With the rapid development of social media on the Internet, many customers can now express their opinion on various kinds of products in discussion groups, merchant sites, their personal blog or review website. People can make comments on products they have purchased, and express individual information that is about feelings, evaluations, and sentiments. As a result, more and more online product reviews are becoming available on the internet. However, it is almost impossible for a customer to read all of the opinions and discern a consensus opinion about a product. Therefore, automated opinion discovery and summarization systems have emerged to assist people in making an informed decision.
With this trend, sentiment analysis has grown out of this need. We can see the rising studies of analyzing opinionated information as a new research topic in natural language processing and web mining. Previous researches on this issue present various models that address different tasks of sentiment classification, subjective identification and aspect-based sentiment analysis. Sentence level and document level classification are widely studies topic; they identify subjective sentences and classifies a review as positive or negative. However, these tasks are too coarse for most applications nowadays because computed sentiment values
are not directly associated with the topics (i.e., entities or aspects of entities) discussed in the text. In contrast, aspect-based evaluation identifies the targets of the opinion and estimate aspect sentiment score. The more complicated a task is and the more information that’s input or output, the more subtleties and complex techniques an intelligent web mining system needs. Thus, most of recent researches focus on the tasks of product aspect extraction, aspect aggregation, aspect term sentiment estimation.
Our work is related but quite different from previous publications because we address the issue of aspect ratings and aspect weights by proposing a model that aims to represent customer reviews. The obtained representation is then used to generate the overall sentiment from a given review. Our model draws inspiration from prior work on sentiment analysis and distributed representations of words and phrases. We aim to develop a system that can utilize representation learning to predict product ratings from raw text representation to refined representation. Consider representation in our system to be a series of processing levels. The system starts processing at the lowest level (word representation) that is be a very specific representation and then, as levels increase, the representation becomes more aware of aspect rating representation. So that, the highest level of representation produces an overall rating as output.
리뷰에서의 고객의견의 다층적 지식표현
Anh-Dung Vo, 원광복, 옥철영 울산대학교
[email protected], [email protected], [email protected]
With the rapid development of e-commerce, many customers can now express their opinion on various kinds of product at discussion groups, merchant sites, social networks, etc. Discerning a consensus opinion about a product sold online is difficult due to more and more reviews become available on the internet. Opinion Mining, also known as Sentiment analysis, is the task of automatically detecting and understanding the sentimental expressions about a product from customer textual reviews. Recently, researchers have proposed various approaches for evaluation in sentiment mining by applying several techniques for document, sentence and aspect level. Aspect-based sentiment analysis is getting widely interesting of researchers; however, more complex algorithms are needed to address this issue precisely with larger corpora. This paper introduces an approach of knowledge representation for the task of analyzing product aspect rating. We focus on how to form the nature of sentiment representation from textual opinion by utilizing the representation learning methods which include word embedding and compositional vector models. Our experiment is performed on a dataset of reviews from electronic domain and the obtained result show that the proposed system achieved outstanding methods in previous studies.
Keywords: Aspect Based Sentiment Analysis, Knowledge Based, Opinion Mining, Representation Learning, Sparse Coding Approach, Word Embedding
As a result of the above analysis, it was found that aspect based is the most important application in opinion mining. The issue of product aspect extraction is getting widely interesting of researchers; however, to address this issue precisely is highly desired. To address this need, this literature offer a brief summary of the previous work in the context of ensemble methods for sentiment analysis.
Text summarization [1] emphasizes identification and extraction of certain core entities and facts that are packaged in a document. The extraction framework identifies certain segments of the text that are most representative of the document’s content. Moreover, the summarization of multiple documents is generated by selecting sentences that cover the most specific word associations within the documents. Our work is related but different from traditional text summarization. We do not summarize the reviews by rewriting a subset of the original sentences from the reviews to capture their main points as in traditional text summarization, but sought to represent reviews at different sentiment levels from textual sources to overall estimation.
Opinion mining can be classified into three subtasks topic: sentiment classification [2-4], subjective identification [5, 6] and aspect-based sentiment analysis. For example, sentiment classification classifies a review as expressing a positive or negative opinion. This task is also commonly known as document-level sentiment classification because the whole review is considered the basic information unit. The next level of sentiment analysis is subjective classification, which focuses on identifying subjective sentences. Sentiment analysis at both the document and sentence level are useful but they do not determine what people liked and disliked. Thus, algorithms are needed to digest a massive amount of information and extract aspects and the corresponding opinions. Herein, the task is focused on extracting product features that customers refer to in their reviews. To overcome this problem, researchers have proposed various approaches for evaluation based on frequent nouns [7, 8], topic modeling [9, 10], opinion target relations [11-13], and supervised learning [14-17]. Our work builds upon these researches in aspect ratings.
With progress of machine learning techniques in recent year, word embedding models become possible to train more complex Natural Language Processing (NLP) system on much larger data set, and they typically outperform the simple models. Vector-based models capture the rich relational structure of the lexicon by presenting words with
vectors that encode continues similarities between words as distance between word vectors in a high-dimensional space. The early work proposed by Bengio et al. focus on word vector representations as part of simple neural network architecture for language modeling [18]. Subsequently, a rapid spread and adoption in NLP was sparked when Mikolov et al. introduced an efficient model for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships [19, 20]. Hence, this approach has proven useful in NLP tasks such as part of speech tagging, word sense disambiguation, machine translation, named entity recognition, information retrieval, text classification, and web mining [21-29].
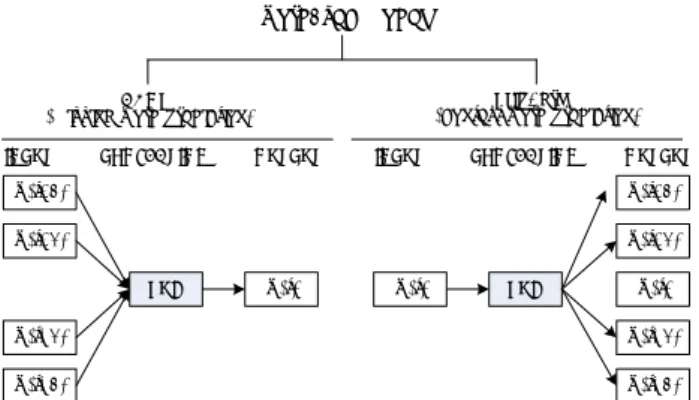
Recently, word2vec models gained popularity in neural network language model since they allow keeping semantic information by analyzing text in a sliding window depicted in FIGURE 1. Word2vec encode each word in a vector by representing words against other words that neighbor them in the training corpus. It does so in one of two ways, either using context to predict a target word (a method known as continuous bag of words, or CBOW), or using a word to predict a target context, which is called skip-gram. These models architecture is illustrated in FIGURE 2.
The CBOW architecture is similar to the Feedforward Neural Net Language Mode (FNNL)[18, 20]. It consists of input, projection, hidden and output layers. At the input layer, N previous words are encoded using 1-of-V coding, where V is size of the vocabulary. The input layer is then projected to a projection layer P that has dimensionality N×D, using a shared projection matrix. The projection layer is shared for all words; thus, all words get projected into the same position. CBOW based model is highly useful in identifying missing word in sentence or long phrase, bigram extracting, effective sentiment orientation.
Our model draws inspiration from prior work on sentiment analysis and distributed representations of words and phrases.
At both the document-level and the sentence-level,
months six camera G12 Canon a bought I ago
input context words m word window
(m=2)
input context words m word window (m=2) center word position t (target word) Wt-2 Wt-1 Wt Wt+1 Wt+2
FIGURE 1.Text analyzing in sliding window of size 5
SUM w(t+1) w(t+2) w(t-1) w(t-2) w(t) word2vec model CBOW
(missing word prediction) (context word prediction)Skip-gram INPUT PROJECTION OUTPUT
SUM w(t+1) w(t+2) w(t-1) w(t-2) w(t) INPUT PROJECTION OUTPUT
w(t)
FIGURE 2. Word2vec can be further categorized into continuous bag of words based architecture and skip gram based architecture.
estimated opinion values are indirectly related to the topics (i.e., products or aspects of products) expressed in the text. They are useful, but they are too coarse for most applications. In contrast, the aspect-based sentiment analyses found in recent surveys [30, 31] use more information from the review. To allow for an appropriate level of depth, we here emphasize a specific subtask of aspect-level analysis: identify aspect ratings from customer reviews. Opinion values on individual aspects affect the aggregate opinion about a product to varying degrees. Our work thus addresses the issues of feature-based summaries of product reviews [13]. In this paper, we focus on how to perform aspect-level sentiment analysis task based on representation learning methods. However, before going into the details of the task, we need to define the terminology of our system.
Reviews — Reviews, R = {r1, r2, … , r|R|} is a set of unstructured textual documents that contain opinions about a product.
Opinion — An opinion is defined as a quintuple (ej, ajk, soijkl, hi, tl) [13, 30], where ej is a target entity (product), ajk is an aspect of entity ej (product aspect), soijkl is the sentiment score of the opinion held by opinion holder hi about aspect ajk of entity ej at time tl, hi is an opinion holder, and tl is the time when the opinion was expressed.
Aspect — An aspect is also known as a feature of the product that is the opinion target. The aspect can be one of these terms: a part of the given product, an attribute of the given product, or an attribute of a known aspect of the given product. A product can also be an aspect. Let ej= {aj1, aj2, … , aj|ej|} is a set of |ej| aspects of entity ej. For example reviewers comment on aspects of camera such as battery, screen, lens, picture quality and so on.
Aspect ratings — Aspect ratings of entity ej from review rr R , denoted by ARjr= {arjr1, arjr2, … , arjr|Aj|} , is |Aj|
-dimensional vector, where arjrk is aspect rating score of aspect ajk from the reviewrr. Aspect rating arjrk is obtained from opinions in the review rr corresponding to aspect ajk.
Aspect rating weights — Aspect rating weights of entity ej
from reviewrr R, denoted byARWjr= {jr1,jr2, … ,jr|Aj|}, is |Aj|-dimensional vector, where jrk indicates the weighting of aspect arjrk on review rr. For normalization purposes, we ensure that the value for any jrk in the interval [0, 1] and the sum of entries ∑|Aj|jrk
1 is 1.
To allow for an appropriate level of depth, we here emphasize a specific subfield of aspect-level analysis: aspect ratings based on representation learning methods. The system takes a set of reviews R = {r1, r2, … , r|R|} as input and produces overall rating as output. The algorithm performs aspect ratings by combining information gained from individual aspect ratings based on a multilayer representation. The overall experimental architecture is illustrated in FIGURE 3.
The system architecture involves six main levels of representation from raw text representation to summary representation that implies the overall rating. These stages are described in detail in the following sections.
Word Representation Stage — The word representation
layer transforms each word from the given review into the corresponding semantic vector using the word embedding technique. The CBOW model is applied to generate word representation. In other words, a word is placed into a semantic space that obtained by learning a large corpus. Hence, word embedding model exploit distributional hypothesis by learning word vectors based on the local context of words. This probabilistic model on the other hand utilizes word co-occurrences across documents to identify topically related words.
Given a set of review reviews R = {r1, r2, … , r|R|}, suppose that each review 𝑟𝑟 𝑅 contains a set of sentences 𝑟𝑟𝑘= {𝑠𝑟𝑘1, 𝑠𝑟𝑘2, … , 𝑠𝑟𝑘|𝑆𝑟𝑘|} related to aspect 𝑎𝑗𝑘. Suppose that each sentence 𝑠𝑟𝑘𝑝 contains a set of words denoted by srkp= {wrkp1, wrkp2, … , wrkp|srkp|} and each word wrkpq is represented by a vector denoted byvrkpq. More generally, the word representation layer simply encodes each word into the corresponding semantic vector based on CBOW architecture.
Sentence Representation Stage — In this stage, words are combined to generate the sentence representation by applying a composition model [32-34]. Assume that, 𝑠𝑟𝑘𝑝 indicates a sentence that includes |srkp| word vectors denoted by {wrkp1, wrkp2, … , wrkp|srkp|} and each word is n -dimensional vector. The process of composition, known as sentence representation, computes the representation vector of S by the sum of its word vectors.
𝑣(𝑠𝑟𝑘𝑝) = ∑ 𝑓( 𝑛
𝑖=1
𝑤𝑟𝑘𝑝(𝑖−1)+ 𝑤𝑟𝑘𝑝𝑖)
Where v(srkp) is the computed representation vector of sentence srkp , (wrkp(i−1)+ wrkpi) is element-wise weighted addition of two components wrkp(i−1) and wrkpi . The Word Representations Sentence Representations Cross-Sentence Representations Aspect Representations Aspect Ratings Overall Rating Textual Sources Overall Estimation
FIGURE 3. The proposed system: levels of representations from raw text representation to abstract representation.
composition function f(wrkp(i−1)+ wrkpi) is hyperbolic tangent functions, defined as:
f(wrkp(i−1)+ wrkpi) = tanh (wrkp(i−1)+ wrkpi)
In other words, sentence representation layer capture bigram information, using a non-linearity over bigram pairs in its composition function:
v(srkp) = ∑ tanh (wrkp(i−1)+ wrkpi) n
i=1
More generally, the use of a non-linearity enables the model to learn interesting interactions between words in a review [35].
Cross-Sentence Representation Stage — We aim to
determine the influence of global contextual information on sentiment analysis. Indeed, considering the review as a whole can help to resolve ambiguities and inconsistencies. At this state, a cross-sentence context-aware technique is used to serves as an auxiliary information source for sentence representation.
Given a source sentence srkp that contains a set of words srkp= {wrkp1, wrkp2, … , wrkp|srkp|} , we consider its related sentences in the same review rr R as cross-sentence context RSsrkp. These related sentences are determined based on the dependence of all words in srkpupon exploiting certain
syntactic relationship. A sentence
srkq= {wrkq1, wrkq2, … , wrkq|srkq|} is related to sentence srkp if there exists a wrkqy srkq and a wrkx srkp that satisfies the word wrkqy is related to wrkx.Here, syntactic relationship is obtained from dependency relations and associated annotations.
Aspect Representation Stage — The system takes
obtained sentence representation as input and produces an aspect representation as output. The algorithm performs aspect representation by composing sentence representations using compositional vector model. Furthermore, a multilayer layers neural network is used in order to capture the relationship between aspects. Thus, the system utilizes the shared information between aspects to enrich the knowledge of the representation.
AspectRatingsStage — The aspect representation is then transferred to higher representation. Each element is a vector that represents the corresponding aspect. The system performs a process of computing the aspect ratings and aspect weights by fitting the weighted sum over all elements to the overall rating. Concretely, the sigmoid function is used to calculate the aspect rating and the parameters is obtained from the learning process.
Overall Ratings Stage — The highest level of
representation would be processed using a weighted sum function. The algorithm determines the importance degree of aspects and obtains the overall rating.
In this work, we focus on how to perform aspect-level product aspect ratings and weightings based on
representation learning methods. However, before going into the details of the learning model, we need to clarify the system model.
Given: A source reviewsR = {r1, r2, … , r|R|} , an entity (product) ej contains a set of product aspect ej= {aj1, aj2, … , aj|ej|}, is a set of system parameter (unknown parameters)
The task: To learn system parameters in order to perform aspect ratings and aspect weights.
Assume that V = {w1, w2, … , w|V|} is dictionary, each word wt V is represented by a one-hot vector x(wt) of size |V|. Given a sentence S including n words S = {w1, w2, … , wn} a window size of m, a target word 𝑤𝑖 is predicted based the
on the global context C = {wi−m, … , wi−1, wi+1, … , wi+m}. By applying CBOW model, the system takes one-hot vectors of context words in C as input and produces one-hot vector of the word 𝑤𝑖 as output. The CBOW model is illustrated in FIGURE 4 illustrated in which P1 and P2 are learning parameters. The parameters P1 R|V|×k, P2 Rk×|V| are the connection weight matrixes between input layer and projection layer, projection layer and output layer, respectively. We note that the 𝑡-th (1 t |V|) row of P1 R|V|×k is k-dimensional embedded vector for word w
t, and the l-th (1 l |V|) column of P2 is k -dimensional embedded vector for word 𝑤𝑙. The model aims to predict target word 𝑤𝑡 from bag-of-words context in terms of word vectors. The context is surrounding words in windows of radius m of center word. The probability p(wt|context), which has a loss function, e.g. J = 1 − p(w−t|context), look at many position 𝑡 in a big corpus, keep adjusting the vector representation of word to minimize this loss function. The conceptual objective function is described as follows:
J′() = ∏ ∏ p(wt|wt+j; ) −m≤j≤m(j≠0)
T
t=1 (1)
In which, is parameters of model that represents all variables we will optimize. It is going to be the vector representation of the words. The notation p is probability to a word appearing in the center word given a context; m indicates a window of size 2m; t + j indicates each position in the text; T implies taking the whole of corpus and go through each position in the text; J′ is objective function that maximizes the probability of any center word given the context words.
In practice, the function J′() can be turned to log probabilities by using Negative Log-Likelihood as follows:
INPUT PROJECTION OUTPUT
SUM ... P1 P1 P1 P2 P 1
J() = −T1∑Tt=1∑−m≤j≤m (j≠0)log p(wt|wt+j) (2)
Rather having probability the whole corpus, we can solve by taking the average (1𝑇 ) over each position (normalization). Furthermore, math gets easier to work by swapping between problems of maximizing and minimizing things. Softmax is known as a standard map from RV to a probability distribution. Hence, Softmax pi= e
ui
∑ ej ujcan be applied in J() by using word c to obtain probability of word o. For p(wt|wt+j) the simplest first formulation is p(o|c) = exp(uo Tvc)
∑V exp(uwTvc)
w=1 (3), where o is the center word index, c is the context (outside) word index, vc and uo are context and center vectors of indices o and c. Note that uwTvc indicates how similar each word is to vc.
Using Softmax function, the learning problem becomes: J() = −1T∑ ∑ log exp(uo Tvc)
∑Vw=1exp(uwTvc) −m≤j≤m (j≠0)
T
t=1 (4)
We can change parameters by using gradient to maximize the probability we predict J1() = log exp(uo Tvc)
∑V exp(uwTvc)
w=1 (5)
Let suppose we look at the context word, partial derivative with respect to the context word is applied for equation (5) as follows: J1′() = ∂ ∂vclog exp(uoTvc) ∑Vw=1exp(uwTvc) (6) J1′() = ∂
∂vc (log exp(uoTvc) − log ∑ exp(uwTvc) V w=1 ) J1′() = ∂ ∂vc uoTvc− ∂ ∂vc log ∑ exp(uwTvc) V w=1 J1′() = uo− ∂∂ vc log ∑ exp(uw Tvc) V w=1 (7)
Using the chain rule (𝑓 ° 𝑔(𝑥))′= 𝑔′(𝑥)𝑓′(𝑔(𝑥)) (8), the 𝐽 1′() in equation (7) becomes: J1′() = uo− 1 ∑Vw=1exp (uwTvc) ∂ ∂vc ∑ exp(uxTvc) V x=1 J1′() = uo− ∑ exp(u1 w Tv c) V w=1 ∑ ∂ ∂vc V x=1 exp(uxTvc) (9) Applying the chain rule (8), the 𝐽1′() in equation (9) is updated as: J1′() = uo− 1 ∑V exp(uwTvc) w=1 ∑ exp(uxTvc) V x=1 ux J1′() = uo− ∑ exp(uxTvc) ∑Vw=1exp(uwTvc) V x=1 ux= uo− ∑ p(x|c) V x=1 ux Finally, 𝐽1′() is written as:
J1′() = ∂ ∂vc= uo− ∑ p(x|c) V x=1 ux Where uo is observed and ∑V p(x|c)
x=1 ux is expectation of the probability that word x occurs given any context word c.
To minimize J() over the entire training data, the algorithm requires computing gradients for all windows. Parameters is updated for each element of with step α
θjnew= θjold− α ∂ ∂θjold
J(θ)
In other words, we will update parameters after each window t using stochastic gradient descent:
θnew= θold− α ∂ ∂θoldJ(θ) In matrix notation for all parameters:
θnew= θold− α∇θ J(θ)
In general, there are three kinds of metrics for evaluati ng an aspect-base system: Root Mean Square Error (RMSE) on aspect rating prediction, aspect correlation inside reviews, and aspect correlation across reviews prediction. Typically, RMSE is the standard deviation of the residuals (prediction errors). Residuals are a measure of how far from the regression line data points are; RMSE is a measure of how spreads out these residuals are and defined as RMSE = √(f − o)̅̅̅̅̅̅̅̅̅̅2, where f is forecasts (expected values), o is observed values (known results) and the bar indicates the mean.
Hence, in order to evaluate the performance of the aspect ratings, we use the same formula to verify experimental result, RMSE = [∑ ∑ (rf−ro)2 |D||A| |A| a=1 |D| d=1 ] 1 2 , where Σ is summation, (rf− ro)2 i s squared difference, |D| and |A| are size of reviews and aspects, and |𝐷||𝐴| indicates the sample size.
A large number of sources is needed for a knowledge-based system. However, to demonstrate how our method works in practice, we evaluate Customer review data1 and the SemEval-2016 Laptop Reviews-English2. These review collections are used to test our new system and to evaluate its performance. The Customer review data are a collection of annotated customer reviews of five products that were collected from amazon.com. They are labeled with respect to product aspect and their opinions. The SemEval-2016 Laptop is distributed in the context of the SemEval 2016, which annotated aspect categories and sentiment polarity labels at the text level. The obtained results of aspect ratings through the RMSE evaluation measure is shown in following table.
As shown in the Table 1, we achieved satisfactory experiment results. The aspect ratings task was evaluated on camera reviews and it showed the RMSE score of 0.793. Meanwhile, the evaluation of aspect ratings based on laptop reviews showed the RMSE score of 0.768. A model in previous study [7, 36] was implemented in order to evaluate the effectiveness of using higher aspect representation layer. The experiment shows that our system performs a better result than the related works.
1 https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#datasets 2 http://alt.qcri.org/semeval2016/task5/index.php?id=data-and-tools
TABLE 1.EXPERIMENTAL RESULTS
METHODS RMSE
Camera Laptop Latent Rating Regression 0.806 0.794
The structured knowledge representation, gained from learning process, can be used for deep inference. We can exploit such group aspects by mining different words and phrases that aim to describe the same product aspect. For example, in our experiment we found that display, screen, lcd refer to the same aspect for camera. Similarity, disk, hdd, ssd refer to the same feature for laptop. This kind of observation is used in the extensional parts of our system to analyze the relationship between sentiment and aspect, opinions and actions, and so on. Since reviews contain subjective and objective information, we have a lot of problems to deal with such as writing style, uncompleted sentence, short text, grammatical errors, informal text, internet slang, emotion, comparison, domain dependence, sarcastic statement, and so on. We had improved the system to address above issues.
This paper made an attempt to address product ratings issues based on multilayer representation architecture. Our work focuses on how to utilize the representation learning methods to obtain sentiment representation from textual customer review. Our models benefit from larger contexts, and would be possibly further enhanced by other information, such as aspect-opinion relations. This strategy may offer a new approach to address the issue of aspect-based sentiment analysis in large corpora and potentially apply in challenging tasks, such as implicit aspect inference, aspect grouping, and so on.
This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2016S1A5B6913773).
[1] Goldstein, J., et al., Summarizing text documents: sentence selection and evaluation metrics, in Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval. 1999, ACM: Berkeley, California, USA. p. 121-128.
[2] Turney, P.D., Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews, in Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. 2002, Association for Computational Linguistics: Philadelphia, Pennsylvania. p. 417-424.
[3] Pang, B., L. Lee, and S. Vaithyanathan, Thumbs up?: sentiment classification using machine learning techniques, in Proceedings of the ACL-02 conference on Empirical methods in natural language processing - Volume 10. 2002, Association for Computational Linguistics. p. 79-86.
[4] Vo, A.-D. and C.-Y. Ock, Sentiment classification: a combination of PMI,
sentiwordnet and fuzzy function, in Proceedings of the 4th international conference on Computational Collective Intelligence: technologies and applications - Volume Part II. 2012, Springer-Verlag: Ho Chi Minh City, Vietnam. p. 373-382.
[5] Riloff, E. and J. Wiebe, Learning extraction patterns for subjective expressions, in Proceedings of the 2003 conference on Empirical methods in natural language processing. 2003, Association for Computational Linguistics. p. 105-112.
[6] Mukund, S. and R.K. Srihari, A vector space model for subjectivity classification in Urdu aided by co-training, in Proceedings of the 23rd International Conference on Computational Linguistics: Posters. 2010, Association for Computational Linguistics: Beijing, China. p. 860-868.
[7] Moghaddam, S. and M. Ester, ILDA: interdependent LDA model for learning latent aspects and their ratings from online product reviews, in Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. 2011, ACM: Beijing, China. p. 665-674.
[8] Shu, L.a.X., Hu and Liu, Bing, Lifelong Learning CRF for Supervised Aspect Extraction. SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017: p. 148-154.
[9] Titov, I. and R. McDonald, Modeling online reviews with multi-grain topic models, in Proceedings of the 17th international conference on World Wide Web. 2008, ACM: Beijing, China. p. 111-120.
[10] Brody, S. and N. Elhadad, An unsupervised aspect-sentiment model for online reviews, in Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. 2010, Association for Computational Linguistics: Los Angeles, California. p. 804-812. [11] Qiu, G., et al., Expanding domain sentiment lexicon through double propagation, in
Proceedings of the 21st international jont conference on Artifical intelligence. 2009, Morgan Kaufmann Publishers Inc.: Pasadena, California, USA. p. 1199-1204.
[12] Z hang, L., et al., Extracting and ranking product features in opinion documents, in
Proceedings of the 23rd International Conference on Computational Linguistics: Posters. 2010, Association for Computational Linguistics: Beijing, China. p. 1462-1470.
[13] Vo, A.-D., Q.-P. Nguyen, and C.-Y. Ock, Opinion–Aspect Relations in Cognizing
Customer Feelings via Reviews. IEEE Access, 2018. 6: p. 6.
[14] 14. Kovelamudi, S., et al. Domain Independent Model for Product Attribute
Extraction from User Reviews using Wikipedia. in IJCNLP. 2011.
[15] Toh, Z. and J. Su, NLANGP at SemEval-2016 Task 5: Improving Aspect Based
Sentiment Analysis using Neural Network Features. Proceedings of the 10th International Workshop on Semantic Evaluation, 2016: p. 7.
[16] Pontiki, M., et al., SemEval-2016 Task 5: Aspect Based Sentiment Analysis. Proceedings of the 10th International Workshop on Semantic Evaluation, 2016. [17] Xenos, D., et al., Ensembles of Classifiers and Embeddings for Aspect Based
Sentiment Analysis. Proceedings of the 10th International Workshop on Semantic Evaluation, 2016: p. 6.
[18] Bengio, Y., et al., A neural probabilistic language model. J. Mach. Learn. Res., 2003.
3: p. 1137-1155.
[19] Mikolov, T., et al., Distributed representations of words and phrases and their compositionality, in Proceedings of the 26th International Conference on Neural Information Processing Systems - Volume 2. 2013, Curran Associates Inc.: Lake Tahoe, Nevada. p. 3111-3119.
[20] Mikolov, T., et al., Efficient Estimation of Word Representations in Vector Space. CoRR, 2013. abs/1301.3781.
[21] Gery, N.O.-A.P.M.M., Toward Word Embedding for Personalized Information Retrieval. Proceedings of the SIGIR 2016 Workshop on Neural Information Retrieval, 2016. abs/1606.06991.
[22] Amini, G.B.M.-R., An empirical study on large scale text classification with skip-gram embeddings. ACM SIGIR Workshop on Neural Information Retrieval, 2016. [23] Kuzi, S., A. Shtok, and O. Kurland, Query Expansion Using Word Embeddings, in
Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. 2016, ACM: Indianapolis, Indiana, USA. p. 1929-1932. [24] Liang, S., et al., Dynamic Embeddings for User Profiling in Twitter, in Proceedings
of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018, ACM: London, United Kingdom. p. 1764-1773.
[25] Song, Y. and C.-J. Lee, Embedding Projection for Query Understanding, in
Proceedings of the 26th International Conference on World Wide Web Companion. 2017, International World Wide Web Conferences Steering Committee: Perth, Australia. p. 839-840.
[26] Nalisnick, E., et al., Improving Document Ranking with Dual Word Embeddings, in Proceedings of the 25th International Conference Companion on World Wide Web. 2016, International World Wide Web Conferences Steering Committee: Montreal, Quebec, Canada. p. 83-84.
[27] Guo, J., et al., Semantic Matching by Non-Linear Word Transportation for Information Retrieval, in Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. 2016, ACM: Indianapolis, Indiana, USA. p. 701-710.
[28] Wang, R., et al., Graph-Based Bilingual Word Embedding for Statistical Machine Translation. ACM Trans. Asian Low-Resour. Lang. Inf. Process., 2018. 17(4): p. 1-23.
[29] Das, A., D. Ganguly, and U. Garain, Named Entity Recognition with Word Embeddings and Wikipedia Categories for a Low-Resource Language. ACM Trans. Asian Low-Resour. Lang. Inf. Process., 2017. 16(3): p. 1-19.
[30] Liu, B., Sentiment Analysis and Opinion Mining. 2012: Morgan & Claypool. [31] Medhat, W., A. Hassan, and H. Korashy, Sentiment analysis algorithms and
applications: A survey. Ain Shams Engineering Journal, 2014. 5(4): p. 1093-1113. [32] Blunsom, K.M.H.P., Multilingual Models for Compositional Distributed Semantics.
Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014. 1.
[33] Socher, R., et al., Semantic compositionality through recursive matrix-vector spaces, in Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. 2012, Association for Computational Linguistics: Jeju Island, Korea. p. 1201-1211. [34] Moritz Hermann, K.B., Phil, The Role of Syntax in Vector Space Models of
Compositional Semantics. ACL 2013 - 51st Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, 2013.
[35] Hermann, K.M. and P. Blunsom, Multilingual Models for Compositional Distributed Semantics. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 2014. 1.
[36] Wang, H., Y. Lu, and C. Z hai, Latent aspect rating analysis on review text data: a
rating regression approach, in Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. 2010, ACM: Washington, DC, USA. p. 783-792.