Journal of KIISE, Vol. 44, No. 1, pp. 36-43, 2017. 1 https://doi.org/10.5626/JOK.2017.44.1.36
․이 논문은 2015년도 강원대학교 대학회계 학술연구조성비(과제번호-520150464), 2016년도 정부(미래창조과학부)의 재원으로 정보통신기술진흥센터의 지원을 받아 수행된 연구임(No.R0101-16-0062, (엑소브레인-1세부) 휴먼 지식증강 서비스를 위한 지능진화형 WiseQA 플랫폼 기술 개발)
논문접수 : 2016년 5월 26일 (Received 26 May 2016) 논문수정 : 2016년 10월 3일 (Revised 3 October 2016) 심사완료 : 2016년 10월 21일
†
††
비 회 원 종신회원 : :
강원대학교 컴퓨터과학과 [email protected] 강원대학교 컴퓨터과학과 교수 (Kangwon National Univ.) [email protected] (Corresponding author임)
(Accepted 21 October 2016)
CopyrightⒸ2017 한국정보과학회ː개인 목적이나 교육 목적인 경우, 이 저작물 의 전체 또는 일부에 대한 복사본 혹은 디지털 사본의 제작을 허가합니다. 이 때, 사본은 상업적 수단으로 사용할 수 없으며 첫 페이지에 본 문구와 출처를 반드시 명시해야 합니다. 이 외의 목적으로 복제, 배포, 출판, 전송 등 모든 유형의 사용행위 를 하는 경우에 대하여는 사전에 허가를 얻고 비용을 지불해야 합니다.
정보과학회논문지 제44권 제1호(2017. 1)
Stacked Bidirectional LSTM-CRFs를 이용한 한국어 의미역 결정
(Korean Semantic Role Labeling using Stacked Bidirectional LSTM-CRFs)
배 장 성
†이 창 기
††(Jangseong Bae) (Changki Lee)
요 약 의미역 결정 연구에 있어 구문 분석 정보는 술어-논항 사이의 의존 관계를 포함하고 있기 때 문에 의미역 결정 성능 향상에 큰 도움이 된다. 그러나 의미역 결정 이전에 구문 분석을 수행해야 하는 비용(overhead)이 발생하게 되고, 구문 분석 단계에서 발생하는 오류를 그대로 답습하는 단점이 있다. 이 러한 문제점을 해결하기 위해 본 논문에서는 구문 분석 정보를 제외한 형태소 분석 정보만을 사용하는 End-to-end SRL 방식의 한국어 의미역 결정 시스템을 제안하고, 순차 데이터 모델링에 적합한 LSTM RNN을 확장한 Stacked Bidirectional LSTM-CRFs 모델을 적용해 구문 분석 정보 없이 기존 연구보다 더 높은 성능을 얻을 수 있음을 보인다.
키워드: 의미역 결정, 딥러닝, Stacked Bidirectional LSTM-CRFs, End-to-end SRL
Abstract Syntactic information represents the dependency relation between predicates and arguments, and it is helpful for improving the performance of Semantic Role Labeling systems.
However, syntax analysis can cause computational overhead and inherit incorrect syntactic informa- tion. To solve this problem, we exclude syntactic information and use only morpheme information to construct Semantic Role Labeling systems. In this study, we propose an end-to-end SRL system that only uses morpheme information with Stacked Bidirectional LSTM-CRFs model by extending the LSTM RNN that is suitable for sequence labeling problem. Our experimental results show that our proposed model has better performance, as compare to other models.
Keywords: Semantic Role Labeling, Deep-learning, Stacked Bidirectional LSTM-CRFs, End-to-end SRL
1. 서 론
의미역(semantic role)은 문장 내에서 서술어에 의해 기술되는 행동이나 상태에 대한 명사구의 의미 역할을 말하며 의미역이 부여된 각 명사구를 논항(argument) 이라고 한다. 의미역 결정(semantic role labeling)은 문 장의 각 서술어의 의미와 그 논항들의 의미역을 결정하 여 “누가, 무엇을, 어떻게, 왜” 등의 의미 관계를 찾아내 는 자연어처리의 한 단계이며 기계 번역, 정보 추출, 질 의 응답과 같은 다양한 자연어처리 응용의 성능 향상을 위한 입력 자질 정보로 사용될 수 있다. 예를 들어 의미 역으로부터 시간 및 공간 정보, 사건의 주체, 문장이 가 지는 의미 등을 파악해 정보 추출 및 질의 응답 시스템 이 필요로 하는 정보를 제공한다. 최근 의미역 결정 연 구에는 Structural-SVM, 딥러닝(deep-learning)과 같 은 기계학습 알고리즘을 이용한 연구가 주로 이루어지 고 있다[1-6].
자연어처리 모듈 개발에 사용되는 대부분의 기계학습 알고리즘들은 사람이 디자인한 자질(feature)을 입력으 로 받고 이 자질들의 최적의 가중치(weight)를 구한다.
그러나 각 자연어처리 모듈 마다 적합한 자질을 설계하 고 최적의 자질 조합을 구하는 것은 많은 시간과 노력 을 필요로 한다. 이러한 문제를 해결하기 위해 자질들을 높은 수준의 표현으로 추상화 시켜줄 수 있는 딥러닝 기술이 최근 많이 연구되고 있다[5]. 딥러닝은 비선형 (non-linear)의 hidden layer가 여러 층으로 쌓여 이루 어진 인공신경망(artificial neural network)으로, 입력 자질들을 여러 비선형 변환기법의 조합을 통해 높은 수 준의 표현으로 추상화할 수 있는 장점이 있다.
Long Short-Term Memory(LSTM)를 이용한 Recur- rent Neural Network(RNN)는 기존 RNN 모델의 그래 디언트 소멸 문제(vanishing gradient problem)[7]를 해결한 딥러닝 모델이다. LSTM 기반 RNN은 음성 인 식, 필기체 인식, 언어 모델, 자연어이해 등의 분야에서 우수한 성능을 보이고 있으며[7], 순차 데이터(sequ- ential data) 모델링에 적합한 구조로 이루어져 있다.
구문 분석 정보는 술어와 논항 사이의 의존 관계 정 보를 포함하고 있어 의미역 결정 시스템의 성능 향상에 크게 기여한다[8]. 따라서 기존 의미역 결정 연구들은 구문 분석 정보를 의미역 결정의 주요 자질로 사용하였 다. 그러나 구문 분석 정보의 사용은 구문 분석 단계에 서 발생하는 오류를 그대로 답습하는 단점[9] 및 의미역 결정 이전에 구문 분석을 수행해야 하는 단점이 존재한 다. 따라서 본 논문에서는 구문 분석 정보를 제외하고 형태소 분석 정보만 사용하는 End-to-end SRL 방식의 한국어 의미역 결정 시스템을 제안한다. 이를 위해, 한 국어 의미역 결정을 순차열 분류 문제로 보고 순차 데
이터 모델링에 적합한 딥러닝의 LSTM RNN 모델을 이용한 Stacked Bidirectional LSTM RNN 모델을 한 국어 의미역 결정에 적용하고, Conditional Random Field(CRFs)를 이용하여 의미역 태그 사이의 의존성(전 이 확률)을 추가한다.
본 논문의 구성은 다음과 같다. 제 2장에서는 관련 연 구를 소개하고 제 3장에서는 본 논문에서 제안한 한국 어 의미역 결정 시스템을 기술한다. 제 4장에서는 실험 데이터에 대해 설명하고 실험 결과를 분석한다. 마지막 으로 제 5장에서는 결론에 대해 기술한다.
2. 관련 연구
의미역 결정 연구는 크게 격틀사전에 기반을 둔 방법 과 말뭉치에 기반을 둔 방법으로 나눌 수 있다. 격틀사 전에 기반을 둔 방법은 서술어와 논항들의 쓰임을 기술 한 격틀사전을 이용하는 방법으로, 서술어와 논항에 대 한 문법 관계를 기술한 격틀(frame)과 논항들의 정보를 기술한 선택제약(selectional restriction) 등을 이용하여 서술어-논항 관계에 부합하는 격틀을 선택하여 의미역 을 결정하는 방법이다. 격틀사전에 기반을 둔 방법은 입 력 문장과 격틀 사이의 유사도 계산 과정을 통해 의미 역이 결정되기 때문에 처리속도가 빠르고 높은 정확률 을 보이지만, 격틀사전의 구축이 어렵고 격틀사전에 기 술되지 않은 임의격을 처리하지 못하는 문제가 있다[10].
말뭉치에 기반을 둔 방법은 의미역이 태깅된 말뭉치 를 구축하고 이를 이용하여 기계학습 방법으로 의미역 을 결정하는 방법이다. 이 방법은 격틀사전에 기반을 둔 방법에 비해 적용률이 높은 장점이 있으나, 의미역이 태 깅된 말뭉치의 구축이 어렵다는 단점이 있다[10]. 최근에 는 엑소브레인 언어분석 말뭉치[11], Korean PropBank[12]
와 같이 공개된 의미역 말뭉치와 기계학습 알고리즘을 이용한 연구가 활발히 이루어지고 있다[1-6]. 또한 [13]
과 같이 격틀 사전과 말뭉치 정보를 같이 사용하는 하 이브리드 기법의 연구도 이루어지고 있다.
[2]에서 사용한 Feed-Forward Neural Network(FFNN) 모델은 출력 레이블을 결정하기 위해 현재 입력 단어를 포함한 고정된 크기의 윈도우만을 이용해야 하는 단점 이 있다. [3]의 모델은 LSTM 구조를 통해 멀리 떨어져 있는 단어의 정보를 활용할 수 있다는 장점이 있으나 입력된 시점 이후에 나타나는 단어의 정보는 활용할 수 없는 단점이 존재한다.
[4]의 연구는 의미역 결정을 위해 기존에 사용하지 않 았던 의미 정보를 기계 학습의 자질로 채택하는 방법을 제시하였다. [4]의 연구는 의미역의 부가격 필터링 및 유의어 사전, 개체명 인식 정보, 격틀사전 확장 등을 통 해 높은 성능을 보였으나, 전체 시스템의 크기가 커지고
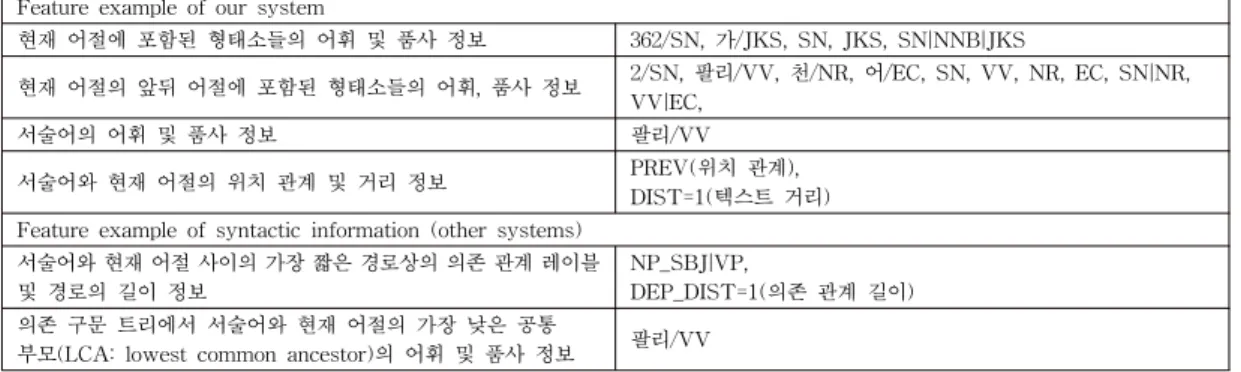
표 1 한국어 의미역 결정 자질 예제
Table 1 Feature examples for Korean Semantic Role Labeling Feature example of our system
현재 어절에 포함된 형태소들의 어휘 및 품사 정보 362/SN, 가/JKS, SN, JKS, SN|NNB|JKS
현재 어절의 앞뒤 어절에 포함된 형태소들의 어휘, 품사 정보 2/SN, 팔리/VV, 천/NR, 어/EC, SN, VV, NR, EC, SN|NR, VV|EC,
서술어의 어휘 및 품사 정보 팔리/VV
서술어와 현재 어절의 위치 관계 및 거리 정보 PREV(위치 관계),
DIST=1(텍스트 거리) Feature example of syntactic information (other systems)
서술어와 현재 어절 사이의 가장 짧은 경로상의 의존 관계 레이블 및 경로의 길이 정보
NP_SBJ|VP,
DEP_DIST=1(의존 관계 길이) 의존 구문 트리에서 서술어와 현재 어절의 가장 낮은 공통
부모(LCA: lowest common ancestor)의 어휘 및 품사 정보 팔리/VV 격틀사전 확장을 위해 많은 시간이 필요한 단점이 있다.
[5,6]의 연구는 딥러닝 기반의 영어 의미역 결정 연구이 다. [5]는 이미지 인식에서 뛰어난 성능을 보인 Convo- lutional Neural Network(CNN) 모델을 영어 의미역 결 정 및 여러 자연어처리에 적용한 연구이다. [5]의 연구에 사용된 CNN 모델은 자질 정보를 스스로 잘 압축할 수 있 는 모델이지만, [2]의 연구와 마찬가지로 현재 시점으로부 터 멀리 떨어져 있는 정보를 활용할 수 없는 단점이 있다.
[6]의 연구는 LSTM RNN 모델을 여러 층으로 쌓는 시도 를 통해 영어 의미역 결정에서 좋은 성능을 보였다.
본 논문에서는 LSTM-CRFs 모델에 Bidirectional 방법을 적용하여 입력 시점 이전 단어 및 이후 단어의 정보를 모두 활용할 수 있게 한다. 또한 Bidirectional LSTM RNN을 여러 층으로 쌓아 더 높은 수준의 추상 화를 시도하고자 한다. 본 논문은 매 층 마다 LSTM RNN의 방향이 역전되는 [6]의 모델과 달리, 각 층 마 다 Bidirectional LSTM RNN을 사용하여 양 방향 정 보를 모두 활용한다.
기존 의미역 결정 연구는 구문 분석 정보를 의미역 결정의 자질로 사용한다[1-5]. 이는 의미역 결정 시스템 의 성능을 향상 시킬 수 있지만 그에 따르는 비용이 발 생하며, 구문 분석 단계에서 발생하는 오류를 답습하게 된다. 이러한 문제점에서 자유롭기 위해 본 논문에서는 구문 분석 정보를 사용하지 않는 한국어 의미역 결정 시스템을 제안하고 Stacked Bidirectional LSTM-CRFs 모델을 이용하여 구문 분석 정보 없이 기존 연구보다 더 높은 성능을 얻을 수 있음을 보인다.
3. 딥러닝 기반의 한국어 의미역 결정 시스템
이 장에서는 본 논문에서 제안한 한국어 의미역 결정 시스템의 자질과 LSTM RNN 모델, LSTM-CRFs 모 델, Bidirectional LSTM-CRFs[14] 모델, Stacked Bidi- rectional LSTM-CRFs 모델에 대해 기술한다.3.1 한국어 의미역 결정 자질
대부분의 의미역 결정 시스템이 구문 분석 정보를 사 용하는 것과 달리 본 논문에서는 형태소 분석 정보를 바탕으로 한 자질 정보만 사용한다. 본 논문에서 사용하 는 자질 정보는 다음과 같다.
- 현재 어절에 포함된 형태소들의 어휘 및 품사 정보 - 현재 어절의 앞뒤 어절에 포함된 형태소들의 어휘, 품
사 정보
- 서술어의 어휘 및 품사 정보
- 서술어와 현재 어절의 위치 관계 및 거리 정보 구문 분석 정보를 사용하는 기존 연구와의 비교 실험 을 위해 사용한 자질은 다음과 같다.
- 서술어와 현재 어절 사이의 가장 짧은 경로상의 의존 관계 레이블 및 경로의 길이 정보
- 의존 구문 트리에서 서술어와 현재 어절의 가장 낮은 공통 부모(LCA: lowest common ancestor)의 어휘 및 품사 정보
어절의 어휘 및 품사 정보는 어절의 첫 형태소 및 어 절의 마지막 형태소의 정보를 사용하며, 마지막 형태소 가 마침표, 물음표, 쉼표 등과 같은 기호일 경우 그 앞 의 형태소로 대치한다. 또한 어절을 이루는 전체 형태소 의 품사 정보를 사용한다. 서술어의 어휘 및 품사 정보 는 서술어를 이루는 어절의 첫 형태소를 사용하고, 서술 어와 현재 어절의 위치 관계 및 거리 정보는 문장 내 실제 텍스트 상의 거리를 사용한다.
표 1은 문장 ‘한편 외국 자동차는 총 7만 2천 362대 가 팔려 점유율이 39.8퍼센트로 떨어졌다.’의 ‘362대가’
어절의 레이블을 결정할 때 사용되는 자질 예제이다.
3.2 LSTM RNN
RNN은 순차 데이터를 처리하는데 적합한 형태로 디자 인되어 있으며 RNN을 입력 순서에 따라 언폴드(unfold)한 구조는 그림 1과 같다. 입력 단어 열
와hidden layer의 노드 열
, 출력 단어 열(의미역 태그 열)을
라 할 때 RNN은 식 (1)과 같이 정의된다.(1)
식 (1)에서 U, V 및 W는 가중치 행렬이며, E는 단 어 및 자질의 가중치 행렬이다. bh, by는 각각 hidden layer와 output layer의 bias 벡터(vector)를 나타낸다.
f(z)는 Sigmoid 혹은 Tanh 함수이고 g(z)는 Softmax 함수이다. f(z)와 g(z)는 식 (2)와 같이 정의된다.
(2)
그림 1 RNN 모델 Fig. 1 A RNN model
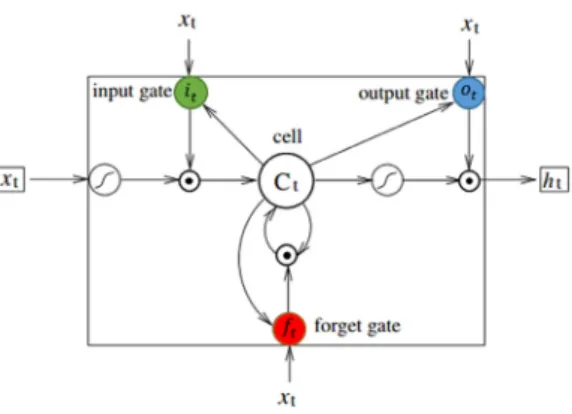
RNN은 순차 데이터를 쉽게 모델링할 수 있는 장점 이 있지만 연속된 입력 데이터의 열이 길어지게 되면 신경망 구조가 깊어져 에러 전파(error propagation)가 어려워지는 그래디언트 소멸 문제가 발생한다. 본 논문 에서는 RNN의 그래디언트 소멸 문제를 해결한 LSTM RNN을 이용하고 그 정의는 식 (3)과 같다.
식 (3)에서 는 Sigmoid 함수이고, ⊙ 는 벡터 간의 element-wise product를 나타낸다. i, f, o, c 는 각각 input 게이트, forget 게이트, output 게이트, memory cell 벡 터이며 각 벡터의 크기는 hidden layer 벡터 크기와 같다.
가중치 행렬의 아래 첨자는 연결된 각 노드를 나타낸다.
예를 들어 Wih는 hidden layer와 input 게이트 간의
그림 2 Long Short-Term Memory cell 구조 Fig. 2 A Long Short-Term Memory cell structure
그림 3 LSTM RNN 모델 Fig. 3 A LSTM RNN model
가중치 행렬이다. 그림 2는 LSTM memory cell의 구 조를 나타낸다. LSTM(LSTM RNN)의 hidden layer는 그림 2의 memory cell에 의해 갱신되기 때문에 이전 단어들의 정보와 현재 단어의 정보를 손실 없이 유지할 수 있어 그래디언트 소멸 문제에서 자유롭다. LSTM RNN 모델은 그림 3과 같으며 빨강, 파랑, 초록으로 표 시된 부분이 LSTM RNN의 각 게이트를 나타낸다.
LSTM의 입력 어절 벡터는 3.1절의 표 1의 자질들이 projection layer를 거친 후 concatenate되어 하나의 벡 터로 만들어지고, 만들어진 1개의 벡터가 LSTM의 입 력으로 들어가게 된다.
3.3 LSTM-CRFs
본 논문에서는 현재의 의미역 태그를 결정하기 위해 인접한 의미역 태그 정보를 활용하고자 한다. 이를 위해 출력 레이블의 인접성 정보를 바탕으로 현재 레이블을 추측할 수 있는 Conditional Random Field(CRFs)를 이용하여 output layer를 식 (4)와 같이 확장하였다[15].
(3)
(4)
그림 4 LSTM-CRFs 모델 Fig. 4 A LSTM-CRFs model
식 (4)에서 [A]yt-1,yt는 의미역 태그 yt-1에서 yt로 전 이될 확률을 의미하고, Ssent(x,y)는 의미역 태그 y열의 점수이다. log P(y|x)를 구하기 위해 forward 알고리즘 을 이용하며, 최적의 태그 열을 구하기 위해 Viterbi search 알고리즘을 적용한다. 그림 4는 LSTM-CRFs 모델을 나타낸다. LSTM RNN 모델에 출력 레이블 간 의 의존성(전이확률)이 추가된 것을 알 수 있다.
3.4 Bidirectional LSTM-CRFs
본 논문은 의미역 결정을 순차열 분류 문제로 보고 순 차 데이터 모델링에 적합한 LSTM RNN을 이용한다고 하였다. 하지만 LSTM RNN은 그림 2에서 알 수 있듯, 현재 시점의 의미역을 결정할 때 현재 입력 이후에 나오 는 단어의 정보를 활용할 수 없는 단점이 있다. 본 논문 에서는 현재 입력 이전의 단어 정보와 현재 입력 이후의 단어 정보 모두를 활용하여 현재 시점의 의미역을 결정 할 수 있는 양방향(Bidirectional) LSTM RNN을 이용 하여 LSTM RNN의 단점을 보완한다. 그림 5는 양방향 방법을 적용시킨 Bidirectional LSTM-CRFs 구조를 나 타낸다.
Bidirectional LSTM-CRFs 모델의 학습을 위해 Sto- chastic Gradient Descent(SGD)를 이용하여 -log p(y|x)
그림 5 Bidirectional LSTM-CRFs 모델 Fig. 5 A Bidirectional LSTM-CRFs model
를 최소화하였고, Back-Propagation Through Time (BPTT) 알고리즘을 이용하였다.
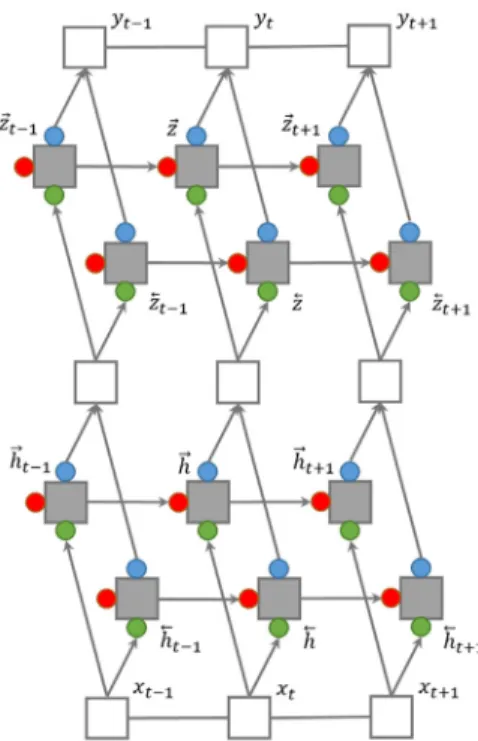
3.5 Stacked Bidirectional LSTM-CRFs
본 논문에서는 Bidirectional LSTM-CRFs 모델에 Bidirectional LSTM으로 구성된 hidden layer를 한층 더 쌓은 Stacked Bidirectional LSTM-CRFs 모델을 한국어 의미역 결정에 적용한다. 그림 6은 Stacked Bidirectional LSTM-CRFs 구조를 나타낸다. 첫 번째 정방향 hidden layer
와 역방향의 hidden layer 가
합쳐져 다시 다음 hidden layer ,
의 입력으로 사용 됨을 알 수 있다.
표 2는 Stacked Bidirectional LSTM-CRFs 모델의 학습 알고리즘이다. 첫 번째 줄에서 사용자가 입력한 epoch 만큼 반복 횟수를 지정한다. 두 번째 줄을 보면 모델의 학습이 문장 단위로 동작하는 것을 알 수 있다.
(3~9) 번째 줄은 학습 모델의 forward pass이고 10 번 째 줄에서 학습한 결과와 실제 정답과의 차이(error)를 구하게 된다. (11~16) 번째 줄은 에러를 전파하여 가중 치 행렬들을 갱신하는 Error Back-Propagation 단계이 고 학습은 첫 번째 줄에서 지정한 epoch에 다다르면 종 료된다. 본 논문에서는 epoch을 50으로 지정하여 실험 하였으며, 3 epoch을 수행하는 동안 성능 향상이 없을 경우 학습률(learning rate)을 1/2씩 감소 시켰다.
그림 6 Stacked Bidirectional LSTM-CRFs 모델 Fig. 6 A Stacked Bidirectional LSTM-CRFs model
표 2 Stacked Bidirectional LSTM-CRFs 학습 알고리즘 Table 2 A Learning algorithm of Stacked Bidirectional
LSTM-CRFs 1: for each epoch do 2: for each sentence do
3: Stacked Bidirectional LSTM-CRFs forward pass:
4: forward pass for first forward state LSTM 5: forward pass for first backward state LSTM 6: concatenate first LSTM states
7: forward pass for second forward state LSTM 8: forward pass for second backward state LSTM 9: concatenate second LSTM states
10: CRFs layer
11: Stacked Bidirectional LSTM-CRFs backward pass:
12: backward pass for second forward state LSTM 13: backward pass for second backward state LSTM 14: backward pass for first forward state LSTM 15: backward pass for first backward state LSTM 16: update parameters
17: end 18: end
4. 실험
4.1 실험 데이터본 논문에서 제안한 시스템을 기존 연구와 비교하기 위하여 기존 연구에서 사용한 Korean PropBank[12]를 학습 말뭉치로 사용하였다. Korean PropBank는 Virginia 말뭉치와 Newswire 말뭉치로 구성되어 있으나, Virginia 말뭉치가 군대 용어로 이루어져 있기 때문에 한국어 의 미역 결정에는 주로 Newswire 말뭉치가 사용된다. 또 한 기존 연구와 동일한 학습 및 평가 데이터를 구성하 기 위해 구구조로 되어 있는 말뭉치를 의존 구조로 재
표 3 학습 및 평가 셋의 문장, 어절, 의미역 태그 수 Table 3 Size of sentences, words, and semantic labels
for train and test sets
train test
Sentences 19302 3773
Words 469913 91958
Semantic labels 23
표 4 의미역 태그 집합 Table 4 Set of semantic labels Mandatory
labels
ARG0, ARG1, ARG2, ARG3, ARG4, ARG5, ARGA, ARGM
Optional labels
ARGM-ADV, ARGM-CAU, ARGM-CND, ARGM-DIR, ARGM-DIS, ARGM-EXT, ARGM-INS, ARGM-LOC, ARGM-MNR, ARGM-NEG, ARGM-PRD, ARGM-PRP, ARGM-TMP, AUX
None Label O
가공 하였다[1]. 표 3은 학습 및 평가 데이터의 문장, 의 미역을 결정할 단어, 의미역 태그의 개수를 나타내고 표 4 는 실제 사용된 의미역 태그 집합이다.
4.2 Word Embedding(단어 표현)
자연어처리에 딥러닝을 적용하는 경우 자연어처리 특 성상 자질의 차원이 매우 높아지는(course of dimen- sionality) 문제가 발생한다. 따라서 일반적인 딥러닝과 달리 대용량의 원시 말뭉치로부터 Neural Network Language Model(NNLM)로 학습한 단어 표현을 차원 축소(dimension reduction) 및 사전 학습에 사용한다[16].
NNLM은 언어모델을 인공 신경망을 이용하여 구현한 것으로, 목표 단어의 앞뒤 단어들을 신경망의 입력으로 받아 projection layer와 hidden layer를 거쳐 목표 단 어의 후보들의 확률을 구한다. 본 논문에서는 NNLM 모델 중 하나인 word2vec[17]을 이용하여 10만 단어를 50차원의 벡터로 압축한 한국어 단어 표현을 사용한다.
4.3 실험 결과
실험은 3장에서 기술한 각 딥러닝 모델에 같은 데이 터 셋을 이용하여 학습하였으며, 한국어 단어 표현은 4.2에서 구한 것을 이용하였다. Feature embedding은 평균이 0, 분산이 0.01이 되도록 임의로 초기화한 값을 사용하였다. 과적합 문제를 줄이기 위해 Dropout[18]을 projection layer와 hidden layer에 각각 0.2, 0.25, 0.5 의 값을 적용하였고, 그 중 가장 높은 성능을 보이는 값 을 사용하였다.
의미역 결정의 성능은 술어 인식 및 분류(Predicate Identification and Classification)와 논항 인식 및 분류 (Argument Identification and Classification)로 나눌 수 있는데, 본 논문에서 제시하고 있는 성능은 논항 인식 및 분류(AIC)[1]에 해당하며 성능 지표는 정확률(precision) 과 재현율(recall)의 조화평균인 F1값을 사용한다. 평가의 단위는 어절 단위이며, Micro average를 사용한다. 딥러 닝 기술은 학습 시 각 파라미터를 임의로 지정하기 때문 에 매 학습 시 성능이 다르게 나올 수 있다. 따라서 같은 학습 조건에 대해 10번의 반복 수행을 통해 얻은 성능의 평균을 구하였다. 또한 딥러닝의 hidden layer를 여러 층 으로 계속해서 쌓는 것이 의미역 결정 성능 향상에 도움 을 주는지 알아보기 위해 hidden layer를 각각 두 층과 세 층으로 쌓아 실험을 진행하였다.
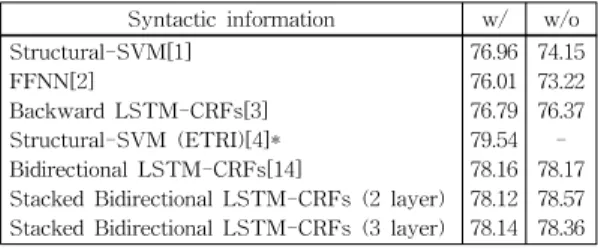
표 5와 6은 기계학습 모델 별 한국어 의미역 결정 실 험 성능 및 학습 속도 결과이다. w/는 기존 연구와 같 이 구문 분석 정보를 사용하였음을 의미하고 w/o는 본 논문에서 제안하는 구문 분석 정보를 사용하지 않는 End-to-end SRL 방법을 의미한다.
구문 분석 정보를 중요 자질로 사용하는 Structural- SVM[1]과 순차 데이터 모델링이 불가능한 FFNN 모델
표 5 모델 별 한국어 의미역 결정 성능 비교(AIC, F1) Table 5 Comparison of F1 scores of different models
Syntactic information w/ w/o Structural-SVM[1]
FFNN[2]
Backward LSTM-CRFs[3]
Structural-SVM (ETRI)[4]*
Bidirectional LSTM-CRFs[14]
Stacked Bidirectional LSTM-CRFs (2 layer) Stacked Bidirectional LSTM-CRFs (3 layer)
76.96 76.01 76.79 79.54 78.16 78.12 78.14
74.15 73.22 76.37 - 78.17 78.57 78.36
*Using WSD(word sense disambiguation) and NE(name entity) system, and Extending Frame file
표 6 모델 별 한국어 의미역 결정 학습 속도 Table 6 Comparison of Training time of different models
Model # sent/sec
FFNN[2]
Backward LSTM-CRFs[3]
Bidirectional LSTM-CRFs[14]
Stacked Bidirectional LSTM-CRFs (2 layer) Stacked Bidirectional LSTM-CRFs (3 layer)
274/sec 58/sec 36/sec 14/sec 9/sec
에서는 구문 분석 정보의 유무에 따라 의미역 결정 성능 변화가 뚜렷하게 나타났다. Structural-SVM에서는 -2.81%
의 성능 하락이, FFNN에서는 -2.79%의 성능 하락이 있 었다. 반면 순차 데이터 모델링에 적합한 LSTM RNN 을 적용한 Backward LSTM-CRFs 모델은 -0.42%의 경미한 성능 하락을 보였고, Bidirectional LSTM-CRFs 와 Stacked Bidirectional LSTM-CRFs 모델 에서는 성 능 하락이 나타나지 않았다. 이는 LSTM 구조가 멀리 있는 단어의 정보를 사용할지, 사용하지 않을지를 정하 여 마치 구문 분석 정보를 사용하는 것과 같은 효과를 나타낸다고 볼 수 있다. 또한 Bidirectional LSTM-CRFs 모델의 성능이 Backward LSTM-CRFs 모델 보다 1.3% 내지 1.8% 더 높게 나타났다. 이 결과로부터 이전 단어들의 정보와 더불어 다음 단어들의 정보를 같이 활 용하는 것이 한국어 의미역 결정 시스템 성능 향상에 도 움이 됨을 알 수 있었다. 모델 한국어 의미역 결정 성능 에서 [4]의 시스템이 가장 높은 성능을 보였는데, [4]의 시스템은 부가격 필터링, WSD와 NE 시스템, 프레임의 확장을 통해 자질 정보를 늘린 경우로 본 논문에서 제시 한 모델과는 그 차이가 있어 비교가 어렵다고 생각된다.
본 논문에서 제안한 Stacked Bidirectional LSTM- CRFs 모델의 성능이 Bidirectional LSTM-CRFs 모델 의 성능보다 0.5% 높게 나타났다. 이 결과가 유의미한 결과인지 알아보기 위해 각 실험 결과에 대해 paired t-test를 수행하였다. Paired t-test 수행결과 0.027의 p-value 값이 나와 의미역 결정의 성능 향상이 신뢰도 95% 에서 통계적으로 유의함을 알 수 있다.
추가적인 실험을 통해 Stacked Bidirectional LSTM- CRFs (3 layer) 모델의 의미역 결정 성능이 Stacked Bidirectional LSTM-CRFs (2 layer) 모델 보다 낮게 나타남을 알 수 있었다. 이를 통해 hidden layer의 중첩 이 성능 향상을 항상 동반하는 것이 아님을 알 수 있었 다. 또한 표 6의 모델 별 학습 속도 비교를 통해 본 논 문에서 제시한 모델이 이전 모델에 비해 성능은 높으나, [2-4]의 모델에 비해 다소 느린 학습 속도를 나타낸다.
이를 통해 모델의 복잡도에 따라 시스템의 성능과 학습 속도 사이의 trade-off가 있음을 알 수 있다.
5. 결 론
본 논문에서는 기존 LSTM RNN 모델에 Bidirectional LSTM RNN 구조와 hidden layer를 한층 더 쌓은 Stacked Bidirectional LSTM-CRFs (2 layer) 모델을 이용한 End-to-end SRL 방식의 한국어 의미역 결정 시스템을 제안하고, 이를 한국어 의미역 결정에 적용하 여 기존 연구 보다 더 높은 성능을 얻었다. 또한 기존 연구에 사용한 자질과 End-to-end SRL 방식의 자질 실험 결과 비교를 통해 Bidirectional LSTM RNN 구 조를 이용하여 문장 전체의 정보를 이용할 수 있을 뿐 만 아니라 LSTM RNN 구조를 통해 구문 분석 정보를 사용하는 것과 같은 효과를 낼 수 있음을 알 수 있었다.
또한 hidden layer를 두 층과 세 층 쌓는 실험을 통해 hidden layer의 중첩이 성능 향상을 항상 동반하는 것 이 아님을 알 수 있었다.
향후 연구로는 서술어가 가진 정보를 알맞게 활용하 기 위해 각 서술어 마다 학습의 깊이를 달리하는 다양 한 네트워크 구조를 연구하고 이를 한국어 및 다른 언 어에도 적용할 예정이다.
References
[ 1 ] Changki Lee, Soojong Lim, and Hyunki Kim,
"Korean Semantic Role Labeling using Structural- svm," Journal of KIISE, Vol. 42, No. 3, pp. 220-226, 2015.
[ 2 ] Jangseong Bae, Changki Lee, and Soojong Lim,
"Korean Semantic Role Labeling using Deep Lear- ning," Proc. of the KIISE Korea Computer Con- gress 2015, pp. 690-692, 2015.
[ 3 ] Jangseong Bae, Changki Lee, and Soojong Lim,
"Korean Semantic Role Labeling using Backward LSTM CRF," Proc. of 27th Hangul and Korean Information Processing Conference, pp. 194-197, 2015.
[ 4 ] Soojong Lim, Hyunki Kim, "A study of Korean Semantic Role Labeling using Word Sense," Proc.
of 27th Hangul and Korean Information Processing
Conference, pp. 194-197, 2015.
[ 5 ] Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa,
"Natural Language Processing (almost) from scratch,"
The Journal of Machine Learning Research, Vol. 12, pp. 2493-2537, 2011.
[ 6 ] Jie Zhou and Wei Xu, "End-to-end learning of semantic role labeling using recurrent neural net- works," Proc. of the Annual Meeting of the Asso- ciation for Computational Linguistics, pp. 1127- 1137, 2015.
[ 7 ] Kaisheng Yao, Baoling Peng, Yu Zhang, Dong Yu, Geoffery Zweig, and Yangyang Shi, "Spoken lan- guage understanding using long short-term memory neural networks," In: Spoken Language Technology Workshop(SLT), 2014 IEEE, pp. 189-194, 2014.
[ 8 ] Vasin Punyakanok, Dan Roth, and Wen-tau Yih,
"The importance of syntactic parsing and inference in semantic role labeling," Computational Linguistics, Vol. 34, Issue 2, pp. 257-287, 2008.
[ 9 ] Sameer Pradhan, Wayne Ward, Kadri Hacioglu, James H. Martin, and Daniel Jurafsky, "Semantic role labeling using different syntactic views," ACL '05 Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pp. 581- 588, 2005.
[10] Byoung-Soo kim, Yong-Hun Lee, Seung-Hoon Na, Jun-Gi Kim, and Jong-Hyeok Lee, "Bootstrapping for Semantic Role Assignment of Korean Case Marke," Proc. of the KIISE Korea Computer Con- gress 2006, Vol. 33, No. 1(B), 2006.
[11] Exobrain corpus[Online]. Available: https://astc.etri.
re.kr/.
[12] Martha Palmer, Shijong Ryu, Jinyoung Choi, Sinwon Yoon, and Yeongmi Jeon, Korean Propbank [Online].
Available: http://catalog.ldc.upenn.edu/LDC2006T03.
[13] Kim Wansu, Ock CheolYoung, "Korean Semantic Role Labeling using Case Frame and Frequency,"
Proc. of the KIISE Korea Computer Congress 2015, pp. 651-653, 2015.
[14] Jangseong Bae and Changki Lee, "End-to-end Learning of Korean Semantic Role Labeling Using Bidirectional LSTM CRF," Proc. of the KIISE Korea Computer Congress 2015, pp. 566-568, 2015.
[15] Changki Lee, "Named Entity Recognition using Long Short-Term Memory Based Recurrent Neural Network," Proc. of the KIISE Korea Computer Congress 2015, pp. 645-647, Jun. 2015.
[16] Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Janvin, "A neural probabilistic lan- guage model," The Journal of Machine Learning Research, Vol. 3, pp. 1137-1155, 2003.
[17] Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean, "Distributed Repre- sentations of Words and Phrases and their Com- positionality," Advances in neural information pro-
cessing systems, pp. 3111-3119, 2013.
[18] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhe- vsky, Ilya Sutskever and Ruslan Salakhutdinov,
"Dropout: a simple way to prevent neural networks from overfitting," Journal of Machine Learning Research, Vol. 15, No. 1, pp. 1929-1958, 2014.
배 장 성
2014년 강원대학교 학사. 2016년 강원대 학교 석사. 2016년 3월~현재 강원대학 교 박사과정. 관심분야는 자연어처리, 기 계학습, 인공지능
이 창 기
1999년 KAIST 학사. 2001년 POSTECH 석사. 2004년 POSTECH 박사. 2004년~
2012년 2월 ETRI 선임연구원. 2012년 3 월~현재 강원대 컴퓨터과학과 부교수 관심분야는 자연어처리, 정보추출, 정보 검색, 기계학습