터 널 工 學
大 韓 土 木 學 會 論 文 集第26卷 第4C 號·2006年 7月 pp. 255~264
의사결정트리 기법을 이용한 터널 보조공법 선정방안 연구
A Study on the Effective Selection of Tunnel Reinforcement Methods using Decision Tree Technique
김종규*·사공명**·이준석***·이용주****
Kim, Jong-Gyu · Sagong, Myung · Lee, Jun S. · Lee, Yong-Joo
···
Abstract
The auxiliary reinforcement method is normally applied to prevent a possible collapse of the tunnel face where the ground condition is not favorable or geologic information is not sufficient. Recently, several engineering approaches have been made to choose the effective reinforcement methods using expert system such as neural network and fuzzy theory field, among oth- ers. Even if the expert system has offered many decision aid tools to properly select the reinforcement method, the quantitative assessment items are not easy to estimate and this is why the data mining technique, widely used in the field of social science, medical treatment, banking and agriculture, is introduced in this study. Using decision tree together with PDA, the decision aids for reinforcement method based on field construction data are created to derive the field rules and future study will be con- centrated on the application of the proposed methods in a variety of underground development cases.
Keywords : Data mining, decision tree, tunnel, reinforcement method, PDA
···
요 지
터널 시공시 지반상황이 불량하거나 불확실한 지질정보로 인한 붕락사고를 방지하기 위하여 지보재와 병용하여 터널보조 공법을 사용한다. 현재 보조공법에 관련된 전문가 시스템은 인공신경망, 퍼지추론 등의 연구가 진행되었고 터널 기술자에게 보조공법을 결정하는데 많은 도움을 주고 있는 상황이나 보조공법을 결정하는데 있어 정량적인 평가항목을 정하는데 어려움 이 많은 것으로 파악되고 있다. 따라서, 본 연구에서는 사회과학, 의료, 금융, 농업 등 다양한 분야에 걸쳐 데이터분석에 이 용되는 데이터마이닝 기법을 공학분야에 적용시켜 보조공법 설계자료를 바탕으로 보조공법의 의사결정 규칙을 추론하고 PDA를 적용한 전문가 시스템을 구축하였다.
핵심용어 : 데이터 마이닝, 의사결정트리, 터널, 보조공법, PDA
···
1. 서 론
급속한 산업과 사회 발달로 인해 지하공간 개발에 대한 관심이 증가하면서 도로 및 철도터널 , 지하철 건설의 안전성 이 주요 이슈가 되고 있다 . 최근 터널 건설이 증가하면서 다양한 문제점에 제기된 바 있으며 , 특히 산악터널과 달리
도심지 터널의 경우 시공 중 소음 및 진동 , 붕괴 등의 사고 가 발생할 개연성이 높다 . 도심지 터널에서 발생한 사고는 막대한 인명피해와 재산손실을 야기시키므로 시공 중 보조 공법을 적용하여 가능한 불확실하고 불안정한 사고를 방지 하는 노력이 필요하다 . 하지만 지반의 불확실성으로 뚜렷한 보조공법을 제시하기가 어려우며 , 터널현장 기술자의 경험을 바탕으로 보조공법을 결정하는 경우가 빈번히 발생하게 된다 . 1982 년 제 1 기 서울지하철 건설 이후 도입단계부터 지금까
지 보조공법의 시공경험 및 이론적 개념이 발전하고 있으나
( 이인기 외 , 2004) 과다설계의 가능성이 대두되면서 효율적
인 보조공법을 결정하기 위한 전문가 시스템 구축연구가 수 행된 바 있다 . 특히 인공신경망과 퍼지추론을 적용한 연구가 활발히 이루어지고 있으며 실제 터널현장의 데이터를 학습 시켜 상관성을 도출한 후 부족한 지질자료를 획득하는 인공 신경회로망의 개발이나 ( 문현구 외 , 1994), 기존 RMR 분류 법의 항목을 신경망을 이용하여 국내 터널현장의 데이터로 학습시켜 한국형 터널 암반분류법을 제시한 경우도 있다 ( 양
형식 외 , 1999). 또한 터널의 안정성을 퍼지추론을 이용하여
판단하고 , 안정성 등급에 따른 터널 보강공법을 선정하는 전
문가 시스템이 연구된 바 있고 ( 김창용 외 , 2000), 퍼지추론
과 인공신경망을 동시에 적용한 뉴로 - 퍼지기법을 이용하여 터널지반의 등급을 평가하기 퍼지추론 시스템이 연구되었다
*한국철도기술연구원연구원
(E-mail : [email protected])
**정회원ㆍ한국철도기술연구원선임연구원
(E-mail : [email protected])
***정회원ㆍ한국철도기술연구원책임연구원
(E-mail : [email protected])
****정회원ㆍ포항산업과학연구원선임연구원
(E-mail : [email protected])
( 조만섭 외 , 2003). 국외의 경우 터널의 지보공결정을 위해 퍼지추론을 이용한 전문가시스템을 구성하였고 (Kalamaras,
1997), 터널의 불안정 정도를 퍼지추론을 이용하여 분류하고 ,
분류등급별 보강대책을 선정할 수 있는 시스템을 연구하였 으며 (Chikahisa 등 , 1997), NATM 터널의 RMR 등급별 안 정성을 인공신경망을 통해 제시한 바 있다 (Sou-Sen Leu 등 , 2001).
본 연구에서는 데이터 마이닝 (Data mining) 을 이용한 터 널 보조공법의 선정기법과 선정과정의 자동화를 위한 PDA S/W 를 개발하였다 . 데이터 마이닝은 대용량의 자료로부터 사 용목적에 부합한 유용한 정보를 선별하는 기법으로 데이터 사이에 숨겨진 패턴을 발견하고 규칙을 추론함으로써 , 의사 결정을 지원하는 기법이다 . 특히 , 지난 수십 년간 축척된 전 자상거래 , 주식거래 , 은행거래 , 신용카드결제 및 세금 등의 대용량 자료의 경우 , 데이터의 양은 계속 증가하는 상황에서 의미있는 정보를 찾아내는 과정을 데이터마이닝이라 부를 수 있다 . 특히 과거의 경우 제한된 정보범주에서는 단지 의사 결정자의 직관에 근거하여 의사결정을 내리는 전문가시스템 ,
즉 전문가의 지식을 지식베이스에 수동으로 입력하여 구축 한 경우 왜곡과 오류를 낳기 쉬운 반면 , 데이터마이닝을 통 해 중요한 데이터 패턴을 찾아내는 일련의 과정을 통해 보 다 객관적이고 효율적인 의사결정을 수행할 수 있다 ( 최기헌 ,
1995). 따라서 본 연구에서는 터널 보조공법 선정분야에 데
이터 마이닝 기법을 적용시켜 , 국내 시공된 터널 설계데이터 에서 터널 보조공법에 관련된 인자의 교호효과를 분석함으 로써 터널 시공 중 현장 상황에 따른 보조공법을 제시할 수 있는 방안을 연구하였다 .
2. 데이터마이닝기법의 적용 2.1 의사결정트리
의사결정트리는 분석대상에 대한 분류나 예측을 수행하기 위해서 사용되는 분석기법으로 대용량의 데이터 내에 존재 하는 관계 , 패턴 및 규칙 등을 탐색하고 모형화하는 역할을 수행하며 , 신경망이나 판별분석 등에 의한 방법과는 달리 적
용결과에 의해 규칙을 명확하게 나타낼 수 있다 . 또한 예측 모형 자체뿐만이 아니라 최적결과를 검색하거나 분석에 필 요한 변수 간의 교호효과 , 즉 두 개 이상의 입력변수가 결 합하여 목표변수에 어떻게 영향을 주는지를 찾아내는데 이 용된다 . 특히 트리구조로 표현되기 때문에 다른 기법들과 비 교하여 쉽게 이해되고 설명할 수 있으며 , 임의의 데이터 범
주에서 동일한 특성을 갖는 집합으로 구분하여 특성을 정의 하고 목표변수에 대한 규칙을 추론하여 미래의 대한 예측을
할 경우 유용하게 활용할 수 있다 ( 최기헌 , 1995).
그림 1 은 의사결정트리구조로서 마디 (node) 로 구성되며 , 뿌
리마디 (root node) 로부터 시작하여 하위마디로 자식마디 (child
node) 를 계속적으로 분리 , 형성해 나감으로써 완성된다 . 뿌리
마디와 반대로 트리의 가장 끝에 위치하여 가지가 분리되지
않는 마디를 끝마디 ( 종단마디 , leaf node) 라고 하며 , 뿌리마
디부터 종단마디까지의 분리단계를 깊이 (depth) 라고 한다 . 그 림 1 에서 총 6 개의 최종마디가 생성되었고 상위마디의 규칙
을 가정 - 결론 (IF-THEN) 방식으로 추론할 수 있다 . 예를 들
어 , 최종마디 “No(45%) ” 의 경우 “IF Own home=Rent AND Family income=High THEN Savings=No" 와 같은 규칙이 추론된다 .
2.2 의사결정트리의 알고리즘
의사결정트리는 뿌리마디에서 최종마디인 종단마디까지 가 지를 분리시켜 마디를 생성하는 일련의 과정으로 구성된다 .
이때 상위마디에서 하위마디로 분리되는 분리기준은 분할 알 고리즘에 따라 결정된다 . 의사결정트리의 대표적인 알고리즘 은 CHAID(Chi-squared Automatic Interaction Detection)
알고리즘 (Kass, 1980) 으로 명목형 , 순서형 , 연속형 등 모든
종류의 목표변수와 분류변수에 적용이 가능하며 , Exhaustive CHAID 알고리즘 (Biggs 등 , 1991) 으로 발전하였다 . 그 밖에
CART(Classification and Regression Tree), QUEST(Quick, Unbiased, Efficient, Statistical), C5.0, C4.5 알고리즘 등이
있으며 , 표 1 은 각각의 알고리즘의 특징을 나타낸다 ( 강현철 외 , 2001).
그림 1. 의사결정트리의 흐름도(강현철 외, 2001)
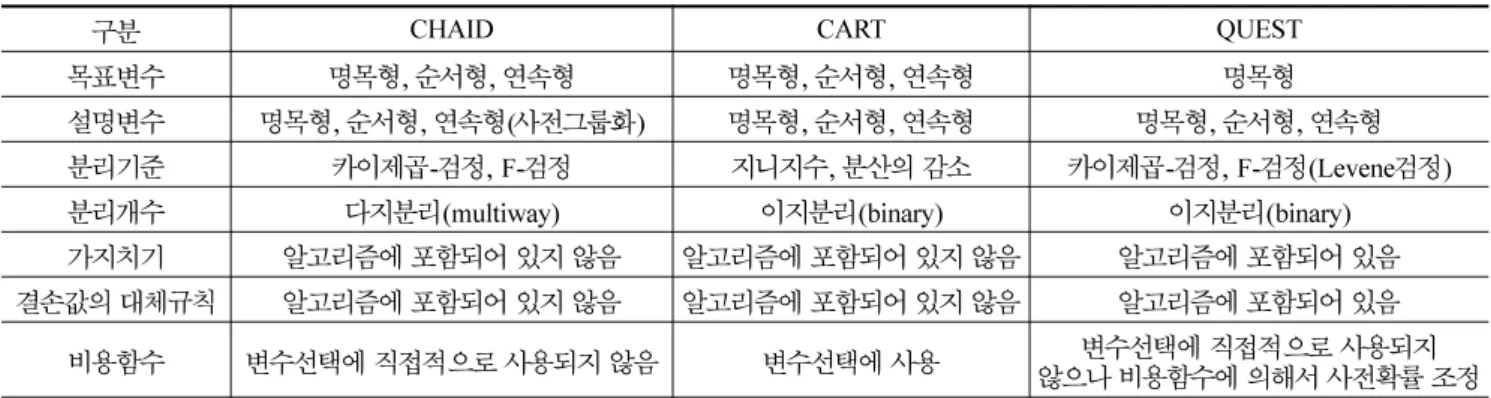
표 1. 의사결정트리의 알고리즘
구분 CHAID CART QUEST
목표변수 명목형 , 순서형 , 연속형 명목형 , 순서형 , 연속형 명목형 설명변수 명목형 , 순서형 , 연속형 ( 사전그룹화 ) 명목형 , 순서형 , 연속형 명목형 , 순서형 , 연속형
분리기준 카이제곱 - 검정 , F- 검정 지니지수 , 분산의 감소카이제곱 - 검정 , F- 검정 (Levene 검정 )
분리개수 다지분리 (multiway) 이지분리 (binary) 이지분리 (binary)
가지치기 알고리즘에 포함되어 있지 않음 알고리즘에 포함되어 있지 않음 알고리즘에 포함되어 있음 결손값의 대체규칙 알고리즘에 포함되어 있지 않음 알고리즘에 포함되어 있지 않음 알고리즘에 포함되어 있음
비용함수 변수선택에 직접적으로 사용되지 않음 변수선택에 사용 변수선택에 직접적으로 사용되지
않으나 비용함수에 의해서 사전확률 조정
CHAID 은 카이제곱 - 검정 ( 이산형 목표변수 ) 또는 F- 검정 ( 연 속형 목표변수 ) 을 이용하여 분리와 병합을 반복하면서 Pearson 카이제곱 또는 우도비 (Likelihood ratio) 카이제곱 통계량을 분리기준으로 사용한다 . 카이제곱 통계량은 관측도 수 ( f
ij) 로 이루어진 r ( 설명변수 ) × c ( 목표변수 ) 분할표로부터 계산되며 , 분할표의 구조는 표 2 와 같다 .
분할표로부터 Pearson 의 카이제곱 통계량은 다음과 같다 . (1)
여기서 두 통계량의 자유도 (degree of freedom) 는 ( r− 1)( c−
1) 로 통일하며 e
ij는 분포의 통일성 또는 독립성의 가설 하에
서 계산된 기대도수 (expected frequency) 로서 다음과 같다 . (2)
분할표로부터 우도비 카이제곱 통계량은 다음과 같다 . (3)
카이제곱 통계량이 자유도에 비해서 매우 작다는 것은 설 명변수의 각 범주에 따른 목표변수의 분포가 서로 동일하여 설명변수가 목표변수의 분류에 영향을 미치지 않는 것이다 .
한편 자유도에 대한 카이제곱 통계량이 크고 작음은 해당집 단에서 그 조건이 틀렸다고 잘못 생각할 확률인 p- 값으로 표현되는데 , 카이제곱 통계량이 자유도에 비해 작으면 p- 값 은 증가하므로 , p- 값이 가장 작은 설명변수에서 최적분리가
발생하는 것이다 . 표 3 은 Pearson 의 카이제곱 통계량을 이
용한 분할표의 예이다 .
표 3 의 분할표에서 자유도는 가로축이 GOOD, BAD 의 2
개 항목과 세로축 RIGHT, LEFT 의 2 개 항목으로 (2-1) ×
(2-1) 로 1 이다 . 이때 관측도수로부터 기대도수를 계산하고 ,
기대도수와 관측도수로부터 카이제곱통계량을 계산한 결과
46.75 가 산출되었다 . 카이제곱통계량 분포표에서 자유도가 1
인 경우 유의확률을 0.05 로 정의할 때 p- 값은 0.03841 이 산 출되며 , p- 값이 카이제곱통계량보다 작기 때문에 가지의 분 리가 가능하게 된다 .
분리알고리즘을 통해 자식마디를 형성시키는 과정은 그림
2 와 같다 .
3. 터널 보조공법의 분류 및 예측
3.1 터널 보조공법 결정을 위한 입력변수와 목표변수의 결정
터널단면의 계획 , 굴착방법의 선정 , 지보형식의 결정 등을 지배하는 주요 요소는 암종 , 풍화도 , 절리 , 파쇄대 등 암반 상태와 역학적 특성 , 변형특성 및 지하수 상태 등이다 . 이들 요소 중 터널의 굴착방법이나 지보형식을 선정하는데 중요 한 사항은 암반상태와 역학적 특성이며 특히 지보형식을 결 정하기 위한 암반의 분류는 암질의 상태에 의존하고 터널보 조공법 적용시 암질의 상태는 중요한 항목이다 ( 한국철도시
설공단 , 2004). 따라서 터널 보강계획을 수립하는데 있어서
보강목적에 적합한 공법을 선정하기 위해서는 해당 지점의 지반조건과 시공환경을 고려한 조사항목을 표 4 와 같이 선 정하였다 .
x
2( f
ij– e
ij)
2e
ij---
∑
i j,=
e
ijf
i× f
.jf ..
---
=
x
22 f
iji j,