Article
http://dx.doi.org/10.4217/OPR.2019.41.3.183 Ocean and Polar Research September 2019
효과적인 자원평가모델 선정을 위한 잉여생산량모델의 비교 분석:
동해 생태계의 잠재생산량 분석을 대상으로
최민제 · 김도훈
*
국립부경대학교 수산과학대학 해양수산경영학과 (48513) 부산광역시 남구 용소로 45
Comparing Surplus Production Models for Selecting Effective Stock Assessment Model: Analyzing Potential Yield of East Sea, Republic of Korea
Min-Je Choi and Do-Hoon Kim
*
Department of Marine & Fisheries Business and Economics, College of Fisheries Sciences, Pukyong National University, Busan 48513, Korea
Abstract : This study sought to find which model is most appropriate for estimating potential yield in the East Sea, Republic of Korea. For comparison purposes, the Process-error model, ASPIC model, Maximum entropy model, Observation-error model, and Bayesian state-space model were applied using data from catch amounts and total efforts of the whole catchable fishes in the East Sea. Results showed that the Bayesian state-space model was estimated to be the most reliable among the models. Potential yield of catchable species was estimated to be 227,858 tons per year. In addition, it was analyzed that the amount of fishery resources in 2016 was about 63% of the biomass that enables a fish stock to deliver the maximum sustainable yield.
Key words : bayesian state-space model, observation-error model, surplus production, stock assessment, East Sea, Korea
1. 서 론
전 세계적으로 해면어업의 생산량은 감소추세에 있다.
1996 년 약 8,740만 톤으로 최대치를 기록한 후 지속적으 로 감소하여 2016년에는 약 7,990만 톤을 기록하였다 (FAO 2018). 우리나라 해면어업의 생산량 또한 예외가 아 니다. 1986년 173만 톤을 기록한 이후 감소추세에 있다.
특히 2016년 이후에는 해면어업의 연간 생산량이 100만 톤에도 미치지 못하고 있다. 구체적으로 2017년 어획량은 약 93만 톤으로, 5년 전 2012년 대비 약 85%, 그리고
1986년 대비 약 54%에 수준에 머무르고 있다(통계청 2018).
수산자원의 관리를 위한 노력은 전 세계적으로 이루어 져 왔지만, 남획어종의 비율은 1974년 10%에서 2013년 31.4% 로 지속적으로 증가하는 추세를 보이고 있다(FAO 2016). 이러한 상황을 개선하기 위하여 최근 다양한 방안 들이 강구되고 있다. 특히 불확실성을 고려할 수 있는 보 다 정교한 자원평가 모델을 제시하고, 기존 자원평가 모델 결과와의 비교·분석을 통해 보다 효과적인 수산자원의 평 가와 관리를 위한 시도가 국내·외에서 이루어지고 있다 (McAllister and Ianelli 1997; Millar and Meyer 2000a;
Zhang and Lee 2001; Bolker 2008; Zhang et al. 2009; 김
*Corresponding author. E-mail : [email protected]
등 2018; Winker et al. 2018). 그 중 하나의 사례로 전통 적 자원평가 모델 중 하나인 잉여생산량 모델을 다양한 분석법에 적용하여 보다 현실적인 추정치를 도출하기 위 한 노력이 활발하게 이루어지고 있다(Clarke et al. 1992;
Polacheck et al. 1993; Meyer and Millar 1999; Chaloupka and Balazs 2007; 김 등 2018; 임 등 2018).
잉여생산량 모델은 어획량과 어획노력량 자료를 이용한 자원평가 모델로 시계열 변수의 적용 여부에 따라 크게 정태적 분석방법(equilibrium method)과 동태적 분석방법 (dynamic method)으로 구분할 수 있다(Bolker 2008;
Haddon 2010). 그러나 정태적 분석방법의 경우 대상자원 에 대한 평형상태를 가정하는 등 평가결과가 다소 부정확 한 것으로 지적되고 있다(Haddon 2010). 특히, 고갈되고 있는 자원에 대해서는 지속적 어획량을 과대평가하는 문 제가 발생하는 등 적용상에 있어 주의가 필요한 것으로 제기되고 있다(Boerema and Gulland 1973). 동태적 분석 방법은 분석기법에 따라 다시 과정오차 모델(process-error model), 관측오차 모델(observation-error model), 그리고 Bayesian state-space 모델 등으로 구분할 수 있다(Schnute 1977; Punt 1990; Polacheck et al. 1993; Millar and Meyer 2000b; de Valpine and Hilborn 2005).
과정오차 모델은 국내 자원평가에 가장 널리 활용되고 있는 평가기법 중 하나이다(장 등 1992; 박 등 2000; 남 등 2015). 그러나 과정오차 모델의 경우 대표본일 때도 추 정결과가 편의성을 갖는 것으로 나타나 부정확한 평가결 과를 도출할 수 있는 것으로 나타났다(Uhler 1980). 이러 한 문제를 해결하기 위해 개발된 모델이 관측오차 모델이 며, 통상적으로 관측오차 모델의 추정결과가 과정오차 모 델의 추정결과보다 현실에 부합하는 것으로 분석되었다 (Hilborn and Waters 1992; Polacheck 1993). 그럼에도 불 구하고 두 모델 모두 자원평가에서 발생하는 오차인 과정 오차와 관측오차를 동시에 고려하지 못한다는 한계가 존 재한다. 반면, Bayesian state-space 모델은 과정오차와 관 측오차를 동시에 고려하여 자원평가 결과를 산출하는 것 이 가능하다. 이러한 장점으로 최근 국외 및 국제수산기구 에서 널리 활용되고 있으며, 구체적으로 하와이 바다거북, 대서양 흉상어, 남대서양 날개다랑어 등에 적용되었다 (Millar and Meyer 2000b; McAllister et al. 2001;
Chaloupka and Balazs 2007; McAllister 2014; Winker et al. 2018; ICCAT 2018). 하지만 관측오차 모델과 Bayesian state-space 모델을 이용한 국내 자원평가 연구는 아주 제 한적인 실정이다.
이러한 배경 하에 본 연구에서는 다양한 자원평가모델 을 이용하여 분석이 실시된 임 (2018)의 동해 생태계의 잠 재생산량 추정 연구에 사용된 분석자료를 관측오차 모델 과 Bayesian state-space 모델을 이용해 분석하고자 한다.
그리고 분석결과를 임 (2018)의 연구에서 활용한 Fox 모 델, ASPIC 모델, 그리고 Maximum entropy 모델 결과들 과 비교·분석하여 보다 효과적인 자원평가모델과 분석결 과를 제시하고자 한다.
2. 분석 방법 및 자료
잉여생산량 모델
잉여생산량 모델은 자원의 가입량과 성장량의 합에서 자원의 자연사망으로 인한 감소 부분을 뺀 것을 자원의 잉여생산으로 가정하여 자원평가를 실시하는 것으로 다음 과 같이 정의된다.
(1) 여기서, B y 는 y년도의 자원량, 은 자원의 잉여생산 량, 그리고 C y 는 y년도의 어획량을 의미한다. 잉여생산량 은 형태에 따라 식 (2)와 같은 로지스틱(logistic) 모 형과 식 (3)의 지수(exponential) 모형 등으로 구분된다.
(2)
(3)
식 (2)는 Schaefer (1954)에 의해 고안되었으며, 식 (3) 은 Fox (1970)에 의해 제안되었다. 여기서, r은 수산자원 의 본원적 성장률(intrinsic growth rate), 그리고 K는 환경 수용력(carrying capacity) 혹은 수산자원이 전혀 이용되지 않은 상태를 의미한다.
어획량(C y ) 을 어획노력량(E y ) 으로 나누면 식 (4)와 같은 단위노력당어획량(I y )을 구할 수 있고, 자원량(B y )과의 관 계를 파악할 수 있다.
(4)
여기서, C y 는 y연도의 어획량, E y 는 y연도의 어획노력량, I y 는 y연도의 단위노력당어획량(CPUE), 그리고 q는 어획 능률계수(catchability coefficient)를 의미한다.
관측오차 모델
관측오차 모델은 수산자원의 평가에 이용되는 함수는 확정적이기 때문에 오차가 발생하지 않고, 모든 오차는 관 측자료인 CPUE에서 발생한다고 가정하며 다음의 식 (5) 와 같이 나타낼 수 있다(Polacheck et al. 1993).
(5) B y 1 + = B y + g B ( ) C y – y
g B ( ) y
g B ( ) y
g B ( ) rB y y 1 B y --- K
⎝ – ⎠
⎛ ⎞
=
g B ( ) rB y y Ln K ( ) 1 ln B ( ) y ln K ( ) ---⎠ ⎞ –
=
I y C y E y --- qB y
= =
Iˆ y C ˆ
y
E y
--- qB y e ε , ε~N o;σ ( 2 )
= =
여기서, e ε 는 관측자료에서 발생하는 오차이며, 로그정규 분포의 형태를 갖는 것으로 가정한다. 관측오차 모델에서 는 관측자료를 확률적으로 고려할 수 있는 최대우도추정 법(Maximum likelihood estimation)을 이용하여 자원평가 결과를 도출한다(Haddon 2010). 최대우도추정법은 수집 된 표본을 통하여 표본에서 얻은 우도가 최댓값이 되도록 하는 모수들의 추정치를 계산하는 것으로, 관측오차 모델 에서 표본은 CPUE이고, 추정모수는 초기 자원량(B 0 ), 본 원적 성장률(r), 환경수용력(K), 그리고 어획능률계수(q) 등이다.
(6)
(7)
(8)
구체적으로 관측오차 모델에서는 최대우도추정법을 사 용하기 위해 식 (6)과 같은 우도함수를 이용한다. 여기서, 는 추정된 모수의 값에 따라 나타나는 관측치의 우도이며, n은 관측자료의 개수이다. 식 (6)의 함수식 양변에 로그를 취하여 정리하면 식 (8)과 같은 로 그우도함수의 형태를 도출할 수 있다. 식 (8)의 로그우도 함수를 최대화함으로써 관측오차 모델을 이용한 자원평가 결과를 도출할 수 있다(Haddon 2000).
Bayesian state-space 모델
Bayesian state-space 모델은 베이지안 추론(Bayesian inference) 을 바탕으로 자원평가를 수행한다. 베이지안 추 론은 관측된 자료와 모수 모두에 확률모형을 사용하는 것 으로, 베이지안 추론의 특징은 추론의 대상이 되는 모수는 불확실하며 이를 확률모형으로 가정한다는 것이다. 또한 베이지안 추론은 주어진 문제에서 관측된 자료에 포함된 정보와 사전정보를 결합하여 사후분포를 계산한 후 이를 근거로 통계적 추론을 수행하는 방법이다. 이에 따라, 베 이지안 추론에는 분석대상에 대한 분석자료뿐만 아니라 분석대상에 대한 사전정보가 필요하다(Meyer and Millar 1999; 김 2013). 결과적으로, Bayesian state-space 모델을 이용하면 수산자원평가에 활용되는 자원평가 함수와 관측 자료 모두에서 발생할 수 있는 오차를 고려하여 자원평가 결과를 산출할 수 있다.
Bayesian state-space 모델의 추정을 위해 B y 를 재구성 (P y = B y /K) 하였으며, 오차는 로그정규분포를 따르는 것으 로 가정하여 추정하였다(Millar and Meyer 2000b).
(9)
(10)
Bayesian state-space 모델의 추론은 베이즈 정리를 기 반으로 한다. 베이즈 정리에 따르면 수산자원의 생물적·기 술적 계수에 대한 사전분포와 관측자료로부터 얻어진 우 도를 바탕으로 사후분포를 추정할 수 있다(김 2013). 수산 자원의 생물적·기술적 계수에 대한 결합사전확률밀도 (joint prior density) 함수는 식 (11)과 같이 나타낼 수 있다.
(11)
사전분포에 대해서는 McAllister et al. (1994)와 Punt and Hilborn (1997)에 따라 정보적(informative) 사전분포 를 가정하고, Meyer and Millar (2000b)와 임 (2018)을 참 고하여 설정하였다. 구체적으로 Table 1에서 정리된 바 와 같이, 동해 생태계의 잠재생산량 추정을 위한 변수들 의 사전분포는 우선 r의 경우 평균(μ r ) -1.38, 표준편차 (σ r ) 0.51인 로그정규분포(Lognormal distribution)로 설 정하였다. q는 μ q = 1 과 σ q = 1 인 역감마분포(Inverse- gamma distribution), K 는 μ K = 16 과 σ K = 0.75 인 역로그정 규분포(Inverse-lognormal distribution), σ 2 은 = 3.79와
= 0.01인 역감마분포, 그리고 τ 2 은 = 3.79와
= 0.01 인 역감마분포로 설정하였다.
그리고 각각의 생물계수가 특정한 값을 가질 때 해당 관측자료가 발생할 확률인 우도는 식 (12)와 같이 나타낼 수 있다.
L data B ( 0 , , , r K q ) 1 I y 2πσˆ ---e
lnI
y– lnIˆ
y( )
2– 2σˆ
2---
∏ y
=
σˆ 2 ( lnI y – lnIˆ y ) 2 --- n
∑ y
=
LL n
2 --- Ln 2 ( ( ) 2Ln σˆ π + ( ) 1 + ) –
=
L data B ( 0 , , , r K q )
P 1 σ 2 = e u
0P y P y 1 – , , , K r σ 2 P y 1 – rP y 1 – ( 1 P – y 1 – ) C y 1 – --- K –
⎝ + ⎠
⎛ ⎞e u
y=
I y P y , , q τ 2 = qKP y e v
yp K r q ( , , , , , , , σ 2 τ 2 P 1 … P N )
p K ( )p r ( )p q ( )p σ ( )p τ 2 ( )p P 2 ( 1 σ 2 )
=
p P ( y 1 + P y , , , K r σ 2 )
y 1 =
∏ N
×
μ σ
2σ σ
2μ τ
2σ τ
2Table 1. Summary of prior probability density functions used for parameters
Parameter Form of prior
distribution Mean Standard error
r Lognormal -1.38 0.51
q Inverse-gamma 1 1
K Inverse-lognormal 16 0.75
σ
2Inverse-gamma 3.79 0.01
τ
2Inverse-gamma 3.79 0.01
(12)
베이즈 정리에 따라 식 (11)과 (12)를 결합하여 식 (13) 과 같은 사후분포를 추정할 수 있다.
(13)
추정된 사후분포로부터 각각의 계수를 산출하기 위해서 는 사후분포에 대한 적분 계산이 필요하다. 그러나 Bayesian state-space 모델에서 사후분포 추정의 대상이 되 는 값은 K, r, q, 과정오차(σ 2 ), 관측오차(τ 2 ), 그리고 연도 별 자원량( ) 등으로 총 (N + 5) 차원의 다차원적 적분 계산이 필요하다. 이러한 다차원적 적분 계산을 수치 적으로 수행하는 것은 거의 불가능하고, 주로 사용되는 방 법이 마코브체인 몬테카를로(Markov Chain Monte Carlo, MCMC) 기법이다(Millar and Meyer 2000b).
마코브체인 몬테카를로 기법은 다차원적 적분 계산을 통계적으로 수행하는 방법으로 사전분포와 관측치로부터 계산된 우도를 바탕으로 랜덤표본추출을 통해 사후분포를 도출하는 방법이다. 하지만 위의 식 (13)과 같은 다차원의 결합확률분포의 경우 랜덤표본의 생성이 어려워 식 (14) 와 같이 다른 변수들의 조건부확률분포로부터 변수를 하 나씩 순차적으로 추출하게 되는데, 이를 깁스 샘플링 (Gibbs sampling)이라 한다. 깁스 샘플링을 이용한 마코브 체인 몬테카를로 기법에는 사후분포 추정을 위한 다양한 알고리즘이 존재한다. 본 연구에서 사용된 WinBUGS 프 로그램은 추정변수 각각의 분포형태를 고려하여 적절한 알고리즘을 선정한 후 사후분포를 도출한다(Lunn et al.
2000; Kéry and Schaub 2011).
simulate
simulate
simulate
(14)
위 과정과 같이 순차적인 표본추출을 m번 반복하면 각 각의 변수에 대한 사후분포를 식 (15)와 같이 추정할 수 있다.
(15)
모델 검정
자원평가모델 간 비교를 위해서 각 모델에 대한 오차의 제곱평균제곱근(Root Means Square Error, RMSE)과 결 정계수(R 2 ) 를 계산하여 모델 간 적합성을 비교하였다.
RMSE = (16)
(17)
여기서 는 실제 CPUE, 는 모델에 의해 추정된 CPUE, 는 전체 CPUE의 평균값을 의미한다.
분석 자료
관측오차 모델과 Bayesian state-space 모델의 추정에는 동해 생태계의 잠재생산량 추정을 위해 임 (2018)의 연구 에서 사용된 동해 연근해어업의 어획량 및 표준화된 어획 노력량 자료를 사용하였다(APPENDIX A). 구체적으로, 해당 자료는 1966~2016년까지 강원도와 경상북도 지역에 서 조업 중인 어선들의 어획량과 톤수 자료를 활용하였 다. 또한 어로기술 개발에 따른 어획효율의 변화를 고려하 기 위하여 NIFS (2016)와 Seo et al. (2017)의 연구에서 추정된 우리나라 어업별 어획성능지수를 활용하여 연도별 어획노력량 자료를 표준화하였다.
3. 분석 결과
Bayesian state-space 모델 추정 결과
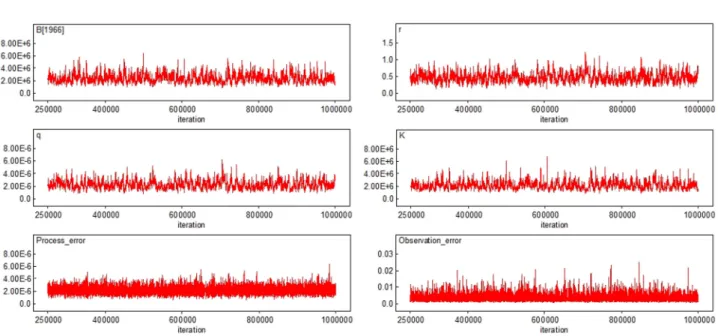
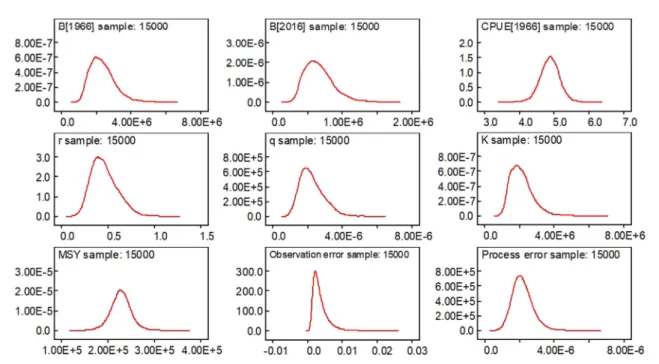
본 연구에서는 WinBUGS 프로그램(http://www.mrc- bsu.cam.ac.uk/) 을 이용하여 Bayesian state-space 모델을 분석하였다. 구체적인 분석에 있어서는 분석모델의 유의 성을 확보하기 위하여 1,000,000개의 표본을 추출하였다.
이 중 사후분포에 수렴하지 못하는 초기 표본들의 영향을 제거하기 위해 번인(burn-in) 과정을 통해 초기 250,000개 의 표본을 제외시켰다. 또한 표본추출 과정에서 발생하는 표본 간의 자기상관 문제를 해결하기 위해 매 50번째 표 본을 추출하여 분석결과를 도출하였다.
Bayesian state-space 모델의 계산이 유의성을 가지기 p I (
1, , … I
NK r q σ , , , , , , ,
2τ
2P
1… P
N) p I (
yP
y, , q τ
2)
y 1=