http://dx.doi.org/10.4491/KSEE.2016.38.2.87 ISSN 1225-5025, e-ISSN 2383-7810
데이터마이닝 기법을 이용한 상수도 시스템 내의 탁도 예측모형 개발에 관한 연구 A Study on the Turbidity Estimation Model Using Data Mining
Techniques in the Water Supply System
박노석․김순호․이영주*․윤석민†
No-Suk Park․Soonho Kim․Young Joo Lee*․Sukmin Yoon† 경상대학교 토목공학과 및 공학연구원․*K-water 연구원
Department of Civil Engineering and Engineering Research Institute, Gyeongsang National University
*K-water Institute
(Received January 27, 2016; Revised February 18, 2016; Accepted February 23, 2016)
Abstract : Turbidity is a key indicator to the user that the 'Discolored Water' phenomenon known to be caused by corrosion of the pipeline in the water supply system. 'Discolored Water' is defined as a state with a turbidity of the degree to which the user visually be able to recognize water. Therefore, this study used data mining techniques in order to estimate turbidity changes in water supply system. Decision tree analysis was applied in data mining techniques to develop estimation models for turbidity changes in the water supply system. The pH and residual chlorine dataset was used as variables of the turbidity estimation model.
As a result, the case of applying both variables(pH and residual chlorine) were shown more reasonable estimation results than models only using each variable. However, the estimation model developed in this study were shown to have underestimated predictions for the peak observed values. To overcome this disadvantage, a high-pass filter method was introduced as a pre- treatment of estimation model. Modified model using high-pass filter method showed more exactly predictions for the peak observed values as well as improved prediction performance than the conventional model.
Key Words : Turbidity, Discolored Water, Data Mining Techniques, Decision Tree Analysis
요약 : 탁도는 송·배수 관로의 부식 등에 의해 발생되는 것으로 알려진 ‘Discolored Water’현상을 수용가의 물 사용자가 인지 할 수 있는 주요 지표로서 활용되고 있다. 즉, ‘Discolored Water’는 수돗물 사용자가 육안으로 인지할 수 있는 정도의 탁도를 가진 상태로 정의할 수 있으며, 사용자는 수돗물에 존재하는 불특정의 용존 물질보다는 미세한 입자들에 대한 시각적인 인 지인 탁도를 통해서 ‘Discolored Water’를 인식하게 된다. 이에 본 연구에서는 실제 국내 상수도 시스템 내에서 관측된 다항 목의 수질데이터(탁도, pH 및 잔류염소)를 대상으로 하여 탁도 이외의 수질데이터들을 예측모형의 설명변수로 설정한 후 데 이터 마이닝 기법(data mining)을 통해 기계학습(machine learning)을 수행하여, 상수도 시스템 내에서의 탁도 변화를 예측하는 모형을 수립하고자 하였다. 수집된 수질 데이터를 대상으로 데이터 마이닝 기법인 Decision Tree를 이용해 탁도 예측모형을 구축한 결과 pH 및 잔류염소를 설명변수로 적용한 모형이 가장 높은 예측결과를 나타내었다. 하지만 예측모형들은 peak 관 측치에 대해서는 예측오차가 다소 증가하였는데 이를 보완하기 위해 고주파통과필터를 이용한 전처리 과정을 적용하였다.
그 결과 탁도 데이터의 시계열변화 및 peak 관측치에 대한 예측오차가 감소하는 것으로 나타났다.
주제어 : 탁도, 데이터 마이닝, 의사결정나무 분석, 고주파통과필터
1. 서 론
하천 및 호소수에 있어서 수중 탁도(Turbidity)는 미세 플 랑크톤에 의한 생물성 입자 및 비생물성 입자의 양에 주로 의존하게 되며, 수중 생태계 및 광환경 그리고 인간의 친수 활동과 밀접한 관련이 있는 것으로 알려져 있다.1~3)
한편, 상수도시스템에 있어서 탁도는 송․배수 관로의 부 식 등에 의해 발생되는 것으로 알려진 ‘Discolored Water’
현상을 수용가의 물 사용자가 인지할 수 있는 주요 지표로서 활용되고 있다. 즉, Fig. 1에서 나타낸 것과 같이 ‘Discolored Water’는 수돗물 사용자가 육안으로 인지할 수 있는 정도 의 탁도를 가진 상태로 정의할 수 있으며, 사용자는 수돗물 에 존재하는 불특정의 용존 물질보다는 미세한 입자들에 대한 시각적인 인지인 탁도를 통해서 ‘Discolored Water’ 인
식하게 된다.4)
과거 상수도 시스템 내에서 ‘Discolored Water’의 발생과 관련된 주요 원인으로서 주철관종에 의한 부식이 최우선적 으로 고려되어져 왔다. 하지만 1945년~1980년 기간 동안 상 수관망의 대규모 확장을 통해 전체 관종을 PVC (Polyvunyl chloride) 또는 AC (Asbestos cement)관으로 교체한 네덜란 드의 사례를 살펴보면 매년 상수도 관련부서(Ministry of Hosing, Spatial Planning and Environment, VROM)의 지속 적인 관리(고도처리공법의 도입, 주철관종의 교체 등)에도 불구하고 년간 3,000에서 6,000건의 ‘Discolored Water’에 대 한 수용가들의 민원이 보고되고 있으며, 이에 대한 대응으 로 네덜란드 정부는 년간 천가구당 0.5~1회의 관망 세척을 지속적으로 수행하고 있다.5)
물론 상수도 관망의 평균연령이 100년을 상회하는 주철
Fig. 1. Examples of discolored water.4)
관종이 지배적인 영국의 경우 ‘Discolored Water’에 대한 대 응으로 년간 천가구당 4회 정도의 세척을 수행하는 등 여 전히 상수도관의 부식이 ‘Discolored Water’ 현상의 주요원 인으로 작용되기는 하나, 고도정수처리의 도입과 더불어 대규모 관종 교체를 통해 주철관의 사용이 제한적인 네덜 란드의 사례는 상수도 시스템 내에서 ‘Discolored Water’의 발생은 관종의 부식 이외에도 다양한 요소들에 의한 복합 전인 현상임을 시사한다고 할 수 있다.
상수도시스템 내에서의 ‘Discolored Water’의 발생과 관 련된 최근의 연구들을 살펴보면 ‘Discolored Water’ 현상은 관의 부식에 의한 원인과 더불어 관망 내에서 발생되는 입 자들의 축적과 이들의 유동과 관련이 깊다는 것을 언급하 고 있다.6~8) 그리고 상수도 관망 내에서 발생되는 입자들의 조성은 상이한 크기와 밀도 등을 가지고 있으며, 입자들의 발생과 관련된 주요원인들 또한 내적요인과 외적요인으로 분류 할 수 있다. 우선 입자발생과 관련된 내적요인들을 살 펴보면 관 및 부속품(밸브 및 라이닝 등)의 부식,9,10) 관내 에서의 미생물의 재성장 및 용존 물질들의 화학적 반응에 의한 부유성 입자로의 환원11)등을 고려할 수 있다. 그리고 외적요인들로는 관을 보수하는 동안 외부 오염물질의 유입 또는 침투 및 역류7)에 의한 원인과 더불어 표준 정수처리 공정에 있어서 침전지로부터 유출되는 미소플록들과 같은 부유된 고체성 물질에 대한 불완전한 제거, 활성탄 또는 모 래여과 과정에서 잔존하는 입자 그리고 바이오 필터로 발 생될 수 있는 미세 바이오 입자 등과 같이 정수처리공정 자 체로부터 유입되는 입자들이 주요 원인으로 고려될 수 있
다.6,12) 이러한 복잡한 원인들의 상호작용 과정은 상이한 수
리학적 조건과 더불어 관종 및 관년령 그리고 관망 내부의 서로 다른 물리적 또는 화학적 조건에 의해 더욱 복잡하게 반응하게 되며, 이로 인해 ‘Discolored Water’ 현상의 발생 메커니즘을 명확히 이해하기란 대단히 어렵다 할 수 있다.
하지만 여기서 중요한 사실은 비록 상수도 시스템 내의 복잡한 상호작용으로 인해 ‘Discolored Water’의 발생 메커 니즘에 대한 명확한 이해가 현실적으로 불가능 하다 할지라 도, 상기에서 언급한 것과 같이 수용가의 물 소비자들은 수 질에 대한 시각적인 인지인 탁도의 변화를 통해 ‘Discolored Water’에 관한 민원을 제기한다는 것이다. 즉, 상수도시스 템 내에서 다양한 지점에서의 연속적인 탁도 모니터링은
‘Discolored Water’ 현상에 의한 수질오염의 감시를 위한 필수조건이라 할 수 있으며, 관망을 통해 이동하는 부유물 질의 수리학적 거동을 설명하기 위한 정보를 제공하게 된
Table 1. Status of water quality monitoring at major cities of South Korea
City Water qualities Measuring location
Seoul Turbidity, pH, Chlorine Intake, Water treatment plant, Reservoir, and faucet Gwangju Turbidity, pH, Chlorine Water treatment plant Daejeon Turbidity, pH, Chlorine Water treatment plant Daegu Turbidity, pH, Chlorine Water treatment plant
Busan Turbidity, pH, Chlorine Conductivity, Temperature
Intake, Water treatment plant, Reservoir, and faucet
Ulsan Turbidity, pH, Chlorine
Temperature Water treatment plant
다. 이와 관련해 Vreeburg4)는 수질 모니터링은 수압 모니 터링에 비해 상수도 운영에 있어서 즉각적인 효과를 갖는 운영 도구로서 기능을 하지 않는 반면, 수도시스템의 운영 자에게 장래에 발생 가능한 수질사고에 대한 경고와 신속 한 대응을 위한 정보를 제공해준다고 언급한바 있다.
수질 모니터링과 관련된 국내의 현황을 살펴보면 상수도 사업을 수행하고 있는 각 지자체들은 자동계측시스템을 근 간으로 Online 수질측정을 통해 원수에서 부터 수도꼭지까 지의 수질상태를 실시간으로 모니터링 하고 이를 수돗물 사 용자들에게 공개하는 수질자동감시시스템을 운영하고 있다.
Table 1은 국내 특․광역시에서 시민들을 대상으로 공개 하고 있는 수질항목들과 측정지점을 요약한 것으로서 탁도, pH 및 잔류염소는 모든 특․광역시에서 공통적으로 공개 하고 있는 수질항목임을 알 수 있다. 하지만 현재 국내의 각 지자체에서 운영하고 있는 수질자동감시시스템은 실시간 으로 계측되고 있는 관측값을 근간으로 수질변화가 환경부 에서 고시한 ‘먹는물 수질기준’을 초과하는 경우에 대해서 만 경보를 하는 ‘Set point’ 방법으로서, 상수도시스템 내에 서의 수질변화와 관련해 대응적인 방안으로서만 반응하고 있다고 할 수 있다.
이에 반해 최근 미국 환경청에서는 수돗물을 생산하고 공 급하는 전 과정에서 발생할 수 있는 수질 사고(물리적, 화학 적, 생물학적 및 방사능 오염)를 조기에 감시하고 신속한 대 응을 위한 총체적인 시스템을 ‘Contamination Warning System (CWS)’이라 명명하고, 신시내티 지역을 포함함 다수의 지 역들에서 파일럿 플랜트 구축․운영하고 있다. 특히, 미국 환경청에서도 효과적인 수질감시와 신속한 대응을 위해서 는 수리변동을 고려한 다수의 지점에서 높은 정확도의 수 질 모니터링이 필수적임을 언급한 바 있다.13,14) 이와 더불
어 수질감시에 있어서 관계법 등으로 제시된 수질기준의 임 계치만을 이용하는 ‘Set point’ 방법에 기초하여 수질오염 을 판단하는 경우 실제 여러 가지의 문제점들이 발생될 수 있다고 보고하였다. 즉, 수질감시에 있어서 ‘Set point’ 방법 은 상수도시스템 내의 연속적인 수리변화와 이에 따른 수 질변동과의 상호 교섭 작용은 전혀 고려하지 못함으로서 과 도하면서도 불필요한 위양성(false positive)의 거짓경보가 발생하게 되며, 이는 결국 전체적인 수질 경보시스템의 신 뢰도와 운영효율에 부정적인 영향을 미칠 수 있음을 지적
하였다.15,16) 그리고 이에 대한 대응으로서 미국 환경청에서
는 ‘Set point’ 방법에 의한 수질감시의 기술적 한계를 지양 하고자 새로운 수질감시체계 알고리즘인 ‘Event Detection System (EDS)’을 도입하였다. 여기서, EDS에 관해 간략히 살펴보면 상수도 시스템 내에서 모니터링된 실시간의 수질 데이터들을 바탕으로 통계학적 예측모형(e.g., Time series model, Multivariate model)을 수립하고 이를 근간으로 가까 운 미래시점의 수질변화를 예측한 후 현시간의 관측값과의 비교를 수행한다. 그리고 예측값과 관측값의 차이로 정의되 는 ‘잔차(Residual)’들에 대한 확률론적 분석(e.g., Binominal event discriminator model)을 기반으로 상수도시스템 내의 연속적인 수리변화 등에 의한 수질오염 경보의 위양성을 최소화한 분석 결과를 도출하게 된다.17)
그러나 상기에서 언급한 것과 같이 현재 국내에서 수행되 고 있는 수질자동감시시스템의 기본적인 절차는 환경부에 서 고시한 ‘먹는물 수질기준’에 근간한 ‘Set point’ 방법에 기초하는 만큼 추후 효율적인 수질감시에 있어서 다양한 문 제점들이 발생될 가능성이 높다고 할 수 있다. 그리고 지난 2015년 3월 00혁신도시 공동주택지역(아파트 4개 단지, 3,147 가구)에서 발생된 ‘Discolored Water’ 현상으로 인해 수돗물 의 음용이 중단되는 사례에서와 같이 새로운 도심지의 개발 과 입주과정에 있어서 상세불명의 원인들에 의한 ‘Discolored Water’ 현상의 발생과 이에 따른 수용가의 민원은 상시 발 생할 가능성을 내포하고 있다고 할 수 있다.
이에 본 연구에서는 실제 국내 상수도 시스템 내에서 관 측된 다항목의 수질데이터를 대상으로 하여 탁도 이외의 수질데이터들을 예측모형의 설명변수(explanatory variable) 들로 설정한 후 데이터 마이닝 기법(data mining)을 통해 기 계학습(machine learning)을 수행하여 상수도시스템 내에서 의 탁도 변화를 예측하고자 하였다. 또한 미국 환경청에서 제안한 EDS 알고리즘에서와 같이 수돗물의 공급 전 수질 변화를 예측하고 관측 데이터와 비교를 통해 실제 수질오 염여부를 빠른 시간에 결정하는 것이 수질자동감시시스템의 핵심 기능임을 인식할 때 국내에서 실시간으로 관측되고 있는 다항목의 수질데이터를 대상으로 데이터 마이닝 기 법을 이용하여 상수도 시스템 내에서의 탁도 예측 가능성을 판단하는 것이 본 연구의 궁극적인 목적이라 할 수 있다.
2. 이론적 배경
Decision tree는 분석대상의 데이터들로 부터 나무구조의 의사결정규칙을 설정하고 관심의 대상을 몇 개의 하위집단으 로 분류하거나 예측을 하는 데이터 마이닝 기법이다. 이러 한 decision tree는 분석과정이 나무구조에 의해서 표현되기 때문에, 분류 또는 예측을 목적으로 하는 다른 데이터 마이 닝 기법들에 비해 분석과정의 이해와 결과의 해석이 쉽다 는 장점을 가지고 있다. 특히, 데이터 마이닝에서 decision tree의 활용 범위가 다양한데, 이는 decision tree 자체가 분류 또는 예측 모형으로 활용되어 데이터 마이닝 기법으로 사 용되기도 하고, 다른 데이터 마이닝 기법을 적용하기 전 데 이터의 전처리 작업에도 사용할 수 있기 때문이다. Decision tree는 연속형이나 범주형 등의 예측변수를 그대로 이용하 므로 데이터의 변형에 따른 시간과 작업을 줄일 수 있고, 모형을 구축하는 시간이 짧다는 장점이 있다. 이러한 특성 때문에 decision tree는 다른 예측 기법을 수행하기 전에 많 은 예측변수 중에서 유용한 것들만 고르는 과정에 사용될 수 있다.
Decision tree는 뿌리마다 시작해서 각 가지가 끝마디가 될 때까지 자식마디를 만들면서 형성된다. 이러한 decision tree를 완성하기 위해서는 마디의 분리기준(splitting rule)의 선택, 분리를 멈추기 위한 정지기준(stopping rule)의 선택, 가지치기(pruning)방법의 선택, 입력변수의 값에 결측치가 있는 경우 대치(imputation) 방법의 선택 등 여러 단계를 수 행하여야 한다. 이러한 과정을 수행하여 decision tree를 형 성하는 주요 알고리즘으로는 CHAID, CART, C4.5, QUEST 등이 있으며, 각 단계에서 서로 다른 기준을 가지고 있어 다른 decision tree가 만들어진다.18)
본 연구에서는 C4.5 알고리즘을 개량하여 개발된 기계 학습 패키지 중 하나인 WEKA (Waikato Environment for Knowledge Analysis; Witten and Frank, 1999)로 구현한 M’5 (prime) 알고리즘을 사용하여 연구를 수행하였다. M’5 알 고리즘은 세 개의 모형 즉, 선형회귀식, 회귀나무(regression tree), 모형 트리(model tree) 분석을 수행한다. 선형회귀식 은 n개의 서로 다른 입력 변수에 대한 회귀식을 제공한다.
회귀나무와 모형트리는 의사결정나무의 결과로서 수치형 결과를 제공하는 면에서는 유사하나, 회귀나무 알고리즘은 출력 결과에 대한 평균값을 제시하고 모형트리는 선형회귀 식을 제공한다는 면에서 차이가 있다.
모형트리는 의사결정나무 알고리즘의 잎 노드를 선형 회 귀함수로 제시한다. 따라서 모형트리는 의사결정구조를 명 료하게 제시함과 동시에 결과로서 제시된 선형함수는 일반 적으로 많은 변수를 포함하지 않는다는 장점을 가지고 있 다. M’5 알고리즘은 모형트리의 한 종류로서 부분적으로 선형모형으로서 선형모형인 ARIMA와 비선형모형인 인공 신경망(ANN)의 중간정도 위치를 갖는다. 분류문제에 있어 서 의사결정나무 알고리즘은 다음과 같은 분할 정복(divide- and-conquer) 방법을 사용한다.
1) 뿌리마디에 위치할 변수를 선택하고 가능한 값에 대하 여 하나의 가지를 생성한다.
(a) Raw dataset (b) Filtered dataset Fig. 2. Plotting of time series for water quality dataset.
2) 선택된 값에 대하여 자식마디를 분리 생성한다.
3) 자식마디에 할당된 모든 샘플이 하나의 범주로 분리 될 때 자식마디의 분리 생성을 중지한다.
모형트리에서 통계학적 분리기준은 자식마디의 엔트로피 (entropy) 감소에 근거하고 있다. 즉 유사한 성질의 샘플을 가능한 하나의 자식마디로 분류하는 방식으로 분리를 수행 한다. M’5모형트리는 자식마디 T 에 할당된 샘플의 표준편 차(standard deviation)가 줄어드는 방향으로 분리를 수행하 며, 각 마디에 할당된 데이터의 표준편차는 예측오차로서 평가되고 표준편차의 감소량을 최대화 시키는 변수가 분리 기준으로 선정된다.
×
(1)여기서, 식 (1)에 나타낸 SDR (standard deviation reduction) 은 표준편차의 감소량, Ti는 선정된 변수에 의해 생성된 자 식마디의 샘플 집합이다. 나무구조의 분리는 표준편차변화 가 미미하거나(약 5% 미만) 자식마디에 할당된 샘플 수가 거의 없을 때 중지된다. 최종적으로 각각의 자식마디 샘플 에 대하여 선형회귀모형을 구축한다.
3. 적용 변수 및 데이터
본 연구에서는 decision tree 기법을 이용해 배수지의 탁 도 예측모형을 구축하기 위해 국내 K_배수지를 대상으로 실시간으로 측정되고 있는 탁도(NTU) 데이터를 수집하였 다. 그리고 탁도 예측모형에 대한 decision tree를 구축하기 위해 잔류염소(mg/L) 및 pH 데이터를 추가적으로 수집하였 으며, 각 수질데이터들의 측정기간은 2015년 11월 9일~11 월 22일으로서 1분 단위로 측정되었다.
Fig. 2(a)은 데이터수집기간 동안의 각 수질 데이터의 원 시 관측값을 도시한 것으로서 탁도 및 pH는 데이터 전기 간에 걸쳐 비교적 안정적인 관측결과를 나타내는 반면, 잔 류염소는 측정 잡음들이 상대적으로 강하게 분포하는 것을 알 수 있다. 이에 본 연구에서는 수질 데이터의 시계열변화 를 보다 더 명확히 분석하기 위해 고주파통과필터(High-Pass Filter)를 이용하여 각 측정데이터의 관측 잡음을 소거하였 다. 여기서, 고주파통과필터는 Fig. 3에 나타낸 것과 같이 측정과정에 있어서 입력되는 신호의 장기변동을 나타내는 저주파 성분들을 걸러내고 측정 잡음들과 같은 고주파 성 분만 통과시키게 된다. 즉, 잡음을 포함한 측정신호가 입력 되면 측정신호는 걸러지고 잡음만 추출되게 되며 이를 원 시데이터들로부터 제거함으로서 측정신호의 고유변화를 용
Fig. 3. Analysis procedure of the High-Pass Filter.
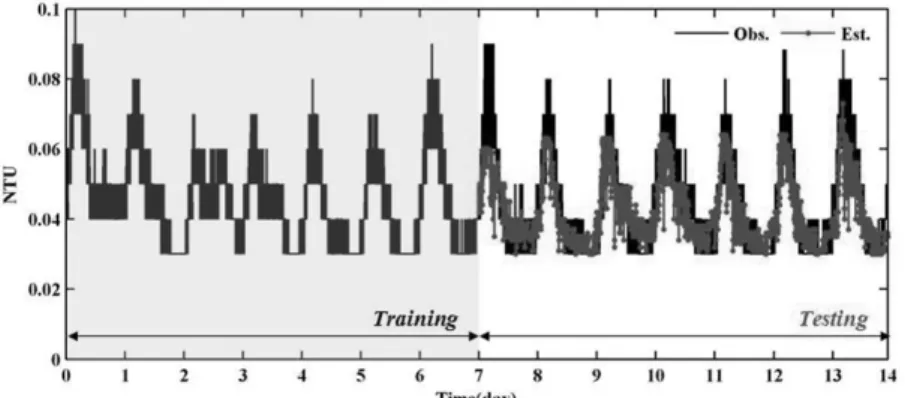
Fig. 4. The simulation results of turbidity changes using Model 1.
Table 2. The correlation coefficient matrix for the water quality dataset
Turbidity pH Chlorine
Turbidity 1 -0.51 (-0.52*) 0.39 (0.55)
pH 1 -0.14 (-0.17)
Chlorine 1
*derived from filtered dataset
이하게 분석할 수 있게 된다.19)
Fig. 2(b)는 고주파통과필터로부터 측정 잡음들이 소거된 각 수질 데이터들을 도시한 것으로서 원시 수질 데이터에 비해 시계열분포 특성이 보다 명확하게 나타나는 것을 알 수 있다. 그리고 각 수질 데이터들의 시계열분포 특성을 살 펴보면 시간변동에 따라 추세성분은 나타내지 않는 반면 일 단위의 짧은 주기를 갖는 계절성분을 포함하고 있는 것을 알 수 있다.
계절성분에 의한 각 수질데이터들의 시계열 변화와 이에 따른 상호간의 선형적 관계를 분석하기 위해 피어슨의 상 관계수(Pearson correlation coefficient, CC)를 이용하였으며, 그 결과는 Table 2에 요약하여 나타내었다.
피어슨의 상관계수들로부터 각 수질데이터들 사이의 선 형적 관계를 분석한 결과 탁도와 pH 사이에는 뚜렷한 음 의 상관관계가 나타났으며, 탁도와 잔류염소 사이에는 뚜 렷한 양의 상관관계, pH와 잔류염소 사이에는 약한 음의 상관관계 나타났다.
4. 모형 수립 및 검정
본 연구에서는 배수지 내의 탁도 변화를 예측하기 위해 데이터 마이닝 기법인 decision tree를 이용하였다. 그리고 탁도 예측모형의 구축에 있어서 최고의 이득비율을 얻기 위한 끝가지의 분리 및 최적 회귀식(model tree)을 효과적으 로 유도하기 위해 뉴질랜드 University of Waikato에서 개 발 보급중인 WEKA 3.6 M’5 알고리즘을 적용하였다. 그리 고 본 연구에서 구축한 탁도 예측모형들의 decision tree 구 조는 다음과 같은 설명변수들로 이루어진 n개의 선형회귀 식 형태로 구성되어 있다.
▪Model 1
배수지 탁도(NTU) =
잔류염소
▪Model 2
배수지 탁도(NTU) =
▪Model 3
배수지 탁도(NTU) =
잔류염소
상기의 탁도 예측모형들을 구축하기 위해 수집된 데이터 중 2015년 11월 9일~11월 15일(10,080 set)기간의 데이터는
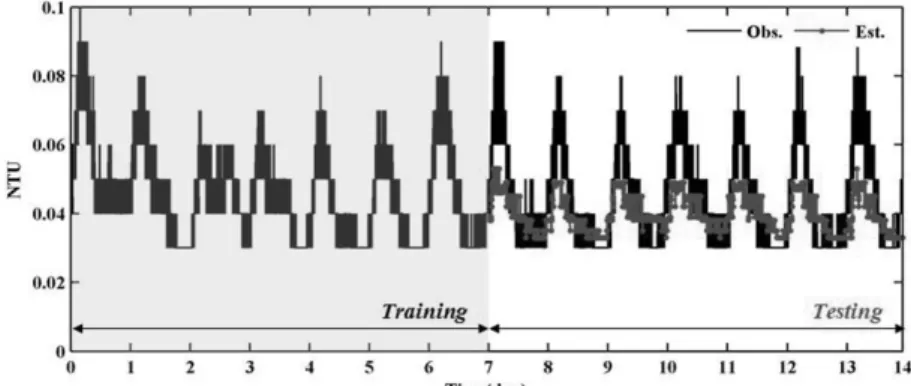
Fig. 5. The simulation results of turbidity changes using Model 2.
Fig. 6. The simulation results of turbidity changes using Model 3.
예측모형을 구축하는데 사용하였으며, 2015년 11월 16일~
11월 22일(10,080 set)기간의 데이터는 예측모형의 검증을 위해 적용되었다.
Fig. 4는 Model 1 이용하여 국내 K_배수지의 탁도 변화를 예측한 결과이다. Model 1의 설명변수로서 pH와 잔류염소 데이터가 적용되었으며, decision tree의 구조는 자식마디의 분기를 통해 총 69개의 선형회귀식을 갖는 형태이다. 데이 터기간 관측된 탁도의 시계열변화를 Model 1을 이용해 예 측한 결과 상관계수는 0.78로서 원시 탁도 데이터에서 나타 난 시계열변화 특성인 일단위의 계절성분들이 잘 모의되는 것으로 나타났다. 하지만 탁도 데이터의 시계열변화에 있 어서 국부적으로 발생되는 peak 관측값들에 대해서는 다 소 과소한 예측 결과를 나타내었다.
Fig. 5는 Model 2 이용하여 국내 K_배수지의 탁도 변화 를 예측한 결과이다. Model 2의 설명변수로서 pH 데이터 가 적용되었으며, decision tree의 구조는 자식마디의 분기 를 통해 총 9개의 선형회귀식을 갖는 형태이다. 데이터기 간 탁도 데이터의 시계열변화를 Model 2로 예측한 결과 상 관계수는 0.57로서 원시 탁도 데이터에의 계절성분들은 잘 모의되는 것으로 나타났으나, peak 관측값에 대해서는 앞 선 Model 1의 예측결과 보다 더 과소한 예측결과를 나타 내었다.
Fig. 6은 Model 3을 이용하여 국내 K_배수지의 탁도 변 화를 예측한 결과이다. Model 3의 설명변수로서 잔류염소 데이터가 적용되었으며, decision tree의 구조는 자식마디의
분기를 통해 총 13개의 선형회귀식을 갖는 형태이다. 데이 터기간 탁도 데이터의 시계열변화를 Model 3을 이용해 예 측한 결과 상관계수는 0.55로서 Model 2의 예측결과에서와 같이 원시 탁도 데이터의 계절성분들은 잘 모의되는 것으로 나타났으나, peak 관측값에 대해서는 다소 과소한 결과를 나타내었다. 또한 설명변수로 적용된 원시 잔류염소 데이터 내에 잡음들이 강하게 분포함으로(Fig. 2) 인해 탁도 예측결 과에서도 Model 1, 2에 비해 전반적으로 예측값들의 산포 도가 증가하는 것으로 나타났다.
본 연구에서는 decision tree로부터 개발된 탁도 예측모형 들의 정확도를 정량적으로 검증하기 위해 Mean Absolute Error (MAE, 식 (2)), Root Mean Square Error (RMSE, 식 (3)) 를 활용하였다. 여기서, MAE와 RMSE는 모형이 예측한 값 (Ei)과 실제 환경에서 관측된 값(Oi)의 차이인 잔차(residual) 를 정량적으로 평가하기 위해 사용되는 측도로서는 각 지 표가 ‘0’에 수렴할수록 모형은 높은 예측성능을 나타내게 된다.
(2)
(3)
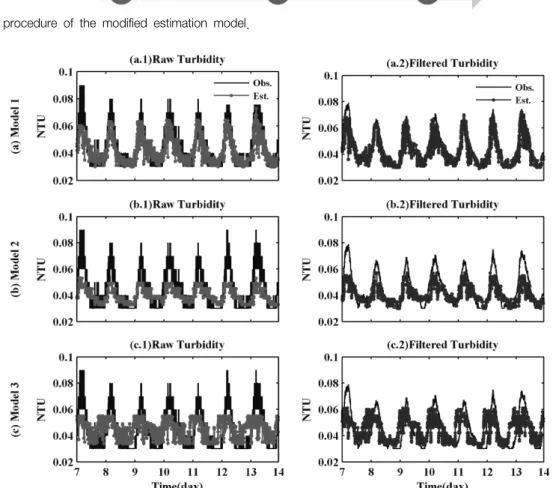
Fig. 7. Analysis procedure of the modified estimation model.
Fig. 8. The comparison of simulation results.
Table 3. Simulation condition and test criteria values
Parameter Rules Model test criteria
CC MAE RMSE
Model 1 pH, Chlorine 69 0.78 0.006 0.008
Model 2 pH 9 0.57 0.009 0.011
Model 3 Chlorine 13 0.55 0.009 0.011
Table 3은 본 연구에서 decision tree를 이용해 개발한 탁 도 예측모형들의 MAE 및 RMSE의 산정 결과를 요약한 것 이다. 각 예측모형들의 MAE는 0.006~0.009, RMSE는 0.008~
0.011로서 원시 탁도 데이터의 표준편차가 0.013임을 고려 할 때 각 모형들의 예측성능은 전반적으로 높은 적합도를 나타내는 것으로 판단 할 수 있다. 하지만 상기에서 언급한 것과 같이 각 예측모형들은 원시 탁도 데이터의 시계열 특 성인 일단위의 계절변화에 대해서는 높은 상관성을 나타내 는 반면, peak 관측값에 대해서는 다소 과소한 예측 결과를 나타내었다. 그리고 peak 관측값에 대한 과소 예측정도가 증가함에 따라 MAE 및 RMSE도 증가하게 되는 것으로 미 루어 볼 때 peak 관측값에 대한 과소 예측 경향이 모형들의 예측성능에 부정적인 영향을 미친다는 것은 쉽게 추정할
수 있는 사실이다.
따라서 본 연구에서는 상기의 예측모형들에서 나타나는 peak 관측값들에 대한 과소 예측 경향을 보완하고자 수정 된 탁도 예측모형을 구성하였으며, 수정된 모형의 가장 두 드러진 특징은 Fig. 7에 나타낸 것과 같이 각 입력데이터에 대해 상기 3장에서 언급한 고주파통과필터를 전처리 과정으 로서 적용한 것이다.
상기의 Fig. 7에서 나타낸 절차를 통해 수정된 탁도 예측 모형을 재구축한 결과 기존 모형들에 비해 decision tree 구 조의 선형회귀식들이 다소 증가하여 Model 1은 192개의 선 형회귀식, Model 2는 61개의 선형회귀식 그리고 Model 3 는 19개의 선형회귀식으로 구성된 decision tree 구조를 갖 는 것으로 나타났다. 이처럼 수정 예측모형들의 decision tree 구조는 기존 예측모형의 비해 보다 다양한 분류규칙을 갖 게 되며, 이는 수정된 모형들이 기존의 모형들에 비해 수질 인자간의 교호작용을 보다 엄격하게 분류할 수 있음을 의 미한다. 그리고 수정된 탁도 예측모형들의 성능을 분석하기 위해 검정기간에 대해 예측을 재수행하였으며, 그 결과를 Fig. 8에 도시하였다.
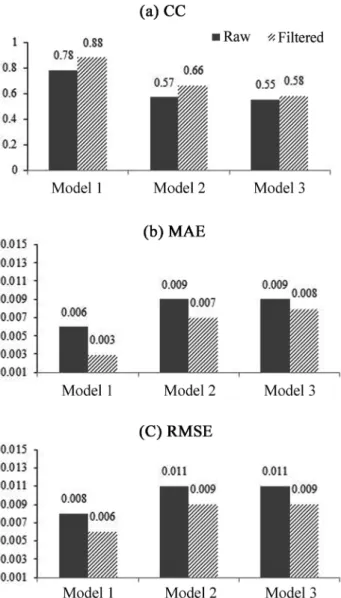
Fig. 8은 원시 데이터만을 이용한 기존 예측모형과 고주파 통과필터를 전처리 과정으로 도입한 수정 예측모형들의 탁 도 예측결과를 상호 비교하여 도시한 것으로서 Fig. 8(a.2), (b.2), (c.2)에 도시된 것과 같이 수정 모형들의 예측값들은 기존 모형들에 비해 탁도 데이터의 시계열변화 뿐만 아니 라 peak 관측값들을 보다 더 정확하게 예측하는 것을 알 수 있다. 고주파통과필터를 이용한 전처리 과정의 적용과 de- cision tree의 증가된 분류규칙으로 인한 수정 모형들의 예 측성능 개선 정도를 정량적으로 평가하기 위해 CC, MAE 및 RMSE를 산정한 후 그 결과들을 Fig. 9에 요약하여 나 타내었다.
Fig. 9. The comparison of model test criteria.
Fig. 9에 나타낸 것과 같이 수정 모형들의 예측결과에 대 한 CC는 기존 모형들의 예측결과와 비교해 5~14% 정도 향 상 되었으며, MAE 및 RMSE는 13%~100% 및 22%~33%
감소하였다. 이는 수정 탁도 예측모형이 기존 모형과 비교 해 탁도 데이터의 시계열변화를 보다 더 잘 모의함을 의미 하며, 예측 정확도 또한 기존 모형과 비교해 향상되었음을
의미한다. 따라서 고주파통과필터를 이용한 전처리 기법을 적용한 수정 예측모형들은 기존 모형들에서 나타난 peak 관 측값에 대한 과소 예측경향을 최소화 할 수 있는 장점이 있 으며, 예측과정에 있어서 입력데이터들에 의도치 않은 변동 성이 발생하더라도 상대적으로 안정적인 예측결과를 제공 할 수 있을 것으로 판단된다.
5. 결 론
본 연구의 목적은 국내 상수도 시스템 내에서 관측되고 있는 다항목의 수질데이터를 대상으로 데이터 마이닝 기법 인 decision tree를 이용해 기계학습을 수행하고 이를 근간 으로 탁도 예측모형을 수립하고자 함에 있다. 이를 위해 국 내 K_배수지를 대상으로 탁도, pH 및 잔류염소 데이터를 수집한 후 탁도 예측모형을 개발하고 검정을 수행하였다.
그 결과들을 요약하면 다음과 같다.
1) 탁도 예측모형 구축을 위해 pH 및 잔류염소 데이터를 이용하였으며, 예측모형은 pH와 잔류염소, pH 그리고 잔류 염소만을 설명변수로 갖는 3가지 형태로 구성하였다. 그리 고 국내 K_배수지에서 관측된 실측 데이터를 기계학습의 입력 자료로 활용하여 decision tree를 통해 예측모형을 구 축한 결과 각 모형들은 원시 탁도 데이터의 시계열변화 특 성인 일단위의 계절성분들을 비교적 잘 모의하는 것으로 나 타났다. 특히, pH와 잔류염소를 모두 설명변수로 활용하는 경우 예측모형의 상관계수는 0.78로서 개발된 예측모형들 중 가장 우수한 예측 결과를 나타내었다.
2) 하지만 본 연구에서 개발한 예측모형들은 탁도 데이터 의 시계열변화를 상대적으로 잘 모의하는 반면, 탁도 데이 터의 계절변화에 있어서 국부적으로 발생되는 peak 관측값 들에 대한 예측들은 전반적으로 과소한 예측결과를 나타내 었다. 이에 본 연구에서는 peak 관측값들에 대한 과소 예측 경향을 보완하고자 수정 예측모형을 재구성하였으며, 수정 모형의 주요 특징은 입력데이터에 대해 고주파통과필터를 전처리 과정으로서 적용한 것이다. 그리고 수정 모형의 효 과를 검정하기 위해 기계학습과 예측을 재 수행한 결과 수 정 탁도 예측모형들은 기존 모형과 비교해 탁도 데이터의 시계열변화 뿐만 아니라 peak 관측값들에 대한 예측성능 또한 뚜렷하게 개선되는 것으로 나타났다.
앞선 서론부에서 언급한 바와 같아 수용가의 물 소비자들 은 수질에 대한 시각적인 인지인 탁도의 변화를 통해 ‘Dis- colored Water’에 관한 민원을 제기하게 된다. 그리고 2015 년 3월 국내 00혁신도시의 사례에서처럼 새로운 도심지의 개발과 입주과정에 있어서 상세불명의 원인들에 의한 ‘Dis- colored Water’ 현상의 발생과 이에 따른 수용가의 민원은 상시 발생할 가능성을 내포하고 있다고 할 수 있다.
그리고 미국 환경청에서 제안한 것과 같이 수돗물의 공
급 전 수질 변화를 사전에 예측하고 관측 데이터와 비교를 통해 실제 수질오염여부를 빠른 시간에 결정하는 것이 수 질감시의 핵심 기능임을 인식할 때 본 연구에서 제안한 데 이터 마이닝 기법을 근간으로 하는 탁도 감시 알고리즘은 추후 확장 또는 신설되는 수도 시스템 내에서의 수질관리 에 있어서 유용한 감시 도구로서 활용될 수 있을 것으로 기대된다.
Acknowledgement
본 연구는 환경부 “차세대 에코이노베이션사업(글로벌탑 환경기술개발사업)”의 지원에 의해 수행되었으며 이에 감 사드립니다(GT-SWS-11-02-007-8).
References
1. Hong, J., Mun, H., Yun, H., Yu, C. and Kang, B., “Sensitivity Analysis of Real-time Water Quality Index added Turbidity”
Proceedings of the 2015 spring conference of KSWW and KSWQ, pp. 521~522(2015).
2. Shin, J., Jeong, S. and Hwang, S., “Long-term variation of water turbidity in a Korean river ecosystem (Youngsan River)”
Proceedings of the 2005 spring conference of KSWW and KSWQ, pp. 711~714(2005).
3. Wetzel, R. G., Limnology: Lake and River Ecosystems, 3rd ed., Academic Press, California(2001).
4. Vreeburg, J. H. G., Discolouration in drinking water systems : the role of particles clarified, IWA Publishing(2010).
5. REWAB, “Registration system yearly analysis results of Dutch water companies, available through ministry of VROM (Netherlands Ministry of Housing, Spatial Planning and the Environment,”(Eds), Den Haag, The Netherlands
6. Ellison, D., Investigation of Pipe Cleaning Methods, AW- WARF, Denver(2003).
7. Prince, R., Goulter, I. and Ryan, G., “Relationship Between Velocity Profiles And Turbidity Problems In Distribution Systems,” World Water and Environmental Resources Con- gress, pp. 1~9(2001).
8. Slaats, N., Rosenthal, L. P. M., Siegers, W. G., Boomen,
M. V. d., Beuken, R. H. S. and Vreeburg, J. H. G. Processes involved in the generation of discolored water, American Water Works Association Research Foundation / Kiwa, The Netherlands(2002).
9. Boxall, J. B., Skipworth, P. J. and Saul, A. J., “Aggressive flushing for discolouration event mitigation in water distri- bution networks,” Water Sci. Technol. Water Supply, 3(1-2), 179~186(2003).
10. Clement, J. A., Hayes, M., Kriven, W. M., Sarin, P., Bebee, J., Jim, K., Beckett, M., Snoeyink, V. L., Kirmeyer, G. J.
and Pierson, G., Development of red water control strategies, American Water Works Association Research Foundation, Denver(2002).
11. Kirmeyer, G. J., Friedman, M., Clement, J., Sandvig, A., Noran, P. F., Martel, K. D., Smith, D., LeChevallier, M., Volk, C., Antoun, E., Hiltebrand, D., Dyksen, J. and Cushing, R., Guidance manual for maintaining distribution system water quality, AWWA Research Foundation and American Water Works Association, Denver(2000).
13. Lee, D., Kwan, B. and Ryu, S., “Filtration Performance Evaluation by Monitoring the Filtered Water Turbidity in Water Treatment Plant,” Proceedings of the 2000 autumn con- ference of KSWW and KSWQ, pp. 115~118(2000).
14. U.S. EPA, Water Sentinel System Architecture Draft, Version 1.0(2005).
15. Janke, R., Murray, R. Uber, J. and Taxon, T., “Comparison of Physical Sampling and Real-Time Monitoring Strategies for Designing a Contamination Warning System in a Drink- ing Water Distribution System,” J. Water Resour. Plann. and Manage., 132(4), 310~313(2006).
16. U.S. EPAa, Water Security Initiative: System Evaluation of the Cincinnati Contamination Warning System Pilot, U.S EPA Water Security Division(2014).
17. U.S. EPAb, Water Security Initiative: Evaluation of the Water Quality Monitoring Component of the Cincinnati Contamina- tion Warning System Pilot, U.S EPA Water Security Divi- sion(2014).
18. Park, N. S., Lee, Y., Chae, S. and Yoon, S., “A Study on the Statistical Predictability of Drinking Water Qualities for Contamination Warning System,” J. Korean Soc. Water and Wastewater, 29(4), 469~479(2015).
19. Park, N. S., Park, S., Kim, S. and Jeong, N., “Establishment of the Refined Model for Prediction of Flocculation/Sedi- mentation Efficiency Using Model Tree Technique,” J. Korean Soc. Water and Wastewater., 20(6), 1~436(2006).