Water for Future
요인분석과 군집분석을 이용한 인공신경망 모델링 일반화 정확도 향상에 관한 연구:
유량 및 수질 예측에의 적용
1. 서론
최근 인공지능의 열풍을 일으킨 알파고와 같이 기계학습 분야의 혁신적인 발전으로 인공신경망 (Artificial Neural Networks, 이하 ANN) 모델은 다양한 분야에서 그 적용성과 활용성을 넘어서 혁 신적인 기술로 주목받고 있으며, 수자원 및 환경 분야에서도 새로운 모델링 툴 (tool)로 주목을 받 고 있다. 최근 15년 동안 혹은 그 이상, 인공신경 망 모델은 다양한 분야에서 비선형적 관계의 데이 터 해석에 매우 좋은 결과를 보였으며, 수자원 및 환경분야에서도 인공신경망 모델을 이용하여 유량 및 수질을 예측하고 평가하는 많은 연구들이 이루 어져 왔다. 하지만, 기존의 수자원 분야에서 개발
및 적용된 많은 인공신경망 모델들은 모델 구성과 정과 결과에 대한 설명이 불확실하였고, 결과적 으로 인공신경망 모델은 수자원 및 환경 분야에서 널리 사용되어지고 있는 다른 모델들과 같이 보편 적인 모델로써 평가 받지 못하게 되었다. 이는 인 공신경망 모델링의 방법론적인 측면에 대한 연구 가 거의 이루어지지 않았기 때문이며, 현재도 그 러한 실정이다. 그러므로, 인공신경망 모델을 통 한 분석에서 방법론적인 측면의 연구가 매우 중요 하게 떠오르고 있다. 일반적으로 고려되어지는 인 공신경망 모델링의 방법론적인 측면은 입력과 목 표인자의 선정, 데이터의 선처리, 인공신경망의 최적 구조 선정 등이 있으며, 이들은 모두 해결하 기 힘든 모델링의 일반화(Generalization)에 대한 문제에 속한다.
본 연구의 주목적은 수자원 및 환경분야에서 인 공신경망 모델의 적용에 있어서, 방법론적인 측면 에서 모델링 에러를 줄일 수 있는 방안을 제시하 여 인공신경망 모델링의 일반화 정확도를 향상시 키는데 있다. 이를 위하여 본 연구에서는 인공신 경망 모델링 구성과정 에서 모델링의 일반화 정확 도를 향상 시킬 수 있는 방법론 측면에서의 세 가 지 방안을 제시하였다. 첫번째 방안으로는 탐색적 요인분석 (Exploratory Factor Analysis, 이하 EFA)을 통한 적절한 입력인자의 선정방안이며, 두번째 방안으로는 다양한 군집분석 방법을 적용 김 성 은 ●●●
인천대학교 안전공학과 선임연구원 [email protected]
서 일 원 ●●●
서울대학교 건설환경공학부 교수 [email protected]
Water for Future
하여 선택된 입력인자의 데이터들에 내재된 모든 종류의 패턴이 반영될 수 있도록 균형된 학습자료 와 검사자료를 구성하는 방안이다. 세번째는 인공 신경망 모델의 학습과정에서 앙상블 (Ensemble) 모델링의 적용을 통해 모델의 일반화를 향상시키 는 방안이다. 제시된 방안의 적용결과를 평가하 기 위하여 낙동강 유역에 대하여 유량 및 수질 예 측 인공신경망 모델을 구성하고 일반화 향상 방안 을 적용한 모델과 적용하지 않은 모델을 각각 비 교 검증하였다.
2. 본론
2.1 탐색적 요인분석을 이용한 입력인자의 선정
기존 ANN 모델의 입력인자는 대부분 목표인자 와 인과관계가 일반적으로 알려진 인자를 입력인 자로 선정하거나 사용가능한 모든 인자에 대하여 선형 상관관계 분석을 통해 목표인자와 상관관계
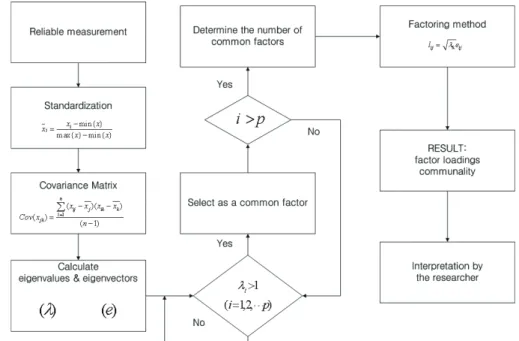
가 큰 인자를 입력인자로 선정한다. 이러한 방식 으로 선정된 입력인자는 필요이상의 정보를 포함 하거나 정보력이 없는 인자를 포함하게 되는 데이 터 과잉입력 (Data Redundancy) 문제가 발생한 다. 이러한 이유로, 선정된 다양한 입력인자들을 조합하여 ANN 모델의 결과를 비교하는 방법을 통 해 최종적으로 입력인자를 선정한다. 하지만, 가 능한 모든 입력인자의 조합에 대하여 모델의 결과 를 비교하는 model-based 방식으로는 모델 개 발 및 실행에 상당한 시간과 노력이 필요하며, 이 런 방식으로 선택된 입력인자가 최적의 결과를 나 타내는 최적의 인자조합인지 설명하기 어렵다. 본 연구에서는 탐색적 요인분석(EFA)을 통해 ANN 모델의 각 목표인자에 대한 적절한 입력인자를 선 정하였다. 탐색적 요인분석(EFA)은 측정된 인자 들의 변동성(Covariance)이 내재된 공통요인에 의해 기인된 것으로 가정하여 인자들간의 인과관 계를 지배하는 주요 과정 및 상관관계를 분석하는 다변량 통계기법의 한 방법이다. EFA는 목표인자 의 변동성에 대한 각 인자들의 설명력을 산정하기
Fig. 1. Steps of inputs selection by EFA (Kim, 2014; Kim and Seo, 2015a)
Water for Future
때문에 ANN 모델의 학습 목표인자 혹은, 예측인 자에 대한 데이터 과잉입력 정도와 정보력이 낮은 입력인자 등을 고려하여 목표인자의 변동성에 큰 설명력이 있는 인자를 입력인자로 선정이 가능한 방법이다. 또한, model-free 방식이기 때문에 모 델의 개발 및 실행에 소요되는 시간과 자원을 크 게 절약할 수 있다. 그러므로, EFA에 의한 입력인 자 선정방식은 ANN 모델 개발 해석성과 효율성을 크게 높일 수 있다. EFA에 의한 입력인자의 선정 절차는 Fig. 1과 같다.
2.2 군집분석을 이용한 학습자료의 구성
ANN 모델은 기왕의 데이터를 학습하여 값을 예측하는 Data-driven 모델이기 때문에 학습자 료의 구성이 매우 중요하다. 그리고, ANN 모델 의 학습 알고리즘은 주어진 학습자료에 대한 모델 의 결과의 오차가 최소가 되도록 반복계산을 하기 때문에 원 자료의 구성비와 패턴 등에 큰 영향을 받는다. 하지만, 기존 ANN 모델 개발 과정에서
의 학습자료 구성은 일반적으로 무작위 추출 방식 이나, 반복적인 무작위 추출법을 이용하여 모델의 결과를 비교하는 모델링 방식을 주로 적용하였다.
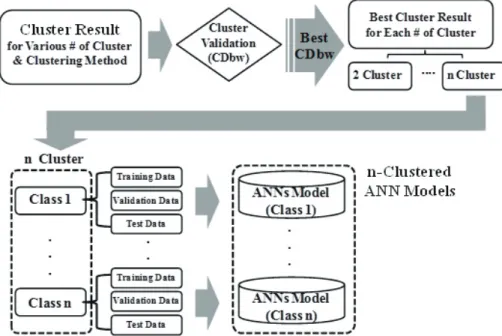
이러한 방식은 원자료의 분포와 패턴을 왜곡시키 는 자료의 불균형(Imbalanced Data Set)문제를 야기하게 되었다. 본 연구에서는 원자료의 패턴과 분포를 왜곡시키지 않고 학습자료가 갖고 있는 패 턴이 모두 반영될 수 있도록 군집분석(Clustering Analysis)를 통해 자료를 분리하였다. 군집분석 은 자료의 이용 목적에 맞도록 비슷한 범위의 속 성을 갖는 자료끼리 묶는 방법을 말하며, 본 연 구에서는 대표적인 군집분석 방법인 K-means, Fuzzy C-means, Subtractive Clustering 방 법과 이들 방법을 결합한 결합적 군집분석 방법 (Conjunctive Clustering Methods)을 이용하 여 학습자료를 분리하였으며, 분리된 결과의 적절 성을 객관적으로 평가하기 위하여 군집분석 검증 지수인 CDbw(Coposing Density between and within clusters)을 이용하였다. 군집분석 방법에 의해 분리된 각 목표인자의 범위 속성이 비슷한
Fig. 2. Ggeneralization approach of ANN modeling using data clustering method (Kim, 2014; Kim and Seo, 2015b)
Water for Future
각각의 학습자료를 이용하여 각각의 n-clustered ANN 모델을 개발하였다(Fig. 2. 참조).
2.3 다양한 초기 가중치에 대한 앙상블 모델링 기법 적용
ANN 모델은 정보처리 프로세서인 뉴런(Neuron) 으로 구성되어있으며, 이들 뉴런들은 각각의 다른 강도에 따라 서로 연결되어 있다. ANN 모델의 학 습은 각 뉴런들을 연결강도의 가중치를 산정하는 과정이다. 하지만, 학습 알고리즘은 일종의 최적 화 알고리즘이기 때문에 이들 연결강도의 초기 가 중치에 따라 학습의 결과가 다르다. 즉, ANN 모 델 초기 가중치에 따라 학습의 결과가 달라지기 때문에 동일한 입력인자와 ANN의 구조를 이용한 다 할지라도 다른 결과를 도출하게 된다. 이에 따 라, ANN 모델의 최적 초기 가중치 선정에 대한 여러 연구들이 진행되어져 왔으며, 최적 초기 가 중치는 학습자료의 구조 및 학습 알고리즘에 민감 하며, 다양한 구조의 입력자료와 학습 알고리즘 을 모두 만족하는 초기 가중치는 정해져 있지 않
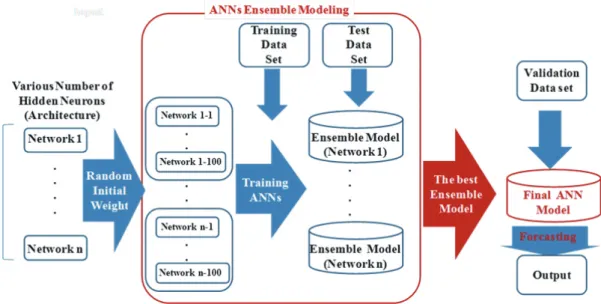
다는 것을 보여주었다. 일반적으로 ANN 모델 개 발자는 여러 번의 학습을 통해 주어진 검사자료에 대해 가장 좋은 결과를 보이는 단일 모델을 최적 모델로 선정한다. 이런 방식으로 개발된 ANN 모 델은 동일한 자료에 대해 모델 개발자에 따라 각 기 다른 모델이 최적 모델로 선정되며, 그 결과 또 한 다른 값을 제시하게 된다. 당연히 이러한 모델 은 일반화 정확도가 낮기 때문에 결과의 최적성을 설명하기 어렵다. 초기 가중치의 영향으로 인한 ANN 모델 학습이 불안정하기 때문에 학습에 대 한 적절한 성능의 평가 방식이 필요하다. 본 연구 에서는 다양한 초기 가중치에 대한 ANN 모델의 학습결과의 변동성을 고려한 전반적인 학습 결과 를 평가할 수 있도록 초기 가중치에 대한 앙상블 모델링을 적용하였다. 동일한 학습 자료에 대해 초기 가중치가 다른 100개의 동일한 구조의 ANN 모델을 학습하여 제시된 결과를 종합하였다. ANN 모델의 성능 평가는 100개의 모델결과에 대한 평 균값과 실측값과의 비교를 통해 모델의 bias error 를 RMSE와 NSE(Nash-sutcliffe Efficiency)를 통해 측정하였으며, 앙상블 모델 자체의 variance
Fig. 3. Ggeneralization approach through ensemble modeling (Kim, 2014; Kim and Seo, 2015a; Kim and Seo, 2015b)
Water for Future
error는 사분범위(interquartile range)를 이용하 여 측정하였다. 초기 가중치에 대한 ANN 앙상블 모델 방식은 Fig. 3과 같다.
3. 탐색적 요인 방법을 적용한 ANN 앙상 블 모델링
3.1 유량 예측
본 연구에서는 낙동강 유역에 위치한 23개의 수 위-유량 관측소와 12개의 강우관측소의 2003년
부터 2009년까지의 일(day) 데이터를 사용하였으 며, 어제(t-1)와 오늘(t)의 일 유출량 및 강우자료 를 이용하여 내일(t+1)의 유출량을 예측하는 ANN 앙상블 유량예측 모델을 낙동강 상류에 위치한 낙 동(v5), 낙동강 중류에 위치한 고령교(v9), 낙동강 하류에 위치한 수산(v13)지점에 대해 구축하였다.
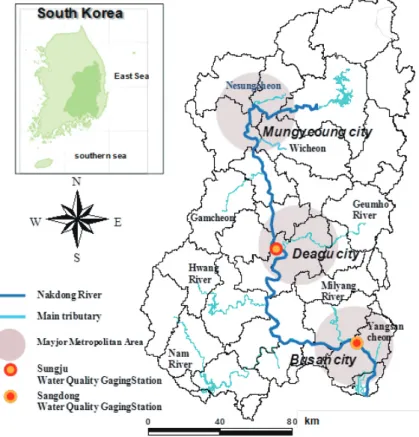
낙동(v5), 고령교(v9), 수산(v13)지점에서의 내 일의 유출량을 예측하기 위한 입력인자의 선정은 EFA 분석을 통해 선정하였다. 대상유역의 관측소 위치와 각 지점별 선정된 입력인자 결과는 Fig. 4 와 Table 1과 같다.
Fig. 4. Study site: Nackdong River (Kim, 2014; Kim and Seo, 2015b)
Table 1. Input aariables selected by EFA (Kim, 2014; Kim and Seo, 2015b) Desired
Output
Inputs
Streamflow (Q) Precipitation (P)
v5 Qt , Qt-1, Qt-2 of Nakdong P*t, P*t-1
v13 Qt , Qt-1, Qt-2 of Koryunggyo &
Qt of Gumi P*t, P*t-1
v19 Qt , Qt-1, Qt-2 of Susan Pt, Pt-1, Pt-2 of all rainfall stations
Water for Future
요인분석에 의해 선택된 입력인자와 임의적으 로 선택된 인자들을 이용하여 각 인자의 자료를 stratified 추출방식을 통해 각각의 목표인자에 대 한 학습자료를 구성하고 ANN 앙상블 모델을 구축 하였다. 각각의 입력인자를 갖는 ANN 앙상블 모 델에 대한 교차검증 결과를 비교한 결과, 요인분 석에 의해 선택된 입력인자를 사용하는 ANN 앙상
블 모델의 결과가 더욱 좋은 결과를 보였다. Fig.
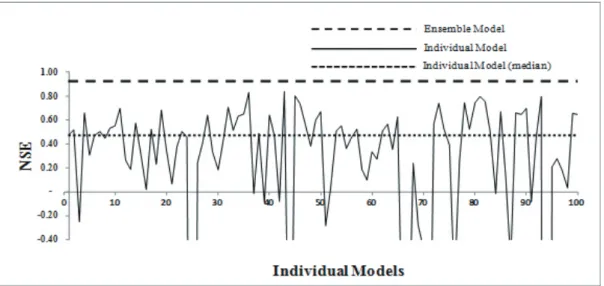
5는 선택된 입력인자를 사용하는 낙동(v5) 지점 유량 예측 ANN 모델의 100개 앙상블 모델에 대한 각각의 결과 및 앙상블 종합 결과를 나타낸 것이 며, Fig. 6은 각 지점의 앙상블 예측 모델을 이용 한 검증 결과이다.
Fig. 5. Comparison of the result between individual and ANN ensemble models (Kim, 2014; Kim and Seo, 2015b)
Fig. 6. Stream prediction results using ANN ensemble model with EFA (Kim, 2014; Kim and Seo, 2015b)
(a) Nackdong (v5) (b) Goryonggyo (v13) (c) Susan (v19)
3.2 수질 예측
수질예측 ANN 앙상블 모델의 개발을 위하여 낙동강 중류 및 상류에 각각 위치한 성주 및 상 동 수질관측소 지점의 2009년부터 2012년까지의
일(day)수질자료를 이용하였다. 각 지점별 어제 (t-1)와 오늘(t)의 수질지표들의 일 수질자료를 이 용하여 내일(t+1)의 수질을 예측하는 ANN 앙상블 수질예측 모델을 구축하였으며, 성주 및 상동의 각 수질지표를 예측하기 위한 입력 수질지표의 선
Water for Future
정은 EFA를 통해 선정하였다. 대상 관측소 위치 는 Fig. 7과 같다.
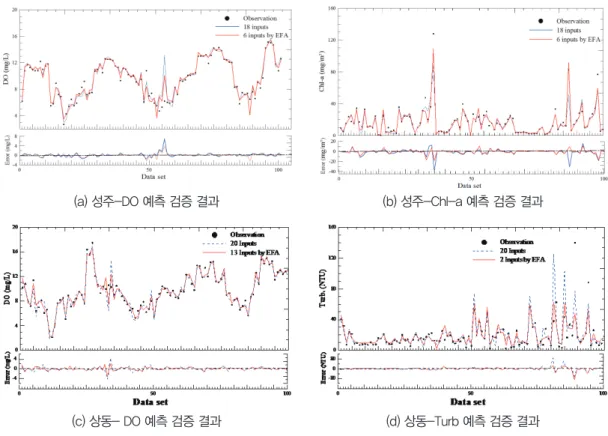
EFA에 의해 선택된 입력인자와 전체 수질인자 들을 이용하여 각 인자의 자료를 stratified 추출 방식을 통해 각각의 목표인자에 대한 학습자료를 구성하고 ANN 앙상블 모델을 구축하여 각각의 입 력인자를 갖는 ANN 앙상블 모델의 결과를 비교하 였다. 비교한 결과, 요인분석에 의해 선택된 입력 인자를 사용하는 ANN 앙상블 모델의 결과가 더욱 좋은 결과를 보였으며, 상동지점의 Turb.(탁도)를 제외한 나머지 수질예측 검증 결과 NSE가 평균적 으로 약 0.90이 나타나고 있다. 상동지점의 Turb 의 경우는 전체 수질인자를 입력인자로 사용할 경 우 NSE 0.41, EFA 분석을 통해 선정된 입력인자 를 사용할 경우 NSE 0.58로 예측 결과의 정확도
가 크게 증가하지 않고 있으며, 특히, 고농도의 예 측 능력이 현저하게 떨어지고 있다. Fig. 8은 EFA 에 의해 선택된 입력인자를 사용하는 상동 및 성 주 지점의 일부 수질인자의 예측 검증 결과이다.
4. 군집분석 방법을 적용한 ANN 앙상블 모델링
EFA 분석을 이용한 성주 및 상동의 ANN 수질 예측 앙상블 결과에서 상동지점의 Turb 예측 결과 가 전체 수질인자를 입력인자로 사용할 경우 NSE 0.41, EFA 분석을 통해 선정된 입력인자를 사용 할 경우 NSE 0.58로 예측 결과의 정확도가 크게 증가하지 않고 있으며, 특히, 학습자료의 수가 적
Fig. 7. Study site for water quality prediction (Kim, 2014; Kim and Seo, 2015a)
Water for Future
은 고농도의 예측 능력이 현저하게 떨어지고 있 다. 이는 최적화 알고리즘인 학습 알고리즘의 특 성에서 기인한 것으로 학습자료의 패턴이 지배적 인 범위에 대해서 학습의 최적화가 이루어지며, 학습자료에 내포된 소수의 패턴을 가지고 있는 범 위에 있는 자료는 학습의 최종 결과에 큰 영향을 미치지 못하게 된다. 즉, 학습 자료의 분포와 패턴 의 불균형(Imbalanced Data Set)에 의해 ANN 모델의 학습 능력이 저하되고 연속적으로 모델 의 정확도를 낮추게 된다. 성주 및 상동지점의 수 질예측 결과 중 비교적 낮은 NSE를 보이는 성주 지점의 Chl-a와 상동지점의 Turb의 자료구성비 에 따른 EFA 적용 전 후 예측결과의 오차를 살펴 보면 자료의 분포가 고르지 못하고 자료의 분포가 적은 범위에 대해서 예측결과의 오차인 RMSE가 크게 증가하는 것을 알 수 있다 (Fig. 9 참조).
성주지점의 Chl-a와 상동지점의 Turb에 대해 서 군집분석 방법을 적용하여 학습 자료의 패턴에 따라 2개에서 4개의 그룹으로 나누고 각각의 자료 를 학습자료로 하는 ANN 수질 예측 앙상블 모델 을 구성하였다. 군집분석을 적용하여 3개의 학습 자료로 분리한 ANN 모델을 사용했을 경우, 상주 지점의 Chl-a의 NSE 결과는 EFA를 적용한 모델 의 결과인 0.86에서 0.96으로 증가하였으며, 상 동지점의 Turb으 NSE 결과는 EFA를 적용한 모 델의 결과인 0.58에서 0.88으로 크게 증가하였다.
자료구성비에 따른 예측결과의 오차 RMSE를 살 펴보면, 전체 자료의 범위에 대한 예측 오차가 감 소하고 있으며, 특히, 큰 오차를 보였던 고농도에 서의 예측 오차가 군집분석을 적용함으로써 크게 감소하여 정확도의 증가와 함께 모델의 전체적인 예측 능력이 크게 향상되었다 (Fig. 9 참조).
Fig. 8. Water quality prediction results using ANN ensemble model with EFA (Kim, 2014; Kim and Seo, 2015a) (a) 성주-DO 예측 검증 결과
(c) 상동- DO 예측 검증 결과
(b) 성주-Chl-a 예측 검증 결과
(d) 상동-Turb 예측 검증 결과
Water for Future
5. 결론
본 연구에서는 ANN 모델의 일반화 정확도를 향 상 시킬 수 있는 방법을 제안하고 제안한 방법을 유량 및 수질 예측 모델에 적용하여 검증하였으며 다음과 같은 결론을 얻었다.
1. EFA를 통해 목표인자의 변동성에 큰 영향을 주는 입력인자를 선정함으로써 데이터의 중복 및 과잉에 따른 인공신경망 모델의 오차를 줄일 수 있었으며, 기존 모델기반의 방식에 비해 입력인자 선정을 위한 시간과 입력인자 개수의 감소로 인한 학습 시간을 크게 줄일 수 있었다.
2. 앙상블 모델링 기법을 통해 초기 가중치에 따 른 앙상블 모델 결과의 변동성을 확인할 수 있었 으며, 초기 가중치의 영향이 없는 각 모델의 성능 을 평가 할 수 있었다.
3. 군집분석 방법을 통해 학습자료의 패턴에 따 라 분리하고 분리된 학습자료를 이용하여 각각의 모델을 구축함으로써, 학습 자료의 분포와 패턴의 불균형(Imbalanced Data Set)에 의한 ANN 모델 의 학습 능력 및 정확도 저하현상을 크게 개선하 였다.
본 연구에서 제시한 ANN 모델 일반화 향상 방 안을 적용한 모델의 결과가 기존의 방식에 의한
인공신경망 모델 결과에 비해 더욱 정확하게 예측 하는 것으로 나타났으며, 전반적인 모델링 에러도 감소하는 것으로 나타났다. 본 연구에서 제시한 일반화 방안이 수자원 및 환경 분야에서의 인공신 경망 모델 개발에 유용한 방법으로 적용되어질 수 있을 것으로 기대된다.
6. 맺음말
최근 수자원 및 환경 분야에서 인공신경망 모델 과 같은 데이터 기반 모델을 활용한 연구들이 진 행되어지고 있지만, 아직까지 실무적으로 직접적 인 데이터 기반 모델의 적용 및 활용은 거의 전무 한 실정이다. 데이터 기반 모델은 데이터 분석에 서 대표적으로 사용되는 데이터 마이닝, 기계 학 습과 같은 컴퓨터 사이언스 기반으로 발전해왔으 며, 컴퓨터의 빠른 발전 속도와 더불어 빠르게 발 전하고 있다. 이 기술을 물리적으로 설명하기 힘 든 자연현상이나 아직까지 밝혀지지 않은 물리적 관계의 발견을 위해 기존의 물리기반 모델과 결합 하여 활용한다면, 기존 물리기반 모델의 한계를 보완하고 더 나아가 물리-데이터 기반의 물리적 관계를 분석하는 한 분야로도 발전할 수 있지 않 Fig. 9. Interval RMSE according to the distribution ratio of total data set before/after clustering (Kim, 2014; Kim and
Seo, 2015a)
(a) Chl-a (b) Turb
Water for Future
을까 조심히 예상해 본다. 이를 위해 이 분야에 대 한 많은 관심과 물리기반 모델을 기반으로한 데이 터 기반 모델의 전문가 혹은 데이터 기반 모델을 연계한 물리기반 모델 전문가의 양성이 필요할 것 으로 생각된다.
감사의 글
본 연구는 국토교통부 물관리연구사업의 연구비 지원(11기술혁신C06)에 의해 수행되었습니다.
참고문헌
1. Kim, S. E. 2014. “Improving the Generalization Accuracy of ANN Modeling Using Factor Analysis and Clustering Analysis: Its Application to Streamflow and Water Quality Predictions”, Ph.D. Thesis, Seoul National University, Korea.
2. Kim, S. E., and Seo, I. W. 2015a. “Artificial Neural Network Ensemble Modeling with Conjunctive Clustering for Water Quality Prediction in Rivers”, Journal of Hydro-environmental Research. Vol. 9(3), pp.325-339.
3. Kim, S. E., and Seo, I. W. 2015b. “Artificial Neural Network Ensemble Modeling with Exploratory Factor Analysis for Streamflow Forecasting”, Journal of Hydroinformatics. Vol. 17(4), pp.614-639.