위한 방법으로 많이 사용된다 . 특히 SOM 은 복잡한 다차원 자료의 클러스 터링에 그 적용성이 뛰어난 방법으로 알려져 있으며 , 자료의 가시화가 쉽고 , 클러스터링 결과의 구조를 미리 지정해줄 수 있는 장점을 가지고 있다 . 또한 입력 자료의 수가 많아도 빠른 시간내에 양질의 결과를 얻을 수 있다 .
SOM 은 비교사 학습방법 (unsupervised learning algorithm) 의 일종으로 스스로 n 차원의 입력 자료들을 클러스터링하여 2
차원으로 사상시켜주며 그림 1 에 SOM 의 일반적인 구조를 나타내었다 . 그림에 도시되어 있는 SOM 구조는 n 차원의 입 력자료를 표현하는 n 개의 입력 노드들과 k 개의 분류영역을 표현하기 위한 k 개의 출력노드로 구성되어 있다 . 모든 입력 노드들은 모든 출력노드들과 연결되어 있고 각각의 연결강
도 (weight) 를 가진다 . 일반적으로 입력노드는 입력자료를 네
트워크로 전달하는 기능을 하며 , 출력노드는 전달된 입력벡 터와 입·출력 노드들을 연결하는 연결강도벡터를 이용하여
두 벡터간의 거리 (distance) 를 계산하는 기능을 수행한다 . 그
림 2 는 입력노드 i 와 출력노드 j 를 연결하는 연결강도 w
ij들 의 행렬을 보여준다 .
이러한 과정에서 각 노드들은 학습할 수 있는 특권을 부
여받기 위해 서로 경쟁 (competitive) 하며 , 거리가 가장 가까
운 노드가 승리하게 된다 . 결국 이 승자 노드만이 출력신호 를 보낼 수 있는 유일한 노드가 된다 . 승자 노드와 이에 인 접한 이웃 노드들만이 제시된 입력벡터에 대하여 학습이 허 용된다 . 이것은 학습에 있어서 전혀 새로운 접근방식이며 이 러한 모형이 제안되기 이전에는 네트워크에 있는 모든 노드 들이 반복학습과정인 훈련을 통해 연결강도를 조정하는 방 법을 이용해 왔다 . 그러나 코호넨 네트워크의 학습 철학은 승자만이 출력을 할 수 있는 “ 승자독점 (winner take all)” 개 념이며 승자와 그의 이웃들만이 그들의 연결강도를 조정할 수 있다 . 이를 위해 먼저 노드의 연결강도 벡터가 임의의 값을 가지면서 적합하게 초기화되어야 하며 각 노드는 다음 세 가지 단계의 중요한 처리 과정인 경쟁과정 , 근접반경의 조정과정 , 적응학습 과정이 진행되는 동안 연결강도를 조정 하게 된다 .
2.2. 경쟁과정 (Competitive Process)
경쟁과정에서 각 노드들은 학습할 수 있는 특권을 갖기 위해 서로 경쟁하며 연결강도 벡터와 입력벡터의 거리가 가 장 가까운 노드가 승자로 판정된다 . m 개의 입력을 가진 입
그림 1. SOM의 일반적인 구조
그림 2. 연결강도 행렬
력패턴과 노드 의 연결강도 벡터를 다음과 같이 정의한다 . (1) (2)
여기서 l은 전체 노드 수이다 .
출력 노드 중의 승자 노드 ( i ( X )) 은 다음의 조건에 의해 결 정된다 .
(3)
위의 식은 입력벡터 ( X ) 와 연결강도벡터 ( W ) 간의 거리가 최 소 일 때의 노드의 위치를 결정하여 i라는 변수를 나타내는 수학적 표현이다 .
결국 , 승자 노드의 선택은 입력벡터의 패턴과 가장 유사한
연결강도 벡터를 선정하는 것이며 , 유사도 (similarity
matching) 측정을 위해 유클리드 거리 (Euclidean distance) 를
이용한다 .
2.3. 근접반경의 조정과정(Cooperative Process) 코호넨의 시스템은 생물학적 모델에서 보여지는 바와 유사
하게 이웃한 노드와의 연계과정 (cooperative process) 을 통한
측면제어 (lateral inhibition) 를 사용한다 . 즉 경쟁과정에서 승 자가 된 노드와 함께 그에 인접한 노드들에게도 제시된 입 력벡터에 대한 학습이 허용되며 인접노드를 결정하는 반경 은 학습이 진행됨에 따라 서서히 줄어들어 점점 적은 개수 의 노드들이 학습을 하게 된다 . 최종적으로는 단지 승자 노 드만이 그것의 연결강도를 조정하게 된다 .
이러한 과정을 위해 출력층의 노드는 1 차원으로 배열하는 방법과 2 차원으로 배열하는 방법이 있으며 , 특히 2 차원 배열 에는 그림 3 에서와 같이 사각형배열 (rectangular array) 과 육 각형배열 (hexagonal array) 의 2 가지 형태가 있다 .
기하학적 반경을 조정하는 과정에 있어 대칭성과 수렴특성 을 지닌 가우시안 함수 (Gaussian function) 를 이용하였다 . 기 하학적 이웃 반경을 정의하는 h
j,i(X)는 이웃한 노드와의 거리 를 나타내는 d
j,i와 함께 다음과 같이 나타낼 수 있다 .
(4)
여기서 , d
j,i(x)는 거리 벡터
γj와 승자노드 i에 의해 정의되는 에
γi의해 다음과 같이 정의된다 .
(5)
그리고 , 일반적으로 지수적 감쇠를 위한
σ는 다음과 같이 선택할 수 있다 .
(6)
식 (6) 에서
σ0는 SOM 알고리즘의 초기화에서 갖는
σ의
값이며 ,
τ1은 시간상수 이다 .
2.4. 적응학습 과정(Adaptive Process)
이상과 같은 단계의 처리가 끝나면 마지막으로는 시냅스의 적응과정과 같은 실제 연결강도의 조정이 이루어진다 . 조정 되기 이전의 연결강도 벡터를 W
j( n ), 조정된 후의 새로운 연결강도 벡터를 W
j( n +1) 와 같이 이산 시간 t 에 대하여 정 의할 때 조정을 위한 규칙은 다음 식으로 표현된다 .
(7)
여기서 ,
η는 시간 n이 증가함에 따라 서서히 감소하는 학습 율을 나타내는 매개변수로서 초기값
η0와 지수적 감쇠를 만 족시킬 수 있도록 다음과 같은 식으로 나타낼 수 있다 .
(8)
τ2
는 SOM 알고리즘의 다른 시간상수 이다 .
3. 대상지점 및 입력자료
본 연구의 대상지점인 영산강 유역은 우리나라 서남부에 위치하며 , 총 유역면적은 3,455 km
2이고 , 본류의 유로연장은
129.5 km 이며 , 본 연구에서는 강우의 시·공간적 분포의 비
선형적 변동성을 고려한 강우패턴을 분류하고 강우 - 유출간의 특성을 분석하기 위해 , 그림 4 에 나타내었듯이 영산강 본류
의 대표지점인 나주수위관측소와 그에 영향을 미치는 상류 의 광주 , 동곡 , 능주강우관측소를 선정하였다 . 수위 및 강우 자료는 영산강홍수통제소의 30 분 자료를 이용하였고 , 나주지 점의 수위자료를 유출량자료로 환산하기 위해 『영산강 유 량측정 보고서』 ( 영산강홍수통제소 , 2004) 의 나주지점의 수 위 - 유량관계곡선을 이용하였다 .
모형의 입력자료 구축을 위해 광주 , 동곡 , 능주강우관측소 의 강우량이 나주지점 유출량에 기여하는 시차를 산정하기 X = [ x
1, , , x
2… x
m]
TW
j= [ w
j1, w
j2, , … w
jm]
T, j 1 2 … l = , , ,
i X ( ) min
arg
jX W –
j, j 1 2 … l , , ,
= =
h
j i X,( )( ) exp n d
j i2,2σ
2( ) n ---
⎝ – ⎠
⎜ ⎟
⎛ ⎞
n
, 0 1 2 … , , ,
= =
d
j i2,= γ
j– γ
i2σ n ( ) σ
0n τ
1---
⎝ – ⎠
⎛ ⎞ n 0 1 2 … , = , , , , exp
=
W
j( n 1 + ) W =
j( ) η n n + ( ) ⋅ h
j i X,( )( ) X W n ⋅ [ –
j( ) n ]
η
( ) n =
η0exp n ⎝ ⎛ –
τ---
2⎠ ⎞ n 0 1 2 … , = , , , ,
그림 3. 이웃반경의 크기 조정 그림 4. 대상지점 유역도
그림 5. 시차결정을 위한 상관분석 결과
그림 6. SOM 적용 흐름도
그림 7. U-matrix method 결과
그림 9. 각 분할구역에 대한 대표적인 강우 - 유출관계
위해 무강우를 제외한 각 강우관측소의 강우자료와 그에 대 한 지체시간을 적용한 나주지점의 유출량자료 사이의 상관 분석을 실시한 결과 그림 5와 같이 광주, 동곡, 능주강우관 측소 모두 7시간 후가 가장 높은 상관성을 갖는 값으로 분 석되었다. 동곡 강우관측소는 다른 강우관측소와 비교하여 나주 수위관측소와 매우 가까운 거리에 위치하여 있으나, 동 곡 강우관측소에 해당하는 지배면적 대부분이 농경지와 산 지가 산재되어있고, 유출로 기여 할 수 있는 큰 지류가 없 는 지형적인 영향으로 인해 근접한 거리에도 불구하고 다른 강우관측소와 같은 지체시간을 나타내는 것으로 판단된다.
그러므로 입력벡터 는 나주지점의 유출량과 각 우량관측소
의 지체시간을 고려한 강우량에 1시간 30분의 시차를 고려
하면 식 9와 같은 12차원 구조의 SOM 훈련 데이터의 구
조가 된다. 1시간 30분의 시차를 적용한 이유는 강우의 양
상과 유출량 사이의 관계를 파악하기 위해서는 긴 시간의 많은 자료가 필요하다고 판단되나, 입력자료의 크기를 최소 화하기 위하여 강우와 유출의 양상을 검토해 본 결과 연속 된 3점(1시간 30분)의 자료로도 강우와 유출량의 증·감이 뚜렷이 구분되어 1시간 30분 동안의 자료를 SOM의 입력자 료로 이용하였다.
x(t)=(P
G(t-16), P
D(t-16), P
N(t-16), Q
(t-2), P
G(t-15), P
D(t-15), P
N(t-15), Q
(t-1), P
G(t-14), P
D(t-14), Q
(t)) (9)
4. 적용방법 및 결과
4.1 SOM 모형의 적용
SOM의 적용을 위해 그림 6의 SOM 적용 흐름도와 같이
그림 10. SOM 에 의해 구분된 강우 - 유출관계 : 강우주상도 및 유량도
그림 11. Event(a) 에 대한 강우 - 유출관계 : 강우주상도 및 유량도
그림 12. Event(b) 에 대한 강우 - 유출관계 : 강우주상도 및 유량도
그림 8. k-means algorithm 결과
광주 , 동곡 , 능주강우관측소의 강우량과 나주유출량의 30 분 자 료로부터 2004 년 6 월 1 일부터 2004 년 7 월 12 일까지의 1,999
쌍의 자료를 선택하여 각 우량관측소와 나주유출량간의 상관 분석으로부터 산정된 시차를 적용하여 1,999 × 12 행렬의
SOM 입력자료를 구축하였다 . 선택된 자료의 정규화 과정을
거친 후 SOM 훈련을 위해 Map 크기를 결정하는데 우선 ,
Map 을 구성하는 단위구조의 총 수 (M) 의 결정은 Garcia 등
(2004) 에 의해 연구 보고된 식을 이용하였다 ( 식 10).
(10)
여기서 M 은 map 을 구성하는 단위구조 (unit) 의 총 수이며 ,
N 은 훈련 자료의 수이다 .
본 연구에서의 훈련자료는 1999 쌍이며 , map 크기는 식 10
에 의해 산정된 224 의 근사치로부터 20 × 12 로 결정하였다 .
결정된 map 크기에 대해 최적의 분할구역 구분은 U-matrix
method 와 K-means algorithm 의 방법을 적용하여 구분할 수
있다 . U-matrix method 에 의해 구분된 결과를 그림 7 에 나
타내었으며 , k-means algorithm 결과 최적의 분할구역으로 구분된 결과는 그림 8 과 같다 . 또한 분할구역의 대표적인 강우 - 유출간의 관계는 그림 9 와 같다 .
또한 SOM 에 의해 구분된 강우 - 유출관계를 규명하기 위해 그림 10 과 같이 도시하였고 , 명확한 결과의 도시를 위하여 강우발생 전후로 한 기간의 사상들을 선별하여 그림
11(Event(a))~ 그림 12(Event(b)) 에 도시하였다 . 그 결과
cluster_1 은 강우량은 감소하는 경향을 보이는 반면 유출량은
점진적으로 증가하는 수문곡선의 상승부 유출부분을 나타내
고 있으며 , cluster_2 는 강우가 시작됨에 따라 유출량은 점
진적으로 증가되는 수문곡선의 상승기점의 유출부분을 나타
내었다 . cluster_3 은 강우량은 급격히 증가되나 유출량의 변
화는 미미한 증가를 보이는 유출부분으로 구분되었으며 ,
cluster_4 는 강우가 종료된 후 또는 1~2 mm 이내의 약한
강우가 발생한 경우이며 그 때의 유출량은 점진적으로 증가 또는 감소하는 수문곡선의 상승부와 감수부의 변곡점 하 ( 下 ) 의 유출부분으로 구분되었다 . cluster_5 는 광주 , 능주 , 동곡강우 관측소 모두 강한 강우강도의 강우가 발생하고 유출량은 급 변하여 증가하는 수문곡선의 첨두부 유출부분으로 분할되었
으며 , cluster_6 은 약한 강우가 발생하거나 강우가 종료될
때 유출량은 증가 또는 감소되는 수문곡선의 상승부와 감수 부의 변곡점 상 ( 上 ) 의 유출부분으로 구분되었다 . 마지막으로
cluster_7 은 무강우기간에 해당하며 유출량의 변화가 미미한
수문곡선의 기저유출부분을 나타내었다 . 이상의 결과와 같이 강한 비선형성을 가지고 있는 강우 - 유출관계가 SOM 의 적용 을 통해 강우 - 유출의 패턴분류가 가능함을 확인 할 수 있었
고 , cluster_4 와 cluster_6 은 수문곡선의 상승부와 감수부의
변곡점을 구분지어 주는 것으로 판단된다 .
4.2 예측모형의 비교 및 검토
본 절에서는 강우 - 유출관계의 패턴분류를 수행하지 않은 기존의 인공신경망 예측모형과 본 연구에서 적용한 SOM 에 의해 패턴분류를 수행한 후 예측모형에 적용한 결과를 상 호·비교를 통하여 앞서 기술한 기존 인공신경망 모형의 연 구에 대한 문제점들을 검토하기 위해 역전파 학습 알고리즘 을 이용하여 모형을 구축하였다 .
모형의 구성은 식 11 과 같이 SOM 의 입력자료와 동일하 게 모형을 구축하였다 . 구축 모형에 대하여 은닉층의 노드 의 수는 기존의 연구결과를 토대로 우수한 예측력을 보이는 것으로 알려진 3 n =36 개 (n 은 입력자료로 본 연구에서는 12
개 ) 를 선택하였고 훈련 수는 20,000 회로 동일 조건하에서
각각의 모형에 대해 홍수예·경보 발령을 위해 필요한 선 행예보 최소 시간인 3 시간 후 유출량을 예측하여 이를 검 토하였다 .
(11)
자료의 범위는 그림 13 과 같이 2004 년 6 월 1 일 0 시 부 터 2004 년 7 월 12 일 15 시까지 모형의 훈련자료로 2004 년
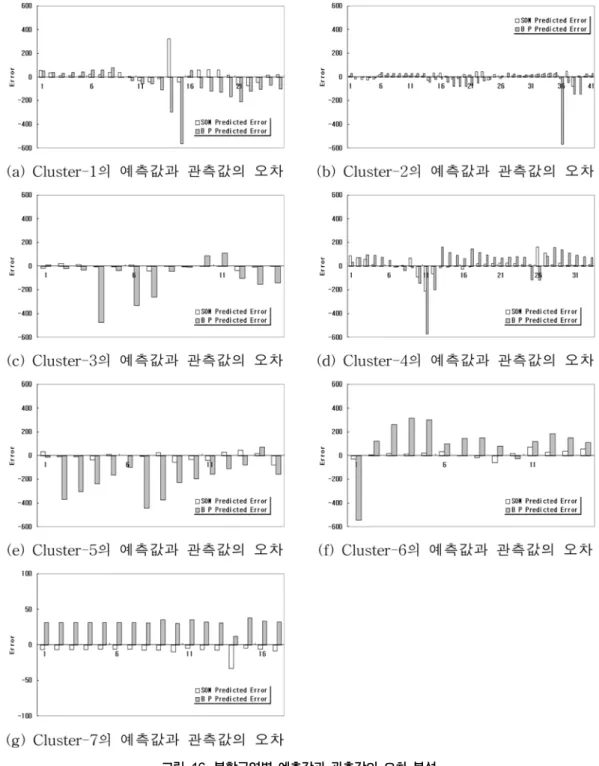
7 월 12 일 15 시 30 분부터 7 월 30 일 23 시 30 분까지를 모형의 검증자료로 활용하였다 . SOM 을 적용하지 않은 모형과 적용 한 모형 사이의 비교를 위하여 훈련에 대하여 패턴분류를 수 행하지 않은 입력자료를 SOM 에 의해 패턴이 구분된 자료군과 동일하게 분할구역별로 추출하여 관측값과 각각의 예측값을 그 림 14 에 도시하였다 . 또한 그림 15 에는 분류된 자료들의 각 예측값들을 이용하여 전 범위의 유출량 값을 재구축 하여 각 각의 산포도와 함께 도시하였고 , 그림 16 에는 각 예측값의 오 차를 도시하였다 . 분할구역별 자료 수가 많은 cluster_4, cluster_6, cluster_7 은 유출량의 크기가 유사한 자료를 각각 5,
5, 100 개를 평균하여 그 예측값의 오차를 나타내었다 .
M 5 N =
Model QNaju(t 6+ ) f
PG t 16(– ),PD t 16(– )
( ,PN t 16(– ),QNaju t 2(– ) PG t 15(– ),PD t 15(– ),PN t 15(– ),QNaju t 1(– )
PG t 14(– ),PD t 14(– ),PN t 14(– ),QNaju t()
=
그림 13. 훈련 및 검증자료의 범위
패턴분류를 수행하지 않은 기존의 방법의 예측값을 BP Predicted, SOM에 의해 패턴분류를 수행한 예측값을 SOM Predicted라고 명명할 때, 저·갈수기 자료와 홍수기 자료로 구분된 cluster-7과 cluster-5의 기저유출부와 첨두부를 그림 14와 16의 결과에서 살펴보면 기저유출부(cluster-7)에서는 기 존의 방법인 BP Predicted는 과대추정, 홍수기자료로 구분된 cluster-5의 첨두부에서는 과소추정의 경향을 나타내고 있다.
반면 SOM Predicted는 관측값에 대응하여 보다 정확한 예 측값을 나타내고 있다. 전반적으로 BP Predicted가 SOM Predicted보다 더 큰 오차를 수반하고 있으며, 그림 15의 전 범위의 유출량 예측의 R
2과 RMSE의 비교에서도 SOM Predicted는 각각 0.9799와 0.0624로 BP Predicted의 0.8942와 0.076보다 더 우수한 예측력을 보여주고 있다.
4.3 모형의 검증
지금까지 도출된 결과의 타당성의 검토를 위해 훈련기간 외의 2004년 7월12일 15시 30분부터 7월 30일 23시 30분 까지의 기간을 선정하여 모형의 검증을 수행하였다. 검증 방 법으로는 검증기간의 자료를 SOM으로 패턴분류를 실시하고, 훈련 과정에서 각 분류별로 결정되어진 매개변수를 이용하여 예측값을 계산하였다. 그 결과를 그림 17에 나타내었으며, 그 림에서 보듯이 기존의 적용방법인 BP predicted는 앞서 기 술한 저·갈수기의 자료의 과대평가, 홍수기의 과소평가되는 문제점과 예측값이 선행 유출량의 지속성을 갖는 Persistence 현상의 문제점을 수반하였다. 반면 SOM predicted는 예측값 이 관측값에 대한 보다 정확한 예측을 해주고 있다.
그림 18과 19는 관측값과 예측값의 산포도를 나타낸 결과
그림 14. 분할구역별 예측값과 관측값의 비교
로 그림 18에서와 같이 기존의 인공신경망의 경우 수문곡선 의 상승부는 산포도의 45
o선상의 아래에 분포하는 과소평 가가 되고 있는 반면에 수문곡선의 하강부는 산포도의 45
o선상의 위에 분포하는 과대평가로 나타나고 있으며, 반시계 방향으로 전이되는 Persistence현상이 명확하게 나타나고 있 으나, 그림 19에서와 같이 SOM을 전처리 과정으로 이용한 인공신경망의 경우는 산포도의 45도 상에 집중 분포되어 있 으며 전이현상이 나타나지 않아 이전단계의 예측값에 지속성 을 갖는 Persistence현상이 제거되었음을 확인할 수 있었다. 또 한 R
2와 RMSE의 비교에서도 SOM Predicted는 각각 0.9971과 0.0778로 BP Predicted의 0.8957과 0.09217보다 더 우수한 예측력을 보여주었다.
5. 결 론
본 연구에서는 영산강 유역을 대표하는 나주지점의 유출량 을 예측하기 위하여 대상지점에 지배적인 영향을 미치는 것 으로 판단되는 광주, 능주, 동곡지점의 강우자료를 이용하여 강우-유출관계를 모형화하고자 하였으며, 예측모형의 구성을 위해 자기조직화 이론을 모형의 전처리 과정으로 적용하였 다. 또한 본 연구에서 제안한 모형과 기존의 인공신경망 모 형을 이용하여 홍수 예·경보발령을 위해 필요한 선행예보 최소시간인 3시간 후의 유출량을 예측하여 그 결과를 비교 하였다. 본 연구를 통해 얻어진 결론은 다음과 같다.
1. SOM으로 구분된 분할구역(Cluster-1~Cluster-7)과 유출과 의 관계를 비교 검토한 결과 Cluster-1은 강우량은 감소하 는 경향을 보이는 반면 유출량은 점진적으로 증가하는 수 문곡선의 상승부 유출부분으로 구분되었고, Cluster-2는 수 문곡선의 상승기점의 유출부분, Cluster-3은 강우량은 급격 히 증가되나 유출량은 미미한 증가를 보이는 유출부분으 로 분류되었다. 또한 Cluster-4는 변곡점 아래의 수문곡선 상승부와 감수부, Cluster-5는 수문곡선의 첨두부로 분류되 었다. Cluster-6은 변곡점 위의 수문곡선 상승부와 감수부, Cluster-7은 수문곡선의 기저유출 부분으로 분할되었다.
2. 기존의 인공신경망 모형과 SOM을 전처리 과정으로 이용 한 인공신경망 모형을 상호 비교한 결과 훈련과정에 대한 R
2은 0.8942와 0.9799, RMSE는 0.076과 0.0624로 각각 나타났으며, 검증과정의 R
2은 0.8957에서 0.9971, RMSE 는 0.09217에서 0.0778로 향상되어 과소 및 과대평가되는 현상을 개선할 수 있었다.
3. 관측값과 예측값을 나타내는 산포도에 의하면 수문곡선의 상승부는 과소평가가 하강부의 과대평가로 반시계방향으 로 전이되는 Persistence현상이 명확하게 나타나고 있으나, SOM을 전처리 과정으로 이용한 인공신경망의 경우는 이 상적인 적합을 나타내는 45도 선상에 집중 분포되어 있으 며 전이현상이 나타나지 않아 Persistence 현상이 제거되 었다.
4. 마지막으로, SOM 적용의 심화연구를 위해 강우자료 또는 그림 15. 모형의 훈련 결과 및 산포도
그림 17. 모형의 검증 결과
그림 16. 분할구역별 예측값과 관측값의 오차 분석
그림 19. SOM Predicted와 Observed의 산포도 그림 18. BP Predicted와 Observed의 산포도
유출량자료만을 이용한 단일변량의 패턴분류가 가능할 것 으로 판단되며, 이는 각 변량의 본질적인 특성을 파악할 수 있을 것으로 기대된다.
참고문헌