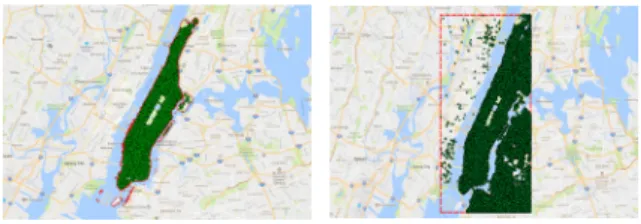
A Benchmark Test of Spatial Big Data Processing Tools and a MapReduce Application
10
0
0
전체 글
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
수치
+4


관련 문서
The proposal of the cell theory as the birth of contemporary cell biology Microscopic studies of plant tissues by Schleiden and of animal tissues by Microscopic studies of
Historical Data in HDFS 3rd-Party Hadoop Tools Data Scientist. Splunk Archive
For example, while a human baby and a kitten are both capable of inductive reasoning, if they are exposed to exactly the same linguistic data, the human will
Process data in registers using a number of data processing instructions which are not slowed down by memory access. Store results from registers
In this paper, we introduce different types of software reliability models and propose a sequential probability ratio test as a technique for determining
주거지 관리 도시계획 (Urban Planning). •거시적(Macro)인 도시 관리 - 용도지역,지구 계획 - 도시계획시설
Processing data transmission and reception packets which are coupled with the CubeSat communication protocol such as AX.25 and KISS is a critical step in a
The Autodesk Raster Design module supports grids and images and the Autodesk Onsite module handles all of the standard GIS data operations. extensive tools
