JKSCI
Multi-scale face detector using anchor free method
1)
Dong-Ryeol Lee*, Yoon Kim*
*Student, School of Computer Science and Engineering, Kangwon National University, Chuncheon, Korea
*Professor, Dept. of Computer Science and Engineering, Kangwon National University, Chuncheon, Korea
[Abstract]
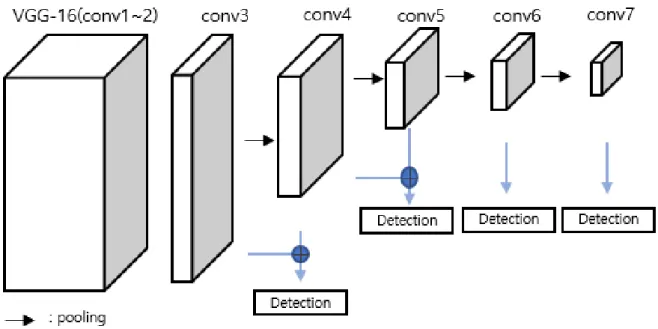
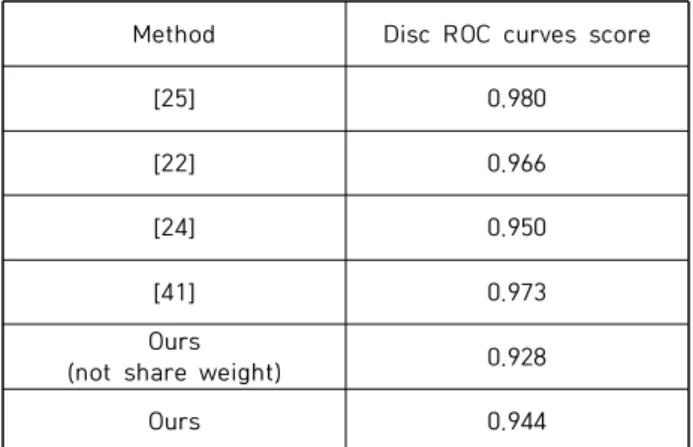
In this paper, we propose one stage multi-scale face detector based Fully Convolution Network using anchor free method. Recently almost all state-of-the-art face detectors which predict location of faces using anchor-based methods rely on pre-defined anchor boxes. However this face detectors need to hyper-parameters and additional computation in training. The key idea of the proposed method is to eliminate hyper-parameters and additional computation using anchor free method. To do this, we apply two ideas. First, by eliminating the pre-defined set of anchor boxes, we avoid the additional computation and hyper-parameters related to anchor boxes. Second, our detector predicts location of faces using multi-feature maps to reduce foreground/background imbalance issue. Through Quantitative evaluation, the performance of the proposed method is evaluated and analyzed. Experimental results on the FDDB dataset demonstrate the effective of our proposed method.
▸Key words: Face detection, Anchor free method, Multi-scale detection, Deep learning, Feature pyramid learning
[요 약]
본 논문에서는 앵커 프리 방법을 이용한 FCN(Fully Convolutional Network)기반의 1단계 다중 크 기 얼굴 검출기를 제안한다 . 최근 대부분의 연구들은 사전 정의된 앵커를 사용하여 얼굴이 있을 만한 위치를 예측한다. 그러나 사전 정의 앵커를 이용함으로써 학습 시 하이퍼 파라미터의 설정 과 추가적인 계산이 필요하다. 제안하는 방법의 핵심 아이디어는 앵커 프리 방법을 사용하여 하 이퍼 파라미터를 없애고 여러 개의 특징 맵을 사용함으로써 클래스 내 불균형 문제를 완화하는 것이다. 이 방법들은 다음과 같은 효과가 있다. 첫째로 사전정의 앵커를 없앰으로써 앵커와 관련 된 하이퍼 파라미터와 추가적인 계산을 피한다. 둘째로 클래스 내 불균형을 완화하기 위해 여러 개의 특징 맵으로부터 얼굴을 예측한다 . 정량적 평가를 통해 제안하는 방법에 따른 검출 성능을 평가 및 분석한다. FDDB(Face Detection Dataset & Benchmark) 데이터 셋의 실험 결과에서 제안하 는 방법이 효과가 있음을 증명했다.
▸주제어: 얼굴 검출, 앵커 프리 방법, 다중 크기 검출, 딥 러닝, 특징 피라미드 학습
∙First Author: Dong-Ryeol Lee, Corresponding Author: Yoon Kim
*Dong-Ryeol Lee ([email protected]), School of Computer Science and Engineering, Kangwon National University *Yoon Kim ([email protected]), Dept. of Computer Science and Engineering, Kangwon National University
∙Received: 2020. 06. 11, Revised: 2020. 07. 02, Accepted: 2020. 07. 03.
Copyright ⓒ 2020 The Korea Society of Computer and Information http://www.ksci.re.kr pISSN:1598-849X | eISSN:2383-9945