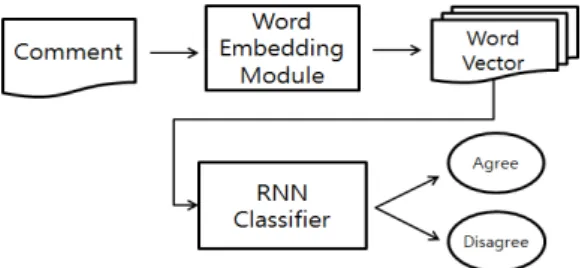
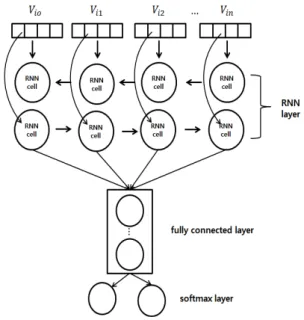
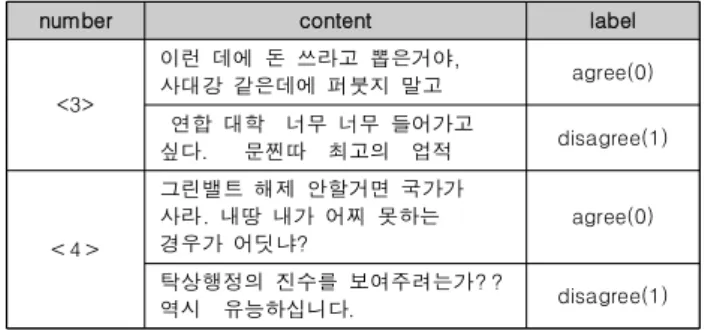
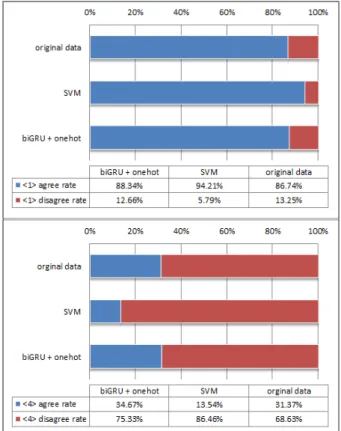
Political Opinion Mining from Article Comments using Deep Learning
1)
전체 글
1)
수치
관련 문서
In this study, using concept mapping of a variety of learning techniques in the area of science, especially biology, has a positive effect on learning
The purpose of this study was to examine the effect of shadowing using English movies on listening and speaking skills, learning interest, and attitudes
As the basis of the study, concept behind information communication technology was formed, and based on theoretical fundamentals of current internet use, ICT
A Method for Collision Avoidance of VLCC Tankers using Velocity Obstacles and Deep Reinforcement Learning.. 지도교수
Lee, Mechanism of micro crack sensor using electrohydrodynamic printing, Journal of Advanced Engineering and Technology.. Schubert, Inkjet Printing of Polymers:
"Brazilian test: stress field and tensile strength of anisotropic rocks using an analytical solution." International Journal of Rock Mechanics and Mining
First, there were 11 error-triggers in the process of communication of information design using natural objects as a metaphor: ① Ratio of visual expressions
Park, “NDT of a nickel Inconel specimen using by the complex induced current - magnetic flux leakage method and linearly integrated hall sensor array”, Journal of the
