Prediction on the amount of river water use using support vector machine with time series decomposition
Choi, Seo HyeaㆍKwon, Hyun-HanbㆍPark, Moonhyungc*
aResearcher, Korea Institute of Civil Engineering and Building Technology, Gyeonggi-do, Korea
bProfessor, Department of Civil & Environmental Engineering, Sejong University, Seoul, Korea
cResearcher, Korea Institute of Civil Engineering and Building Technology, Gyeonggi-do, Korea
Paper number: 19-082
Received: 29 October 2019; Revised: 3 December 2019 / 9 December 2019; Accepted: 9 December 2019
Abstract
Recently, as the incidence of climate warming and abnormal climate increases, the forecasting of hydrological factors such as precipitation and river flow is getting more complicated, and the risk of water shortage is also increasing. Therefore, this study aims to develop a model for predicting the amount of water intake in mid-term. To this end, the correlation between water intake and meteorological factors, including temperature and precipitation, was used to select input factors. In addition, the amount of water intake increased with time series and seasonal characteristics were clearly shown. Thus, the preprocessing process was performed using the time series decomposition method, and the support vector machine (SVM) was applied to the residual to develop the river intake prediction model. This model has an error of 4.1% on average, which is higher accuracy than the SVM model without preprocessing.
In particular, this model has an advantage in mid-term prediction for one to two months. It is expected that the water intake forecasting model developed in this study is useful to be applied for water allocation computation in the permission of river water use, water quality management, and drought measurement for sustainable and efficient management of water resources.
Keywords: The amount of water intake, Support vector machine, Time series decomposition, Prediction modeling, Drought
TDSVM을 이용한 하천수 취수량 예측
최서혜aㆍ권현한bㆍ박문형c*
a한국건설기술연구원 국토보전연구본부 신진연구원, b세종대학교 건설환경공학과 응용수문연구실 교수,
c한국건설기술연구원 국토보전연구본부 수석연구원
요 지
최근 기후 온난화의 발생과 이상기후의 발생빈도가 증가함에 따라 강수량, 하천유량과 같은 수문학적 요소의 예측이 복잡해지고 있으며 물부족 발 생 위험도 증가하고 있다. 따라서 본 연구에서는 중단기 하천 취수량을 예측하기 위한 모델을 개발하고자 하였다. 입력인자를 선정하기 위해 취수 량과 기상인자들 간의 상관성분석을 수행한 결과 온도가 가장 영향이 큰 것으로 나타났다. 또한 취수량은 시계열에 따른 증가 경향과 계절적 특성 이 뚜렷하게 나타나므로 시계열분해기법을 이용하여 전처리를 수행하고 잔차에 대해 서포트 벡터 머신(SVM)을 적용하여 취수량 예측 모델을 개 발하였다. 이 모델은 평균적으로 4.1%의 오차율을 나타내며, 전처리를 하지 않은 SVM 모델에 비해 높은 정확도를 나타냈다. 특히, 1∼2달에 대 해 중단기 예측을 수행하였을 때 더 유리한 결과를 나타냈다. 본 연구에서 개발된 취수량 예측모델은 수자원의 지속가능하고 효율적인 관리를 위해 하천수 사용허가, 수질관리, 가뭄 대책 마련에 활용이 가능할 것으로 예상된다.
핵심용어: 취수량, 서포트벡터머신, 시계열분해기법, 예측 모델링, 가뭄
© 2019 Korea Water Resources Association. All rights reserved.
*Corresponding Author. Tel: +82-31-995-0868 E-mail: [email protected] (M. Park)
1. 서 론
최근 지역 간 인구 불균형, 경제 및 기술발전, 삶의 질 향상 등으로 인하여 물사용 패턴이 복잡해짐에 따라 물수요 예측이 어려워지고 있다. 또한 기후변화로 인한 가뭄, 집중호우가 발 생됨에 따라 하천의 생태계를 유지하고 물수요를 감당하기 위해 하천유량과 다양한 목적으로 활용되고 있는 취수량의 예측 및 모의에 대한 중요성이 강조되고 있다. 특히, 우리나라 의 경우 기후변동성 증가로 인한 유황변동성의 증가와 더불어 지역간 인구밀도의 편차가 심화됨에 따라 하천수 취수량의 적절한 배분이 중요해지고 있다. 또한 하천 수량 관리를 위해 Tank 모형을 이용하여 갈수량을 산정하고, 이 기준갈수량에 서 허가량과 유지유량을 뺀 유량을 기준으로 하여 허가 가능 여부를 판단하고 있다(MLTM, 2009). 이는 실제 하천의 상황 을 적절히 반영하지 못하여 가용 유량의 평가 시 과소 및 과대 추정되는 사례가 빈번히 발생하고 있으며, 하천수의 효율적 활용 측면에서 부정적 효과를 얻을 수 있다는 점을 시사하고 있다. 현재는 관측된 하천유량 및 하천수 취수실적 등 실제 측 정된 자료를 활용하여 하천수허가기준이 개선되고 있다. 또 한 수자원장기종합계획(MOLIT, 2016)의 생활용수 수요량 은 상수도 급수지역 수요량, 상수도 미급수지역 수요량 및 기 타 지하수 이용량의 합으로 산정한다.
최근 UN Water, WMO와 같은 국제적인 물 관련 기관에서 는 수자원관리에 있어서 통합관리, 지속가능한 개발, 효율적 인 사용을 강조하고 있다(UN Water, 2015; WMO, 2019). 이 에 따라 해외에서는 실시간 모니터링 기술과 이에 동반되는 실시간 자료들을 이용한 물관리 최적화 관련 연구가 활발하게 진행되고 있다(Barnett et al., 2004; Bolouri-Yazdeli et al., 2014; Meng et al., 2017; Farriansyah et al., 2018; Benitez et al., 2019). Farriansyah et al. (2018)은 통합적인 실시간 저수 지 운영을 위하여 수요 대비 공급률에 대한 지표와 저수율에 대한 지표를 이용하여 물 할당량을 결정하는 도구를 제안하였 다. 또한 Benitez et al. (2019)는 수요 예측을 통해 초기 단계에 서 상수관망 내 누수를 탐지하고 위치를 파악하기 위해 1분단 위의 자료를 이용하여 단기 예측을 수행하였다. 이와 같이 효 율적인 수자원 분배, 효과적인 가뭄 대응을 위해서는 물수요 를 예측하는 것이 필수적이며 물수요를 예측 모델과 관련한 연구가 지속적으로 수행되고 있다(Gato et al., 2007; Bai et al., 2014; Candelieri, 2017). Gato et al. (2007)는 1일 물 사용 량을 예측하기 위해 물 사용량을 기본 사용량과 계절적 사용 량으로 구분한 시계열분해 모델을 개발하였으며, 86%의 정 확도를 나타냈다. 또한 다수의 연구에서 시계열분해기법과
인공신경망 등의 기계학습 모델을 결합하여 사용한 물수요 예측모델을 제안하였다(Bougadis et al., 2005; Kwon et al., 2012; Altunkaynak and Nigussie, 2017). 이와 같이 물 수요를 예측하는 모델에서는 물수요량 뿐만 아니라 기온, 강우량과 같은 수문학적 인자들을 입력인자로 사용하였다(Jain and Ormsbee, 2001; Bougadis et al., 2005; Gato et al., 2007).
본 연구에서는 취수량을 예측하기 위해 시계열 분해 기법 과 서포트 벡터 머신(Support Vector Machine, SVM)을 연계 한 Hybrid 모델을 개발하였다. 또한 취수량 예측 모델에 사 용하기 위한 입력인자를 선정하기 위해 자기상관성(auto- correlation)과 설명변수로서 기온, 습도, 강수량 등 수문기상 학적 인자들 간의 상관성을 검토하였다. 개발된 취수량 예측 모형은 중단기 예측기간에 대한 모델링을 수행하고 평가지표 를 통해 모형의 우수성을 평가하였다. 우리나라의 경우 지속 적으로 용수사용량이 증가추세에 있으며, 가정용수의 취수 량 또한 계절성을 가지는 것으로 알려지고 있다. 따라서, 비정 상성(nonstationary) 요소의 증가 또는 감소경향과 다양한 주 기특성을 가지는 용수사용량의 특징을 효과적으로 고려하기 위한 방안으로서 시계열 분해 기법(decomposition) 기반의 취수량 예측모형을 개발하는 것이 본 연구의 주된 목적이다.
앞서 언급된 비정상성 요소를 제외한 시계열의 잔차(resudial) 를 효과적으로 예측하기 위한 방법으로 기계학습 모형인 SVM기법을 도입하였으며, 이를 통해 잔차 시계열의 비선형 성을 효과적으로 고려할 수 있는 모형으로 확장하였다. 따라 서, 1장에서는 연구배경 및 목적에 대해서 언급하였으며, 2장 에서는 본 연구에서 사용된 자료 및 대상유역에 대해서 요약 정리하였다. 3장에서는 본 연구를 통해 제안된 방법론에 대해 서 서술하였으며 4장에서는 시범유역을 대상으로 모형의 적 합성을 평가하였다. 마지막으로 5장에서는 연구결론 및 향후 연구에 대해서 서술하였다.
2. 자료 및 대상유역
2.1 자료 및 유역
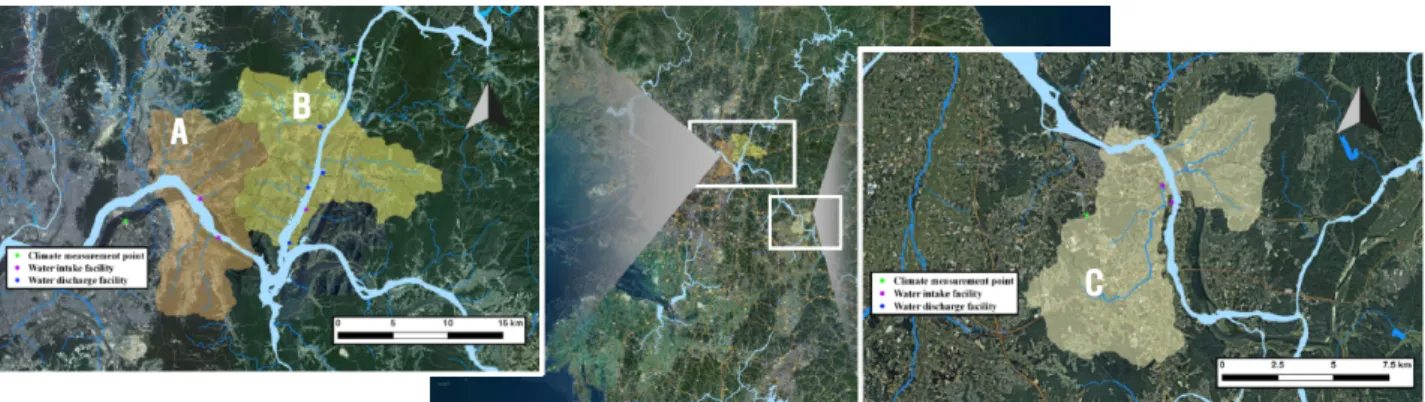
본 연구에서는 취수량 예측모델 구축 및 적용을 위한 유역 을 선정하기 위해 자료 확보 가능성, 자료 신뢰도, 용수목적을 기준으로 검토하였다. 즉, 신뢰도 높은 자료를 확보하기 위해 전자유량계를 통해 일(daily) 취수량이 측정되는 생활용수 시 설을 우선적으로 고려하였으며, 이에 따라 표준유역인 팔당 댐하류(유역A), 북한강하류(유역B), 여주수위표(유역C)를
A B
C
Fig. 1. Test bed for applying water use model Table 1. Data information used to train and test of modeling for each facility
Basin From To Number of
training data
Number of test
data Ave. SD Skew. Kurt. CV
I-1 A 2002.1 2017.12 4745 1095 756232 56059 0.11 2.69 0.07
I-2 B 2002.1 2017.12 4745 1095 2922 936 -0.16 2.25 0.32
I-3 C 2002.1 2017.12 4745 1095 32653 5301 -0.38 2.93 0.16
I-4 A 2009,1 2017.12 2190 1095 13196 1293 -0.19 3.07 0.10
대상유역으로 선정하였다(Fig. 1). 대상유역 내 하천수 취수 량은 홍수통제소에서 확보하였으며, 공공하·폐수장의 하천 방류량은 환경부에서 매년 공개하는 전국오염원조사 자료를 사용하였다. 또한, 온도, 강수량, 상대습도와 같은 기후관련 자료는 방재기상관측장비(AWS)의 기상관측자료를 취득하 였으며, 취수시설들과 가장 인접한 관측소의 데이터를 사용 하였다. 취수시설의 경우 각 시설별로 취수 허가기간에 따라 최소 9년에서 최대 16년 자료를 확보하였으며, 방류시설의 경 우 모든 시설의 2012년~2017년의 6년간의 자료를 확보하였 다. 모델링에 활용된 취수시설별 자료 정보를 Table 1에 정리 하였다. 모델링 수행 대상인 4개의 생활용수 취수 시설물에 대한 시계열 자료의 특성을 검토하기 위해 평균(ave.), 표준편 차(SD), 왜도(skew.), 첨도(kurt.), 변동계수(CV)를 산정하였 다. 평균과 표준편차는 시설규모에 따라 다양하게 나타나며, 표준편차에서 평균값을 나눈 변동계수는 일반적으로 0.1~0.3의 값을 갖는다. 이는 타 용도의 취수량과 비교했을 때 변동성 측면에서 상대적으로 안정적인 것으로 판단할 수 있 다. 또한 왜도는 –0.4∼0.2의 값을 나타내며, 첨도는 2.0∼3.0 의 값을 나타내므로 정규분포에 근접한 것으로 판단된다.
3. 모델링 방법
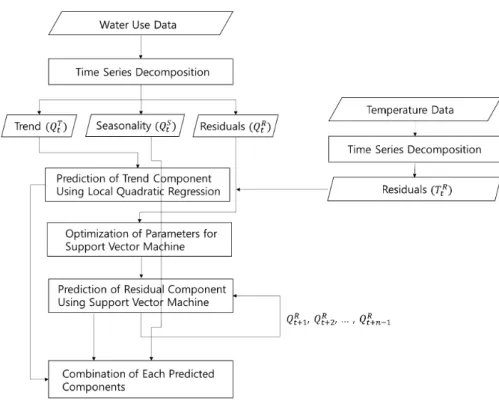
본 연구에서는 시설별 하천수 취수량을 예측하는데 있어 서 시계열 분해 기법을 적용한 SVM 모델을 사용하였다. 모델 에 필요한 입력인자를 선정하기 위해 편자기상관함수(Partial Auto-Correlation Function, PACF), 상관성 분석을 이용하였 으며, 1일, 2일 과거자료와 온도를 입력인자로 결정하였다. 영 향인자 분석에 대한 자세한 설명은 4.1절에 제시하였다. 이 인 자들을 활용한 취수량 예측 모델링 순서는 Fig. 2에 도식화하 였다. 우선적으로, 시계열분해기법을 이용하여 취수량자료 와 온도자료에 대해 전처리를 수행하였다. 둘째, 경향성분 ()을 예측하기 위해 학습데이터 중 가장 최근의 부분 자료 들을 이용하여 도출된 2차회귀식을 이용하였다. 셋째, 주기성 분()을 예측하기 위해 학습 데이터에 대해 시계열분해기법 을 통해 추출된 365일에 대한 주기성분 값을 그대로 적용한다.
넷째, 잔차()를 예측하기 위해서는 과거 취수량의 잔차와 온도의 잔차()를 사용하는데 이들의 비선형적 관계를 반 영하기 위해 SVM 모형을 사용하였다. 마지막으로, 경향성 분, 주기성분, 잔차성분에 대해서 각각 예측을 수행한 값들을 결합한다. 모델링에 주로 사용된 기법인 시계열분해 모형과 SVM모형에 대해서는 아래에 자세히 설명하고자 한다.
Fig. 2. Flowchart of TDSVM to predict the amount of water use during n days
Fig. 3. Flowchart of TDSVM to predict the amount of water use during n days
3.1 시계열 분해 모형
시계열자료는 경향성(Trend), 주기(Seasonality), 잔차 (Residuals) 성분으로 구분할 수 있다(Eq. 1). 경향성분은 Fig.
4(a)의 검은 실선과 같이 시계열의 지속적인 증가 또는 감소추 세를 나타내며, 주기성분은 Fig. 4(b)의 검은 실선과 같이 시계 열자료에서 주기적으로 반복되는 경향을 의미한다. 잔차는 Fig. 4(c)와 같이 불규칙한 변동성분을 의미하며 경향성과 주 기성은 일정한 패턴이 있는 성분으로서 시계열 예측성 개선에 활용이 용이하다. 즉, 시계열분해는 비정상성을 갖는 증가성 분과 일정한 주기를 갖는 계절성분을 복잡한 시계열로부터
분리하여 보다 명시적으로 고려하기 위함이다. 시계열 분해 는 크게 가법분해모형(additive decomposition model)과 승 법분해모형(multiplicative decomposition model)으로 분류 할 수 있으며, 가법분해모형은 성분간에 합(+)으로 관계되어 있는 경우이고 주기변동이 시간에 의존하지 않고 주기의 폭이 일정한 경우 사용한다. 승법분해모형은 성분간에 곱(×)으로 관계되어 있는 경우이며, 주기변동이 시간에 따라 증가 또는 감소하는 추세를 보여 주기의 폭이 일정하게 변하는 경우 사 용한다. 생활용수와 관계된 취수량 및 방류량 자료의 경우 뚜 렷한 계절성을 나타내며 주기의 진폭이 일정하므로 가법분해 모형을 사용하였다.
(1)
여기서, 는 시계열 자료, 는 경향 성분, 는 주기 성분,
은 잔차 성분 이다.
국내외의 다양한 연구에서 시계열 분해 모형을 이용해서 수요량 예측을 수행하였다(Gato et al., 2007; Choi et al., 2009;
Sohn et al., 2016; Altunkaynak and Nigssie, 2017). 시계열분 해기법은 산정방법이 정형화되어 있지 않고 목적에 따라 적절 한 방식을 선택할 수 있다. 본 연구에서는 LOESS(Local
(a)
(b)
(c)
Fig. 4. Result of Time series decomposition method for water use of facility I-2: (a) trend, (b) seasonal, and (c) residuals
Regression)을 이용하여 경향성분을 추출하였다. LOESS는 회귀범위(span)에 따라서 달라질 수 있는데 본 연구에서는 Fig. 3과 같이 계절성분의 진폭이 최대가 되는 3년을 회귀범위 로 선택하였다. 이로 인해 계산상의 효율성 개선을 위해서 계 절성을 충분히 설명하면서 회귀분석 범위가 가장 짧도록 유도 할 수 있었다. 이와 같은 부분회귀분석 결과는 Fig. 4(a)에 검은 실선으로 나타내었다. 다음으로, 주기성분을 고려하기 위하 여 Fig. 4(b)의 회색 실선과 같이 경향성분을 제거한 시계열 값에 대해 일별 평균값을 추출하여 Fig. 4(b)의 검은 실선과 같은 주기성분을 산정하였다. 최종적으로 본래의 시계열 값 에서 경향성과 주기성를 제외하여 Fig. 4(c)의 잔차성분을 도 출할 수 있다.
3.2 서포트 벡터 머신(SVM) 모형
SVM은 가장 널리 활용되는 지도학습(supervised learning) 기법 중 하나이다(Boser et al., 1992; Cortes and Vapnik, 1995; Goodfellow et al., 2016). 이 모델은 선형함수에 의해 구동된다는 점에서 로지스틱 회귀와 유사하다. SVM와 관련 된 한 가지 중요한 점은 커널 트릭(kernel trick)을 사용하는 것이다(Kwon et al., 2012). 커널 트릭은 많은 기계학습 알고 리즘들이 표본들 간의 내적(inner product)항으로만 표현될 수 있도록 한다. 예를 들면, SVM에서 사용되는 선형 함수는 다음과 같이 표현될 수 있다.
⊤
⊤ (2)여기서, 는 학습(training) 표본, 는 가중치, 는 계수의 벡 터, 는 상수이다. 이 방법으로 학습 알고리즘을 다시 작성하 면 를 주어진 특성함수 의 출력으로 교체하고 내적을 핵함수(kernel function) ∙ 로 대체 할 수 있다. Dot(•) 연산자는 ⊤와 유사한 내적을 나타낸다. 즉, 내적을 핵함수를 통해 추정하는 것으로서 다음 과 같이 나타낼 수 있다. SVM의 자세한 이론적 배경은 Goodfellow et al. (2016)에 제시되어 있다.
(3)핵함수는 를 모든 입력인자에 적용한 다음에 새로운 변형된 공간에서 선형모델을 학습시키는 방식으로 자료를 전 처리하는 것과 동일하다. 비선형성적 관계를 가지는 독립변 수와 종속변수를 선형적인 문제로 해석하기 위한 목적으로 도입된다. 즉, SVM은 입력데이터를 고차원 특성공간으로 사 상시키고(mapping), 학습 데이터를 최적으로 분리하기 위해 반복적으로 최대 여백을 갖는 초평면(hyper-plane)을 탐색하 는 과정을 수행한다. 유효한 학습 데이터를 Support Vectors (SVs)라고 하며 초평면함수는 이 SVs의 결합으로 표현된다.
(a)
(b)
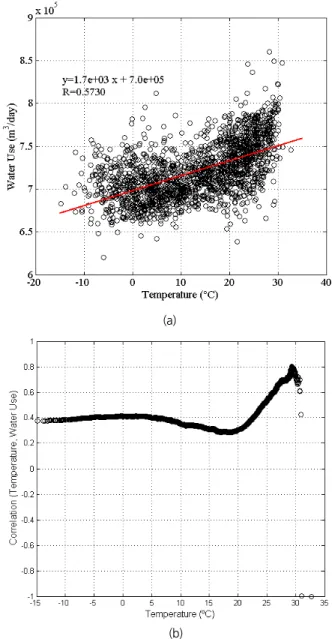
Fig. 5. Influence analysis on temperature for a facility I-1: (a) relation between temperature and water use, and (b) variation in the correlation of temperature and water use with the decrease of the temperature
SVM의 성능은 커널함수에 따라 크게 달라질 수 있음에도 불구하고, 데이터에 따라 적합한 커널 함수를 선택하는 방법 에 대한 이론이 존재하지 않는다는 적용상의 한계점이 있다 (Amari and Wu, 1999; Byun and Lee, 2002). 따라서, 자료의 특성에 따라 적절한 커널함수를 선정하기 위해 매개변수를 탐색하는 과정을 거쳐야 한다. 이와 같이, 예측 모형으로서 SVM을 사용하는데 있어서 매개변수 추정은 매우 중요하다.
여기서 주의해야할 부분은 학습데이터에 편향적으로 적합 도가 높은 매개변수를 설정하는 것인데, 이를 과적합(over- fitting)이라고 한다. 즉, 기 사용된 학습데이터에 대해서 성능 은 향상되나 새로운 데이터에 대해서는 성능이 감소할 수 있 다. 따라서 본 연구에서는 이러한 문제를 해결하기 위해 교차 검증(cross-validation, CV) 방법으로 10-Fold CV 기법을 사 용하였다. 이는 무작위로 자료(x, y)를 10개의 세트로 나누고 하나를 평가(validation)자료로 활용하고 나머지를 학습 자료 로 이용하는 방식으로서, 모델링을 수행한 후 평균 오차값을 활용하여 해당 매개변수에 대한 모델의 성능을 평가한다.
3.3 평가 지표
본 연구에서는 모델의 정량적인 평가를 위해 통계적 지표 인 평균절대오차(Mean Absolute Error, MAE), 일치도(Index of Agreement, IoA)를 사용하였다. 또한 SVM 모델의 매개변 수 선정에 있어서 MAE 값을 기반으로 하였다. IoA 지표는 0
∼1 사이의 값을 가지며 1에 가까울수록 관측값과 일치함을 나타내며 일반적으로 0.8 이상이 권고된다(De Jager, 1994;
Barioni et al., 2014). MAE는 Eq. (4)와 같이 관측값과 예측값 의 편차의 절대값 평균으로 값이 적을수록 예측 성능이 높은 것을 나타내며, 이를 관측값의 평균으로 나눈값은 0.2 이하가 권고된다(De Jager, 1994; Barioni et al., 2014). IoA은 다음 Eq. (5)과 같이 정의된다.
(4)
(5)
여기서, 는 관측값, 은 예측값을 나타낸다. 본 연구에서 는 MAE 지표를 기준으로 SVM 모델링에 사용되는 매개변수 를 선정하였으며, IoA 지표를 기준으로 모델의 신뢰도를 평가 하였다.
4. 결 과
4.1 영향인자 검토
수요 예측을 위한 모델 구성에 있어서 입력변수 선정은 취 수량 예측의 정확도 향상에 있어서 중요하다. 물수요는 강수 량, 온도, 습도, 증발량 등의 수문학적 및 기상학적 변수뿐만 아니라 인구수, GDP와 같은 사회·경제적 요소들을 고려할 수 있으며, 일반적으로 자료의 자기상관성과 함께 온도, 강수량 과 같은 기상학적 변수가 고려된다(Jain and Ormsbee, 2001;
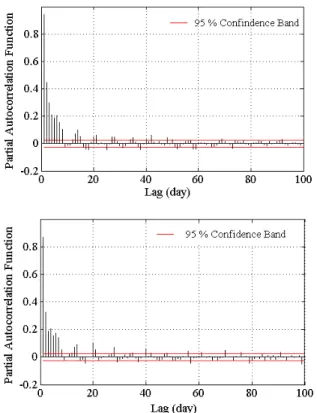
Fig. 6. PACF results according to the lag time: (a) Facility I-1, and (b) Facility I-2
Table 2. Structures of the input factors for the models applied in this study
Input structure SVM
TDSVM
*where, Q: daily water use, T: daily average temperature, super- script, T: trend, superscript, S: seasonality, superscript, R: residuals Nigssie, 2017). 모델의 입력인자를 선정하기 위해 온도(),
체감온도(), 강수량()을 검토하였다. 입력인자들과 취 수량 및 시계열 분해의 각 성분들과 상관성을 검토한 결과, 온 도의 경우 취수량과의 상관계수가 시설별로 0.2~0.6의 양의 상관관계를 나타내며, 이는 온도가 증가할수록 물 사용량이 증가하는 경향이 있다는 것을 의미한다. Fig. 5(a)의 그림에서 온도와 취수량의 분포를 살펴보면 15도 이하에서는 온도의 영향이 거의 없다가 그 이상의 높은 온도에서 취수량이 선형 적으로 증가하는 것으로 나타났다. 또한 Fig. 5(b)와 같이 정량 적으로 온도에 따른 취수량의 민감도를 검토했을 때도 마찬가 지 결과를 나타냈다. 즉, 온도에 따른 취수량과 온도의 상관성 의 변화를 살펴보면, 23도 이상의 높은 온도에서 상관성이 0.6~0.8로 나타나 취수량이 온도에 더 민감하게 반응한다는 것을 알 수 있으며, 그보다 온도가 낮을 땐 상관성이 0.4로 일정 하게 나타났다. 이는 기존연구과 다른 결과를 보였는데, 김화 수 등(2008)은 기온에 따른 가정용수의 사용 경향을 살펴보았 을 때 –14℃~0℃까지 물 사용량이 급격하게 증가하는 경향 을 보였으나 0℃이상에서는 큰 변화양상을 보이지 않았음을 제시하였다. 이는 대상지역의 주거형태, 기반시설 등에 따라
상된다. 또한 온도와 습도를 결합한 지표인 체감온도를 이용 했을 때 온도의 상관성과 거의 유사한 반면, 강수량은 생활용 수의 취수량과의 상관계수가 0∼0.1로 나타나 전반적으로 예 측인자로서 영향은 제한적이라 할 수 있다. 추가적으로, 1일 전 과거자료뿐만 아니라 지체시간(1, 2, …, 30일)을 고려하여 온도, 강수량과의 지체상관성을 분석하여 보았으나 지체시 간이 길어질수록 상관성이 낮아졌다.
취수량은 온도, 생활패턴 등에 따라 자기상관성이 높을 것 으로 판단되어 입력인자로서 과거자료를 사용하였다. Fig. 6 과 같이 입력인자로 사용될 과거자료의 시점을 결정하기 위해 자기상관분석을 수행하였다. 특히 편자기상관함수는 모든 시설에서 1일전부터 8일 전 자료가 영향을 미치는 것으로 나 타났으며, 실제 모델링 수행 시 2일전까지 고려하였을 때는 뚜렷한 증가추세를 보이다가 수렴하는 경향이 있었다. 2일전 과거자료를 적용하였을 때 잔차의 상관계수가 0.04∼0.16 향 상되었으며, 모델의 정확도는 1∼11%까지 증가하였다. 이에 따라 잔차를 추정하는데 있어서 AR(2) 모델을 사용하였다.
4.2 취수량 모델 검증
기존에 수행된 다양한 수문 예측 모형관련 연구들에서 경 향과 계절적 변동을 제거하기 위해 시계열분해기법이 사용되 었다(Khorasani et al, 2016; Altunkaynak and Nigussie, 2017). 본 연구에서는 널리 사용되는 기계학습 기법 중 하나인 SVM 모형과 시계열 분해 기법을 결합한 TDSVM 모형을 개 발하였으며, 모델의 정확도를 평가하고 시계열분해기법을 적용하였을 때의 효과를 검토하고자 한다. 본 연구에서 사용 된 SVM을 단독으로 고려한 모형과 TDSVM 모형의 구조를 Table 2에 제시하였다. 본 연구에서는 N일후 취수량을 예측 하기 위해 앞서 상관성분석과 편자기상관분석을 이용한 영향 인자 분석 결과를 기반으로 모델의 입력인자로서 과거 취수량 값과 온도를 사용하였다. 즉, 개발된 모형은 입력인자로서 편 자기상관분석 결과에 기반하여 1일전, 2일전 취수량 과거자 료와 상관성분석 결과에 기반하여 온도를 입력인자로서 사용
Table 3. Comparison of accuracies for training data and testing data for each facility
Lead
time Facility
Training Forecasting
MAE (%) IoA MAE (%) IoA
SVM TDSVM SVM TDSVM SVM TDSVM SVM TDSVM
1day
I-1 2.53 2.53 0.9109 0.9337 2.81 2.56 0.9198 0.9350
I-2 6.34 5.96 0.9631 0.9733 5.81 5.30 0.8072 0.8297
I-3 5.95 4.70 0.9324 0.9425 5.31 4.19 0.7723 0.8360
I-4 5.15 4.32 0.8564 0.8612 4.43 4.35 0.8507 0.8273
Table 4. Comparison of accuracies for training data and testing data for the extended lead time
Lead
time Facility
Training Forecasting
MAE (%) IoA MAE (%) IoA
SVM TDSVM SVM TDSVM SVM TDSVM SVM TDSVM
1month
I-1 4.13 3.60 0.7926 0.9007 4.60 3.71 0.6890 0.8521
I-2 10.43 8.94 0.9278 0.9595 8.84 6.57 0.5699 0.8309
I-3 7.51 5.95 0.8533 0.9379 6.71 4.75 0.5548 0.7317
I-4 6.14 5.83 0.6756 0.8550 6.41 5.34 0.5482 0.8000
2month
I-1 4.53 3.60 0.7151 0.9003 5.24 3.71 0.4651 0.8513
I-2 11.93 8.94 0.9008 0.9594 10.36 6.57 0.3399 0.8303
I-3 7.83 5.95 0.8328 0.9379 7.55 4.75 0.4068 0.7294
I-4 6.82 5.83 0.4806 0.8550 6.87 5.34 0.3096 0.8000
하였다. 또한 모델링의 시간적 효율성을 고려하여 향후 N일 의 기간에 대한 예측을 수행하기 위해서 예측된 1일전 값들을 반복적으로 입력인자로 사용하는 방식을 선택했다(Fig. 2).
모든 시설에 대해 최근 3년간의 일자료를 평가자료로 사용 하였으며, 나머지는 학습자료로 활용하였다. SVM 모델과 TDSVM 모델을 이용하여 각 취수시설을 모델링한 결과를 MAE, IoA 평가지표에 대해 Table 3에 나타냈다. 모든 시설에 대해 IoA값은 0.8 이상으로 나타나므로 생활용수 취수량 예 측에 적절한 모델인 것으로 평가되었다. 시계열분해기법으 로 전처리했을 때 일치도(IoA)가 평균적으로 0.857로 나타나 며 SVM모델에 비해 일반적으로 0.03 정도 증가한다. MAE 값의 경우 시설별로 규모가 크게 달라 비교가 어려우므로 관 측값의 평균으로 나누는 방식으로 표준화하여 검토하였다.
즉, 평균 사용량 대비 오차율을 나타내며 작을수록 좋은 모델 임을 의미한다. 평균적으로 SVM만을 단독으로 사용했을 때 오차율은 4.6%이며, TDSVM 모델의 오차율은 4.1%로 약간 개선됨을 확인하였다. 시설별로 검토했을 때 단독 SVM 모형 에 비해 I-4가 1.7%로 가장 작게 개선되었으며, I-3 시설에서 26.7%로 가장 크게 향상되었다. 이처럼 시계열분해기법을 사용함으로써 유의미한 개선의 정도를 보이는 원인을 추정해
보기 위해 시설별로 시계열 자료를 정성적으로 검토하였다.
I-4시설의 취수량 시계열은 증가 또는 감소추세가 거의 없었 으며, I-2시설(Fig. 4(a) 검은 실선)과 I-3시설의 취수량 시계 열은 증가하는 경향이 있었다. 특히 I-3시설의 경우 경향 성분 이 증가하다가 일정해지는 시계열분포를 가지는데, 이때 SVM 단독모형의 경우 일반적인 학습 데이터와 다르게 최근 발생된 변화를 적절히 반영하지 못할 가능성이 있다. 즉, SVM 단독모형은 시간에 대한 고려가 없기 때문에 학습 자료에 대 해 일반적인 관계를 도출하여 최근 발생된 변화를 반영함에 있어서 취약하다는 문제점이 있었다. 반면, TDSVM 모형의 경우 중·단기 예측 시 자기상관을 이용하는 모형에서 취약한 부분인 인구증가, 도시개발 등의 기타원인으로 인한 장기적 인 변화를 입력변수를 증가시키지 않고도 간단히 부분2차회 귀식을 통해 보완할 수 있다는 장점이 있다.
4.3 중단기 예측
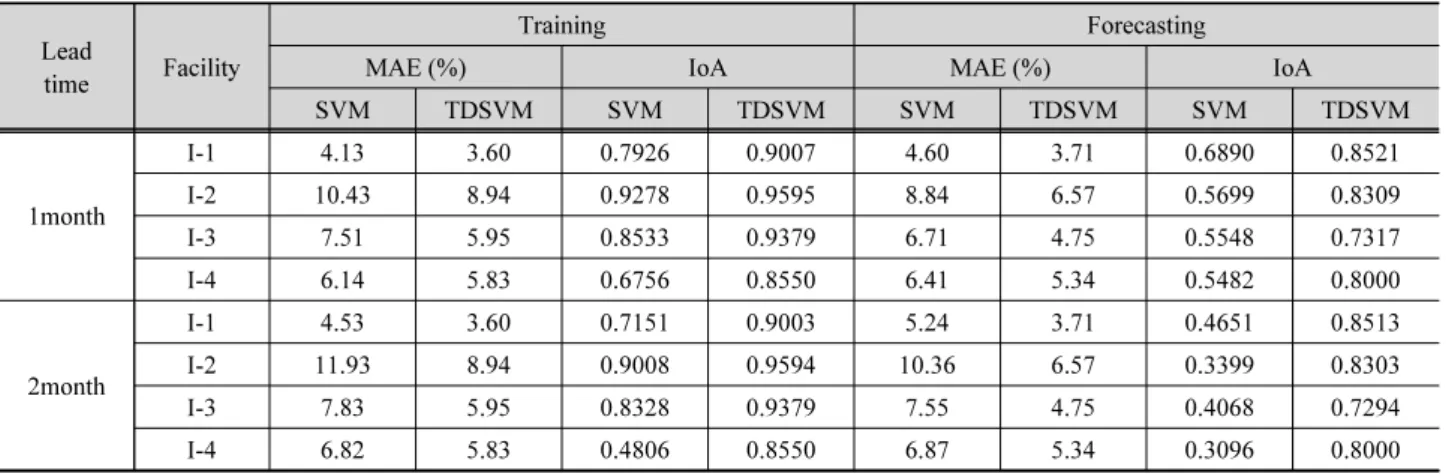
앞에서 검증된 두개의 모델을 이용하여 예측기간(lead time)을 1일에서 1달, 2달로 변경시켜가며 중단기 예측의 가 능성을 검토하고자 하였다. 따라서 예측기간 1, 2달에 대해 마 찬가지로 검증을 수행하고 결과를 Table 4에 제시하였다. 중
(a) I-1 Facility (b) I-2 Facility Fig. 7. Variation in an accuracy of the water use models (lead time: 1 day ∼ 2 Month)
Fig. 8. Result of Fast Fourier transform for time series of water use for facility of I-2
단기 예측 시 SVM 단독모형은 정확도가 크게 감소하였으며, TDSVM 모형은 일반적으로 IoA 0.8 이상, MAE 20% 이하로 취수량 중단기 예측에 적절한 것으로 나타났다.
표준화된 MAE 지표를 이용하여 예측기간에 따른 모델의 정확도 변화를 살펴보면, Fig. 7과 같이 두 시설에서 TDSVM 모델의 정확도가 더 높게 나타났다. 또한 SVM 단독 모델은 시설 I-1의 경우 1일 예측 시 2.8%의 오차율로 TDSVM 모델 과 비슷한 결과를 보였으며, 예측기간이 증가할수록 오차율 도 증가하여 한 달 예측 시 4.6%, 두 달 예측 시 5.2%까지 나타 났다. 마찬가지로 시설 I-2에서도 예측기간이 증가할수록 오 차율도 증가하며 두 달 예측 시 10.4%로 다소 크게 발생하였 다. 반면, TDSVM 모델을 활용했을 때는 두 시설 모두 예측기 간의 증가에 따라 한 달 예측 오차율이 각각 3.7%, 6.6%로 증
가했으며 일정하게 수렴하는 경향을 나타냈다. 이는 시계열 분해기법의 특성상 내재되어 있는 장기적인 주기특성을 고려 한 이유로 판단되며 시계열분해기법과 연계한 SVM 모형이 중단기 예측에 유리함을 알 수 있다.
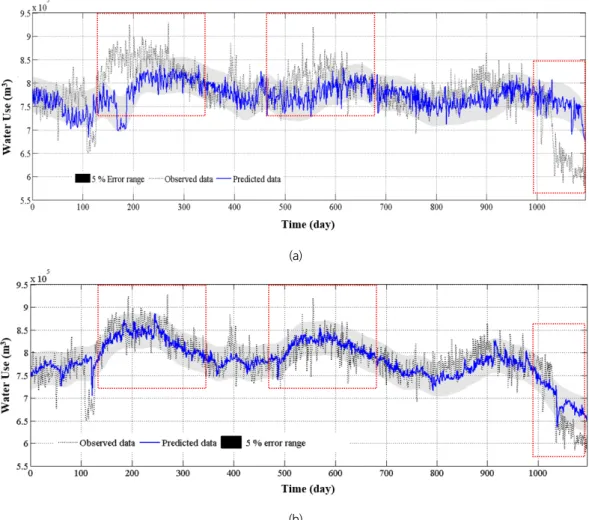
최근 3년에 대해 2달 단위로 예측한 결과를 Fig. 9에 제시하 였다. 시계열분해를 통해 전처리를 한 TDSVM 모델의 경우 대체로 취수량의 변화 경향을 추적하는데 유리하며 평년과 달리 다소 물의 수요가 높은 시기에 상대적으로 예측성이 크 게 나타났다. 관측 값에서 예측 값을 제거한 값에 대해 FFT(Fast Fourier Transform) 분석을 수행한 결과 시설별로 1.5년, 0.6년, 일주일 등의 다양한 주기성이 나타났다(Fig. 8).
이는 생활용수는 사용 특성상 넓은 지역에 걸쳐 여러 이용자 에게 다양한 목적으로 공급되기 때문에 다양한 주기를 가진 시계열이 중첩되기 때문인 것으로 보인다. 따라서 시계열 분 해 시 1년 주기 외에 시설에 따라 다양한 주기성을 고려한다면 정확도의 개선이 가능할 것이다. 두 모델 모두 극치를 예측하 기에는 적합하지 않았음에도 불구하고 전처리를 적용한 모델 의 경우 취수량 평균치의 ±5%의 오차범위 내에서 예측이 가 능한 것으로 나타났다. SVM모델만 사용된 경우 Fig. 9에서 빨간 점선으로 표시된 부분과 같이 매년 반복되는 일반적인 경향을 벗어나서 다소 높거나 낮게 취수량이 발생하는 경우에 오히려 변화에 대한 민감도가 비교적 낮은 것으로 보인다. 이 는 입력인자로 사용되는 2달전 취수량의 값의 영향이 높기 때 문인 것으로 보인다. 따라서 시계열 분해기법을 통해 장기적 인 변화를 반영하는 경향성분과 반복되는 온도, 생활패턴을 반영하는 주기성을 제거한 잔차를 모델링하는 방식이 중단기 취수량 예측에 적합한 것으로 판단된다.
(a)
(b)
Fig. 9. An example of results for prediction of the water use using models based on SVM (lead time: 2 month): (a) SVM model, (b) TDSVM hybrid model
5. 결 론
본 연구에서는 수자원의 통합관리와 효율적이고 공정한 이용을 위해 하천에서 취수되는 수량을 예측하기 위한 모델을 구축하고 정확도를 평가하고자 하였다. 강수량, 하천유량과 같은 물순환 시스템 내의 수자원 예측에 관한 연구에 비해 취 수장 및 하·폐수장에 의한 물이용과 같은 인위적인 수자원의 이동량에 대한 중요도는 간과되어왔다. 그러나 최근 국제적 인 물관리 추세가 지속적이고 효율적인 수자원 관리가 강조됨 에 따라 인위적인 물이동량을 정확하게 파악하는 것이 중요하 다. 따라서, 상대적으로 기기로 계측되고 있는 시설이 많은 생 활용수 취수실적을 이용하여 두 개의 표준유역 내 시설들을 대상으로 예측을 수행하였다.
취수량 모델을 개발하기 위해 일반적으로 입력인자로서 과거 취수량값을 선정하기 위해 PACF 분석을 수행하였으며
그 결과 일주일까지 유의미한 영향을 미치는 것으로 나타났 다. 그러나 모델링의 경제성을 고려하여 가장 뚜렷하게 상관 도가 높게 나타난 1일전과 2일전 취수량 값만을 모델링에 사 용하였다. 또한 강수량, 온도, 습도와 같은 기상학적 인자들을 취수량과 상관성 분석하였으며 이들 중 유의미한 상관성을 나타낸 온도를 취수량 과거자료와 함께 입력인자로서 고려하 였다. 취수량은 온도에 따라 민감도가 달라지는 경향을 보였 으며, 상온에서 취수량과의 상관성이 더 높게 나타났다. 이러 한 선형관계의 변화를 반영하기 위해 기계학습 방법의 일종인 Support Vector Machine(SVM)을 이용하였다. 또한 취수량 은 시계열적 특성이 비교적 뚜렷한 특성을 가지므로 시계열분 해기법을 이용하여 전처리하는 방안을 고려하였다. 이와 마 찬가지로 입력인자인 온도도 시계열 분해한 잔차 값을 사용하 였다. Table 1에서 언급한 시설들에 대해 최근 3년 자료에 대 해 평가를 수행한 결과, 취수량의 1일 예측은 평균적으로
5.09%의 오차율을 나타내고, 2달 동안을 예측했을 때는 5.09%로 수렴하는 경향을 나타냈다. 따라서 본 연구에서 개 발한 TDSVM 모델은 중단기 취수량을 예측하는데 적합한 것 으로 판단된다. SVM 단독모형을 적용했을 때는 초기에는 4.6%로 비슷한 오차율을 나타내지만 예측기간이 길어질수 록 오차율이 급격하게 증가하였다. 이는 일반적으로 취수량 에 증가 추세가 존재하는데 SVM만을 사용했을 때는 과거자 료에 대한 의존도가 높아 예측기간이 증가할수록 최근 변화경 향에 따라 예측을 수행하기에 불리하였다. 이러한 장기적인 경향을 결정하는 인자를 정의할 수 있다면 더 정확한 예측이 가능하겠지만, 시계열분해기법을 이용하는 것이 시계열적 특성이 분명한 중단기 모델링의 경제성 측면에서 상당히 유리 한 결과를 나타낼 것으로 보인다.
물수요를 예측하고 현재 수자원 유수 및 저수 현황을 파악 한다면 중단기 수자원 관리에 있어서 상황을 파악하고 가뭄 시 대안을 마련하는데 기여할 수 있을 것이다. 또한 실시간 모 니터링 기술과 결합하여 누수의 원인과 양을 파악할 수 있고, 가용한 수자원을 현실적이고 효율적으로 분배 및 관리가 가능 해짐으로 인해 인간의 생활과 생태계에 긍정적인 영향을 미칠 뿐만 아니라 에너지 절약과 경제성을 확보할 수 있을 것이다.
감사의 글
본 연구는 국토교통부/국토교통과학기술진흥원의 지원 으로 수행되었음(과제번호: 19AWMP-C140010-02).
References
Altunkaynak, A., and Nigussie, T.A. (2017). “Monthly water consumption prediction using season algorithm and wavelet transform-based models.” Journal of Water Resources Planning and Management, Vol. 143, No. 6, pp. 04017011-1-04017011-10.
Amari, S., and Wu, S. (1999). “Improving support vector machine classifiers by modifying kernel functions.” In Proceedings of International Conference on Neural Networks, Vol. 12, No. 6, pp. 783-789.
Bai, Y., Wang, P., Li, C., and Xie, J. (2014). “Dynamic forecast of daily urban water consumption using a variable-structure support vector regression model.” Journal of Water Resources Planning and Management, Vol. 14, No. 3, pp. 04014058.
Barioni, L.G., Bellocchi, G., Touhami, H.B., Conant, R., Chang, J., Coltri, P.P., Hassen, A., Martin, R., Silvestri, S., Sicerly, J.,
data comparison and improved model parameterisaion. INRA, France, p. 59 (hal-01611412).
Barnett, M., Lee, T., Jentgen, L., Conrad, S., Kidder, H., Wools- chlager, J., and Groff, C. (2004). “Real-time automation of water supply and distribution for the city of Jacksonville, Florida.” USA. EICA, Vol. 9, No. 3, pp. 15-29.
Benitez, R., Ortiz-Caraballo, C., Preciado, J.C., Conejero, J.M., Figueroa, F.S., and Rubio-Largo, A. (2019). “A short-term data based water consumption prediction approach.” Energies, Vol. 12. No. 12, pp. 2359.
Bolouri-Yazdeli, Y., Haddad, O.B., Fallah-Mehdipour, E., and Mariño, M.A. (2014). “Evaluation of real-time operation rules in reservoir systems operation.” Water resources management, Vol. 28, No. 3, pp. 715-729.
Boser, B.E., Guyon, I.M., and Vapnik, V.N. (1992). “A training algorithm for optimal margin classifiers.” In COLT '92:
Proceeding of the fifth annual workshop on Computational learning theory, ACM, New York, NY, USA, pp. 144-152.
Bougadis, J., Adamowski, K., and Diduch, R. (2005). “Short-term municipal water demand forecasting.” Hydrological Processes:
An International Journal, Vol. 19, No. 1, pp. 137-148.
Byun, H., and Lee, S.W. (2002). “Applications of support vector machines for pattern recognition: a survey.” International Workshop on Support Vector Machines. Springer, pp. 213-236.
Candelieri, A. (2017). “Clustering and support vector regression for water demand forecasting and anomaly detection.” Water, Vol. 9, No. 3, p. 224.
Choi, B.S., Kang, H.C., Lee, K.Y., and Han, S.T. (2009). “A development of time-series model for city gas demand forecasting.” Korean Journal of Applied Statistics, Vol. 22, No. 5, pp. 1019-1032.
Cortes, C., and Vapnik, V. (1995). Support vector networks. Machine Learning, Vol. 20, pp. 273-297.
De Jager, J.M., (1994). “Accuracy of vegetation evaporation ratio formulae for estimating final wheat yield.” Water SA, Vol. 20, pp. 307-314.
Farriansyah, A., Juwono, P., Suhartanto, E., and Dermawan, V.
(2018). “Water allocation computation model for river and multi-reservoir system with sustainability-efficiency-equity criteria.” Water, Vol. 10, No. 11, pp. 1537.
Gato, S., Jayasuriya, N., and Roberts, P. (2007). “Forecasting residential water demand: case study.” Journal of Water Resources Planning and Management, Vol. 133, No. 4, pp. 309-319.
Goodfellow, I., Bengio, Y., and Courville, A. (2016). “Deep learning.”
MIT press.
Jain, A., and Ormsbee, L.E. (2001). “A decision support system for drought characterization and management.” Civil Engineering Systems, Vol. 18, No. 2, pp. 105-140.
Khorasani, M., Ehteshami, M., Ghadimi, H., and Salari, M. (2016).
“Simulation and analysis of temporal changes of groundwater depth using time series modeling.” Model. Earth Syst. Environ., Vol. 2, No. 2, p. 90.
Kim, H., Lee, D., Park, N., and Jung, K. (2008). “Analysis on statistical characteristics of household water end-uses.” Journal of the Korean Society of Civil Engineers, Vol. 28, No. 5, pp.
603-614.
Kwon, H., Kim, M., and Kim, W. (2012). “A development of water demand forecasting model based on Wavelet transform and Support vector machine.” Journal of Korea Water Resources Association, Vol. 45, No. 11, pp. 1187-1199.
Meng, F., Fu, G., and Butler, D. (2017). “Cost-effective river water quality management using integrated real-time control tech- nology.” Environmental science & technology, Vol. 51, No.
17, pp. 9876-9886.
MLTM (2009). Manual for the Permit-to-Use of River Water.
MOLIT (2016). Water Vision (2001~2020).
Sohn, H., Jung, S., and Kim, S. (2016). “A study on electricity demand forecasting based on time series clustering in smart grid.” The Korean Journal of Applied Statistics, Vol. 29, No. 1, pp. 193- 203.
UN Water (2015). “The united nations world water development report 2015, water for a sustainable world.” UNESCO, Paris, France.
WMO (2019). “2018 Annual Report, WMO for the Twenty-first Century.” WMO, Switzerland.