콘텐츠 신디케이션을 이용한 웹 데이터 수집 및 활용
황 상 현*・김 희 완**
목 차 요약
1.
서론
2.관련 연구
2.1 RSS와
Atom 2.2리더
(Reader) 3.시스템 설계 및 구현
3.1설계
3.2
개발환경 및 구현 결과
4.데이터 가공 및 활용
4.1데이터 가공 제안
4.2활용 서비스
5.결론
참고문헌
Abstract요약
ㄴ
웹 상에는 수 많은 데이터가 존재하고 있지만 원하는 데이터를 수집하여 서비스 제공을 위한 콘텐츠로 가공해 내는 것은 쉽지 않다. 그 이유 중 하나가 바로 표준화된 데이터 제공 방식이 없기 때문이다. 따라서 사이트 콘텐츠의 일부 또는 전체를 다른 서비스에서 이용할 수 있도록 해주는 콘텐츠 신디케이션은 매우 중요하다고 볼 수 있다.
콘텐츠 신디케이션의 대표적 포맷으로 XML에 기반한 RSS와 Atom, OPML 등이 있다. 이러한 신디케이션 포맷에서 제공하는 링크를 통틀어 피드 주소라고 한다. 피드 주소를 이용하면 기존 HTML을 파싱하는 것 보다 빠르게 데이터를 수집할 수 있고 데이터 제공자는 간편하게 데이터를 외부로 제공할 수 있다는 장점이 있다.
본 논문에서는 피드 주소를 기반으로 하는 웹 데이터 수집 시스템을 구현하여 수집하여 얻은 데이터를 바탕으로 해당 데이터를 가공하고 활용하는 방법을 제안하였다.
표제어: 웹 데이터 수집, 웹 신디케이션, RSS, Atom
접수일(2015년 8월 10일), 수정일(1차: 2015년 9월 15일), 게재확정일(2015년 9월 15일)
* 삼육대학교 컴퓨터학부, [email protected]
** 교신저자, 삼육대학교 컴퓨터학부 교수, [email protected]
1. 서론
웹에는 다양한 데이터가 존재하고 있지만 이러한 많은 데이터 중에서 원하는 데이터를 수집하여 가공 하는 것은 쉽지 않다. 그 이유 중 하나가 바로 표준화 된 데이터 제공 방식이 없기 때문이다.
콘텐츠 신디케이션(Content Syndication)이란, 사이 트 콘텐츠의 일부 또는 전체를 다른 서비스에서 이용 할 수 있도록 하는 것을 말한다[1]. 대표적인 컨텐츠 신디케이션 포맷으로는 RSS(Really Simple Syndication) 와 Atom, OPML(Outline Processor Markup Language) 등이 있으며 이러한 신디케이션 포맷에서 제공하는 링크를 피드 주소(Feed Address)라고 한다.
피드 주소는 W3C에서 규정한 다목적 마크업 언어 인 XML(eXtensible Markup Language)에 기반하여 만 들어졌으며, 웹 피드(web feed) 또는 뉴스 피드(news feed)라고도 하는데 사용자에게 자주 업데이트되는 콘텐츠를 제공하는 데 주로 이용되어져 왔다.
2000년대 초중반 Web 2.0 시대의 핵심 기술 중 하나 로 주목을 받아 블로그를 중심으로 한 대부분의 서비 스에서 RSS 2.0 또는 Atom 0.3의 형식으로 광범위하게 제공되어 왔으나 최근 SNS(Social Network Service)가 발달하면서 피드 주소를 기반으로 하는 관련 서비스들 은 급격히 쇠퇴하였다.
하지만 피드주소는 기존에 HTML 파싱(parsing)보다 빠르고 간편하게 데이터를 제공할 수 있고 수집할 수 있다는 장점이 있다. 따라서 현재는 뉴스나 팟 캐스팅 과 같은 미디어 배포의 용도로도 사용되고 있다[2].
이에 본 논문에서는 피드 주소를 이용하여 데이터 를 수집하고 가공 및 활용하는 방법을 제안한다.
2. 관련 연구
2.1 RSS와 Atom
데이터 수집을 위해서는 기본적으로 데이터 제공자
가 RSS 2.0 또는 Atom 0.3 표준을 바탕으로 데이터를 출력하여 피드주소를 제공해야 한다. 기본적인 형식 에 대한 정의는 각각 그림 1, 그림 2와 같다[3].
<?xml version=“1.0” encoding=“UTF-8”?>
<rss version=“2.0”>
<channel>
<title>제목</title>
<link>주소</link>
<description>요약 설명</description>
<item>
<title>제목</title>
<link>글(콘텐츠) 주소</link>
<description>내용</description>
<pubDate>시간</pubDate>
</item>
</rss>
그림 1. RSS 2.0의 기본 형식 Fig. 1. Basic format of RSS 2.0
RSS는 Netscape사에서 신문사의 기사를 쉽게 제공 하기 위해 고안되었으며 빠른 구독과 히스토리 관리, 콘텐츠 재사용성 향상 등의 장점이 있다.
초기 RSS 0.9x에서 다양한 확장 태그를 추가한 RSS 2.0은 기본 형식에 <category>나 <image> 등의 태그를 포함하여 콘텐츠의 태그(키워드)나 이미지를 넣을 수 있다. 또한 <enclosure> 태그 내에 MP3나 MOV 등의 미디어 파일을 첨부하여 배포할 수도 있다.
RSS가 확산되면서 콘텐츠 신디케이션의 인식과 중 요도가 높아지면서 새 기능과 표준화 요구의 필요성 이 증가하였다. 그러나 RSS의 한계로 인하여 새 프로 젝트인 Atom이 등장하게 된다[4, 5].
Atom은 기존 RSS의 뉴스나 블로그 뿐만 아니라 검 색엔진 등 다양한 웹 서비스의 API(Application Pro- gramming Interface)로도 활용할 수 있으며, 엔트리 (Entry)라는 최소단위로 구성된다. 이후 Atom 1.0이 발표되어 RFC 인터넷 표준의 제안표준(proposed stan- dard)으로 인정을 받았다.
이렇듯 서비스 제공자는 피드에는 다양한 콘텐츠를
포함하여 제공할 수 있다. 다만 아직까지도 일부 제공
자는 표준 형식이 아닌 자체 형식으로 데이터를 제공
하고 있어 앞서 언급 한 것처럼 표준화가 요구되어 지 고 있다. 표준화가 이루어지지 않는 경우에는 수집 시 이에 대한 예외처리가 필요하다[6].
<?xml version=“1.0” encoding=“utf-8”?>
<feed
xmlns=“http://www.w3.org/2005/Atom”>
<title>제목</title>
<subtitle>소제목</subtitle>
<link href=“주소”/>
<updated>시간</updated>
<author>
<name>이름</name>
<email>이메일</email>
</author>
<id>고유값 (주소)</id> <entry>
<title>글(콘텐츠) 주소</title>
<link href=“주소”/>
<id>고유값 (주소)</id>
<updated>시간</updated>
<summary>내용 요약</summary>
</entry>
</feed>
그림 2. Atom 0.3의 기본 형식 Fig. 2. Basic format of Atom 0.3 2.2 리더(Reader)
서비스 제공자가 웹 신디케이션 형식에 맞추어 피드 주소를 제공한다면 해당 피드 주소에 접근하여 데이 터를 수집할 수 있다. 데이터를 수집은 리더(Reader) 를 사용하는데 리더는 해당 피드의 형식을 분석하고 파싱하는 역할을 수행한다.
리더는 해당 피드 주소에 접근하여 전문을 읽어 온 뒤 RSS 태그를 바탕으로 각 데이터를 식별한다. 세부 적인 수집 원리는 기존의 피드 리더기와 동일하나 제 안하는 방법에서는 웹 데이터의 수집을 위해 미리 다 량의 피드 주소를 수집 대상 데이터베이스에 등록한 다. 등록이 완료되면 다량의 피드 주소에 접근하여 데 이터를 수집한다. 신디케이션 포맷만 표준 형식으로 작성되어 제공된다면 등록할 수 있는 피드 주소에는 콘텐츠 분류나 범위에는 제한이 없지만 리더의 형태 에 따라 제공 포맷은 달라질 수 있다.
그림 3. 수집대상의 피드주소 Fig. 3. Feed Address of Collection Object
수집 대상의 리스트를 가지고 수집 리더는 특정 주 기로 해당 피드주소에 접속하여 관련 콘텐츠를 가져 와 별도의 데이터베이스에 저장한다. 또한 해당 콘텐 츠 내용에 변경 사항이 있는 경우 지속적으로 업데이 트를 하여 데이터베이스를 갱신 한다.
피드 주소는 제공자에 따라 기본적인 데이터 외에 도 사진과 태그, MP3 타입 등이 포함될 수 있다. 사진 과 태그는 블로그 콘텐츠에서 많이 이용되고 있으며 MP3 타입은 팟 캐스트에서 그림 4와 같이 널리 사용 되고 있다.
그림 4. 팟 캐스트 RSS 형식 Fig. 4. Podcast RSS format
리더로부터 수집된 콘텐츠들은 각 데이터 형태 별
로 자동으로 분류되어 각각의 데이터베이스 영역에
저장된다. 피드 내에 포함된 이미지는 원본을 그대로
저장하거나 축소하여 썸네일(Thumbnail) 이미지를 저
장한다. 오디오나 비디오 형식 또한 원본을 수집하여
저장할 수 있다.
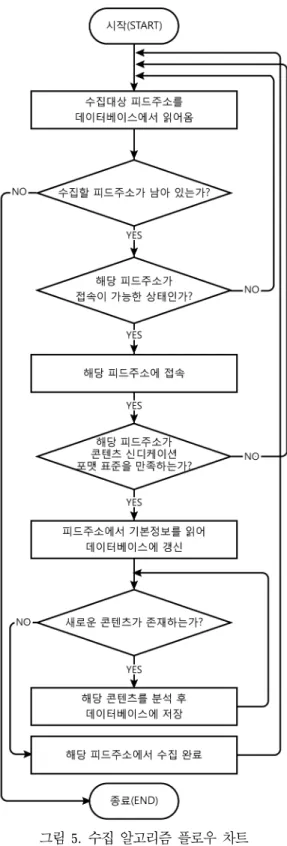
그림 5. 수집 알고리즘 플로우 차트 Fig. 5. Collection Algorithm Flowchart 3. 시스템 설계 및 구현
3.1 설계
웹 데이터를 수집하고 가공하기 위해 피드 주소를 기반으로 하는 웹 데이터 수집 시스템(리더)을 구현하 였다.
3.1.1 수집 알고리즘
시스템이 데이터를 수집하는 알고리즘에 대한 플로 우 차트는 그림 5와 같다.
먼저 데이터베이스 상에서 수집 대상 피드주소 데 이터를 읽고 해당 피드가 접속 가능한지 확인한다. 이 후에 RSS 2.0 또는 Atom 0.3의 표준을 만족 하는지 분 석하여 해당 피드주소가 표준을 만족 시, 기본정보를 데이터베이스에 갱신하고 피드에 포함된 각 엔트리와 콘텐츠를 분석하여 데이터를 저장한다. 이 과정을 데 이터베이스 상에 존재하는 피드의 수만큼 반복하게 된다.
3.1.2 테이블 구조
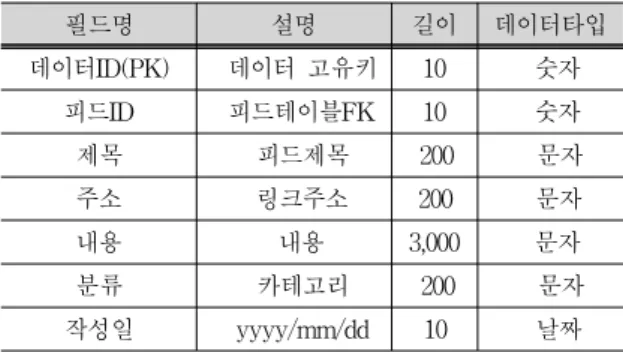
수집 시스템에서 사용하는 테이블은 수집 대상 테 이블과 피드 데이터를 저장하는 저장 테이블로 구성 된다. 테이블 표 1과 표 2는 각 테이블의 테이블 정의 서를 보여준다.
필드명 설명 길이 데이터타입
피드ID(PK) 피드 고유키 10 숫자
피드URL 피드주소 200 문자
피드제목 피드제목 200 문자
피드형식 피드표준형식 10 문자
피드언어 피드제공언어 10 문자
피드상태 피드상태 10 문자
최근 수집일 yyyy/mm/dd 10 날짜
표 1. 수집대상 테이블 정의서
Tab. 1. Table Definition of Collection Target
수집 대상 테이블에는 다수의 피드 주소를 등록하 고 수집 시스템이 일정 주기로 접근하여 해당 피드 주 소에 접근하여 수집하는 방식으로 이루어진다. 이때 피드제목과 형식, 언어, 상태, 최근 수집일은 접근 시 마다 갱신된다.
필드명 설명 길이 데이터타입
데이터ID(PK) 데이터 고유키 10 숫자
피드ID 피드테이블FK 10 숫자
제목 피드제목 200 문자
주소 링크주소 200 문자
내용 내용 3,000 문자
분류 카테고리 200 문자
작성일 yyyy/mm/dd 10 날짜
표 2. 수집데이터 테이블 정의서 Tab. 2. Table Definition of Collection Data
수집 데이터 테이블에는 피드주소에 접근하여 수집 한 데이터를 저장한다. 이미 동일한 글이 있는 경우는 주소 값으로 중복 데이터를 확인 후에 기존 콘텐츠에 대하여 갱신처리를 진행한다.
3.2 개발환경 및 구현 결과
3.2.1 개발환경
시스템 개발환경은 표 3과 같다.
구 분 내용
개발언어 JAVA
데이터베이스 환경 MYSQL 5.X
개발환경 JDK 1.8, TOMCAT 8
OpenShift Enterprise
표 3. 시스템 개발환경
Tab. 3. System development Environment
3.2.2 구현 결과
구현된 시스템은 수집 대상 피드 데이터의 수만큼
리더를 호출하여 각 피드에 접근하게 된다. 이 후 수 집 알고리즘에 따라 수집을 진행 하게 된다. 아래는 데이터를 수집하는 실례로서 그림 6, 그림 7 그리고 그림 8에서 보여주고 있다.
그림 6. 수집대상 데이터 Fig. 6. Collection target data
그림 7. 수집된 데이터 Fig. 7. Collected Data
그림 8. 수집로그 기록 Fig. 8. Collecting log record 4. 데이터 가공 및 활용
4.1 데이터 가공 제안
피드 주소를 통하여 수집된 데이터에는 콘텐츠와
이미지, 오디오 등 다양한 멀티미디어 데이터를 포함
한다. 수집 범위와 형태, 제공자에 따라서 다양하게 변화할 수 있다. 이렇게 수집한 데이터를 적절하게 가 공하여 활용하는 방안에 대하여 제안한다.
본 논문에서는 앞서 구현한 시스템을 바탕으로 블로 그와 커뮤니티 사이트에서 제공되는 약 3,200여 개의 피 드 주소를 바탕으로 수집한 데이터를 활용하였다.
4.1.1 데이터 통계
그림 9. 태그 정보 통계 Fig. 9. Tag Information Statistics
그림 9는 블로그에서 콘텐츠 작성시 글 게시자가 작성하는 태그(키워드)를 수집하여 통계를 낸 것이다.
관심 분야나 자주 방문한 식당을 알 수 있다. 데이터 의 수집기간과 주제를 지정할 경우에는 보다 상세한 데이터의 추출이 가능하다.
4.1.2 검색어 제안
데이터 통계와 마찬가지로 수집한 태그를 바탕으로 검색어 제안(자동완성)에 활용할 수 있다.
이는 현재 SNS에서 제공하고 있는 해시태그(hash tag)를 통한 콘텐츠 검색과 동일한 부분이며 새로운 기술이 아닌 기존에 블로그의 태그 기능에서 고안된 것이다.
그림 10. 검색어 제안 Fig. 10. Keyword suggest list
태그는 검색의 편리함과 효율성을 높이기 위하여 도입된 기능이지만 최근에는 특정 주제에 대한 관심 을 드러내는 수단으로 활용되어지고 있다. 이를 응용 하면 마인드 맵(mind map)과 같은 형태로도 데이터를 가공하여 서비스 제공에 활용할 수 있다.
4.1.3 이미지 타일
그림 11. 피드에서 추출한 이미지타일 Fig. 11. Image-tile Derived from Feed
수집한 데이터 중에서 이미지만 별도로 추출하는
경우 그림 11과 같은 형태로 이미지 타일 구현이 가능
하다. 또한 수집된 이미지 데이터를 바탕으로 크기와
색상, 유형(사람/사물)등의 구체적인 정보로 필터를 하
는 경우 포털 사이트의 이미지 검색과 유사한 서비스
를 구현할 수 있다.
4.1.4 기타 활용방안
앞서 언급한 내용 외에도 뉴스, 주식 시세, 실시간 데이터 검색 등의 다양한 영역의 데이터를 활용할 수 있다. 따라서 SNS에서 제공되는 피드 주소를 활용할 경우 더 방대한 데이터를 수집할 수 있다. 원하는 데 이터를 얻어내기 위해서는 다양한 데이터 가공 및 활 용 방식이 필요하다.
4.2 활용 서비스
4.2.1 팟 캐스트, 팟빵
Apple사의 아이튠즈와 비슷한 서비스로 기존 iOS에 서만 사용할 수 있었던 팟 캐스트 서비스를 웹이나 안 드로이드에서도 청취 할 수 있도록 하였다. RSS 피드 를 통하여 제공되며 대표적인 국내 팟 캐스트 포털 서 비스이다. 현재 약 6,000여 개의 라디오 또는 개인 방 송을 청취할 수 있으며 모든 데이터는 피드를 통하여 실시간으로 업데이트 된다.
그림 12. 팟 캐스트 용 모바일 어플리케이션 Fig. 12. Podcast Mobile Application
4.2.2 메타 블로그, 콜콜넷
개별 블로그를 하나로 묶기 위한 일종의 블로그 포털 사이트로 블로거가 피드 주소를 등록하면 블로 그에 새 글을 작성할 때마다 메타 블로그에 새 글 목 록으로 추가되는 형태로 특정 블로그를 알지 못해도 여러 블로그의 글을 한 곳에서 볼 수 있다.
그림 13. 메타블로그 서비스 Fig. 13. Meta-blog Service 5. 결론
국내에서는 주로 블로그에서 제공되는 RSS나 Atom 같은 피드는 초기에 신문기사를 손쉽게 제공하기 위하 여 제안되었으며 Web 2.0 시대에 들어 핵심 기술로 주 목 받게 되었다. 그러나 최근 들어 SNS가 우리 사회에 서 인기를 끌면서 기존 블로그와 같은 서비스는 점점 설 자리를 잃어가고 있다. 블로그를 통하여 제공되었 던 피드는 근래 들어서 제공 및 사용 범위가 매우 축소 되었고 표준 형식에 일부 정보를 추가하여 팟 캐스트 서비스 등에만 이용되어지고 있다. 하지만 피드 주소 를 데이터 수집에 이용하면 기존에 HTML 파싱보다 빠 르고 간편하게 데이터를 수집할 수 있다. 따라서 대부 분의 사이트에서 다양한 피드 주소를 제공한다면 이 러한 피드 주소 정보를 한 곳에 모은 뒤 주기적으로 리더가 데이터를 수집한다면 방대한 데이터를 확보할 수 있다. 단순한 텍스트 데이터뿐만 아니라 이미지나 MP3와 같은 미디어 데이터도 손쉽게 수집이 가능한 것 이다. 피드 주소의 가치를 재발견하여 피드 형태로 데 이터를 제공하는 제공자가 늘어나고 이렇게 수집한 데이터가 적절하게 가공되어 활용되기를 기대한다.
참 고 문 헌
[국내 문헌]
[1] 강필구, 김재환, 이상준, 채진석 (2007), “웹 2.0 기
반 RSS 데이터 수집 엔진의 설계 및 구현”, 한국멀티
미디어학회 멀티미디어학회논문지, 10(11), 1496-
1506.
[2] 현미환, 이상환, 이태석, 예용희 (2007), “RSS 기반 과학기술정보 수집시스템의 개발과 활용방안에 관한 연구”, 한국콘텐츠학회 종합학술대회 논문 집, 5(2-1), 405-409.
[3] 강필구, 김남중, 이예슬, 채진석 (2006), “웹 2.0을 위한 효율적인 태그 관리 시스템의 설계 및 구축”, 한국정보과학회 학술발표논문집, 33(2_D), 170-173.
[국외 문헌]
[4] Cong, Y. and Du, H. (2008), "Web Syndication Using RSS”, Journal of accountancy, 205(6), 48-53.
[웹사이트]
[5] http://atomenabled.org/developers/syndication/.
[6] http://ko.wikipedia.org/wiki/RSS.
황 상 현 (Sanghyun Hwang)
삼육대학교 컴퓨터학부 컴퓨터시스템 전공에 재학하고 있으며 주요 관심 분야는 웹, 데이터베이스 등이다.
김 희 완 (Heewan Kim)
성균관대학교에서 데이터베이스 전공으로 공학석사와 공학박사를 취득
하였고, 현재 삼육대학교 컴퓨터학부 교수로 재직 중이다. 한국전력공사에
재직하였으며, 정보관리 기술사와 정보시스템 수석감리원 자격을 보유하고
있다. 주요 관심분야는 데이터베이스, 정보시스템 감리 및 평가, 데이터
아키텍처 등이다.
Web Data Collection and Utilization using Content Syndication
Sanghyun Hwang*․Heewan Kim**
ABSTRACT
ㄴ
Many data on the web are present, put out by processing in the content in order to provide services by collecting the necessary data is not easy. One of the reasons is because there is no way to provide a standardized data. Therefore, it can be seen as a part or all of the contents of the site, the content distribution to be available for other services is very important.
A syndication format that allows you to use a representative of some or all of the site's content for other services such as RSS and there are Atom, OPML-based XML. Throughout the links provided in this syndication format is called feed address. With a feed address to collect data faster than the conventional HTML parsing and data provider is the advantage of being able to easily provide the data to the outside.
In this study, we feed the data obtained by collecting by implementing the web address based on the data acquisition system to propose a method for processing and utilizing the data as a background.
Keywords: Web Syndication, Web Data Collection, RSS, Atom
1)