The Video on Demand System Failure Evaluation of Software Development Step
1)
전체 글
1)
수치
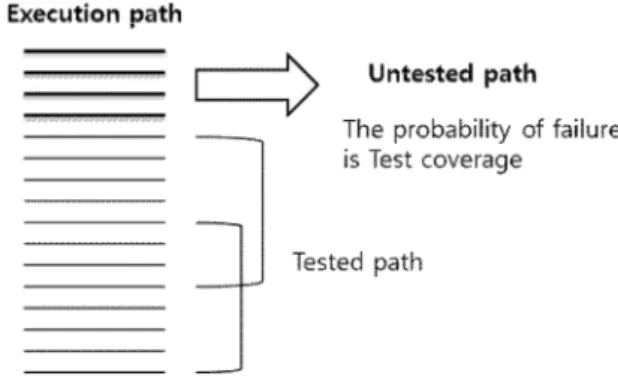
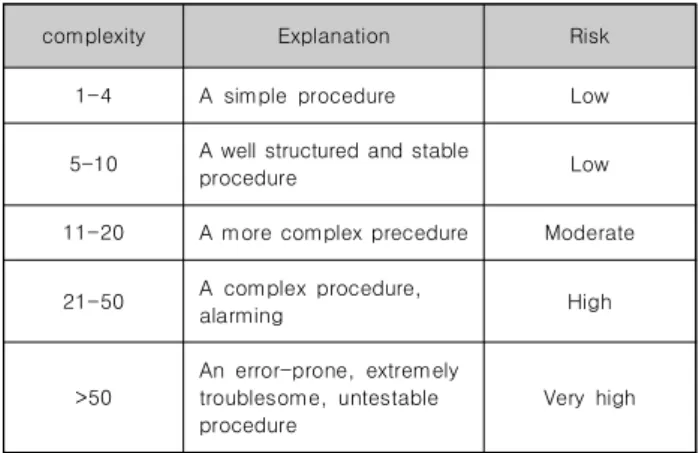

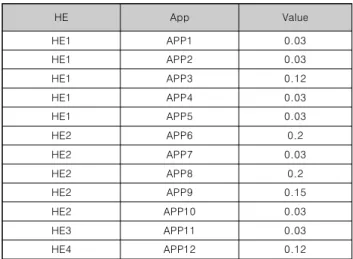
관련 문서
We describe the case of a patient with new-onset heart failure in whom cardiac CT (5) identified characteristic myocardial changes of the isolated left ventricular non-compaction
Abstract: In this study, we have established the design techniques, with which we can design and evaluate performance of blades on a horizontal axis
An evaluation model including the effects of thinning depth, length, circumferential angle, thinning location, and elbow geometries on the failure pressure is derived based
Key Words : Attributes Evaluation, Erlang Distribution, Finite Failure NHPP, Lifetime Distribution, Pareto Distribution,
