머신러닝 기법의 산림 총일차생산성 예측 모델 비교
이보라
1
, 장근창1
, 김은숙1*
, 강민석2
, 천정화3
, 임종환1
1)1
국립산림과학원 기후변화생태연구과,2
국가농림기상센터,3
국립산림과학원 연구기획과 (2019년 3월 8일 접수; 2019년 3월 25일 수정; 2019년 3월 27일 수락)Predicting Forest Gross Primary Production Using Machine Learning Algorithms
Bora Lee 1 , Keunchang Jang 1 , Eunsook Kim 1* , Minseok Kang 2 Jung-Hwa Chun 2 and Jong-Hwan Lim 1
1 Forest Ecology & Climate Change Division, National Institute of Forest Science, Seoul, Republic of Korea
2 National Center for AgroMeteorology, Seoul, Republic of Korea
3 Research Planning and Coordination, National Institute of Forest Science, Seoul, Republic of Korea
(Received March 8, 2019; Revised March 25, 2019; Accepted March 27, 2019)ABSTRACT
Terrestrial Gross Primary Production (GPP) is the largest global carbon flux, and forest ecosystems are important because of the ability to store much more significant amounts of carbon than other terrestrial ecosystems. There have been several attempts to estimate GPP using mechanism-based models. However, mechanism-based models including biological, chemical, and physical processes are limited due to a lack of flexibility in predicting non-stationary ecological processes, which are caused by a local and global change. Instead mechanism-free methods are strongly recommended to estimate nonlinear dynamics that occur in nature like GPP. Therefore, we used the mechanism-free machine learning techniques to estimate the daily GPP. In this study, support vector machine (SVM), random forest (RF) and artificial neural network (ANN) were used and compared with the traditional multiple linear regression model (LM). MODIS products and meteorological parameters from eddy covariance data were employed to train the machine learning and LM models from 2006 to 2013. GPP prediction models were compared with daily GPP from eddy covariance measurement in a deciduous forest in South Korea in 2014 and 2015. Statistical analysis including correlation coefficient (R), root mean square error (RMSE) and mean squared error (MSE) were used to evaluate the performance of models. In general, the models from machine-learning algorithms (R = 0.85 – 0.93, MSE = 1.00 – 2.05, p < 0.001) showed better performance than linear regression model (R = 0.82 – 0.92, MSE = 1.24 – 2.45, p < 0.001).
These results provide insight into high predictability and the possibility of expansion through the use of the mechanism-free machine-learning models and remote sensing for predicting non-stationary ecological processes such as seasonal GPP.
Key words: Machine learning, Gross primary production, MODIS, GPP modeling, Eddy covariance, KoFlux
* Corresponding Author : Eunsook Kim ([email protected])
DOI: 10.5532/KJAFM.2019.21.1.29
ⓒ Author(s) 2019. CC Attribution 3.0 License.
I. 서 론
산림생태계에서 총일차생산성(Gross Primary Production, GPP)은 식물의 광합성으로 발생하는 탄소의 총량으 로 기후변화에 따른 산림의 생산성과 그에 영향을 미 치는 식물계절, 건강성, 탄소 순환 등을 대표하는 지표 이다(Running et al., 1999; Smith et al., 2010). 생태계 총일차생산성은 전지구적 탄소 순환에서 가장 큰 부분 을 차지하며 특히 산림생태계에서의 탄소 저장 능력은 다른 생태계보다 높아 그 중요성이 더욱 강조된다(Beer
et al., 2010, Gray and Whittier, 2014). 총일차생산성은
생태계호흡(ecosystem respiration, R)과 순생태계교환 량(net ecosystem exchange, NEE)으로 구성되며 산림 총일차생산성의 측정 및 예측을 위해서는 에디공분산 플럭스 타워 관측, 인공위성정보, 모델링 등의 방법이 사용되고 있다. 에디공분산 기술은 대기의 연직 난류 수송을 직접 관측하는 방식으로 순생태계교환량 (NEE) 등을 정량적으로 측정하여 산림과 같은 복잡지 형의 총일차생산성을 계산 가능하게 한다(Kang et al., 2014). 에디공분산 플럭스 타워 자료들은 위성정보나 기작기반 탄소 예측 모델링의 검증 자료로 사용되고 있으며 전세계적으로 500개 이상의 플럭스 관측 사이 트가 운영되고 있다(Baldocchi et al., 2001). 그러나 플럭스 관측 타워의 측정 범위는 최대 1,000 m 내외로 여전히 넓은 지역이나 접근성이 낮은 지역에서의 측정 은 어렵다. 이를 극복하기 위한 방법으로 인공위성정 보를 이용하거나 기작기반모델링을 활용한다. 인공위 성 관측자료에서도 총일차생산성을 계산하여 제공하 기는 하나 그 자료의 신뢰성이 낮아 지역적 활용을 위해서는 지역 특성에 맞는 보정과정이 필요하다 (Reeves et al., 2005). 기작기반 모델은 지형 및 기후 영향을 반영한 산림 총일차생산성을 예측하기 위해서 주로 사용되었다. 그러나, 총일차생산성을 포함한 산 림 탄소 순환의 기작기반 모델링은 식물의 생물, 생리, 화학적 기작들의 반응과 결과 그리고 지형, 기후 및 시간 등과 같은 환경 조건들, 갑작스러운 기상이변 영 향 등이 복잡하게 얽혀 있어 선형적이지 않은 다양한 조건들을 모두 적용하기가 어렵다(Schindler et al., 2015; Ye et al., 2015).산림 총일차생산성은 계절적 특성을 가진 시계열 자료로 산림 총일차생산성을 추정하는 일은 식생의 광 합성량에 영향을 미치는 미기상학적 요인들이 지형이 나 지역별로 상이하고 기후변화로 인한 기상 이변이
발생하는 등 비선형적인 기작들이 복잡하게 얽혀 있다. 이러한 비선형적 관계들을 추정하는 방법으로 기작-프 리(mechanism-free) 머신러닝(machine learning) 즉, 기계학습 알고리즘이 많이 제안되고 있다(Schindler et
al., 2015; Ye et al., 2015; Dou et al., 2018). 기계학습
의 개념은 1950년대에 앨런 튜닝의 Turing test를 바탕 으로 시작되었고 컴퓨터 성능의 발전과 빅데이터가 축 적되면서 2000년 전후로 급속도로 발전하였다. 산림 분야를 포함하는 생태학과 같은 분야에서도 기계학습 알고리즘을 생태학적 현상 분석에 적용하는 사례들이 많아지고 있다. 특정 수목의 최적지 예측(Garson etal., 2006), 종분포 및 확장(Stockwell and Peterson,
2002; Elith and Leathwick, 2009), 수목 정보와 지형 정보를 활용한 산사태 지역 예측(Oh, 2010), 서식지 탐색(Kim et al., 2010) 등과 같이 목표물을 찾거나 지형을 분석하고 분류하는 공간적인 분석에 주로 활용 되고 있다. 이러한 기계학습 알고리즘 기법을 공간적 인 정보뿐만 아니라 주변 환경(지형이나 기후 등)의 영향과 비선형적 기작들이 얽힌 산림 시계열 자료 예 측에도 사용 가능할 것인가는 산림생태분야의 지속적 인 관심사이다. 최근 Tramontana et al.(2015), Ichiiet al.(2017), Wang et al.(2017), Dou et al.(2018)이
에디공분산 관측자료와 인공위성 관측자료를 사용하 여 기계학습 알고리즘 기반으로 다양한 생태계에서 총 일차생산성을 예측해 보는 사례가 소개되었고 기계학 습 알고리즘의 성능에 대해서는 이미 그 활용 가능성 이 증명되었으나 국내 산림 유역에서는 아직 소개된 사례가 없다. 산림 분야에서 인공위성, 에디공분산 플 럭스 타워 네트워크 등으로부터의 빅데이터가 축적되 어가고 있어 복잡하고 비선형적 관계들로 이루어진 현 상들을 모두 고려하여 모사할 수 있는 예측력 높은 방법에 대한 요구가 점차 높아질 것으로 보인다.본 연구에서는 에디공분산 자료와 인공위성 자료, 기계학습 알고리즘이 가진 장점들을 활용하여 보다 신 뢰도 높은 산림총일차생산성 예측과 확장가능성을 검 증해 보고자 하였다. 즉, 에디공분산 자료가 가진 정확 도, 인공위성 자료의 높은 공간적 활용도, 기계학습 알고리즘의 비선형 관계 예측력을 종합적으로 활용하 여 향후 인공위성 자료를 기반으로 우리나라 전국 산 림의 총일차생산성 예측의 신뢰도를 높이는 방법을 제 안하고자 한다. 이에 따른 이 연구의 목적은 1) 에디공 분산 플럭스 타워에서 관측된 기상인자들로 기계학습 알고리즘 모델을 학습시켜 그 성능을 검증하고, 2) 에
디공분산 자료의 입력인자와 유사한 인공위성 자료와 에디공분산 자료에서는 제공하지 않는 추가적인 인자 도 포함한 인공위성 입력 자료로 같은 모델을 학습시 켜 그 결과를 에디공분산 자료로만 학습된 모델들과 비교해 보았다. 이를 통해 인공위성자료 기반의 기계 학습 알고리즘 모델의 정확도를 검증함으로써 공간적 한계를 극복하고 전국 산림으로 확대 및 적용할 수 있는 활용 가능성을 보고자 하였다.
이 연구에서는 산림 생태계 분야에서 주로 사용되는 기계학습 알고리즘인 support vector machine (SVM), random forest (RF) 및 기계학습의 하위 분야로 발달 한 계층학습법인 딥러닝 중 비교적 간단한 artificial neural network (ANN) 알고리즘으로 모델을 구축하 고 기계학습 알고리즘 모델들과의 비교를 위해 고전적 방법인 선형모델(multiple linear regression model, LM)의 결과를 제시하였다(Fig. 1). 본 연구에서는 또 한 산림 생태계에서 기계학습 알고리즘뿐만 아니라 나 아가 딥러닝 알고리즘도 적용하여 앞으로 지속적으로
축적되는 빅데이터를 적극 활용하고 응용할 수 있는 기반과 기초 방법을 소개하는 것에 추가적인 목적을 두었다.
II. 재료 및 방법
2.1. 대상지역 및 에디공분산 자료
본 연구는 경기도 포천시 소흘읍에 위치한 광릉 KoFlux 관측지(N37° 45’, E127° 9’)의 활엽수림에 설 치된 에디공분산 플럭스 타워(GDK, http://asiaflux.net/
index.php?page_id=57) 자료를 사용하였다. 플럭스 타워의 40m높이에 설치되어 있는 에디 공분산 시스템 은 3차원 초음파 풍향 풍속계(Model CSAT3, Campbell Scientific Inc., USA)와 고속반응 기체 분석기(Model LI-7500, LI-COR Inc., USA) 로 구성되어 있다. 3차 원 초음파 풍향풍속계와 고속반응 적외선 기체분석기 는 각각 온도와 세 방향 풍속, 이산화탄소 및 수증기 농도를 10Hz로 관측하며, 관측값은 자료집록기
Fig. 1. Schematic diagram showing data flow and analysis. Models were trained in
the testing period (2006 – 2013) by three different types of input data sets as follows, Type 1: air temperature (Tair
), relative humidity (RH), daily net radiation (Rd
), precipitation (PPT), and evapotranspiration (ET) from eddy flux measurement, Type 2: air temperature (T), daily shortwave radiation (Rsd
), and vapor pressure deficit (VPD) from MODIS, and Type 3: air temperature (T), daily shortwave radiation (Rsd
), and vapor pressure deficit (VPD), and EVI from MODIS. Gross Primary Production (GPP) calculated based on multiple linear regression model (LM), support vector machine (SVM), random forest (RF), and artificial neural network (ANN) and evaluated with eddy covariance GPP in 2014 and 2015.(Model CR3000, Campbell Scientific Inc.)에 10Hz 시 계열 자료뿐만 아니라 30분 평균 및 공분산 값이 저장 된다. 이와 함께 다른 미기상 변수들 (순복사, 온도, 습도, 토양 온도, 토양 수분)이 관측 및 저장되었다 (Kwon et al., 2007; Lee et al., 2017).
자료 품질을 향상시키기 위해 수집된 자료는 KoFlux표준화 자료처리 방법을 이용하여 처리되었다 (Hong et al., 2009; Kang et al., 2012, 2014 and 2018). KoFlux 표준화 자료처리 방법에는 좌표 회전, 공기 밀도 보정, 저류항 계산, 튀는 자료 제거, 결측 메우기, 야간 CO
2
플럭스 보정 및 배분이 포함되어있 다. 이 연구에서는 2006년부터 2015년까지의 플럭스 (총일차생산성) 및 미기상 자료(온도, 습도, 복사, 강수, 증발산)를 사용하였다.대상지역은 한반도의 대표적인 활엽수종들인 졸참나무(Quercus serrata), 서어나무(Carpinus
laxiflora), 까치박달(Carpinus cordata), 단당풍(Acer pseudosieboldiamum) 등으로 구성되어 있고 수령은
80-200년, 수고는∼18 m이다(Kang et al., 2018). 해 발고도는 90-530 m, 연평균 기온은 11.5°C, 연평균 강수량 1,332 mm이다(Lee et al., 2017).2.2. MODIS 입력자료 생산
이 연구에서 사용된 인공위성영상은 전구 규모의 육상, 대기 및 해양 환경 모니터링 목적으로 개발된 NASA의 극궤도 위성인 Terra와 Aqua 위성의 36개의 다중분광밴드로 이루어진 다중분광센서(Moderate Resolution Imaging Spectroradiometer, MODIS)의 영상이다.
MODIS07 대기프로파일자료(MYD07_L2)는 공간
해상도 5 km 이며 각각의 영상은 위도, 경도의 고유한 지리적 위치 정보와 기온 및 이슬점 온도 프로파일(K), 지표면 온도(K), 안정도지수(K), 대류권계면 높이 (hPa), 압력(hPa), 총 오존량(Dobson unit, DU), 수증 기량(cm) 등과 같은 다양한 기상자료를 함께 제공한 다. 각 항목의 산출 알고리즘은 MODIS Atmospheric Profile Retrieval Algorithm Theoretical Basis Document 를 참조하면 된다(Borbas et al., 2011). 기온 프로파일 은 Jang et al.(2014b)가 제안한 식에 따라 대기기온감 률방법을 적용하여 고도보정을 하고, 흐린 날도 포함 하는 연속적인 기온정보를 생산하기 위해 픽셀기반회 귀모형(pixel-wise regression model)을 활용하여 전천 후 기상자료를 생산하였다. 대기 수증기 관련 자료인 현재수증기압(VP)과 포화수증기압(SVP) 산출 방법은 Dingman(2008)에 의해 제안된 방법을 사용하였고 포 화수증기압과 현재수증기압 차로 수증기압 포차 (Vapor Pressure Deficit, VPD)를 계산하였다.
일 단위 일사량은 Bird and Hulstrom(1981)가 제안 한 simple clear sky model (the Bird Model)을 적용하 였다. 이 모델은 Houborg and Soegaard(2004), Ryu
et al.(2008)에 의해 검증된 방법으로 MODIS알베도
(MCD43) 자료를 사용하였다. 각각의 복사요소들의 자세한 산출 방법에 대해서는 Jang et al.(2009)에 제 시되어 있다.식생지수는 MODIS의 산출물 중 해상도 1 km
2
, 16 일 단위의 MOD13A2와 MYD13A2를 결합하여 8일 단위(DOY 1, 9, 17, 25, ...) 자료로 구성하였다. 기존 연구에서 우리나라 산림의 산림식물계절변화에는 개 량식생지수(Enhanced Vegetation Index, EVI)가 좀 더 적합하다는 Lee et al.(2018)의 결과에 따라 본 연구MODIS product Description Band Pixel size (m) Temporal
MCD43 BRDF/Albedo 1, 2, 3, 4, 5, 6, 7 500 Daily MYD11A1 Temperature, Emissivity 20, 22, 23, 29, 31, 32, 33 1000 Daily MYD & MOD13A2 Vegetation indices 1, 2, 3,7 1000 16-Day
Table 1. Summary of MODIS Land Products used in explanatory variables from 2006 to 2015
MODIS product Description Band Pixel size (m)
MYD04_L2 Aerosol 1, 2, 3, 4, 5, 6, 7, 20 10000
MYD06_L2 Clouds 29, 31, 32, 33, 34, 35, 36 5000
MYD07_L2 Temperature and Water Vapor Profiles 25, 27, 28, 29, 31, 32, 33, 34, 35, 36 5000
Table 2. Summary of MODIS Atmosphere Products used in explanatory variables from 2006 to 2015
에서도 개량식생지수를 사용하였다. 개량식생지수 의 일자료 생산을 위해 Lee et al.(2018)이 제안한 방법을 사용하였다. 이 연구에서 사용된 MODIS 자료의 정보 는 지상산출물과 대기산출물로 구분하여 Table 1과 Table 2에서 제시하였다.
2.3. 입력자료 선정
총일차생산성 추정 시 필요한 설명변수들은 MODIS 총일차생산성 알고리즘 식을 바탕으로 선택하였다. 위 성 기반의 총일차생산성 추정 알고리즘은 미국항공우 주국의 알고리즘을 바탕으로 아래의 식을 이용하여 추 정할 수 있다(Lee et al., 2011; Running and Zhao, 2015).
(Eq. 1)
여기서, 는 최대 빛이용효율(KgC m
-2
day-1
MJ-1
), 는 최저기온, VPD는 포화수증기압, FPAR 는 광합성유효복사량 흡수 비율(%), Rs
는 일사량(MJ Day-1
)을 의미한다. 광합성유효복사량(photosynthetically active radiation, PAR)은 일사량에 계수 0.45를 곱하 여 산출하는데 여기서 계수 0.45는 지구평균 수치이 며, 일사량과 PAR 간의 관계를 통해 산출되었다. 광합 성유효복사량 흡수량(absorbed photosynthetically active radiation, APAR)은 PAR에 광합성유효복사량 흡수 비율(FPAR)를 곱하여 산출하였다. 최대 빛이용 효율 는 식생형에 따른 생물리특성 색인표(Biome Property Look-Up Table, BPLUT)를 따랐다(Runninget al., 2000; White et al., 2000).
Eq. 1의 설명변수 중 VPD의 경우에는 최저 온도와 상대습도의 영향을 받으므로 에디공분산 관측자료에 서는 상대습도와 온도로 설명 가능하다. Eq. 1에 의하 면 MODIS 총일차생산성은 FPAR 즉 광합성유효복사 량 흡수비율을 사용하여 광합성에 사용되는 태양복사 량을 결정하는데 이 변수는 개량식생지수로 대체 될 수 있다. 에디공분산 자료 중에는 개량식생지수의 역 할을 동일하게 해 줄 수 있는 변수는 없지만 식생지수 가 온도, 복사, 엽면적 등과 함께 증발산을 계산하는 항목으로 사용되므로 증발산을 설명변수 중의 하나로 선택하였다. 그래서 MODIS 입력자료를 사용한 경우 에는 에디공분산 측정자료(에디공분산 입력자료 모델) 와 특성이 같거나 대체 가능한 항목들을 설명변수로 선택한 모델(MODIS 개량식생지수제외 모델)과 에디
공분산 측정자료의 항목과는 다르나 MODIS 는 총일 차생산성을 계산할 때 반드시 필요한 개량식생지수를 추가한 모델(MODIS 개량식생지수 포함 모델)을 모두 구축하여 비교해 보았다.
2.4. 기계학습 알고리즘 모델
산림 총일차생산성 추정 모델은 1) 에디공분산 관 측 기온(T
air
), 태양복사(Rd
), 상대습도(RH), 강수(PPT), 증발산(ET) 자료, 2) MODIS 관측 기온(T), 일사량 (Rsd
), VPD 자료(개량식생지수 제외), 3) MODIS 관측 기온(T), 일사량(Rsd
), VPD, 개량식생지수 자료를 사 용하는 세 가지 경우로 나누어 구축하였다.모델 구축에서 사용된 기계학습 알고리즘은 생태 연구에 많이 이용되는 support vector machine (SVM), random forest (RF), artificial neural network (ANN) 과 기계학습 알고리즘 모델과 단순 비교를 위해 고전 적 방법인 선형모델 multiple linear regression model (LM)을 함께 제시하였다. 선형모델은 일반적으로 잘 알려져 있으므로 제외 하였고 기계학습 알고리즘에 대 한 설명을 아래에 추가 하였다.
2.4.1. Support Vector Machine (SVM)
Support Vector Machine (SVM)은 사례기반 최근 접이웃 학습 방법과 단순회귀식 모델의 조합으로, 복 잡한 수준의 관계도 모사가 가능한 알고리즘으로 다차 원에 그려진 자료들 간의 경계를 구분 짓는 평면을 그린다고 가정 할 수 있다. 이 때 자료들 간의 경계는 설명 가능한 특징을 가지는 그룹으로 구분되고 최적화 된 분류기준을 가진 이 평면을 초평면(hyperplane)이 라고 부른다. 초평면이라고 하는 이 경계는 데이터 간 의 마진(margin)이 가장 큰 기준선을 선택하도록 하여 최적화된 분류 기준으로 자료들을 그룹화한다. 여기서 서포트벡터(support vectors)라는 초평면에 가장 가까 운 데이터가 최대 마진을 설명하는 포인트 데이터가 된 다. 결국 SVM 의 목표는 서포트벡터(support vectors) 의 최대 마진을 구하는 것이다. 특히, 비선형의 관계를 가지는 여러 개의 비선형 독립 변수들을 적절하게 트 레이닝 하기 위해 비선형 독립 변수들을 고차원의 공 간에 배치하여 선형관계로 변환하기 위해 커널 기능 (kernel function)을 사용하는데 선형커널, 다항식커널, 시그모이드커널, 가우시안커널 등 자료와 목적에 맞는 커널을 선택할 수 있다. 이 연구에서는 기본 커널인 radial basis 커널을 사용하였다. 알고리즘에 대한 자세
한 내용은 Cortes and Vapnik(1995)와 Smola and Schölkopf(2002)를 참조한다. 연구를 위해 사용된 프 로그램은 R (version 3.3.3), 패키지는 “e1071”이다 (Dimitriadou et al., 2008).
2.4.2. Random Forest (RF)
Random Forest (RF) 모델은 다수의 의사결정 트리 를 생성하여 만들어진 트리의 결과들을 모아 다수결에 따라 최종결과를 선택하는 일종의 앙상블(ensemble)학 습 기법이다. Breiman(1996 and 2001)의 논문에서 제 시한 배깅(bagging)과 임의노드 최적화를 결합하여 상 관관계가 없는 트리들로 구성된 포레스트가 이 기법의 개념이다. 배깅은 학습 자료에서 부트스트랩 샘플링 (bootstrap sampling)을 사용하여 무작위로 선정한 데 이터셋(서브셋)을 구성하고 이 무작위로 선정된 데이 터셋을 같은 알고리즘에 적용한다. 최종 모델의 예측은 반복된 데이터셋에서 훈련된 결과를 회귀(regression) 문제인지, 분류(classification) 문제인지에 따라 평균이 나 다수결로 결정된다(Lantz, 2013). 랜덤포레스트는 원자료의 2/3만 배깅을 하고 나머지 1/3은 out-of-bag (OOB)이라 하여 배깅한 데이터셋에서 훈련되고 결정 된 모델을 테스트하는데 사용된다. 때문에 극단적인 자 료값을 가진 데이터셋에서도 가장 중요한 속성만 선택 하고 튀는 자료들과 결측 자료가 있어서도 적용이 가능 하며 과적합을 피한다. 이 연구에서 사용된 랜덤포레스 트 알고리즘은 R (version 3.3.3) 프로그램에서 패키지
“randomForest”이다(Liaw and Wiener, 2002).
2.4.3. Artificial Neural Network (ANN) Artificial Neural Network (ANN) 모델은 인간 뇌 의 뇌세포들(neurons)의 네트워크가 스스로 학습하며 작동하는 원리를 모방하여 만들어진 모델로 인공뇌세 포(artificial neuron) 즉 노드(node)들로 이루어진 네트 워크를 이용한다고 할 수 있다. 신호가 뉴런의 가지돌 기(dendrites)를 통해 들어오고 신호의 중요도나 반복 도에 따라 가중치(weight)가 매겨져 임계치(threshold) 를 넘게 되면 전기적 작용에 따라 신호가 이웃한 뉴런 에 전달된다. ANN모델에서는 가중치는 입력신호마 다 적용되며 활성화 함수의 임계값에 따라 처리되어 출력된다. 활성화함수로 가장 많이 사용되는 것은 시 그모이드 함수(sigmoid function)가 있고 선형(linear), 하이퍼볼릭 탄젠트(Hyperbolic Tangent), 가우시안 (Gaussian) 함수 등 다양하게 선택 가능하다. ANN모
델의 학습능력은 층(layer)이 몇 개인지, 층마다 노드 가 몇 개인지, 역전파(back-propagation)방법을 사용 하는지 등의 여부에 따라 결정된다. 층은 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)로 구분하고 여기서 은닉층은 실제 정보를 처리하는 부분 이다(Vidal et al., 2017). 은닉층에서 계산된 값과 출 력자료 사이에 오차가 존재하면 가중치와 은닉층 값을 역으로 수정하는 알고리즘(backpropagation)이 존재 한다(Recknagel, 2001). 알고리즘 수행을 위해 프로그 램은 R (version 3.3.3), 패키지는 “neuralnet”을 사용 하였다(Fritsch et al., 2019).
III. 결 과
3.1. 에디공분산 관측자료 기반 총일차생산성
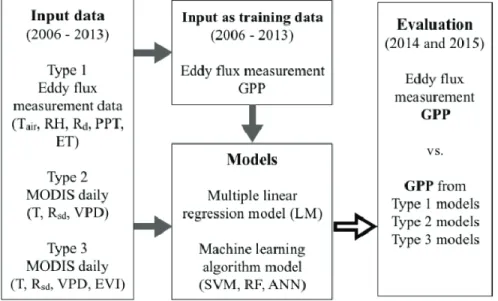
추정 모델에디공분산 관측자료의 기상인자들을 사용한 추정 모델은 선형회귀식을 사용한 선형모델(LM), 세 가지 기계학습 알고리즘(SVM, RF, ANN)으로 학습시키고, 학습된 모델로 총일차생산성을 추정하였다. 모든 모델 들을 2006년부터 2013년까지의 자료로 학습시켜 예 측 능력을 향상시켰다. 이렇게 구축된 모델로 2014년 과 2015년의 총일차생산성을 예측해 본 결과, 이른 봄 에는 총일차생산성이 천천히 증가하다가 개엽이 시작 되면서 급격하게 증가하는 지수적 경향을 기계학습 기 반의 모델들이 비교적 정확히 모사하는 결과를 보였다 (Fig. 2). 관측된 총일차생산성과 모델의 총일차생산성 을 비교한 결과를 보면, LM모델의 경우 식생 생장이 시작되는 봄철(Fig. 2, red circles)에 총일차생산성의 값이 선형적으로 증가하여 관측된 총일차생산성이 지 수적으로 증가하는 경향을 잘 모사하지 못하는 것을 볼 수 있다. LM모델은 2014년과 2015년 모두 식생 최고 성장시점에서 과소평가하는 경향을 보였고 SVM, RF, ANN알고리즘 모델들은 2014년에는 최고 성장시점에서 과소평가하는 경향을 보이나 2015년은 전반적으로 관측치와 큰 차이를 보이지 않았다. Fig.
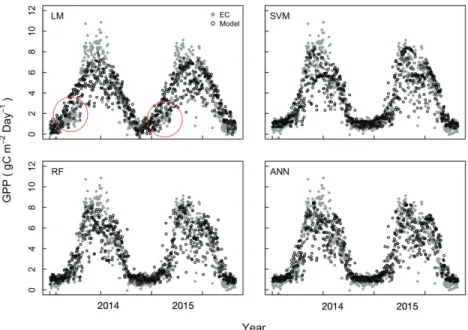
3에서 SVM, RF, ANN 알고리즘 모델들은 LM 모델 보다 회귀선에 집중되는 패턴을 보여 LM 모델 보다 상대적으로 높은 예측력을 보였다. SVM, RF, ANN 알 고리즘 모델들은 상관계수 0.91 - 0.92, RMSE 1.11 - 1.14, MSE 1.24 - 1.30 사이로 비슷한 결과를 보이는 데 그 중 RF 모델이 매우 근소한 차이로 더 나은 성능 을 보였다(Table 3).
Fig. 3. Comparisons of Eddy Covariance (EC)
measurement GPP and modeled GPP from the trained models by EC measurement datasets in 2014 and 2015. LM = linear regression model, SVM = Support Vector Machine, RF = Random Forest, ANN = Artificial Neural Network.3.2. MODIS daily 자료 기반 총일차생산성 추정
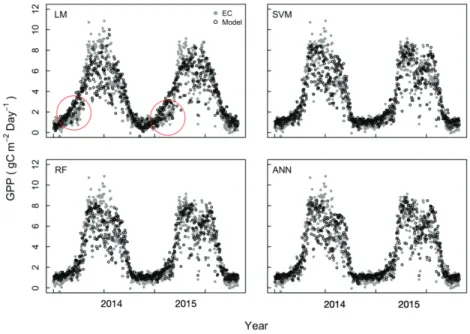
모델MODIS 일단위 자료로 모델을 구축함에 있어서 두 가지 다른 입력 자료세트를 사용하였다. 먼저 개량식 생지수(EVI)가 설명변수로 포함되지 않는 모델과 개 량식생지수를 설명변수로 포함하는 모델이다. 개량식 생지수가 설명변수로 포함되지 않은 LM, SVM, RF, ANN모델들은 상관계수 0.82 - 0.86, RMSE 1.41 - 1.57, MSE 1.99 - 2.45로 에디공분산 측정자료 사용 모델, MODIS 자료 사용 모델들 중에서 성능이 가장 낮게 나왔다(Table 3). 전반적으로 모델들은 최고 성장 시점에서 과소평가하는 경향을 보였고, LM 모델의 경 우 식생 개엽이 시작되는 시기와 낙엽이 시작되어 총 일차생산성이 급격히 증가하거나 감소하는 경향을 잘 모사하지 못하였다(Fig. 4, red circles). 기계학습 알고 리즘 기반 모델 중에서는 SVM 모델이 가장 좋은 결과 를 보였고 모든 모델들에서 나타나는 성장 시즌 중반 의 과소평가도 다른 모델들 보다 비교적 적게 나타나 는 경향을 보였다. RF모델과 ANN모델은 매우 근소한 차이이나 ANN이 더 유의성 높은 결과를 보였다. Fig.
5의 관측된 총일차생산성과 모델의 총일차생산성을 비교한 결과를 보면, LM모델의 경우 총일차생산성의
Fig. 2. Daily GPP prediction obtained with linear regression model (LM), Support
Vector Machine (SVM), Random Forest (RF), and Artificial Neural Network (ANN) (black opened circle) and GPP obtained eddy covariance (EC) measurement (gray closed circle) using EC measurement datasets in 2014 and 2015.
값이 낮은 지점에서 모델의 예측력이 감소하는 것을 알 수 있다. SVM, RF, ANN 알고리즘 모델들은 총일 차생산성 측정값이 높은 지점에서 값들이 흩어지지만 LM 모델 보다 회귀선에 집중되는 경향을 보여 LM 모델 보다 예측력이 높다고 판단된다.
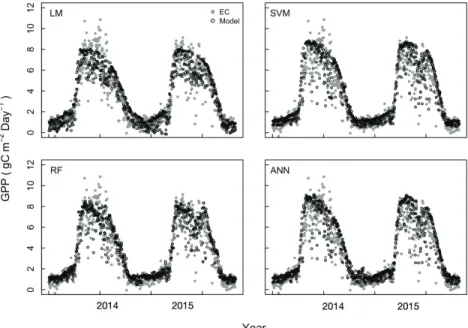
개량식생지수를 설명변수로 포함한 모델들의 경우, 세 가지 입력자료 유형의 모델들 중에서 가장 좋은 결 과를 보여주었다(Fig. 6 and Fig. 7). 상관계수 0.92 - 0.93으로 에디공분산 타워에서 관측된 GPP과 통계적 으로 매우 높은 상관성을 보였는데 선형회귀모델인 LM모델보다 기계학습 알고리즘의 모델들이 근소하 지만 더 높은 상관성을 보였다. 식생 생장 기간 중 여 름 동안 발생하는 며칠의 갑작스러운 증가나 감소를 제외하고 대부분의 포인트들이 회귀선에 모여있는 결 과를 보였다.
개량식생지수를 포함한 입력자료를 사용한 경우에 는 에디공분산 플럭스타워의 관측 기상자료로 훈련시 킨 모델들과 비슷하거나 오히려 더 높은 상관성을 보 였다. 식생지수는 반사도를 이용해 식물의 엽록소의 양을 반영하는 지표로 식생의 식물계절변화를 감지하
Fig. 4. Daily GPP prediction obtained with linear regression model (LM), Support
Vector Machine (SVM), Random Forest (RF), and Artificial Neural Network (ANN) (black opened circle) and GPP obtained eddy covariance (EC) measurement (gray closed circle) using MODIS datasets (without Enhanced Vegetation Index, EVI) in 2014 and 2015.
Fig. 5. Comparisons of Eddy Covariance (EC)
measurement GPP and modeled GPP from the trained models by MODIS datasets (without Enhanced Vegetation Index, EVI) in 2014 and 2015.LM = linear regression model, SVM = Support Vector Machine, RF = Random Forest, ANN = Artificial Neural Network.
고 특히 개량식생지수는 산림지역에서 더 유용한 것으 로 알려져 있다(Lee et al., 2018). Sims et al.(2006)의 결과에 따르면 산림에서는 개량식생지수와 총일차생 산성의 상관관계가 높다고 하였다. 개량식생지수를 포 함한 입력자료로 훈련된 모델의 예측 결과에서도 이러 한 상관관계가 반영되어 생장 시즌이 시작되는 시점에 서 개량식생지수가 제외된 입력자료나 에디공분산 입 력자료로 훈련된 모델의 예측력보다 향상된 결과를 보 이는 것으로 판단된다(Fig. 6).
IV. 결 론
이 연구에서는 인공위성 자료 기반의 기계학습 알 고리즘 모델의 산림 총일차생산성 추정의 예측 정확도 를 평가하기 위해 2006년부터 2015년까지의 광릉 활 엽수림의 에디공분산 플럭스 타워 기상자료와 MODIS 인공위성자료에서 산출된 기상자료로 SVM, RF, ANN알고리즘 모델을 구축하였다. 기계학습 알고리 즘 모델과의 단순 비교를 위해 고전적 방법인 선형회 귀식을 사용한 모델 LM을 같은 방법으로 구축하여 비교하였다. 모델은 에디공분산 입력자료, MODIS입
Fig. 6. Daily GPP prediction obtained with linear regression model (LM), Support
Vector Machine (SVM), Random Forest (RF), and Artificial Neural Network (ANN) (black opened circle) and GPP obtained eddy covariance (EC) measurement (gray closed circle) using MODIS datasets (with EVI) in 2014 and 2015.
Fig. 7. Comparisons of Eddy Covariance (EC)
measurement GPP and modeled GPP from the trained models by MODIS datasets (with EVI) in 2014 and 2015. LM = linear regression model, SVM = Support Vector Machine, RF = Random Forest, ANN = Artificial Neural Network.력자료로 나누어 구축하였고 MODIS입력자료는 에디 공분산과 유사한 인자들로 구성된 입력자료와 개량식 생지수를 포함한 입력자료로 다시 나누어 적용하였다. 세 가지 유형의 다른 입력자료를 사용한 모든 경우에 선형회귀모델(LM)보다 기계학습 알고리즘 기법을 적 용한 모델들의 결과가 신뢰수준 99% 내에서 더 높은 유의성을 보였다(Table 3). SVM, RF, ANN 알고리즘 모델 중에서는 에디공분산 입력자료만 사용한 경우에 는 RF 알고리즘 모델, 개량식생지수를 제외한 MODIS 입력자료를 사용한 경우 SVM알고리즘 모델이 근소 한 차이로 더 좋은 예측력을 보였으나 통계결과의 차 이는 매우 적다. 개량식생지수를 포함한 MODIS 입력 자료를 사용하였을 때는 상관계수(R)는 모두 0.93으 로 같았고 RMSE 1.09 – 1.10, MSE 1.00 – 1.21로 모델간에는 거의 차이가 나지 않았다.
기존의 연구 결과에 따르면 산림에서는 개량식생지 수가 총일차생산성과의 상관관계가 높고(Sims et al., 2006), 개량식생지수는 산림의 총일차생산성을 결정 하는 산림식물계절과 높은 상관성을 보인다(Lee et
al., 2018). 따라서, 개량식생지수를 포함한 입력자료
로 훈련된 모델의 예측 결과에서도 이러한 상관관계가 반영되어 성장 시즌이 시작되는 시점에서 개량식생지 수가 제외된 입력자료나 에디공분산 입력자료로 훈련 된 모델의 예측력보다 산림 총일차생산성을 더 잘 모 사하는 것으로 판단된다. 이러한 결과는 산림 총일차 생산성과 같이 시계열 특징을 가진 자료와 주변 환경 과 기후의 영향을 받는 다이나믹한 결과를 예측하는 모델을 구축하는 일에 MODIS 와 같은 인공위성 자료 와 기계학습 알고리즘이 충분히 사용될 수 있으며 그 예측력 또한 신뢰할 만한 수준임을 입증하였다. 향후, 보다 넓은 지역에서 다양한 수종을 가진 산림에 적용 가능한지를 더 정밀히 살펴보고 우리나라와 같은 복잡 지형에서 지역적 차이를 같은 알고리즘을 적용하여 예측이 가능한지 등 적극적인 활용을 고려해 보아야 할 것이다.
적 요
산림생태계에서 총일차생산성(Gross Primary Production, GPP)은 기후변화에 따른 산림의 생산성 과 그에 영향을 미치는 식물계절, 건강성, 탄소 순환 등을 대표하는 지표이다. 총일차생산성을 추정하기 위 해서는 에디공분산 타워 자료나 위성영상관측자료를 이용하기도 하고 물리지형적 한계나 기후변화 등을 고 려하기 위해 기작기반모델링을 활용하기도 한다. 그러 나 총일차생산성을 포함한 산림 탄소 순환의 기작기반 모델링은 식물의 생물, 생리, 화학적 기작들의 반응과 지형, 기후 및 시간 등과 같은 환경 조건들이 복잡하게 얽혀 있어 비선형적이고 유연성이 떨어져 반응에 영향 을 주는 조건들을 모두 적용하기가 어렵다. 본 연구에 서는 산림 생산성 추정 모델을 에디공분산 자료와 인 공위성영상 정보를 사용하여 기계학습 알고리즘을 사 용한 모델들로 구축해 보고 그 사용 및 확장 가능성을 검토해 보고자 하였다. 설명변수들로는 에디공분산자 료와 인공위성자료에서 나온 대기기상인자들을 사용 하였고 검증자료로 에디공분산 타워에서 관측된 총일 차생산성을 사용하였다. 산림생산성 추정 모델은 1) 에디공분산 관측 기온(T
air
), 태양복사(Rd
), 상대습도 (RH), 강수(PPT), 증발산(ET) 자료, 2) MODIS 관측 기온(T), 일사량(Rsd
), VPD 자료(개량식생지수 제외), 3) MODIS 관측 기온(T), 일사량(Rsd
), VPD, 개량식생 지수(EVI) 자료를 사용하는 세 가지 경우로 나누어 구축하여 2006 – 2013년 자료로 훈련시키고 2014, 2015년 자료로 검증하였다. 기계학습 알고리즘은 support vector machine (SVM), random forest (RF), artificial neural network (ANN)를 사용하였고 단순 Eddy covariance method MODIS (no EVI) MODIS (including EVI) Model R RMSE STD MSE R RMSE STD MSE R RMSE STD MSELM 0.89 1.27 2.25 1.62 0.82 1.57 2.02 2.45 0.92 1.11 2.58 1.24 SVM 0.91 1.13 2.51 1.27 0.86 1.41 2.25 1.99 0.93 1.09 2.84 1.18 RF 0.92 1.11 2.44 1.24 0.85 1.43 2.33 2.05 0.93 1.00 2.62 1.00 ANN 0.91 1.14 2.54 1.30 0.85 1.43 2.31 2.05 0.93 1.10 2.87 1.21
Table 3. Table Summary of statistics for the different algorithms based on the three different input sets. R,
RMSE, STD and MSE denote correlation coefficient, root mean square error, standard deviation and mean squared error, respectively비교를 위해 고전적 방법인 multiple linear regression model (LM)을 사용하였다. 그 결과, 에디공분산 입력 자료로 훈련시킨 모델의 예측력은 피어슨 상관계수 0.89 – 0.92 (MSE = 1.24 – 1.62), MODIS 입력자료로 훈련시킨 모델의 예측력은 개량식생지수 제외된 모델 은 0.82 – 0.86 (MSE = 1.99 – 2.45), 개량식생지수가 포함된 모델은 0.92 – 0.93(MSE = 1.00 – 1.24)을 보였 다. 이러한 결과는 산림총일차생산성 추정 모델 구축 에 있어 MODIS인공위성 영상 정보 기반으로 기계학 습 알고리즘을 사용하는 것에 대한 높은 활용가능성을 보여주었다.
REFERENCES
Baldocchi, D., E. Falge, L. Gu, R. Olson, D.
Hollinger, S. Running, P. Anthoni, C. Bernhofer, K. Davis, R. Evans, J. Fuentes, A. Goldstein, G.
Katul, B. Law, X. Lee, Y. Malhi, T. Meyers, W.
Munger, W. Oechel, K. T. Paw U, K. Pilegaard, H. P. Schmid, R. Valentini, S. Verma, T. Vesala, K. Wilson, and S. Wofsy, 2001: FLUXNET: a new tool to study the temporal and spatial variability of ecosystem-scale carbon dioxide, water vapor, and energy flux densities. American
Meteorological Society 82(11), 2415-2434.
Beck, P. S. A., C. Atzberger, K. A. Høgda, B.
Johansen, and A. K. Skidmore, 2006: Improved monitoring of vegetation dynamics at very high latitudes: A new method using MODIS NDVI.
Remote Sensing of Environment 100(3), 321–334.
Beer, C., M. Reichstein, E. Tomelleri, P. Ciais, M.
Jung, N. Carvalhais, C. Rödenbeck, M. A. Arain, D. Baldocchi, G. B. Bonan, and A. Bondeau, 2010: Terrestrial gross carbon dioxide uptake:
global distribution and covariation with climate.
Science 329(5993), 834-838.
Bird, R. E., and R. L. Hulstrom, 1981: Simplified
clear sky model for direct and diffuse insolation on horizontal surfaces (No. SERI/TR-642-761). Solar
Energy Research Institute, Golden, CO (USA).Borbas, E. E., S. W. Seemann, A. Kern, L. Moy, J.
Li, L. Gumley, and W. P. Menzel, 2011: MODIS atmospheric profile retrieval algorithm theoretical basis document. technical report, gfsc. nasa.
Breiman, L., 1996: Bagging predictors. Machine
learning 24(2), 123-140.
Breiman, L., 2001: Random Forests. Machine
Learning 45(1), 5–32.
Cortes, C., and V. Vapnik, 1995: Support-Vector Networks. Machine Learning 20(3), 273–297.
Dimitriadou, E., K. Hornik, F. Leisch, D. Meyer, and A. Weingessel, 2008: Misc functions of the Department of Statistics (e1071), TU Wien. R
package 1, 5-24.
Dingman, S. L., 2008: Physical hydrology. Second Edition ed. Long Grove, Illinois, USA: Waveland Press, 636pp.
Dou, X., Y. Yang, and J. Luo, 2018: Estimating forest carbon fluxes using machine learning techniques based on eddy covariance measurements.
Sustainability 10, 203pp.
Fritsch, S., F. Guenther, and M. F. Guenther, 2019:
Package ‘neuralnet’. Training of Neural Networks.
Gray, A. N., and T. R. Whittier, 2014: Carbon stocks and changes on Pacific Northwest national forests and the role of disturbance, management, and growth. Forest ecology and management 328, 167-178.
Houborg, R. M., and H. Soegaard, 2004: Regional simulation of ecosystem CO
2
and water vapor exchange for agricultural land using NOAA AVHRR and Terra MODIS satellite data. Application to Zealand, Denmark. Remote Sensing of Environment93(1-2), 150-167.
Ichii, K., M. Ueyama, M. Kondo, N. Saigusa, J.
Kim, M. C. Alberto, J. Ardö, J., E.S. Euskirchen, M. Kang, T. Hirano, and J. Joiner, 2017: New data‐driven estimation of terrestrial CO
2
fluxes in Asia using a standardized database of eddy covariance measurements, remote sensing data, and support vector regression. Journal of GeophysicalResearch: Biogeosciences 122(4), 767-795.
Jang, K., S. Kang, and S. Y. Hong, 2014: Comparisons of Collection 5 and 6 Aqua MODIS07_L2 air and dew temperature products with ground-based observation dataset. Korean Journal of Remote
Sensing 30(5), 571-586.
Jang, K., S. Kang, J. S. Kimball, and S. Y. Hong, 2014b: Retrievals of all-weather daily air temperature using MODIS and AMSR-E data. Remote Sensing
6(9), 8387-8404.
Jang, K., M. Won, and S. Yoon, 2017: Evaluation of the satellite-based air temperature for all sky conditions using the Automated Mountain Meteorology Station (AMOS) records: Gangwon Province case study. Korean Journal of Agricultural
and Forest Meteorology 19(1), 19-26.
Kang, M., H. Kwon, J.-H. Cheon, and J. Kim, 2012:
On estimating wet canopy evaporation from
deciduous and coniferous forests in the Asian monsoon climate. Journal of Hydrometeorology 13(3), 950-965.
Kang, M., J. Kim, H.-S. Kim, B. M. Thakuri, and J.-H. Chun, 2014: On the nighttime correction of CO2 flux measured by eddy covariance over temperate forests in complex terrain. Korean
Journal of Agricultural and Forest Meteorology 16(3), 233-245.
Kang, M., J. Kim, B. M. Thakuri, J. Chun, and C.
Cho, 2018: New gap-filling and partitioning technique for H2O eddy fluxes measured over forests. Biogeosciences 15(2), 631–647.
Kim, N. S., D. Han, J. Y. Cha, Y. S. Park, H. J.
Cho, H. J. Kwon, Y.-C. Cho, S.-H. Oh, and C.
S. Lee, 2015: A detection of novel habitats of
Abies koreana by using species distribution
models (SDMs) and its application for plant conservation. Journal of the Korea Society ofEnvironmental Restoration Technology 18(6),
135-149.Kwon, H., S. Park, M. Kang, J. Yoo, R. Yuan, and J. Kim, 2007: Quality control and assurance of eddy covariance data at the two KoFlux sites.
Korean Journal of Agricultural and Forest Meteorology 9(4), 260-267.
Lantz, B., 2013: Machine learning with R. Packt Publishing Ltd., 125-135.
Lee, J. H., S. Kang, K. C. Jang, J. H. Ko, and S.
Y. Hong, 2011: The evaluation of meteorological inputs retrieved from MODIS for estimation of gross primary productivity in the US corn belt region. Korean Journal of Remote Sensing 27(4), 481-494.
Lee, B., W. Kang, C.-K. Kim, G. Kim, and C.-H.
Lee, 2017: Estimating carbon uptake in forest and agricultural ecosystems of Korea and other countries using eddy covariance flux data. Journal
of Environmental Impact Assessment 26(2),
127-139.Lee, B., E. Kim, J. Lee, J.-M. Chung, and J.-H.
Lim, 2018: Detecting phenology using MODIS vegetation indices and forest type map in South Korea. Korean Journal of Remote Sensing 34(2), 267-282.
Liaw, A., and M. Wiener, 2002: Classification and regression by randomForest. R news 2(3), 18-22.
Masuoka, E., A. Fleig, R.E. Wolfe, and F. Patt, 1998: Key characteristics of MODIS data products.
IEEE Transactions on Geoscience and Remote Sensing 36(4), 1313-1323.
Oh, H. J., 2010: Landslide detection and landslide susceptibility mapping using aerial photos and artificial neural networks. Korean journal of remote
sensing 26(1), 47-57.
Recknagel, F., 2001: Applications of machine learning to ecological modelling. Ecological Modelling
146(1-3), 303-310.
Reeves, M. C., M. Zhao, and S. W. Running, 2005:
Usefulness and limits of MODIS GPP for estimating wheat yield. International Journal of Remote
Sensing 26(7), 1403–1421
Running, S. W., D. D. Baldocchi, D. P. Turner, S.
T. Gower, P. S. Bakwin, and K. A. Hibbard, 1999: A global terrestrial monitoring network integrating tower fluxes, flask sampling, ecosystem modeling and EOS satellite data. Remote Sensing
of Environment 70(1), 108–127.
Running, S. W., P. E. Thornton, R. Nemani, and J.
M. Glassy, 2000: Global terrestrial gross and net primary productivity from the Earth Observing System. In Methods in ecosystem science, 44-57.
Springer, New York, NY (USA).
Running, S. W., and M. Zhao, 2015: Daily GPP and annual NPP (MOD17A2/A3) products NASA Earth Observing System MODIS land algorithm.
MOD17 User’s Guide.
Ryu, Y., S. Kang, S. K. Moon, and J. Kim, 2008:
Evaluation of land surface radiation balance derived from moderate resolution imaging spectroradiometer (MODIS) over complex terrain and heterogeneous landscape on clear sky days. agricultural and
forest meteorology 148(10), 1538-1552.
Schindler, D. E., and R. Hilborn, 2015: Prediction, precaution, and policy under global change.
Science 347(6225), 953–954. http://doi.org/10.1126/
science.1261824
Sims, D. A., A. F. Rahman, V. D. Cordova, B. Z.
El‐Masri, D. D. Baldocchi, L. B. Flanagan, A. H.
Goldstein, D. Y. Hollinger, L. Misson, R. K.
Monson, and W. C. Oechel, 2006: On the use of MODIS EVI to assess gross primary productivity of North American ecosystems. Journal of
Geophysical Research: Biogeosciences 111(G4).
Smith, P., G. Lanigan, W. L. Kutsch, N. Buchmann, W. Eugster, M. Aubinet, E. Ceschia, P. Béziat, J.
B. Yeluripati, B. Osborne, and E. J. Moors, 2010:
Measurements necessary for assessing the net ecosystem carbon budget of croplands. Agriculture,
ecosystems and environment 139(3), 302-315.
Smola, A. J., and B. Schölkopf, 2004: A tutorial on support vector regression. Statistics and computing
14(3), 199-222.
Tramontana, G., K. Ichii, G. Camps-Valls, E. Tomelleri, and D. Papale, 2015: Uncertainty analysis of gross primary production upscaling using Random Forests, remote sensing and eddy covariance data. Remote
Sensing of Environment 168, 360-373.
Wang, X., Y. Yao, S. Zhao, K. Jia, X. Zhang, Y.
Zhang, L. Zhang, and X. Chen, 2017: MODIS- based estimation of terrestrial latent heat flux over North America using three machine learning algorithms. Remote Sensing 9(12), 1326pp.
White, M. A., P. E. Thornton, S. W. Running, and R. R. Nemani, 2000: Parameterization and sensitivity
analysis of the BIOME–BGC terrestrial ecosystem model: net primary production controls. Earth
interactions 4(3), 1-85.
Vidal, R., J. Bruna, R. Giryes, and S. Soatto, 2017:
Mathematics of deep learning. arXiv preprint arXiv:1712.04741.
Ye, H., R. J. Beamish, S. M. Glaser, S. C. Grant, C. H. Hsieh, L. J. Richards, J. T. Schnute, and G. Sugihara, 2015: Equation-free mechanistic ecosystem forecasting using empirical dynamic modeling. Proceedings of the National Academy of