Jackknife Estimation in an Exponential Model
8
0
0
전체 글
(2)
(3)
(5)
(7)
(8)
수치
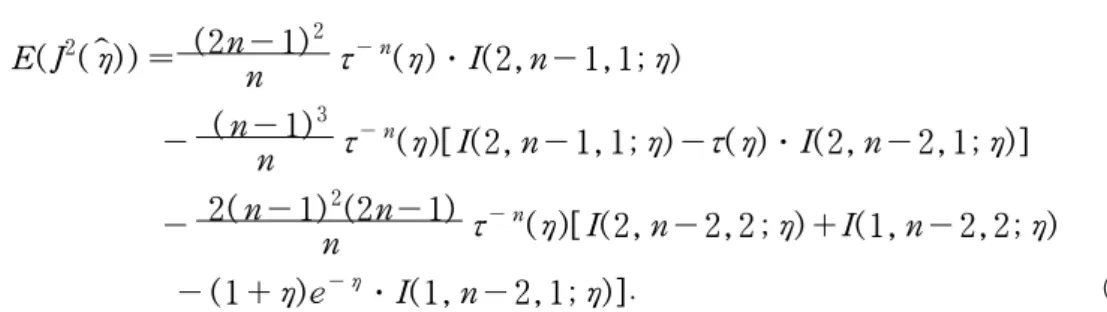
관련 문서
The Dutch physicist Pieter Zeeman showed the spectral lines emitted by atoms in a magnetic field split into multiple energy levels... With no magnetic field to align them,
Nonlinear Optics Lab...
Modern Physics for Scientists and Engineers International Edition,
The kick-o ff method is based on an OLS estimator that is not robust to outliers in the data. To overcome this problem, we have modified the kick-o ff approach based on the
웹 표준을 지원하는 플랫폼에서 큰 수정없이 실행 가능함 패키징을 통해 다양한 기기를 위한 앱을 작성할 수 있음 네이티브 앱과
_____ culture appears to be attractive (도시의) to the
이하선의 실질 속에서 하악경의 후내측에서 나와 하악지의 내측면을 따라 앞으로 간다. (귀밑샘 부위에서 갈라져 나와
If the volume of the system is increased at constant temperature, there should be no change in internal energy: since temperature remains constant, the kinetic
