(Received May 2, 2019; Revised June 11, 2019; Accepted June 12, 2019)
Abstract
Classification criteria for Korean alphabet (Hangul) fonts are undeveloped in comparison to numerical clas- sification systems for Roman alphabet fonts. This study finds important features that distinguish typeface styles in order to help develop numerical criteria for Hangul font classification. We find features that deter- mine the characteristics of the two different styles using a convolutional neural network to create a model that analyzes the learned filters as well as distinguishes between serif and sans-serif styles.
Keywords: convolutional neural networks, local feature, fontstyle, hangul, visualization
1. 서론
1.1. 연구배경
로마자 서체에 대한 수치적 분류 체계 연구는 활발히 진행되어 왔으며 그에 대한 자동화 도구도 많이 발 달되어 있다. 그 예로 산업기반 폰트 분류 및 매칭 시스템인 PANOSE (Bauermeister, 1988)는 로마자 서체의 시각적인 특성을 기반으로 한 분류체계 시스템으로 서체마다의 특징을 대표할 수 있는 10가지의 특성을 정의한다. 이 특성은 로마자 26개의 모양에 따라 정의되는데, 로마자 서체의 대표 특성값 세트 로 글꼴 분류체계를 정의한다. 서체 연결(matching)법은 두 서체의 PANOSE 숫자세트 속 개별의 정의 된 값들을 비교하는 것으로 각 정의된 값들의 차이를 구하고 계산식을 적용하여 연결값을 생성한다. 이 연결값은 두 서체 간의 거리가 되며, 연결값이 작을수록 두 서체가 시각적으로 비슷함을 뜻한다. 이러한 서체들 간의 비교 방법을 통해 로마자의 수치적 분류 체계 시스템은 서체가 없는 경우나 서로 다른 플랫 폼에서 서체가 호환되지 않는 상황에서의 서체 대체 문제를 줄여 준다. 로마자에 대한 수치적 분류체계 연구가 활성화됨으로 서체 관리가 편리해지고, 서체간 호환이 발전하였다. 마찬가지로 한글 또한 수치 적 분류 체계에 관한 연구가 필요하다.
PANOSE 와 같은 방법으로 한글을 수치화하려면 한글 문자에 알맞은 구성 요소들의 특성을 정의를 해 야한다. 이에 대한 연구로 수치분석 기반 한글글꼴 분류체계 연구 (Lim과 Kim, 2016)에서 한글 글꼴을 대표하는 문자 ‘맘마몸’, ‘이아으’ 등을 선택하여 한글 글꼴의 수치기반 분류체계를 제안하였다. 이는 서 체의 이름 및 개발사가 정한 기준에만 의존하여 분류해 온 한글 서체를 조금 더 객관적인 수치로 정의하 여 글꼴을 분류할 수 있도록 글꼴 관리의 새로운 기준을 제시하였다.
This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government (MSIT) (No.2019R1A2C1007126).
1
Corresponding author: Department of Statistics, Seoul National University, 1 Gwanak-ro, Gwanak-gu,
Seoul 08826, Korea. E-mail: [email protected]
본 연구에서는 서체의 문자를 이미지로 인식해 컨볼루션 뉴럴 네트워크(convolutional neural network;
CNN) 방법을 이용하고자 한다. 한글을 몇 가지의 대표적 문자로 특성을 정의하는 것이 아닌 심층학 습(deep learning) (LeCun 등, 2015) 기법으로 다양한 문자 이미지를 학습하여 서체 스타일의 특징을 구분짓는 특징을 찾고자 한다.
2. 방법론
2.1. 개요
컨볼루션 뉴럴 네트워크를 이용해 한글 서체 이미지에 대한 학습 후 한글 서체 스타일을 분류하는 데에 중요한 영향을 미치는 특정한 특징을 찾고자 한다. 서체 스타일 분류를 잘하는 것이 아닌 서체 스타일 구분에 영향을 주는 부분적인 특징을 찾는 것이 목표이므로 신경망 시각화 방법들 (Simonyan 등, 2013;
Springenberg 등, 2014; Zeiler와 Fergus, 2014)을 통해 각 층에서 활성화되는 특징들을 확인한다. 한글 서체의 종류는 바탕체와 돋움체로 나뉜다. 바탕체(세리프체)는 붓글씨와 비슷하게 돌기(세리프)가 있는 반면, 돋움체(산세리프체)는 판에 새긴듯한 모양으로 묵직하고 반듯한 느낌이 드는 것이 특징이다. 일 반적으로 바탕체, 돋움체보다는 명조체와 고딕체라는 명칭이 익숙하기 때문에 본 연구에서는 서체 스타 일의 종류를 명조스타일과 고딕스타일로 정의하겠다.
2.2. 컨볼루션 뉴럴 네트워크(convolution neural network)
컨볼루션 뉴럴 네트워크란, 심층학습의 한 기법으로 인간이 시각적 정보를 처리하는데에 중요한 역할을 하는 기관과 비슷한 역할을 하는 시각 피질 내의 뉴런들간의 연결을 모형화한 인공신경망을 말한다. 개 별적인 뉴런들은 수용영역이라고 하는 공간에서 발생한 자극들에 대해 반응하고 각각 다른 뉴런들의 수 용 영역들이 부분적으로 겹쳐지면서 커지게 된다. 개별적 뉴런들의 수용 영역 안에서 자극에 대한 반응 은 컨볼루션 연산(convolution operation)에 의해 수학적으로 근사 될 수 있다. 컨볼루션 뉴럴 네트워 크는 최소한의 전처리 과정을 사용하도록 고안된 다층 퍼셉트론(multilayer perceptron) 모형으로, 영상 인식 또는 분류에 특화되어 있다.
컨볼루션 뉴럴 네트워크는 컨볼루션층(convolution layer), 풀링층(pooling layer), 완전 연결층(fully connected layer)의 세 개의 핵심 구조로 이루어져 있다. 이 구조들이 모형의 모수 개수를 효율적으로 줄여주어 전체 모형의 복잡도를 줄여주는 효과를 얻게 해준다.
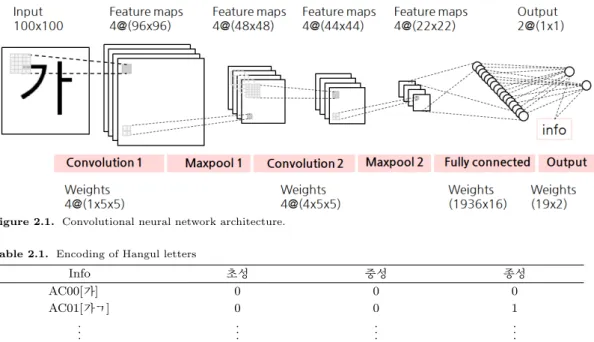
본 연구에서 사용한 컨볼루션 뉴럴 네트워크의 구조는 Figure 2.1과 같으며, 입력(input) - 컨볼루
션1(convolution1) - 최댓값 풀링1(maxpooling1) - 컨볼루션2(convolution2) - 최댓값 풀링2(maxpool-
ing2) - 완전 연결(fully connected) - 문자 정보 연결((info) concatenate) - 결과(output)으로 구성되어
있다. 처음 입력 이미지의 사이즈는 (100×100)이고 첫 번째 컨볼루션층에서 필터의 크기는 (1×5×5),
두 번째 컨볼루션층의 필터의 크기는 (4 × 5 × 5), 필터의 수는 4개로 동일하게 적용하고자 한다. 각 풀
링층의 스트라이드는 (2 × 2)로 적용하고, 완전 연결층에서 유닛의 개수는 16개로 설정하였다. 문자에
대한 정보를 추가하는 층의 전, 후로 50% 드롭아웃(drop out) (Krizhevsky 등, 2012)을 적용하였다.
Figure 2.1. Convolutional neural network architecture.
Table 2.1. Encoding of Hangul letters
Info 초성 중성 종성
AC00[ 가] 0 0 0
AC01[ 가ㄱ] 0 0 1
. .
. . . . . . . . . .
D7A3[ 히ㅍ] 18 20 26
D7A3[히ㅎ] 18 20 27
2.3. 분석 방법
2.3.1. 문자 정보 문자 분류가 아닌 서체 스타일의 학습이 목적이기 때문에 문자 자체의 학습보다 좀 더 부분적인 특징을 학습하도록 문자에 대한 정보를 생성했다. 문자에 대한 정보는 한글 낱자의 유니 코드 순서(Table A.1)대로 초성, 중성, 종성 행렬(Table 2.1)을 만들어 모형의 완전 연결층 다음에 추가 한다.
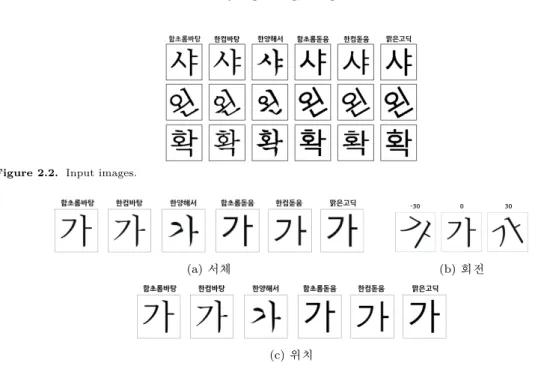
2.3.2. 시각화 네트워크의 각 층에서 출력된 특정한 특징들의 활성화 값들을 입력 이미지와 맵 핑(mapping)하는 디컨볼루션 시각화(deconvolution visualization)방법 (Zeiler와 Fergus, 2014)과 가 장 중요한 부분의 위치를 표현해주는 샐리언시 맵(saliency maps) (Simonyan 등, 2013; Springenberg 등, 2014)을 이용해 컨볼루션 뉴럴 네트워크의 각 층에서 활성화 된 값들을 시각하여 학습하는 과정을 파악하고자 한다. 본 연구에서는 문자들이 서체 스타일 별로 나타내는 부분적인 특징을 비교하기 위해 세 가지 문자를 선택했다. 그 문자들은 돌기(serif)부분이 잘보이는 ‘샤’, 둥근 부분을 위해 ‘왼’과 일직 선의 획이 많은 ‘확’으로 서로 특징이 다른 대표 문자를 선정하였다. 문자 ‘왼’은 회전된 문자를 사용하 여 문자의 변형에도 서체 스타일의 분류에 영향을 주는 부분적 특징들이 잘 보이는지 확인하고자 선택하 였다. 대표 문자들은 Figure 2.2에서 확인할 수 있다.
3. 결과 3.1. 데이터
3.1.1. 학습 데이터 한글 문자 11,172개 중 자주 쓰이는 문자 963개를 선택했다. 문자 선택의 기
준은 국립국어 연구원이 발표한 자주 쓰이는 한국어 5,888개의 기초 낱말 (National Institute of The
Figure 2.2. Input images.
(a) 서체 (b) 회전
(c) 위치 Figure 3.1. Training dataset composition.
Table 3.1. Hangul font file names (.ttf) and their names (in Korean)
.ttf HANBatang HBATANG UNI HSR HANDotum HDOTUM malgun
서체이름 함초롬바탕 한컴바탕 한양해서 함초롬돋움 한컴돋움 맑은고딕
Korean Language, 2004) 중 고유한 문자들이다. 고유 문자는 ‘가’, ‘각’, ‘간’, . . . , ‘흰’, ‘히’, ‘힘’이다.
서체는 명조 스타일 서체인 함초롬바탕, 한컴바탕, 한양해서와 고딕 스타일 서체인 함초롬돋움, 한컴돋 움, 맑은고딕으로 총 6가지를 선택했고 문자크기는 동일하게 설정했다. 문자에 대한 위치를 학습하지 않도록 문자의 각도를 −30
◦, 0
◦, 30
◦로 회전하고 중앙, 왼쪽위, 오른쪽 아래, 아랫부분, 윗부분, 왼쪽부 분, 오른쪽부분으로 위치의 변화와 온전한 문자뿐만이 아닌 잘린 문자의 변형을 통해 총 121,338개의 데이터를 생성했다. 데이터 생성 코드는 깃허브(https://github.com/inkyeongh/A-Study-in-Hangul- font-using-CNN) 에 공유하였다. 문자의 변형은 Figure 3.1에서 확인할 수 있다.
3.2. 학습 결과
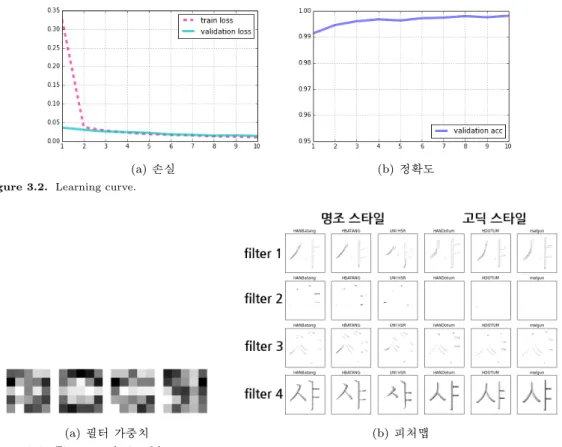
총 121,338개의 데이터를 훈련자료(train set) 101,338개, 시험자료(test set) 20,000개로 나누었고, 배 치 크기(batch size)는 100, 에폭(epoch)은 10으로 네트워크 모형을 설정했다. 학습 과정 동안 정확 도(Figure 3.2(b))는 98%–99%로 높게 나왔다. 본 연구의 모형은 Intel(R) Xeon(R) CPU E5-2680 v2
@ 2.80GHz 프로세서와 2048개 CUDA 코어와 1GHz 및 4GB 메모리의 NVIDIA GeForce 980 GPU를 사용했고, 전체 훈련에 134초가 소요되었으며 평균 학습 시간은 에폭(epoch)마다 13.40초가 소요되었 다. 실험 구현 프로그램은 Python을 사용하였고, 라이브러리 Lasagne (Dieleman 등, 2015)와 Keras를 기반으로 실험을 구현했으며 예제 코드는 데이터 생성 코드와 함께 공유하였다.
앞으로 나오는 그림의 이해를 돕기 위해 Table 3.1을 확인하여 각 그림이 나타내는 한글 서체의 이름을
확인하길 바란다.
(a) 손실 (b) 정확도 Figure 3.2. Learning curve.
(a) 필터 가중치 (b) 피처맵
Figure 3.3. First convolutional layer.
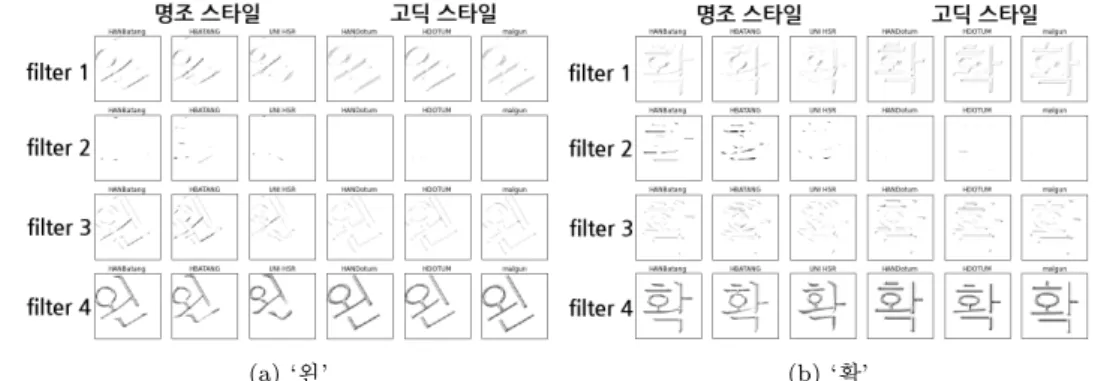
3.2.1. 첫 번째 컨볼루션층(convolution layer 1) 첫 번째 컨볼루션층에서 필터의 가중치는 Fig- ure 3.3(a)로 흰 부분이 양수, 검정 부분이 음수의 값을 갖는다. Figure 3.3(b)는 첫 번째 컨볼루션층에 서 확인할 수 있는 문자 ‘샤’의 피처맵으로 진한 부분일수록 강한 활성화 값을 갖는다. 전체적으로 문자 의 외곽선이나 외곽선을 제외한 문자의 채워진 부분을 학습하는 것으로 보인다. 문자 ‘왼’과 ‘확’의 피처 맵은 부록 Figure B.1에서 확인할 수 있다.
3.2.2. 두 번째 컨볼루션층(convolution layer 2) 두 번째 컨볼루션층에서 필터의 가중치는 Fig- ure 3.4(a)와 같다. 첫 번째 컨볼루션층에서 나온 하나의 피처맵마다 4개의 필터가 다시 한 번씩 생기 는 것으로 총 16개의 가중치가 생성된다. Figure 3.4(b)는 문자 ‘샤’의 피처맵으로 첫 번째 컨볼루션층 과 비교하여 좀 더 강한 활성화 값을 가지며 문자의 전체적인 부분이 아닌 특정한 부분들이 학습되었다 고 판단할 수 있다. 예를 들면 고딕스타일과 비교하여 명조스타일에서 활성화 값이 두드러지게 나타나 는 부분들이 있다. 대체적으로 문자의 꺾이는 부분, 획이 가늘어지는 부분과 일직선으로 이루어진 부분 은 서체 스타일에 관계없이 활성화 값이 강하게 나타나는 것을 볼 수 있다. 문자 ‘왼’과 ‘확’의 피처맵은 부록 Figure B.2에서 확인할 수 있다.
3.2.3. 완전 연결층(fully connected layer) 완전 연결층에서는 각 유닛들의 활성화 값을 막대 도
표(bar plot)로 나타냈다. Figure 3.5에서 x축은 1부터 16까지 유닛의 순서이고 y축은 각 유닛의 활성
(a) 필터 가중치 (b) 피처맵 Figure 3.4. Second convolutional layer.
Figure 3.5. Fully connected layer: bar charts.
화 값으로, 두 서체 스타일을 나타내는 유닛들이 구분되는 것을 확인할 수 있다. 명조 스타일에 활성화 를 보이는 유닛은 3, 4, 6, 10, 11, 12, 13, 15, 16이고 나머지 유닛들은 고딕 스타일의 문자에서 활성화를 보인다. 세 번째 열인 한양해서체는 명조 스타일 서체들 중에서 활성화 값이 약한 편이다. 또한 명조 스 타일 서체들에 비해 고딕 스타일 서체들은 상대적으로 활성화 값이 낮은 것을 알 수 있다.
유닛별 산점도(scatter plot)를 통해 두 서체 스타일이 유닛의 활성화 값에 의해 명확하게 구분되는지 확 인하고자 한다. 산점도는 Figure 3.6처럼 네가지의 유형을 보인다.
(a) x 축과 y축이 고딕 스타일인 유형으로 명조 서체들은 (0, 0) 근처로 모여있고 고딕 서체들은 양의 상 관관계를 보이며 고르게 흩어져 있다.
(b) x축은 고딕 스타일, y축은 명조 스타일인 유형으로 각 축을 따라 서체들이 분포되어 있다.
(c) x 축과 y축이 명조 스타일인 유형으로 고딕 서체들은 (0, 0) 근처로 모여있고 명조 서체들은 서체별
순서로 양의 상관관계를 보인다.
(a) 유닛 1 vs 유닛 2 (b) 유닛 1 vs 유닛 3 (c) 유닛 3 vs 유닛 4 (d) 유닛 3 vs 유닛 5 Figure 3.6. Fully connected layer: scatter plots.
(a) 유닛 순서
(b) 서체 스타일별 순서 Figure 3.7. Fully connected layer: filter weights.
(d) x축은 명조 스타일, y축은 고딕 스타일인 유형으로 각 축에 따라 서체들이 분포되어 있다.
Figure 3.6에서 두 스타일을 나타내는 유닛별로 구분이 잘 되는 것을 볼 수 있다. 대체로 유닛 1은 고딕 스타일, 유닛 3은 명조 스타일에 대한 활성화 값을 나타내는 유닛으로 판단된다. 고딕 스타일의 서체들 은 고르게 흩어져 있지만, 명조 스타일의 서체들은 한양해서체(UNI HSR), 함초롬바탕(HANBatang), 한컴바탕(HBATANG)의 순으로 활성화 값을 갖는다. 이것은 고딕 스타일의 서체들은 비슷하지만, 명 조 스타일의 서체들은 각 서체별 특징이 뚜렷하다는 것을 뜻한다. 다른 서체들에 비해 특히 한양해서체 가 약한 활성화 값을 갖는데, 이는 한양해서체의 두꺼운 부분이 컨볼루션층의 필터에서 제대로 학습되지 못했기 때문이다. 모든 유닛별로 산점도를 그려본 결과는 부록 Figures B.3–B.5에서 확인할 수 있다.
다음으로 완전 연결층의 유닛에 영향을 준 필터를 확인하고자 한다. 유닛별로 필터가 가지는 가중치는
Figure 3.7(a) 와 같다. 좌측 상단의 초록색 숫자는 행을 나타내며 필터 번호 1, 2, 3, 4를 뜻하고, 파란색
숫자는 열을 나타내며 유닛의 번호인 1, . . . , 16을 뜻한다. Figure 3.5에서 확인한 명조와 고딕 스타일의
유닛순서로 정렬하면 Figure 3.7(b)처럼 서체 스타일별로 비슷한 유형의 가중치를 갖는다는 것을 확인
Figure 3.8. Fully connected layer: letter ‘ 샤’ in the HANBatang (함초롱바탕) font.
Figure 3.9. Fully connected layer: letter ‘ 샤’ in the HANDotum (함초롱돋움) font.
할 수 있다.
각 유닛에 영향을 주는 필터가 무엇인지 파악하기 위해 두 번째 최댓값 풀링층의 피처맵과 유닛별 가중 치로 새로운 피처맵을 생성했다. Figures 3.8–3.13에서 좌측 상단의 초록색 숫자는 행을 나타내며 필터 번호인 1, 2, 3, 4를 뜻하고, 파란색 숫자는 열을 나타내며 유닛의 번호를 뜻한다. 열은 각 스타일을 나타 내는 순으로 정렬이 되어있기에 열 1, . . . , 7은 고딕 스타일을 나타내는 유닛, 열 8, . . . , 16은 명조 스타일 을 나타내는 유닛이다.
문자 ‘샤’의 피처맵 중 명조 스타일의 서체인 함초롬바탕체(Figure 3.8)에서는 명조 스타일을 나타내는 오른쪽의 유닛들(열 8, . . . , 16) 중 두 번째와 세 번째 필터(행 2, 3)에서 활성화 값이 강하게 나타나는 진한 부분이 보인다. 이 부분은 문자 ‘샤’의 돌기 부분과 얇아지는 부분임을 알 수 있다. 함초롬돋움 체(Figure 3.9)에서는 고딕 스타일을 나타내는 왼쪽 유닛들(열 1, . . . , 7) 중 첫 번째와 네 번째 필터(행 1, 4)에서 일직선의 부분이 진하게 표현된다.
문자 ‘왼’의 피처맵 중 명조 스타일인 한컴바탕체(Figure 3.10)는 세 번째 필터에서 ‘ㅇ’과 ‘ㄴ’에서 강한 활성화 값이 보이고, 한컴돋움체(Figure 3.11)에서는 뚜렷하지 않지만 전체적인 문자의 형태가 잡힌다.
문자 ‘확’의 피처맵 중 한양해서체(Figure 3.12)는 획이 시작하는 부분에서 강한 활성화를 보인다고 할 수 있고, 맑은고딕체(Figure 3.13)에서 처음과 네 번째 필터에서 일자획이 활성화 값을 갖는다. 나머지 문자별 서체의 피처맵들은 부록 B의 유닛별 피처맵 Figure B.6–B.17에서 확인하기 바란다.
새로운 피처맵을 통해 명조 스타일의 서체에서는 유닛 3, 4, 6, 10, 11, 13, 15, 16의 두 번째, 세 번째 필
터에서 문자의 부분들이 강한 활성화 값을 보인다. 고딕 스타일의 서체에서는 유닛에 관계없이 활성화
값이 약하게 나타나며, 특히 일자획에서 처음과 네 번째 필터에서 상대적으로 강한 값을 보인다. 전체적
으로 일자획이 많고 복잡한 문자일수록 활성화되는 부분이 많고, 명조 스타일 서체에서는 문자의 부분적
특징들이 강한 활성화 값을 갖는다.
Figure 3.10. Fully connected layer: letter ‘ 왼’ in the HBATANG (한컴바탕) font.
Figure 3.11. Fully connected layer: letter ‘ 왼’ in the HDOTUM (한컴돋움) font.
Figure 3.12. Fully connected layer: letter ‘ 확’ in the UNI HSR (한양해서) font.
Figure 3.13. Fully connected layer: letter ‘ 확’ in the malgun (맑은고딕) font.
3.2.4. 출력층(output layer) 마지막 출력층에서는 샐리언시 맵을 통해 서체 스타일 분류에 가장
영향을 미치는 특정한 부분의 위치를 확인하고자 한다. Figure 3.14에서 행 4, 5, 6에서 고딕스타일 서체
(a) ‘ 샤’
(b) ‘ 왼’
Figure 3.14. Output layer: saliency map.
들은 전체적인 부분이 중요하게 표현된다. 이것은 특정한 부분이 아니기 때문에 전체적인 부분이 잡히 는 것으로 판단할 수 있다. 하지만 행 1, 2, 3에서 명조 스타일 서체는 문자 분류에 중요한 특정 부분만이 강하게 표현되는 것을 볼 수 있다. 즉, 분류에 영향을 미치는 중요한 부분들은 각 문자 별로 다르게 나타 나지만 공통적으로 ‘얇아지는 부분’ 혹은 ‘꺾이는 부분’과 ‘돌기 부분’임을 알 수 있다. 문자 ‘확’의 샐리 언시 맵은 부록 Figure B.18에서 확인하기 바란다.
3.3. 특징 기반 분류 성능 실험
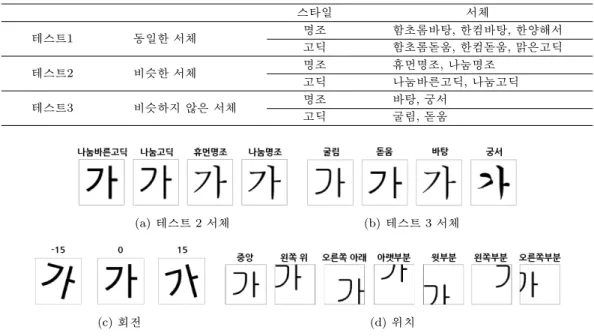
서체 스타일 분류에 영향을 미치는 특정한 부분을 학습한 모형은 학습하지 않은 문자와 서체 데이터로 테스트할 경우에도 정확도가 높은 분류를 할 것이다. 따라서 Table 3.2대로 서체를 선택하고 학습하지 않은 문자로 Figure 3.15와 같은 변화를 주어 각 테스트마다 30,000개의 데이터를 생성했다.
각 테스트별 결과는 Table 3.3에서 확인할 수 있다. 세 종류의 테스트 모두 정확도가 높은 분류율을 보
이며, 비교적 쉬운 문자로 학습한 컨볼루션 뉴럴 네트워크의 모형임에도 불구하고 획이 많고 복잡한 문
자들에 대해서도 서체 스타일을 정확도 높게 분류한다. 테스트 1(학습한 서체)보다 테스트 2(비슷한 서
체)에서 정확도가 더 높았으며 테스트 3(비슷하지 않은 서체)에서는 분류율이 많이 떨어진다.
(a) 테스트 2 서체 (b) 테스트 3 서체
(c) 회전 (d) 위치
Figure 3.15. Test dataset composition.
Table 3.3. Test results
잘못 분류된 문자
정확도 고딕스타일 명조스타일 온전한 문자 잘린 문자
테스트 1 99.62% 99.12% 0.89% 8% 92%
테스트 2 99.74% 98.70% 1.30% 9% 91%
테스트 3 90.86% 29.07% 70.93% 5% 95%
(a) 테스트 1 (b) 테스트 2 (c) 테스트 3
Figure 3.16. Misclassified characters.
잘못 분류된 문자의 비율을 보면 테스트 1과 테스트 2는 고딕 스타일의 문자를, 테스트 3은 명조스타일 의 문자를 오분류하는 편이다. 그리고 세 가지의 테스트 모두 잘린 문자에서 오분류가 많이 발생한다.
Figure 3.16은 테스트마다 오분류한 문자들을 확인한 그림이다. 좌측 상단에 있는 첫 번째 숫자는 이미
지의 클래스인 고딕 스타일(0), 명조 스타일(1)이고 두 번째 숫자는 오분류된 클래스를 뜻한다. 오분류
그림을 보면 테스트 1과 테스트 2는 대부분의 문자가 일직선이 많고 왼쪽의 잘린 문자들이 오분류 되었
고, 테스트 3도 일직선이 많은 문자와 ‘궁서체’가 잘못 분류된 것을 확인할 수 있다.
타일 별로 유닛들이 뚜렷하게 구분된다는 것과 각 유닛에 어떠한 필터가 영향을 주었는지 파악할 수 있 고, 샐리언시 맵을 통해 각 문자에서 서체 스타일 분류에 영향을 미치는 가장 중요한 부분이 돌기부분 혹은 꺾이거나 얇아지는 부분이라는 것을 확인했다. 이를 통해 서체 스타일을 구분하는 특정한 부분적 특징을 확인할 수 있고 이는 사람의 눈이 서체 스타일을 판단하는 부분들과 상당히 일치하는 것을 알 수 있다. 사람들은 명조 스타일과 고딕 스타일을 구분할 때 문자의 돌기부분을 파악하는 것과 달리 신경망 모형은 획의 굵기가 바뀌는 부분이 가장 큰 특징으로 나타났다.
본 연구는 사람의 직관적 판단이 아닌 통계적 모형을 사용해 서체 스타일의 분류에 영향을 미치는 특징 들을 밝혀내었다. 본 연구를 바탕으로 향후에는 무수한 한글 서체들을 간편하게 관리할 수 있는 수치적 분류 기준을 제안하는 연구가 계속 되기를 바란다.
부록 A: Table
Table A.1. Hangul initial, medial, and final jamo orders.
0 1 2 3 4 5 6 7 8 9 10 11 12 13
ㄱ ㄲ ㄴ ㄷ ㄸ ㄹ ㅁ ㅂ ㅃ ㅅ ㅆ ㅇ ㅈ ㅉ
ㅏ ㅐ ㅑ ㅒ ㅓ ㅔ ㅕ ㅖ ㅗ ㅘ ㅙ ㅚ ㅛ ㅜ
ㄱ ㄲ ㄳ ㄴ ㄵ ㄶ ㄷ ㄹ ㄺ ㄻ ㄼ ㄽ ㄾ
14 15 16 17 18 19 20 21 22 23 24 25 26 27
ㅊ ㅋ ㅌ ㅍ ㅎ
ㅝ ㅞ ㅟ ㅠ ㅡ ㅢ ㅣ
ㄿ ㅀ ㅁ ㅂ ㅄ ㅅ ㅆ ㅇ ㅈ ㅊ ㅋ ㅌ ㅍ ㅎ
부록 B: Figure 첫 번째 컨볼루션층
(a) ‘ 왼’ (b) ‘ 확’
Figure B.1. First convolutional layer.
(a) ‘ 왼’ (b) ‘ 확’
Figure B.2. Second convolutional layer.
완전 연결층: 유닛별 산점도
(a) 유닛 1 vs 유닛 2 ∼ 유닛 16
(b) 유닛 2 vs 유닛 3 ∼ 유닛 16 Figure B.3. Fully connected layer: unit-wise scatter plots (units 1 and 2).
완전 연결층: 유닛별 피처맵
(a) 유닛 3 vs 유닛 4 ∼ 유닛 16
(b) 유닛 4 vs 유닛 5 ∼ 유닛 16
(c) 유닛 5 vs 유닛 6 ∼ 유닛 16
(d) 유닛 6 vs 유닛 7 ∼ 유닛 16
(e) 유닛 7 vs 유닛 8 ∼ 유닛 16
Figure B.4. Fully connected layer: unit-wise scatter plots (units 3 through 7).
(b) 유닛 9 vs 유닛 10 ∼ 유닛 16
(c) 유닛 10 vs 유닛 11 ∼ 유닛 16
(d) 유닛 11 vs 유닛 12 ∼ 유닛 16
(e) 유닛 12 vs 유닛 13 ∼ 유닛 16 (f) 유닛 13 vs 유닛 14 ∼ 유닛 16
(g) 유닛 14 vs 유닛 15 ∼ 유닛 16 (h) 유닛 15 vs 유닛 16 Figure B.5. Fully connected layer: unit-wise scatter plots (units 8 through 15).
Figure B.6. Fully connected layer: letter ‘ 샤’ in the HBATANG (한컴바탕) font.
Figure B.7. Fully connected layer: letter ‘ 샤’ in the HDOTUM (한컴돋움) font.
Figure B.8. Fully connected layer: letter ‘ 샤’ in the UNI HSR (한양해서) font.
Figure B.9. Fully connected layer: letter ‘ 샤’ in the malgun (맑은고딕) font.
Figure B.10. Fully connected layer: letter ‘ 왼’ in the HANBatang (함초롱바탕) font.
Figure B.11. Fully connected layer: letter ‘ 왼’ in the HANDotum (함초롱돋움) font.
왼’ in the UNI HSR (한양해서) font.
Figure B.13. Fully connected layer: letter ‘ 왼’ in the malgun (맑은고딕) font.
Figure B.14. Fully connected layer: letter ‘ 확’ in the HANBatang (함초롱바탕) font.
Figure B.15. Fully connected layer: letter ‘ 확’ in the HANDotum (함초롱돋움) font.
Figure B.16. Fully connected layer: letter ‘ 확’ in the HBATANG (한컴바탕) font.
Figure B.17. Fully connected layer: letter ‘ 확’ in the HDOTUM (한컴돋움) font.
출력층
Figure B.18. Output layer: letter ‘ 확’.
References
Bauermeister, B. (1988). A Manual of Comparative Typography: The PANOSE System, Van Nostrand Reinhold, New York.
Dieleman, S., Schl¨ uter, J, Raffel, C., et al. (2015). Lasagne: First Release, (Version v0.1), Zenodo.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105).
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learning, Nature, 521, 436.
Lim, S. B. and Kim, H. Y. (2016). Hangul font classification study based on numerical analysis, Extended Abstracts of HCI Korea, 180–181.
Simonyan, K., Vedaldi, A., and Zisserman, A. (2013). Deep inside convolutional networks: visualising image classification models and saliency maps, CoRR, abs/1312.6034.
Springenberg, J. T., Dosovitskiy, A., Brox, T., and Riedmiller, M. A. (2014). Striving for simplicity: the all convolutional net, CoRR, abs/1412.6806.
Zeiler, M. D. and Fergus, R. (2014). Visualizing and understanding convolutional networks, ECCV, 818–
833.
a
( 주)베가스,
b서울대학교 통계학과
(2019 년 5월 2일 접수, 2019년 6월 11일 수정, 2019년 6월 12일 채택)
요 약
로마자 서체에 대한 수치적 분류체계는 잘 발달되어 있지만, 한글 서체 분류를 위한 기준은 수치적으로 잘 정의되어 있지 않다. 본 연구의 목표는 한글 서체 분류를 위한 수치적 기준을 세우기 위해, 서체 스타일을 구분하는 중요한 특 징들을 찾는 것이다. 컨볼루션 뉴럴 네트워크(convolutional neural network)를 사용하여 명조와 고딕 스타일을 구 분하는 모형을 세우고, 학습된 필터를 분석해 두 스타일의 특징을 결정하는 피처(feature)를 찾고자 한다.
주요용어: 컨볼루션 뉴럴 네트워크, 국소적 특징, 한글, 서체 스타일, 시각화
이 논문 또는 저서는 2019년 한국연구재단의 지원을 받아 수행된 연구임 (NRF No.2019R1A2C1007126).
1