https://doi.org/10.9717/kmms.2021.24.8.1000
Breast Tumor Cell Nuclei Segmentation in Histopathology Images using EfficientUnet++ and Multi-organ
Transfer Learning
Tuan Le Dinh
†, Seong-Geun Kwon
††, Suk-Hwan Lee
†††, Ki-Ryong Kwon
††††ABSTRACT
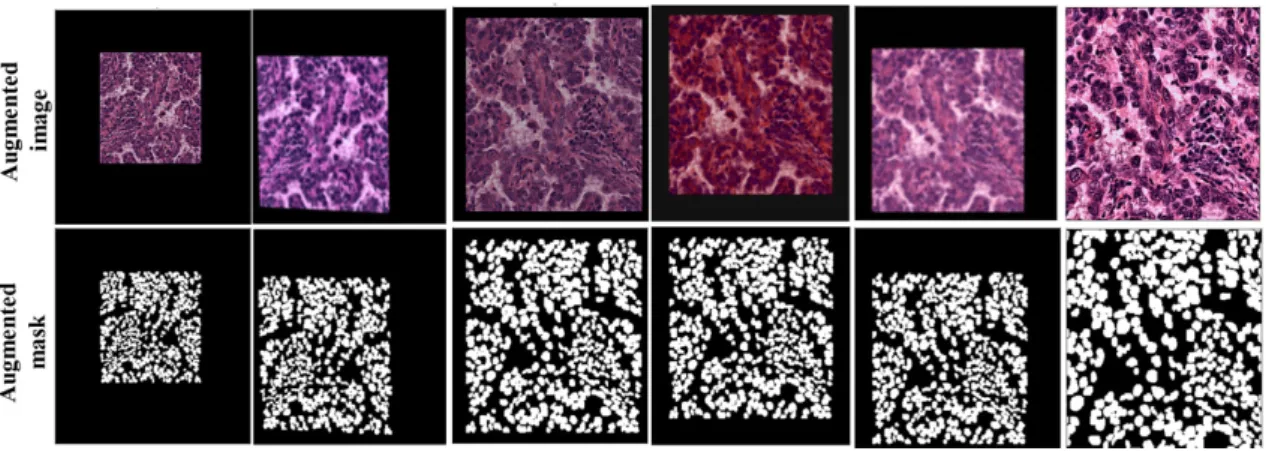
In recent years, using Deep Learning methods to apply for medical and biomedical image analysis has seen many advancements. In clinical, using Deep Learning-based approaches for cancer image analysis is one of the key applications for cancer detection and treatment. However, the scarcity and shortage of labeling images make the task of cancer detection and analysis difficult to reach high accuracy.
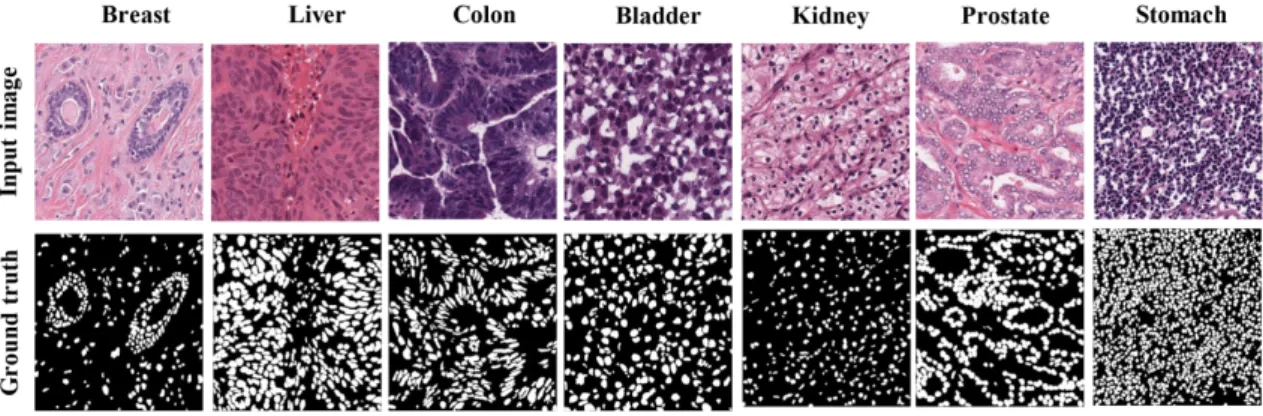
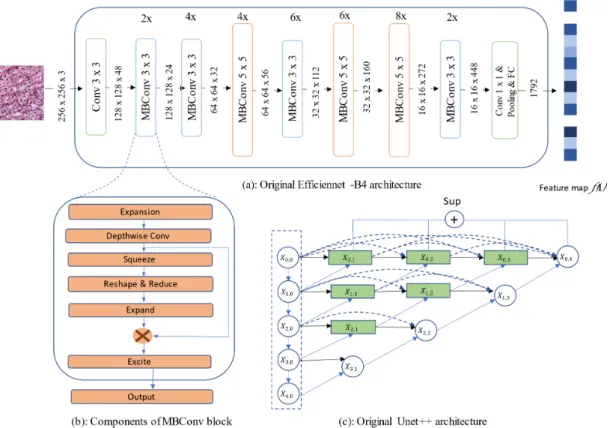
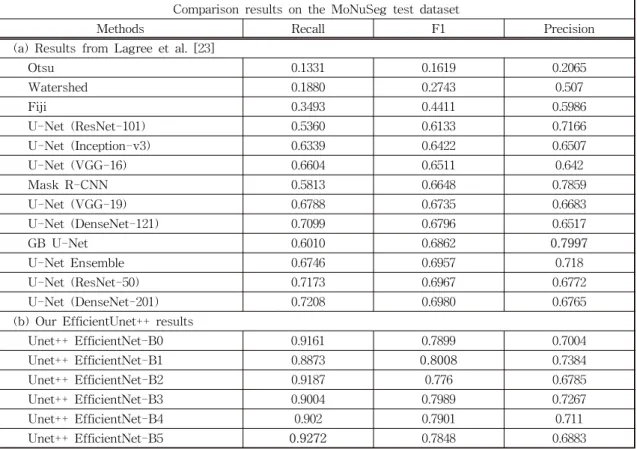
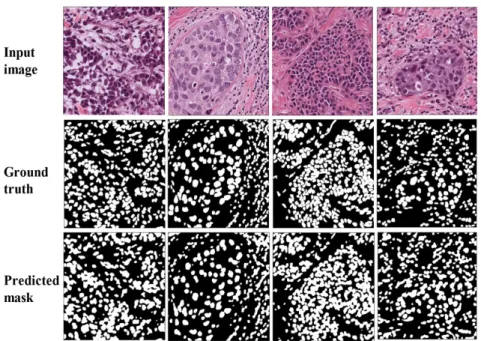
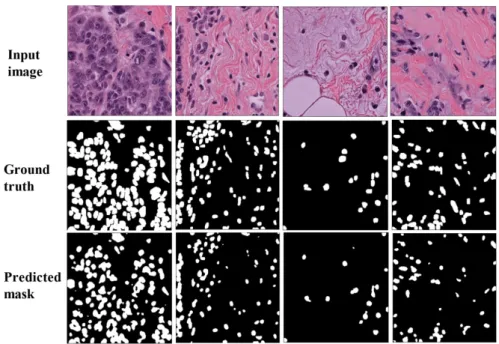
In 2015, the Unet model was introduced and gained much attention from researchers in the field. The success of Unet model is the ability to produce high accuracy with very few input images. Since the development of Unet, there are many variants and modifications of Unet related architecture. This paper proposes a new approach of using Unet++ with pretrained EfficientNet as backbone architecture for breast tumor cell nuclei segmentation and uses the multi-organ transfer learning approach to segment nuclei of breast tumor cells. We attempt to experiment and evaluate the performance of the network on the MonuSeg training dataset and Triple Negative Breast Cancer (TNBC) testing dataset, both are Hematoxylin and Eosin (H & E)-stained images. The results have shown that EfficientUnet++ architecture and the multi-organ transfer learning approach had outperformed other techniques and produced notable accuracy for breast tumor cell nuclei segmentation.
Key words: Deep Learning, Image Segmentation, Nuclei Segmentation, Unet, Unet++, EfficientNet, Hematoxylin and Eosin (H & E), Breast Cancer
※ Corresponding Author : Ki-Ryong Kwon, Address: 45 Yongso-ro, Nam-gu, Busan, Pukyong National University, Daeyon campus, TEL : +82-51-629-6257, FAX : +82-51- 629-6230, E-mail : [email protected]
Receipt date : Aug. 4, 2021, Approval date : Aug. 12, 2021
†††
Dept. of Artificial Intelligence Convergence, Pukyong National University (E-mail : [email protected])
†††
Dept. of Electronics Engineering, Kyungil University (E-mail : [email protected])
†††
Dept. of Computer Engineering, Dong A University (E-mail : [email protected])
††††