2021, 32(2),283–295
설명 가능한 AI 기술을 활용한 신용평가 모형에 대한 연구
ᄎ
ᅥᆫ예은1· 김세빈2·이자윤3·우지환
4
1234신한은행 AI 통합센터 ·4고려대 기술경영전문대학원 저
ᆸ수 2020년 12월 21일, 수정 2021년 1월 21일, 게재확정 2021년 1월 27일
요 약 ᄋ
ᅵᆫ공지능기술이 발전함에 따라, 금융산업에도 인공지능기술을적용하는사례들이 증가하고 있 ᄃ
ᅡ. 그러나 인공지능기술의 경우 많은부분비선형성이 높기 때문에 결과를도출하는과정에 대한 이 ᄒ
ᅢ가 직관적이지 않는것이 문제이다. 이런 특성으로 인해서 인공지능으로 결과를도출하는과정을 ᄇ
ᅳᆯ랙박스로 표현하기도 한다. 최근 EU에서 새로운개인정보 보호 규정을만들면서, 인공지능알고리 ᄌ
ᅳ
ᆷ을 통해 도출된결과에 대해서 고객이 서비스 제공자에게 설명을요청할 수 있는 권리를보장하였 ᄃ
ᅡ. 즉,금융산업에서 인공지능기술을적용하기 위해서는, 높은정밀도뿐만 아니라 설명할 수 있는 ᄂ
ᅳᆼ력도 고려해야 한다는것이다. 본 논문에서는외부에 오픈된다양한 신용정보 데이터를활용하여, ᄋ
ᅵᆫ공지능기반의 신용평가 알고리즘을제안하였다. 이와 함께, 인공지능이 도출한 결과에 대해서, 데 ᄋ
ᅵ터의 다양한 특성들 중에서 어떤 특성이 결과 도출에큰영향을끼쳤는지 도출하는알고리즘을제안 ᄒ
ᅡ였다. 또한, 이를확장해서 인공지능이 도출한 결과의 변동이 있었을때, 변동결과를설명하는방 버
ᆸ을금융데이터에 적용하였다. 제안된방법을 통해서,금융서비스에서 인공지능기술을도입할 때, 서
ᆯ명력을제공할 수 있음을확인하였다는점에서큰의미가 있다.
ᄌ
ᅮ요용어: 디지털금융, 설명 가능한 AI, 신용평가.
1. 서론 ᄌ
ᅥᆫ통적으로 대출업을 영위하는금융기관들은 리스크관리 및 효과적인 규제 대응을위하여 신용등급 미
ᆾ 대출심사를위한 다양한 모형을 구축하여 운영하고 있다. 바젤II협약 (국제 결제은행에서 은행들의 ᄌ
ᅡ기자본비율 (BIS비율) 설정의 국제기준을제시한 것으로 은행의 재무건정성을확보하기 위한 국제협 ᄋ
ᅣ
ᆨ) 이후 이러한 모델의 고도화에 대한 필요성이 증가함에 따라, 금융기관들이 보유한 데이터를기반으 ᄅ
ᅩ 외부 신용평가사 정보를결합하여 통계적 기법을활용한 모델을사용하고 있다 (Lee 등, 1996). 이러 ᄒ
ᅡᆫ 모형들은주로 이분법 분류를담당하는로지스틱 선형 회귀 기법을기반으로 설계되었다. 따라서 모 ᄃ
ᅦᆯ의 예측력은다른머신러닝 기법에 비해 상대적으로 낮지만 결과에 대한 설명이 직관적인 장점이 있다 (Kim, 2012).
4차 산업혁명 시대를맞이하여 빅데이터와 인공지능기술이 전 산업으로확대되는가운데,금융산업 ᄃ
ᅩ 기존에 사용되던 신용평가 모형 등에 인공지능기술을도입하는시도를 진행하고 있다 (Zhen, 2019).
ᄐ ᅳ
ᆨ히 데이터 분석 기법과 머신러닝 알고리즘이 고도화됨에 따라 기존 통계 기반 모형의 예측력 향상을
1 (04513)서울특별시 중구 세종대로 55, 신한은행 AI Competency Center, 대리.
2 (04513)서울특별시 중구 세종대로 55, 신한은행 AI Competency Center, 과장.
3 (04513)서울특별시 중구 세종대로 55, 신한은행 AI Competency Center, 행원.
4 교신저자: (04513) 서울특별시 중구 세종대로 55, 신한은행 AI Competency Center, 부부장.
Email: jihwan [email protected]
ᄋ
ᅱ한 다양한 시도가 진행되었다 (Zhen, 2019). 주요 내용으로는, 기존의금융데이터뿐만 아니라 대안 ᄃ
ᅦ이터를활용하여 분석의 범위를넓히는방법과 부스팅 기반의 머신러닝 모델이나 딥러닝과 같은 복잡 ᄒ
ᅡᆫ 모형을적용하는방법들이 존재한다 (Zheng 등, 2018). 그러나 인공지능기반 모델이 복잡해질수록 ᄆ
ᅩ델의 내부가 블랙박스와 같이 알 수 없다는단점이 존재한다 (Qiu와 Choi, 2019; Jang 등, 2020). 따 ᄅ
ᅡ서 기존에는큰 문제가 되지 않았던 모델 결과에 대한 설명력을확보하는방안이 요구되고 있다. 결과 ᄋ
ᅦ 대한 설명력확보를 통해서, 투명하고 결과에 대한 해석 가능한 시스템을만들수 있기 때문이다. 특 ᄒ
ᅵ AI 윤리의 이슈와 GDPR (general data protection regulation의 약자로 기존 개인정보 보호 지침 (data protection directive)을모든회원국에 직접적인 법적 구속력을갖는규정 (regulation)으로 강화 ᄒ
ᅡᆷ) 등설명력확보에 대한 외부 규제가 점차 강화되고 있으며, 복잡한 모델의 결과 값에 대한금융사 임 지
ᆨ원의 이해도를 높이고 고객들에게 충분한 설명을제공해야하는내부적인 요구도 증가하고 있다 (Lee, 2020). 이러한 배경을바탕으로, 설명 가능한 인공지능, XAI (eXplainable AI, 설명 가능한 인공지능의 ᄋ
ᅣ
ᆨ자)에 대한금융권모형 도입이 필수적이다 (Kim, 2020).
ᄋ
ᅵ에 대응하기 위해서, 각종 금융회사들은대리 모델 (surrogate model)을기반으로 하여 결과 값에 ᄃ
ᅢ한 변수간의 기여도를 측정하여 블랙박스인 머신러닝 모델에 대한 해석력을확보하는 시도를 진행하 ᄀ
ᅩ 있다. 이러한 방법들은개별 결과에 대한 설명력을제공한다는장점이 있다. 그러나 금융회사의 고 개
ᆨ들은정기적으로 신용도에 대한 평가를받기에 개별 결과보다는과거 결과와의 비교를 통한 변화 정도 ᄋ
ᅦ 대한 설명을제공할 수 없다는한계점이 존재한다. 또한 개별 결과에 대한 해석만으로는금융회사의 ᄀ
ᅲ제모형에서 필요한 투명성과 신뢰성에 미치지 못하기 때문에금융산업에서 인공지능 기술의 도입에 ᄏ
ᅳᆫ걸림돌이 되고 있다.
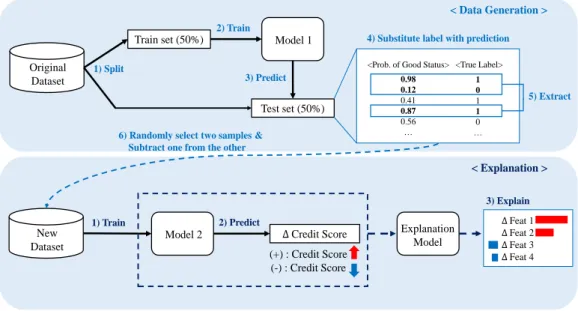
보
ᆫ 논문에서는이러한 배경을바탕으로 인공지능모델이 도출한 신용평가 결과 변화에 대한 다양한 요 ᄋ
ᅵᆫ들의 영향도를계산하여 기존의 대리 모델을보완하는방법론을제안하고자 한다.
2. 문헌연구
2.1. 머신러닝 알고리즘 ᄆ
ᅥ신러닝은 AI의 한 분야로 데이터를 바탕으로 내재되어 있는 패턴을 알고리즘을 통해 학습하고자 ᄒ
ᅡᆫ다. 이러한 학습을 통해 새로운 데이터에 대해서 예측 및 분류하는 일에 활용할 수 있다. 머신러 니
ᆼ은 학습되는 데이터의 형식과 목표에 따라 지도학습 (supervised learning), 비지도학습 (unsuper- vised learning),강화학습 (reinforcement learning)으로 나눌수 있다. 지도학습의 경우 정답 (ground truth)이 포함된 데이터를 바탕으로 분류 및 평가하는 학습 방법이며, 비지도학습은 데이터의 분포를 부
ᆫ석하여 클러스터를 찾고 분류하는 학습 방법이다. 마지막으로 강화학습은 수행 결과에 따른 보상을 ᄐ
ᅩ
ᆼ하여 주어진환경에서 최적의 방법을찾는 방법이다. 본연구는지도학습에서 사용되는모델링 기법 으
ᆯ바탕으로 생성된모델을대상으로 신용평가 모형을제시한다. 이를위해서, 의사결정나무 (decision tree)와 부스팅 (boosting) 계열의 알고리즘을사용하였다. 그리고 인공지능모델의 도출한 결과에 대한 서
ᆯ명력 강화를 목표로 한다.
2.2. 의사결정나무 ᄋ
ᅴ사결정나무는 각 데이터들이 가진 속성들을 여러 단계의 패턴으로 구분하여 분류 및 예측하는 방 버
ᆸ이다. 이때 모델의 의사결정 규칙은최초의 과정부터 점차 하위로 발산하기에 마치 나무 가지처럼 갈 ᄅ
ᅡ지는 모습을 보인다. 따라서 의사결정나무라는 이름을 사용한다. 갈라지는모습을이용하여 의사결 저
ᆼ나무는 정답을 탐색하는 과정을 도식화 할 수 있다는 장점이 있다. 의사결정나무의 구조는 가장 상