커널 스펙트럼 모델 backfitting 기반의 로그 스펙트럼 진폭 추정을 적용한
배경음과 보컬음 분리
Music and Voice Separation Using Log-Spectral Amplitude Estimator Based on Kernel Spectrogram Models Backfitting
이준용, 김형국†
(Jun-Yong Lee and Hyoung-Gook Kim†)
광운대학교 전파공학과
(Received December 15, 2014; revised February 12, 2015; accepted April 1, 2015)
초 록: 본 논문은 커널 스펙트럼 모델 backfitting 기반의 로그 스펙트럼 진폭 추정부를 적용한 배경음과 보컬음 분리 를 제안한다. 기존의 커널 스펙트럼 모델 기반의 배경음과 보컬음 분리는 추출하고자하는 객체의 모델을 기반으로 위 너형태의 평균 제곱의 오차의 이득값을 학습함으로써 배경음과 보컬음을 분리하는 기술이다. 본 논문은 기존의 커널 스펙트럴 모델 기반의 배경음과 보컬음 분리 방식에서 위너형태의 이득값 대신 로그 스펙트럼 진폭 추정을 적용하여 기존 방식 보다 명료한 배경음과 보컬음을 추출한다. 실험결과는 본 논문에서 제안한 방식이 기존의 방식들보다 더 우 수하다는 것을 보인다.
핵심용어: 음원 분리, 커널 스펙트럼 모델, 로그 스펙트럼 진폭, Backfitting
ABSTRACT: In this paper, we propose music and voice separation using kernel sptectrogram models backfitting based on log-spectral amplitude estimator. The existing method separates sources based on the estimate of a desired objects by training MSE (Mean Square Error) designed Winer filter. We introduce rather clear music and voice signals with application of log-spectral amplitude estimator, instead of adaptation of MSE which has been treated as an existing method. Experimental results reveal that the proposed method shows higher performance than the existing methods.
Keywords: Source separation, Kernel spectrogram models, Log-spectral amplitude (LSA), Backfitting PACS numbers: 43.60.–c
†Corresponding author: Hyoung-Gook Kim ([email protected]) Department of Wireless Communication Engineering, Kwang- Woon University, 20 Gwangun-Ro, Nowon-Gu, Seoul 139-701, Republic of Korea
(Tel: 82-2-940-5574, Fax: 82-2-913-5006)
I. 서 론
음원 분리 기술은 혼합된 오디오 신호에 대해 배 경음과 보컬음을 분리하는 기술로써 지난 30년간 꾸 준히 연구되고 있으며 텔레커뮤니케이션, 오디오 신 호 처리, 은닉 성분 분석, 생체 신호처리, 입체음향 재 현 등 다양하게 적용되고 있다. 음원 분리 기술은 ICA (Independent Components Analysis),[1] RPCA(Robust
Principal Component Analysis),[2] NMF(Non-negative Matrix Factorization)[3] 등 여러 가지 방식을 이용하여 음원을 보컬음과 배경음의 객체로 분리하는 연구로 진행되고 있는데 그 중 Rafii와 Pardo[4]의 REPET 방식과 Liutkus et al.[5]의 커널 스펙트럼 모델기반의 음원분 리기술이 가장 대표적이다.
Rafii와 Pardo[4]의 반복적인 배경음에 대한 배경음, 보컬음 분리기술(REPET)은 배경음이 반복적인 특 성을 갖는 점을 이용하여 반복적인 배경음과 보컬음 을 추출하는 방식이다. 하지만 이 방식은 강한 에너 지를 갖는 주기만을 검출하기에 그 외의 반복적인
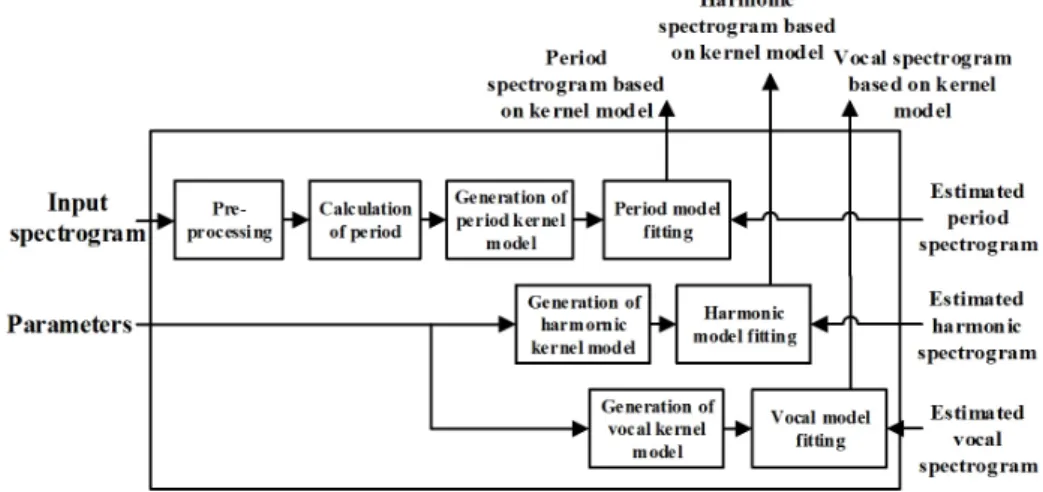
Fig. 1. A block diagram of music and voice separation using log-spectral amplitude estimator based on kernel spectrogram models backfitting.
주기를 잘 검출하지 못한다는 문제점과 추출된 배경 음을 원음에서 차감하는 식으로 보컬음을 추출하기 에 명료한 배경음이 추출되지 않을 경우 보컬음에도 배경음이 묻어나온다는 문제가 있다.
또한 최근 가장 활발히 연구되고 있는 NMF 기반 의 음원분리 기술은 지역적으로 변화하는 주기에 대 한 모델을 형성하지 못하기 때문에 정확한 배경음과 보컬음을 분리하지 못한다는 문제점이 있다.
이를 보안하기 위해 Liutkus et al.[5]는 커널 스펙트럼 모델기반의 음원분리기술을 연구했으며, 이 방식은 주기에 대한 객체를 다중으로 분리함으로써 강한 에 너지를 갖는 주기 뿐만 아니라 일정한 패턴을 갖는 반 복적인 배경음을 추출한다. 또한 분리하고자 하는 객 체의 모델을 생성하고 학습을 통한 위너형태의 게인 을 적용하여 지역적인 배경음과 보컬음을 추출 할 수 있다. 하지만 Liutkus et al.[5]의 방식에서 사용된 위너 필터 기반의 이득값 갱신 방법은 진폭만을 고려하기 에 정확한 이득값을 갱신하지 못한다는 문제가 있다.
따라서 본 논문에서는 기존에 적용된 위너 필터 방식 대신, 로그 스펙트럼 진폭(log-spectral amplitude) 추정[6]을 적용함으로써 위상과 진폭에 대한 이득값 을 갱신하고 기존 방식보다 명료한 배경음과 보컬음 을 분리 하는 방식을 제안한다.
본 논문은 다음과 같이 구성되어있다. II장에서는 커널 스펙트럼 모델 backfitting 기반의 로그 스펙트 럼 진폭 추정을 적용한 배경음과 보컬음 분리 과정 을 설명하고 III장에서는 제안된 방식에 대한 실험 결과를 제시하며 마지막으로 IV장에서 결론 및 향후 연구 방향을 서술한다.
II. 커널 스펙트럼 모델 backfitting
기반의 로그 스펙트럼 진폭 추정을 적용한 배경음
과 보컬음 분리커널 스펙트럼 모델 backfitting 기반 의 로그 스펙트럼 진폭 추정을 적용한 배경음과 보 컬음 분리는 Fig. 1과 같이 STFT(Short Time Fourier Transform), 커널 스펙트럼 backfitting 기반의 로그 스 펙트럼 진폭 추정부, ISTFT(Inverse Short Time Fourier Transform), 배경음 믹싱부, 4개의 모듈로 구성되어 있다.
먼저 입력된 오디오 신호 s(n)은 STFT 과정을 거쳐 시간축 영역의 신호가 주파수 축으로 변환된다. 오 디오 스펙트럼 은 주기성과 하모닉한 특성을 지닌 여러 악기음과 하나의 보컬음이 혼합된 스펙트 럼이며 하나의 소스를 객체라 가정하고 주기, 하모 닉, 보컬에 대한 객체로 구성되어 있다.
, (1)
여기서 j는 객체에 대한 인덱스를 의미하며, J는 전 체 객체의 개수이고 f는 주파수 빈, l은 시간 인덱스 를 의미한다. 은 객체에 대한 스펙트럼이다.
변환된 오디오 스펙트럼은 커널 스펙트럼 backfitting 기반의 로그 스펙트럼 진폭 추정부에 입력되어 각 각의 객체(주기, 하모닉, 보컬)를 추정하고 객체로부 터 추정된 스펙트럼들은 ISTFT 과정을 거쳐 시간축 신호로 다시 전환된다. 이때 주기 신호와 하모닉 신 호는 배경음 믹서에 입력되어 하나의 배경음 신호로 출력되며 추정된 보컬음 스펙트럼은 독립적으로 ISTFT가 수행되어 최종적으로 분리된 보컬음 신호 가 출력된다.
2.1 커널 스펙트럼 backfitting 기반의 로그 스펙트럼 진폭 추정부
커널 스펙트럼 backfitting 기반의 로그 스펙트럼 진폭
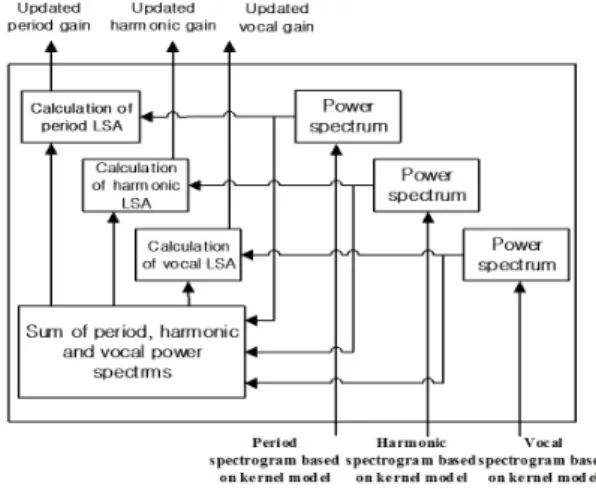
Fig. 2. A block diagram of log-spectral amplitude estimator based on kernel spectrogram models.
Fig. 3. A block diagram of fitting of kernel spectrogram models.
추정부에 대해 보다 상세한 내용은 Fig. 2에 나타나 있으며, 커널 스펙트럼 모델 피팅부, 로그 스펙트럼 진폭 추정부, 신호 출력 판단부 3가지 모듈로 구성되 어 있다. 각각의 객체들은 독립적으로 수행된다.
먼저 원신호의 오디오 스펙트럼에 로그 스펙트럼 진폭이득값을 곱하여 추정된 객체 스펙트럼을 계산 하고 신호 출력 판단부로 입력한다. 신호 출력 판단 부의 신호 출력 조건에 충족되지 않을 경우, 현재 입 력된 스펙트럼을 커널 스펙트럼 모델 피팅부로 입 력하여 추출하고자하는 객체의 모델 형상에 맞는 스 펙트럼으로 갱신한다. 갱신된 스펙트럼은 로그 스펙 트럼 진폭 추정부에 입력되어 커널 스펙트럼 모델에 해당하는 이득값
을 계산하고, 원신호 오 디오 스펙트럼 에 적용하여 추정된 객체 스펙 트럼을 갱신한다.
∙ . (2)
최종적으로 추정된 객체 스펙트럼이 계산될 때까 지 반복적으로 커널 스펙트럼 모델 갱신, 로그 스펙 트럼 진폭 이득값 갱신, 추정된 객체 스펙트럼 갱신 을 하는데 이 과정을 backfitting 이라 정의하며 각 모 듈의 상세한 내용은 세부 장에서 설명한다.
2.1.1 커널 스펙트럼 모델 피팅부
커널 스펙트럼 모델 피팅부는 추정하고자 하는 객 체의 모델을 생성해서 입력된 스펙트럼을 생성된 모 델 형태에 맞게 스펙트럼을 변환해 주는 과정으로 커널 스펙트럼 모델 생성부와 모델 피팅부 2가지로 구성되어있다.
커널 스펙트럼 모델은 주기, 하모닉, 보컬음 객체 의 지역적인 스펙트럼에서 주파수 축에 의한 일정 간격의 반복된 주기 모델, 시간축 영역으로 일정하 게 존재하는 하모닉 모델, 주파수 축과 시간축 영역 이 결합된 십자형 형태의 보컬음 모델로 독립적으로 생성되며 커널 스펙트럼 모델을 생성하는 과정은 다 음과 같다.
먼저 주기커널 스펙트럼에 대한 모델을 생성하기 위해 입력된 오디오 스펙트럼 에 대한 파워스 펙트럼된 정규화 과정 을 실시한다. 정규화 과정은 각 주파수 빈의 전체프레임의 평균을 계산하 여 각 주파수 빈에 계산된 평균을 가중치로 부여하 는 방식으로 저주파의 강한 신호들과 고주파의 상대
Fig. 4. A block diagram of log-spectral amplitude (LSA) estimator.
적으로 약한 신호를 정규화해주는 역할을 한다.
정규화된 파워스펙트럼을 기반으로 비트스펙트
럼 을 계산하는데 비트스펙트럼은 에너지의
밀도(power spectrum density)를 이용하여 주기 템포 나타내는 스펙트럼으로써 비트스펙트럼의 각 프레 임에서의 주파수 빈의 평균값 중 최대값을 지니 는 시간축의 인덱스가 주기 P가 된다.
,
, (3)
max,
여기서 r은 전체 주파수 빈의 개수를 나타내고 w는 윈도우의 크기를 나타낸다. 생성된 주기를 기반으로 타악기와 같은 퍼커시브한 성분의 주기에 해당하는 커널 스펙트럼 모델을 생성한다.
하모닉 스펙트럼 모델 커널과 보컬음 스펙트럼 커 널 모델은 주기 스펙트럼 모델 커널과 다르게 입력 된 파라미터를 통해 생성된다. 하모닉 스펙트럼 모 델 커널은 화성 악기음이 하모닉한 성분을 가진다는 특성을 이용하여 입력된 스펙트럼의 하모닉한 성분 을 추출해주는 커널 모델이다. 이 모델은 입력된 파 라미터에 해당하는 스펙트럼의 크기만큼 시간축의 행의 형태로 구성된다.
보컬음 스펙트럼 모델 커널은 포만트한 특징을 갖 는 음성을 추출하기 위해 사용되며 시간축과 주파수 축의 영역의 십자형 형태의 2차원 커널로 생성된다.
커널 모델 생성부 과정을 통해 생성된 객체의 커 널 스펙트럼 모델들은 피팅부에 적용되어 추정된 객 체의 스펙트럼 에 대한 커널 스펙트럼 모델 기 반의 객체 스펙트럼 으로 갱신된다. 커널 스 펙트럼 모델을 적용하기 위해서 메디언 필터링 과정 을 수행하는데 메디언 필터링은 입력된 스펙트럼에 서 커널 스펙트럼 모델에 해당하는 영역만큼의 중간 값을 출력함으로써 커널 모델에 해당하는 값만을 부 드럽게 갱신해주는 역할을 한다.
∈ , (4)
여기서 a는 커널 스펙트럼 모델의 주파수 빈, b는 커 널 스펙트럼 모델의 시간축 인덱스를 의미하며
는 주기, 하모닉, 보컬 객체의 커널 스펙트럼
모델을 나타낸다.
커널 스펙트럼 모델 피팅부를 통해 갱신된 스펙트 럼 값들은 로그 스펙트럼 진폭 추정부로 입력된다.
2.1.2 로그 스펙트럼 진폭 추정부
스펙트럴 진폭은 위상과 청각적으로 밀접한 관계 가 있다고 선행 연구되었다.[7] 로그 스펙트럼 진폭은 인간의 청각적인 특성을 고려하여 위상과 진폭을 모 두 고려한 로그화된 이득값을 추정한다. 이 방식은 위 상과 진폭에 대한 이득값 추정방식인 MMSE STSA 방 식보다 잡음제거 방식에서 더 적합하다고 알려져있 다.[8] Fig. 4는 로그 스펙트럼 진폭 추정을 나타낸다.
먼저 로그 스펙트럼 진폭 추정부에 입력된 커널 스 펙트럼 모델 기반의 스펙트럼들 은 크기와 위 상으로 구성되어 있는데 그 중 크기만을 고려하여 객체의 파워스펙트럼 을 계산해준다. 그리고 전체 스펙트럼에 대한 비율을 계산해주기 위해 객체 전체의 파워스펙트럼의 합 을 계산한다.
객체의 파워스펙트럼 값과 전체 객체의 파워스펙 트럼의 값을 기반으로 Eq.(5)와 같이 로그 스펙트럼
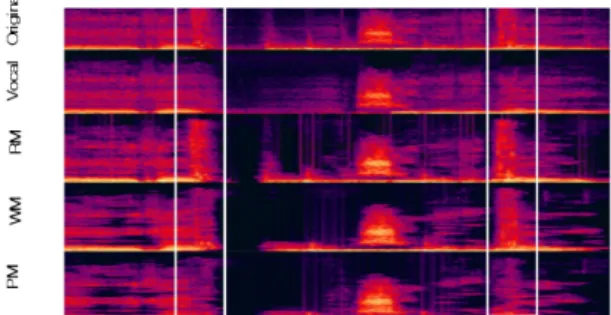
Fig. 5. Comparison of the output spectra of several schemes.
진폭 이득값
을 계산할 수 있다.
∞
∙
(5)
여기서 은 추정하고자하는 객체의 커널 모델
이 적용된 스펙트럼에 대한 나머지 객체의 커널 모델 이 적용된 스펙트럼의 비율이다. 즉, 사전 신호 대 잡 음 비를 의미하고 은 원신호의 파워스펙트럼 값에 대한 나머지 객체의 커널 모델이 적용된 스펙 트럼의 비율인 사후 신호 대 잡음비를 나타낸다.
로그 스펙트럼 진폭 추정을 통해 갱신된 이득값은 원신호의 스펙트럼에 적용되어 추정된 객체 스펙트 럼을 획득하는데 사용된다.
2.1.3 신호 출력 판단부
신호 출력 판단부는 입력된 객체의 추정 스펙트럼 과 이전에 입력된 객체의 추정 스펙트럼에 대한 변 화 추이를 비교하여 최종적으로 추정된 객체 스펙트 럼을 출력해주는 부분이다.
추정된 객체 스펙트럼이 신호 출력 판단부에 입력 되면, 입력된 객체 스펙트럼에 대한 평균값 계산한 다. 계산된 평균값을 기반으로 이전에 입력된 객체 스펙트럼과 현재 입력된 스펙트럼간의 비율을 계산 한다. 이 비율을 오차 판정 문턱값 T와 비교하여 T보 다 작다면 현재 스펙트럼과 이전 스펙트럼간의 변화 가 거의 없다는 것으로 판단하여 최종적으로 객체에 대한 추정 스펙트럼을 출력한다. 반대로 오차 판정 문턱값 T보다 계산된 비율 값이 크다면 현재 추정된 스펙트럼이 충분히 커널 모델에 맞게 갱신되지 않다 고 판단하여 커널 스펙트럼 모델 피팅부로 입력 후 앞선 모든 과정을 반복하는데 이 과정을 backfitting 이라고 정의한다.
i f
최종신호 출력
, (6)
여기서 은 이전에 추정된 객체 스펙트럼이며 T는 오차 판정 문턱값이다.
Backfitting은 앞서 계산된 커널 스펙트럴 모델 갱 신, 로그 스펙틀럴 이득값 갱신 , 추정된 객체 스펙트 럼 갱신 과정이 유기적으로 연결되어 반복 학습되는 과정으로 backfitting 과정을 통해 입력된 오디오 신 호에서 커널 스펙트럴 모델과 유사한 객체를 추정할 수 있다.
III. 실험 결과
본 논문에서 제안한 방식의 성능을 측정 및 비교하 기 위해 REPET Adaptive 방식(RM), 위너형태의 이득 값을 적용한 커널모델 기반의 분리방식(WM), 본 논 문에서 제안한 로그 스펙트럼 진폭 추정부 기반의 방 식(PM), 3가지 방식을 이용했다. Fig. 5는 원음에서 각 방식을 통해 출력된 스펙트럼을 나타낸다.
Fig. 5의 제일 상단에 있는 스펙트럼은 배경음과 보컬음이 혼합된 원음에 대한 스펙트럼 그리고 두 번째는 클린한 보컬음만 존재하는 스펙트럼을 나타 낸다. Fig. 5에서 박스로 표시 한 부분은 퍼커시브한 성분의 배경음이 보컬음과 혼합된 영역을 나타내는 데 그림에서 보이는 바와 같이 본 논문에서 제안한 방식인 PM이 WM과 RM 보다 더 많은 퍼커시브한 성 분을 제거하여 클린한 보컬음에 유사하게 출력되는
Fig 6. ∆SDR performance for vocal signal.
것을 확인할 수 있다.
본 논문에서 제안한 방식에 대한 객관적인 지표의 성능을 나타내기 위해 BSS_Oracle 툴박스의[9] ∆ SDR(Source-to-Distortion Ratio)을 측정하였다. ∆SDR 은 레퍼런스 신호(클린한 배경음 혹은 보컬음)와 측 정신호간의 왜곡의 정도를 데시벨 단위로 나타내며 0 dB에 가까울수록 측정신호가 레퍼런스 신호와 유 사하는 것을 의미한다.
실험에 사용된 음원은 44.1 kHz의 샘플링레이트, 16 비트의 깊이의 50개 트랙의 ccMixter 데이터를 사 용했다. Liutkus et al.[5]의 방식과 동일한 조건으로 실 험을 하기 위해 50개의 트랙을 30 s 구간으로 세그먼 트 하여 보컬음에 대한 ∆SDR을 측정하였으며 각 방식의 파라미터 값들은 최적화되었다. Fig. 6은 3가 지 방식에 대한 보컬음의 SDR 측정결과를 나타낸다.
실험결과 WM 방식과 PM방식이 RM 방식보다 확 연히 높은 SDR 측정결과가 나왔으며 이는 커널 스펙 트럼 모델 기반의 배경음과 보컬음 분리 방식이 RM 방식보다 우수한 방식이라는 것을 입증한다. 또한 본 논문에서 제안한 PM방식은 기존의 WM 보다 ∆ SDR 측정결과가 평균 0.7이 상승한 결과를 보인다.
IV. 결 론
본 논문은 커널 스펙트럼 모델 backfitting 기반의 로그 스펙트럼 진폭 추정을적용한 배경음과 보컬음 분리를 제안하였다. 실험결과 커널 스펙트럼 모델 기반의 배경음과 보컬음 분리 방식이 REPET 방식보 다 더 명료한 보컬음을 추출한다는 것을 확인했으며
특히, 논문에서 제안한 방식이 배경음과 보컬음 모 두 기존의 REPET 방식, 위너형태의 커널 모델 기반 분리 기법보다 레퍼런스 신호에 더 유사하게 분리 된다는 것을 확인했다.
제안된 방식을 통해 추출된 배경음과 보컬음은 입 체음향 시스템에 적용되어 분리된 객체기반으로 풍 성한 음장감과 명료한 방향감을 부여할 수 있을 것 이라 사료된다.
향후 본 알고리즘을 최적화 하는 방안과 분리된 배경음과 보컬음을 입체음향 시스템에 적용하는 방 안에 대해 연구 할 예정이다.
감사의 글
본 연구는 2014년도 광운대학교 교내 학술연구비 지원과 미래창조과학부 및 정보통신기술진흥센터 의 대학 ICT 연구센터 육성 지원사업의 연구결과로 수행되었음(IITP-2015-H8501-15-1016).
References
1. P. Comon and C. Jutten, Handbook of Blind Source Separation:
Independent Component Analysis and Applications (Academic Press, 2010). pp. 208-214.
2. P.-S. Huang, S. D. Chen, P. Smaragdis, and M. H. Johnson,
“Singing-voice separation from monaural recordings using robust principal component analysis,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 57-60 (2012).
3. A. Ozerov, E. Vincent, and F. Bimbot, “A general flexible framework for the handling of prior information in audio source separation,” Audio, Speech, and Language Processing, IEEE Transactions on, 1118-1133 (2011)
4. Z. Rafii and B. Pardo, “Repeating pattern extraction technique (REPET): A simple method for music/voice separation,”
IEEE Transactions on Audio, Speech & Language Processing, 71-82 (2013).
5. A. Liutkus, Z. Rafii, E. Fitzgerald and L. Daudet, “Kernel spectrogram models for source separation,” 4th Joint Workshop on Hands-free Speech Communication Microphone Arrays, (2014).
6. Y. Ephraim and D. Malah, “Speech enhancement using a minimum mean-square error log-spectral amplitude esti- mator,” IEEE Trans. Acoust. Speech Signal Process, 443-445 (1985).
7. B. J. Shannon and K. K. Paliwal, “Role of phase estimation in speech enhancement,” in Proc. 9th Int. Conf. Spoken Language Processing - Interspeech, Pittsburgh, PA, 1423- 1426 (2006).
8. Y. Ephraim and I. Cohen, “Recent advancements in speech enhancement,” in the Electrical Engineering Handbook, (CRC press, 2005).
9. E. Vincent, R. Gribonval, and M. Plumbley, “Oracle estimators for the benchmarking of source separation algorithms,”
Signal Processing, 1933-1950, (2007).
저자 약력
▸이 준 용 (Jun-Yong Lee)
2014년: 광운대학교 전자융합공학과 학사 2014년 ~ 현재: 광운대학교 전파공학과
석사과정
▸김 형 국 (Hyoung-Gook Kim)
1999년 ~ 2002년: 독일 SIEMENS/ Cortologic AG 책임연구원
2002년 ~ 2005년: 독일 베를린 공과대학교 Assistant Professor
2005년 ~ 2007년: 삼성종합기술원 수석 연구원
2007년 ~ 현재: 광운대학교 전자융합공학과 교수

![Fig 6. ∆ SDR performance for vocal signal. 것을 확인할 수 있다. 본 논문에서 제안한 방식에 대한 객관적인 지표의 성능을 나타내기 위해 BSS_Oracle 툴박스의 [9] ∆ SDR(Source-to-Distortion Ratio)을 측정하였다](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4745045.269861/6.892.129.392.168.371/performance-확인할-논문에서-객관적인-나타내기-툴박스의-distortion-측정하였다.webp)
