1. INTRODUCTION
In recent years, Advanced Driver Assistance System (ADAS) has been an important issue for enhancing driver's safety and comfort in automo- bile industry. Especially, according to Department of Transportation National Highway Traffic Safety Administration in United States [1], tens of thou- sands of drivers and pedestrians have passed away on the roads in each year. This fact brings huge interests in ADAS and autonomous vehicles to help drivers to escape collision with other vehicles.
Especially, detecting vehicles in an image is one of the most important and fundamental technology
of ADAS. Conventionally, they were based on di- verse sensors including active sensors (Radars, Lidars) and passive sensors (RGB cameras). Since camera sensing system is smaller, cheaper, and of higher quality than non-visible sensors, vehicle detections based on monocular vision or stereo vi- sion were popularly explored by many researchers.
However, in practice, the monocular vision based systems have poor performance since they are sensitive to lighting conditions or cluttered back- grounds. In this case, conventional vehicle de- tection methods cannot guarantee reliable solutions.
In case of bad visibility at night, the far-infrared (FIR) sensor is beneficial to solve these problems
Multi-spectral Vehicle Detection based on Convolutional Neural Network
Sungil Choi†, Seungryong Kim††, Kihong Park†††, Kwanghoon Sohn††††
ABSTRACT
This paper presents a unified framework for joint Convolutional Neural Network (CNN) based vehicle detection by leveraging multi-spectral image pairs. With the observation that under challenging environments such as night vision and limited light source, vehicle detection in a single color image can be more tractable by using additional far-infrared (FIR) image, we design joint CNN architecture for both RGB and FIR image pairs. We assume that a score map from joint CNN applied to overall image can be considered as confidence of vehicle existence. To deal with various scale ratios of vehicle candidates, multi-scale images are first generated scaling an image according to possible scale ratio of vehicles. The vehicle candidates are then detected on local maximal on each score maps. The generation of overlapped candidates is prevented with non-maximal suppression on multi-scale score maps. The experimental results show that our framework have superior performance than conventional methods with a joint framework of multi-spectral image pairs reducing false positive generated by conventional vehicle detection framework using only single color image.
Key words: Vehicle Detection, Convolutional Neural Network, Multi-spectral Imaging
※ Corresponding Author : Kwanghoon Sohn, Address:
C129, The 3rd Engineering Building, Yonsei University, 50 Yonsei-ro, Seodaemun-Gu, Seoul 120-749, Korea, TEL : +82-2-2123-2879, FAX : +82-2-2123-7712, E-mail : [email protected]
Receipt date : May 26, 2016, Revision date : June 3, 2016 Approval date : Nov. 21, 2016
†Dept. of Electrical and Electronic Engineering, Yonsei University (E-mail : [email protected])
††††Dept. of Electrical and Electronic Engineering, Yonsei University (E-mail : [email protected])
††††Dept. of Electrical and Electronic Engineering, Yonsei University (E-mail : [email protected])
††††Dept. of Electrical and Electronic Engineering, Yonsei University
※ This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIP) (NRF-2013R1A2A2A01068338)
because it captures long-wavelength infrared which is called thermal band and does not rely on the illumination of the scene [2]. Furthermore, the market price of FIR sensors have kept decreasing these years [3], thus FIR sensors have been effec- tive alternatives to color cameras for detecting ve- hicles and pedestrians [4]. Therefore, some re- searches tried to use both color and FIR images from regular traffic scenes in urban environment in order to detect pedestrians [5, 6]. However, it is not an easy task to leverage multi-spectral im- ages in vehicle detection.
Based on these insights, we propose a vehicle detection algorithm for multi-spectral image pairs based on joint convolutional neural network (CNN).
The joint CNN is trained to extract features which have more discriminative power by jointly using color and FIR images. Our approach is based on assumption that score map from joint CNN can be considered as vehicle candidate hypothesis. In the case of detecting vehicles with various size and ra- tio, multi-scale color and thermal images are used as the input for joint CNN. With non-maximal suppression on these score maps, bounding boxes for vehicle are detected.
The paper is organized as follows. In Section 2, we briefly review vehicle detection methods based on monocular vision in color image and sensor fusion. The proposed vehicle detection algorithm with detailed explanation is described in Section 3.
Section 4 shows evaluation results of our algorithm for challenging scenarios, demonstrating its supe- rior performance using multi-spectral sensors.
Lastly, we conclude the paper with future work in Section 5.
2. RELATED WORK
2.1 Hand-crafted feature based detection For many years, learning-based vehicle de- tection algorithms have been studied widely. Basi- cally researchers trained the classifiers to learn the
characteristics of vehicle patterns on the training dataset. Supervised learning approach such as support vector machine (SVM) [7] and AdaBoost [8] on the set of positive images (vehicle) and neg- ative images (non-vehicle) were applied in this learning-based detectors. In order to produce the reliable vehicle detectors, one of the most im- portant part is building a discriminative feature.
Various feature extraction methods are proposed to enhance detection performance, such as histo- gram of oriented gradients (HOG) [9], Haar-like [10], and Gabor feature [11]. These feature ex- traction methods are essential to learning based detection system [12,13]. Especially, deformable parts based models (DPM) apply a sliding window approach for detection extracts HOG features, fol- lowed by a Latent SVM [14]. With these results, it estimates bounding box prediction and non- maximal suppression. DPM made a breakthrough performance in detection by aggregating local templates of each vehicle part. With study of trying to acquire more discriminative features than be- fore, detectors based on aggregated channel fea- tures (ACF) [15] get more accurate detection re- sults with more augmented channels such as LUV channels, a channel of gradient magnitude, and 6 channels from simplified version of HOG.
2.2 Detection in multi-spectral images
The methods we explained above are using only color images, which have some problems for ve- hicle detection such as bad visibility at night. To overcome this problem, multi-spectral ACF [5] has been proposed to utilize the information from a thermal sensor which is useful for detecting pedes- trians and vehicles extracting discriminative fea- tures adding conventional ACF features in color image to thermal intensity and HOG features in thermal image.
2.3 Convolutional neural network (CNN) based detection
Recently, with the success of convolutional neu- ral network (CNN) in image classification in ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [16], many researchers tried to apply CNN structures for object detection task. R-CNN [17] extracts features from CNN in each region proposal and apply SVM to score each proposal.
With SVM scores of proposals, R-CNN adjusts the bounding boxes by a linear model and eliminates overlapped bounding boxes by applying non-max- imal suppression.
3. PROPOSED METHOD
3.1 Problem statement and overview
Given both RGB image and FIR image, our goal is to detect all vehicles under challenging con- ditions including day and even night circumstances.
Specifically, the expected output of our detection algorithm is bounding boxes for ve- hicles, where th bounding box is denoted by
. Components of stands for coordinate of top-left corner (), width and height of bounding box. To solve the problem, our approach learn the joint convolutional neural network (CNN) defined for multi-spectral image pairs . Utilizing the joint CNN, which takes multi-scale input images
generated by down-scaling the width and height of multi-spectral image pairs with specific ratio
, we predict vehicle score functions
indicating existence of vehicle by utilizing the net- work output . With non-maximal sup- pression on , we predict bounding box candidates of vehicles.
3.2 Joint convolutional neural network for vehicle classification
In this section, we formulate CNN architecture to estimate a vehicle existence. Before we explain full CNN architecture which takes both RGB and FIR input images, we explain the
simple CNN architecture only for RGB image.
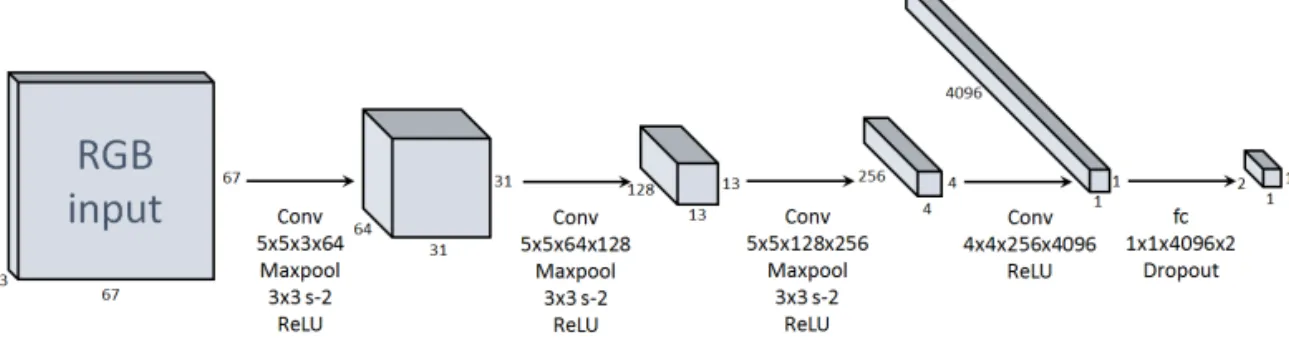
As presented in Fig. 1, it takes a 67×67×3 RGB im- age as an input. Because it has fixed input size, vehicle crops which can be considered positive im- ages are resized to 67×67×3 for training. The weights of each convolution layer is initialized us- ing Xavier initialization method [18] for variance of signal to remain the same while going through all layers. All convolutional layers have stride 1 which guarantees accuracy of the network. Our approach tried to estimate existence of vehicle, thus the output of the architecture is 1×1×2 label vector, , each of which indicates the con- fidence of vehicle or not. We use a softmax loss function as shown in equation (1) because our classification CNN is a binary classifier.
log
log∑ (1)
where is the class labels which represents vehicle ( ) or not ( ). The output of the network
Fig. 1. Classification CNN for RGB image.
only for RGB can be denoted by where
represents the network and is all weights in the network. The existence of vehicle is recog- nized by the investigating score function defined by ranging form 0 to 1. The details of implementation for training the network will be explained in Section 3.4.
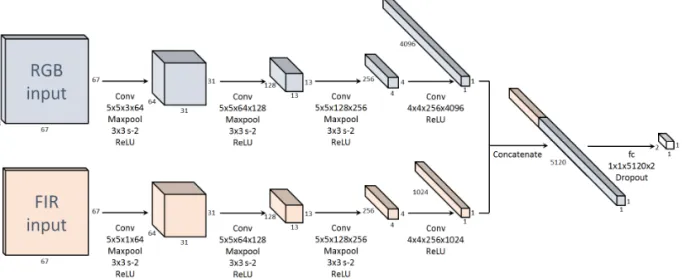
We designed the network for FIR images almost same as CNNs for RGB images. The only differ- ence is that the depth of 4th layer's output is 1024.
We set the dimension of features from FIR image smaller than that of RGB since FIR image has smaller information than RGB image. Since the ve- hicle detection rate can be improved using sensor fusion [19], we build a joint CNN where inputs are both RGB and FIR images. In order to increase the recognition performance, the joint network is de- signed as shown in Fig. 2. Fully connected layers are removed at each CNN and discriminative fea- tures from the 4th layer of each network (as known as CNN features) are concatenated. A new fully connected layer of filter size 1x1x5120x2 are added after the concatenated features. The final output of the joint network is denoted by where
represents the joint network and is all weights of the joint network. As it is shown that CNN features have excellent performance on rec-
ognition, classification and even detections [17, 20]
and combining features from different images in- crease the detection performance [5], the con- catenated features have more discriminative power since recognition performance improves according to increase of feature dimensions. The joint CNN definitely increases the vehicle recognition per- formance better than CNN with input of only RGB images.
3.3 Extension of joint CNN for vehicle classi- fication to detection
Many sliding-window searches extract a hand- crafted feature for each window which is inefficient and time-consuming because windows are overlapped. Unlike this, our method is based on the intuition that CNN features can avoid this in- efficiency in sliding-window search because CNN naturally shares feature computations common to overlapping regions [4]. When applying our classi- fication network to full images larger than size of 67×67 in sliding window search, fully connected layers are substituted by 1×1 convolutional layers [21]. In this way, the output can be generated and it is not non-spatial (1×1) due to larger size than the defined input size of the network. In addition, the score function
Fig. 2. Joint Classification CNN for multi-spectral image pairs.
, defined by softmax function of , is spatial and each pixel of this score map indicates the score of vehicle existence. It should be noted that our network yields spatial output size of 2×2 when the input image has 75x75 size while it outputs non-spatial output (1×1) when the input image has 67×67 size. Therefore, our network be- haves like a sliding-window search with window size 67×67 and stride 8 for both x and y directions.
As the output of the network denoted by is spa- tial, the score function becomes a spatial score map, each pixel of which indicates confidence of vehicle existence in each searching window.
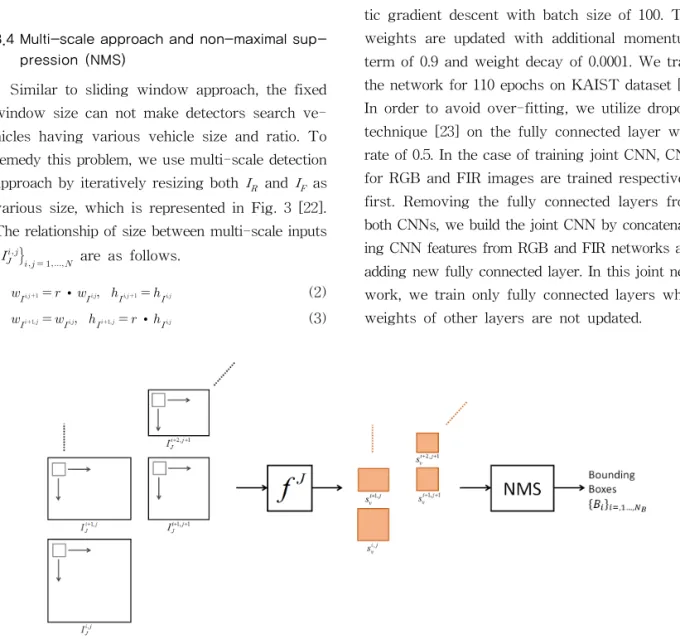
3.4 Multi-scale approach and non-maximal sup- pression (NMS)
Similar to sliding window approach, the fixed window size can not make detectors search ve- hicles having various vehicle size and ratio. To remedy this problem, we use multi-scale detection approach by iteratively resizing both and as various size, which is represented in Fig. 3 [22].
The relationship of size between multi-scale inputs
are as follows.
· (2)
· (3)
where , denote width and height of multi- scale image respectively, and is the down- scaling ratio.
The scores maps, denoted by
, are generated from the joint network which takes multi-scale inputs. Finally, we can obtain the bounding box candidates after non- maximal suppression (NMS) on the score map
.
3.5 Implementation details
The classification CNN was trained by stochas- tic gradient descent with batch size of 100. The weights are updated with additional momentum term of 0.9 and weight decay of 0.0001. We train the network for 110 epochs on KAIST dataset [5].
In order to avoid over-fitting, we utilize dropout technique [23] on the fully connected layer with rate of 0.5. In the case of training joint CNN, CNN for RGB and FIR images are trained respectively first. Removing the fully connected layers from both CNNs, we build the joint CNN by concatenat- ing CNN features from RGB and FIR networks and adding new fully connected layer. In this joint net- work, we train only fully connected layers while weights of other layers are not updated.
Fig. 3. The detection framework.
For selecting training images from the dataset, positive images are vehicle crops from the training dataset, and negative images are randomly sam- pled patches from the training dataset. After first training of CNN, it may contain many false positives. In order to solve this problem, hard ex- amples (false positives) generated by running the network on the training dataset are added to neg- ative images. With iteratively re-training using this augmented training images, vehicle recog- nition performance gets improved.
4. EXPERIMENTAL RESULTS
4.1 Experimental setting
In the experiments, the proposed method was implemented with fixed parameters such that down-scaling ratio and the number of down-scaling=10 for both height and width. We trained our network using MatConvNet library [24]
on the training set from KAIST benchmark [5].
Since it only has annotations for pedestrians, we labeled ground truth for vehicles using Piotr's Computer Vision Toolbox [25]. We set the dataset consisting of 455 training images and 405 test im- ages from KAIST benchmark [5]. We include both training and test dataset have lots of difficult cases such as small scales and occluded. In the case of occluded vehicles, the ground truth box includes occluded parts. For training classification CNN, positive images sampled referring to bounding box annotations for vehicles, while negative images are gained by randomly cropping training dataset.
4.2 Evaluation on KAIST benchmark [5]
We evaluated our algorithm with the use of only RGB, with joint use of RGB+FIR, and aggregated channel features (ACF) detector [15] which utilize more augmented channels such as LUV channels, a channel of gradient magnitude, and 6 channels from simplified version of HOG features when de- tecting objects in color images on the test images
from KAIST benchmark [5]. Bounding box candi- dates as an output of each algorithm are regarded as true with a criteria that the intersection-over- union (IOU) is more than 0.5. Aggregating the de- tection results form test images, precision-recall (PR) curve are plotted in Fig. 4 and mean Average Precision(mAP) are recorded in Table 1. In table 1, mAPs of above methods are low since there are difficult cases to detect vehicles such as occluded vehicles and vehicles of small scales. In Fig. 4 and Table 1, it is represented that proposed method trained on multi-spectral image pairs shows more accurate detection than the method trained on only RGB images. In Fig. 4, ACF detector could not de- tect most of vehicles since it utilizes fixed ratio sliding window approach while vehicles have vari- ous scale and ratios. In addition hand-crafted fea- tures are not learned to detect vehicles make the ACF detector fail to distinguish vehicles from background. Our method trained for RGB images detect more vehicles than ACF detector because
Fig. 4. Precision and recall curve of our methods in KAIST dataset [5].
Table 1. run time and mean Average Precision of our algorithm and ACF detector [15].
ACF [15] Ours
(RGB) Ours
(RGB+FIR)
run time 0.2s 2.2s 2.7s
mAP 40.66% 47.86% 51.88%
it utilizes CNN feature more suitable for detecting vehicles. However, it has many false positives since background of RGB images has textures which are hard to distinguish from texture of vehicles. In FIR images, textures caused by emit- ted energy are different from that of RGB images are helpful to eliminate false positives in RGB images. Therefore, our method trained on RGB-
FIR images had less false positives by concatenat- ing CNN features from RGB and FIR images hav- ing more discriminative power than CNN feature extracted only form color image. With this joint CNN features, the proposed method applied multi- scale approach able to detect vehicles of various scale and ratio which made run time of our algo- rithm is slower than ACF detector which does not
Fig. 5. Comparison our algorithms with ACF [15] method. (a) Ground truth of vehicles, (b) Results of ACF [15], (c) Results of our method based on RGB image, (d) Results of our method based on both RGB and FIR images.
utilize multi-scale sliding window approach. How- ever, it made less false positives than using RGB only, and higher recall rate shows as shown in Table 1.
5. CONCLUSION
This paper proposed the framework for vehicle detection which consists of convolutional neural network on color and thermal images to overcome inherent limitations of conventional framework based on single color image. Color images could have bad visibility in night condition or challenging illumination and FIR images were more robust in these condition, therefore they were effectively collaborated for vehicle detection. Our algorithm extracted more discriminative features than both CNN features from color images and than hand- crafted features, resulting more accurate vehicle detection results. To estimate vehicle's location and size, we extended the CNN to fully convolu- tional network taking multi-scale and ratio inputs.
Non maximal suppression is applied to avoid over- lapped bounding boxes. In future work, our pro- posed method can be applied to other object de- tection scenarios such as pedestrian detection in challenging conditions. In addition, instead of mul- ti-scale sliding window approach, we will study a single scale approach which predicts bounding box directly to reduce complexity. Lastly, we will study the applications of the joint feature extraction and extension of the proposed method.
REFERENCE
[ 1 ] National Highway Traffic Safety Administra- tion,Traffic Safety Facts, Annals of Emergency Medicine, 2013.
[ 2 ] D.W. James and V. Sharma, "Background- Subtraction in Thermal Imagery Using Con- tour Saliency,"International Journal of Com- puter Vision, Vol. 71, No. 2, pp. 161-181, 2007.
[ 3 ] L. Walchshäusl, R. Lindl, K. Vogel, and T.
Tatschke,Advanced Microsystems for Auto- motive Applications, Springer Publishers, Berlin Heidelberg, 2006.
[ 4 ] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, Overfeat: Integrat- ed Recognition, Localization and Detection Using Convolutional Networks, arXiv pre- print arXiv:1312.6229, 2013.
[ 5 ] S. Hwang, J. Park, N. Kim, Y. Choi, and S.
Kweon, "Multispectral Pedestrian Detection:
Benchmark Dataset and Baseline,"P roceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1037- 1045, 2015.
[ 6 ] LSI Far Infrared Pedestrian Dataset, http://
www.uc3m.es/islab/repository (accessed July, 2013).
[ 7 ] C.J. Burges, "A Tutorial on Support Vector Machines for Pattern Recognition," Data Mining and Knowledge Discovery, Vol. 2, No.
2, pp. 121-167, 1988.
[ 8 ] F. Yoav and S.E. Robert, "A Decision-theo- retic Generalization of On-line Learning and an Application to Boosting,"Journal of Com- puter and System Sciences, Vol. 55, No. 1, pp.
119-139, 1997.
[ 9 ] D. Navneet and T. Bill, "Histograms of Oriented Gradients for Human Detection,"
P roceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 886-893, 2005.
[10] L. Rainer and M. Jochen, "An Extended Set of Haar-like Features for Rapid Object Detection,"Proceeding of International Con- ference on Image P rocessing, pp. 900-903, 2002.
[11] S. Zehang, B. George, and M. Ronald, "On- road Vehicle Detection Using Gabor Filters and Support Vector Machines,"Proceeding of International Conference on Digital Signal P rocessing, pp. 1019-1022, 2002.
[12] J. Seo and K. Sohn, “Superpixel-based Vehicle
Detection Using Plane Normal Vector in Dis- parity Space,” Journal of Korea Multimedia Society, Vol. 19, No. 6, pp. 1003-1013, 2016.
[13] Y. Lee, T. Kim, and J. Shim, “Two-wheeler Detection System Using Histogram of Orient- ed Gradients Based on Local Correlation Coefficients and Curvature,”Journal of Korea Multimedia Society, Vol. 2, No. 4, pp. 303-310, 2015.
[14] F. Pedro, M. David, and R. Deva, "A Discriminatively Trained, Multiscale, Defor- mable Part Model,"Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-8, 2008.
[15] P. Dollar, R. Appel, and S. Belongie, "Fast Feature Pyramids for Object Detection,"
J ournal of P attern Analysis and Machine Intelligence, Vol. 36, No. 8, pp. 1532-1545, 2014.
[16] J. Deng, W. Dong, R. Socher, L.J. Li, K. Li, and L. Fei-Fei, "ImageNet: Large-scale Hierarchical Image Database,"Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 248-255, 2009.
[17] G. Ross, D. Jeff, D. Trevor, and M. Jitendra,
"Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation," Pro- ceedings of the IEEE Conference on Compu- ter Vision and Pattern Recognition, pp. 580- 587, 2014.
[18] X. Glorot and Y. Bengio, "Understanding the Difficulty of Training Deep Feedforward Ne- ural Networks," Proceeding of International Conference on Artificial Intelligence and
Statistics, pp. 249-256, 2010.
[19] M. Tarek, A. Nabil, S.A. Domingo, A. Cris- thian, and T. Ricardo, "Multispectral Stereo Odometry,"IEEE Transactions on Intelligent Transportation Systems, Vol. 16, No. 3, pp.
1210-1224, 2015.
[20] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N.
Zhang, T. Darrell, et al., "DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition," Proceeding of the Inter- national Confidence on Machine Learning, pp.
647-655, 2014.
[21] J. Long, E. Shelhamer, and T. Darrell, "Fully Convolutional Networks for Semantic Seg- mentation,"Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, pp. 3431-3440, 2015.
[22] C. Papageorgiou and T. Poggio, "A Trainable System for Object Detection," International J ournal of Computer Vision, Vol. 38, No. 1, pp. 15-33, 2000.
[23] N. Srivastava, G. Hinton, A. Krizhevsky, Alex, I. Sutskever, and R. Salakhutdinov,
"Dropout: A Simple Way to Prevent Neural Networks from Overfitting," The Journal of Machine Learning Research, Vol. 15, No. 1, pp. 1929-1958, 2014.
[24] A. Vedaldi and K. Lenc, "MatConvNet- Convolutional Neural Networks for MATLAB,”
P roceedings of the 23rd ACM International Confidence on Multimedia, pp. 689-692, 2015.
[25] [Available] P. Dollar, Piotr’s Computer Vision Matlab Toolbox, http://vision.ucsd.edu/˜pdol- lar/toolbox/doc/index.html.
Sungil Choi
2015 BS Electronic Engineering, Yonsei University, Seoul, Korea
2015~2016 Joint Master's/
Doctoral Course Electrical
& Electronic Engineering, Yonsei University, Seoul, Korea.
Research interests : Computer vision, Vehicle image processing
Seungryong Kim
2012 BS Electronic Engineering, Yonsei University, Seoul, Korea
2012~2016 Joint Master's/
Doctoral Course Electrical
& Electronic Engineering, Yonsei University, Seoul, Korea.
Research interests : Computer vision, Machine learn- ing
Kihong Park
2014 BS Electronic Engineering, Sogang University, Seoul, Korea
2014~2016 Joint Master's/
Doctoral Course Electrical
& Electronic Engineering, Yonsei University, Seoul, Korea.
Research interests : Machine learning, Image matching
Kwanghoon Sohn
1983 BS Electronics Engineering, Yonsei University, Seoul, Korea.
1985 MS Electrical Engineering, University of Minnesota 1991 Ph.D Electrical & Computer
Engineering, North Carolina State University.
1988~1992 Research Assistant, North Carolina A&T State University, Image Proc. & Computer Vision Lab.
1992~1993 Senior Researcher, Digital Broadcasting Systems Division, Electronics & Telecommunications Research Institute, Daeduk Science Town, Korea.
1994 Post-Doctoral Research Fellow, MRI Center, Georgetown University Hospital, Washington D.C., U.S.A.
1995~present Professor, School of Electrical &
Electronic Engineering, Yonsei University, Seoul, Korea.
2002~2003 Visiting Professor, School of Computer Engineering, Nanyang Technological University, Singapore.
2009년~2010 Visiting Scholar, Agency for Defence Development.
Research interests : 3D image processing, Computer vision
![Fig. 4. Precision and recall curve of our methods in KAIST dataset [5].](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4763824.516979/6.892.467.800.662.925/fig-precision-recall-curve-methods-kaist-dataset.webp)
![Fig. 5. Comparison our algorithms with ACF [15] method. (a) Ground truth of vehicles, (b) Results of ACF [15], (c) Results of our method based on RGB image, (d) Results of our method based on both RGB and FIR images](https://thumb-ap.123doks.com/thumbv2/123dokinfo/4763824.516979/7.892.95.803.356.1080/comparison-algorithms-method-ground-vehicles-results-results-results.webp)
