기획특집 바이오 인포메틱스-
바이오 인포메틱스 기술 현황
정 의 섭*,†․이 진 원*,**
*서강대학교 공과대학 화공생명공학과, **서강대학교 바이오융합기술사업단
Situation and Prospect of Bioinformatics
Ui Sub Jung*,† and Jinwon Lee*,**
*Department of chemical and biomolecular engineering, Sogang University, Seoul 121-742, Korea
**Interdisciplinary Program of Integrated Biotechnology, Sogang University, Seoul 121-742, Korea
Abstract: 20세기 중반부터 생물학자들과 공학자들은 분자생물학 연구방법을 통하여 모든 생명체에서 중요한 역할을 하는 특정인자가 유전자와 단백질, 그리고 대사산물이고, 이들의 구조와 기능을 분석하고 규명하는 데에 힘써 왔다. 이 를 통해 얻은 각각의 생물정보를 이용하여 과학자들은 생명체 전체에 대한 생체조절 기작을 설명하려고 하였으나, 생명 체에 있어서 그 구성성분들이 각각 따로 존재하며 작용하는 것이 아니라 서로 간에 유기적인 상호작용을 하고 있어, 한 구성성분의 기능이 바뀌거나 양적인 변화가 있을 때 이는 그 생명체를 이루고 있는 다른 많은 구성성분에 영향을 미치 고 세포내의 전체적인 효과로 나타난다. 생물학적 데이터는 다른 데이터들에 비해 훨씬 복잡한 내용을 가지고 있으며, 다양한 분야와 목적에 적합하게 데이터들을 분류, 상호 연결을 해야 한다. DNA나 단백질의 서열분석부터 구조나 기능 그리고 나아가 생명 현상의 설명에 이르기까지 응용대상과 수준도 광범위하며 그에 따라 분석하는 방식도 다양하다. 따 라서 많은 수학적, 통계학적 분석 기법들이 이용되고 있다. 바이오인포메틱스가 현재 응용되는 생물학의 분야는 분자생 물학의 모든 분야를 포함하고 있으며 유전체학, 전사체학, 단백질체학, 대사체학, 약리유전체학 등 분자생물학의 모든 분야이다. 이에 유전체학, 단백체학, 대사체학 학문들의 바이오인포메틱스와의 연계성과 기술현황을 살펴보았다.
Keywords: bioinformatics, biological database, genomics, proteomics, metabolomics
1. 서 론1)
바이오인포메틱스(bioinformatics)란 이처럼 생명 현상 관련 연구에서 나오는 다양한 정보 를 수집, 관리, 분석하는 데 필요한 제반분야 를 말한다. 이미 알려져 있는 유전자, 단백질 의 서열데이터베이스와 단백질 구조나 기능에 대한 정보를 컴퓨터를 통해 접근하여 비교 분 석할 수 있도록 하는 것이 바이오인포메틱스 의 주된 기능이라고 할 수 있다. 바이오인포메 틱스의 응용은 제약, 농업, 화학, 환경에 이르 는 다양한 산업에 영향을 미치고 있어 현재
† 주저자 (E-mail: [email protected])
상당한 기술력을 가지고 있으며, 앞으로 5~10 년 내에 관련 기술의 발전과 더불어 여러 혁 신적 성과들이 가시화될 전망이다.
바이오인포메틱스가 급격하게 발전하게 된 것은 얼마 되지 않았다. 1970년대 중반 이후부 터 DNA, 단백질의 자동서열분석이 수행되었 고, 1980년대 중반에 들어서야 컴퓨터가 각종 데이터의 저장소 역할을 하게 되고 온라인을 통한 원격 접근이 가능하게 되었다. 바이오인 포메틱스가 생물공학 연구에 본격적인 영향력 을 발휘하기 시작한 것은 1980년대 후반에 개 별 과학자들이 발견한 여러 생물의 DNA 정 보를 수록하는 공공의 데이터베이스가 만들어 지면서 부터라고 할 수 있다. 이들 중 가장 대
2001년에 국가유전체정보센터(KOBIC)를 설립 하여 연구주체들 간의 유기적 네트워크와 통 합 데이터베이스 구축 및 생명정보 분석 시스 템을 제공해오고 있다(Figure 1)[1-4].
이들 기관에서는 DNA 서열 데이터베이스 외에도 단백질 아미노산 서열 및 3차원 구조 데이터베이스, 데이터 마이닝(Data-mining) 소 프트웨어, 생물학 관련 문헌정보 데이터베이 스, 인터넷을 통한 온라인 서비스 프로그램 등 을 발전시켜 왔다. 이러한 바이오인포메틱스 기술을 발전시키는 데에 가장 큰 역할을 한 것은 인간게놈프로젝트(Human Genome Proj- ect)를 비롯한 각종 미생물, 동식물 등의 게놈 프로젝트들이다(Figure 2)[1]. 이들 프로젝트 의 성과가 쏟아지면서 바이오인포메틱스는 방 대한 데이터의 처리뿐만 아니라 각종 게놈 데 이터들로부터 신약의 타깃이 되는 물질의 탐 색과 검증을 위한 기본적인 수단으로 사용되 면서 수요가 크게 증가하였으며, 유용한 정보 를 먼저 분석해내기 위해 수많은 생명공학기 업과 제약기업들은 바이오인포메틱스 기술 확 보에 열을 올리게 되었다. 이와 같은 관심과 투자를 기울이는 이유는, 바이오인포메틱스를 통해 신약개발 과정에 있어 후보물질의 발굴 과 개발에 보다 체계적으로 접근할 수 있을 뿐만 아니라, 개발에 소요되는 시간을 대폭 줄 일 수 있을 것으로 기대하기 때문이다.
바이오인포메틱스를 발전시킨 계기를 앞서 서도 인간 유전체 프로젝트(Human Genome Project) 및 다양한 미생물 유전체 프로젝트 등이라 언급하였다. 이를 통해 수많은 생물학
BIC-한국).
Figure 2. 기하급수적으로 증가하는 Gene Bank 데이터.
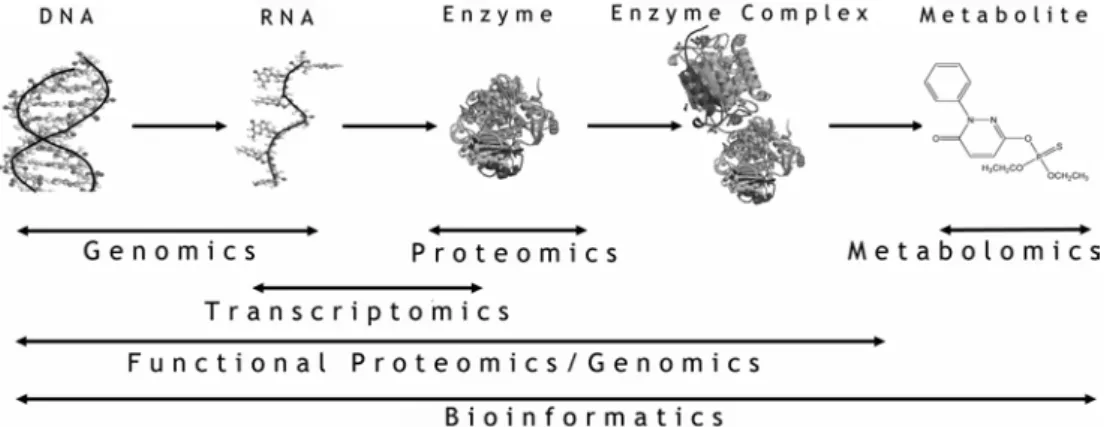
적 서열 데이터가 수집되어 데이터베이스로 구축되었으며, 이들 1차 염기서열 즉 DNA 레 벨에서 유전자의 발현양상을 연구하는 학문인 유전체학(genomics)을 발전시켰으며, 한편 중 심원리(central dogma)의 최종산물인 단백질 의 기능과 구조분석을 위한 단백체학(proteo- mics)이라는 또 다른 학문이 파생되었다.
그 다음으로 유전자의 정보가 단백질로 전 달되는 중간 과정인 전사(transcription)단계에 서 mRNA (messenger RNA)의 발현(transcrip- tion) 정도를 연구하는 학문인 전사체학(tran- scriptomics)과 세포 내 다양한 유전적, 환경적 조건에서 단백질 효소(enzyme)에 의해 만들 어지는 수많은 대사산물(metabolite)의 종류와 농도를 분석기기를 사용하여 포괄적으로 해석 함으로서 생명현상을 총체적으로 연구하기 위
Figure 3. 바이오인포메틱스와 여러 오믹스 기술(-omics technology)의 상관 관계.
한 새로운 학문인 대사체학(metabolomics) 등 새로운 형태의 다양한 학문들이 생겨났다. 이 러한 의미에서 이들 모두를 포괄하는 의미로 컴퓨터를 이용하여 생명현상을 연구하는 학문 을 바이오인포메틱스(bioinformatics)라고 말할 수 있다(Figure 3)[5].
연구 분야
▸ 염기배열 해석: 세포내에서 유전자는 DNA 에서 mRNA로 전사되고, 그것이 해석된 후 아미노산 배열이 결정되게 된다. 그러나 DNA 염기 배열 상에서 유전자는 연속해 있지 않고 띄엄띄엄 분포되어 있으며, 아무 런 의미가 없는 인트론은 전체 염기 배열 중 95%나 된다고 한다. 이 때문에 가장 먼 저 의미있는 엑손 부위가 염기 배열 상 어 디에 존재하고 있는 지가 문제가 된다. 이 유전자 영역 코드 영역 예측 문제는 마코프 모델(Markov model)이라는 확률 모델을 컴퓨터에서 해석하여 해결할 수 있다.
▸ 데이터베이스 검색 및 구축: 연구자가 새롭 게 발견한 유전자의 기능을 예측하기 위해 염기서열 데이터베이스에서 유사한 배열을 찾는 방법이 있다. 이 유사 배열을 검색하 는 방법을 호몰로지(homology) 검색이라고 하는데, 염기 배열의 적절한 곳에 갭(gap)
을 주어 가장 유사한 배열을 동적 계획법이 라 하는 최적화 문제를 풀 때 사용되는 방 법을 이용한다.
▸ 단백질의 고차 구조 예측 : 단백질은 생명 활동의 기본적인 기능성을 가진 분자이며, 아미노산이 폴리펩티드 결합에 의해 일차원 적으로 연결되어 생기지만 배치에 자유도가 거의 없이 각각이 특유의 입체 구조를 가지 고 효소 등 생체 내에서 기능을 한다. 이 고차 구조가 단백질의 기능을 결정하는데, 새로 발견된 단백질은 X선 결정 구조 해석 에 의해 이미 데이터베이스에 등록되어 있 는 단백질의 입체 구조와 비교하여 기능이 추정된다.
▸ 대사계 해석 : 유전자는 세포내에서 단독으 로 발현하는 일이 적고 상호 작용을 한다.
이 유전자 사이의 네트워크는 DNA칩 등에 서 시계열 데이터를 바탕으로 연구되고 있다.
단백질이나 생체 내 분자 사이의 생화학적 반응을 패스웨이(pathway)라고 하는데, 이 화학 반응 네트워크를 대사 네트워크라고 한 다. 이 부분은 바이오인포메틱스의 등장으로 좀 더 포괄적으로 연구할 수 있게 되었고, 패스웨이(pathway)나 효소 반응의 정보를 통합적으로 관리하는 데이터베이스는 바이오 인포메틱스 중에서도 게놈을 이용한 약품개 발에 가장 유용한 것으로 주목받고 있다.
서열 분석기가 개발되고 BAC library를 이용 하게 되면서 효율의 문제가 해결되어 염기서 열 분석에 가속도가 붙게 되었다. 뿐만 아니라 많은 염기서열 정보를 분석할 수 있는 알고리 즘의 개발로 불과 1년 만에 전체 염기서열 분 석을 마칠 수 있었다. 실제로 인간 유전체 속 에는 3~4만개의 유전자가 있다는 것이 현재 까지 알려진 내용이다. 즉 이들 유전자들이 어 떤 기능을 갖고 있는지, 그리고 각종 현상들과 어떻게 연관되어 있는지, 또한 이들 유전자들 의 상호관계를 이해하는 것이 필요하였다.
인간 유전체에 관한 정보이외에 미생물의 전 유전체 염기서열의 결정도 또한 빠른 속도 로 연구되고 있어 이미 공표되고 있는 것만 해도 수십 종을 넘어서고 있다. 이들 유전체의 전 염기서열을 결정하는 데에 주로 사용하는 방법으로 무작위 또는 샷건(shot gun) 염기결 정법이다[6,7]. 이 방법은 실험 및 컴퓨터에 의한 해석절차가 단순하므로 대량 데이터를 취급하는 전 유전체 염기서열 결정에는 특히 유용하게 이용되고 있다. 여기서 컴퓨터에 의 한 해석은 다수의 무작위 클론끼리의 상동성 을 이용하여 서로 연결하는 것으로 DNA 결 합편집기라고 불리는 소프트웨어를 이용하게 된다[8].
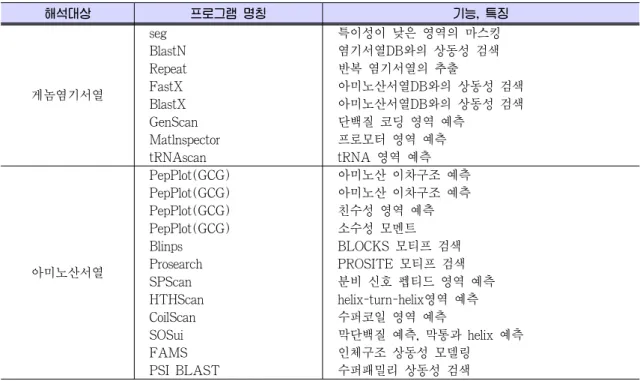
한편, 결합편집(assemble)의 후반부터는 유 전자 코딩영역 예측을 비롯한 다양한 게놈 구 조 및 기능 annotation (주석달기)이 필요하게 된다. 세계 여러 연구 팀에서 사용하는 anno- tation (주석달기) 프로그램을 Table 1에 정리 하였다.
두 번째는 기능 유전체학(functional geno- mics)으로 새로운 유전자의 발굴과 기능을 연 구하는 것으로 현재까지 인간의 전체 유전자 서열은 밝혀졌으나, 기능이 알려진 유전자는 전체의 10% 정도에 불과하다. 유전자 기능을 연구하는 방법에는 이미 기능이 규명된 유전 자와 새로운 유전자간의 서열 유사성으로부터 각 유전자의 기능을 유추하는 것인데, 이는 각 종 데이터베이스를 이용한 작업을 통해 활발 하게 진행 중에 있다(Figure 4)[9].
마지막은 비교 유전체학(comparitive ge- nomics)으로 표준 염기서열을 바탕으로 개체 간 유전적 특성을 밝히는 것이다. 이런 연구 방법을 통해 얻은 결과를 이용해 단순한 서열 정보에서 유전자의 구조와 기능을 밝히고 개 체간의 유전적 특성을 예측해 세포 내 수용체 (receptor)의 공간적 관계를 예측하기도 한다.
또한 이러한 방법을 통해 유전자 질환의 진단 과 신약 개발 연구에 직접 응용할 수 있다.
이러한 유전체에 대한 정보는 생명체를 시 스템적으로 모델링하고 해석하는 가장 근본적 인 정보를 제공하는 시작점이 될 뿐 아니라, 생명체의 거동을 조절하고 예측할 수 있는 조 작 시점이 되기도 한다.
2.2. 단백체학(Proteomics)
최근, 다수의 DNA 단편이나 올리고뉴클레 오타이드(oligonucleotide)를 고형 표면에 정렬 시킨 소위 cDNA microarray나 DNA probear- ray (DNA chip)를 이용하여 다수의 유전자의 발현 유무를 동시에 관찰할 수 있게 되었다
Table 1. Annotation에 사용되는 주요 program (유전자와 아미노산 염기관련)
해석대상 프로그램 명칭 기능, 특징
게놈염기서열
seg 특이성이 낮은 영역의 마스킹
BlastN 염기서열DB와의 상동성 검색
Repeat 반복 염기서열의 추출
FastX 아미노산서열DB와의 상동성 검색
BlastX 아미노산서열DB와의 상동성 검색
GenScan 단백질 코딩 영역 예측
Matlnspector 프로모터 영역 예측
tRNAscan tRNA 영역 예측
아미노산서열
PepPlot(GCG) 아미노산 이차구조 예측 PepPlot(GCG) 아미노산 이차구조 예측 PepPlot(GCG) 친수성 영역 예측 PepPlot(GCG) 소수성 모멘트
Blinps BLOCKS 모티프 검색
Prosearch PROSITE 모티프 검색
SPScan 분비 신호 펩티드 영역 예측
HTHScan helix-turn-helix영역 예측
CoilScan 수퍼코일 영역 예측
SOSui 막단백질 예측, 막통과 helix 예측
FAMS 인체구조 상동성 모델링
PSI BLAST 수퍼패밀리 상동성 검색
Figure 4. 서로 다른 유전자 발현 분석에서의 DNA microarray 사용.
[10,11]. 이 기술에 의해서 여러 형태․동태를 나타내는 세포에서 일어나고 있는 mRNA 발 현의 변화를 직접 관찰할 수 있게 되고 미지
의 유전자의 기능에 대한 단서를 얻기 쉬어졌 다. 또한 이러한 유전자 발현 프로필을 계통적 으로 수집하여 상세하게 해석함으로써 유전자 발현에 관한 유전자간 상호작용의 정보도 얻 을 수 있게 되었다.
그러나 세포 시스템은 유전자의 발현뿐만 아니라, 유전자 산물인 단백질간의 상호작용에 의해서 유지되고 있는 복잡한 계(system)이 다. 실제 미생물 시스템은 예상 외로 적은 수 의 유전자에 의해서 구성되고 있다. 대장균의 유전자수는 4,397개, 효모의 전 유전자는 단 6,548개이다. 하지만 세포 내에서 이들 유전자 가 항상 작용하고 있는 것이 아닌데다가, 세포 가 최소한의 활동을 하기 위해 필요한 하우스 키핑(housekeeping) 유전자 수는 더욱 적다.
이와 같이 적은 수의 유전자만이 사용되고 있 음에도 불구하고 복잡한 세포활동이 영위되고 있는 배경에는 하나의 유전자에 암호화되어 있는 단백질이라도 그 발현 시기, 수송되는 부 위, 각종 효소군에서 받는 번역 후 수식의 차
Figure 5. 단백체학(proteomics)에서 사용하는 2-Dimensional Gel Electrophoresis (2-DE) 기법.
이, 상호작용하는 단백질의 종류 등에 따라서 다양한 작용을 보인다는 것이다.
이처럼 복잡한 거동을 보이는 세포 시스템 을 이해하기 위해서는 게놈상의 전 유전자산 물의 집합을 나타내는 표현으로 프로테옴(pro- teome; 단백체)이라는 용어를 사용하게 되었 다[12]. 단백체 해석에서는 전 유전자산물이 언제 어느 정도의 양이 발현되어 수송․번역 후 수식을 받아 기능하고, 언제 분해되는지를 전체적으로 해석한다. 또한 단백체 해석에 이 용하는 수단이나 기술을 의미하는 프로테오믹 스(proteomics; 단백체학)라는 용어가 사용되 고 있는데, 이들은 최종적으로 하나의 세포에 서 전 단백질이 어떻게 작용되고 있는지를 해 명하는 것을 포함하는 말이기도 하다[13]. 게 놈 상에 암호화된 유전자의 발현산물인 단백 질을 망라하여 취급하기 위한 중요한 기술적 기반은 세포를 구성하는 복잡한 단백질 혼합 물의 분리기술과 번역 후 수식의 유무 및 종 류를 알 수 있는 단백질 동정기술이다.
일반적 세포상태에서는 많은 유전자는 침묵 하고 있으며 당연히 모든 단백질이 세포 내에 서 항상 발현하고 있는 것이 아니다. 또한 세 포 내에서의 단백질 수명도 단백질에 따라서
다양하며 발현량은 한 세포 당 수개에서 수만 개로 다양하다. 이렇게 발현량의 범위가 넓고 복잡한 단백질 혼합물에서 수천종류의 단백질 을 분리하는 가장 효과적인 방법으로서 이차 원 폴리아크릴아미드겔전기영동(two-dimen- sional polyacrylamide gel electrophoresis; 2D- PAGE)이 이용된다.
가용화된 단백질 혼합물을 2D-PAGE하여 단백질을 분리․전개한 후, 염색하여 가시화하 는 방법을 Figure 5에 나타내었다[14].
2.3. 대사체학(Metabolomics)
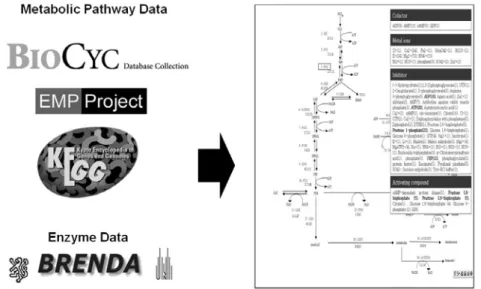
대사체학이란 세포 내 다양한 유전적, 환경 적 조건에서 단백질 효소(enzyme)에 의해 만 들어지는 수많은 대사산물(metabolite)의 종류 와 농도를 MS (mass spectrometer)나 NMR (nuclear magnetic resonance)과 같은 다양한 분석기기를 사용하여 포괄적으로 해석함으로 써 생명현상을 총체적으로 연구하기 위한 새 로운 학문으로 정의되어진다(Figure 6)[15,16].
다시 말해 전사체학(transcriptomic), 단백체 학(proteomics)과 함께 포스트 게노믹시대(post- genomic era)에 기능 유전체학(functional ge- nomics)의 한 방편으로 유전형질과 표현형질
Figure 6. 미생물 대사 모델 구축 과정과 시뮬레이 션을 통한 세포 시스템 분석과정을 나타낸 모식도.
의 관계를 규명해줄 궁극적인 수단으로 이용 되고 있으며 대사체학 연구를 통해, 알려져 있 지 않던 유전자와 단백질의 기능 규명도 가능 하게 된다. 또한 대사산물 데이터베이스 확보 및 네트워크 구축에 의해 얻어진 정보를 이용 한 세포의 생리학적 상태를 판단함으로써 유 전자 발현 및 단백질 발현 여부를 확인하는 것이 가능해졌다. 이에 최근 바이오관련 연구 소에서는 생명현상을 총체적으로 이해하기 위 해서는 무엇보다도 대사체에 관한 연구가 필 수적임을 인지되기 시작했으며 선진국에서는 이미 대사체학에 관한 많은 연구가 이루어지 고 있다[17-19].
2.4. 세포 네트워크 모사연구(Simulation)
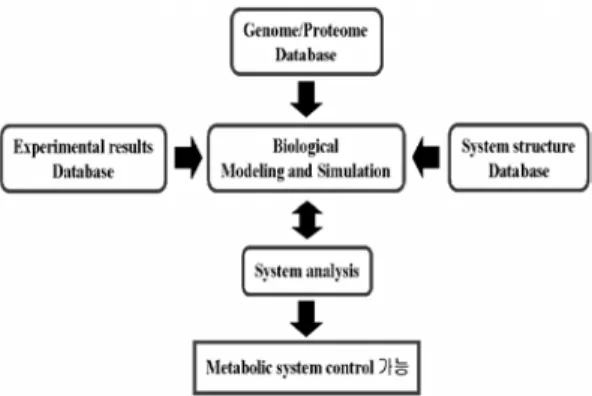
대장균 전체 대사 네트워크만 보더라도 수 천 개의 효소들이 서로 상호작용을 하여 어떠 한 화학공정보다 정교하다. 따라서 세포 시스 템 동역학 모델을 구축하기 위해서는 몇 가지 구성 요소가 필요한데, 즉, 모델 형상화 단계, 기본적 모델링의 원리, 기본 법칙들, 단순화 (simplification)를 위한 가정, 반응 속도식의 파라미터(parameter), 마지막으로 측정 데이터 를 통한 비교 및 보완 등이 필요하다.
형상화 단계의 경우 세포 시스템의 복잡성 을 설명하기 위해서는 대사 반응 네트워크, 효 소 반응 메커니즘 등을 형상화시켜 나타내야
한다. 그리고 세포의 구성 요소 중에서 탐색하 고자 하는 부분에만 초점을 맞추고 다른 부분 의 영향이 있다 할지라도 이를 무시하여 단순 화해야 한다. 대부분의 대사 네트워크 모델에 서 적용하는 기본적인 형상화 작업은 대사 시 스템을 단위 구획을 나누어 시스템 내에서 균 일한 농도를 갖는 대사 물질 간의 변화 또는 이동을 표시하는 것인데, 이 과정에서는 대사 물질의 수가 많다고 가정하고 확률적인 미세 한 변화를 무시하면 농도 변수로 세포 내 대 사 시스템의 상태를 표시 할 수 있게 된다.
형상화 단계가 확립되었으면 그 다음으로 일반적인 모델링 방법으로 모델식들을 정하게 된다. 수학적 모델링 방법은 세포 시스템의 모 델 구축에 있어 대단히 중요한 기법 중의 하 나라고 할 수 있다. 앞에서 언급했듯이 세포 시스템의 모델 구축이 이루어 질 경우, 대사 데이터의 평가, 세포 시스템의 분석 및 예측, 새로운 세포 시스템의 설계(design) 및 최적 화(optimization)가 가능해 진다고 할 수 있다.
지금까지 개발된 모델링 기법들에 대해 살펴 보면, 구조적 모델(structural model), 스토이 키오메트릭 모델(stoichiometric model), 탄소 흐름 분석 모델(carbon flux model), 동역학 모델(dynamic model) 등이 있다. 각각의 모델 링 기법들의 경우 모델링 기법 특징에 따라 장․단점이 있으며, 또한 모델링 구축에 대한 가정과 단순화(simplification) 정도에 따라 그 정확도와 효용성이 다르게 나타날 수 있다.
앞에서 잠깐 언급했듯이 대사 시스템을 보 다 자세히 묘사하기 위한 세밀한 모델 구조를 만들 수 있지만 수식과 파라미터(parameter) 값들이 늘어나기 때문에 실질적인 적용을 하 기에는 어려움이 따르게 된다. 이러한 경우 모 델을 단순화하기 위한 몇 가지 가정을 하게 되면 모델의 복잡성을 줄일 수 있다. 많이 사 용되는 단순화 방법으로는 일련의 대사반응 단계를 하나의 단위로 묶거나, 전체의 대사경 로를 몇 개의 반응 단계로 축약하는 방법이 있다.
Figure 7. 미생물의 대사네트워크 구축과정 간략화한 그림.
다음으로 반응 속도식에 있어서 파라미터 값은 반응 속도식의 정확도를 결정짓는 중요 한 인자(factor)라 할 수 있다. 이러한 파라미 터 값의 경우 대부분이 문헌이나 데이터베이 스를 통해서 얻을 수 있다. 하지만 이러한 자 료에서 매우 주의를 기울여야 할 것이, 한 가 지 반응 속도식에 대해 각각 다른 파라미터 값을 제시하는 경우가 있는데, 이는 각각 시행 한 실험의 조건 및 방법, 그리고 측정에 있어 그 차이가 있기 때문이다.
앞에서 언급했던 모델링 과정은 컴퓨터를 이용한 모사(in-silico simulation), 즉 시뮬레이 션 분석을 위한 준비 과정이라고 할 수 있다.
모사의 경우 생물 분야 외에 여타 다른 영역 에서도 많이 사용되고 있는 기법 중 하나이며, 특히 생물 분야에 있어 컴퓨터 모사 기법은 신약개발에 활용될 경우 매우 유용한 기법이 될 수 있다.
현재 생물분야 관련 소프트웨어의 경우 크 게 두 가지로 나눌 수 있는데, 그 하나는 대사 경로(metabolic pathway)를 포함한 효소(en- zyme) 및 유전자관련 데이터베이스(data base) 이다. 다른 하나는 이러한 데이터베이스를 바 탕으로 생체 내 물질 대사가 어떻게 이루어지
는지에 대한 종합적인 분석을 가능하게 하는 모사 관련 소프트웨어가 그것이라 할 수 있다.
Table 2에 대사공학 관련 데이터베이스와 모 사 관련 URL을 제시하였다.
3. 결 론
지금까지 바이오인포메틱스와 유전체학, 단 백체학, 대사체 학문의 연계성 및 기술현황에 대하여 논의하였다. 요약하면, 바이오인포메틱 스란 앞서 말한 오믹스 기술을 기반으로 얻어 진 막대한 양의 생물정보를 컴퓨터를 이용하 여 세포 내의 시스템을 분석하고 총괄적이고 체계적으로 이해하는 것을 목적으로 하고 있 는 생물학의 새로운 분야이다. 즉, 단위 생물 개체 또는 단위세포를 시스템적으로 접근하고 해석할 수 있는 연구를 말하며, 연구 방법 또 한 다량의 유전체나 단백체 및 대사체를 동시 에 실험을 통해 분석할 수 있는 새로운 공학 적 접근을 필요로 하고 있다.
바이오인포메틱스 연구를 위해서는 생물학 적 시스템들을 전체적인 관점에서 이해하기 위한 방법론과 기술의 도움이 필요하고, 이러
Table 2. 대사공학 관련 데이터베이스(Database)와 모사(Simulation) 관련 URL
Name URL
KEGG http://www.genome.ad.jp/kegg/metabolism.html BioCyc http://biocyc.org/
BRENDA http://www.brenda.uni-koeln.de/
E-cell http://www.e-cell.org/
GEPASI http://www.gepasi.org/
COPASI http://www.copasi.org/
MCELL http://www.mcell.cnl.salk.edu/
Virtual cell http://www.nrcam.uchc.edu/
MetaFluxNet http//mbel.kaist.ac.kr
한 생명현상의 구성성분에 대한 방대한 분석 데이터를 만들어 내는 생화학자 및 분석화학 자 뿐만 아니라, 분석 데이터를 사용하여 세포 시스템을 모델링하고 모사(simulation)하고 검 증실험을 할 수 있는 공학자, 이를 통하여 얻 어지는 가설들을 다시 세포내에서 재구성할 수 있는 세포생물학자 등 여러 분야 과학자들 의 긴밀한 협력이 필수적이며, 이를 통해야만 생명현상의 시스템적인 이해가 가능해 질 것 이다. 즉 효율적인 바이오인포메틱스 연구를 위해서는 지금까지 각 분야의 과학자들이 독 자적으로 자기 분야를 연구하는 방식을 탈피 하여 각각의 연구대상에 관한 다양한 기술들 의 집합과 여러 연구 분야들에서의 공통적 노 력을 필요로 하겠다.
국내의 바이오인포매틱스를 발전시키기 위 해서는 인프라의 구축, 소프트웨어 연구개발 등에 투자가 필요하며 이를 위해 우대정책이 요구되고 있다. 특히, 정부 지원의 연구개발 프로젝트의 경우 바이오인포매틱스 분야의 특 성과 초창기 산업의 기반을 제공한다는 측면 에서 단기성 과제보다는 수년에 걸친 장기과 제로 분류하는 등의 배려가 필요하다. 동시에 기업들은 응용 분야의 발굴, 국내 실정에 맞게 특화된 소프트웨어 개발, 독창적인 생물 정보 데이터베이스 구축 등에 주력하여 경쟁 역량 을 확보하려는 노력이 필요하다.
참 고 문 헌
1. http://www.ncbi.nlm.nih.gov/
2. http://www.ebi.ac.uk/embl/
3. http://www.ddbj.nig.ac.jp/
4. http://www.kobic.re.kr/kobic/index.php 5. N. M. Morel, J. M. Holland, van der J.
Greef, E. W. Marple, C. Clish, J. Loscalzo, and S. Naylor, Primer on medical gen- omics. Part XIV: Introduction to systems biology--a new approach to understand- ing disease and treatment, Mayo Clin Proc., 79, 651 (2004).
6. G. Sutton, O. White, M. Adams, and A.
R. Kerlavage, TIGR Assembler: a new tool for assembling large shotgun se- quencing projects, Genome Sci. Technol., 1, 9 (1995).
7. F. J. M. Iris, Optimized Methods for Large-Scale Shotgun DNA Sequencing in Alu-Rich Genomic Region, Automatic DNA Sequencing, Academic Press, New York, p. 199 (1994).
8. M. S. Waterman, Sequence assembly.
Introduction to Computational Biology, Chapman and Hall, London, p.135 (1995).
Dubiley, and A. Mirzabekov, DNA analy- sis and diagnostics on oligonucleotide mi- crochips, Proc. Natl. Acad. Sci. USA., 93, 4913 (1996).
12. M. R. Wilkins, C. Pasquali, R. D. Appel, K. Ou, O. Golaz, J. C. Sanchez, J. X.
Yan, A. A. Gooley, G. Hughes, and I.
Humphrey-Smith, From proteins to pro- teomes - large-scale protein identification by 2-dimensional electrophoresis and amino acid analysis, Biotechnology, 14, 61 (1996).
13. W. P. Blackstock, T. Nishimura, and Y.
Fujita, Proteomics in pharmaceutical in- dustry, Tanpakushitsu Kakusan Koso., 43,
% 저 자 소 개
이 진 원
1987 서울대학교 공과대학 화학공학과 졸업 1989 서울대학교 공과대학
화학공학과 공학석사 1993 미국 Carnegie Mellon University 공학박사 1994~2005. 2 광운대학교 화학공학과 교수 2005. 3~현재 서강대학교 화공생명공학과
부교수
in pharmaceutical research and develop- ment, Curr. Opin. Mol. Ther., 6, 265 (2004).
17. J. C. Lindon, E. Holmes, M. E. Bollard, E. G. Stanley, and J. K. Nicholson, Metabonomics technologies and their ap- plications in physiological monitoring, drug safety assessment and disease diagnosis, Biomarkers., 9, 1 (2004).
18. D. B. Kell, Metabolomics and systems biology: making sense of the soup, Curr.
Opin. Microbiol., 7, 296 (2004).
19. http://mbel.kaist.ac.kr/index_ko.html
정 의 섭
2004. 2. 광운대학교 화학공학과 졸업 2005.~현재 서강대학교 석사과정