A Study on Word Sense Disambiguation Using Bidirectional Recurrent Neural Network for Korean Language
*
전체 글
*
수치
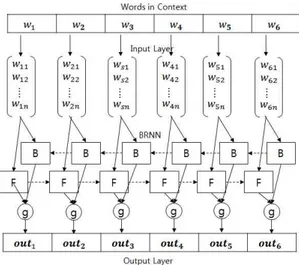
![Fig. 1. Structure of Recurrent Neural Network[5]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/5317263.385062/2.892.460.791.652.973/fig-structure-recurrent-neural-network.webp)
관련 문서
1) 주변상권이 외식사업에 적합하며 향후 발전가능성이 있는가. 3) 경쟁이 치열하거나 대형점포가 들어설 가능성은 없는가. 5) 주방상태나 기구, 시설 등의
제 2조 (계약문서) 계약문서는 계약서와 공사청부약관, 시방서, 첨부도 면,견적서의 사양의 기초로 해서 상호보완 효력을 가지며 을은 공ㅅ를 성실히 집행하며 갑은
휴게음식 영업자*일반음식점영업자 또는 단란주점 영업자는 영업장 안에 설치된 무대시설외의 장소에서 공연을 하거나 공연을 하는 행위를 조장*묵인하여서는
– 거리에 관계없이 개체를 같은 크기로 인식하고, 어떤 각도에서든 같은 형태로 보이는 것으로 지각 – 조명이 변하더라도 일정한 명도를 유지하고, 친숙한 개체는 감각
Therefore, this study speculated on block building toys that can enhance spatial sense in infants based on the development of creativity and sociability
시간에 종속되는 통행 속도의 특 성을 반영하기 위해 적용되었던 시계열 분석 기법인 Autoregressive Integrated Moving Average(ARIMA)와 순환 신경망(Recurrent
비속어 판별의 정확성을 높이기 위해 단어 의 의미와 형태적인 정보를 학습시켜 단어 임베딩(Word Embedding) 할 수 있는 FastText 모델과 문맥의 흐름을 학습 할
Appearance and prevalence of women hero novels at the time when existing sense of value collided with a new sense of value have significant meaning