A study on the classification of households in Rwanda based on factor scores
Pacifique Nizeyimana 1 · Kee-Won Lee 2 · Songyong Sim 3
123 Department of Statistics, Hallym University
Received 17 February 2018, revised 13 March 2018, accepted 14 March 2018
Abstract
Many researchers have focused on grouping or classifying households into different categories based on either income/consumption or household assets. However, these practices may lead to an inadequate classification due to Rwanda’s unique family struc- ture. In Rwanda, households are classified into six socio-economic classes known as
‘Ubudehe categories’. This classification is based on subjective perceptions of people.
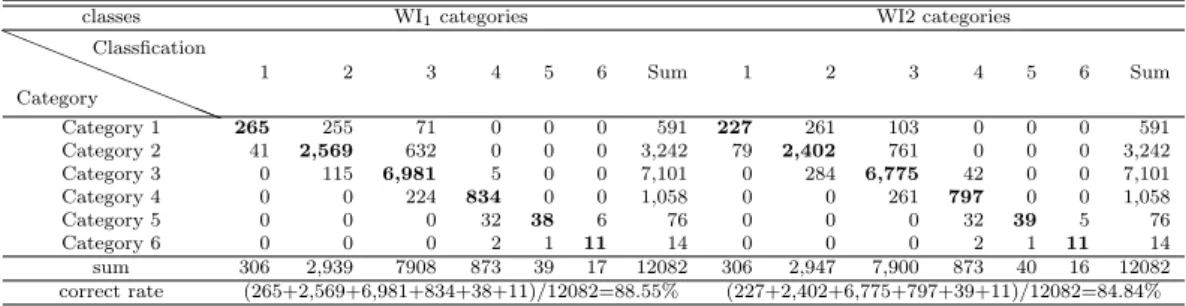
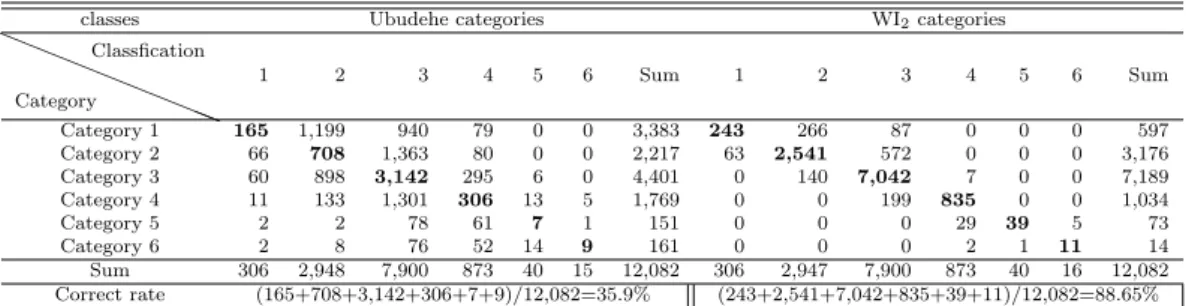
In this study, we propose to use household assets as well as income/consumption to classify Rwandan households into different socio-economic categories. These approaches are summated Likert scale method and factor score method. When these two meth- ods are compared by a discriminant analysis, the factor score method brings out more reliable results than Likert method.
Keywords: Factor score, household assets, summated Likert scale, Ubudehe categories, wealth index.
1. Introduction
As a developing country, Rwanda has a vision of fighting against poverty and improving the welfare of its population. One way the Rwandan government has sought to improve the welfare of its people is by classifying households into categories based on individual living standards and economy. These categories are commonly known as “Ubudehe categories”.
In 2001, the government reintroduced Ubudehe as a process whereby people from the same cell come together to evaluate their current living situations, and decide on solutions to improving development. In this process, the heads of households from the same cell come together and classify themselves into six different socio-economic categories, ranging from the poorest households (Category 1) to the richest households (Category 6). The main goals of this practice of Ubudehe are as follows:
1. To fight against poverty.
1
Graduate student, Department of Statistics, Hallym University, Chuncheon 24252, South Korea.
2
Professor, Department of Statistics, Hallym University, Chuncheon 24252, South Korea.
3