2018, 29
(2)
,367–375
랜덤포레스트를 이용한 신문사들의 19대 대통령 선거 보도 특성 분석 †
ᄌ
ᅩ현채
1
·박철용2
12계명대학교 통계학과
ᄌ ᅥ
ᆸᄉ ᅮ 2018ᄂ ᅧ ᆫ 1ᄋ ᅯ ᆯ 18ᄋ ᅵ ᆯ, ᄉ ᅮᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 2ᄋ ᅯ ᆯ 19ᄋ ᅵ ᆯ, ᄀ ᅦᄌ ᅢ ᄒ ᅪ ᆨᄌ ᅥ ᆼ 2018ᄂ ᅧ ᆫ 3ᄋ ᅯ ᆯ 5ᄋ ᅵ ᆯ
요 약
ᄀ
ᅮ ᆨᄆ ᅵ ᆫᄃ ᅳ ᆯᄋ ᅳ ᆫ ᄃ ᅢᄐ ᅩ ᆼᄅ ᅧ ᆼ ᄉ ᅥ ᆫᄀ ᅥᄋ ᅪ ᄀ ᅡ ᇀᄋ ᅳ ᆫ ᄌ ᅵ ᆨᄌ ᅥ ᆸ ᄉ ᅥ ᆫᄀ ᅥᄋ ᅦᄉ ᅥ ᄑ ᅵ ᆯᄋ ᅭᄒ ᅡ ᆫ ᄌ ᅥ ᆼᄇ ᅩᄅ ᅳ ᆯ ᄋ ᅥ ᆮᄀ ᅵ ᄋ ᅱᄒ ᅢᄉ ᅥ ᄃ ᅢᄌ ᅮ ᆼ ᄆ ᅢᄎ ᅦᄅ ᅳ ᆯ ᄆ ᅡ ᆭᄋ ᅵ ᄋ ᅵᄋ ᅭ ᆼ ᄒ ᅡ ᆫ ᄃ
ᅡ. ᄐ ᅳ ᆨ ᄒ ᅵ ᄉ ᅥ ᆫᄀ ᅥᄀ ᅵᄀ ᅡ ᆫ ᄃ ᅩ ᆼ ᄋ ᅡ ᆫ ᄀ ᅡ ᆨ ᄉ ᅵ ᆫᄆ ᅮ ᆫ ᄉ ᅡᄃ ᅳ ᆯᄋ ᅳ ᆫ ᄌ ᅡᄉ ᅵ ᆫᄃ ᅳ ᆯ ᄋ ᅴ ᄉ ᅥ ᆼᄒ ᅣ ᆼᄋ ᅳ ᆯ ᄂ ᅡᄐ ᅡᄂ ᅢᄀ ᅩ, ᄐ ᅳ ᆨᄌ ᅥ ᆼ ᄌ ᅥ ᆼᄃ ᅡ ᆼᄋ ᅳ ᆯ ᄀ ᅡ ᆫᄌ ᅥ ᆸᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄌ ᅵᄋ ᅯ ᆫ ᄒ ᅡᄂ ᅳ ᆫ ᄀ ᅧ
ᆼᄒ ᅣ ᆼᄋ ᅵ ᄋ ᅵ ᆻᄃ ᅡ. ᄋ ᅵᄇ ᅥ ᆫ 19ᄃ ᅢ ᄃ ᅢᄉ ᅥ ᆫᄋ ᅵ ᄌ ᅮ ᆼ ᄋ ᅭᄒ ᅢ ᆻᄃ ᅥ ᆫ ᄆ ᅡ ᆫ ᄏ ᅳ ᆷ ᄌ ᅮᄋ ᅭ ᄌ ᅥ ᆼᄃ ᅡ ᆼᄒ ᅮᄇ ᅩ 5ᄆ ᅧ ᆼᄋ ᅦ ᄃ ᅢᄒ ᅡ ᆫ ᄀ ᅡ ᆨ ᄉ ᅵ ᆫᄆ ᅮ ᆫ ᄉ ᅡᄃ ᅳ ᆯ ᄋ ᅴ ᄇ ᅩᄃ ᅩ ᄐ ᅳ ᆨᄉ ᅥ ᆼᄋ ᅵ ᄋ
ᅥᄄ ᅥ ᇂᄀ ᅦ ᄃ ᅬᄂ ᅳ ᆫ ᄌ ᅵ ᄌ ᅡᄅ ᅭ ᄇ ᅮ ᆫᄉ ᅥ ᆨᄋ ᅳ ᆯ ᄐ ᅩ ᆼ ᄒ ᅢ ᄋ ᅡ ᆯᄋ ᅡᄇ ᅩᄀ ᅩᄌ ᅡᄒ ᅡ ᆫᄃ ᅡ. ᄀ ᅮᄎ ᅦᄌ ᅥ ᆨᄋ ᅳᄅ ᅩ ᄋ ᅵ ᄋ ᅧ ᆫᄀ ᅮᄋ ᅦᄉ ᅥᄂ ᅳ ᆫ ᄇ ᅵ ᆨᄏ ᅡᄋ ᅵ ᆫᄌ ᅳᄋ ᅦᄉ ᅥ 13ᄀ ᅢᄋ ᅴ ᄉ ᅵ ᆫ ᄆ
ᅮ ᆫ ᄉ ᅡᄃ ᅳ ᆯᄋ ᅳ ᆯ ᄉ ᅥ ᆫᄌ ᅥ ᆼ ᄒ ᅮ ᄀ ᅥ ᆷᄉ ᅢ ᆨ ᄏ ᅵᄋ ᅯᄃ ᅳᄋ ᅦ ᄆ ᅡ ᆽᄂ ᅳ ᆫ ᄉ ᅵ ᆫᄆ ᅮ ᆫ ᄀ ᅵᄉ ᅡ ᄒ ᅢᄃ ᅡ ᆼ ᄀ ᅥ ᆫᄉ ᅮ ᄌ ᅡᄅ ᅭᄅ ᅳ ᆯ ᄉ ᅡᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ ᆻᄃ ᅡ. ᄅ ᅢ ᆫᄃ ᅥ ᆷᄑ ᅩᄅ ᅦᄉ ᅳᄐ ᅳᄅ ᅳ ᆯ ᄋ ᅵᄋ ᅭ ᆼ ᄒ
ᅡᄋ ᅧ ᄉ ᅵ ᆫᄆ ᅮ ᆫ ᄉ ᅡ ᄀ ᅡ ᆫᄋ ᅴ ᄋ ᅲᄉ ᅡᄉ ᅥ ᆼ ᄒ ᅢ ᆼᄅ ᅧ ᆯᄋ ᅳ ᆯ ᄀ ᅨᄉ ᅡ ᆫᄒ ᅡᄀ ᅩ, ᄃ ᅡᄎ ᅡᄋ ᅯ ᆫᄎ ᅥ ᆨᄃ ᅩᄇ ᅥ ᆸᄋ ᅳ ᆯ ᄌ ᅥ ᆨᄋ ᅭ ᆼ ᄒ ᅡᄋ ᅧ 2ᄎ ᅡᄋ ᅯ ᆫ ᄌ ᅵᄀ ᅡ ᆨᄃ ᅩᄅ ᅳ ᆯ ᄀ ᅳᄅ ᅧ ᆻᄃ ᅡ. ᄀ ᅳ ᄀ ᅧ ᆯ ᄀ
ᅪ ᄌ ᅦ1ᄎ ᅮ ᆨᄋ ᅳ ᆫ ᄉ ᅵ ᆫᄆ ᅮ ᆫ ᄀ ᅵᄉ ᅡ ᄎ ᅩ ᆼ ᄀ ᅥ ᆫᄉ ᅮ, ᄌ ᅦ2ᄎ ᅮ ᆨᄋ ᅳ ᆫ ᄇ ᅩᄉ ᅮ ᄃ ᅢ ᄇ ᅵᄇ ᅩᄉ ᅮᄅ ᅩ ᄒ ᅢᄉ ᅥ ᆨᄒ ᅡ ᆯ ᄉ ᅮ ᄋ ᅵ ᆻᄋ ᅥ ᆻᄃ ᅡ.
ᄌ
ᅮᄋ ᅭᄋ ᅭ ᆼ ᄋ ᅥ: ᄃ ᅡᄎ ᅡᄋ ᅯ ᆫᄎ ᅥ ᆨᄃ ᅩᄇ ᅥ ᆸ, ᄅ ᅢ ᆫᄃ ᅥ ᆷᄑ ᅩᄅ ᅦᄉ ᅳᄐ ᅳ, ᄇ ᅵ ᆨᄏ ᅡᄋ ᅵ ᆫᄌ ᅳ, ᄋ ᅲᄉ ᅡᄉ ᅥ ᆼ ᄒ ᅢ ᆼᄅ ᅧ ᆯ.
1. 서론 ᄀ
ᅮᆨ민들은대통령 선거와 같은 직접 선거에서 후보자에 대한 정보를대중매체를 통해 많이 제공받는다.
ᄀ
ᅪ거에 비해 다양하게 발달한 대중매체를매개로 한 선거홍보활동이 주종을이루면서 선거보도의 역할 ᄋ
ᅵ 갈수록 중요해지고 있다. 또한 선거보도는 신문사에서 자사의 성향과 거의 유사한 정당대표자를 지 ᄌ
ᅵ하고, 간접적으로 지원하는경향이 있기 때문에 각 신문사들의 보도 특성에관심을가지게 되면서 이 ᄋ
ᅧᆫ구가 시작되었다.
ᄎ
ᅬ근에 있었던 제 19대 대통령 선거는 18대 대선에서 당선된박근혜 전 대통령의 박근혜-최순실 게이 ᄐ
ᅳ 파문으로 대통령직을상실하면서 치러졌다. 2017년 5월 9일에 실시된 19대 대통령 선거는 촛불시위 ᄋ
ᅪ 탄핵으로 인해 온 국민에게 큰이슈이자 관심사가 되었고, 언론에서도 집중적으로 보도하였을 것이 ᄅ
ᅡ고 생각했다. 또한 19대 대선은 5개의 주요 정당 후보자들인 문재인, 홍준표, 안철수, 유승민, 심상정 5명간의 대결 구도로 진행되었다. 실제로 Kim (2005)에 따르면 후보자, 즉정당 대표자는그 해당 정당 ᄋ
ᅴ 이념적 성향을 축소해놓은 집합체이므로 각 신문사에서도 자사의 성향과 유사한 이념적 정당 대표자 르
ᆯ지지할 것이며, 선거가 임박한 법정 선거기간 동안 그 논조가 점차 심화될 것이라고 했다. 현재는대 주
ᆼ매체를 통한 선거홍보활동이 주종을이루면서 과거보다는언론의 역할이 더욱 중요해질 수밖에 없다.
†
ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ ᄌ ᅩᄒ ᅧ ᆫᄎ ᅢᄋ ᅴ ᄉ ᅥ ᆨᄉ ᅡᄒ ᅡ ᆨᄋ ᅱ ᄂ ᅩ ᆫᄆ ᅮ ᆫ ᄋ ᅦᄉ ᅥ ᄇ ᅡ ᆯᄎ ᅰᄒ ᅢᄉ ᅥ ᄌ ᅡ ᆨᄉ ᅥ ᆼᄃ ᅬᄋ ᅥ ᆻᄋ ᅳ ᆷ. ᄋ ᅵ ᄂ ᅩ ᆫᄆ ᅮ ᆫᄋ ᅳ ᆫ 2015ᄂ ᅧ ᆫᄃ ᅩ ᄌ ᅥ ᆼᄇ ᅮ (ᄀ ᅭᄋ ᅲ ᆨ ᄇ ᅮ)ᄋ ᅴ ᄌ
ᅢᄋ ᅯ ᆫ ᄋ ᅳᄅ ᅩ ᄒ ᅡ ᆫᄀ ᅮ ᆨᄋ ᅧ ᆫᄀ ᅮᄌ ᅢᄃ ᅡ ᆫᄋ ᅴ ᄌ ᅵᄋ ᅯ ᆫᄋ ᅳ ᆯ ᄇ ᅡ ᆮᄋ ᅡ ᄉ ᅮᄒ ᅢ ᆼᄃ ᅬ ᆫ ᄀ ᅵᄎ ᅩᄋ ᅧ ᆫᄀ ᅮᄉ ᅡᄋ ᅥ ᆸᄋ ᅵ ᆷ (No. NRF-2015R1D1A1A01056871).
1
(42601) ᄃ ᅢᄀ ᅮ ᄃ ᅡ ᆯᄉ ᅥᄀ ᅮ ᄃ ᅡ ᆯᄀ ᅮᄇ ᅥ ᆯᄃ ᅢᄅ ᅩ 1095, ᄀ ᅨᄆ ᅧ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄀ ᅪ, ᄃ ᅢᄒ ᅡ ᆨᄋ ᅯ ᆫᄉ ᅢ ᆼ.
2
ᄀ ᅭᄉ ᅵ ᆫᄌ ᅥᄌ ᅡ: (42601) ᄃ ᅢᄀ ᅮ ᄀ ᅪ ᆼᄋ ᅧ ᆨᄉ ᅵ ᄃ ᅡ ᆯᄉ ᅥᄀ ᅮ ᄃ ᅡ ᆯᄀ ᅮᄇ ᅥ ᆯᄃ ᅢᄅ ᅩ 1095, ᄀ ᅨᄆ ᅧ ᆼᄃ ᅢᄒ ᅡ ᆨᄀ ᅭ ᄐ ᅩ ᆼ ᄀ ᅨᄒ ᅡ ᆨᄌ ᅥ ᆫᄀ ᅩ ᆼ, ᄀ ᅭᄉ ᅮ.
E-mail: [email protected]
ᄄ
ᅩ한, 대중매체의긍정적 혹은부정적 보도에 따라 정당에 대한 지지도와 투표 의사에 영향을미친다는 ᄋ
ᅧᆫ구결과 (Dobrzynska 등, 2003)에서 입증되듯이 선거와 같이 언론이 유권자의 선거 과정이나 결과에 ᄆ
ᅵ치는영향력은막강하다고 할 수 있다. 이러한관점에서 국민들의관심도가 높았고 민감한 정치 사안 ᄋ
ᅵᆫ 19대 대통령 선거에서 주요 5명 후보에 대한 신문사의 보도 특성이 어떻게 되는지 알아보고자 이 연 ᄀ
ᅮ의 주제를 설정하였다. 구체적으로 이 연구에서는 신문사들이 19대 대선에서 주요 정당 후보자 5명 ᄋ
ᅦ 대해 보도하는 특성을 분석하고자 빅카인즈 (www.kinds.or.kr) 사이트에서 19대 대선 공식 선거 기 ᄀ
ᅡᆫ 동안 25개의 키워드를포함하는 신문기사를수집하였다. 이 신문기사 건수를 바탕으로 랜덤포레스 ᄐ
ᅳ (random forest) 방법에 의해 신문사 간 유사성행렬 (proximity matrix)을 계산하고 다차원척도법 (multidimensional scaling)에 의해 2차원지각도 (perceptual map)를그려 신문사들의 보도 특성을 분 ᄉ
ᅥᆨ하였다.
ᄋ
ᅵ 논문은다음과 같이 구성되어 있다. 2절 연구방법에서는 이 연구에서 사용된 자료가 수집된과정 ᄀ
ᅪ 이 연구에서 사용된 통계적 방법론인 랜덤포레스트와 다차원척도법을설명한다. 3절 연구결과에서는 ᄋ
ᅯ
ᆫ자료 및 표준화된자료에근거한 유클리드 거리법과 랜덤포레스트의 유사성행렬의 결과를다차원척도 버
ᆸ의 2차원지각도를 통해 비교한다. 4절 결론에서는이 연구의 내용과 결과를요약하고 이 연구의 한 ᄀ
ᅨ점과 추후 연구과제를제시한다.
2. 연구방법
2.1. 연구자료 ᄋ
ᅵ 연구에서는 19대 대통령 선거의 5대 주요 정당의 후보자들인 문재인, 홍준표, 안철수, 유승민, 심 ᄉ
ᅡᆼ정에관련된 특정 키워드가 들어간 신문기사 건수를찾아내기 위해 한국언론재단 뉴스 검색 사이트인 비
ᆨ카인즈 (www.kinds.or.kr)를이용하였다. 이 연구에 포함된 언론사는 빅카인즈에서 중앙지, 경제지 ᄅ
ᅩ 분류되어 있는 신문사들이다. 중앙지에 속한 신문사로는 경향신문, 국민일보, 내일신문, 문화일보, ᄉ
ᅥ울신문, 세계일보, 한겨레, 한국일보가 있으며 경제지에 포함된 신문사는 매일경제, 서울경제, 파이 ᄂ
ᅢᆫ셜뉴스, 한국경제, 헤럴드경제가 있어 총 13개의 신문사가 포함되었다. 기사의 검색범위는 ‘제목+본 무
ᆫ’으로 키워드가 포함된모든뉴스를검색할 수 있는바이그램을 통해 키워드를검색하였다. 연구대상 ᄀ
ᅵ간은 19대 대선의 공식 선거기간인 2017년 4월 17일부터 5월 8일까지로 설정하였다. 왜냐하면 공식 ᄉ
ᅥᆫ거기간 동안 각 정당이 본격적으로 선거운동을하며, 신문사들도 이와관련된기사를 집중적으로 보도 ᄒ
ᅡ기 때문이다.
2.2. 변수 정의 비
ᆨ카인즈의 연관성분석 서비스에 의하면 각 후보자 이름과 후보자들이 속한 당 이름, 대한민국,유세, ᄉ
ᅵ민, 지지라는단어가 공통으로 많이 나타났다. 대한민국의 경우 신문성향을파악할 수 있는단어가 아 ᄂ
ᅵ라 제외시켰다. 후보자별로 후보자 이름, 후보자가 속한 정당, ‘후보자 이름+지지 선언’, ‘후보자 이 ᄅ
ᅳᆷ+지지 호소’, ‘후보자 이름+유세’를주제어로 잡고, 다른후보 4인의 이름이나 속한 정당이 나타나면 ᄀ
ᅳ 기사를제외한 후 후보자당 5문항씩 총 25개의 변수를생성하였다. 단, 후보자가 속한 정당에는후보 ᄌ
ᅡ 이름이, ‘후보자 이름+유세’에는호소라는단어가 신문기사에 같이 나타나는경우가 많아서 후보자 ᄀ
ᅡ 속한 정당에는후보자 이름을 ‘후보자 이름+유세’의 변수에는호소를제외시킨 후 검색하였다.
부
ᆫ석대상으로 삼은 신문기사 자료는 Table 2.1에 주어진 변수이며, 목표변수가 존재하지 않는자율예 ᄎ
ᅳ
ᆨ에 해당된다. 랜덤포레스트 분석을 통해 신문사 간 유사성행렬을계산하고 다차원척도법을 통해 2차 ᄋ
ᅯ
ᆫ지각도를 그려 보도 특성을나타내고자 한다. 신문사 간의 유사성 행렬을 계산하기 위해 R 패키지
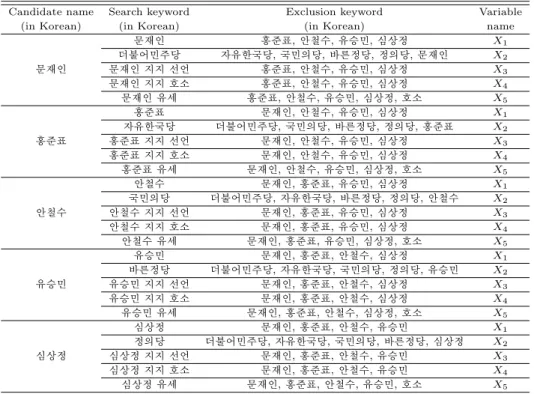
Table 2.1 Variable list with definition
Candidate name Search keyword Exclusion keyword Variable
(in Korean) (in Korean) (in Korean) name
ᄆ
ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
1ᄃ
ᅥᄇ ᅮ ᆯ ᄋ ᅥᄆ ᅵ ᆫᄌ ᅮᄃ ᅡ ᆼ ᄌ ᅡᄋ ᅲᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅡ ᆼ, ᄀ ᅮ ᆨᄆ ᅵ ᆫᄋ ᅴᄃ ᅡ ᆼ, ᄇ ᅡᄅ ᅳ ᆫᄌ ᅥ ᆼᄃ ᅡ ᆼ, ᄌ ᅥ ᆼᄋ ᅴᄃ ᅡ ᆼ, ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ X
2ᄆ
ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ ᄌ ᅵᄌ ᅵ ᄉ ᅥ ᆫᄋ ᅥ ᆫ ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
3ᄆ
ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ ᄌ ᅵᄌ ᅵ ᄒ ᅩᄉ ᅩ ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
4ᄆ ᅮ
ᆫ ᄌ ᅢᄋ ᅵ ᆫ ᄋ ᅲᄉ ᅦ ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ, ᄒ ᅩᄉ ᅩ X
5ᄒ
ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
1ᄌ
ᅡᄋ ᅲᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅡ ᆼ ᄃ ᅥᄇ ᅮ ᆯ ᄋ ᅥᄆ ᅵ ᆫᄌ ᅮᄃ ᅡ ᆼ, ᄀ ᅮ ᆨᄆ ᅵ ᆫᄋ ᅴᄃ ᅡ ᆼ, ᄇ ᅡᄅ ᅳ ᆫᄌ ᅥ ᆼᄃ ᅡ ᆼ, ᄌ ᅥ ᆼᄋ ᅴᄃ ᅡ ᆼ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ X
2ᄒ ᅩ
ᆼᄌ ᅮ ᆫ ᄑ ᅭ ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ ᄌ ᅵᄌ ᅵ ᄉ ᅥ ᆫᄋ ᅥ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
3ᄒ
ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ ᄌ ᅵᄌ ᅵ ᄒ ᅩᄉ ᅩ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
4ᄒ
ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ ᄋ ᅲᄉ ᅦ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ, ᄒ ᅩᄉ ᅩ X
5ᄋ
ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
1ᄀ
ᅮ ᆨᄆ ᅵ ᆫᄋ ᅴᄃ ᅡ ᆼ ᄃ ᅥᄇ ᅮ ᆯ ᄋ ᅥᄆ ᅵ ᆫᄌ ᅮᄃ ᅡ ᆼ, ᄌ ᅡᄋ ᅲᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅡ ᆼ, ᄇ ᅡᄅ ᅳ ᆫᄌ ᅥ ᆼᄃ ᅡ ᆼ, ᄌ ᅥ ᆼᄋ ᅴᄃ ᅡ ᆼ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ X
2ᄋ
ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ ᄌ ᅵᄌ ᅵ ᄉ ᅥ ᆫᄋ ᅥ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
3ᄋ
ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ ᄌ ᅵᄌ ᅵ ᄒ ᅩᄉ ᅩ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
4ᄋ
ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ ᄋ ᅲᄉ ᅦ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ, ᄒ ᅩᄉ ᅩ X
5ᄋ
ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
1ᄇ
ᅡᄅ ᅳ ᆫᄌ ᅥ ᆼᄃ ᅡ ᆼ ᄃ ᅥᄇ ᅮ ᆯ ᄋ ᅥᄆ ᅵ ᆫᄌ ᅮᄃ ᅡ ᆼ, ᄌ ᅡᄋ ᅲᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅡ ᆼ, ᄀ ᅮ ᆨᄆ ᅵ ᆫᄋ ᅴᄃ ᅡ ᆼ, ᄌ ᅥ ᆼᄋ ᅴᄃ ᅡ ᆼ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ X
2ᄋ
ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ ᄌ ᅵᄌ ᅵ ᄉ ᅥ ᆫᄋ ᅥ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
3ᄋ
ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ ᄌ ᅵᄌ ᅵ ᄒ ᅩᄉ ᅩ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
4ᄋ
ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ ᄋ ᅲᄉ ᅦ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ, ᄒ ᅩᄉ ᅩ X
5ᄉ ᅵ
ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ X
1ᄌ ᅥ
ᆼᄋ ᅴᄃ ᅡ ᆼ ᄃ ᅥᄇ ᅮ ᆯ ᄋ ᅥᄆ ᅵ ᆫᄌ ᅮᄃ ᅡ ᆼ, ᄌ ᅡᄋ ᅲᄒ ᅡ ᆫᄀ ᅮ ᆨ ᄃ ᅡ ᆼ, ᄀ ᅮ ᆨᄆ ᅵ ᆫᄋ ᅴᄃ ᅡ ᆼ, ᄇ ᅡᄅ ᅳ ᆫᄌ ᅥ ᆼᄃ ᅡ ᆼ, ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ X
2ᄉ ᅵ
ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ ᄉ ᅵ ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ ᄌ ᅵᄌ ᅵ ᄉ ᅥ ᆫᄋ ᅥ ᆫ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ X
3ᄉ ᅵ
ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ ᄌ ᅵᄌ ᅵ ᄒ ᅩᄉ ᅩ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ X
4ᄉ ᅵ
ᆷᄉ ᅡ ᆼᄌ ᅥ ᆼ ᄋ ᅲᄉ ᅦ ᄆ ᅮ ᆫ ᄌ ᅢᄋ ᅵ ᆫ, ᄒ ᅩ ᆼᄌ ᅮ ᆫ ᄑ ᅭ, ᄋ ᅡ ᆫᄎ ᅥ ᆯᄉ ᅮ, ᄋ ᅲᄉ ᅳ ᆼᄆ ᅵ ᆫ, ᄒ ᅩᄉ ᅩ X
5randomForest의 randomForest 함수를 이용하였다. 그리고 랜덤포레스트에서 계산된 유사성 행렬을 2차원에서 시각화 시켜주기 위해서 R 패키지 stats의 cmdscale 함수를이용하였다.
2.3. 랜덤포레스트 모형 ᄅ
ᅢᆫ덤포레스트 (random forest)는 낮은 예측력과 과적합될가능성이 높은 의사결정나무의 단점을 개 ᄉ
ᅥᆫ하기 위해 Breiman (2001)에 의해 개발된앙상블 (ensemble)기법이다. 앙상블이란 주어진 자료를 ᄋ
ᅵ용하여 예측모형을여러 개 만든후 이 예측모형들을하나로 결합하여 최종예측모형을생성하는기법 ᄋ
ᅵ다. 목표변수의 형태에 따라 분류분석, 회귀분석에서도 사용할 수 있다. 앙상블기법에는대표적으로 ᄇ
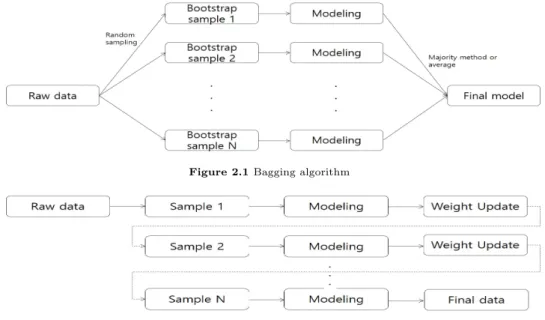
ᅢ깅 (bagging)과 부스팅 (boosting) 두 가지의 기법이 있다. 먼저, 배깅은 ‘bootstrap aggregating’의 주
ᆫ말로 Breiman (1996)에 의해 개발된 앙상블방법이다. 주어진 자료에서부터 부스트랩 표본을 여러 ᄇ
ᅥᆫ 생성하여, 각 부스트랩 표본을모형화한 후 그 예측결과를결합하여 최종예측모형을만드는방식으 ᄅ
ᅩ 이루어진다. 따라서 배깅은 일반적으로 분산이 작아져 의사결정나무보다 더 좋은성능을향상시킨다 ᄀ
ᅩ 알려져 있다. 부스팅은 Shapire 등 (1998)에 의해 개발된방법이다. 배깅과 유사하지만 이전 분류기 ᄋ
ᅴ 학습결과를토대로 다음 분류기의관측치에 대한 가중치를조정해 순차적으로 학습을 진행하는방식 ᄋ
ᅵ 다르다. 다시 말해 부스팅은이전 분류기로 올바르지 않게 예측된 관측치에 가중치를더 부여함으로 ᄊ
ᅥ 배깅에 비해 더 좋은예측정확성을보이는것으로 알려져 있다. 배깅과 부스팅의 알고리즘을그림으 ᄅ
ᅩ 정리하면 Figure 2.1과 Figure 2.2와 같다.
ᄋ
ᅮ리가 사용하는 분류용 랜덤포레스트에서는의사결정나무의 각 노드에서 모든변수를사용하지 않고 ᄆ
ᅮ작위로 일부 입력변수를선택하여 사용하기 때문에 서로 특성이 다른의사결정나무들이 생성되게 된
Figure 2.1 Bagging algorithm
Figure 2.2 Boosting algorithm
ᄃ
ᅡ. 이렇게 함으로써 의사결정나무들 간에 상관성이 작아지게 되어 예측정확성이 높아지는것으로 알 ᄅ
ᅧ져 있다 (Dudoit 등, 2002; Hamza와 Larocque, 2005; Park, 2016, 2017). 이 연구에서는 랜덤포레스 ᄐ
ᅳ를 통해 계산된신문사 간의 유사성행렬을 이용한다. 구체적으로 같은 잎 노드에 속하는의사결정나 ᄆ
ᅮ의 비율에 따라 신문사 간의 유사성행렬을구한다. 이 유사성행렬은변수 간의관련성까지 고려한 통 ᄀ
ᅨ적 거리가된다.
2.4. 다차원척도법 ᄃ
ᅡ차원척도법 (multidimensional scaling)은 개체들 간의 유사성 및 비유사성을 이용하여 개체들을 ᄀ
ᅩ
ᆼ간상의 점으로 표현하고자 한다. 일반적으로 2차원또는 3차원 공간상에 점으로 표현하며 공간상 위 ᄎ
ᅵ에 따라 개체들사이의관계를파악할 수 있다. 즉,유사성이 작은대상끼리는멀리, 유사성이큰대상 ᄁ
ᅵ리는가깝게 위치하여 각 대상들의 좌표를 공간상에 배치시켜준다. 자료 종류에 따라 분석 과정이 다 ᄅ
ᅳ다. 자료가 연속형인 경우에는각 개체들간의 거리를유클리드 거리행렬을사용하여 비유사성을 공 ᄀ
ᅡᆫ상에 표현하고, 자료가 순서형인 경우에는 순서척도를거리의 속성과 같도록변환하여 거리를생성 후 ᄀ
ᅩ
ᆼ간상에 표현하는과정을거친다. 본 논문에서는 랜덤포레스트에서 계산되는 유사성행렬을가지고 다 ᄎ
ᅡ원척도법을 통해 2차원 공간상에서 시각화 시켜주는 목적으로 사용하였다.
3. 연구결과
3.1. 신문사 성향 분류
Jecheon News Journal (2017. 10. 28)의 기사자료와 나무위키 (namu.wiki)의 자료에근거하여 분 ᄉ
ᅥᆨ에 사용한 13개의 신문사의 성향을보수와 비보수로 나누었다. 보수 신문사에는 Kukmin Ilbo (국 ᄆ
ᅵᆫ일보), Maeil Business Newspaper (매일경제), Munhwa Ilbo (문화일보), Segye Times (세계일보), Korea Economic Daily (한국경제), Herald Business (헤럴드경제), Seoul Economic Daily (서울경제)
ᄅ
ᅩ 비보수 신문사에는 Kyunghyang Shinmun (경향신문), Hankyoreh (한겨레), Seoul Shinmun (서울 ᄉ
ᅵᆫ문), Hankook Ilbo (한국일보), Naeil Shinmoon (내일신문), Financial News (파이낸셜뉴스)로 분류 ᄒ
ᅡ였다.
3.2. 랜덤포레스트의 유사성 행렬을 시각화한 결과
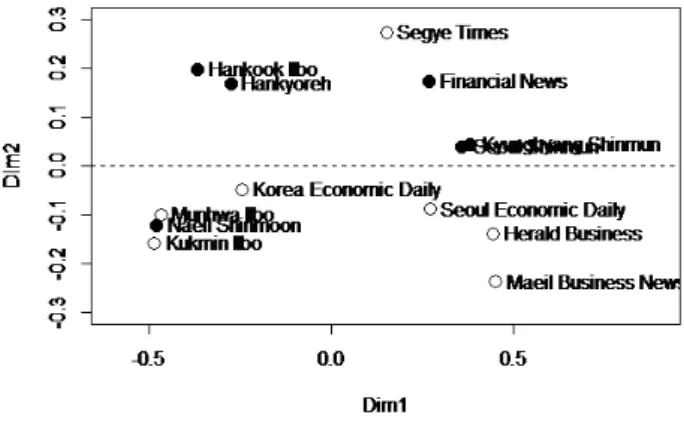
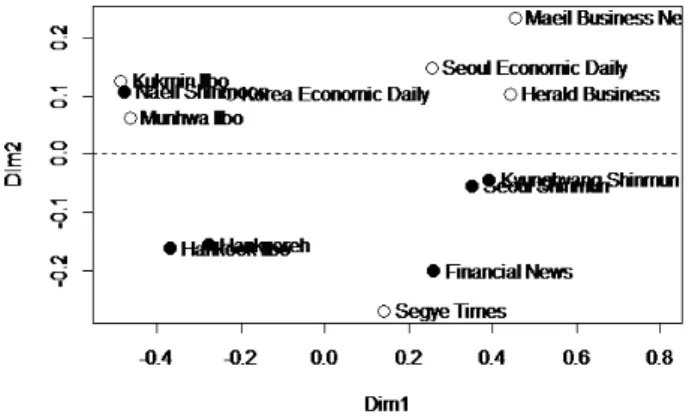
Figure 3.1 Two dimensional MDS map for the proximity matrix from random forest of the raw data
Figure 3.1은 원자료를이용하여 랜덤포레스트를 통해 유사성행렬을 계산하고 다차원척도법으로 시 ᄀ
ᅡ
ᆨ화한 결과이다. ‘•’은비보수, ‘◦’은보수의 신문사들을나타낸다. Dim1 (제 1축)을기준으로 살펴보 ᄆ
ᅧᆫ 신문기사 총건수가 많을수록오른쪽에 위치하고 있다. 그리고 Dim2 (제 2축)를기준으로 살펴보면 0을기준으로 위쪽에는비보수가 많고 아래쪽에는보수가 많아 보수 및 비보수로 해석할 수 있다. 세계 이
ᆯ보와 내일신문의 성향의 결과가 반대로 되어있는 것은세계일보는유세변수에서 차이가 나타났으며, ᄂ
ᅢ일신문은 신문기사 건수가 적어 편차가 많지 않아 뚜렷한 성향이 나타나지 않은결과라고 판단된다.
3.3. 원자료의 유클리드 거리행렬을 시각화한 결과
Figure 3.2는 원자료의 유클리드 거리행렬을이용하여 다차원척도법으로 시각화한 결과이다. 앞에서 ᄋ
ᅪ 마찬가지로 ‘•’은비보수, ‘◦’은보수 신문사들을나타낸다. Dim1 (제 1축)은 신문기사 총건수로 해 ᄉ
ᅥᆨ할 수 있지만 Dim2 (제 2축)는해석하는데 어려움이 있다. 변수 간의 분산이 다르기 때문에 발생하는 무
ᆫ제가 아닌지 궁금해서 표준화된자료를이용한 유클리드 거리행렬을이용하여 추가로 분석하였다.
3.4. 표준화된 유클리드 거리행렬을 시각화한 결과
Figure 3.3은표준화된자료를이용하여 유클리드 거리행렬을계산하고 다차원척도법을이용하여 시 ᄀ
ᅡ
ᆨ화한 결과이다. Dim1 (제 1축)은 신문기사 총건수로 해석할 수 있으나 Dim2 (제 2축)는역시 해석 ᄒ
ᅡ는데 어려움이 있다. 이를 통해 변수들의 분산 차이만 조정해서는 충분하지 않고 변수 간의관련성을 ᄀ
ᅩ려해주어야 한다는것을알 수 있다.
Figure 3.2 Two dimensional MDS map for the Euclidean distance matrix of the raw data
Figure 3.3 Two dimensional MDS map for the Euclidean distance matrix of the scaled data
3.5. 표준화된 자료의 유사성행렬을 다차원척도법으로 시각화한 결과
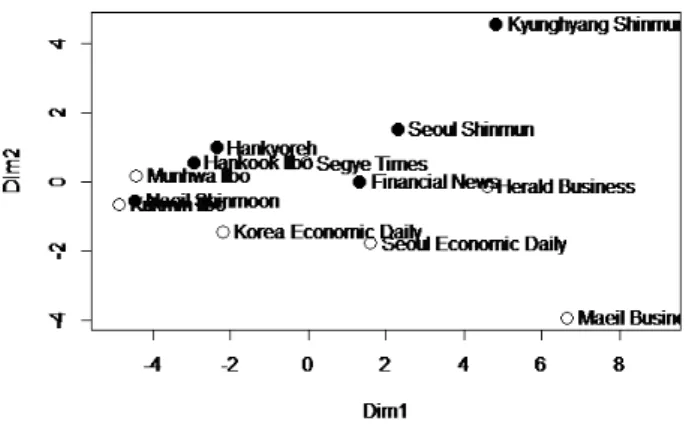
Figure 3.4는 표준화된자료를 이용해 랜덤포레스트를 통해 유사성행렬을계산하고 다차원척도법에 ᄋ
ᅴ해 시각화한 결과이다. Dim2의 값의 순서가 반대로된 것을제외하면 앞의 원자료를 이용한 유사성 ᄒ
ᅢᆼ렬 결과와 거의 비슷한 양상을 나타낸다. 의사결정나무 형성 과정에는 원자료의 값이 중요하지 않고 ᄀ
ᅳ 순서만 중요하기 때문에 랜덤포레스트 분석에는표준화된자료를사용하지 않아도큰 문제가 없다는 거
ᆺ을알 수 있다.
4. 결론 ᄃ
ᅢ중매체를 통한 선거 정보 제공의 비중은커지고 있다. 선거보도는 신문사에서 자사의 성향과 거의 ᄋ
ᅲ사한 정당대표자를지지하고, 간접적으로 지원하는경향이 있기 때문에 각 신문사들의 보도 특성에관
Figure 3.4 Two dimensional MDS map for the proximity matrix from random forest of the scaled data
시
ᆷ을가지게 되었다. 2017년 5월 19일에 이루어진 이번 19대 대통령 선거는여느 선거와는달리 촛불시 ᄋ
ᅱ와 탄핵, 정치에 대한 국민적관심이 높았기에 이번 19대 대통령 선거는그만큼언론의 역할이 중요해 지
ᆯ 수밖에 없다고 생각했다. 이런관점에서 19대 대선에서 주요 정당후보 5명에 대한 각 신문사들의 보 ᄃ
ᅩ 특성이 어떻게 되는지 분석하는것이 중요하다고 판단하여 이 연구의 주제로 설정하였다.
부
ᆫ석대상은 빅카인즈에 나와 있는 신문사들 중 중앙지, 경제지의 총 13개의 언론사들인 경향신문, 국 ᄆ
ᅵᆫ일보, 내일신문, 매일경제, 문화일보, 서울경제, 서울신문, 세계일보, 파이낸셜뉴스, 한겨레, 한국경 ᄌ
ᅦ, 한국일보, 헤럴드경제이다. 분석기간은 공식 선거 활동기간인 2017년 4월 17일부터 5월 8일 사 ᄋ
ᅵ이며 13개 신문사들을 대상으로 특정 키워드가 들어간 신문기사 건수를 검색하여 분석에 사용하였 ᄃ
ᅡ. 각 후보자당 5개의 키워드로 후보자이름, 후보자의 소속정당, ‘후보자이름+지지 선언’, ‘후보자이 ᄅ
ᅳᆷ+지지 호소’, ‘후보자이름+유세’를주제어로 선정하고 다른후보 4인의 이름이나 소속정당이 포함된 ᄀ
ᅵ사는제외시켜 총 25개의 변수를생성하였다. 이 연구에서는 랜덤포레스트의 유사성행렬과 원자료 및 ᄑ
ᅭ준화된자료의 유클리드행렬을다차원척도법으로 시각화하였다.
ᄋ
ᅵ 연구의 결과는 다음과 같다. 랜덤포레스트의 유사성행렬을 이용한 방법이 다른방법들보다 해석 겨
ᆯ과가 더 좋았다. 제 1축은 신문사의 총기사건수, 제 2축은 0을기준으로 보수 대 비보수로 해석할 수 이
ᆻ었다. 하지만 원자료 및 표준화된자료의 유클리드행렬을다차원척도법으로 시각화시킨 결과는변수 ᄀ
ᅡᆫ의관련성을고려하지 못하여 제 1축은 신문사의 총기사건수로 해석할 수 있으나 제 2축을해석하는 ᄃ
ᅦ 어려움이 발생하였다.
보
ᆫ연구의 한계점은다음과 같다.
처
ᆺ째, 연구대상 신문사 선정에서 한국 신문협회 사이트의 회원사의 전체가 아닌 빅카인즈에 나오는 신 ᄆ
ᅮᆫ사들로만 사용하였다. 한국 신문협회의 회원사를보면 전국의 일간신문 및 뉴스통신사 가운데 엄격한 시
ᆷ사절차를거쳐 49개의 신문과 1개의 통신사가 회원사가 가입되어 있지만 빅카인즈 사이트에는 42개 ᄋ
ᅴ 신문사가 있다. 특히 보수성향인 동아일보, 조선일보, 중앙일보가 빠져있어서 성향을나누어 해석하 느
ᆫ데 어려움이 있었다.
ᄃ ᅮ
ᆯ째, 빅카인즈 사이트에서 중앙지, 경제지의 언론사만 선정하여 분석에 사용하였다. 빅카인즈에서는 ᄋ
ᅥᆫ론사 구분을 중앙지, 경제지, 지역종합지, 방송사 이렇게 4가지의 분류로 나누고 있다. 지역종합지의 ᄏ
ᅵ워드 검색 결과에는결측치가 많았고, 방송사의 키워드 검색 결과에는 뚜렷한 성향적 차이를보이지 ᄋ
ᅡ
ᆭ아 분석에서 제외시켰다. 이런 이유로 중앙지, 경제지만 대상으로 하여 분석을 실시하였기 때문에 본
노
ᆫ문의 분석결과를다른언론사에확대 해석하는것은경계할 필요가 있다.
ᄉ
ᅦᆺ째, 연구기간 선정을 들 수 있다. 본연구는가장 최근의 19대 대선일정 중 후보자등록 신청 후인 4월 17일부터 투표 전날인 5월 8일까지의 자료만 사용하였다. 그러나 지난 2∼3년간에 걸친 데이터와 ᄒ
ᅡᆷ께 분석하였다면 각 신문사들의 선거보도의 특성을보다확실하게 흐름까지 짚어볼수 있지 않았을까 새
ᆼ각한다.
비
ᆨ카인즈에 있는지역종합지, 방송사뿐만 아니라 보수성향인 신문사들을포함시켜 장기간에 걸쳐 분 ᄉ
ᅥᆨ하게 되면 더욱보편적이고 다각적인 분석이 가능하리라고 생각한다.
References
Breiman, L. (1996). Bagging predictors. Machine Learning, 24, 123-140.
Breiman, L. (2001). Random forest. Machine Learning, 45, 5-32.
Dobrzynska, A., Blais, A. and Nadeau, R. (2003). Do the media have a direct impact on the vote?: The case of the 1997 Canadian election. International Journal of Public Opinion Research, 15, 27-43.
Dudoit, S., Fridlyand, J. and Speed, T. P. (2002). Comparison of discrimination methods for the classi- fication of tumors using gene expression data. Journal of the American Statistical Association, 97, 77-87.
Hamza, M. and Larocque, D. (2005). An empirical comparison of ensemble methods based on classification trees. Journal of Statistical Computation and Simulation, 75, 629-643.
Jecheon News Journal. (2017. 10. 18.). Summary of each newspapers’ disposition, Available from http:
//www.jnjl.kr/VIS_bbs/board.php?bo_table=s1_1&wr_id=2620.
Kim, S. Y. (2005). A non-verbal expression comparison of newspapers’ photographic coverage in the 17th national assembly election based on report-inclination of newspaper , Master Thesis, Kyungpook Na- tional University, Daegu.
Park, C. (2016). A simple diagnostic statistic for determining the size of random forest. Journal of the Korean Data & Information Science Society, 27, 855-863.
Park, C. (2017). A measure of discrepancy based on margin of victory useful for the determination of random forest size. Journal of the Korean Data & Information Science Society, 28, 515-524.
Shapire, R., Freund, Y., Bartlett, P. and Lee, W. (1998). Boosting the margin: A new explanation for the
effectiveness of voting methods. Annals of Statistics, 26, 1651-1686.
2018, 29
(2)
,367–375
Analysis of reporting characteristics of newspapers in the 19th presidential election based on random forest †
HyunChae Jo
1
· Cheolyong Park2
12Department of Statistics, Keimyung University
Received 18 January 2018, revised 19 February 2018, accepted 5 March 2018
Abstract
People usually get information from mass media for their decision in direct election like presidential election. Especially each newspaper shows its disposition and tends to support specific party during the election. The 19th presidential election was very important and thus, in this study, we aimed to analyze reporting characteristics of newspapers for five major candidates in this election. More specifically, in this study, our analysis utilized the number of newspaper articles for some key words from 13 newspapers selected from BigKinds website. We calculated a proximity matrix between newspapers based on random forest, and then drew a two dimensional perceptual map of the matrix based on multidimensional scaling. From the map, we can interpret that the first axis represents the total number of newspaper articles and the second axis represents conservative vs non-conservative groups of newspapers.
Keywords: BigKinds website, multidimensional scaling, proximity matrix, random for- est.
†
This paper is extracted from HyunChae Jo’s Master Thesis. This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2015R1D1A1A01056871).
1
Master candidate, Department of Statistics, Keimyung University, Daegu 42601, Korea.
2