水 工 學
大 韓 土 木 學 會 論 文 集第26卷 第3B 號·2006年 5月 pp. 279 ~ 289
Support Vector Machine과 상태공간모형을 이용한 단변량 수문 시계열의 동역학적 비선형 예측모형
Dynamic Nonlinear Prediction Model of Univariate Hydrologic Time Series Using the Support Vector Machine and State-Space Model
권현한*·문영일**
Kwon, Hyun-Han·Moon, Young-Il
···
Abstract
The reconstruction of low dimension nonlinear behavior from the hydrologic time series has been an active area of research in the last decade. In this study, we present the applications of a powerful state space reconstruction methodology using the method of Support Vector Machines (SVM) to the Great Salt Lake (GSL) volume. SVMs are machine learning systems that use a hypothesis space of linear functions in a Kernel induced higher dimensional feature space. SVMs are optimized by min- imizing a bound on a generalized error (risk) measure, rather than just the mean square error over a training set. The utility of this SVM regression approach is demonstrated through applications to the short term forecasts of the biweekly GSL volume.
The SVM based reconstruction is used to develop time series forecasts for multiple lead times ranging from the period of two weeks to several months. The reliability of the algorithm in learning and forecasting the dynamics is tested using split sample sensitivity analyses, with a particular interest in forecasting extreme states. Unlike previously reported methodologies, SVMs are able to extract the dynamics using only a few past observed data points (Support Vectors, SV) out of the training examples.
Considering statistical measures, the prediction model based on SVM demonstrated encouraging and promising results in a short-term prediction. Thus, the SVM method presented in this study suggests a competitive methodology for the forecast of hydrologic time series.
Keywords :
nonlinear prediction, support vector machine, state-space reconstruction, learning model···
요 지
최근에 수문시계열로부터 저차원의 비선형 거동을 재구성하고자 하는 연구가 활발히 진행되고 있다
.이러한 관점에서 본
연구에서는
Support Vector Machine(SVM)을 이용하여 우수한 상태
-공간 재구성 능력을 갖는 비선형 예측모형을 구성하여
Great Salt Lake(GSL) Volume
에 적용하였다
. SVM은
Kernel함수로부터 유도된 고차원의 특성공간 안에서 선형함수의 가
상공간을 이용하는
Machine Learning방법론이다
.또한
SVM은 훈련자료로부터 얻어지는 평균제곱오차가 아닌 일반화된 오
차를 최소화함으로써 상대적으로 기존 방법에 비해 적은 수의 매개변수와 과적합
(over fitting)을 피하면서 비선형 함수의 최
적화가 가능하다
.본 연구에서 제시한
SVM회귀분석의 적용성은 미국의
GSL의
2주 간격
Volume을 대상으로 검토하였다
. SVM을 이용한 비선형 예측모형은
GSL Volume의
2주
(1-Step), 8주
(4-Step)와 반복예측
(Iterated Prediction, 121-Step)까지 적용되었다
.본 연구에서는 극치사상 즉
,급격한 감소 및 증가 구간을 예측하는데 있어서 훈련구간과 예측구간을 구분하여 모형의 신뢰성을 평가하였다
.예측결과
SVM은 훈련자료로부터 적은 수의 관측치를 이용하여 동역학적 거동을 추출할 수 있
었으며 실제 관측자료와 거의 유사한 예측이 가능함을 통계적 지표로 확인할 수 있었다
.따라서 비선형 수문시계열의 단기 예측을 위한 모형으로 적용이 가능할 것으로 판단된다
.핵심용어 : 비선형 예측
, support vector machine,상태
-공간 재구성
,학습모형
···
1. 서 론
최근에 기상이변 및 이상홍수 등의 수문기상학적 불확실성 이 점점 커지고 있으며 과거보다 심한 홍수 및 가뭄이 빈번 하게 발생하고 있다. 따라서, 이러한 수문학적 불확실성 및
위험도를 낮추기 위한 일환으로 수문시스템 예측의 중요성 이 대두되고 있다. 일반적으로 수문시계열은 많은 경우 비선 형 특성을 갖고 있으며, 이에 대한 시계열 분석으로 일반적 으로 사용되는 선형 방법을 확장한 비선형 방법에 의한 접 근 방법이 필요하다 하겠다. 그러나 기존의 AR(autoregressive), *
정회원·Postdoctoral Research Associate Columbia University, NY, USA(E-mail: [email protected])
**
정회원·교신저자·서울시립대학교토목공학과부교수(E-mail: [email protected])
ARMA(autoregressive moving average), ARIMA(autore- gressive integrated moving average) 모형은 대부분 선형모 형으로서 비선형특성을 갖는 수문시계열의 선형모형을 적용 하여 실시함으로써 통계적인 특성을 충분히 반영하기 어려우 며 특히 이전과는 다른 극치사상 및 큰 전환점이 존재하는 지점에서 신뢰할 수 없는 예측이 이루어지는 단점이 있다 .
국내에서의 수문시계열 예측에 관한 연구를 살펴보면 박무 종과 윤용남 (1989) 은 Multiplicative ARIMA 모형을 사용하 여 주기성과 경향성을 가지는 월유량계열을 예측하였으며 문
영일 (1997) 은 수문 시계열자료의 비선형 상관관계를 검토하
기 위해서 Mutual Information(MI) 을 이용하였다 . 김형수 등 (1998) 은 DVS(deterministic versus stochastic) 비선형 예 측 알고리즘을 이용하여 미국의 St. Johns 강의 일유량을 예 측한 바 있다 . 안상진과 이재경 (2000) 은 ARIMA 모형을 토 대로 하여 계절별 월 유출량을 모의하였다 . 문영일 (2000) 은 지역가중다항식을 이용하여 수문시계열 예측을 위한 모형을 구성하였고 윤강훈 등 (2004) 은 신경망 모형을 사용하여 댐유 입량 예측모형을 개발하였다 . 또한 권현한과 문영일 (2005) 은
상태공간 모형과 Nearest Neighbor 방법에 근거한 국부선형
회귀모형으로 단기예측 모형을 구성한바 있다 . 외국의 경우
Yakowitz 와 Karlsson(1987), Kember 등 (1993), Abarbanel
등 (1996), Smith(1991) 는 비매개변수적 회귀모형을 이용한
수문시계열의 예측기법을 제안하였다 .
만약 자연계로부터 얻은 수문시계열 자료가 결정론적
(deterministic) 시스템의 신호라면 , 이 신호를 동역학 법칙이 존재하는 시스템으로 간주할 수 있다 . 이 경우 시계열은 확 률 분석 (stochastic analysis) 대신 비선형 분석 (nonlinear
dynamical analysis) 을 통해 시스템에 대한 정보를 얻어야
한다 . 비선형 분석이란 결국 신호의 동역학 특성을 측정함으 로써 계의 상태가 달라지는 것을 정량화하고 , 궁극적으로 계 모델링을 위해 필요한 모든 정보를 끄집어내는데 있다 .
비선형 분석을 위해서는 먼저 위상공간으로의 재구성
(phase space reconstruction) 과정이 필요하다 . Embedding
과정이라고 불리는 이 과정은 스칼라 시계열로부터 다차원
시스템에 대한 정보를 얻기 위해 시간 지연 방법 (delay
coordinate) 을 이용해 다차원 위상 공간 (phase space) 안에 벡터 궤적을 만든 후 궤적들의 동역학적 성질을 조사하는 것이다 . 수학자 Takens(1981) 은 위상 공간의 차원이 충분히 크다면 ( 원래 계가 가지는 차원의 두 배보다 크다면 ), 이때 얻은 궤적들의 다발 , 즉 끌개 (attractor) 가 원래 계와 위상적 으로 등가 (topologically equivalent) 라는 사실을 증명했다 .
수문학에서 Chaos 이론의 응용은 계속 증가하고 있으나 대 부분의 연구가 강우량의 비선형성의 존재 (Hense, 1987;
Rodriguez-Iturbe 등 , 1989) 와 유출량의 비선형성의 존재 여 부 (Jayawardena 와 Lai, 1994) 에 대해 초점을 맞추고 있다 .
이러한 점에서 본 연구는 낮은 차원의 비선형 동역학적 거 동을 보이는 Great Salt Lake Volume 을 대상으로 Vapnik (1995) 이 제안한 비선형 학습 (learning) 예측 모형인 Support Vector Machine(SVM) 의 단기예측 가능성을 검토하였다 .
SVM 은 ‘Universal Feed Forward’ 네트워크의 일종으로
서로 다른 Class 에 속하는 자료들의 Margin 을 최대화하는
초평면 (Hyperplane) 을 구함으로써 최적의 일반화 성능을 지
니는 모델을 구현하는 것이다 . SVM 이론에 따르면 , K-
Nearest 방법과 같은 일반적인 Pattern 인식 기법들이 경험 적인 (empirical) 위험 (risk) 을 최소화하는데 기초한 반면 , SVM 은 구조적인 (structural) 위험을 최소화하는 것에 기초하 고 있다 . 여기서 경험적 위험의 최소화라는 의미는 훈련 자 료의 정확도를 최적화하려는 과정을 의미하며 , 구조적 위험 의 최소화란 미지의 확률분포를 갖는 자료에 대해서 그릇된
Pattern 인식의 확률을 최소화하는 것을 말한다 . SVM 의 장
점은 무엇보다도 훈련을 위한 자료 Vector 에 내재한 정보를 인식하는 능력이 뛰어나다는 점과 상대적으로 낮은 공간의 결정 평면 집단을 사용한다는 것이다 . SVM 이 회귀분석을
위해 이용될 때 신경망 (Neural Network) 방법과 비교해서
SVM 은 크게 3 가지 다른 특징이 있다 . 첫째 , SVM 은 고차 원 상태공간에서 정의되는 선형함수들을 이용하여 회귀방정 식을 추정한다 . 둘째 , SVM 은 e -insensitive Loss 함수를 이 용하여 추정된 위험도를 최소화하도록 함수를 추정하는 것 이다 . 마지막으로 , SVM 은 경험적인 오차와 구조적인 위험도 의 최소화 이론으로부터 유도된 조정항 (term) 으로 구성되는 위험도 (risk) 함수를 이용한다 .
따라서 본 연구의 목적은 SVM 의 장점을 최대한 이용하여 상태 - 공간 모형을 통한 낮은 차원의 수문시계열 예측모형을 구성하고자 하며 이를 위한 연구 진행 절차는 다음과 같다 .
첫째 , 상태 - 공간 모형에 간단한 소개와 둘째 , Support
Vector Machine 에 대한 이론적 배경 및 개념을 검토한 후
마지막으로 Great Salt Lake Volume 에 대한 예측을 실시하 였다 .
2. 상태-공간 모형
수문시계열은 일반적으로 대부분 단변량 (univariate) 의 형식 을 취하고 있으며 따라서 비선형 시계열에서의 예측 방법은 이러한 단변량이 갖는 단점을 보완하고자 먼저 이 시계열들 을 가지고 적절히 상태 ( 위상 )- 공간을 통해서 재구성을 하는 방법론을 취하고 있다 . 재구성된 상태 공간에서 단기간 동안
일련의 상태 공간상의 점들의 군 (group) 을 과거의 전체 시계
열에 대한 상태 - 공간상의 점들의 군 중에서 현재의 시점과 유사한 거동을 갖는 시계열의 군을 찾아 이를 예측에 이용 하는 것이다 .
수문시계열 자료의 비선형 분석에는 다양한 해석학적 방법 이 사용된다 . 그러나 비선형성을 고려하는 해석 방법은 여전 히 난해한 문제로 인식되고 있으며 시계열 예측에서 이러한 비선형성의 특징을 파악하고 해석하는 것은 매우 중요하다 .
그러나 다른 타 분야의 시계열 자료에 비해 수문시계열자료 는 계측상의 어려움과 여러 자연적인 원인으로 양질의 자료 를 구축하기가 쉽지 않아 대부분의 시계열은 단변량의 형태 를 가지고 있다 .
그러므로 한 변량으로부터 다른 변수들의 거동을 유추해 낼 수 있는 기법이 필요하며 이러한 문제는 상태 - 공간 모형 을 구성함으로써 어느 정도 보완이 가능하다 . 상태 - 공간 모
형은 시계열 Embedding 이라고 부르며 이 방법을 이용하여
시계열을 재구성하고 시계열의 거동을 분석할 수 있다
(Takens, 1981; Hilborn, 1994; Sauer 등 , 1991). 상태 - 공간
구성은 일정한 시간지체
τ와 d차원 변수의 벡터로 시계열을 구성할 수 있으며 다음 식 (1) 과 같다 .
x
t= ( x
1, x
t-τ, … , x
(d−1)τ) (1)
여기서 d는 Embedding Dimension 이라고 하며
τ는 지체시 간 (delay time) 으로 정의할 수 있다 . 따라서 d와
τ를 합리적
으로 결정하는 것은 매우 중요한 요소이다 . Embedding
Dimension 을 원자료의 비선형 동역학계의 차원보다 크게 하
면 , 재구성한 벡터 변수 는 본래 동역학계의 특성을 재현할 수 있다 .
3. Support Vector Machine
SVM 은 AT&T Bell 연구소에서 분류 (classification) 의 문제를
해결하기 위한 수단으로 1990 년대에 개발되었다 (Boser 등 ,
1992; Guyon 등 , 1993; Cortes 과 Vapnik, 1995; Schölkopf
등 , 1995). 회귀분석을 위한 SVM 은 Vapnik(1995) 에 의해 서 처음 소개되었으며 여러 분야에서 응용적인 연구가 진행 되었다 (Drucker 등 , 1997; Vapnik 등 , 1997; Müller 등 , 1999; Mattera 과 Haykin, 1999). Müller 등 (1999) 은 Mackey- Glass Delay 미분방정식 (Mackey 와 Glass, 1977) 에 의해서
모의된 Chaotic 시스템을 예측하기 위한 수단으로 SVM 을
이용하였다 . Mattera 과 Haykin(1999) 은 Lorenz 시스템
(Lorenz, 1963) 의 재구성을 위해 SVM 을 이용하였다 . 두 연
구 모두 Chaotic 시스템을 예측하기 위한 방법론으로 SVM
의 우수성을 입증하였다 .
이와 같이 다른 분야에서 활발한 연구와는 다르게 SVM 의
수문학적 응용은 상대적으로 미비하며 Remote 센서 이미지 의 분류 및 강우 - 유출 모의 등을 신경망 모형과 비교하여
SVM 의 우수성을 입증한 바 있다 (Dibike 등 , 2001; Liong
과 Sivapragasam, 2002).
SVM 을 수문시계열 예측에 적용하기에 앞서 본 장에서는
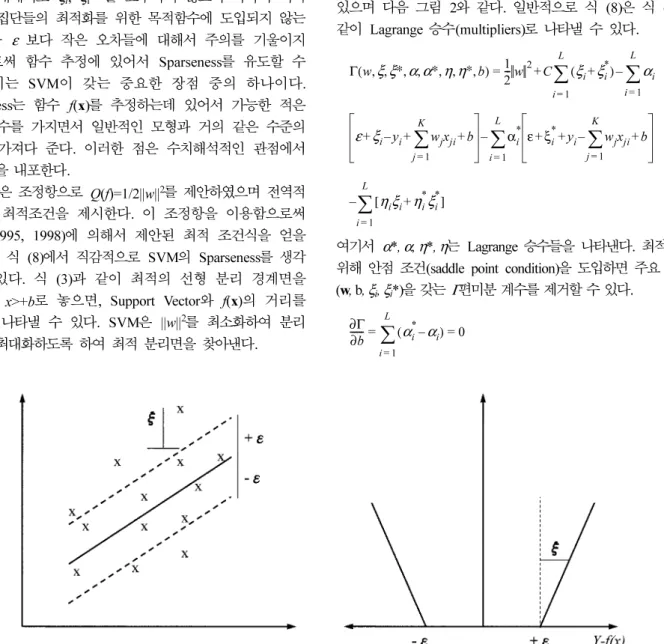
SVM 의 기본적인 이론 및 배경을 간단하게 소개하고자 한다 . SVM 은 기본적으로 분류 (classification) 의 문제를 해결하기 위한 수단으로 응용되었다 . 그림 1 은 간단한 2 개의 Class 를
갖는 자료에 대한 SVM 의 Pattern 인식 개념 즉 , 초평면
(hyperplane) 의 결정 과정을 나타낸다 . 그림 1 과 같이 기하 학적으로 w는 평면 h의 방향을 나타내며 다양한 b 의 변화 는 평면을 움직이는 역할을 한다 . 즉 w와 b 를 적절히 조정 하여 최적의 평면을 찾음으로써 2 개의 Class 를 효과적으로 구분할 수 있다 . 여기서 최적의 경계면이란 그림 1 과 같이
Margin 이 가장 큰 경계면을 찾는 것이다 .
이를 SVM 회귀분석에 응용한다면 , 에서 추출된
입력항 { x
1, x
2,…, x
l} 와 I.I.D(independent and identically distributed) 의 특성을 갖는 L차원의 인 { y
1, y
2, …. y
l}
출력항의 함수적인 의존관계 f ( x ) 를 추정할 수 있다 . 여기서 함수 f ( x ) 의 추정은 다음 위험도 함수를 최소화 하는 문제로 귀결될 수 있다 . 즉 , f ( x ) 는 기하학적으로 다수의 입력벡터와 출력항 중에서 이들 관계를 규정할 수 있는 최적의 회귀함 수를 의미한다 .
(2)
여기서
(3)
SVM 회귀분석에서 b 는 bias 를 w는 Basis 함수를 나타 내며 조정치 (regularized estimation) 의 선택을 위해서 이들 함수가 어떻게 이용되는지 후에 설명할 것이다 . 〈 .,. 〉는
x의 벡터내적 (dot product) 을 의미하며 K는 입력자료의 차
원을 나타낸다 .
Γ( x , y, f ( x )) 는 관측치 y 와 예측치 f ( x ) 와의 차이 즉 , Loss 함수 또는 Discrepancy 함수를 나타낸다 .
만약 우리가 Quadratic Loss 함수 ,
Γ( x , y , f ( x , y ))=( y−f ( x ))
2,
를 이용한다면 다음 식 (4) 는 일반적인 최소자승법 으로 나타내게 된다 . 만약 Loss 함수를
Γ( x , y , f ( x , y ))=| y−f ( x )| 으 로 나타낸다면 이는 Robust 회귀함수를 정의하기 위한 소 위 Least Modulus 방법으로 표현된다 (Huber, 1964). 그러 나 Vapnik (1995) 은 다음과 같은 더욱 일반화된 Loss 함 수를 제안하였다 .
(4)
그러나 조건부확률분포 P ( x ,y) 를 모르기 때문에 식 (2) 의 정확한 해를 계산할 수 없다 . 따라서 경험적인 위험도 함수
(empirical risk function) 의 형태로 다음과 같이 나타낼 수 있다 .
Minimize R [ f ]= (5)
식 (5) 의 경험적 함수를 최소화하는 문제는 Tikhonov와 Arsenin (1977) 에서 제안된 ill-posed 문제 즉 , 해의 발산 및 비수렴 등으로 이어진다 . 그러므로 실제로 이러한 문제는 주 어진 경험적인 위험도 함수 f와 관련된 벌칙함수 Q[ f ] 의 항 으로 조정될 수 있다 . 여기서 벌칙함수는 경험적인 위험도 함수와 벌칙함수의 상호작용 (trade-off) 을 통해 보다 일반화된 해를 제공하기 위함이며 한편으로는 과도한 수의 매개변수
로 인한 Over fitting 등의 문제를 피하고 이를 조정하기 위
한 목적을 갖는다 .
x R ∈
Ky ∈ R
R f [ ] =
∫Γ x y f ( , , ( ) x ) P d ( x , y )
f x ( ) = 〈 w x , 〉 b with + w ∈ X b R , ∈
f ( ) x w
jx
j+ b
j 1=
∑K
=
Γ
( x , , y f ( x , y ) ) y f – ( ) x
ε0 if y f – ( ) x ≤
εy f – ( ) x – otherwise
ε⎩ ⎨
= = ⎧
1 L
--- Γ ( x
i, , y f ( ) x
i)
i 1=
∑L
그림 1. SVM의 최적 분리 경계면 추정 개념
(6)
여기서
λ>0 는 조정매개변수 (regularization parameter) 를 나
타낸다 .
식 (6) 은 다음 식 (7) 과 같은 형태로 다시 나타낼 수 있 다 (Vapnik, 1998; Smola, 1998).
Minimize
Subject to (7)
여기서 C =1/
λ∈R
+를 나타낸다 .
ξi,
ξi* 는
ε보다 큰 오차 를 갖는 표본들에 대해서 주어지는 벌칙의 정도를 결정하는
Slack 변수들을 의미한다 . 다시 말해서 ,
ε보다 작은 어떤
오차에 대해서도
ξi,
ξi* 를 요구하지 않으며 따라서 이러 한 표본집단들의 최적화를 위한 목적함수에 도입되지 않는 다 . 이는
ε보다 작은 오차들에 대해서 주의를 기울이지 않음으로써 함수 추정에 있어서 Sparseness 를 유도할 수 있다 . 이는 SVM 이 갖는 중요한 장점 중의 하나이다 . Sparseness 는 함수 f ( x ) 를 추정하는데 있어서 가능한 적은 수의 계수를 가지면서 일반적인 모형과 거의 같은 수준의 오차를 가져다 준다 . 이러한 점은 수치해석적인 관점에서 큰 장점을 내포한다 .
Vapnik은 조정항으로 Q ( f )=1/2|| w ||
2를 제안하였으며 전역적
(global) 최적조건을 제시한다 . 이 조정항을 이용함으로써
Vapnik (1995, 1998) 에 의해서 제안된 최적 조건식을 얻을 수 있다 . 식 (8) 에서 직감적으로 SVM 의 Sparseness 를 생각 할 수 있다 . 식 (3) 과 같이 최적의 선형 분리 경계면을 f ( x )=< w, x >+ b로 놓으면 , Support Vector 와 f ( x ) 의 거리를
1/|| w || 로 나타낼 수 있다 . SVM 은 || w ||
2를 최소화하여 분리 간격을 최대화하도록 하여 최적 분리면을 찾아낸다 .
Minimize
Subject to (8)
최적해는 Margin( 각 Class 의 support vector 사이의 거리 )
을 가장 크게 하는 것과 오차를 최소화는 것 사이의 상호과 정을 통해 얻어지며 , 이는 정규화 된 매개변수에 의해 조정 된다 . 모든 학습자료가 오류 없이 분류될 수는 없으므로 상 수 C를 통하여 이를 어느 정도 허용할 수 있다 . 이 값이 클 때에는 학습오류를 적게 허용하므로 보다 정확한 함수를 구할 수 있지만 , 너무 클 경우에는 학습자료에 지나치게 편
향되어 과적합 (over fitting) 하게 되므로 적당한 값을 선택하
는 것이 중요하다 .
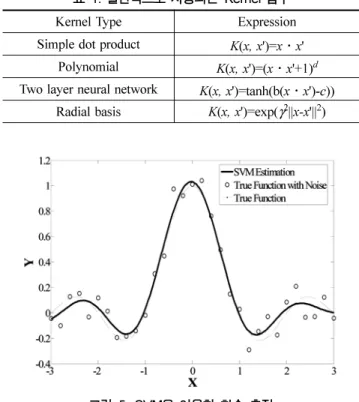
상수 C > 0 는 허용되는
ε보다 큰 오차의 양과 f 사이의
상호작용을 결정하며
ε-insensitive Loss 함수로 나타낼 수 있으며 다음 그림 2 와 같다 . 일반적으로 식 (8) 은 식 (9) 와 같이 Lagrange 승수 (multipliers) 로 나타낼 수 있다 .
(9)
여기서
α* ,
α,
η* ,
η는 Lagrange 승수들을 나타낸다 . 최적화를 위해 안점 조건 (saddle point condition) 을 도입하면 주요 변량
( w, b ,
ξi,
ξi*) 을 갖는
Γ편미분 계수를 제거할 수 있다 .
(10)
R
regf[]
λQ f [ ] 1 L --- y
i– f x ( )
i εi 1=
∑L
+
=
Q f[] C1 L --- (
ξi+
ξi*)
i 1=
∑L
+
y
iw
jx
jii 1=
∑K j 1=
∑K
– b ≤
ε ξ+
i–
w
jx
jii 1=
∑L j 1=
∑K
+ b y –
i≤
ε ξ+
i*ξi
,
ξi*0 ≥
⎩ ⎪
⎪ ⎪
⎪ ⎨
⎪ ⎪
⎪ ⎪
⎧
1 2
--- w
2C (
ξi+
ξi*)
i 1=
∑L
+
y
iw
jx
jii 1=
∑L j 1=
∑K
– b ≤
ε ξ+
i–
w
jx
jii 1=
∑L j 1=
∑K
+ b y –
i≤
ε ξ+
i*ξi
,
ξi*0 ≥
⎩ ⎪
⎪ ⎪
⎪ ⎨
⎪ ⎪
⎪ ⎪
⎧
Γ w ( , , , ,
ξ ξ∗
α α∗ , , ,
η η∗ b ) 1 2 --- w
2C (
ξi+
ξi*)
αii 1=
∑L
–
i 1=
∑L
+
=
ε ξi
– y
iw
jx
ji+ b
j 1=
∑K
+ + α
i*ε ξ
i*y
iw
jx
ji+ b
j 1=
∑K
– + +
i 1=
∑L
–
ηiξi
+
ηi*ξi*[ ]
i 1=
∑L
–
∂Γ ∂b
--- (
αi*–
αi)
i 1=
∑L
0
= =
그림 2. 회귀함수의 최적화를 위한 SVM의 ε-insensitive Loss Function
(10a)
(10b)
여기서 는 단위벡터 (unit vector) 를 나타낸다 .
(11) (12)
식 (10) 에서 (12) 를 식 (9) 에 대입하여 정리하면 á에
관해서 식 (13) 을 최대화 시킴으로써 다음과 같은 이차계
획 (Quadratic Programming) 최적화 식 (13) 을 얻을 수 있다 .
Subject to
(13)
또한 함수의 Bias b 는 Larush-Kuhn-Tucker(KKT) 조건 을 도입함으로써 추정이 가능하며 다음과 같이 표현될 수 있다 (Smola 와 Schölkopf, 1998; Cristianini 와 Shawe- Taylor, 2000). 식 (14b) 를 위한 조건식은 식 (10) 으로부 터 얻어진다 .
(14a)
(14b)
식 (10b) 로부터 , 를 Support Vector 전개라
고 한다 ( Vapnik , 1995), 여기서 w는 훈련자료 (training patterns)
들의 선형 조합으로 나타낼 수 있다 . 다음 제약식 | f ( x
i)- y
i| ≥
ε을 만족하는 Lagrange 승수만이 최적화를 위해 고려되며 ,
즉
ε안에 놓이는 모든 표본에 대해서
αi,
αi*는 제거된다 .
따라서 제거되지 않고 남은 계수들을 갖는 표본들을
Support Vector(SV) 라고 부른다 . 따라서 식 (3) 을 고려하여
다음과 같이 함수 f ( x ) 를 추정할 수 있다 .
(14)
여기서 x
i는 SV 를 나타낸다 . 식 (14) 에서 N은 SV 의 수를 나타내며 일반적으로 입력차원 L에 비해 상대적으로 작은 값 ( N << L)을 갖는다. 이것이 함수 추정에 Sparseness 를 나 타낸다 (Girosi, 1998).
∂ ∂Γ w --- ∂Γ
∂w
j---ζ
jj 1=
∑K
w
jζ
j( α
i*– α
i) x
ijζ
j 1=∑K
= { } 0
i 1=∑L
+
j 1=
∑K
= =
w ( α
i*– α
i) x
i= { } 0
i 1=
∑L
–
=
w ( α
i*– α
i) x
ii 1=
∑L
=
ζ
∂ξ ∂Γ
i--- C = –
αi–
ηi= 0
∂Γ
∂ξ
i*--- C = –
αi*–
ηi*= 0
W (
α*,
α)
ε(
αi+
αi*) y
i(
αi–
αi*) 1 2 ---
j 1=
∑L i 1=
∑L
–
i 1=
∑L
+
i 1=
∑L
–
=
αi–
αi*( ) (
αj–
αj*) 〈 x
i, x
j〉
αi*
–
α( )
i 1=
∑L
= 0 , 0 ≤
αi,
αi*≤ C
αi
(
ε ξi– y
iw
jx
ji+ b)
j 1=
∑K
+ + = 0
αi*
(
ε ξi*y
iw
jx
ji+ b)
j 1=
∑K
+ + + = 0
αi
– C ( )
ξi= 0
αi*
– C ( )
ξi*= 0
w
(αi*–αi)x
ii 1=
∑L
=
f ( ) x (
αi*–
αi) 〈 x x ,
i〉 b +
i 1=
∑N
=
그림 3. Mapping 함수를 이용한 비선형 SVM 의 기본개념
그림 4. 특성 공간 (Feature space) mapping 과정
결국 SVM 회귀분석은 입력항과 출력항의 비선형 함수 관 계를 선형의 조합으로 분류함으로써 가능하며 결국 이러한
문제는 Pattern 분류와 밀접한 관계가 있다 . SVM 에서 비선
형성은 Kernel 함수를 이용하여 훈련자료를 고차원으로 보냄
으로써 고려할 수 있으며 식 (13) 에서와 같이 훈련자료는
항상 표본들의 내적 (inner product) 의 형태로 항상 표현된다 .
따라서 내적항을 적절하게 선택된 Kernel 함수로 대체함으로
써 , 부수적인 매개변수의 증가 없이 고차원의 함수로
Mapping 할 수 있으며 이를 소위 “Kernel Trick” 한다 . 즉
Kernel 함수를 이용하여 입력항과 출력항의 상호관계를 효과
적으로 규명할 수 있다 . 그림 3 은 Mapping 함수를 이용한 비선형 SVM 의 기본 개념도를 나타낸다 . 그림에서 보는 바
와 같이 특정한 Mapping 함수 x
2를 도입함으로써 특성이
다른 두 집단을 효과적으로 구분할 수 있다 .
그림 4 는 특성공간에서의 Mapping 함수를 통한 선형화를
나타낸다 . SVM 알고리즘은 오직 표본들의 내적에만 의존하
기 때문에 다음과 같이 내적을 Kernel 함수로 대체할 수
있다 , . 따라서 입력차원의
비선형성은 특성공간에서 선형적으로 변환된 자료를 이용하 여 용이하게 함수 f ( x ) 를 유도할 수 있다 . 최종적으로 다음
식 (15) 와 형태에 회귀방정식을 유도할 수 있다 .
(15)
여기서 K ( x , x
i) 는 입력자료의 내적을 Kernel 함수로 대체한 것이다 . 여기서 모든 매개변수는 훈련을 통해서 최적화된다 .
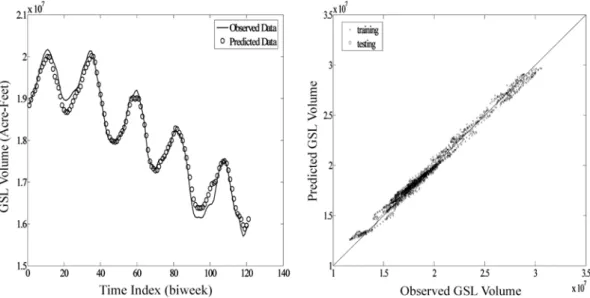
일반적으로 사용되는 주요 Kernel 함수는 다음 표 1 과 같다 .
그림 5 는 SVM 을 이용한 회귀방정식을 추정하는 간단한 예제로서 실제함수 Y =sin(
πx )/
πx에 백색잡음을 추가하여 모 의 발생된 자료를 대상으로 SVM 을 이용하여 추정된 예측함 수를 나타내며 실제함수와 거의 유사한 거동을 보이고 있다 .
4. 수문시계열의 SVM 적용
본 연구에서는 상태공간 모형과 Support Vector Machine
을 결합한 비선형 예측모형을 Great Salt Lake 의 Volume
을 대상으로 예측을 실시하였다 . 분석에 앞서 구성된 모형의 적합성을 평가하기 위해서 다음 표 2 와 같은 지표들을 이용 하였다 . 여기서 y
t는 관측치를 은 예측치를 나타내며 E ( y )
는 평균을 나타낸다 . 평균제곱오차 (Root Mean Square Error,
RMSE) 는 모형의 수행결과가 평균적으로 어느 정도 오차가 발
생하는지를 나타내는 지표로 일종의 평균치라고 할 수 있다 . 모 형효율성계수 (Coefficient of Efficiency) 는 통계적 기준으로서 편 의를 줄일 수 있는 무차원계수이다 . 예측치와 관측치가 일치할 수록 1 에 가까워지는 성질이 있다 . 이 기준은 무차원양으로서 자 료의 개수에 관계없이 절대적 평가기준이 될 수 있다 . 평균오차
(Mean Absolute Error, MAE) 는 예측값과 실제값의 절대 오차 를 평균한 값으로 관측치와 예측치의 차이가 적으면 적을 수록 좋은 예측값을 나타낸다 . 마지막으로 모형효율성계수 E
는 이상치에 민감한 단점이 있으며 이를 보완할 수 있는 일 치계수 (Index of Agreement, IOA) 를 이용하였으며 상대적
으로 극치값에 민감하지 않은 통계치이다 .
4.1 대상 자료
본 연구에서는 미국 Utah 에 위치한 Great Salt Lake
(GSL) 의 Volume 을 대상으로 연구를 진행하였다 . GSL
Volume 은 장기간의 자료일 뿐만 아니라 비선형 특성을 갖는
대표적인 수문시계열 자료로서 비선형 모형의 검증을 위해 많은 연구가 이루어지고 있다 (Sangoyomi, 1993; Lall 과 Mann, 1995; Moon 과 Lall, 1996; Abarbanel 등 , 1996;
Abarbanel 과 Lall, 1996; Lall 등 , 1996; Mann 등 , 1995).
특히 Lall 등 (1996) 은 자기회귀모형과 같은 전통적인 선형
모형은 GSL Volume 의 급격한 증가 및 감소를 반영하지
못함을 증명하였다 . 따라서 본 연구에서는 선형 모형과 비교 없이 SVM 을 이용한 비선형 예측 모형을 토대로 연구를 진 행하였다 .
수문시계열의 비선형예측에 앞서 시계열의 비선형성을 검 토하는 것은 필수적이다 . 그러나 GSL Volume 의 경우 이전 연구에서 시계열의 비선형성을 입증한바 있으며 따라서 본 연구에서는 이들 연구들에서 추정한 Embedding 차원과 지 체시간을 그대로 이용하였다 . 즉 GSL Volume 의 경우
Embedding Dimension 과 지체시간은 이전 연구들에서 다양
x x , ′
〈 〉 ← 〈 Φ ( ) x , Φ ( ) x ′ 〉
=K 〈 x x , ′ 〉
f ( ) x (
αi*–αi)K ( x x ,
i) b
+i 1=
∑N
=
y
ˆi표 1. 일반적으로 사용되는 Kernel 함수
Kernel Type Expression
Simple dot product
K
(x, x
')=x·x
' PolynomialK
(x, x
')=(x·x
'+1)d Two layer neural networkK
(x, x
')=tanh(b(x·x
')-c
))Radial basis
K
(x, x
')=exp(γ
2||x-x
'||2)그림 5. SVM 을 이용한 함수 추정
Table 2. Different efficiency measures used in this study
Statistics Formula
RMSE Mean absolute error Coefficient of efficiency
Index of agreement
Q1=RMSE= n–1Σt 1n= (yt–yˆt)2 Q2=MAE n= –1Σt 1n= (yt–yˆt)
Q3 E 1 Σt 1n= (yt–yˆt)2 Σt 1n= (yˆt–E yˆ( )t)2 --- –
= =
Q4 d 1 Σt 1n= yt–yˆt Σt 1n= yt–E yˆ( )t +yˆt–E yˆ( )t --- –
= =
한 방법론을 통해 각각 5 와 10 을 제시하였다 (Sangoyomi 등 , 1996).
4.2 Great Salt Lake Volume
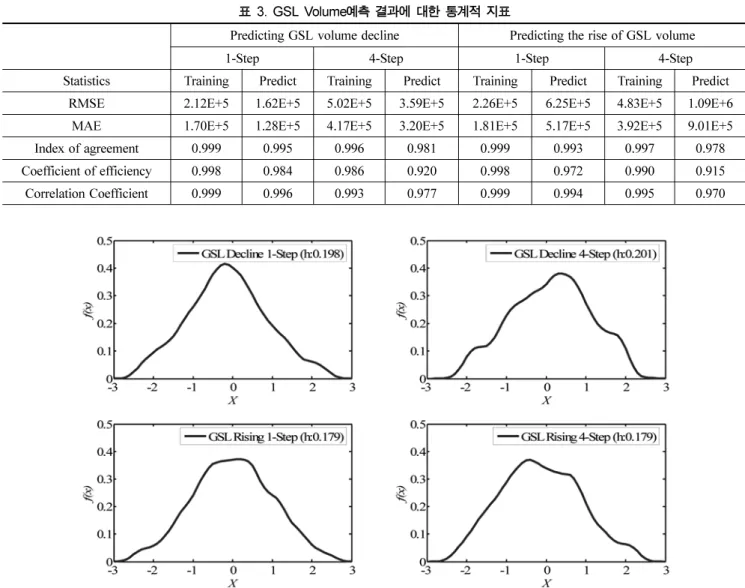
예측
본 연구에서는 상태 - 공간 모형과 SVM 을 이용하여 1925
년부터 1929 년의 급격한 감소구간과 1983 년부터 1987 년까 지의 급격한 증가 구간을 대상으로 예측을 실시하였다 . 기존
연구에서 2 개의 급격한 변화시점을 예측하는데 있어서 선형 모형을 사용할 경우 이들 비선형 특성을 반영하지 못함을 입증한 바 있으며 (Sangoyomi, 1993; Lall 등 , 1996) 따라 서 본 연구에서도 이들 예측시점을 통해 SVM 의 비선형 예 측 특성을 평가하고자 한다 . 그림 6 은 GSL Volume 시계열 을 나타낸다 .
GSL Volume 은 2 주 단위의 자료로 구성되며 예측은 1- Step(2 주 ) 과 4-Step(2 개월 ) 으로 나누어 진행하였으며 1-Step 은 예측 이전시점의 자료를 이용하여 한 단계씩 예측을 하게 된다 . 장기예측 관점에서 4-Step 은 예측 4 단계 이전시점까지
의 자료를 이용하여 예측이 진행된다 . 그림 7-12 은 각각 급
격한 감소 및 증가구간의 1-Step 과 4-Step 예측을 나타낸다 .
본 연구에서는 상태 - 공간 구성을 위한 Embedding
Dimension 과 지체시간은 이전 연구들에서 다양한 방법론을
통해 각각 5 와 10 을 제시하였으므로 이를 이용하였다 .
그림 7 은 급격한 감소구간 예측을 위해 사용된 훈련자료 와 Support Vectors(SV) 들을 나타낸다 . 앞서 언급했지만
그림 6. Great Salt Lake Volume 시계열 및 본 연구에서 선택한 예측시점
그림 7. GSL Volume 의 급격한 감소구간 예측을 위한 훈련결과
및 Support Vectors
그림 8. GSL Volume 의 1-Step 예측 결과 ( 감소구간 )
SVM 을 이용한 예측에 있어서 SV 들은 입력자료와 출력자
료의 관계의 Pattern 을 분류하는데 있어서 매우 중요한 역할
을 하게 되며 가능한 한 적은 수의 SV 로 구성되는 것이 바람직하다 . 즉 , 가능한 한 적은 수의 매개변수를 이용하여 과적합을 방지할 수 있다 .
그림 8-9 는 각각 1-Step 과 4-Step 예측결과를 나타낸다 .
1925 년부터 급격한 감소구간에서는 1-Step 의 경우 예측시작 후 20 과 90 Time Step 에서 상대적으로 오차가 크게 발생하 지만 전체적으로 GSL Volume 의 비선형 특성을 효과적으로 반영하여 실측자료와 거의 동일한 거동을 보여주고 있다 . 4-
Step 의 경우 1-Step 만큼 정확한 예측은 아니지만 장기예측
관점에서 보면 합리적인 결과라 사료된다 .
그림 10 은 GSL Volume 의 급격한 증가구간의 예측을 위
한 훈련결과와 Support Vector 들을 나타낸다 . 따라서 , 이와
같은 훈련과정을 통해 추정된 예측함수를 이용하여 1-Step
예측과 4-Step 예측을 실시하였다 .
그림 11-12 는 각각 1-Step 과 4-Step 예측결과를 나타낸다
1983 년부터 급격한 증가 구간의 경우 1-Step 은 예측시작 후
40, 60 과 70 Time Step 에서 상대적으로 실측치와 차이가 크
지만 GSL Volume 의 비선형 특성을 비교적 정확하게 반영
하는 것으로 판단되며 증가에서 감소구간으로 바뀌는 시점 도 정확히 예측이 이루어지고 있다 . 4-Step 의 경우 1-Step 보 다 왜곡된 결과를 나타내지만 전체적으로 GSL Volume 의 거동을 효과적으로 예측하고 있으며 비교적 장기간의 예측 자료로서 활용이 가능할 것으로 사료된다 .
표 3 는 표 2 에서 제시한 5 가지의 통계적 지표를 토대로 그림 9. GSL Volume 의 4-Step 예측 결과 ( 감소구간 )
그림 10. GSL Volume 의 급격한 증가구간 예측을 위한 훈련결
과 및 Support Vectors
그림 11. GSL Volume 의 1-Step 예측 결과 ( 증가구간 )
추정된 훈련과정과 예측과정의 결과를 나타낸다 . 모형효율성 계수 예측치와 관측치가 일치할수록 1 에 가까워지는 특성이 있으며 모든 경우에서 0.9 이상의 값을 제시하고 있다 . 또한
일치계수 (IOA) 와 상관계수 0.9 이상의 값을 나타내고 있어
예측모형으로서의 단기예측을 위한 모형으로서 타당성을 보 여주고 있다 .
각 예측 결과에 따른 잔차 (residual) 검정을 위해서
Portmanteau Test( Ljung과 Box , 1978) 를 실시하였으며 모든 결과에서 비자기상관성의 가정을 만족하였다 . 마지막으로 핵 밀도함수 (kernel density function) 를 추정하여 그림 13 에 나
타내었다 . 그림 13 과 같이 모든 결과에서 잔차의 정규성을 확인할 수 있다 .
마지막으로 GSL Volume 을 대상으로 이전 연구에서 응용 된 비선형 모형 즉 Multivariate Adaptive Regression
그림 12. GSL Volume 의 4-Step 예측 결과 ( 증가구간 )
표 3. GSL Volume 예측 결과에 대한 통계적 지표
Predicting GSL volume decline Predicting the rise of GSL volume
1-Step 4-Step 1-Step 4-Step
Statistics Training Predict Training Predict Training Predict Training Predict
RMSE 2.12E+5 1.62E+5 5.02E+5 3.59E+5 2.26E+5 6.25E+5 4.83E+5 1.09E+6
MAE 1.70E+5 1.28E+5 4.17E+5 3.20E+5 1.81E+5 5.17E+5 3.92E+5 9.01E+5
Index of agreement 0.999 0.995 0.996 0.981 0.999 0.993 0.997 0.978
Coefficient of efficiency 0.998 0.984 0.986 0.920 0.998 0.972 0.990 0.915
Correlation Coefficient 0.999 0.996 0.993 0.977 0.999 0.994 0.995 0.970
그림 13. 각 예측 결과에 잔차에 대한 핵밀도함수 ( h는 핵밀도함수 추정을 위해 사용된 최적의 광역폭을 의미한다 .)
Splines(MARS; Lall 등 ,1996) 과 대표적인 비선형 모형인
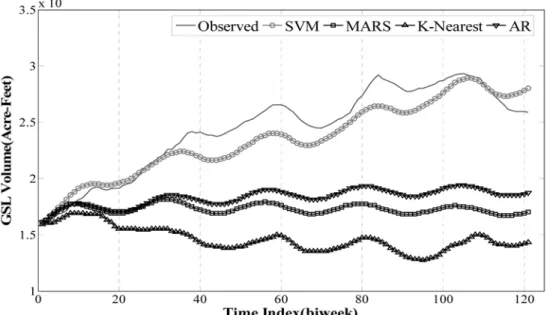
K-Nearest 방법 , 선형모형인 AutoRegressive(AR) 방법을 비 교모형으로 모형의 적합성을 평가하였다 . 4 가지 모형에 대해 서 반복예측 (Iterated Prediction) 을 대상으로 모형의 적합성 을 평가하였다 . 여기서 , 반복예측은 예측시점 이후로 실측자 료를 이용하지 않고 예측된 결과를 다시 예측을 위한 자료 로 반복적으로 사용하는 방법으로 비선형 모형의 적합성을 평가하는데 유용하다 . 예측구간은 급격한 증가경향을 나타내
는 지점을 대상으로 하였다 . 그림 14 는 각각 SVM,
MARS, K-Nearest 와 AR 방법을 통한 반복예측 결과를 나타
낸다 .
그림 14 의 4 가지 모형의 반복예측 결과를 보면 정확히 실 측자료의 거동을 추정하지는 못하지만 SVM 은 예측시점을 기준으로 예측된 이전자료들을 이용하여 GSL Volume 의 증 가경향을 비교적 정확하게 반영하고 있다 . 이에 반해 3 개 모형은 증가경향을 반영하지 못하고 예측시점을 기준으로 수 평적으로 반복하거나 감소하는 결과를 나타내고 있다 . 이들 결과를 바탕으로 판단해보면 SVM 은 기존의 비선형 모형 및 선형 모형에 비해 비선형거동을 나타내는 수문 시계열의 예 측에 있어 다소 유리할 것으로 사료된다 .
5. 결 론
수문학에서 Chaos 이론의 응용은 계속 증가하고 있으나 대 부분의 연구가 수문시계열의 비선형성의 존재 여부에 대해 초점을 맞추고 있다 . 이러한 점에서 본 연구는 낮은 차원의 비선형 동역학적 거동을 갖는 Great Salt Lake Volume 을 대상으로 Vapnik (1995) 이 제안한 비선형 학습 예측 모형인
Support Vector Machine(SVM) 의 단기예측 가능성을 검토
하였다 .
본 연구에서는 상태 - 공간 모형과 SVM 을 이용하여 Great Salt Lake Volume 의 1925 년부터 1929 년의 급격한 감소구
간과 1983 년부터 1987 년까지의 급격한 증가 구간을 대상으
로 예측을 실시하였다 . 1925 년부터 급격한 감소구간에서는
1-Step 의 경우 전체적으로 GSL Volume 의 비선형 특성을
효과적으로 반영하여 실측자료와 거의 동일한 거동을 보여 주고 있다 . 4-Step 의 경우 1-Step 보다 정도는 떨어지지만 모 든 통계적인 지표에서 만족한 결과를 나타내 주고 있다 . 급 격한 증가구간의 경우도 GSL Volume 의 비선형 특성을 비교 적 정확하게 반영하는 것으로 판단되며 증가에서 감소구간으 로 바뀌는 시점도 정확히 예측이 이루어지고 있다 . 이와 함 께 급격한 예측구간에 대해서 MARS, K-Nearest 와 AR 모형 을 비교모형으로 반복예측을 실시하여 비선형 모형으로서 타 당성을 검증하였으며 SVM 이 기존 모형들에 비해 다소 우수 한 결과를 나타내었다 .
SVM 은 서로 다른 Class 에 속하는 데이터들의 Margin 을 최대화하는 초평면 (Hyperplane) 을 구함으로써 최적의 일반화 성능을 지니는 모델을 구현하는 것이 목적이며 이러한 관점 에서 두 가지 예측 예제에서 20 개 내외에 비교적 적은
Support Vector 들을 가지고 비선형 예측함수를 추정할 수
있으므로 기존 학습 모형에서 나타나는 과적합을 방지할 수 있는 장점을 제공하고 있다 . 따라서 비선형 수문시계열의 단 기예측을 위한 모형으로 적용이 가능할 것으로 판단된다 .
참고문헌
김형수, 최시중, 김중훈(1998) DVS 알고리즘을 이용한 일 유량 자료의 예측, 대한토목학회논문집, 대한토목학회, 제18권 제II- 6호, pp. 563-570.
권현한, 문영일(2005) 상태-공간 모형과 Nearest Neighbor 방법 을 통한 수문시계열 예측에 관한 연구, 대한토목학회 논문집, 대한토목학회, 제25권 제4B호, pp. 275-283.
문영일(1997) 시계열 수문자료의 비선형 상관관계. 한국수자원학 회논문집, 한국수자원학회, 제30권, pp. 641-648.
문영일(2000) 지역가중다항식을 이용한 예측모형, 한국수자원학회 논문집, 한국수자원학회, 제33권, pp. 31-38.
박무종, 윤용남(1989) Multiplicative ARIMA 모형에 의한 월유 량의 추계학적 모의 예측, 한국수자원학회논문집, 한국수자원 학회, 제22권, pp. 331-339.
안상진, 이재경(2000) 추계학적 모의발생기법을 이용한 월 유출 예측, 한국수자원학회논문집, 한국수자원학회, 제33권, pp.
그림 14. 급격한 증가구간의 4가지 모형(SVM, MARS, K-Nearest, AR) 반복예측 결과
159-167.
윤강훈
,서봉철
,신현석
(2004)신경망을 이용한 낙동강 유역 홍 수기 댐유입량 예측
,한국수자원학회논문집
,한국수자원학회
,제
37권
, pp. 67-75.Abarbanel, H.D.I. and Lall, U. (1996) Nonlinear dynamics and the Great Salt Lake: system identification and prediction. Climate Dynamics, Vol. 12. pp. 287-297.
Abarbanel, H.D.I., Lall, U., Moon, Y.I, Mann, M., and Sangoyomi, T. (1996) Nonlinear dynamic of the great salt lake: a predict- able indicator of regional climate, Energy, Vol. 21(7/8), pp.
655-665.
Boser, B.E., Guyon, I., and Vapnik, V. (1992) A training algorithm for optimal margin classifiers, Proceedings Fifth ACM Work- shop on Computational Learning Theory, pp. 144-152.
Cortes, C. and Vapnik, V. (1995). Support vector networks.
Machine Learning, 20, pp. 273-297.
Cristianini, N. and Shawe-Taylor, J. (2000) An introduction to sup- port vector machines and other kernel based learning meth- ods. Cambridge University Press.
Dibike, B.Y., Velickov, S., Solomatine, D. and Abbot, B.M. (2001) Model induction with support vector machines: Introduction and applications, J. Computing in Civil Eng., Vol. 15, No. 3, pp. 208-216.
Drucker, H., Burges, C.J.C., Kaufman, L., Smola, A. and Vapnik, V.
(1997) Support vector regression machines. In M. Mozer, M.
Jordan, and T. Petsche, editors, Advances in Neural Informa- tion Processing Systems, Vol. 9, pp. 155-161, Cambridge, MA, MIT Press.
Girosi, F. (1998) An equivalence between sparse approximation and support vector machines, Neural Computation, Vol. 10, No. 6, pp. 1455-1480.
Guyon, I., Boser, B., and Vapnik, V. (1993) Automatic capacity tun- ing of very large VC-dimension classifiers. In Stephen José Hanson, Jack D. Cowan, and C. Lee Giles, editors, Advances in Neural Information Processing Systems, Vol. 5, pp. 147-155.
Morgan Kaufmann, San Mateo, CA.
Hense, A. (1987) On the possible existence of a strange attractor for the southern oscillation. Beitr. Phys. Atmos. Vol. 60, No. 1, pp.
34-47.
Hilborn, R.C. (1994) Chaos and Nonlinear Dynamics, Oxford Uni- versity Press.
Huber, R, (1964) Robust estimation of a location parameter, Annals of Mathematical Statistics, Vol. 35, No. 1, pp. 73-101.
Jayawardena, A.W., and Lai, F. (1994) Analysis and prediction of chaos in rainfall and stream flow time series, J. Hydrol., Vol.
153, pp. 23-52.
Kember, G., Flower, A.C., and Holubeshen, J. (1993) Forecasting river flow using nonlinear dynamics, Sthoch. Hydrol. Hydraul., Vol. 7, pp. 205-212.
Lall, U. and Mann, M.E. (1995) The great salt lake: a barometer of low-frequency climatic variability. Water Resour. Res., Vol. 31, No. 10, pp. 2503-2515.
Lall, U., Sangoyomi, T., and Abarbanel, H.D.I. (1996) nonlinear dynamics of the great salt lake: nonparametric short-term fore- casting. Water Resour. Res., Vol. 32, No. 4, pp. 975-985.
Liong S.Y. and Sivapragasam, C. (2002) flood stage forecasting with SVM, J. AWRA, Vol. 38, No. 1, pp. 173-186.
Lorenz, E.N. (1963) Deterministic nonperiodic flow. J. Atmos. Sci.
Vol. 20
,
130-141.Ljung, G.M and Box, G..E.P. (1978) On a measure of lack of fit in time-series models, Biometrika, Vol. 65. pp. 297-303.
Mackey, M.C. and Glass, L. (1977) Oscillation and chaos in physi- ological control systems. Science, Vol. 197, pp. 287-289.
Mann M.E, Lall, U., and Saltzman, B. (1995) Decadal-to-centen- nial-scale climate variability: Insight into rise and fall of the Great Salt Lake. Geophysical Res. Let., Vol. 22, No. 8, pp. 937- Mattera, D. and Haykin, S. (1999) Support vector machines for940.
dynamic reconstruction of a chaotic system. In B. Schölkopf, C.J.C. Burges, and A.J. Smola, editors, Advances in Kernel Methods: Support Vector Learning, pp. 211-242, Cambridge, MA, MIT Press.
Moon, Y.I. and Lall, U. (1996) Large scale atmospheric indices and the great salt lake: interannual and interdecadal variability, ASCE, J. of Hydrologic Eng., Vol. 1, No. 2, pp. 55-62.
Müller, K.R., Smola, A., Rätsch, G., Schölkopf, B., Kohlmorgen, J., and Vapnik, V. (1999) Predicting time series with support vec- tor machines. In B. Schölkopf, C.J.C. Burges, and A.J. Smola, editors, Advances in Kernel Methods: Support Vector Learn- ing, pp. 243-254, Cambridge, MA, MIT Press.
Rodriguez-Iturbe I., De Power, F.B., Sharifi, M.B., and Georgaka- kos, K.P. (1989) Chaos in rainfall, Water Resour. Res., Vol. 25, No. 7, pp. 1667-1675.
Sangoyomi, T. (1993) Climate variability and dynamics of Great Salt Lake hydrology, PhD dissertation. 247pp., Utah State Univ., Logan.
Sangoyomi, T, Lall, U., and Abarbanel, H.D.I. (1996) Nonlinear dynamics of the Great Salt Lake: Dimension estimation. Water Resour. Res., Vol. 32, No. 1, pp. 149-1599.
Sauer, Y., Yorke, J.A., and Casdagli, M. (1991) Embedology. Jour- nal of Statistical Physics, Vol. 65, pp. 579-616.
Schölkopf, B., Burges, C., and Vapnik, V. (1995) Extracting sup- port data for a given task. In U.M. Fayyad and R. Uthurusamy, editors, Proceedings, First International Conference on Knowl- edge Discovery & Data Mining, Menlo Park, AAAI Press.
Smith, J.A. (1991) Long-range streamflow forecasting using non- parametric regression, Water Resour, Bull., Vol. 27, No. 1, pp.
39-46.
Smola, A.J. (1998) Learning with kernels. Ph.D. thesis. Techni- schen Universitat Berlin, Berlin, Germany.
Smola, A.J. and Scholkopf, B. (1998) A tutorial on support vector regression. NeuroCOLT2 Technical Report Series, NC2-TR- 1998-030.
Takens, F. (1981) Detecting strange attractors in turbulence. In, Rand, D.A. and L.S. Young (eds.). Dynamical systems and Turbulence. Springer-Verlag. Berlin, pp. 366-381.
Tikhonov, A. and Arsenin, V. (1977) Solution of ill-posed prob- lems, Washington, D.C. W.H. Winston.
Vapnik, V. (1995) The nature of statistical learning theory. Springer, New York.
Vapnik, V. (1998) Statistical learning theory. Wiley, New York.
Vapnik, V., Golowich, S., and Smola, A. (1997) Support vector method for function approximation, regression estimation, and signal processing. In M. Mozer, M. Jordan, and T. Petsche, edi- tors, Advances in Neural Information Processing Systems 9, pages 281-287, Cambridge, MA, MIT Press.
Yakowitz, S., and Karlsson, M. (1987) Nearest neighbor methods with application to rainfall/runoff prediction, Stochastic hydrol- ogy, Edited by Macneil, J.B., and Humphries, G.J., D. Reidel, Hingham, MA, pp. 149-160.
(