저작자표시-비영리-변경금지 2.0 대한민국 이용자는 아래의 조건을 따르는 경우에 한하여 자유롭게
l 이 저작물을 복제, 배포, 전송, 전시, 공연 및 방송할 수 있습니다. 다음과 같은 조건을 따라야 합니다:
l 귀하는, 이 저작물의 재이용이나 배포의 경우, 이 저작물에 적용된 이용허락조건 을 명확하게 나타내어야 합니다.
l 저작권자로부터 별도의 허가를 받으면 이러한 조건들은 적용되지 않습니다.
저작권법에 따른 이용자의 권리는 위의 내용에 의하여 영향을 받지 않습니다. 이것은 이용허락규약(Legal Code)을 이해하기 쉽게 요약한 것입니다.
Disclaimer
저작자표시. 귀하는 원저작자를 표시하여야 합니다.
비영리. 귀하는 이 저작물을 영리 목적으로 이용할 수 없습니다.
변경금지. 귀하는 이 저작물을 개작, 변형 또는 가공할 수 없습니다.
공학석사학위논문
User Diary Record 기반 m-Commerce 에서의 사용자 Context 를 고려한 Persona 모델링
Persona Modeling Considered User Context based on User Diary Record in m-Commerce Experience
2020 년 2 월
서울대학교 대학원 산업공학과
강 재 윤
User Diary Record 기반 m-Commerce 에서의 사용자 Context 를 고려한 Persona 모델링
Persona Modeling Considered User Context based on User Diary Record in m-Commerce Experience
지도교수 윤 명 환
이 논문을 공학석사 학위논문으로 제출함 2019 년 11 월
서울대학교 대학원 산업공학과
강 재 윤
강재윤의 공학석사 학위논문을 인준함 2019 년 12 월
위 원 장 박 우 진 ( 인 )
부위원장 윤 명 환 ( 인 )
위 원 조 성 준 (인)
i
초록
사용자 중심의연구는 제품과 서비스의 물리적스펙의 전체적인 상향 평준화이후 제품/서비스 차별화를 위한 연구 방향으로써 주목받았고 점차 제품/서비스개발에서 주요 연구 방법으로 자 리잡았다 [1]. 상거래환경에서 모바일 환경은빠른 변화와개인의맞춤형 서비스에 대한 요구 로 사용자에 대한 이해가 과거보다 더 크게 요구되었다. 빅데이터를 통한 사용자 분석이 새로 운 수단으로 주목받고 있지만 요구되는 데이터의 크기가 상대적으로 매우 크며 이러한 데이터 를 확보하고 처리하는 데에는 시간과 비용이 많이 든다. 이번 연구에는 사용자가 양식에 맞춰 스스로 기록한 User Diary Record (UDR)로부터 얻은 인사이트를 바탕으로 사용자의 경향성을 분류하는 행동 변수를 정의하고 이에 따라 사용자에게 좌표 공간 상의 위치를 부여하여, 유클 리드 거리에 기반을 둔 사용자 별 유클리드 유사도를 구하고 기준 유사도 설정과 UCINET을 활용한 분석을 통해 사용자세그멘트를 구하는 방법론을 제안한다. 또한 구해진 사용자세그멘 트의 행동 변수 평균 수치를 세그멘트 별 사용자 모델로 제안하였으며 CONCOR 분석을 통해 얻은 사용자 클러스터 결과와 비교하였다. 본 연구의 결과를 맞춤형 서비스 제공을 위한 사용 자 세그멘트 추출과신규 사용자의 빠른 세그멘테이션에 활용할 수 있을 것으로기대된다.
주요어: 사용자 경험, 페르소나, 사용자 세그멘트, 세그멘테이션
학번: 2018-24830
ii
목차
초록 i
목차 ii
표 목차 v
그림 목차 vi
제 1 장 서론 1
1.1 연구배경 및목적 ··· 1
1.2 문제정의 ··· 7
1.3 연구 동기및 공헌 ··· 8
1.4 논문구성 ··· 9
제 2 장 선행연구 및 배경 이론 10
2.1 사용자 연구방법론에 대한연구 ··· 102.2 수집 데이터활용 및분석에 대한 선행연구 ··· 11
2.3 사용자 세분화 ··· 13
2.4 다차원척도법(MDS)과 좌표공간에서의 거리 ··· 14
2.5 행동 변수 ··· 15
제 3 장 연구 방법 16
3.1 UDR 수집··· 163.2 키워드추출 및행동 변수정의 ··· 18
iii
3.3 공간좌표사이의 유클리디안 거리 계산 ··· 19
3.4 실험참여자 별유사도 계산 ··· 19
3.5 유사도매트릭스 기반시각화 ··· 19
3.6 기준유사도에 따른그룹 생성비교 ··· 20
3.7 유사도필터링 및 CONCOR 분석 결과비교 ··· 20
제 4 장 실험 결과 및 논의 21
4.1 UDR 분석결과 ··· 214.2 행동변수 정의결과 ··· 23
4.3 행동변수 별수준 부여결과 ··· 25
4.4 유클리디안거리 계산결과 ··· 27
4.5 유클리디안유사도 계산결과 ··· 28
4.6 UCNINET을통한 유사도기반 시각화 ··· 29
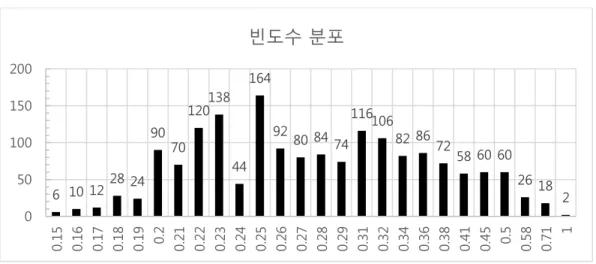
4.7 실험참여자 간유사도 분포조사 ··· 30
4.8 기준유사도 설정이후 세그멘테이션 결과 ··· 31
4.9 세그멘트별 특성확인 ··· 34
4.10 필터링 이후 세그멘테이션 결과 비교 ··· 38
4.11 CONCOR 분석 클러스터링 결과 비교 ··· 46
제 5 장 결론 50
5.1 결론 ··· 505.2 향후 연구 ··· 53
참고문헌 55
iv
Abstract 59
감사의 글 60
v
표 목차
표 4.1.1: Keyword ··· 21
표 4.1.2: Insight ··· 22
표 4.2.1: 행동 변수 ··· 23
표 4.2.2: 행동 변수양극단 설정 ··· 24
표 4.3.1: 행동 변수부여 결과 ··· 25-26 표 4.3.2: 분산 및표준편차 ··· 25-26 표 4.4.1: 유클리디안 거리계산 결과 ··· 27
표 4.5.1: 유클리디안 유사도 계산결과 ··· 28
표 4.7.1: 유사도 분포 ··· 30
표 4.9.1: 세그멘트 A ··· 34
표 4.9.2: 세그멘트 B ··· 34
표 4.9.3: 세그멘트 C ··· 34
표 4.9.4: 세그멘트 D ··· 35
표 4.9.5: 세그멘트 E ··· 35
표ᅟ4.9.6: 각 세그멘트 별 행동 변수 평균 값과 분산 값, 행동 변수 별 각 세그멘트 사이의 분산 (유사도 0.58의경우) ··· 37
표 4.10.1: 유사도가중치 계산결과 ··· 38
표 4.11.1: 유사도 로그곡선 가중치 계산결과 ··· 47
vi
그림 목차
그림 2.4.1 사용자 행동패턴 매핑예시 ··· 15
그림 3.1.1: UDR 입력 양식 ··· 17
그림 3.2.1: 행동 변수 생성및 사용자행동 변수 수준 도출 과정 ··· 18
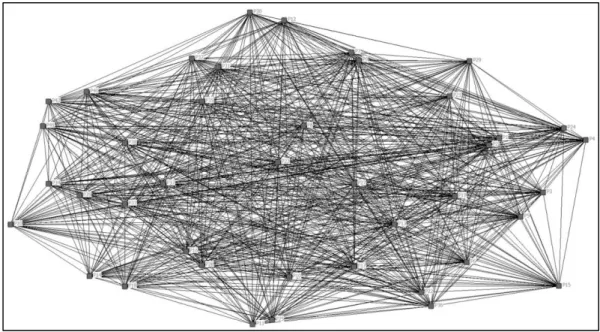
그림 4.6.1: 네트워크 시각화 ··· 29
그림 4.7.1: 유사도 분포 ··· 30
그림 4.8.1 유사도 0.44 기준실험 참여자네트워크 시각화 결과 ··· 31
그림 4.8.2: 유사도 0.45(左上)/ 0.50(右上) / 0.58(左下) 별 실험 참여자 유사도 네트워크 시각화결과 및전체 결과(右下) ··· 32
그림 4.9.1: 유사도 0.50 기준 실험 참여자네트워크 시각화결과 ··· 34
그림 4.9.2: 유사도 0.58 기준 실험 참여자네트워크 시각화결과 ··· 36
그림 4.10.1: 로그가중치 유사도 결과 0.17 기준유사도 세그멘테이션 결과(左) 0.45 기준유사도 세그멘테이션 결과(右) 비교 ··· 39
그림 4.10.2: 로그가중치 유사도 결과평균 기준유사도 세그멘테이션 결과(上) 평균기준 유사도세그멘테이션 결과(下) 비교 ··· 40
그림 4.10.3: 각실험 참여자 별타 유사도평균 기준(M) 필터링 ··· 41
그림 4.10.4: 각실험 참여자 별유사도 평균배수 기준(M*1.3) 필터링 ··· 42
그림 4.10.5: 각실험 참여자 별유사도 평균배수 기준(M*1.4) 필터링 ··· 43
그림 4.10.6: 각실험 참여자 별유사도 평균배수 기준(M*1.5) 필터링 ··· 44
그림 4.10.7: 실험참여자 별 유사도평균 배수 기준(M*1.8) 필터링 ··· 45
그림 4.10.8: 실험참여자 별 유사도평균 배수 기준(M*1.9) 필터링 ··· 46
그림 4.11.1: CONCOR Attribute to group by: 3/ Scrunch Factor: 8 Diagram depth: 3 ··· 48
그림 4.11.2: 유사도 0.58 기준 실험참여자 네트워크 시각화결과 및 CONCOR 분석클러스터링 결과비교··· 49 그림 5.1.1: 유사도 평균 배수 기준(M*1.9) 필터링 결과(左)와 일괄 적용(0.58)결과(右)
vii 51
1
제 1 장 서론
1.1 연구 배경 및 목적
상거래란 상업상의 거래로 제품이나 서비스를 거래를 통해 공급자와
사용자가 주고받는 활동이다. 사용자는 거래의 결제 방법으로 현금이나 카드, 앱 결제 등을 사용하여 공급자에게 제품/서비스의 가치에 해당하는 금액을 지불한다.
상거래에는 TV매체나 인터넷매체를 통하여 제품/서비스를 예약하거나 구매하는
것도 포함된다. TV매체를 이용한 전자상거래로는 TV홈쇼핑이 있고,
인터넷매체(스마트폰, 데스크탑, 노트북 등 활용)를 활용한 전자상거래로는
온라인쇼핑몰(앱 마켓, 소셜 커머스, 해외 직구 포함)과 개인 간의 물품 거래(중고 물품 거래 및 개인 블로그 판매 등) 등의 구매 방식이 있다. 1990년대부터
인터넷을 사용할 수 있는 장비의 확산과 지식 교육으로 영향으로 인터넷 상으로 상거래가 활성화 되었고 인터넷상에서의 전자 상거래(e-Commerce)가 점차 증가하였다[1]. 이후 2000년 초 등장한 스마트폰의 보급과 기술 발달로 사용자가 어디에서나 정보를 찾고 접근하여 결재하는 유비쿼터스(Ubiquitous) 상거래 환경이 갖춰지게 되었다. 스마트폰을 활용한 상거래인 모바일 커머스(m-
Commerce)는 앱 결제 등의 간편해진 결제 방법과 생체 인식 등 간소화된 인증
절차 등의 수혜를 입어 더 빠르게 발전하고 있다. m-Commerce가 전체 전자 상거래에서 차지하는 비중은 점차 증가하여 국내의 경우 2017년 모바일 커머스의 시장 중 모바일 쇼핑의 규모가 전체 온라인 쇼핑 시장 규모의 64%를 차지하였다.
이처럼 모바일 커머스의 범위는 넓어지고 간편 결제 기술 등의 발달에 힘입어 규모가 점차 증가하고 있다[2].
현재 2018년 기준 대한민국 전체 가구 중 99.5%의 비율이 인터넷 접속 가능이 가능한 것으로 나타났는데 이 가구들 중 94.8%가 스마트폰을 가지고
2
있으며 데스크톱(56.3%)과 노트북(24.2%)을 가지고 있는 것으로 나타나 접속 매체 보급률에 있어서 스마트폰이 다른 기기와 큰 격차를 보였다[3]. 사용자의 온라인(On-line)상태가 점차 개인의 모바일 디바이스(스마트폰)를 통해
이루어지고 있고 생체 정보를 통해 잠금 암호와 결제 암호를 대체하는 등 모바일 디바이스가 사용자의 온라인 연결 디바이스이자 사용자의 정보를 담고 있는 일체화된 기기로서의 모습을 볼 수 있다.
또한 오프라인 시장과 다르게 온라인 상태로 연결된 m-Commerce의 경우 어플리케이션의 업데이트와 같은 방법으로 빠른 변화가 가능하기 때문에 m-
Commerce 시장은 변화가 가장 민첩한 활발한 특성을 가지고 있으며
사용자로부터의 요구에 부응할 기대를 받고 있는 시장이라고 볼 수 있다. 기술의 발전으로 많은 영역에서 과거로부터 이어지던 전통적인 행동 양식이 없어지거나 새롭게 등장한 기술과 서비스를 활용해 전에 없던 행동 양식들이 생기고 있다.
m-Commerce 시장에서 사용자들이 보이는 행동 특성은 e-Commerce에서
보이는 행동과 차이가 있기 때문에 사용자에 대한 빠른 이해가 중요하게 되었다[4]. 높은 온라인 쇼핑몰의 거래 증가율은 상거래에서의 소비자의 이용 방식 변화가 예상 될 뿐 아니라 기업들의 온라인 환경에서의 경쟁이 가속화되고 있는 상황임을 알 수 있다[5].
실제로 사용자의 이용 행태의 변화에 대한 이해를 바탕으로 사용자들을 많이 모아 시장의 주도권을 가져와서 기존 경쟁 관계에 있던 경쟁사보다 우위에 서는 사례가 증가하고 있다. 또한 상대적 후발 주자인 신생 기업이 사용자들에게 차별화된 사용자 경험을 제공하여 기존에 지배적인 입지를 가지고 있던
기업으로부터 시장 점유율을 유의미하게 가져오는 사례들이 증가하고 있다. 예를 들어 국내 간편 송금 시장의 경우 2018년 기준 97%의 점유율을 신생 기업이 점유하였는데 인증절차를 간소화한 간편하고 빠른 송금 절차를 제공한 것이 주요한 요인으로 생각된다[6].
상거래에 있어서 고객 관계 관리(Customer Relationship Management)를
3
통해 고객을 세분화(Segmentation)해 차별화된 서비스를 제공하는 방법은 전통적으로 시도되어왔다[7]. 하지만 윤종수(2016)의 연구에 따르면 성별이나 연령대와 같은 단순한 사용자 구분으로는 사용자들의 성향 유형에 유의미한 연관성을 찾을 수 없었다[8]. 따라서 사용자를 이해하는 다른 측면의 접근과 분석이 필요하다고 볼 수 있다.
사용자를 이해하기 위해 사용자 자체만이 아니라 제품/서비스를 사용하는 과정 전체를 이해할 필요가 있다. 제품/서비스를 사용하는 사용자가
제품/서비스와 접촉하는 모든 형태의 접촉면을 유저 인터페이스(User Interface;
UI)라고 볼 수 있다. 또한 사용자가 인터페이스와 상호작용(Interaction)하는 일련의 전체 과정을 사용자 경험(User Experience; UX)으로 볼 수 있다. 이러한 사용자 경험이 이루어지는 과정에서의 사용 문맥(User Context)에는 사용자의 사용 목적, 사용 수단, 사용 당시의 정황 등 사용자의 행동을 설명하는 많은 내용이 담길 수 있다.
사용 문맥을 파악하는 과정에서 사용자들에 대한 많은 인사이트(Insight)를 얻을 수 있다. 이러한 인사이트는 사용자 맞춤형 서비스 개발, 사용자 경험 개선 등으로 이어질 수 있다. 그러므로 사용 문맥을 정확하게 분석하여 이해하는 방법론의 개발과 활용은 사용자를 위한 UX / UI 연구에 있어서 중요한 접근이라고 볼 수 있다.
이러한 사용자 입장에서의 연구는 초기에는 산업화시대가 시작되고 규격의 개념으로 보다 많은 사용자가 사용할 수 있도록 사용자의 평균 신장이나 팔 길이 같은 신체적 요소 등 물리적인 요소를 고려한 인간 공학(Human Factor)의 측면에서 고려되었다고 볼 수 있다. 따라서 UX의 개념은 크게 부각되지 못했고 PUI(Physical User Interface) 개선의 관점에서 많이 연구되었다. 그 이후 버튼 및 키보드와 디스플레이로 이루어진 전자식 입력 및 출력 장치가 확대
보급되었고, 사용자가 도구를 사용하는 과정에서 인터페이스를 통한 시각적 상호작용이 중요시되었다. 또한 센서로부터의 사용자로의 정보 표시와 전달에
4
대한 개념이 부각되었다. 때문에 이후 HCI(Human Computer Interaction) 측면의 접근이나 정보 전달의 효율에 대한 연구 등이 중심이 되었다. 또한 차별화된 디자인 요소가 시장에서 요구되면서 사용자의 감성을 만족시킬 수 있는 감성 디자인을 위한 감성 공학도 주목받았다.
감성 공학(感性 工學)은 Kansei Engineering의 우리말로 해당 용어가 처음으로 사용되었던 공식적인 기록은 1986년 10월 23일에, 미국의 미시건 대학에서 당시 마쓰다 자동차의 회장이던 야마모토 켄이치가 했던 강연인
‘Kansei Engineering - The Art of Automotive Development at Mazda’에서가 최초인 것으로 알려지고 있다[9]. 야마모토 켄이치는 오감을 초월한 전체적인 감각 또는 이를 초월한 감각을 감성이라고 설명했고 이는 일본식으로 감성을 발음한 칸세이(Kansei)가 그대로 용어화 되었다. 이후 1990년대 물리적 요소에 대한 상향평준화가 이루어지고 제품/서비스의 차별화를 위한 돌파구를 찾는 과정에서 감성 공학이 부상하였고 이와 같은 움직임은 사용자의 선택 기준이 점차 변화하고 있는 것으로 해석할 수 있다.
사용자들이 제품/서비스에 접근하는 상황적 맥락은 스마트폰과 태블릿 같은 모바일 기기와 고속 인터넷 망이 널리 보급되면서 사용자들이 자신이 원하는 시간과 장소에서 거의 모든 제품/서비스에 접근할 수 있게 됨에 따라 다양해졌다.
따라서 제품/서비스를 공급하는 공급자는 이제 사용자들의 다양한 사용 맥락(Context-of-Use)을 이해하기 위해 사용자에 대한 데이터 수집과 이를 연구하기 위한 다양한 방법론들을 개발하였다.
사용자에 대한 연구는 사용자들로부터 데이터를 수집하는 것으로 시작한다.
설문과 인터뷰 (1:1 인터뷰, 포커스 그룹 인터뷰, 전문가 인터뷰 등) 등의 전통적인 방법을 통해 데이터를 수집하는 방법은 이메일이나 어플리케이션을 통해서 현재까지도 여전히 쓰이고 있다. 인터뷰 외에도 사용자를 관찰하면서 사용자로부터 사용 맥락을 수집할 수 있으며 최근에는 사용자와 공급자가 온라인 상태로 연결되어 사용자의 행동양식 데이터가 실시간으로 수집된다. 최근에는
5
소셜 네트워크 서비스(Social Network Service)등을 통해서 사용자가 공급자에게 피드백을 주면서 직접 개선을 요구하는 경향이 있다. 이처럼 데이터의
소스(Source)가 다양해진 지금에는 연구자가 선택할 수 있는 데이터 수집 방법이 다양해졌다.
사용자가 제품/서비스를 이용할 때의 사용 문맥적 데이터를 수집하기 위한 방법에는 1998년 Hugh Beyer와 Karen Holtzblatt가 개발한 문맥적
이해(Contextual Inquiry)를 예시로 들 수 있다. 이 방법은 사용자가
제품/서비스를 이용하는 장소로 찾아가 사용자가 하는 행동을 관찰하고 사용자가 제품/서비스를 이용하면서 보인 행동의 이유에 대해 질문하는 순서를 거친다.
이는 사용자 현장 관찰과 인터뷰를 결합한 방식으로 사용자와 적극적으로 상호작용하는 과정에서 많은 구체적 사용 문맥 데이터를 수집할 수 있다[10].
사용자 현장 관찰 방법의 경우 사용자가 있는 공간에서 고정식 또는 이동식 관찰 도구를 활용하여 사용자의 사용 맥락 정보를 수집한다. 고정식 관찰의 경우 설치형 카메라를 많이 사용하며 이동식 관찰의 경우 섀도잉(Shadowing)의 형태로 관찰자가 사용자를 계속 따라다니면서 사용자의 일상을 기록한다. 하지만
사용자가 자신이 관찰 당하고 있다는 사실을 자각하고 자신의 행동을 조정하는 등의 왜곡이 일어나는 호손 효과(Hawthorne Effect) 등의 문제점이 지적되고 있다[10].
관찰자의 개입 효과를 배제하기 위해 단서(Probe) 수집 등의 방법 또한 사용되고 있다. 문화적 증거(Cultural Probes)로 명명된 이 방법은 사용자가 자신의 행동에 대한 기록을 남기는 것으로 데이터를 수집하는 방법이다. 이때 사용자 스스로 기록을 남기기 때문에 허위 사실이나 객관적이지 못한 정보가 기록되는 문제점 등이 지적된다.
사용자로부터 수집한 데이터를 분석하여 활용하는 방법 또한 데이터 수집 방법의 진화와 더불어 여러 방식으로 제안되었는데 대표적으로 “사용자 모델”의 개념을 도입하여 “사용자 모델”과 “주변 환경”과의 “관계”의 관점에서
6
제품/서비스가 사용되는 과정을 이해하려는 사용자 시나리오(Scenario), 사용자 프로필(Profile), 사용자 역할(Role), 페르소나(Persona) 등의 방식이 제안된 바 있다. 하지만 해당 사용자의 유형이 얼만큼 보편적이고 공통적인 특징을 가지고 있는지 설명하기 어렵고 연구자가 강하게 인상을 받은 특정 인사이트나
에피소드를 강조하게 되는 문제점이 있다[10]. 강은혜와 박남춘(2014)은 사용자의 행동 변수라는 개념을 도입하여 사용자 군을 설정하는 사용자 행태 패턴 매핑의 개념을 소개한 바 있으나 해당 연구에서는 매핑 과정에서 연구자의 주관이 강하게 개입되는 한계점이 있다[12].
곽원섭(1998)의 연구에서 중다차원척도법(Multidimensional Scaling; MDS)을 활용한 사용자의 선택 이유의 독특성에 대한 연구가 이번 연구에서 활용된 유클리디안 거리를 유사하게 활용하는 접근을 보여주었다. 하지만 해당 연구는
45개의 내구재 및 비내구재 상품에 대한 선택의 이유에 대한 연구로 사용자의
행동 변수의 개념 대신 소비자에게 설문 형식으로 선택 이유를 수집하여 벡터의 방향성으로 결과를 해석하였기 때문에 이번 연구에서 활용하는 각 요소별 거리에 기반한 유클리디안 유사도를 활용하지는 않았다[13].
사용자 집단을 이해하는 방법으로 세그멘테이션의 방법을 활용하는 경우 전체 사용자로부터 일정하게 동일한 경향성을 가지는 사용자 세그멘트를 분리시켜 이해하고 해당 세그멘트에 적합한 서비스 등을 제공하는 방법 있는데 세그멘테이션 과정에서 사용 문맥적인 고려와 이를 활용한 방법론이 부족하다고 보았다.
따라서 이번 연구의 사용자들의 사용 문맥상 경향성을 확인하고
세그멘테이션하는 방법을 제안하기 위해서 위해 가장 활발하고 가장 민첩하게 변화하는 m-Commerce 환경에서 사용자 데이터를 수집하였다. 이를 기반으로 새로운 사용자 세그멘테이션 방법론을 제안하고, 세그멘테이션 결과물을 분석하여 효과를 확인하며, 추후 활용방안을 제안하는 것이다.
7
1.2 문제 정의
사용자로부터 사용 문맥(Context)을 수집하고 이해하기 위해 개인 및 집단 인터뷰, 실제 관찰, 재현 등의 방법을 사용하는데 이러한 방법으로부터 얻은 데이터들은 단순 통계 처리가 어려운 정성적 데이터가 다수이다. 최근 정성적 데이터 분석에 데이터 마이닝(Data Mining)의 활용이 증가하고 있지만 이러한 기법을 활용하기 위한 빅데이터 구축에는 물리적으로 대량의 데이터가 필수적이다. 하지만 앞서 언급된 심층 인터뷰 결과나 사용자 관찰 기록 등은 대량으로 수집하는데 시간과 비용 측면에서 큰 어려움이 있고 연구 과정에서 얻은 인사이트를 분석을 위한 수준으로 적절하게 전처리하는 과정에 많은 연구 인력이 필요해 어렵다. 또한 전문가 활용 방식으로 휴리스틱을 통해 데이터를 분석하고 인사이트를 얻는 과정에서도 연구자의 주관이 지나치게 크게 반영될 수 있는 문제가 있다. 또한 해당 방법으로 얻은 인사이트를 반영하여 생성한 페르소나가 다른 사용자들과 어떠한 수준의 관계성이 있는지, 전체 사용자에 대한 대표성을 가지고 있는지를 확인하기 어렵다는 문제가 있다.
1.3
연구 동기 및 공헌
따라서 앞서 언급한 문제가 상대적으로 적은 데이터의 연구 분석 방법을 제안하는 것을 통해 사용자들의 “지출 과정”에서의 주요 고려 사항을 파악하고
“집단적 경향성”을 도출하여 사용자 모델로 재구성하는 과정을 체계적으로 할 수 있는 방법론을 제안하고자 하였다. 이 방법론을 다른 사용자 연구에도 사용자 모델 생성 방법으로 활용할 수 있을 것으로 기대한다.
8 본 연구의 동기 및 공헌은 다음과 같다.
(a) 수집한 사용자 사용 문맥 데이터로부터 얻은 인사이트로부터 사용자 행동 변수를 정의한다
(b) 사용자들을 정의한 행동 변수에 따른 경향성 수준을 부여하여 유클리디안
유사도를 구하고, 이를 기반으로 한 기준 유사도 기준 설정을 통한 세그멘테이션 방법을 제안한다.
(c) 세그멘테이션을 진행한 결과를 분석하여 고객 세그멘트의 특징을 파악한다.
(d) 고객 세그멘트의 특징에 부합하는 사용자 모델을 생성하여 이를 맞춤형 서비스 등에 활용하도록 제안한다.
1.4 논문 구성
본 논문은 5 장으로 구성되어 있음을 밝힌다. 본 항목이 포함된 제1장에서는 연구 배경과 연구 방향 대해 기술한다. 제2장에서는 선행 연구 및 배경 이론에 대한 내용을 담았다. 제3장에서는 연구 방법을 소개한다. 제4장에서는 3장에서 소개한 연구 방법을 데이터에 적용한 결과를 소개하고 이에 대한 논의를 적었다.
제5장에서는 이번 연구의 결론과 향후 나아갈 연구의 방향을 제시하였다.
9
제 2 장 선행 연구 및 배경 이론
2.1 사용자 연구 방법론에 대한 연구
2.1.1 사용자 인터뷰
사용자가 어떻게 제품/서비스를 사용하는지 데이터를 얻기 위해 설문/인터뷰하는 방식은 전통적으로 사용되어 왔다. 인터뷰는 포커스 그룹 인터뷰와 같이 인터뷰 대상의 규모와 대상, 방법 등에 따른 분류가 있으며 설문과 함께 사용자의 일반적인 태도와 인식에 대한 정보를 모으는데 적합하다[15]. 인터뷰 결과는 설문 작성 결과나 인터뷰 당시의 영상 등으로 기록을 남겨 데이터화 한다. 인터뷰는 사전에 질문의 틀이나 방향을 정하고 진행되기 때문에 사용자가 답변할 수 있는 내용의 한계의 영역이 정해진다. 따라서 인터뷰 과정에서 브레인스토밍 (Brainstorming)이나 마인드 매핑(Mind Mapping), 카드 소팅(Card Sorting) 등의 정해진 틀 외의 창의적 아이디어를 수집할 수 있는 활동을 진행하여 추가적인 데이터를 수집할 수 있다.
2.1.2 사용자 관찰 방법
사용자의 행동을 관찰하고 기록하는 방법으로 관찰의 장소나 활용 방법에 따라 분류할 수 있다. 먼저 에스노그래피(Ethnography)나 Contextual
Inquiry[17]와 같은 형태의 인류학에서도 쓰이는 필드 리서치 방식으로
사용자의 사용 환경 속에 Deep Dive하여 관찰을 진행하는 방법이 있다.
이는 사용 맥락 전체를 수집할 수 있는 장점이 있지만 연구에 많은 시간과 비용이 드는 단점이 있다[15]. 또는 실험실이나 사용 환경을 재현한 공간에서 사용자가 과업을 수행하고 사용자에게 다양한 센서를
10
부착하거나 다양한 관찰 카메라를 통해 사용자의 정밀한 움직임을 감지하는 방식으로 관찰할 수 있다[16]. 사용자를 동행 관찰(Shadowing)하며 사진이나 오디오 등을 통해 데이터를 기록하거나 실험실에서 관찰할 경우 사용자가 관찰 당하고 있다는 사실을 인지하고 자신의 행동을 수정하는 호손 효과 등의 문제점이 있다.
2.1.3 Cultural Probes
1999년 Bill Gaver가 개발한 방법으로, 사용자로부터 자신의 행동이나 판단 등 행동양식에 대한 단편의 증거물(Probe)들을 모아 행동 양식에 영향을 미치는 사용 문맥 요소를 파악하기 위한 방법이다. 이를 위해 1회용 카메라나, 일기, 스마트폰 어플리케이션 등의 기록 방법 등이 많이 제시되었다[18]. 하지만 사용자가 일기나 자서전의 형태로 기록하는 방식은 주요 내용의 누락이 있을 수 있고 사용자 자신의 주관이 반영되거나 사실과 다른 허위의 사실이 기록될 수 있는 위험성이 있어 결과가 왜곡될 수 있다[10].
2.2 수집 데이터 활용 및 분석에 대한 선행 연구
2.2.1 사용자 모델
사용자 모델(Model)은 제품/서비스와 사용자 사이의 관계로 복잡한 사용 과정의 구조를 간단하게 이해할 수 있게 도움을 줄 수 있다. 설정된
Model은 주변의 상황에 따라 의사결정을 하고 행동으로 옮기는 사용자의
경향성을 대표하는 주체가 된다. Scenario(John Carroll, 1995)[19], User Profile(Hackos, 1998)[20], User Role(Beyer, 1998)과 같은 사용자에 대한 이해를 돕는 방법론들이 과거부터 많이 제시되었고 Alan Cooper는
Persona의 개념을 처음 언급하였다. 사용자에 대한 서사적 묘사와
11
경향성을 표시한 프로필을 사용하는 방식이다. 서사적 묘사에는 해당
Persona가 사용 과정에서 겪는 문제점과 감정들이 묘사되어 있고 사용
과정에서 생길 수 있는 문제에 대해 사용자 측면에서 서술되어 있다.
이러한 Persona는 제품/서비스 개발에서의 사용자에 대한 이해를 도와줄 수 있는 자신만의 개성을 가지고 있는 Model로서 쉽게 사용자에 대한 이미지를 떠올릴 수 있도록 사용자의 이미지를 담은 사진을 넣고 사용자의 구체적 요구사항 또는 기대에 대해 언급하거나 사용자의 행동 유형을 표시하는 방식이다[10]. 하지만 대표성이 약한 인사이트로부터 생성된 Persona가 대표 사용자로서 설정될 경우 전체 사용자에 대한 왜곡된 이해로 이어질 수 있기 때문에 주의가 필요하다고 볼 수 있다.
2.2.2 Word Cloud
얻어진 문자 데이터를 출연 빈도에 따라 크기에 표현 가중치를 주고 원 등의 도형의 모양으로 정렬시켜 시각적으로 표현하는 방법으로 문자 데이터에 대한 대략적인 이해를 하는데 도움을 줄 수 있다. 키워드 분석 시에 많이 적용 되고 있다[11]. 하지만 데이터의 단순 빈도로 얻어진 결과물은 직관성이 떨어져 최종 결과물을 얻기보다 인사이트를 얻는 수준에서 그칠 수 있고 적절한 수준의 전처리를 통해 데이터를 재가공하는 과정이 필수적이라고 볼 수 있다.
2.2.3 AHP 분석
AHP(Analytic Hierarchy Process)기법은 의사결정에 있어서 우선순위 도출을
하기 위한 도구로 쌍대비교(pair-wise comparison)에 의한 요소 간 우선순위 판단을 하는 방법이다[21]. 사용자들이 의사 결정에 영향을 미치는 요소들의 순위를 찾을 수 있는 장점이 있지만 요소들의 개수가 늘어날수록 분석에 소요되는 시간이 늘어나는 단점이 있다[22].
12
2.3 사용자 세분화(Segmentation)
Jesse James Garrett은 그의 저서(2010)에서 사용자 세분화는 중요한 공통점을
공유하는 사용자끼리 작은 그룹으로 나누는 것이라고 정의했으며 세그멘테이션의 많은 방법 중 두 가지 방법을 소개하였다[16].
2.3.1 인구통계학적 구분
성별, 나이, 교육수준, 결혼여부, 소득 등의 기준으로 사용자를 분류하는 방법이다. “18∼49세 남성”과 같이 일반적 기준으로 분류할 수도 있으며
“미혼의 대학교육을 이수한, 연 수입 5만 불 이상의 25∼34세 여성”과 같이
구체적 기준으로 분류할 수도 있다.
2.3.2 사용자 심리분석(Psychographic Profile)
인구통계학적으로 나눈 사용자 세그멘트 만으로 설명할 수 없는 사용자에 대한 통찰을 제공해줄 수 있는 접근 방식으로 각 사용자가 제품/서비스에 대하여 가지고 있는 태도와 인식을 설명해줄 수 있다.
2.4 다차원척도법(MDS)과 좌표 공간에서의 거리
다차원척도법은 대상이 되는 요소들을 속성에 따라 평가하여 공간상 구도로 포지셔닝 맵을 작성하는 기법으로 대상 간의 유사도를 거리를 기반으로 표현하여 요소간의 유사성을 시각적으로 쉽게 파악할 수 있게 하는 방법이다[23]. 이번 연구에서 활용되는 유클리디안 거리는 좌표 공간에서 두 지점 간의 거리를
구하는 가장 단순한 축에 속하는 방법이다. L2 Distance라고 불리며 이 방법은 여러
13
차원에서 똑같은 원리를 적용하여 거리를 계산할 수 있기 때문에 인공지능 분야에서도 유사도 측정의 한 방법으로 쓰이는 방법이며 이때는 각 구성요소 별 출연 빈도 등을 기준으로 삼아 계산한다[23]. 이외에도 L1 Distance인
맨하탄(Manhattan)이나 일반화시킨 Lm거리 (민코우스키(Minkowski)) 등의 방식으로 좌표 공간상의 거리를 구할 수 있다. 외에도 공분산을 고려하여 계산하는
마할라노비스 거리 등 이 있다.
𝐝(𝐀, 𝐁) = √∑(𝒂𝒊− 𝒃𝒊)𝟐
𝒏
𝒊=𝟏
𝐏𝐫𝐨𝐩𝐨𝐬𝐢𝐭𝐢𝐨𝐧 𝟐. 𝟑. 𝟏. 유클리디안 거리 공식
𝑳𝒎(𝐀, 𝐁) = (∑|𝒂𝒊− 𝒃𝒊|𝒎
𝒏 𝒊=𝟏
)𝒎𝟏
𝐏𝐫𝐨𝐩𝐨𝐬𝐢𝐭𝐢𝐨𝐧 𝟐. 𝟑. 𝟐. 민코우스키 거리 공식(맨하탄 거리의 경우 m=1)
2.5 행동 변수
강은혜(2014)는 연구에서 행동 변수(Behavioral Variable)라는 개념을 도입하여 각 사용자들을 행동 변수 스펙트럼상에 상대적으로 배치하여 공통적으로 나타나는 패턴을 파악하는 방안을 제시하였다. 각 사용자 별 데이터로부터 Issue를 찾아 다른 사용자에게도 해당되는 이슈(Issue)의 경우를 파악하여 이로부터 특징적인 Context를 추출할 수 있는 핵심 이슈(Key Issues)를 얻었다. 이후 핵심 이슈를 기반으로 행동 변수에 따라 사용자들을 상대적으로 배치하였고 사용자 행동 패턴을 파악하였다. 하지만 사용자 행동 패턴을 파악하는 과정에서 연구자의 주관이 강하게 개입되고 행동 변수의 양극단의 배치가 비일관적인 한계점이 있다[12].
14
Figure 2. 4. 1: 사용자 행동 패턴 매핑 예시[12]
15
제 3 장 연구방법
3.1 UDR수집
총 46명의 실험 참여자를 온라인을 통해 모집하였고, 각 실험 참여자들은
2주간에 걸쳐 UDR을 작성하였다. UDR 수집은 참여자들에 의한 직접 기록으로
각자에게 할당된 표 형식의 구글 스프레드 시트 (Google Spread Sheet)에 작성되었다.
이 형식은 실시간 온라인 공유가 가능한 기록 양식으로 실험 참여자가 스마트폰과 PC로 접근이 가능하며 기록을 실시간으로 연구자가 확인할 수 있어 실험 참여자의 꾸준한 기록을 독려하고 부족한 부분에 대한 추가 기록을 지시할 수 있는 장점이 있다.
실험 참여자들이 기록해야 하는 항목은 날짜, 시간, 과업 분류 (결제, 조회, 이체, 입금), 과업의 초기 상황, 고려되는 제약 사항, 과업 내용, 관련 서비스 제공 업체, 선택한 수단 및 업체 이름(현금, 카드, 앱 결제 등), 과업 실행의 결과, 과업에서 전반적으로 느낀 감정, 불만족을 느꼈다면 해당 내용, 원하는 해결/개선 방안이었다. 또한 예시를 통해 어떤 방식으로 기록하는지 실험 참여자들에게 설명하여 기록의 누락 또는 오류를 최소화하고자 하였다. 감정의 경우
Plutchic(1984)의 Wheel of Emotion의 분류에서 분류된 감정 분류에 따라 입력하도록
하였다.
기록이 저조한 참여자들을 제외하고 총 42 명의 참여자들로부터 수집된
UDR기록에 한하여 분석을 진행하였다. 수집된 UDR 데이터는 총 894개로
참여자들의 기록을 연구자가 확인하고 맞춤법 및 문법 교정 등 내용의 변경이 없는 수준에서 오류를 수정하였다.
16
번호성별나이날짜시간시기Q1. 분류Q2. 장소Q3. 초기 상황Q4. 제약 상황Q5. 선택한 행동Q6-1. 업체Q6-2. 수단Q7. 과업 종료 결과Q8. 전반적 감정Q9. 불만점Q10. 원하는 해결 방법
구 글 스 프 레 드 시 트 양 식
Figure 3.1.1 UDR입력양식예시17
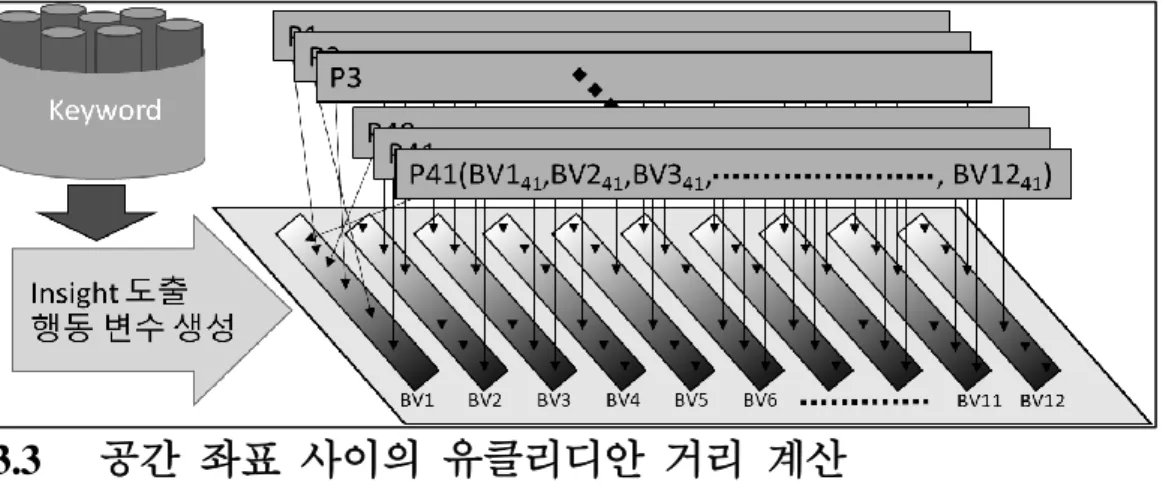
3.2 키워드 추출 및 행동 변수 정의
894개의 UDR 데이터로부터 사용자들의 사용 경험(에피소드)를 확인하고 주요
키워드를 추출하였다. 주요 키워드를 추출하는 과정에서 다른 실험 참여자의 경우에도 해당 키워드가 적용되는지 확인하고 비슷한 키워드를 묶어 범주화 하였다. 묶여진 주요 키워드로부터 인사이트를 추출하였고 해당 인사이트로부터 다시 전체 실험 참여자들의 사용 문맥(Context of Use)상 차이점를 보이는 12개의 행동 변수를 정의하였다. 여기서 행동 변수 (Behavioral Valuable; BV)란 실험 참여자들의 성향을 분류하는 기준으로 해당 변수에 대한 중립적 태도를 기준으로 긍정과 부정의 양극점(兩極占)을 가지는 지표이다. 행동 변수는 서로 독립적으로 가정하여 경향성을 판별할 때 겹치는 내용이 없다고 보았다. 각 행동 변수에 대해 실험 참여자들이 가지는 정도를 중립적 태도 (3점)를 기준으로, 긍정 (5점)과 부정
(1점)으로 나타내었다. 이후 각 실험 참여자들을 12개의 행동 변수에 대한 성향에
따라 기록하여 각자 12개의 행동 변수 지표를 가지도록 구분하였다. 이후 실험 참여자들의 각 행동 변수를 독립적 차원의 축으로 치환하여 각 실험 참여자들이
12차원 상의 좌표를 갖도록 하였다. 이는 MDS 공간에 42개의 사용자 좌표가
있다고 볼 수 있다..
Figure 3.2.1: 행동 변수 생성 및 사용자 행동 변수 수준 도출 과정
3.3 공간 좌표 사이의 유클리디안 거리 계산
18
앞서 실험 참여자들에게 부여한 12차원 공간 좌표를 기반으로 서로 간의 유클리디안 거리를 계산하였다. 이때 실험 참여자 간 유클리디안 거리는 실험 참여자 간의 경향성 차이를 보여주는 지표로 보았다. 실험 참여자와 공간 상 거리가 가장 가까운 타 실험 참여자는 표에서 음영 처리된 칸으로 표시하였으며 실험 참여자 간의 배치 공간상 거리가 동일한 경우도 있었다.
3.4 실험 참여자 별 유사도 계산
유클리디안 유사도는 유클리디안 거리에 기반을 둔 유사도로 이번 연구에서는 실험 참여자간의 유클리디안 거리의 역수를 구해 실험 참여자 간의 유사도로 삼았다. 42명의 실험 참여자 중 12개의 행동 변수의 전체 값이 완전히 일치하는 참여자는 없었다. 따라서 배치 공간에서의 서로간 유클리디안 거리가
“0”인 실험 참여자들 사이의 관계는 없었기 때문에 역수를 취할 때 오류가 발생하지 않았다. 앞서 구한 유사도 매트릭스는 계산의 편의를 위해 한쪽 방향으로만 계산되어 작성 되었기 때문에 이를 UCINET에 적용하기 위해 대칭적으로 기록하였다.
3.5 유사도 매트릭스 기반 시각화
3.4에서 구한 매트릭스를 UCINET 프로그램을 통해 시각화 하였다.
사용자간 유사도가 “0”보다 큰 양의 값을 가지고 있기 때문에 시각화 된 그림
Figure 3.5.1에서는 실험 참여자가 모두 연결된 상태이며, 따라서 이때의 실험
참여자의 공간 상 배치와 거리는 실제의 유사성을 반영하지 못한다. 이를 해결하기 위해 기준 유사도를 설정하여 새롭게 생성되는 세그멘트를 확인하였다.
3.6 기준 유사도에 따른 사용자 세그멘트 생성 비교
19
기준 유사도보다 낮은 유사도를 “0”으로 처리하면 기준 유사도보다 낮은 실험 참여자 사이의 연결이 제거되고 높은 유사성 관계를 가진 사용자만 남아 세그멘테이션 된다. 기준 유사도보다 높은 유사도가 없는 실험 참여자의 경우 다른 사용자와의 연결로부터 분리되어 독립적으로 정렬되었다.
각 사용자가 다른 사용자와 갖는 41개 유사도의 전체 합의 크기를 각 노드(Node)의 크기에 반영하였으며 이를 통해 사용자 사이의 유사도를 개인별 관계와 전체 사용자와의 유사성 측면에서 동시에 확인할 수 있을 것으로 기대하였다. 기준 유사도에 따라서 새롭게 UCNINET 시각화를 수행하였다.
3.7 기준 유사도 필터링 및 CONCOR 분석 결과 비교
기준 유사도 설정 방법을 다양화하는 차원에서 유사도 분포에 자연 로그(log) 형태의 가중치를 취하여 마찬가지로 UCINET 시각화를 수행하여 그 결과를 앞에서 시행한 방식의 결과와 비교하였다. 이때 유사도 1에 가까운 값이 커지도록 하였다.
또한 해당 세그멘테이션 결과의 유효성을 확인하고 결과의 정확한 해석을 위해 UCINET을 활용한 CONCOR (구조적 등위성; CONvergence of iteration
CORrealtion)분석을 동시에 시행하여 결과를 시각화 하였다. CONCOR분석은 이번
연구에서 작성한 실험 참여자들의 행동 변수의 데이터 매트릭스를 동일하게 사용하여 세그멘테이션 결과를 교차 검증하고자 활용되었다.
제 4 장 실험 결과 및 논의
4.1 UDR 분석 결과
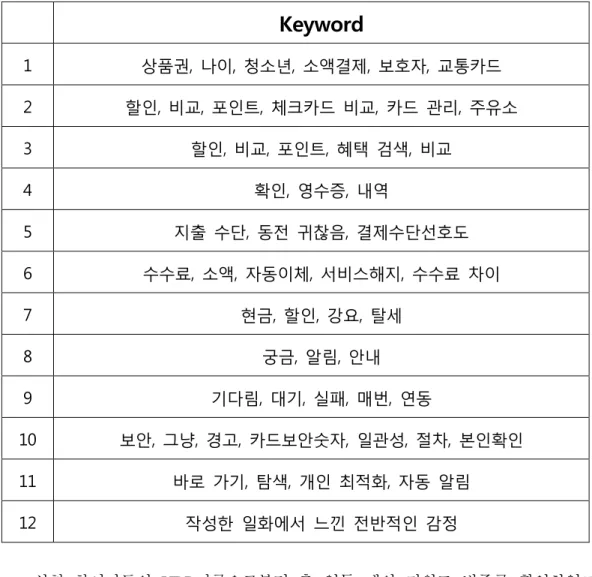
Table 4.1.1: Keyword
20
Keyword
1 상품권, 나이, 청소년, 소액결제, 보호자, 교통카드 2 할인, 비교, 포인트, 체크카드 비교, 카드 관리, 주유소 3 할인, 비교, 포인트, 혜택 검색, 비교
4 확인, 영수증, 내역
5 지출 수단, 동전 귀찮음, 결제수단선호도 6 수수료, 소액, 자동이체, 서비스해지, 수수료 차이 7 현금, 할인, 강요, 탈세
8 궁금, 알림, 안내
9 기다림, 대기, 실패, 매번, 연동
10 보안, 그냥, 경고, 카드보안숫자, 일관성, 절차, 본인확인 11 바로 가기, 탐색, 개인 최적화, 자동 알림
12 작성한 일화에서 느낀 전반적인 감정
실험 참여자들의 UDR기록으로부터 총 열두 개의 키워드 범주를 확인하였고 이로부터 얻을 수 있는 사용자들의 e-Commerce에서의 지출 과정에서의 인사이트(Insight)를 다음과 같이 정리하였다.
Table 4.1.2: Insight
Insight
1 10대는 신용카드 발급 불가, 인증 불가 등 Issue
21
2 할인 혜택을 찾아보려는 노력의 개인별 차이 존재
3 할인 혜택을 찾는 과정에서 짜증과 귀찮음을 느끼는 개인별 차이 존재 4 거래 내역을 보고 정확히 확인하고자하는 노력 차이 존재 5 현금, ARS, 웹, 앱 등의 사용 결제 수단 종류 차이 6 수수료를 비교하거나, 수수료에 대한 반감 수준 차이 7 현금을 사용하는 것에 의미를 두거나, 반감을 가지는 정도 차이 8 모르는 정보에 대한 갈증과 해소 욕구의 정도 차이
9 오래 기다려야 하거나 (학습)노력이 허위로 돌아가는 경우의 반감 차이 10 강제적인 절차를 이해하거나 이를 필요 없다고 생각하는 정도 차이 11 자신이 자주 사용하는 기능에 대해 접근성 향상 희망 정도 차이 12 지출 과정에서 느끼는 감정의 편향도 차이
4.2 행동 변수 정의 결과
Table 4.2.1: 행동 변수
BV1 결제 수단 선택의 자유도
BV2 지출 시 활용하는 결제 수단의 다양성 BV3 할인과 조회를 위한 노력에 대한 피로도
22
BV4 지출의 정확한 금액과 결과를 확인하려는 수준 BV5 할인 및 적립을 챙기는 정도
BV6 수수료/금전적 손해에 대한 거부감/반감 수준 BV7 현금 사용에 대한 거부감 수준
BV8 정보 부족에 대한 해소 욕구 정도
BV9 강제적인 기다림이나 (반복적) 시간 낭비에 대한 반감 정도
BV10 보안 절차에 대한 너그러움(수용도) 또는 요구 수준
BV11 개인맞춤형 서비스에 대한 욕구 정도
BV12 감정적 피드백의 긍정 부정 편향 정도
앞의 Insight로부터 행동 변수를 표(4.2.1)과 같이 정의하고 행동 변수의 양
극단을 다음 표(4.2.2)와 같이 설정하였다.
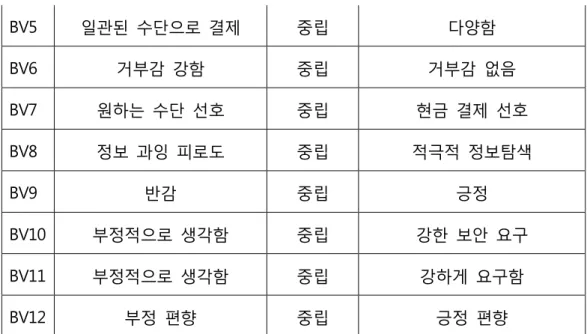
Table 4.2.2: 행동 변수 양극단 설정
BV Negative Neutral Positive
BV1 부자유 중립 자유
BV2 무관심 중립 관심
BV3 피로 느낌 중립 즐거움 느낌
BV4 무관심 중립 반드시 확인
23
BV5 일관된 수단으로 결제 중립 다양함
BV6 거부감 강함 중립 거부감 없음
BV7 원하는 수단 선호 중립 현금 결제 선호
BV8 정보 과잉 피로도 중립 적극적 정보탐색
BV9 반감 중립 긍정
BV10 부정적으로 생각함 중립 강한 보안 요구
BV11 부정적으로 생각함 중립 강하게 요구함
BV12 부정 편향 중립 긍정 편향
이때 양극단 설정의 기준을 긍정과 부정으로 정하여 최대한 일관된 양극단 설정을 하고자 하였다.
4.3 행동 변수 별 수준 부여 결과
Table 4.3.1: 행동 변수 부여 결과
24
BV1 BV2 BV3 BV4 BV5 BV6 BV7 BV8 BV9 BV10 BV11 BV12
P1 1 3 3 3 3 3 3 3 3 3 3 2
P2 4 4 4 4 4 2 2 4 2 2 4 1
P3 4 2 2 5 4 3 3 4 1 4 4 1
P4 4 4 2 4 5 3 4 4 2 3 4 1
P5 5 5 1 4 5 1 3 5 2 4 4 1
P6 4 4 4 4 4 2 1 4 2 2 3 1
P7 4 4 2 4 4 2 2 4 1 3 5 1
P8 4 4 1 4 4 2 3 4 2 4 4 1
P9 4 4 4 2 4 2 3 2 4 3 2 4
P10 4 3 3 3 4 2 2 4 2 4 4 2
P11 4 4 2 4 4 3 2 4 2 4 4 1
P12 4 4 1 4 2 2 2 4 2 4 4 1
P13 4 4 4 4 4 3 3 4 2 2 4 2
P14 4 4 2 3 4 2 3 4 2 2 4 1
P15 4 4 3 4 4 2 3 2 4 2 3 2
P16 4 4 2 4 4 2 2 4 2 4 4 2
P17 1 4 4 2 2 2 2 4 2 2 4 2
P18 4 4 2 4 4 2 3 4 2 3 3 5
P19 4 4 2 4 4 3 2 4 2 2 4 2
P20 4 3 2 4 2 3 3 4 2 3 4 4
P21 4 4 2 4 4 3 3 4 2 2 4 4
P22 4 3 2 4 4 2 3 4 2 2 5 3
P23 4 4 3 4 4 3 3 4 3 3 3 4
P24 2 4 3 4 2 3 2 4 2 3 4 1
P25 2 4 2 4 4 2 2 4 2 3 4 4
P26 4 4 4 4 4 4 2 4 2 2 4 1
P27 4 4 2 5 4 2 2 4 2 3 4 1
P28 4 3 2 4 4 3 3 4 2 5 4 1
P29 4 5 2 4 5 2 2 4 2 2 4 1
P30 4 4 1 5 4 4 3 4 1 2 4 1
P31 4 5 4 4 4 3 2 4 4 4 4 2
P32 4 4 2 4 4 2 2 4 1 2 5 1
P33 4 4 4 4 4 2 2 4 2 4 4 2
25
사용자들의 행동 변수 부여는 표 4.3.1과 같다. 각 행동 변수 별 분산과
표준편차는 다음과 같다
4.4 유클리디안 거리 계산 결과
P34 4 2 2 2 4 2 4 4 2 4 4 1
P35 4 4 4 4 4 3 2 4 2 2 4 4
P36 4 3 2 4 4 2 3 4 2 2 4 1
P37 4 4 2 4 4 2 3 4 2 1 4 2
P38 4 5 2 4 4 2 3 4 2 4 4 4
P39 4 5 2 4 5 2 3 4 2 3 4 4
P40 4 4 2 4 4 2 3 4 2 3 4 4
P41 4 4 4 4 4 2 3 4 2 2 4 4
P42 4 5 4 4 4 2 4 4 2 2 4 1
BV 1 BV 2 BV 3 BV 4 BV 5 BV 6 BV 7 BV 8 BV 9 BV 10 BV 11 BV 12 분산 0.61 0.48 0.99 0.42 0.50 0.39 0.44 0.23 0.43 0.86 0.28 1.70 표준편차 0.78 0.69 0.99 0.65 0.71 0.62 0.66 0.48 0.66 0.93 0.53 1.30
26
Table 4.4.1: 유클리디안 거리 계산 결과
P1P2P3P4P5P6P7P8P9P10P11P12P13P14P15P16P17P18P19P20P21P22P23P24P25P26P27P28P29P30P31P32P33P34P35P36P37P38P39P40P41P42 P1 P24.47 P34.904.00 P44.583.323.00 P56.404.364.363.16 P64.691.414.474.124.80 P75.002.653.002.833.163.32 P84.693.742.832.242.244.242.24 P94.585.206.715.666.635.206.325.92 P104.002.833.163.323.873.162.652.834.58 P114.363.002.652.453.163.322.001.735.662.24 P124.804.123.614.003.744.362.832.246.323.322.45 P134.121.733.872.834.692.653.163.874.693.003.164.47 P144.242.453.742.243.323.162.242.455.202.832.653.322.65 P154.003.465.103.875.203.744.584.243.324.004.124.803.323.46 P164.363.003.002.832.833.322.001.735.101.731.412.453.162.653.87 P173.164.246.165.746.864.475.005.665.574.475.205.204.364.475.295.00 P185.004.805.004.474.905.004.694.364.243.874.474.904.004.364.363.465.74 P194.242.453.462.653.872.832.242.835.202.832.243.322.242.003.462.244.693.61 P204.364.584.124.475.485.004.244.125.103.614.003.743.744.124.583.465.002.833.32 P214.583.874.363.464.694.363.743.874.693.613.744.472.833.323.873.165.202.002.242.45 P2<
![Figure 2. 4. 1: 사용자 행동 패턴 매핑 예시[12]](https://thumb-ap.123doks.com/thumbv2/123dokinfo/11645257.0/24.808.108.706.122.409/figure-2-사용자-행동-패턴-매핑-예시-12.webp)