YOLO알고리즘을 활용한 시각장애인용 식사보조 시스템 개발
이군호*ㆍ문미경**
Development a Meal Support System for the Visually Impaired Using YOLO Algorithm
Gun-Ho Lee*ㆍMi-Kyeong Moon**
요 약
시각이 온전한 사람들은 식사를 할 때 시각에 대한 의존도를 깊게 인지하지 못한다. 그러나 시각장애인은 식단에 어떤 음식이 있는지 알지 못하기 때문에 옆에 있는 보조인이 시각장애인 수저로 음식의 위치를 시계 방향 또는 전후좌우 등 일정한 방향으로 설명하여 그릇 위치를 확인한다. 본 논문에서는 시각장애인이 스마트 폰의 카메라를 이용하여 자신의 식단을 비추면 각각의 음식 이미지를 인식하여 음성으로 음식의 이름을 알려 주는 식사보조 시스템의 개발 내용에 대해 기술한다. 이 시스템은 음식과 식기도구(숟가락)의 이미지를 학습한 YOLO모델을 통해 숟가락이 놓인 음식을 추출해 내고, 이 음식이 무엇인지를 인식하여 이를 음성으로 알려준 다. 본 시스템을 통해 시각장애인은 식사보조인의 도움없이 식사를 할 수 있음으로써 자립의지와 만족도를 높 일 수 있을 것으로 기대한다.
ABSTRACT
Normal people are not deeply aware of their dependence on sight when eating. However, since the visually impaired do not know what kind of food is on the table, the assistant next to them holds the blind spoon and explains the position of the food in a clockwise direction, front and rear, left and right, etc. In this paper, we describe the development of a meal assistance system that recognizes each food image and announces the name of the food by voice when a visually impaired person looks at their table using a smartphone camera. This system extracts the food on which the spoon is placed through the YOLO model that has learned the image of food and tableware (spoon), recognizes what the food is, and notifies it by voice. Through this system, it is expected that the visually impaired will be able to eat without the help of a meal assistant, thereby increasing their self-reliance and satisfaction.
키워드
Computer Vision, Deep Learning, YOLO, Visually Impaired, Intersection over Union(IoU), Android, Text-to-Speech 컴퓨터 비전, 딥러닝, YOLO, 시각 장애인, 공통 영역, 안드로이드, 음성 합성 시스템
* 동서대학교 학부연구원([email protected])
** 교신저자 : 동서대학교 소프트웨어학과 ㆍ접 수 일 : 2021. 08. 25
ㆍ수정완료일 : 2021. 09. 20 ㆍ게재확정일 : 2021. 10. 17
ㆍReceived : Aug. 25, 2021, Revised : Sep. 20, 2021, Accepted : Oct. 17, 2021 ㆍCorresponding Author : Mi-Kyeong Moon
College of Software Convergence, Dongseo University, Email : [email protected]
http://dx.doi.org/10.13067/JKIECS.2021.16.5.1001
Ⅰ. 서 론
현재 대한민국에 등록된 장애인 수는 약 260만여 명이고 그중 시각장애인은 25만여 명으로 약 10%를 차지한다 [1]. 일반인의 경우 눈을 통해 많은 정보를 받아들이고 그 정보를 활용하여 일상 속에서 많은 선 택을 내린다. 그래서 시각을 통해 정보를 제공받지 못하는 것은 곧 생활하는 데에 필수적인 정보를 얻지 못하는 것과 같다 [2-3]. 시각장애인은 이를 두고 신 체적 장애가 사회적 장애가 되는 과정이라 말한다.
시각장애인을 위한 효율적인 식사법으로 가장 많이 거론된 것은 ‘시계 참조 방식 (Clock Reference System)’이다. 시각장애인 본인에게 수직으로 가장 가까운 방향에 있는 음식을 6시, 멀리 있는 음식은 12 시로 정하고, 9시와 3시 방향에는 어떤 음식이 놓여 있는지 미리 인지하는 방식이다. 이는 원형 접시 안 에 모든 음식을 놓고 먹는 서구형 식사방식에 맞춰진 대안인 셈이다. 한식과 같이 반찬이 여러 곳에 흩어 져 있는 경우는 일반적으로 보조인이 시각장애인 수 저를 같이 잡고 음식의 위치를 시계 방향 또는 전후 좌우 등 일정한 방향으로 설명하여 그릇 위치와 음식 을 확인할 수 있도록 한다 [4]. 그러나 보조인이 없는 경우에는 자신이 직접 음식을 하나하나 더듬어 가며 찾고 그 음식이 무엇인지 모르는 상태에서 식사를 해 야 하는 불편함이 생긴다. 자신이 먹는 음식이 무엇 인지도 모르고 식사를 한다는 것은 때로는 불쾌감을 줄 수도 있으며, 자립의지를 떨어뜨리는 원인이 될 수 있다 [5].
본 논문에서는 시각장애인이 스마트폰의 카메라를 이용하여 자신의 식단을 비추면 각각의 반찬 이미지 를 인식하여 음성으로 반찬의 이름을 알려주는 식사 보조 시스템의 개발 내용에 대해 기술한다. 이 시스 템에서는 딥러닝 분야인 객체인식(Object Detection) 모델 중 하나인 오픈소스 라이브러리 YOLO를 사용 하여 음식과 식기도구(숟가락)의 이미지를 학습시킨 후, 사용자가 음식 위에 식기도구를 가져다 놓으면, 해당 음식이 무엇인지를 음성으로 알려준다. 이 시스 템은 추가적인 장비(device) 없이도 시각장애인들이 쉽게 사용할 수 있도록 스마트폰에서 작동 가능한 안 드로이드 앱(Android App)으로 개발한다. 이 시스템 을 통해 시각장애인들은 식사를 할 때 보조인 도움없
이 자신이 먹으려는 음식에 대한 정보를 얻을 수 있 음으로써 자립의지를 높일 수 있고, 식사에 대한 만 족감을 충족할 수 있을 것으로 기대한다.
Ⅱ. 관련 연구
2.1 음식 이미지 인식 모델
현재 AI 딥러닝 모델을 사용하여 음식을 인식하는 연구들이 다양한 시도로 진행되고 있다. 그중 2019년 대한지역사회영양학회에서 발표된 연구 [6]에서는 Deep Convolutional Neural Network(: CNN)를 사용 하여 한식 이미지를 인식하여 모바일을 통해 식단을 관리해주는 시스템을 개발하였다. 해당 연구에서는 한식을 인식하기 위해 모델 학습에 필요한 이미지를 인터넷과 직접 촬영을 통해 약 4,000장을 수집하였고, 이를 이미지 처리 기술을 사용하여 대비, 밝기, 선명 도, 색상 변경을 하여 총 92,000장의 이미지로 만들었 다. 본 연구에서는 이미지 인식의 성능 향상을 위해 깊은 구조로 설계된 ‘K-foodNet’ 이라는 새로운 Deep Convolutional Neural Network를 개발하여 학습을 진 행하였으며, 그 결과 같은 데이터 셋으로 학습을 진 행한 AlexNet, GoogLeNet, VGG, ResNet 등 다른 CNN 모델보다 우수한 성능을 보였다.
이와 유사한 연구로 ‘카카오 엔터프라이즈 AI Lab’
에서 개발한 음식 인식기술이 존재한다 [7]. 본 연구 에서는 개발 당시 최신 분류 모델 중 가장 높은 성능 을 자랑하는 ‘InceptionV4’를 음식 분류의 기반 모델 로 활용하였다. 최적화 알고리즘으로는 초반에는 학 습속도가 빠른 ADAM(: ADaptive Moment estimation)처럼 동작하고 후반에는 SGD(: Stochastic Gradient Descent)[8]처럼 높은 성능에 안정적으로 수 렴하는 ‘Adabound’를 선택하였다. 음식 인식과정에서 는 먼저 Inception블록을 통해 이미지의 특징을 추출 후 다시 별도의 두 개의 Inception모듈을 사용하여 음 식인지 아닌지 판별하는 이진 분류기와 음식의 종류 를 판별하는 음식 분류기로 구성하여 진행한다.
참고한 두 가지 관련 연구 모두 본 연구와 같이 한 국 음식을 구분하여 인식하는 것에 대한 내용은 유사 하지만, 기존 연구는 일반인의 식단 관리를 목적으로 개발되기 위해 보여지는 모든 음식을 구분하는데 초
점을 맞추고 있다. 본 연구는 실시간 영상을 통해 시 각장애인이 숟가락으로 가리키는 해당 음식만을 추출 하여 음식의 위치와 이름을 알려주는 것에 목적을 두 고 있는 점이 다르다.
2.2 딥러닝을 활용한 시각장애인 활동보조시스템 본 연구와 비슷한 주제로 딥러닝 기술을 활용하여 개발된 시각장애인 보조시스템 개발 연구들이 존재한 다. 2018년 대한전자공학회에서 발표된 연구 [9]에 따 르면 ‘Tensorflow Object Detection API’를 활용하여 사물탐지를 진행하였고 구글의 음성인식 기술과 아두 이노 기반의 음성안내 기능을 활용하여 시각장애인을 위한 사물 위치 안내 시스템을 개발하였다. 약 90여 개의 카테고리와 총 30만장의 이미지로 구성된 ‘MS COCO dataset’으로 사전학습된 TensorflowAPI를 사 용하여 사물을 인식하였고 인식결과에 따른 사물의 좌표값을 직렬통신을 통해 아두이노로 전송하였다.
그 후 음성인식 기술을 사용하여 사용자가 물체에 대 한 이름을 말하면 해당 물체의 위치를 알려준다. 알 려준 위치를 기반으로 근접센서가 장착된 기기를 가 까이 가져가면 해당 물체의 정확한 위치를 알 수 있 게 하였다. 본 연구와 공통점으로 Object Detection 기술을 활용하여 시각장애인을 위해 객체의 위치를 알려주는 부분에 있어 유사점이 존재한다. 그러나 해 당 관련연구는 위치를 알려주는 부분을 단순한 좌표 값을 통해 알려주고 근접센서가 부착된 추가적인 기 기가 필요하지만 본 연구는 스마트폰의 카메라를 통 해 감지된 음식과 식기 객체간의 Bounding Box 값에 따른 교차영역 (Intersection over Union, IoU) 수치를 통해 가리키고 있는 객체(음식)을 알려준다는 점이 다르다.
본 연구와 같은 딥러닝 모델인 YOLO를 사용한 시 각장애인 보조 시스템 개발연구가 존재한다. 2019년 한국정보과학회에서 발표된 연구 [10]에 따르면
‘YOLOv2-Tiny’ 모델을 사용하여 횡단보도를 인식하 는 기능을 개발하였다. 횡단보도 사진을 전방, 우측, 좌측 구도에서 촬영하여 이미지 학습을 시켰고, 그 결과 mAP(mean Average Precision) 97%를 달성하 였다. 감지된 횡단보도는 방향을 인식하여 인식된 방 향을 음성으로 안내한다. 만약 이어폰을 착용했을 경 우 Google에서 제공하는 ‘GvrAudioEngine’을 활용하
여 ‘3d 사운드’ 기능을 사용하여 사용자에게 알려주도 록 개발하였다. 본 연구와 같은 딥러닝 모델인 YOLO 를 사용하는 점과 시각장애인을 위한 시스템이라는 유사점이 존재하지만 학습한 이미지가 다르고 위치를 알려주는 접근방법 또한 다르다.
기존 관련 연구들이 음식 인식 모델을 개발하였더 라도 시각장애인을 위한 식사에 대한 문제를 해결할 수는 없다. 본 연구에서는 시각장애인이 식사 시 생 기는 문제점을 해결하기 위해 실시간 객체 인식이 가 능한 YOLO 알고리즘을 사용하였고, 시각장애인이 직 접 숟가락으로 가리키는 음식을 인식하도록 하였으며, 추가적인 디바이스 없이 스마트폰만으로도 작동이 가 능한 시스템으로 개발한 것에 특징이 있다.
Ⅲ. 시스템 개발
3.1 음식 데이터 수집
YOLO를 활용하여 음식과 식기도구(숟가락)를 인 식하기 위해서는 이에 대한 음식 및 식기도구의 이미 지 데이터가 필요하다. 본 연구에서는 3가지 방법으 로 이미지를 수집한다.
1) 크롤링을 통한 이미지 수집 : 음식에 대한 데이 터를 얻기 위해 파이썬 (Python)의 ‘Selenium’와
‘google_image_download’ 모듈을 사용하여 크롤링을 진행한다. 크롤링을 통해 수집한 데이터를 기반으로
‘Darknet’ 프레임워크를 사용하여 YOLO 모델을 학습 시킨다. 수집한 데이터 셋을 기반으로 잘 차려진 음 식 이미지에 테스트를 해본 결과 mAP는 90% 이상으 로 높게 나왔다. 그러나 그림 1과 같이 실제 음식을 촬영한 이미지는 구글 검색결과 나온 이미지와 상이 하기 때문에 인식률이 저조하였다. 이는 구글 이미지 검색의 경우 일반적으로 식당에서 찾아볼 수 있는 음 식의 이미지보다는 대부분 광고를 목적으로 촬영되어 잘 장식(Decoration) 된 음식의 사진이 많아 실제 식 당에서 접하는 이미지와의 차이가 존재하기 때문에 인 것으로 분석되었다. 즉, 실제 식당에서 접할 수 있 는 정돈되지 않은 음식 이미지와 달라서 인식률이 낮 게 나왔다.
그림 1 검색 이미지와 실제 촬영 이미지의 차이 Fig. 1 The difference between the search image
and the actual shot image
2) ‘AiHub’에서 제공하는 ‘음식 이미지 및 영양정 보 텍스트’ 데이터 셋 사용 : 해당 데이터 셋의 경우
㈜에이아이더뉴트리진에서 구축한 데이터 셋으로 400 여 종 이상의 음식 (그림 2)과 각각의 2,000장 이상의 500만 화소 이상의 이미지 총 840,000장과 각각에 대 한 라벨링 값인 annotation 파일이 제공된다. 본 데이 터 셋의 이미지는 실제 이미지와 유사하지만, 해당 라벨링 파일의 형식이 xml형식이어서 YOLO의 학습 에 필요한 라벨링 파일의 포맷 (클래스번호, center x, center y, width, height)으로 변환시켜서 새로 라벨링 을 실시해야 하는 추가적인 작업이 필요하다.
그림 2 AiHub의 한식 데이터셋 Fig. 2 Korean food dataset on AiHub
3) 음식 이미지 직접 촬영 : 본 연구에서는 딥러 닝 모델이 다양한 환경에서도 올바르게 음식을 판별 할 수 있도록 해당 데이터 셋의 일부분과 직접 촬영 한 음식 이미지를 바탕으로 새로운 데이터 셋을 구축 한다. 식기도구에 해당하는 숟가락 이미지는 일반인 이 사용하는 한식용 숟가락으로 직접 들고 있는 영상
을 촬영한 후, 프레임별로 나누어서 수집하였다.
위와 같이 3가지 방법으로 이미지 수집 후, 이미지 프로세싱 기능을 제공하는 라이브러리인 OpenCV를 활용하여 이미지 전처리를 실시한다. 먼저 Grayscale 을 통해 컬러 이미지를 흑백 이미지로 변경한다. 이 때 변환과정에서 원본 이미지와의 픽셀 값이 달라지 는 문제점을 해결하기 위해 히스토그램 균일화를 진 행한다. 히스토그램 균일화란 이미지의 픽셀 값들을 히스토그램으로 나타내었을 때 좁은 범위에 집중되어 있는 픽셀값들이 넓은 범위의 분포를 가질 수 있도록 변환하는 과정이다. 본 연구에서는 히스토그램 균일 화 방법 중 히스토그램 값에 제한을 두어 특정 값 이 상에 있는 픽셀 값을 다시 재분배하는 방법인
‘CLAHE’을 사용하여 이미지를 자연스럽게 만들었다.
딥러닝 모델이 판별할 한식의 반찬 카테고리는 ‘한 국보건산업진흥원에서 진행한 국민영양통계에 따른 음식섭취량’을 참고하여 한국인이 자주 먹는 음식을 기준으로 쌀밥, 김치, 된장국 등 총 10개의 카테고리 에 각각 1,000장을 수집하여 학습에 사용할 데이터셋 을 구축하였다.
3.2 YOLO Custom 모델 개발
수집한 데이터 셋을 기반으로 YOLO 학습을 진행한 다. YOLO는 one-stage object detection 딥러닝 기법 으로, 물체를 한 번에 인식할 수 있는 매우 빠른 속 도의 추론 과정으로 처리되는 알고리즘이다. 본 연구 에서는 다양한 버젼의 YOLO모델 중, 스마트폰에서도 작동이 가능해야 하기에 YOLOv3-Tiny를 선택하였 다. YOLOv3-Tiny는 YOLOv3보다 정확도는 조금 떨 어지지만, 가볍고 처리속도가 빠른 모델이며, YOLOv3에서 가중치를 다르게 해서 사용할 수 있다.
물체를 인식하기 위해서는 설정값과 가중치 값을 부 여해야 하는데, 이는 Darknet 깃허브(Github) 저장소 에서 획득한다. 모델을 Custom 학습을 진행하기 위해 서는 모델의 구조 일부분과 가중치 값을 수정할 필요 가 있기에 학습에 필요한 Hyper parameter와 YOLOv3-Tiny의 모델 구조가 정의되어 있는 cfg파일 을 수정한다. 학습 후 결과를 확인하면 해당 이미지 를 처리하는데 걸린 시간과 객체의 이름, 인식률(%) 이 표시된다. 이중 학습 결과가 가장 좋은 가중치 파 일을 선택해서 안드로이드 앱에서 사용한다.
3.3 음식 결정 알고리즘
식탁에 놓인 음식을 인식하여 알려주기 위하여 다 음과 같은 2가지 방법을 적용할 수 있다.
1) 음식 위치 좌표값으로 인식 : 관련연구 [8]에서 사용한 방식이며, 카메라로 촬영된 이미지를 3x3 형 태로 나누어 인식된 음식의 Bounding Box의 위치 값 을 기준으로 왼쪽 상단, 가운데 상단, 오른쪽 상단 등 9개의 영역으로 나누어 해당하는 위치에 음식이 존재 한다고 설명하는 방식이다. 이 방법을 사용 할 경우, 사용자가 사진을 촬영하는 각도에 따라 기준점이 달 라져서 위치값이 자주 바뀌는 문제점이 있으며 또한 3x3의 부분 경계선 근처에 위치하는 음식이나 여러 영역에 걸친 음식에 대해 인식하는 기준이 모호하게 되는 문제점이 있다.
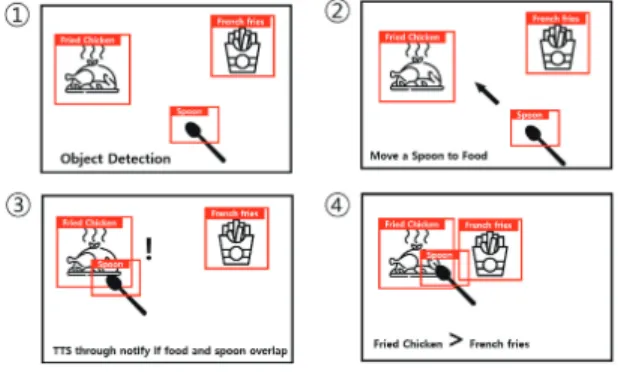
2) 식기도구 이미지와 겹치는 영역으로 인식 : 사 용자가 음식을 가리킬 수 있는 수단은 손, 식기 도구 등 다양한 도구가 존재한다. 그중 생김새가 대부분 일정하고 식사 시 손쉽게 얻을 수 있고 자신이 먹는 음식을 오염시키지 않는 것은 식기 도구 중 숟가락일 것이다. 즉 사용자가 숟가락을 음식위에 놓으면 해당 음식을 알려주도록 한다. 이를 위해서 그림 3과 같은 과정을 거친다. 1) YOLO알고리즘을 통해 학습된 음 식과 숟가락 이미지를 인식한다. 2) 사용자는 숟가락 을 움직여 식탁에 놓인 음식의 영역으로 움직인다. 3) 감지된 음식의 Bounding Box와 숟가락의 Bounding Box가 일정 부분 겹칠 경우 사용자는 해당 음식을 가리키는 것으로 판단하여 해당 음식을 TTS기능을 활용하여 음성으로 알려준다.
그림 3 음식 결정 프로세스 Fig. 3 Food decision process
음식과 숟가락의 Bounding Box의 겹침을 판단하 는 기준은 다음과 같다.
1) 숟가락 Bounding Box의 중앙값이 음식의 영역 에 들어갔을 경우 이를 겹쳤다고 판단하는 방법이다.
해당 방식은 구현이 간단하여 숟가락의 중앙값을 갱 신하면서 음식을 찾아가면 된다. 그러나 실시간 객체 탐지 특성상 객체의 Bounding Box는 매번 달라지며 그에 따라 중앙값 또한 계속 변동하게 됨으로 숟가락 이 음식에 닿았음에도 불구하고 기준점이 중앙값이기 때문에 인식을 못 하는 경우가 발생할 수 있다
2) IoU (Intersection over Union)를 사용하여 두 가지 물체의 겹침의 정도를 분석하는 방법이다. IoU 는 두 물체가 얼마나 일치하는지를 수학적으로 나타 내는 값이다. 해당 값은 일반적으로 객체인식 분야에 서 모델이 인식한 객체의 위치와 실제 객체의 위치를 IoU를 통해 비교하여 성능평가 기준으로 사용된다.
해당 수치가 0에 근접할수록 두 물체는 겹치지 않는 다고 볼 수 있고 1에 근접 할수록 두 물체는 겹친다 고 판단할 수 있다. IoU를 구하는 수식은 식 (1)과 같 다.
(1)
는 모델이 객체에 대한 Prediction 값, 즉 예측 한 객체의 Bounding Box 영역이고 는 Ground-truth, 즉 데이터의 실제 값이다. 본 연구에서 는 을 음식의 영역, 을 숟가락의 영역이라 가 정하고 진행한다. IoU를 사용하는 방식이 앞서 언급 했던 1) 방식보다 계산량이 많아진다는 단점이 존재 하지만 수학적 수치를 통해 비교 가능하다는 점과 중 앙점 값에 구애받지 않고 겹쳤다는 판단을 할 수 있 다는 점에서 효과적인 판단을 할 수 있기에 본 연구 에서는 IoU를 사용하는 방법으로 해당 음식 객체를 인식하도록 한다.
3.4 안드로이드 앱 개발
C/C++ 기반으로 이루어진 Darknet 프레임워크에 서 학습된 YOLO 모델의 경우 안드로이드 앱에서 사 용하는 방법은 두 가지가 있다.
1) Tensorflow Lite 형식으로 변환하여 사용하는
방법 : 이 경우 먼저 Darknet 프레임워크에서 학습된 가중치 파일을 변환기를 통해 Tensorflow 형식으로 이루어진 모델의 구조와 가중치 정보가 담긴 .Pb 파 일로 변환한다. 그 후 Tensorflow Lite 형식인 .TFLite 형식으로 변환한다. 해당 방식으로 모델을 구 성하고 변환하여 앱에서 사용할 경우 앱 실행 시 영 상 재현율을 나타내는 FPS (Frame Per Second)가 높다는 장점이 있지만 모델 변환 과정에서 모델의 정 확도가 낮아진다는 단점이 있다.
2) OpenCV 라이브러리를 사용하는 방법 : 이 방법 은 OpenCV 라이브러리를 안드로이드 앱에 추가한 후 Darknet 기반으로 이루어진 .weights 파일을 읽어 와 모델을 실행할 수 있다. 이 방법의 장점으로는 모
델을 변환하는 추가적인 과정 없이 앱에서 바로 사용 할 수 있다는 점과 변환과정이 필요 없기에 Darknet 에서 학습한 모델의 정확도 그대로 사용이 가능하다 는 것이다. 그러나 OpenCV로 실행할 경우 FPS가 상 당히 떨어진다는 단점이 존재한다. 본 연구의 목적은 시각장애인들이 별도의 보조인 없이 혼자서 음식의 위치와 종류를 알려주려는 목적이기 때문에 실행 속 도에 따른 사용자 편의성보단 사용자에게 정확한 정 보를 알려주는 것이 더 중요하다고 판단되었기에 본 연구에서는 2)번의 방법인 OpenCV를 사용하여 앱을 개발하는 방법으로 진행하였다. 본 시스템의 아키텍 처는 그림 4와 같다.
그림 4. 시스템 아키텍처 Fig. 4 System architecture 먼저 OpenCV라이브러리를 안드로이드 앱에 추가
한다. 추가 후 BaseLoaderCallback를 이용하여 OpenCV를 초기화 한다. OpenCV는 Camera에 접근 하여 이미지를 가져온다. 가져온 이미지를 사용자에 게 보여주기 전에 해당 이미지를 분석하기 위해 CvCameraViewListener 인터페이스를 구현하여 해당 인터페이스의 onCameraFrame 메서드를 사용하여 처 리한다. YOLO 모델의 입력으로 넣기 전에 416x416 크기로 변형한 후 모델의 연산을 진행한다. 모델의 예측값을 받아 Rect 형식으로 저장 후 판단한 객체의
클래스가 ‘숟가락’일 경우 해당 위치 값을 저장하여 이후 다른 클래스를 감지한 경우 해당 객체의 위치 값을 바탕으로 두 물체의 IoU 를 계산한다. 만약 IoU 수치가 일정값 이상일 경우 TTS를 사용하여 해당 음 식의 이름을 사용자에게 알려준다. 이 과정을 반복하 여 해당 이미지 즉 현재 프레임에 대해 분석을 완료 하면 표준 안드로이드 카메라 API를 사용하는 CameraBridgeViewBase를 통해 JavaCameraView에 이미지를 전달하여 사용자에게 보여주는 화면을 갱신 한다.
그림 5. 과적합 테스트 결과 Fig. 5 Overfit Test Results
Ⅳ. 모델 평가 및 테스트
4.1 Custom YOLO 모델 정확도 평가
빠르고 정확한 Custom YOLO모델의 평가와 테스 트를 위해 학습카테고리는 쌀밥, 숟가락 총 2개의 카 테고리로 학습을 진행하였고 이미지 또한 구축한 데 이터 셋 전체를 사용하는 것이 아닌 일부를 사용하였 다. Custom YOLO의 테스트 환경은 앱에 적용시키기 전 데스크탑 환경인 Darknet 프레임워크에서 진행하 였다. 정확도 평가 결과는 표 1과 같다.
Class AP mAP IoU
Rice 100%
99.81% 79.67%
Spoon 99.62%
표 1. Custom YOLO 모델 평가 수치 Table 1. Custom YOLO model evaluation results
전체 데이터셋의 일부분을 학습시켜 평가한 결과 쌀밥의 정확도는 100%를 달성하였고 숟가락도 약 100%에 가까운 정확도를 보여줬다. 또한 학습 및 검 증에 사용된 데이터셋에 대한 평균 정확도인 mean Average Precision 도 100%에 가까웠다. IoU의 경우 약 80%로 해당 모델은 학습이 성공적으로 진행되었 다고 판단되었다. 하지만 전체 데이터셋의 일부분만 사용하여 평가를 진행하였기에 과적합의 문제가 발생 할 경우가 있다고 판단되었다. 모델의 과적합에 빠졌 을 경우 평가 시 높은 평가 수치를 얻을 수 있기에 학습에 전혀 사용되지 않은 이미지를 통해 테스트를 추가로 진행하였다.
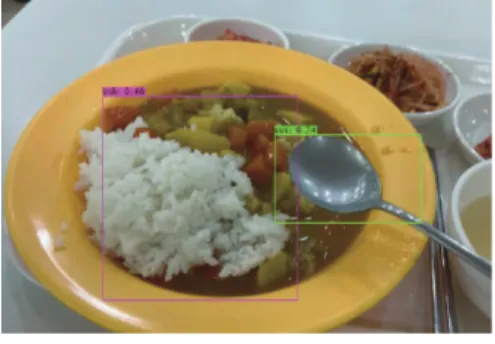
학습에 사용되지 않은 이미지를 통해 테스트를 진행 하였다. 해당 사진은 카레라이스를 촬영한 이미지로써 실제 음식은 카레라이스이지만 고의로 테스트를 방해하 기 위해 선택하였고 또한 해당 사진에는 쌀밥이 포함되 어 있기에 테스트에 사용하였다. 해당 사진의 테스트 결 과 쌀밥과 숟가락의 영역이 각각 52%, 74%로 인식되었 다. 해당 테스트의 결과로 Custom YOLO모델은 과적합 에 빠지지 않고 올바르게 학습하였다고 볼 수 있다.
4.2 안드로이드 앱 실행 테스트
앞서 테스트한 YOLO 모델을 안드로이드 앱에 적 용시켜 OpenCV 라이브러리를 활용하여 개발한 앱의 테스트 결과이다. 테스트 환경은 접시, 국그릇, 밥그릇 총 3가지 환경에서 진행하였다. 모델이 학습한 이미 지에서의 쌀밥 이미지는 오직 밥그릇에만 담겨있는 이미지이기 때문에 정확한 평가를 위해 다양한 그릇 에 담긴 밥을 대상으로 진행하였다. 그림 6은 접시에 담긴 쌀밥을 테스트 한 결과이다. 다양한 환경을 구 사하기 위해 민무늬 접시가 아닌 다양한 무늬가 있는 접시에서 테스트를 진행하였고 그 결과 쌀밥을 올바 르게 검출하였다.
그림 6. 접시에 담긴 쌀밥 감지 테스트 Fig. 6 Plated rice detection test
그림 7은 일반 밥그릇과 국그릇에 담긴 쌀밥을 테 스터한 결과인다. 해당 테스트 결과 쌀밥을 올바르게 인식하였다. 그러나 테스트 도중 비어있는 흰 그릇을 촬영했을 시 해당 부분을 쌀밥이라고 인식하였다. 해 당원인을 분석해본 결과 학습시킨 쌀밥의 이미지의 경우 흰색을 띄는 경우가 대부분이고 밥을 담고 있는 밥그릇 또한 흰색이었기에 발생한 문제점이라 파악되 었다. 그 후 쌀밥의 이미지를 다양화 하기 위해 다양 한 그릇에 담긴 쌀밥 이미지를 수집하여 학습시킨 후 다시 테스트를 해본 결과 이전 모델에 비해 빈 그릇 을 쌀밥이라 인식하는 빈도가 현저히 떨어져 모델을 개선 시킬 수 있었다.
그림 7. 일반 그릇에 담긴 쌀밥 감지 테스트 Fig. 7 Rice detection test in a regular bowl
음식 검출 테스트의 경우 효율적인 테스트 진행을 위해 TTS 실행 시 간단한 Toast Message를 추가하 여 테스트를 진행하였다. 테스트 결과 숟가락과 쌀밥 을 성공적으로 인식하였고 숟가락을 가까이 가져갈 시 TTS 및 Toast Message 또한 올바르게 작동하였 다. 비록 쌀밥, 숟가락 두 개의 클래스로만 학습시킨 제한된 상황의 모델이지만 본 연구에서 진행한 테스 트 결과를 바탕으로 많은 카테고리로 학습하더라도 올바르게 작동할 것이라 예상한다.
그림 8. 음식 검출 테스트 Fig. 8 food detection test
Ⅴ. 결론 및 향후개선 방향
본 논문에서는 딥러닝 분야 중 하나인 객체 인식 기 술의 모델 중 하나인 YOLO를 활용하여 시각장애인을 위한 식사보조 시스템의 개발 내용에 대해 기술하였다.
Object Detection 기술과 모델의 성능평가 기준인 IoU 기술을 응용하여 사용자가 자신이 먹으려는 음식을 숟 가락으로 가리키면 Bounding Box의 IoU를 계산하여 일 정수치에 도달했을 경우 TTS를 통해 알려주는 방식을 제안하였다. 본 연구에서 제안한 시스템을 사용하여 시 각장애인은 보조인 없이도 자신이 먹으려는 음식의 종 류와 위치를 알 수 있게 될 것이다. 향후 개선 방향으로 모델의 인식률 개선과 학습 음식의 카테고리를 증가시킬 것이며 추가 연구로 ‘AiHub’에서 수집한 데이터 중 음식 의 영양정보를 활용하여 자신이 먹는 음식에 대한 영양 정보를 알려주는 방안에 대해 연구할 예정이다.
감사의 글
"본 연구는 2021년 과학기술정보통신부 및 정 보통신기획평가원의 SW중심대학사업의 연구결 과로 수행되었음"(2019-0-01817)
References
[1] Korean Consumer Agency, "Investigation of the Safety Status of Walking for the Visually Impaired," Safety Report, Feb. 2021. pp.1-27.
[2] C. Ban, D. H. Kim, and B. Choi, “Design and Implementation of Order Settlement System Using Artificial Intelligence Speaker,” J. of The Korea Institute of Electronic Communication Sciences, vol. 14, no. 6, 2019, pp. 1181-1186.
[3] Y. Han, J. Sim, G. Kim, H. Lee, and J. Sin,
"Walking Assistance Device for Prevention of Accidents of Visually Impaired People," J. of The Korea Institute of Electronic Communication Sciences, vol. 14, no. 6, 2019, pp. 1241-1248.
[4] B. Liyuan and P. Younghuan."Application research on dining experiences of visually impaired users based on FAST method," In Proc.
of Ergonomics Society of Korea, Oct. 2020.
pp.99-103.
[5] W.-S. Lee, S.-Y. Park, and K.-H. Ye, "A Study on the Quality of Life depending on the Degree of Visual Impairment - With Activities of Daily Living and Instrumental Activities of Daily Living," J. of Korean Ophthalmic Optics Society, vol. 23, no. 3, Sep. 2018. pp.203-212.
[6] S. ark, alvanov, C. ee, N. Jeong, Y. ho, and H.
Je, “The development of food image detection and recognition model of Korean food for mobile dietary management,” Nutrition Research and Practice, vol. 13, no. 6, Dec. 2019, pp.
521-528.
[7] S. Lee, E. Hong, and J.Lee, “Deep Learning Technology for Smart Diet Management,” Kakao Enterprise, TECH&, Oct. 2020.
[8] S. Ruder, "An overview of gradient descent optimization algorithms", arXiv preprint arXiv:1609.04747, 2016.
[9] S. ee and M. ang, “Implementation of Object Detection and Voice Guidance System for The Visually Handicapped using Object Recognition Technology,” J. of the Institute of Electronics and Information Engineers, vol. 55, no. 11, Nov. 2018, pp. 65-71.
[10] J. oo, D. an, C. Yr, and U. h, “YOLO-based Walking Assistance Application for Blind People,” Proc. of the Korean Information Science Society Conference Research and Practice, Jeju, Korea, June 2019, pp. 1776-1778.
저자 소개
이군호(Gun-Ho Lee) 2016~ 동서대학교 컴퓨터공학부
※ 관심분야 : AI융합, 앱 시스템 개발
문미경(Mi-Kyeong Moon) 1990년 이화여자대학교 전자계산 학과 졸업(이학사)
1992년 이화여자대학교 대학원 전자계산학과 졸업(이학석사) 2005년 부산대학교 대학원 컴퓨터공학과 졸업(공 학박사)
2008년 동서대학교 소프트웨어학과 교수
※ 관심분야 : 소프트웨어공학, AI융합기술 응용