2020, 31
(5)
,783–793
일반화 선형혼합모형을 이용한 뇌혈관 질환 예측 모형
기
ᆷ지은
1
·나종화2
12충북대학교 정보통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2020ᄂ ᅧ ᆫ 8ᄋ ᅯ ᆯ 11ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 9ᄋ ᅯ ᆯ 4ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2020ᄂ ᅧ ᆫ 9ᄋ ᅯ ᆯ 10ᄋ ᅵ ᆯ
요 약
ᄂ
ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ ᆯᄒ ᅪ ᆫᄋ ᅳ ᆫ ᄋ ᅮᄅ ᅵᄂ ᅡᄅ ᅡᄋ ᅦᄉ ᅥ ᄋ ᅡ ᆷ ᄃ ᅡᄋ ᅳ ᆷ ᄋ ᅳᄅ ᅩ ᄒ ᅳ ᆫ ᄒ ᅡ ᆫ ᄉ ᅡᄆ ᅡ ᆼᄋ ᅯ ᆫ ᄋ ᅵ ᆫᄋ ᅵᄆ ᅧ, ᄃ ᅡ ᆫᄋ ᅵ ᆯ ᄌ ᅡ ᆼᄀ ᅵᄌ ᅵ ᆯᄒ ᅪ ᆫ ᄋ ᅳᄅ ᅩᄂ ᅳ ᆫ ᄀ ᅡᄌ ᅡ ᆼ ᄂ ᅩ ᇁᄋ ᅳ ᆫ ᄉ ᅡ ᄆ
ᅡ ᆼᄅ ᅲ ᆯᄋ ᅳ ᆯ ᄇ ᅩᄋ ᅵᄂ ᅳ ᆫ ᄌ ᅵ ᆯᄒ ᅪ ᆫ ᄋ ᅵᄃ ᅡ. ᄂ ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ ᆯᄒ ᅪ ᆫᄋ ᅳ ᆫ ᄒ ᅡ ᆫᄇ ᅥ ᆫ ᄇ ᅡ ᆯᄉ ᅢ ᆼᄒ ᅡᄆ ᅧ ᆫ ᄒ ᅮᄋ ᅲᄌ ᅳ ᆼᄋ ᅳ ᆯ ᄂ ᅡ ᆷᄀ ᅵᄂ ᅳ ᆫ ᄀ ᅧ ᆼᄋ ᅮᄀ ᅡ ᄆ ᅡ ᆭᄋ ᅡ ᄎ ᅵᄅ ᅭᄆ ᅡ ᆫ ᄏ ᅳ ᆷ ᄋ ᅨᄇ ᅡ ᆼ ᄋ
ᅵ ᄌ ᅮ ᆼ ᄋ ᅭᄒ ᅡᄃ ᅡ. ᄂ ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ ᆯᄒ ᅪ ᆫ ᄋ ᅴ ᄋ ᅨᄇ ᅡ ᆼᄋ ᅳ ᆯ ᄋ ᅱᄒ ᅡ ᆫ ᄀ ᅵᄎ ᅩ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳᄅ ᅩ, ᄇ ᅩ ᆫ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄀ ᅮ ᆨ ᄂ ᅢᄋ ᅴ ᄉ ᅡ ᆼ ᄒ ᅪ ᆼᄋ ᅦ ᄆ ᅡ ᆽᄂ ᅳ ᆫ ᄂ ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ
ᆯᄒ ᅪ ᆫ ᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄋ ᅨᄎ ᅳ ᆨ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳ ᆯ ᄌ ᅦᄉ ᅵᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄀ ᅥ ᆫᄀ ᅡ ᆼᄇ ᅩᄒ ᅥ ᆷᄀ ᅩ ᆼ ᄃ ᅡ ᆫᄋ ᅳᄅ ᅩᄇ ᅮᄐ ᅥ ᄌ ᅦᄀ ᅩ ᆼᄃ ᅬ ᆫ ᄌ ᅥ ᆫᄀ ᅮ ᆨ 16ᄀ ᅢ ᄉ ᅵᄃ ᅩᄇ ᅧ ᆯ ᄂ ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ
ᆯᄒ ᅪ ᆫ ᄋ ᅴ ᄌ ᅵ ᆫᄅ ᅭᄀ ᅥ ᆫᄉ ᅮᄅ ᅳ ᆯ ᄇ ᅡ ᆫᄋ ᅳ ᆼᄇ ᅧ ᆫᄉ ᅮᄅ ᅩ ᄒ ᅡᄀ ᅩ, ᄋ ᅵᄅ ᅳ ᆯ ᄋ ᅨᄎ ᅳ ᆨ ᄒ ᅡᄀ ᅵ ᄋ ᅱᄒ ᅢ ᄀ ᅵᄉ ᅡ ᆼ, ᄒ ᅪ ᆫᄀ ᅧ ᆼ ᄆ ᅵ ᆾ ᄉ ᅩᄉ ᅧ ᆯᄆ ᅵᄃ ᅵᄋ ᅥ ᄌ ᅥ ᆼᄇ ᅩᄅ ᅳ ᆯ ᄋ ᅨᄎ ᅳ ᆨᄇ ᅧ ᆫᄉ ᅮ ᄅ
ᅩ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄐ ᅳ ᆨ ᄒ ᅵ ᄂ ᅲᄉ ᅳ, ᄇ ᅳ ᆯ ᄅ ᅩᄀ ᅳ, ᄐ ᅳᄋ ᅱ ᆺ ᄃ ᅳ ᆼ ᄋ ᅴ ᄉ ᅩᄉ ᅧ ᆯᄆ ᅵᄃ ᅵᄋ ᅥ ᄌ ᅥ ᆼᄇ ᅩᄂ ᅳ ᆫ ᄀ ᅮ ᆨᄆ ᅵ ᆫᄃ ᅳ ᆯ ᄋ ᅴ ᄉ ᅵ ᆫᄉ ᅩ ᆨ ᄒ ᅡ ᆫ ᄇ ᅡ ᆫᄋ ᅳ ᆼᄋ ᅳ ᆯ ᄉ ᅡ ᆯᄑ ᅧᄇ ᅩ ᆯ ᄉ ᅮ ᄋ ᅵ
ᆻᄂ ᅳ ᆫ ᄌ ᅥ ᆼᄇ ᅩᄅ ᅩ ᄀ ᅪ ᆫᄅ ᅧ ᆫᄃ ᅬ ᆫ ᄋ ᅧ ᆫᄀ ᅪ ᆫ ᄏ ᅵᄋ ᅯᄃ ᅳᄃ ᅳ ᆯ ᄋ ᅴ ᄇ ᅥᄌ ᅳᄅ ᅣ ᆼᄋ ᅳ ᆯ ᄉ ᅮᄌ ᅵ ᆸᄒ ᅡᄋ ᅧ, ᄋ ᅵᄅ ᅳ ᆯ ᄋ ᅨᄎ ᅳ ᆨᄇ ᅧ ᆫᄉ ᅮᄅ ᅩ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄐ ᅩ ᆼ ᄀ ᅨᄌ ᅥ ᆨ ᄋ ᅨᄎ ᅳ ᆨ ᄆ
ᅩᄒ ᅧ ᆼᄋ ᅳᄅ ᅩᄂ ᅳ ᆫ ᄋ ᅵ ᆯᄇ ᅡ ᆫᄒ ᅪ ᄉ ᅥ ᆫᄒ ᅧ ᆼᄆ ᅩᄒ ᅧ ᆼᄀ ᅪ ᄋ ᅵ ᆯᄇ ᅡ ᆫᄒ ᅪ ᄉ ᅥ ᆫᄒ ᅧ ᆼᄒ ᅩ ᆫ ᄒ ᅡ ᆸᄆ ᅩᄒ ᅧ ᆼᄋ ᅵ ᄉ ᅡᄋ ᅭ ᆼ ᄃ ᅬᄋ ᅥ ᆻᄋ ᅳᄆ ᅧ, ᄋ ᅧᄅ ᅥ ᄀ ᅡᄌ ᅵ ᄑ ᅧ ᆼᄀ ᅡ ᄎ ᅥ ᆨᄃ ᅩᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡ ᄋ
ᅧ ᄋ ᅵᄃ ᅳ ᆯ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅴ ᄉ ᅥ ᆼᄂ ᅳ ᆼᄋ ᅳ ᆯ ᄇ ᅵᄀ ᅭᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄀ ᅳ ᄀ ᅧ ᆯᄀ ᅪ ᄀ ᅩᄅ ᅧ ᄃ ᅬ ᆫ ᄆ ᅩᄃ ᅳ ᆫ ᄇ ᅥ ᆷᄌ ᅮᄒ ᅧ ᆼ ᄇ ᅧ ᆫᄉ ᅮᄃ ᅳ ᆯ ᄋ ᅦ ᄃ ᅢᄒ ᅢ ᄋ ᅵ ᆷᄋ ᅴ ᄀ ᅵᄋ ᅮ ᆯ ᄀ ᅵᄅ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄋ ᅵ
ᆯᄇ ᅡ ᆫᄒ ᅪ ᄉ ᅥ ᆫᄒ ᅧ ᆼᄒ ᅩ ᆫ ᄒ ᅡ ᆸᄆ ᅩᄒ ᅧ ᆼᄋ ᅵ ᄀ ᅡᄌ ᅡ ᆼ ᄌ ᅥ ᆨᄒ ᅡ ᆸᄒ ᅡ ᆫ ᄆ ᅩᄒ ᅧ ᆼᄋ ᅳᄅ ᅩ ᄂ ᅡᄐ ᅡᄂ ᅡ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄂ ᅬᄒ ᅧ ᆯᄀ ᅪ ᆫ ᄌ ᅵ ᆯᄒ ᅪ ᆫ , ᄋ ᅵ ᆯᄇ ᅡ ᆫᄒ ᅪ ᄉ ᅥ ᆫᄒ ᅧ ᆼᄆ ᅩᄒ ᅧ ᆼ, ᄋ ᅵ ᆯᄇ ᅡ ᆫᄒ ᅪ ᄉ ᅥ ᆫᄒ ᅧ ᆼᄒ ᅩ ᆫ ᄒ ᅡ ᆸᄆ ᅩᄒ ᅧ ᆼ.
1. 머리말 ᄀ
ᅮ
ᆨ내·외 뇌혈관 질환의 진료건수와 기상, 환경 변수의 관계를 분석한 연구들을 살펴보면, Chan 등 (2006)은대만에서 뇌혈관질환으로 인한 긴급 입원건수가 당일 오존과 이틀전 일산화탄소와 연관이 있 ᄃ
ᅡ고 밝혔다. 또한, Park과 Lee (2009)는서울시 월별 뇌혈관질환 사망자 수가 오존, 평균상대습도에 ᄋ
ᅲ의한 영향을받는것을 음이항 회귀모형을사용하여 분석하였으며, Kim 등 (2015)은큰 일교차가 뇌 혀
ᆯ관질환으로 인한 사망률에 영향을주는것을밝혀냈다. 한편 온라인에서 정보를 공유하기 위해 소셜 ᄂ
ᅦ트워크의 사용량이 증가하면서 소셜 버즈량은 다방면의 키워드에 대한 국민의 즉각적인 반응을살펴 ᄇ
ᅩᆯ수 있는 중요한 지표로 사용되고 있다. 뇌혈관질환의 진료건수를예측하기 위하여 트위터, 뉴스, 블 ᄅ
ᅩ그와 같은 소셜 정보를사용하면 보다 설명력을 높일 수 있을것이라 기대된다. 주요 질환의 예측에 ᄉ
ᅩ셜미디어 정보를활용한 연구로는 Hwang과 Na (2015), Lyuk 등 (2018)이 있다.
ᄇ
ᅩᆫ 논문에서는 뇌혈관질환의 진료건수에 대한 예측모형을구축하였다. 예측변수로는기상, 환경 변 ᄉ
ᅮ 및 소셜미디어 정보가 사용되었다. 2절에서는 분석에 이용한 자료소개와 기초분석 결과를제시하였 ᄀ
ᅩ, 3절에서는 분석 모형과 모형 구축결과, 평가와 비교를제시하였으며 4절에서는연구의 결론을기술 ᄒ
ᅡ였다.
1
(28644) ᄎ ᅮ ᆼᄇ ᅮ ᆨ ᄎ ᅥ ᆼᄌ ᅮᄉ ᅵ ᄉ ᅥᄋ ᅯ ᆫ ᄀ ᅮ ᄎ ᅮ ᆼ ᄃ ᅢᄅ ᅩ 1, ᄎ ᅮ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄉ ᅥ ᆨᄉ ᅡ ᄌ ᅩ ᆯᄋ ᅥ ᆸ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (28644) ᄎ ᅮ ᆼᄇ ᅮ ᆨ ᄎ ᅥ ᆼᄌ ᅮᄉ ᅵ ᄉ ᅥᄋ ᅯ ᆫ ᄀ ᅮ ᄎ ᅮ ᆼ ᄃ ᅢᄅ ᅩ 1, ᄎ ᅮ ᆼᄇ ᅮ ᆨ ᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄌ ᅥ ᆼᄇ ᅩᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
2. 자료소개와 기초분석
2.1. 분석자료 소개 ᄇ
ᅮᆫ석에는 국민건강보험공단이 제공하는 국내 16개 시도별 뇌혈관 질환의 일일 진료건수가 반응변수 ᄅ
ᅩ 사용되었다. 예측변수로는기상청에서 제공하는기상정보 (기온,최고기온,최저기온, 습도, 최저습 ᄃ
ᅩ, 강수량, 풍속)와환경부에서 제공하는환경정보 (아황산가스, 미세먼지, 초미세먼지, 이산화질소, 오 ᄌ
ᅩᆫ, 일산화탄소)가 사용되었다. 소셜 미디어 정보로 사용된뇌혈관질환과 연관된키워드들의 버즈량의 ᄉ
ᅮ집은 ㈜다음소프트에서 제공받았다. 소셜미디어 정보로는뇌질환과 관련된키워드들의 일별 트위터, 브
ᆯ로그, 뉴스 버즈량이 사용되었다. 분석에 사용된 자료는 약 5년 간 (2013년 1월 8일∼2017년 12월 31일)에 걸쳐 전국의 16개 시도에서 수집된일별 자료이다.
2.2. 기초분석 보
ᆫ 논문에서는전국 16개 시도별로 뇌혈관질환의 진료건수에 대한 예측모형을구축하였다. 이 절에 ᄉ
ᅥ는 주요 예측변수들에 대한 기초분석 결과를제시하였다 (서울시의 경우를제시하였으며, 타 지역의 겨
ᆯ과도 유사한 패턴을보임). 또한 고려된 많은 변수 가운데 분석 결과 유의미한 예측변수를 중심으로 겨
ᆯ과를 제시하였다. Figure 2.1은 반응변수에 해당하는서울시의 뇌혈관 질환의 진료건수 시도표이다.
ᄋ
ᅵ 그림에서 해당 질환의 진료건수는매달 1일 급증하며 1일이 아닌 날에는상대적으로 매우 작은값을 ᄀ
ᅡ짐을알 수 있다. 따라서 1일을제외한 진료건수의 패턴을 좀더 자세히 파악하기 위해 1일을제외한 ᄀ
ᅳ림을 Figure 2.2에 제시하였다. Figure 2.2는서울시의 1일 제외 자료의 진료건수로 서서히 증가하고 이
ᆻ는양상을보임을알 수 있다. 이에 따라 1일 여부에 대한 예측변수를생성하여 모형 적합에 이용하도 ᄅ
ᅩ
ᆨ한다. 또한 Figure 2.3은예측변수로 사용할 의료급여 청구건수의 시도표로 진료건수 시도표와 유사 ᄒ
ᅡ게 서서히 증가하는경향을보이고 있음을알 수 있다.
Figure 2.1 Time series plot of cerebrovascular diseases (Seoul)
Figure 2.2 Time series plot of cerebrovascular diseases (Seoul), excluding the first day of the month
Figure 2.3 Time series plot of the number of inquired medical care (Seoul)
Figure 2.4는주요 예측변수들의 시도표를나타낸 것이다. 그림 (a)와 (b)는기상변수인 최저기온,최 ᄌ
ᅥ습도를, 그림 (c), (d)와 (e)는 환경변수인 오존, 일산화탄소, 미세먼지를나타낸다. 그림 (f)는뇌혈 과
ᆫ질환과 연관된뉴스 버즈량으로 전국에서 동일한 값이 예측모형에 사용되었다.
(a) lowest temperature (unit :
◦C)) (b) lowest humidity (unit : %)
(c) O3 (unit : ppm) (d) CO2 (unit : µg/m
3)
(e) PM10 (unit : µg/m
3) (f) SNS(news) buzz (unit : count)
Figure 2.4 Time series plot of some predictive variables
3. 모형적합 및 모형비교
3.1. 분석모형
3.1.1. 일반화 선형모형
Nelder와 Wedderburn (1972)이 제안한 일반화 선형모형 (Generalized Linear Model, 이하 GLM)은 ᄉ
ᅥᆫ형모형의 일반화된모형으로 정규분포 뿐아니라 비정규분포인 이항 자료, 가산자료나 범주형 반응변 ᄉ
ᅮ에 대한 적합모형으로 잘 알려져 있다. GLM은설명변수의관측값이 주어졌을때 반응변수의 분포를 ᄂ
ᅡ타내는 랜덤성분, 설명변수의 선형결합을나타낸 체계적 성분그리고 랜덤성분의 기댓값과 체계적 성 부
ᆫ을연결하는연결함수로 구성되며 다음과 같이 표현된다.
η =g(µ) = Xβ, µ = E(y).
(3.1)
시
ᆨ (3.1)의 µ는반응변수의 기댓값이며, β는모수벡터로 최대가능도방법을사용하여 추정될수 있다.
ᄒ
ᅡ나의관측치에 대한 로그가능도는다음과 같다.
log L(θi, ϕ; yi) = wi[yiθi− b(θi)
ϕ ] + c(yi, ϕ). (3.2) 시
ᆨ (3.2)에서 wi는각 관측치의 가중치이다. 전체 관측값에 대한 로그가능도는 Σilog L(θi, ϕ; yi)이 ᄆ
ᅧ, 이를 최대화하면 최대가능도추정값을 찾을 수 있다. 다만 정규분포뿐 아니라 모든 분포에 적용될 ᄉ
ᅮ 있도록 하려면 수치해석적인 최적화 방법을사용해야 한다. 반복재가중최소제곱추정법 (Iteratively Reweighted Least Squares Estimator)을 사용하면 반복계산을이용해 최대가능도추정량에 수렴하는 β를구할 수 있다. 일반화 선형모형에 대해서는 Agresti (2003)을참고하기 바란다.
3.1.2. 일반화 선형모형 ᄀ
ᅳ룹내관측치가 반복 측정되어 그룹내에 상관관계가 존재하는자료, 경시적 자료 그리고 공간 요소 르
ᆯ포함하는 자료에 대해 독립성을가정하는 분석은적절하지 않다. 개체 내 상관을고려하지 않는 분 ᄉ
ᅥ
ᆨ을수행하면 모수 추정치의 표준오차가 과소 추정되는오류가 발생할 수 있다. 이때 고정효과뿐만 아 ᄂ
ᅵ라 임의효과를 포함하는 선형혼합모형을 사용하여 자료를 설명할 수 있다. 고정효과는 실험이 이뤄 ᄌ
ᅵᆫ 수준에 대해서만 추론이 적용되는경우에 사용하며, 임의효과는 실험이 이뤄진 수준들이 모든수준의 ᄆ
ᅩ집단으로부터의 표본이라고 여겨지는경우에 사용한다. 임의효과는확률분포를가지며 분산요소만을 ᄆ
ᅩ수로 갖기 때문에 모수를절약할 수 있다는장점이 있다.
이
ᆯ반화 선형혼합모형 (Generalized Linear Mixed Model, 이하 GLMM)은 일반화 선형모형과 선형 호
ᆫ합모형이 결합된모형으로 오차에 상관관계가 있거나 과대산포를갖는경우, 여러 그룹으로부터 시간 ᄋ
ᅦ 따른관측치를모형화하는경우 등다양한 자료에 적용될수 있다. 모형은다음과 같이 표현한다.
g(µ) = Xβ + Zb, y|b ∼ h(y; ϕ).
(3.3)
시
ᆨ (3.3)에서 g(µ)는 연결함수로 반응변수의 조건부 평균을 설명변수의 선형결합과 연결한다. y는 ᄇ
ᅡᆫ응변수벡터로 임의효과가 주어졌을 때 기댓값은 µ이며 모수 ϕ를 갖는지수족을 따른다고 가정한다.
X는고정효과에 영향을받는 n × p의 계획행렬이고, β는 p × 1의 고정효과 벡터이다. Z는 임의 효과
ᄋ
ᅦ 영향을받는 n × q행렬이고, b는 q × 1의 임의효과 벡터로 b ∼ N(0, Σ(θ))이다. 여기서 θ는 임의효과 ᄋ
ᅴ 분산요소로 b의 분산-공분산 행렬을정의하는 벡터이다. 위 모형에서 추정될 모수들은고정효과 벡 ᄐ
ᅥ인 β와 임의효과의 분산요소인 θ이며 임의효과 b는예측되어야 한다.
이
ᆯ반화 선형혼합모형에서 추정 역시 최대가능도방법에 기반하지만, 모수를 추정하기 위한 적분 과 저
ᆼ에서 가능도함수가 닫힌 형태를 제공하지 않아 계산에 어려움이 존재한다. 이를 해결하기 위해서 이
ᆷ의효과가 주어졌을 때 반응변수의 분산이 평균의 함수라고 가정하는 벌점화된 준가능도함수 (Pe- nalized Quasi-Likelihood, 이하 PQL)를 이용하는 방법, 로그가능도의 적분을 근사시키는 라플라스 (Laplace)나 가우스-헤르미트 구적 (Gauss-Hermite Quadrature, 이하 GHQ), 적응 가우스-헤르미트 ᄀ
ᅮ적 (Adaptive GHQ) 방법 등을사용한다. 정확한 모수 추정을위해 베이지안 접근을이용하는마코 ᄑ
ᅳ 체인 몬테칼로 (MCMC) 방법 등을사용해 모형 적합을 수행하기도 하지만 임의효과의 사전분포를 서
ᆯ정하는데 어려움이 있고 시간이 오래 걸린다는단점이 있다. 일반화 선형혼합모형에서의 모수 추정과 화
ᆯ용에 대해서는 Breslow와 Clayton (1993), Bolker 등 (2009), Faraway (2006), Gbur 등 (2013)과 Schall (1991)을참고하기 바란다.
3.2. 모형적합 ᄂ
ᅬ혈관질환의 진료건수에 대한 예측을 위해 일반화 선형모형과 일반화 선형혼합모형을고려하였다.
이
ᆯ반화 선형모형으로는 2가지 (포아송회귀와 음이항 회귀) 모형을고려하였으며, 일반화 선형혼합모형 ᄋ
ᅳ로는 특정 변수에 대해 임의 절편과 임의 기울기를 고려한 5가지 형태를고려하였다. 기초분석을 통 ᄒ
ᅢ 전 모형에서 공통으로 고려된 예측 변수 가운데 의료급여 청구건수는 1일 전, 7일 전, 1일 전부터 7일 전까지의 평균정보가, 환경 변수는당일의 정보가 사용되기 어렵기 때문에 1일 전부터 5일 전까지 ᄋ
ᅴ 정보가, 소셜미디어 (뉴스, 블로그, 트윗) 정보는 1일 전의 버즈량이 입력 예측변수로 사용되었다.
ᄄ
ᅩ한 추가적으로 지역, 휴일을고려한 (휴일 당일, 휴일 다음날) 요일, 매월 1일인지의 여부 (one)가 입 ᄅ
ᅧᆨ 예측변수로 사용되었으며, 추세를모형에 반영하기 위해관측시작일인 2013년 1월 8일을 1로 하여 ᄆ
ᅢ일 1씩 증가하는시간 (time) 변수를생성해 모형에 추가하였다.
보
ᆫ 논문에서 고려한 모형은 총 7가지이다. 모형 I, II는 일반화 선형모형을,모형 III ∼ V II는포아 ᄉ
ᅩ
ᆼ 분포를가정한 일반화 선형혼합모형으로 각 모형에 대한 설명은다음과 같다.
ᄆ
ᅩ형 I : 포아송회귀모형 ᄆ
ᅩ형 II : 음이항 회귀모형 ᄆ
ᅩ형 III : 지역, 요일, 1일 여부에 임의 절편을적용한 모형 ᄆ
ᅩ형 IV : 모형 III + 1일 전, 7일 전 의료급여 청구건수에 지역에 따른 임의 기울기 적용 ᄆ
ᅩ형 V : 모형 III + 1일 전, 7일 전 의료급여 청구건수에 요일에 따른 임의 기울기 적용 ᄆ
ᅩ형 V I : 모형 III + 1일 전, 7일 전 의료급여 청구건수에 1일 여부에 따른 임의 기울기 적용 ᄆ
ᅩ형 V II : 모형 III + 1일 전, 7일 전 의료급여 청구건수에 지역, 요일, 1일 여부에 따른 임의 기울 ᄀ
ᅵ 적용
Table3.1과 Table3.2는 각각 일반화 선형모형 (모형 I과 모형 II)과 일반화 선형혼합모형 (모형 III ∼모형 V II)을 적합한 결과이다. 각 표에서 선택된 공통의 고정효과 변수들은 1일 전 의료급여 처
ᆼ구건수 (CNT 1), 7일 전 의료급여 청구건수 (CNT 7), 최저기온 (TEMP L),최저습도 (HM L), 1일 ᄌ
ᅥᆫ 오존 (O3 1), 1일 전 일산화탄소 (CO 1), 5일 전 미세먼지 (PM10 5), 1일 전 뉴스건수 (N 1)이다.
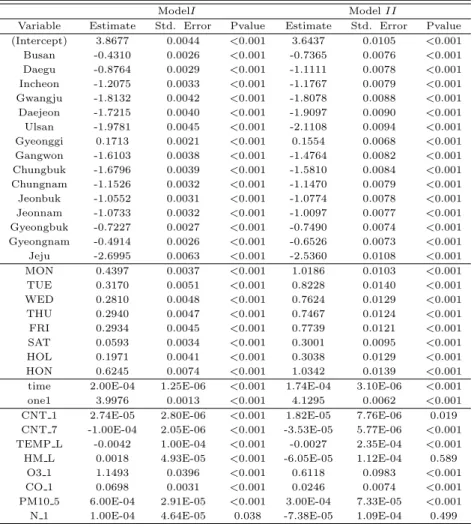
Table 3.1 Estimation of the fixed effect of the generalized linear model
ModelI Model II
Variable Estimate Std. Error Pvalue Estimate Std. Error Pvalue (Intercept) 3.8677 0.0044 <0.001 3.6437 0.0105 <0.001 Busan -0.4310 0.0026 <0.001 -0.7365 0.0076 <0.001 Daegu -0.8764 0.0029 <0.001 -1.1111 0.0078 <0.001 Incheon -1.2075 0.0033 <0.001 -1.1767 0.0079 <0.001 Gwangju -1.8132 0.0042 <0.001 -1.8078 0.0088 <0.001 Daejeon -1.7215 0.0040 <0.001 -1.9097 0.0090 <0.001 Ulsan -1.9781 0.0045 <0.001 -2.1108 0.0094 <0.001 Gyeonggi 0.1713 0.0021 <0.001 0.1554 0.0068 <0.001 Gangwon -1.6103 0.0038 <0.001 -1.4764 0.0082 <0.001 Chungbuk -1.6796 0.0039 <0.001 -1.5810 0.0084 <0.001 Chungnam -1.1526 0.0032 <0.001 -1.1470 0.0079 <0.001 Jeonbuk -1.0552 0.0031 <0.001 -1.0774 0.0078 <0.001 Jeonnam -1.0733 0.0032 <0.001 -1.0097 0.0077 <0.001 Gyeongbuk -0.7227 0.0027 <0.001 -0.7490 0.0074 <0.001 Gyeongnam -0.4914 0.0026 <0.001 -0.6526 0.0073 <0.001 Jeju -2.6995 0.0063 <0.001 -2.5360 0.0108 <0.001
MON 0.4397 0.0037 <0.001 1.0186 0.0103 <0.001
TUE 0.3170 0.0051 <0.001 0.8228 0.0140 <0.001
WED 0.2810 0.0048 <0.001 0.7624 0.0129 <0.001
THU 0.2940 0.0047 <0.001 0.7467 0.0124 <0.001
FRI 0.2934 0.0045 <0.001 0.7739 0.0121 <0.001
SAT 0.0593 0.0034 <0.001 0.3001 0.0095 <0.001
HOL 0.1971 0.0041 <0.001 0.3038 0.0129 <0.001
HON 0.6245 0.0074 <0.001 1.0342 0.0139 <0.001
time 2.00E-04 1.25E-06 <0.001 1.74E-04 3.10E-06 <0.001
one1 3.9976 0.0013 <0.001 4.1295 0.0062 <0.001
CNT 1 2.74E-05 2.80E-06 <0.001 1.82E-05 7.76E-06 0.019 CNT 7 -1.00E-04 2.05E-06 <0.001 -3.53E-05 5.77E-06 <0.001 TEMP L -0.0042 1.00E-04 <0.001 -0.0027 2.35E-04 <0.001 HM L 0.0018 4.93E-05 <0.001 -6.05E-05 1.12E-04 0.589
O3 1 1.1493 0.0396 <0.001 0.6118 0.0983 <0.001
CO 1 0.0698 0.0031 <0.001 0.0246 0.0074 <0.001
PM10 5 6.00E-04 2.91E-05 <0.001 3.00E-04 7.33E-05 <0.001 N 1 1.00E-04 4.64E-05 0.038 -7.38E-05 1.09E-04 0.499
Table3.1은모형 I과 모형 II의 고정효과에 대한 추정 결과이다. 이들모형은 진료건수가 서로 독립 ᄋ
ᅵ라는가정을전제로 한다. 모형 I (포아송회귀모형)에서는모든변수가 유의하였고, 모형 I (음이항 ᄒ
ᅬ귀모형)에서는 최저습도와 1일 전 뉴스건수 변수를 제외한 모든변수가 유의한 변수로 나타났다. 여 ᄀ
ᅵ에서 지역 효과와 요일 효과는각각 서울과 일요일이 기준범주로 적용되었다.
Table 3.2는 일반화 선형혼합모형에서 고정효과의 추정 결과로 모형 V 에서는 1일 전 뉴스건수, 모형 V II에서는 5일 전 미세먼지와 1일 전 뉴스건수를제외한 모든변수가 유의하였다. Table 3.2에서 제시 ᄃ
ᅬ지 않은나머지 변수들 (지역, 요일, 공휴일과 공휴일 다음날 및 1일 여부)은모두 임의효과로 반영되 ᄋ
ᅥᆻ으며, 이에 대한 공분산 행렬의 추정 결과는생략하였다.
Figure 3.1은각 모형의 적합 결과를나타낸 시도표이다 (편의상 서울시의 경우를제시하였으나, 다른 ᄉ
ᅵ도의 결과도 패턴이 유사함). 관측값과 적합값의 월별 평균을 집계하여 각각 실선과 점선으로 나타냈 ᄃ
ᅡ. 과산포가 고려된 음이항 분포를 가정한 모형 II는예측력이 가장 떨어지며, 모든범주형 변수마다 이
ᆷ의 기울기 효과를추가한 모형 V II이 가장 예측력이 우수한 것으로 나타났다.
Table 3.2 Estimation of the fixed effect of the generalized linear mixed model Model III Model IV Model V Model V I Model V II
(Intercept) 5.00*** 5.05*** 4.93*** 6.32*** 6.02***
(1.03) (0.97) (1.10) (1.34) (2.49)
CNT 1 2.73e-05***
· · · ·
(2.80e-06) CNT 7 -5.18e-05***
· · · ·
(2.05e-06)
TEMP L -4.23e-03*** -4.29e-03*** -3.48e-03*** -3.63e-03*** -2.94d-03***
(1.00e-04) (1.00e-04) (1.02e-04) (1.01e-04) (7.97e-05) HM L 1.80e-03*** 1.83e-03*** 1.26e-03*** 7.39e-04*** 2.16e-04***
(4.93e-05) (4.93e-05) (5.04e-05) (4.97e-05) (4.72e-05)
O3 1 1.15*** 1.14*** 1.14*** 1.24*** 1.00***
(3.95e-02) (3.97e-02) (4.04e-02) (3.98e-02) (2.54e-03) CO 1 6.97e-02*** 6.84e-02*** 4.85e-02*** 3.85e-02*** 3.54e-02***
(3.08e-03) (3.09e-03) (3.17e-03) (3.10e-03) (2.01e-03) PM10 5 5.85e-04*** 5.71e-04*** 5.76e-04*** -8.58e-05** 1.60e-05
(2.91e-05) (2.91e-05) (3.01e-05) (2.93e-05) (2.95e-05)
N 1 9.66e-05* 9.87e-05* -3.43e-05 1.15e-04* -9.21e-05
(4.64e-05) (4.64e-05) (4.83e-05) (4.66e-05) (4.83e-05) Time 1.91e-04*** 1.92e-04*** 1.87e-04*** 1.85e-04*** 1.93e-04***
(1.24e-06) (1.24e-06) (1.37e-06) (1.26e-06) (1.39e-06) (() indicates standard error, and *** indicates p-value is less than 0.001.)
Figure 3.1 Prediction of the frequency of monthly treatments for cerebrovascular diseases (Seoul)
3.3. 모형비교 ᄀ
ᅵ상, 환경, 소셜 미디어 정보를활용하여 뇌혈관질환의 진료건수를예측하기 위해 일반화 선형모형 ᄀ
ᅪ 일반화 선형혼합모형을적합하였다. 이 절에서는적합모형에 대한 평가와 비교를수행한다. 모형 평 ᄀ
ᅡ를위한 측도로는 RMSE, AIC, BIC,로그가능도가 사용되었다.
Table 3.3은뇌혈관질환진료건수 예측모형을평가한 결과이다. 먼저 GLM 모형 간의 비교 결과, 모 혀
ᆼ II가 모형 I에 비해 AIC, BIC 측도는더 우수하나 RMSE 측도가 매우큰값을가지므로 모형 I이 ᄃ
ᅡ소 우수한 모형으로 판단된다 (Figure 3.1 참고). 다음으로 모형 I (GLM)과 모형 III (GLMM)을 ᄇ
ᅵ교하면 모형 III의 AIC, BIC가 소폭 증가하였지만 모수의 수가 크게 줄어들었음을확인할 수 있다.
ᄃ
ᅮ 모형은 모수 개수 외에 큰차이를 보이지는않는다. 모형 IV , V , V I은각각 지역, 요일, 1일 여부 벼
ᆯ로 임의 기울기를허용한 모형으로 점차 RMSE, AIC, BIC의 값이 감소하며 로그 가능도의 값은 증 ᄀ
ᅡ하고 있어 성능의 개선이 있음을알 수 있다. 매달 1일에 진료건수가 급증하기 때문에 1일 여부에 따 ᄅ
ᅡ 임의 기울기를허용할 때 모형 개선 효과가 가장 크게 나타나는것으로 보인다. 마지막으로 지역, 요 이
ᆯ, 1일 여부에 따라 임의 기울기를 동시에 허용한 모형 V II이 일반화 선형혼합모형들 중에서 RMSE, AIC, BIC가 모두 가장 작았다. 마찬가지로 로그가능도를사용하여 비교했을때도 모형 V II가 가장큰 ᄀ
ᅡ
ᆹ을보여 최적 모형이라고 판단할 수 있다. 따라서, 일반화 선형혼합모형을 통해 임의 절편 또는 임의 ᄀ
ᅵ울기를 적절하게 적용하면 모수를 절반 이상 줄이면서 (GLM 모형에 비해) 로그가능도를최대화할 ᄉ
ᅮ 있어 모든변수의 효과를고정효과로 사용한 포아송회귀모형에 비해 뚜렷한 개선을보이는것을확 ᄋ
ᅵᆫ할 수 있다.
Table 3.3 Evaluation and Comparison of fitted models for the cerebrovascular disease
RMSE AIC BIC logLik df
GLM Model I 52.458 276697.2 276978.6 -138314.6 34 Model II 155.618 200555.4 200845.2 -100242.7 35
GLMM
Model III 52.455 276951.7 277059.3 -138462.8 13 Model IV 52.128 276619.3 276727.0 -138296.7 13 Model V 50.841 270656.8 270764.4 -135315.4 13 Model V I 39.808 242325.6 242433.2 -121149.8 13 Model V II 37.069 237326.8 237467.5 -118646.4 17
Figure 3.2는 적합모형별 잔차에 대한 상자그림이다. 1일 제외 자료에서는모든모형의 잔차가 유사 ᄒ
ᅡᆫ 범위를 가지며 모형에 따라 사실상큰차이를보이지 않는다. 하지만 1일 자료에서는 모형 II를 제 ᄋ
ᅬ하고 모형에 변화를 줄수록 잔차의 범위가 축소되는 것을 보여준다. 모형 II는 잔차의 분산이 매우 ᄏ
ᅳ며 임의 기울기를추가한 모형 V II에서는잔차의 범위가 가장 작아 고려된7개의 모형 중가장 우수 ᄒ
ᅡᆫ 것으로 나타났다.
(a) residual of data excluding the day 1 (b) residual of the day 1 Figure 3.2 Box plot of residuals by model according to day 1
4. 결론 보
ᆫ 논문에서는기상·환경 자료와 함께 뇌혈관질환과관련한 소셜 버즈량을예측변수로 하여 뇌혈관질 화
ᆫ진료건수를예측하는회귀모형을제시하였다. 일반적으로 정형 데이터인 기상·환경관측값만을이용 ᄒ
ᅡ여 모형을구축해왔던 것과는달리 본연구에서는 즉각적이고 신속하게 질병의 영향력을나타내는소 셔
ᆯ 버즈량 정보를모형에 반영하였다. 소셜 버즈량은 질병의 증상과 원인, 질병이 발생하는시기, 발병 ᄇ
ᅮ위나 치료방법 등 질병과 연관된단어가 언급된트위터, 블로그, 뉴스의 문서 개수로 집계한다. 소셜 ᄆ
ᅵ디어의 실시간성을적극적으로 이용한다면 앞으로의 연구에서도 질병의 위험성을나타내는지표로활 ᄋ
ᅭ
ᆼ될수 있을것이다. 질환의 위험도를나타내는지표 개발과 예측변수의 영향력에 대해서는추가적인 ᄋ
ᅧᆫ구가 필요하다.
ᄒ
ᅬ귀모형으로 포아송회귀모형, 음이항 회귀모형과 일반화 선형혼합모형을고려하였으며 일반화 선형 호
ᆫ합모형의 경우 지역, 요일, 1일 여부에 대해 임의 절편을, 1일 전 7일 전 의료급여 청구건수에 대해 임 ᄋ
ᅴ 기울기를이용한 적합을 수행하였다. 적합된 회귀모형의 평가를위한 측도로는 RMSE, AIC, BIC, ᄅ
ᅩ그가능도가 사용되었다. 그 결과, 음이항 회귀모형보다 포아송 회귀모형이, 포아송 회귀모형보다 임 ᄋ
ᅴ 효과를적용한 일반화 선형혼합모형이 더 예측력이 좋았다. 특히 모든범주형 변수에 대해 임의 기울 ᄀ
ᅵ를반영한 일반화 선형혼합모형이 가장 우수하게 나타났다.
References
Agresti, A. (2003). An introduction to categorical data analysis, 2nd Ed., John Wiley & Sons.
Bolker, B. M., Brooks, M. E., Clark, C. J., Geange, S. W., Poulsen, J. R., Stevens, M. H. H., and White, J. S. S. (2009). Generalized linear mixed models: a practical guide for ecology and evolution. Trends in Ecology & Evolution, 24, 127-135.
Breslow, N. E. and Clayton, D. G. (1993). Approximate inference in generalized linear mixed models.
Journal of the American Statistical Association, 88, 9-25.
Chan, C. C., Chuang, K. J., Chien, L. C., Chen, W. J., and Chang, W. T. (2006). Urban air pollution and emergency admissions for cerebrovascular diseases in Taipei, Taiwan. European Heart Journal , 27, 1238-1244.
Faraway, J. J. (2006). Extending the linear model with R: Generalized linear, mixed effects and nonpara- metric regression models, Chapman and Hall/CRC.
Gbur, E. E., Stroup, W. W., McCarter, K. S., Durham, S., Young, L. J., Christman, M., West, M.
and Kramer, M. (2013). Analysis of generalized linear mixed models in the agricultural and natural resources sciences. American Society of Agronomy, Soil Science Society of America and Crop Science Society of America.
Hwang, E. and Na, J. (2015). Influenza prediction models by using meteorological and social media infor- mations, Journal of theKorean Data & Information Science Society, 26, 1087-1095.
Kim. Y., Kim. C., Noh. M. and Lee. W. (2015). A study on association between local climate change and disease deaths caused by ischaemic heart and cerebrovascular disease. Journal of theKorean Data
& Information Science Society, 17, 1911-1918.
Lyuk, H., Hwang, E. and Na, J. (2018). Prediction of food poisoning occurance by using typical and social media informations, Journal of theKorean Data & Information Science Society, 29, 1491-1503.
Nelder J. A. and Wedderburn, R. W. (1972). Generalized linear models. Journal of the Royal Statistical Society: Series A (General), 135, 370-384.
Park. H. and Lee. J. (2009). Effects of environmental factors on monthly cerebrovascular mortality in seoul. Journal of theKorean Data & Information Science Society, 11, 687-698.
Schall R. (1991). Estimation in generalized linear models with random effects. Biometrika, 78, 719-727.
2020, 31
(5)
,783–793
Cerebrovascular disease prediction model using generalized linear mixed model
Jieun Kim
1
· Jong Hwa Na2
12Department of Information and Statistics, Chungbuk National University
Received 11 August 2020, revised 4 September 2020, accepted 10 September 2020
Abstract
Cerebrovascular disease is the second most common cause of death after cancer in Korea, and is a disease with the highest mortality rate as a single long-term disease.
Cerebrovascular disease often leaves sequelae once it occurs, so prevention is as impor- tant as treatment. As a basic analysis for the prevention of cerebrovascular disease, this paper presents a statistical prediction model for cerebrovascular disease appropriate to the domestic situation. The number of treatments for cerebrovascular diseases in 16 cities and provinces nationwide provided by the Health Insurance Corporation was used as a response variable, and weather, environment and social media information were used as predictive variables to predict the number of cases of cerebrovascular disease.
In particular, social media information such as news, blogs, tweets, etc., is information that allows the quick reaction of the people, and the amount of buzz of related keywords was collected and used as a predictor. Generalized linear model and generalized linear mixed model were used as statistical prediction models, and the performance of these models was compared using various evaluation measures. As a result, it was found that the generalized linear mixed model that applied random slope to all considered categorical variables was the most suitable model.
Keywords: Cerebrovascular disease, generalized linear model, generalized linear mixed model.
1
Master’s graduates, Department of Information & Statistics, Chungbuk National University, Chungbuk 28644, Korea.
2