S 3 -Net: SRU 기반 문장 및 셀프 매칭 네트워크를 이용한 한국어 기계독해
박천음
*O이창기
*배경훈
**장재용
**홍윤기
**홍수린
***황이규
***김현기
****강원대학교 컴퓨터과학과
*, LGU+
**, 마인즈랩
***, 한국전자통신연구원
****{parkce, leeck} @ kangwon.ac.kr, {vclab, jaeyjang, ykhong}@lguplus.co.kr, {lynn, yghwang}@mindslab.ai, [email protected]
S 3 -Net: Korean Machine Reading Comprehension using SRU- based Sentence and Self Matching Networks
Cheoneum Park
*O, Changki Lee
*, Yunki Hong
**, Jaeyong Jang
**, Kyung-Hoon Bae
**, SuLyn Hong
***, Yigyu Hwang
***, Hyunki Kim
****Kangwon National University Dept. of Computer Science
*, LGU+
**, Mindslab
***, ETRI
****요 약
기계 독해(Machine reading comprehension)를 이용한 질의 응답(Question answering)은 주어진 문맥을 이해하 고, 질문에 적합한 답을 문맥 내에서 찾는 문제이다. S2-Net은 Simple Recurrent Unit (SRU)과 자기 자신의 RNN sequence에 대하여 어텐션 가중치(attention weight)를 계산하는 Self-Matching Networks를 기반으로 기계 독해를 해결하는 딥 러닝 모델이다. 기계 독해 질의 응답에서 질문에 대한 답은 문맥 내에서 발생하는데, 하나의 문맥은 여러 문장으로 이뤄지기 때문에 입력 시퀀스의 길이가 길어져 성능이 저하되는 문제가 있 다. 본 논문에서는 이와 같이 문맥이 길어져 성능이 저하되는 문제를 해결하기 위하여 문장 단위의 인코 딩을 추가한 S3-Net을 제안한다. 실험 결과, 본 논문에서 제안한 S3-Net 모델이 한국어 기계 독해 데이터 셋에서 기존의 S2-Net보다 우수한 (dev) EM 70.08%, F1 81.78%, (test) EM 69.43%, F1 81.53%의 성능을 보였다.
1.
서론
기계 독해를 이용한 질의 응답(Question Answering)은 페이스북 bAbi task의 CBT와 같이 주어진 문맥에서 빈칸을 채우는 cloze 스타일과 주 어진 문맥에서 정답이 포함된 문장을 찾는 WikiQA, 주어진 문맥에서 정답의 시작과 끝 경계를 찾는 스탠포드의 SQuAD등과 같은 문제들로 나뉘며, 좀더 복합적인 문제로 마이크로소프트의 MS-MARCO가 있다 [1, 2, 3, 4]. 위와 같은 문제를 해결하기 위해서는 기계가 주어진 문맥을 이해하고 문맥 내에서 정답을 찾아야 하는데, 이처럼 기계가 주어진 문 장을 이해하는 것을 기계 독해(Machine Reading Comprehension)라 한 다. 예를 들어, 기계 독해 시스템은 “국내 건조기 시장 점유율 1위 누구 야?”와 같은 질문에 대하여, 문맥 “2004년 건조기 시장에 ... 의류 건조 기 중 LG전자는 점유율 77.4%로 1위를 차지했다.”를 이해하고, 해당 문맥 내에서 정답 “LG전자”를 찾아 출력한다.
기계 독해 문제를 해결하기 위하여 S2-Net, DrQA, fastQA, R- Net, Bi-Directional Flow (BiDAF) 등[5-9]과 같은 end-to-end 딥 러 닝 모델들이 연구되고 있으며, 이러한 모델들은 주어진 질문과 문 맥에 대하여 매칭과 인코딩을 수행하고, 질문과 문맥을 매칭하고, 어텐션 매커니즘(attention mechanism)[10]을 기반으로 한 포인터 네트워크(Pointer Networks)[11]로 질문과 유사한 정답의 경계 인 덱스(즉, 정답의 시작과 끝 위치)를 출력한다. 본 논문의 선행 연 구인 S2-Net은 한국어 기계 독해 데이터셋인 MindsMRC에서 질 의응답을 적용하였으며, 이때 주어진 하나의 문단은 여러 문장으 로 이루어져 문단의 길이가 길어져서 성능이 저하되는 문제가 있 었다. 본 논문에서는 이와 같은 문제를 해결하기 위하여 S2-Net 모델에 문장 단위 인코딩을 추가한 S3-Net을 제안한다.
2. SRU기반 Sentence 및 Self Matching Networks (S
3-Net)
을
이용한 한국어 기계 독해
기계 독해를 수행하기 위하여 각 모델들은 질문( ), 문단( ), 정답( )의 데이터 셋이 주어지며, 질문은 m개의 단어 = { , , … , } 로 구성되고, 문단은 n개의 단어 = { , , … , }로 구성된다. 문장 단위 인코딩을 수행하기 위하 여 문장 별로 구성된 입력 단어 을 이용하며, = { ′ , , ′ , , … , ′ ,}와 같이 구성된다( 는 문장 인덱스이고, 은 각 문장에 포함된 단어 인덱스이다). 계층적 모델을 사용하 는 기계 독해 시스템은 앞서 언급한 , , ′을 인코딩하고, 포인터 네트워크를 이용하여 정답의 시작 경계 ( ), 마 지막 경계 ( ) 를 출력한다.
본 논문에서는 한국어 기계 독해를 수행하기 위하여 SRU [12]
기반 셀프 매칭 네트워크(S2-Net)를 이용하며, 문장 레벨의 인코딩 을 수행하고 매칭 레이어(Matching Layer)를 적용하여 계층적 구 조를 가지는 S3-Net을 제안한다. S3-Net 모델은 [그림 1]과 같다.
S3-Net은 자질 레이어(Feature Layer)에서 문단과 질문에 대 한 자질 임베딩(feature embedding)을 수행하여 , 를 만들고, 각 히든 레이어(Hidden Layer)에서 bidirectional SRU (BiSRU) 를 이용하여 문단 인코딩(paragraph encoding)과 질문 인코딩 (question encoding)을 수행한다[5]. 문단 인코딩 와 질문 인 코딩 에 대한 수식은 아래와 같다.
= ( , )
= ( , )
질문 문장은 인코딩을 수행한 다음 어텐션 메커니즘을 이용 하여 얼라인먼트 벡터(alignment vector)를 만들고, 이것을 질문 문장의 인코딩 히든 스테이트(hidden state)와 계산하여 질문 벡
649
2017년 한국소프트웨어종합학술대회 논문집
터(question vector) q를 만든다. 질문 벡터 q에 대한 수식은 아 래와 같으며, Output Layer에서 정답을 출력할 때 사용된다.
= ∑
= exp ∙ / exp ( ∙ )
그림
1. S
3-Net 모델 구조
문장 인코딩을 만들 때는 입력 단어의 단어 표현(word embedding)만 고려하며, 각 문장마다 CNN (Convolutional Neural Network)[13]을 적용하여 히든 스테이트 를 만들고, 아래 식과 같이 RNN을 수행하여 문장 인코딩 히든 스테이트를 만든다.
= ( , )
질문-문장 매칭 레이어(Q-S match)에서 gated 어텐션 기반 RNN 을 이용하여 질문 인코딩 히든 스테이트 정보를 문장 인코딩 히 든 스테이트 에 포함시키고, 이를 문장 모델링 레이어(Modeling Layer for Sentence)에서 문장 인코딩 벡터(sentence encoding vector) 로 모델링하여 를 만들며, 그 식은 아래와 같다.
= ( , ; ∗)
= ( ; )
; ∗= ⨀ ;
= exp / ∑ exp ( )
= ∑
여기서 는 문장 인덱스이고, , 는 질문 인덱스이다. 문장 모 델링 레이어 에서는 입력으로 사용되는 와 질문-문장 매칭 레이어의 문맥 벡터 가 연결( ; ∗)되어 모델링이 수행된다.
; ∗는 gated attention이 적용된 것을 의미하며, sigmoid가 적용된 비선형 게이트 레이어 와 ; c 에 대하여 element- wise product을 수행한 것이다. 문장 모델링 히든 스테이트 는 Output Layer에서 질문 벡터 q와 함께 스코어를 계산한다.
문장-문단 매칭 레이어(S-P match)도 모델링 된 문장 인코딩 히든 스테이트 를 문단 히든 스테이트 에 포함시키기 위 하여 gated 어텐션 기반 RNN을 이용하며, 모델링 레이어1 (Modeling Layer 1)에서 한번 더 추상화가 시도되고, 그 식은 아래와 같다. 이때 문단 모델링 레이어 의 입력은 gated attention이 적용된 , ∗이다. 아래 식에서 은 단어 인덱스 이고, , 는 문장 인덱스이다.
= ( , , ∗)
= ( , )
; ∗= ⨀ ,
= exp / ∑ exp ( )
= ∑
셀프 매칭 레이어(Self-matching Layer)에서 문단 인코딩 히든 스테이트에 대한 셀프 어텐션을 적용하며, 모델링 레이어2 (Modeling Layer 2)에서 셀프 어텐션이 적용된 문단 인코더 벡 터를 모델링하고, 출력 레이어(Output Layer)에서 정답에 대한 포인팅을 수행한다. 셀프 매칭 레이어는 입력으로 주어진 열 (sequence)을 대상(즉, 자기 자신)으로 어텐션 메커니즘을 적용 하는 방법이다. 모델링 레이어2 ( )에 대한 수식은 아래와 같으 며, 식에서 , , 모두 단어 인덱스이다.
= ( , , ∗)
= ( , )
; ∗= ⨀ ,
= exp / ∑ exp ( )
= ∑
S3-Net은 계층적 포인터 네트워크를 기반으로, 입력열인 문 단 중에서 질문에 대응되는 정답의 시작( )과 끝( ) 위 치를 포인팅하며, 식은 다음과 같다.
( ) ∝ ( ) ∗ ( )
( ) ∝ ( ) ∗ ( )
정답(answer span)의 시작과 끝의 위치를 찾기 위하여 문장 과 문단의 모델링 정보를 모두 계산하는데, 먼저 입력된 문장 중 질문과 가장 근접한 문장을 찾기 위해 문장 모델링 히든 스테이트 와 질문 벡터 q를 bi-linear sequence attention으로 계산하여 문장 스코어 벡터를 만든다. 그 후에 모델링 레이어 2에서 모델링한 과 질문 벡터 q를 bi-linear sequence attention으로 계산하여 문단 스코어 벡터를 만들고, 문장 스코 어 벡터와 곱하여 질문에 적합한 정답의 위치를 찾아 출력한 다. 각 문장 는 문장을 구성하는 단어 개를 포함한다.
650
2017년 한국소프트웨어종합학술대회 논문집
3.
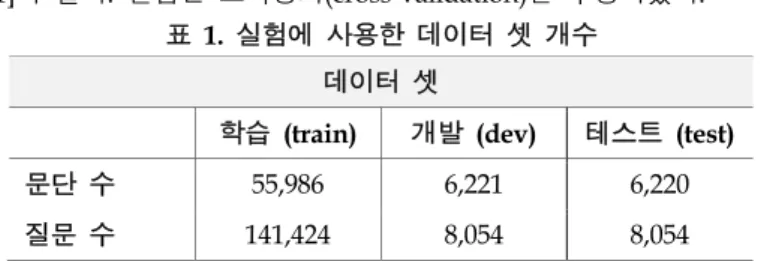
실험실험에 사용된 데이터 셋은 MindsMRC 데이터 셋[5]이며, [표 1]과 같다. 실험은 교차평가(cross-validation)를 수행하였다.
표
1. 실험에 사용한 데이터 셋 개수
데이터셋
학습
(train)
개발(dev)
테스트(test)
문단
수
55,986 6,221 6,220질문
수
141,424 8,054 8,054본 논문에서는 S3-Net을 이용한 한국어 기계 독해에 대하여 다 음과 같이 실험을 하였다. 히든 레이어와 어텐션 레이어에 대한 활성함수는 모두 tanh를 적용하였으며, 모든 RNN 레이어는 BiSRU (CUDA level optimization)를 이용하였다. 드랍아웃은 0.2로 고정하고, 음절 표현의 차원 수는 50 그리고 단어 표현의 차원수 는 100, 히든 레이어의 차원 수는 128로 설정하였다. 본 논문에서 사용한 단어 표현(word embedding)은 10만 단어에 대한 2년치 뉴스기사를 Neural Network Language Model (NNLM) [14]으로 학습한 것을 사용한다. 음절 표현은 CNN을 이용하였고, (2,3,4,5,6)의 사이즈들인 필터(filter)를 사용하고, 각 필터의 차원 수는 30으로 설정하였다. 문장 표현도 CNN을 이용하였고, 필터 윈도우 사이즈 (3,4,5), 각 필터의 차원 수 60으로 설정하였다. 학 습을 위하여 Adam[15]을 이용하고, 학습율(learning rate)을 0.1로 설정하였다. 미니 배치의 배치 크기는 16~32로 설정하였으며, 매 epoch마다 개발 셋으로 성능 평가를 수행하여 최적의 모델을 구 하였다. 성능 측정의 척도는 EM (Exact Match)과 F1을 사용하였다 [3]. EM은 정답과 시스템 결과를 비교하여 똑같이 매칭되는 단어 들의 성능이고, F1은 정답과 시스템 결과의 정확률(precision)과 재현율(recall)의 조화평균이다.
[표 2]는 본 논문에서 제안한 S3-Net과 본 논문의 선행 연구인 S2-Net의 성능 비교를 나타내며, baseline은 DrQA로 설정하였다.
DrQA는 3-stack hidden layer, 1-stack modeling layer를 이용하 고, DrQA+BiSRU, S2-Net, S3-Net은 5-stack hidden layer, 2-stack modeling layer를 이용하였다. 실험 결과, 본 논문에서 제안한 S3-Net이 single 모델일 때 F1 81.78%로 baseline인 DrQA보다 4.78% 더 높은 성능을 보였고, DrQA+BiSRU보다 1.88%, S2-Net 보다 1.39% 좋은 성능을 보였다. 이때 S3-Net의 test set에서의 성능은 EM 69.43%, F1 81.53%이며, S2-Net에 비하여 EM 1.31%, F1 0.98% 더 좋은 성능을 보였다.
표
2. 한국어 기계 독해 모델 별 성능 (single, %)
Model Dev Test
EM F1 EM F1
DrQA (baseline) [2]
64.22 77.04 - -DrQA+BiSRU [5]
67.38 79.90 - -S
2-Net [5]
67.99 80.39 68.12 80.55S
3-Net (our)
70.08 81.78 69.43 81.534.
결론본 논문에서는 계층 구조를 가진 S3-Net를 이용한 한국어 기계
독해 모델을 제안하였고, S3-Net과 DrQA, DrQA+BiSRU, S2-Net에 대한 비교 실험을 수행하였다. 실험 결과, 본 논문에서 제안한 방 법인 S3-Net이 다른 모델들보다 우수한 (dev) EM 70.08%, F1 81.78%, (test) EM 69.43%, F1 81.53%의 성능을 보였다.
향후 연구로는 본 논문의 모델을 지식 기반 베이스를 이용한 검색 모델과 함께 연구할 예정이다.
감사의
글
본 연구는 미래창조과학부 및 정보통신기술진흥센터의 정보통신·방송 연구개발 사업의 일환으로 하였음. [2013-0-00131, (엑소브레인-1세부) 휴먼 지식증강 서비스를 위한 지능진화형 WiseQA 플랫폼 기술 개발]
이 논문은 2017년 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임(NRF-2017M3C4A7068188)
참고문헌
[1] F. Hill, et al. The Goldilocks Principle: Reading Children's Books with Explicit Memory Representations. arXiv preprint arXiv:1511.02301, 2015.
[2] D. Chen, et al. Reading Wikipedia to Answer Open-Domain Questions, arXiv preprint arXiv:1704.00051, 2017.
[3] P. Rajpurkar, et al. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
[4] T. Nguyen, et al. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset, arXiv preprint arXiv:1611.09268, 2016.
[5] 박천음, et al. S2-Net: SRU기반 Self-matching Network를 이용한 한국어 기계 독해. 제 29회 한글 및 한국어 정보처리 학술대회, pp. 35-40, 2017.
[6] D. Chen, et al. Reading Wikipedia to Answer Open-Domain Questions, arXiv preprint arXiv:1704.00051, 2017.
[7] D. Weissenborn, et al. Making Neural QA as Simple as Possible but not Simpler, Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017). 2017.
[8] W. Wang, et al. Gated Self-Matching Networks for Reading Comprehension and Question Answering, In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1:
Long Papers), pp. 189-198, 2017.
[9] M. Seo, et al. Bidirectional Attention Flow for Machine Comprehension.
arXiv preprint arXiv:1611.01603, 2016.
[10] D. Bahdanau, et al. Neural machine translation by jointly learning to align and translate. Proc. of ICLR’ 15, arXiv:1409.0473, 2015.
[11] O. Vinyals, et al. Pointer Networks. Advances in Neural Information Processing Systems, pp. 2674-2682, 2015.
[12] T. Lei and Y. Zhang. Training RNNs as Fast as CNNs. arXiv preprint arXiv:1709.02755, 2017.
[13] Yoon Kim. Convolutional Neural Networks for Sentence Classification.
Proc. of EMNLP’ 14, pp. 1746-1751, 2014.
[14] 이창기, et al. 딥 러닝을 이용한 한국어 의존 구문 분석. 제 26회한글 및한국어정보처리학술대회, pp. 87-91, 2014.
[15] D. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.