논문 2011-6-25
p-시설물 위치선정 모델
p-Facility Location Models
최명복*, 이상운**, 김봉경**, 정승삼**, 한태용**
Myeong-Bok Choi, Sang-Un Lee, Bong-Gyung Kim, Seung-Sam Joung, Tae-Yong Han
요 약 본 논문은 개의 후보 시설과 개의 거주지역이 존재하는 경우, 비용 (주민수 × 최단거리) 측면에서 개 의 최적의 시설 위치를 선정하는 알고리즘을 제안하였다. 이 문제는 다항시간 알고리즘이 제안되지 않아 NP-난제로 분류되어 있다. 본 논문에서는 각 지역에서의 최소 비용을 선택한 의 시설로부터 각 지역을 다음 최소 비용 시 설로 이동시킬 경우 최소비용합으로 삭제할 수 있는 후보 시설을 가 될 때까지 한 번에 하나씩 제거하는 방법으 로 역-삭제 방법이다. 제안된 알고리즘은 다양한 문제들에 적용한 결과 × 이 × , × 인 경우에는 초기 해로 최적해를 구하였다. Swain의 55-노드 망에 대해서는 인 경우 해 개선 과정을 수행하여 최적해를 구하였으며,
인 경우에는 초기해로 최적해를 구하였다.
Abstract This paper suggests -facility locations in candidate locations and areas in optimal cost side(population×shortest distance). This problem has been classified by NP-complete because there is not a polynomial time algorithm. In this paper, we suggests reverse-delete method that deletes a candidate facility one by one from until . As a result of the proposed algorithm for the × and × , the initial solution is obtained. For the Swain's 55-node network, we obtain the optimal solution through a solution improvement process with and it by using the initial solution with .
Key Words:시설 위치, 휴리스틱, 최단거리, 역-삭제
*종신회원, 강릉원주대학교 멀티미디어공학과
**정회원, 강릉원주대학교 멀티미디어공학과
***정회원, 남서울대학교, 스포츠경영학과
****정회원, 경인여자대학 레저스포츠과
*****정회원, 강릉원주대학교, 여성인력개발학과
접수일자 2011.10.14, 수정완료 2011.11.27 게재확정일자 2011.12.16
I. 서 론
개의 노드 ⋯가 존재하는 망 (도 시)에 응급시설 또는 공공시설 ⋯을 개 설치하는 경우, 최적의 시설 위치는 중심 ( Center) 또는 중앙값 ( Median) 방법으로 찾을
수 있다.[1,2] 이 문제에서, 후보시설 와 노드들 사이 의 최단 거리 (shortest length) 와 각 노드의 요구량 (또는 주민수) 를 알고 있다고 가정하자. 이 경우 시설 위치의 효율성은 고객이 위치한 요구 지점 (노드)과 시 설 간의 최소 총 거리 (평균거리) ∑ 또는 최소 총 비용 ∑ × 으로 측정될 수 있다.[2]
이 문제는 대형 할인점, 보건의료, 우체국, 병원, 소방 서, 119의 응급서비스시설 (Emergency Medical Services, EMS), 학교, 도서관 등 공공과 사적 시설물의 최적 위치 를 결정하는데 활용되고 있으며 지역사회의 안전과 복 지(well-being)에 심각한 영향을 미친다.[2-4]
시설에 대한 최적의 위치를 찾는 위치 이론 (location theory)은 수학, 컴퓨터과학, OR (operational research), 경제, 지리학 등 많은 학문들에 근거를 둔 학제적 분야 로 경제적 목적 또는 공공서비스 측면에서 많은 관심의 대상이 되고 있다.
고객과 시설간의 평균거리 (average distance)가 감 소하면 시설 접근성 (accessibility)은 증가하며, 평균 응 답시간 (반응시간, response time)은 감소한다. 이 개념 이 중앙값 ( Median) 이다. 따라서 시설의 위 치는 요구지점과 가장 인접한 시설간의 평균 (총) 거리 를 최소화시키도록 결정한다.[4]
Cooper는 1963년에 다중시설 위치-재배치 문제를 시 작하기 위해 단일-시설 문제를 확장하였으며, Hakimi는 1964년에 중심과 중앙값 문제의 기초를 완성하 였다. 중심 문제의 해는 반드시 노드들에 위치하지 않는 반면에, 중앙값 문제의 해는 항상 노드들에 위 치하는 장점이 있다. 따라서 시설 위치 결정 문제는 중앙값 문제로 발전하였다.[3] Revelle와 Swain은 1970년 에 선형계획법 (linear programming)과 분기한정법 (branch -and-bound)을 결합한 중앙값 알고리즘을 제안하였다. 또한, 휴리스틱 방법인 Myopic 알고리즘 (MA), 이웃탐색 (Neighbourhood Search, NS), 교환 휴 리스틱 (Exchange Heuristic, EH), Tabu 탐색, 유전자 알고리즘, 담금질 방법 (simulated annealing) 등도 적용 되고 있다.[1,4]
만약, 인 경우의 최적의 시설 위치는 ∑
또는 ∑가 되는 로 쉽게 결정될 수 있다. 그러나
≥ 에 대해서는 1960년대에 제기된 이후 지금까지도 가능한 모든 조합
의 경우수에
대해 확인하는 열거방법 (enumeration) 이외에는 정확 한 해를 구하는 다항시간 알고리즘이 알려져 있지 않아 Kariv와 Hakimi는 중심과 중앙값 방법은 NP-난 제 (NP-Hard) 문제임을 증명하였다.[2-4]
본 논문은 시설의 최적 위치를 결정하는 중앙값 문제에 대해 휴리스틱한 근사해를 구하는 알고리즘을 제안한다. 제안된 방법은 부터 까지 해당 노 드 를 가장 인접한 로 이동시 최단거리 (또는 비용) 합이 최소가 되는 시설 1개를 삭제하는 역-삭제 (Reverse-delete) 방법으로 최적의 위치를 찾는다. 2장 에서는 중앙값 문제와 Caccetta와 Dzator[4]가 제안
한 휴리스틱 방법을 고찰한다. 3장에서는 역-삭제 방법 을 제안하고, 4장에서는 사례들을 중심으로 제안된 방법 의 적용성을 평가해 본다.
II. 관련연구와 문제점
응급시설에 대한 최적의 위치를 찾는 기준은 응답시 간을 향상시키는 것이다. 응답시간은 응급시설과 응급 상황이 발생한 지점간의 거리에 의존한다. 따라서 이들 응급시설을 설치할 위치는 이 시설을 이용 (또는 방문) 하는 사람들의 이동 평균거리를 최소화시키는 것이다.
중앙값 문제는 응급상황이 발생한 지점과 가장 근접한 응급시설간의 거리를 최소화시키도록 개의 응 급시설 위치를 결정하는 문제이다. 이 문제는 식 (1)의 수학 공식으로 표현된다.
⋯ : 응급시설 후보 위치
⋯ : 응급상황이 발생하는 지점
: 응급상황이 발생하는 지점 (노드) 와 응급시 설 노드 간의 최 단거리 (shortest distance)
에서에 위치한 고객과 최단거리인 경우
그렇지 않은 경우
응급시설이 에 설치되는 경우
그렇지 않은 경우
: 설치될 응급시설 개수
: 노드 에 거주하는 주민수 (또는 요구량)
응급시설 노드와 응급상황 발생 지점 간 소 요비용 ×
or
(1) subject to
∈
∀∈,
∈
≤ ∀∈ ∀∈, ∈ ∈
MA 알고리즘은 첫 번째로, 모든 지점의 고객들에 대 해 최소 비용인 시설을 선택한다. 두 번째로 시설이 개 가 될 때까지 최소 비용 시설을 한 번에 하나씩 추가한 다. 이 알고리즘은 쉬운 반면에 최종적으로 얻은 해가 최적해 (optimal solution)에서 멀어질 수 있다.
Caccetta와 Dzator[4]는 감소 휴리스틱 (Reduction Heuristic, RH) 알고리즘을 제안하였다. MA 알고리즘은 최단거리행렬에 존재하는 모든 값들을 사용하는 반면에, RH 알고리즘은 극단적인 값 (이상점, outliers)을 삭제하 는 방법이다. 왜냐하면 이상점들은 최적 해에 강력한 영 향을 미치기 때문이다. RH 알고리즘은 이 증가함에 따라 그림 1의 RH1, RH2, RRH (Repeated RH)를 수행 하도록 설계되어 있다.
[RH1]
Step 1. 시설 수 (열)과 노드 수 (행)을 동일하게 설정한 비용 행렬 를 작성한다.
Step 2. 각 열에서 최대값 내림차순으로 개를 “0”으로 치환한 다.
Step 3. 각 열의 합을 계산한다. 열의 합을 오름차순으로 하여 최소 값 개를 초기해 집합으로 선택한다.
Step 4. 원래의 비용행렬에서 선택된 개의 노드 행과 열의 모 든 를 “0”으로 치환하고, 열의 합을 계산 한다.
Step 5. 합이 0이 아닌 열의 최소값 노드 1개를 초기값 노드 개의 초기 노드와 각각 치환한 조합 집합을 생성한다.
Step 6. 각 집합의 합이 최소인 집합을 선택한다. 그렇지 않으면 Step 3으로 복귀하고, 보다 작은 값을 가진 집합을 최종 해 로 선택한다.
[RH2]
RH1의 Step 1 ~ Step 4 수행.
Step 5. 초기 집합 에 속하지 않는 모든 노드를 대상으로 에 속 한 1개 노드와 치환한 조합 집합을 생성한다.
Step 6. 집합의 합이 최소인 집합을 선택한다. 그렇지 않으면 보다 작은 값을 가진 집합을 최종 해로 선택한다.
[RRH]
최종 해를 개선할 수 있을 때까지 RH2의 최종 해를 초기집합으로 설 정하고, RH1의 Step 4와 RH2의 Step 5 ~ Step 6을 반복적으로 수행한다.
그림 1. RH 알고리즘 Fig. 1. RH Algorithm
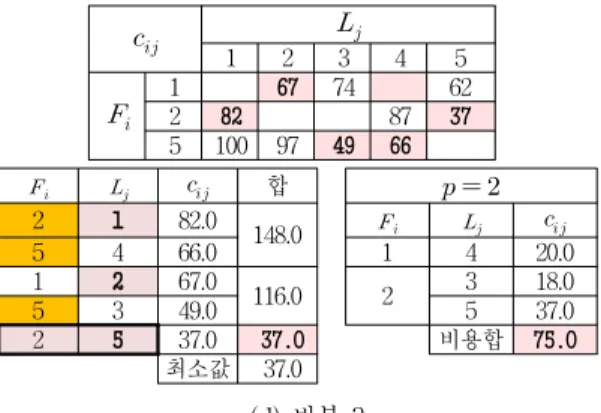
만약, 이 작은 경우는 RH1으로 최적해를 얻을 수 있지만 이 증가함에 따라 RH2로도 해를 얻지 못해 RRH까지도 수행해야 하는 경우가 발생할 수 있다. 표 1 의 데이터에 대해 인 경우 RH1은 그림 2와 같이 수행된다. 참고로, Caccetta와 Dzator[4]는 표 1의 행 렬에 대해 인 경우 , 인 경우
를 얻었다.
표 1. 비용 행렬 데이터 Table 1. Cost Matrix Data
1 2 3 4 5
1 0 82 37 51 100
2 67 0 78 93 97
3 74 18 0 20 49
4 20 87 27 0 66
5 62 37 51 87 0
1 2 3 4 5
1 0 82 37 51 100
2 67 0 78 93 97
3 74 18 0 20 49
4 20 87 27 0 66
5 62 37 51 87 0
(a) Step 1
1 2 3 4 5
1 0 0 37 51 0
2 0 0 0 0 0
3 0 18 0 20 49
4 20 0 27 0 66
5 62 37 0 0 0
(b) Step 2
1 2 3 4 5
1 0 0 37 51 0
2 0 0 0 0 0
3 0 18 0 20 49
4 20 0 27 0 66
5 62 37 0 0 0
합 82 55 64 71 115
(c) Step 3
1 4 5
1 0 51 100
4 20 0 66
5 62 87 0
합 82 138 166
(d) Step 4
→
(e) Step 5
1 2 1 3
1 0 82 0 37
2 67 0 67 78
3 74 18 74 0
4 20 87 20 27
5 62 37 62 51
합 75 145
최적해 :
(f) Step 6 그림 2. 에 대한 RH1 알고리즘 Fig. 2. RH1 Algorithm for of
III. 시설 위치 선정 알고리즘
본 장에서는 새로운 개념의 시설위치 결정 알고리즘 을 제안한다. 제안되는 알고리즘은 일반적으로 개 지 점 중 개의 시설 후보지를 결정하는 경우 으로 초기 집합으로 설정하고, 각 후보 시설 집합에 속한 노 드들을 최소비용이 소요되는 다른 후보시설들이 커버 또는 지배하도록 이동시 비용합이 최소가 되는 후보시 설 집합을 삭제하는 방법이다. 즉, 최소비용이 소요되는 후보 시설을 삭제하는 방법이다. 하나의 후보 시설 집합
가 삭제시 이 후보시설집합에 속한 노드들을 최소비 용 후보시설들의 로 이동시키고, 이동시틴 노드들과 삭제된 롤 로 하는 노드들에 대해서만 최소비 용이 소요되는 다른 후보시설 와 비용 를 갱신한 다. 제안된 알고리즘은 의 개수가 1개씩 감소시키는 형 태로 RD ( Reverse Delete) 알고리즘이라 칭하 며, 그림 3과 같이 수행된다.
사전처리 (Pre-processing)
z 시설 수 ⋯ 행과 노드 수
⋯ 열의 거리행렬 작성.
z 행렬을 와 간 최단거리 행렬 로 변환.
z 행렬을 와 의 비용 × 행렬 로 변환.
초기치 : ⋯.
열 의 삭제, ∀ 열에서 최소비용 선택.
인 열 를 집합에 포함시킴.
While do /* 초기 해
에 해당하는 행 삭제. ╲.
삭제되는 집합의 노드들을 열로 하는 다음 최소값 비 용 와 를 구함. 비용이 갱신된 집합의 비용 합 재 계산.
최소 비용합 집합 노드들을 로 하여 최소 비용 들 로 이동.
end
z 선택된 가 커버하는 들의 중심 위치로 되도록 노드 변 경.
z 외곽 경계 노드들을 제외한 들 조합들 중에서 최소비용 합 노드를 의 최종 해로 결정.
그림 3. RD 알고리즘 Fig. 3. RD Algorithm
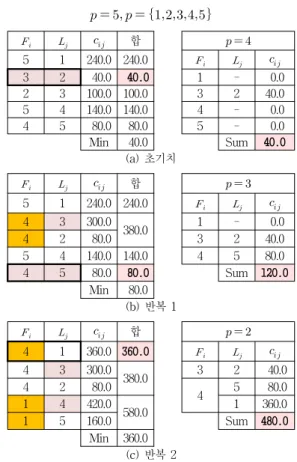
표 1의 행렬 데이터에 제안된 RD 알고리즘을 적용하는 과정은 그림 4와 같다. 만약, 인 경우는 비용합이 최소인 에 설치하는 것이 최적임을 알 수 있다. 따라서 제안된 알고리즘은 ≤ ≤ 에 대해 서만 해를 구한다.
1 2 3 4 5 비용합
1 0 67 74 20 62 223
2 82 0 18 87 37 224
3 37 78 0 27 51 193
4 51 93 20 0 87 251
5 100 97 49 66 0 312
1 - 0.0
2 - 0.0
3 - 0.0
4 - 0.0
5 - 0.0
비용합 0.0
(a) 초기치
1 2 3 4 5
1 67 74 20 62
2 82 18 87 37
3 37 78 27 51
4 51 93 20 87
5 100 97 49 66
합
3 1 37.0 37.0
1 2 67.0 67.0 1 - 0.0
2 3 18.0 18.0 2 3 18.0
1 4 20.0 20.0 4 - 0.0
2 5 37.0 37.0 5 - 0.0
최소값 18.0 비용합 18.0
(b) 반복 1
1 2 3 4 5
1 67 74 20 62
2 82 87 37
4 51 93 20 87
5 100 97 49 66
합
4 1 51.0 51.0
1 2 67.0
87.0 1 4 20.0
4 3 20.0 2 3 18.0
1 4 20.0 20.0 5 - 0.0
2 5 37.0 37.0 비용합 38.0
최소값 20.0 (c) 반복 2
1 2 3 4 5
1
67 74 62
2 82 87 37
5 100 97 49 66
합
2 1 82.0
148.0
5 4 66.0 1 4 20.0
1 2 67.0
116.0 2 3 18.0
5 3 49.0 5 37.0
2 5 37.0 37.0 비용합 75.0
최소값 37.0 (d) 반복 3 그림 4. 에 대한 RD 알고리즘 Fig. 4. RD Algorithm for
제안된 알고리즘은 초기 집합으로 에 대해
을 선택한 를 구하였다. 다음으 로, 을 삭제하고 ⋯ 행에서 최소 값을 선택하고, 로 표기할 경우 인
을 얻는다. 즉, “3” 노드가 “2” 시설에 가장 근접하고 있으므로 “3” 노드를 “2” 시설이 커버하므로
“3” 노드를 삭제한다. 따라서 인 경우
를 얻는다. “3” 노드 행을 삭제하면,
인 경우, 기존에 에 가장 근접한 인 은
“3” 이외의 가장 인접한 다른 시설로 이동이 가능하며, 집합에 포함된 는 이외의 가장 인접한 다른 시설로 이동시키는 값을 찾아야 한다. 따라서 →
→ 으로 변경된다. 또한,
에서 이 되어 를 이동시킬 수 있 는 비용합은 으로 갱신된다. 결국, 중에서 최소 비용으로 삭 제시킬 수 있는 후보 시설 위치는 로 비용 합은 20이 며, 로 이동시킬 수 있다. 이로 인해 은
가 되며, 이 가 된다.
이와 같은 방법으로 최소비용 합 후보 시설을 삭제하는 방법을 적용하면 인 경우 를 얻는다. 제 안된 RD 알고리즘은 회 수행되며, 각 시행시 점에서 1개의 후보 시설이 삭제되고, 이 후보 시설에 가 장 근접한 들의 다음 근접한 후보 시설인 최소값을 선택하는 과정을 수행한다. 이는 최대 수행시 간이 소요되므로, 제안된 알고리즘의 수행시간은
≃이 된다.
IV. 실험 및 결과 분석
본 장에서는 먼저, Eiselt와 Sandblom[1]에서 인용된 그림 5의 3개 데이터에 대해 제안된 알고리즘을 적용하 여 보고, 다음으로 표 2의 Swain 55-노드 망 데이터에 적용하여 본다. 데이터는 에 대해 Lagrangean Relaxation으로, 데이터는 에 대해 욕심쟁이 알고리즘 (Greedy algorithm)으로, 데이터는 에 대해 중심 문제로 해를 구한 사례이다.
1 2 3 4 5 1 2 3 4 5
50 30 40 60 20 50 30 40 60 20 합
1 0 7 9 4 3
1 0 210 360 240 60 870 2 7 0 2 7 5 2 350 0 80 420 100 950 3 9 2 0 6 7 3 45060 0 360 140 1010 4 4 7 6 0 2 4 200210 240 0 40 690 5 3 5 7 2 0 5 150 150 280 120 0 700
(a) 데이터
1 2 3 4 5 1 2 3 4 5
60 20 50 70 40 60 20 50 70 40 합
1 0 5 7 6 4
1 0 100 350 420 160 1030 2 5 0 2 4 6 2 300 0 100 280 240 920 3 7 2 0 6 8 3 420 40 0 420 320 1200
4 6 4 6 0 2 4 360 80 300 0 80 820
5 4 6 8 2 0 5 240 120 400 140 0 900
(b) 데이터
1 2 3 4 5 6 7 합
1 0 3 7 7 7 10 15 49
2 3 0 4 10 9 7 12 45
3 7 4 0 14 8 3 8 44
4 7 10 14 0 6 14 22 73
5 7 9 8 6 0 8 16 54
6 10 7 3 14 8 0 9 51
7 15 12 8 22 16 9 0 82
(c) 데이터 그림 5. 실험 데이터
Fig. 5. Experimental Data
표 2. Swain의 55-노드 망
Table 2. The Swain's 55-Node Network
노드 인구수 위치좌표
노드 인구수 위치좌표
x y x y
1 2 3 4 5 6 7 8 9 10 11 1213 14 1516 17 1819 20 21 2223 24 2526 27 28
120 114110 108 105103 100 94 91 90 88 87 87 85 83 82 80 79 79 77 76 74 72 70 69 69 64 63
32 2927 29 3226 24 3029 29 33 1734 25 2130 19 1722 25 29 2417 6 1910 34 12
31 3236 29 2925 33 3527 21 28 5330 60 2851 47 3340 14 12 4842 26 2132 56 47
29 3031 32 3334 35 3637 38 39 4041 42 4344 45 4647 48 49 5051 52 5354 계55
62 6160 58 5755 54 5351 49 47 4443 42 4140 39 3735 34 33 3332 26 2524 3,57521
19 2721 32 2732 8 1535 36 46 5023 27 3836 32 4236 15 19 4527 52 4040 42
38 4135 45 4538 22 2516 47 51 4022 30 3932 41 3626 19 14 19 5 24 2252 42
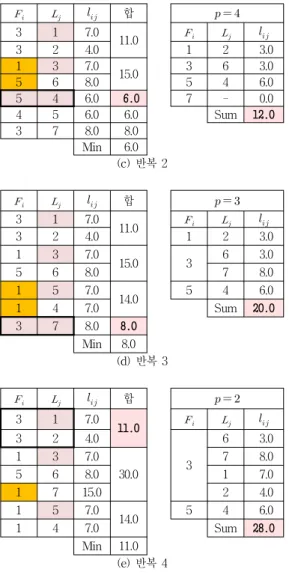
그림 5의 , 와 데이터에 제안된 RD 알고 리즘을 적용한 결과는 각각 그림 6 ~ 그림 8에 제시되어 있다.
합
5 1 150.0 150.0
3 2 60.0 60.0 1 - 0.0
1 3 80.0 80.0 2 - 0.0
5 4 120.0 120.0 3 - 0.0
4 5 40.0 40.0 4 5 40.0
Min 40.0 Sum 40.0
(a) 초기치
합
4 1 200.0 200.0
3 2 60.0 60.0 1 - 0.0
2 3 80.0 80.0 3 2 60.0
1 4 240.0 300.0 4 5 40.0
1 5 60.0 Sum 100.0
Min 60.0 (b) 반복 1
합
4 1 200.0 200.0
4 3 240.0 450.0 3 2 60.0
1 2 210.0 4 5 40.0
1 4 240.0 300.0 1 200.0
1 5 60.0 Sum 300.0
Min 200.0 (c) 반복 2 그림 6. 에 대한 RD 알고리즘 Fig. 6. RD Algorithm for
합
5 1 240.0 240.0
3 2 40.0 40.0 1 - 0.0
2 3 100.0 100.0 3 2 40.0
5 4 140.0 140.0 4 - 0.0
4 5 80.0 80.0 5 - 0.0
Min 40.0 Sum 40.0
(a) 초기치
합
5 1 240.0 240.0
4 3 300.0
380.0 1 - 0.0
4 2 80.0 3 2 40.0
5 4 140.0 140.0 4 5 80.0
4 5 80.0 80.0 Sum 120.0
Min 80.0 (b) 반복 1
합
4 1 360.0 360.0
4 3 300.0
380.0 3 2 40.0
4 2 80.0
4 5 80.0
1 4 420.0
580.0 1 360.0
1 5 160.0 Sum 480.0
Min 360.0 (c) 반복 2 그림 7. 에 대한 RD 알고리즘 Fig. 7. RD Algorithm for
합
2 1 3.0 3.0
1 2 3.0 3.0 1 2 3.0
6 3 3.0 3.0 3 - 0.0
5 4 6.0 6.0 4 - 0.0
4 5 6.0 6.0 5 - 0.0
3 6 3.0 3.0 6 - 0.0
3 7 8.0 8.0 7 - 0.0
Min 3.0 3.0 Sum 3.0
(a) 초기치
합
3 1 7.0
11.0
3 2 4.0 1 2 3.0
6 3 3.0 3.0 3 6 3.0
5 4 6.0 6.0 4 - 0.0
4 5 6.0 6.0 5 - 0.0
3 6 3.0 3.0 7 - 0.0
3 7 8.0 8.0 Sum 6.0
Min 3.0 (b) 반복 1
합
3 1 7.0
11.0
3 2 4.0 1 2 3.0
1 3 7.0
15.0 3 6 3.0
5 6 8.0 5 4 6.0
5 4 6.0 6.0 7 - 0.0
4 5 6.0 6.0 Sum 12.0
3 7 8.0 8.0 Min 6.0
(c) 반복 2
합
3 1 7.0
11.0
3 2 4.0 1 2 3.0
1 3 7.0
15.0 3 6 3.0
5 6 8.0 7 8.0
1 5 7.0
14.0 5 4 6.0
1 4 7.0 Sum 20.0
3 7 8.0 8.0
Min 8.0 (d) 반복 3
합
3 1 7.0
11.0
3 2 4.0
3
6 3.0
1 3 7.0
30.0
7 8.0
5 6 8.0 1 7.0
1 7 15.0 2 4.0
1 5 7.0
14.0 5 4 6.0
1 4 7.0 Sum 28.0
Min 11.0 (e) 반복 4 그림 8. 에 대한 RD 알고리즘 Fig. 8. RD Algorithm for
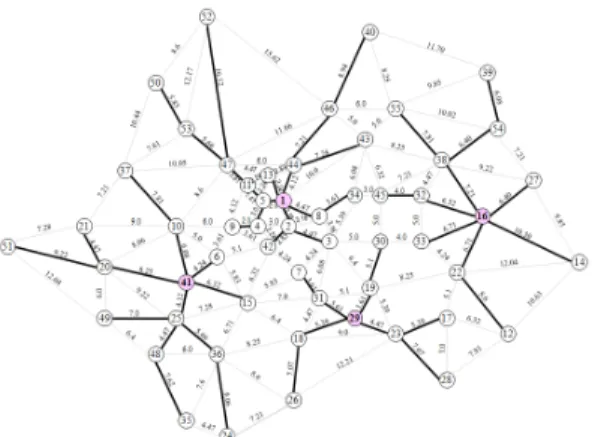
표 2에서 각 노드의 위치는 직각좌표로 제시되어 있 어 인접한 두 노드 와 간의 거리는 유클리드 거리 (Euclidean Distance) 공식
으로 거리 행렬
을 구하면 그림 9와 같다. 그림 9의 거리 데이터에 대 해 최단거리 행렬 를 구한 데이터는 표 3과 같다.
표 3의 최단거리 와 각 노드의 요구량 를 곱하면 비용행렬 × 를 얻는다. 비용 행렬 는 편 의상 제시하지 않았다.
본 데이터에 대해서는 그림 9에서 외곽 경계에 위치 한 51,21, 37,50,52,46,40,39,54,27,14,12,28,23,26,24,35,48,49 의 19개 노드는 중앙값에서 제외시켰다. 왜냐하면
개의 시설물은 외곽 경계에는 위치하지 않기 때문이 다. 따라서 55개 노드 중에서 19개 노드에 대해 가장 인 접한 비용 (최소비용)노드로 이동시키면 을 얻는 다. 이 경우 {⋯{16, 14,27}, {17,28,12}, {18,26}, 19, {20,21,49,51}, 22, {25,48}, {29,23}, 30,31,32,33, 34,{36,24,35}, {38,54}, 41,42,{43,46}, 44,45,47, {53,37,50,52}, {55,39,40}}을 얻는다. 이와 같이 수행한 결과는 표 4에 제시되어 있다.
그림 9. Swain의 55-노드 망
Fig. 9. The Swain's 55-Node Network
표 3. Swain의 55-노드 망의 최단거리 행렬
Table 3. The Shortest distance matrix for Swain's 55-Node Network