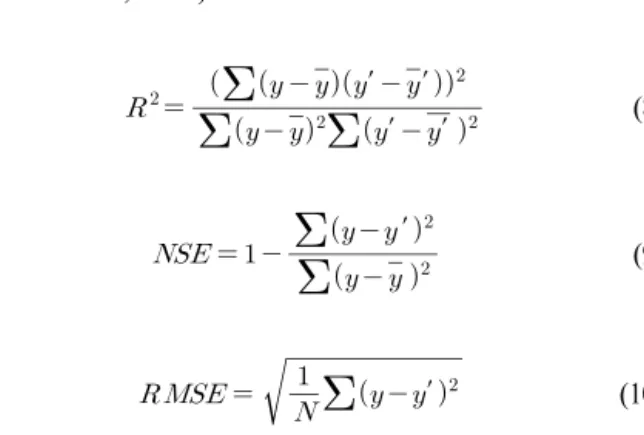홍수량 예측 인공신경망 모형의 활성화 함수에 따른 영향 분석
Impact of Activation Functions on Flood Forecasting Model Based on Artificial Neural Networks
김지혜a⋅전상민b⋅황순호c⋅김학관d⋅허재민e⋅강문성f,†
Kim, Jihye⋅Jun, Sang-Min⋅Hwang, Soonho⋅Kim, Hak-Kwan⋅Heo, Jaemin⋅Kang, Moon-Seong
ABSTRACT
The objective of this study was to analyze the impact of activation functions on flood forecasting model based on Artificial neural networks (ANNs).
The traditional activation functions, the sigmoid and tanh functions, were compared with the functions which have been recently recommended for deep neural networks; the ReLU, leaky ReLU, and ELU functions. The flood forecasting model based on ANNs was designed to predict real-time runoff for 1 to 6-h lead time using the rainfall and runoff data of the past nine hours. The statistical measures such as R2, Nash-Sutcliffe Efficiency (NSE), Root Mean Squared Error (RMSE), the error of peak time (ETp), and the error of peak discharge (EQp) were used to evaluate the model accuracy.
The tanh and ELU functions were most accurate with R2=0.97 and RMSE=30.1 (m3/s) for 1-h lead time and R2=0.56 and RMSE=124.6∼124.8 (m3/s) for 6-h lead time. We also evaluated the learning speed by using the number of epochs that minimizes errors. The sigmoid function had the slowest learning speed due to the ‘vanishing gradient problem’ and the limited direction of weight update. The learning speed of the ELU function was 1.2 times faster than the tanh function. As a result, the ELU function most effectively improved the accuracy and speed of the ANNs model, so it was determined to be the best activation function for ANNs-based flood forecasting.
Keywords: Artificial neural networks; activation function; flood forecasting; ReLU; sigmoid
Ⅰ. 서 론
기후변화로 인해 기상의 변동성이 증가함에 따라, 우리나 라에서는 집중호우로 인한 홍수 피해가 빈번히 발생하고 있 다. 지난 10년 (2009∼2018년) 동안 홍수로 인해 연평균 3,200 억 원 규모의 피해가 발생하였으며 이는 전체 재해 피해액의 88%에 달하는 수준이다 (행정안전부, 2019). 홍수로 인한 피
해는 막대한 경제적 손실을 일으킬 뿐 아니라 사회, 환경, 보 건 등 전반적 생활에도 영향을 미치게 된다. 따라서 사전에 홍수 피해의 규모를 예측하고 적절한 대비 체계를 갖추어 피 해를 최소화해야 하며, 이를 위해 유역의 강우-유출 해석을 기반으로 정확한 홍수량의 예측이 선행되어야 한다.
강우-유출 과정은 시⋅공간적 변동이 심하고 비선형성을 포함하기 때문에 해석에 어려움이 있으며 (Kang et al., 2006), 이를 모의하기 위한 개념적 (conceptual) 또는 물리적 기반 (physically based)의 수문 모형은 수많은 매개변수 값을 정확 하게 추정하는 데에 어려움이 있어 모형의 적용에 한계가 있 다 (Young et el., 2017; Adamowski and Prasher, 2012). 반면에, 머신러닝 (machine learning) 기반의 수문 모형은 실제 물리현 상에 대한 이해 없이 입⋅출력 자료의 관계만을 분석하기 때 문에 최소한의 자료만으로도 유출량의 모의가 가능하다 (Jeung et al., 2019; Solomatine, 2008).
인공신경망 (Artificial Neural Networks)은 머신러닝의 대표 적인 기법으로, 강우량, 유출량의 단순한 자료 조합만으로 강 우-유출 과정의 비선형성을 효과적으로 구현할 수 있어서 유 출량 모의를 위한 다양한 연구에 적용되어 왔다. Kang and Park (2003)은 인공신경망을 이용하여 영산강 유역에서 단기 홍수량을 예측하였고, Kang et el. (2006)은 선행시간 1∼6시 간에 대해 인공신경망과 Grey model의 홍수량 모의 성능을
aPh.D. Student, Department of Rural Systems Engineering, Seoul National University
b Ph.D. Student, Department of Rural Systems Engineering, Seoul National University
cResearch Professor, Research Institute of Agriculture and Life Sciences, Seoul National University
d Assistant Professor, Graduate School of International Agricultural Technology, Institutes of Green Bio Science and Technology, Seoul National University
eUndergraduate Student, Department of Rural Systems Engineering, Seoul National University
fProfessor, Department of Rural Systems Engineering, Research Institute of Agriculture and Life Sciences, Institutes of Green Bio Science and Technology, Seoul National University
† Corresponding author
Tel.: +82-2-880-4582, Fax: +82-2-873-2087 E-mail: [email protected]
Received: July 30, 2020 Revised: October 12, 2020 Accepted: October 14, 2020
비교⋅분석하였으며, Sarkar and Kumar (2012)는 Ajay 강 유 역에서 홍수량을 예측하였다. Young et al. (2017)은 인공신경 망으로 극한 호우 사상에 대한 홍수량을 모의하고 물리적 기 반의 수문 모형에 의한 결과와 비교하였으며, Hu et al. (2018) 은 인공신경망과 장단기메모리 신경망 모형의 홍수량 모의 결과를 비교한 바 있다.
인공신경망의 활성화 함수 (activation function)는 입력값으 로부터 다음 계층으로 전달하는 출력신호를 생성하는 함수로, 활성화 함수의 선택에 따라 출력 결과가 다르게 형성된다. 실 제 물리현상에 대한 분석이 아닌 입력 자료와 출력 자료만을 이용해 강우-유출 관계를 분석하는 인공신경망의 특성상, 모 형의 구축에서 활성화 함수의 선택은 매우 중요한 요소이다.
수문 분야에 인공신경망을 적용한 기존의 연구에서는 대부 분 sigmoid 함수를 활성화 함수로 적용하였다. 하지만 sigmoid 함수는 신경망에서 층의 깊이가 깊어질수록 앞 단으로 기울 기가 잘 전달되지 않는 ‘기울기 소실 문제 (vanishing gradient problem)’가 존재하여 은닉층의 활성화 함수로 사용이 지양된 다 (Goodfellow et al., 2016). 함수 tanh (hyperbolic tangent) 역시 인공신경망에 많이 적용되어 왔으며, sigmoid 함수와 비 교해 기울기 소실 문제가 일부 개선되긴 하였으나 여전히 심 층의 신경망에 적용하기에는 한계가 있다. 딥러닝 (deep learning)의 발달과 함께 신경망의 구조가 점차 복잡해짐에 따 라 기존의 sigmoid, tanh 함수로는 좋은 성능을 내기가 어려워 지고 있으며, 심층의 신경망에도 적용이 가능한 활성화 함수 를 선택할 필요가 있다.
최근 머신러닝 분야에서는 기존의 sigmoid, tanh 함수에 대 한 대안으로 ReLU (Rectified Linear Unit) 함수와 그 변종인 leaky ReLU, ELU 등의 함수가 권장되고 있다 (Clevert et al., 2016; Xu et al., 2015). ReLU 계열의 함수는 기울기 소실 문제 가 없기 때문에 심층의 신경망에 적용이 가능하며, 간단한 선
형함수로 이루어져서 계산 속도가 비교적 빠르다는 장점이 있다. 따라서 인공신경망을 이용한 수문 분석에서 기존의 sigmoid, tanh 함수와 ReLU 계열의 함수를 비교하고, 이에 대 한 적용성을 검토할 필요가 있다.
본 연구에서는 인공신경망 기반의 실시간 홍수량 예측 모 형에서 활성화 함수에 따른 영향을 분석하고, 홍수량 모의를 위한 최적의 활성화 함수를 제시하고자 한다.
Ⅱ. 재료 및 방법 1. 인공신경망 가. 인공신경망 개요
인공신경망 (Artificial Neural Networks, ANNs)은 머신러닝 기법의 하나로 인간 뇌 신경세포의 작용을 모사한 것이다. 인 공신경망은 입력층 (input layer), 은닉층 (hidden layer), 출력층 (output layer)으로 구성되며, 입력값 ()에 가중치 ()를 곱하 고 편차 ()를 더한 후 활성화 함수를 적용한 값이 다음 층으 로 출력되는 구조이다. Fig. 1은 은닉층이 1개인 인공신경망의 구조를 나타내며, 은닉층의 활성화 함수 에 대한 은닉층의 값 와 출력층의 활성화 함수가 인 경우 출력층의 값
는 Eqs. (1), (2)와 같이 계산된다.
×
(1) × (2)
출력층에서 나온 출력값 (output value)과 목푯값 (target value)의 차이로부터 가중치를 업데이트하여 인공신경망이
Fig. 1 Structure of artificial neural networks
입력값 (input value)과 목푯값의 관계를 학습할 수 있도록 하 는 것이 인공신경망의 학습 (training) 과정이다. 인공신경망의 학습은 일반적으로 오류 역전파 과정을 따르며, 출력값과 목 푯값의 오차가 최소가 되고 최적의 가중치를 찾을 때까지 반 복 계산하여 가중치를 업데이트한다.
나. 오류 역전파 기법
인공신경망에서 입력값을 통해 출력값을 예측하는 과정 (순전파 과정)을 완료한 후, 오류 역전파 (backpropagation) 과 정을 통해 출력값과 목푯값의 오차로부터 앞 단의 가중치를 조절한다. Fig. 1과 같이 입력값 ()을 통해 출력값 ()을 얻은 후, 출력값 ()을 목푯값 ()과 비교하여 오차 ()를 계산한다.
그리고 가중치 ()가 오차에 미친 영향을 바탕으로 가중치를 업데이트하기 위하여 오차를 각 가중치로 편미분 한다. Fig.
1에서 은닉층의 가중치 를 업데이트하기 위한 편미분은 Eq. (3)과 같으며, 이는 연쇄 법칙에 따라 4개 편미분 항의 곱으로 분해된다.
(3)
Eq. (3)의 첫 번째 편미분 항은 오차를 계산하는 손실 함수 (loss function)에 따라 계산되며, 두 번째 항과 네 번째 항은 Eq. (2)과 Eq. (1)로부터 각각 , 이 된다. 세 번째 항은 은닉층의 활성화 함수 에 따라 계산되며, 가 sigmoid 함수 인 경우 도함수가 이므로 이 된다. 이를 적 용하여 Eq. (3)의 편미분을 계산한 결과는 Eq. (4)와 같다.
(4)
최종적으로 편미분 결과에 학습률()를 적용하여 Eq. (5) 와 같이 가중치를 업데이트한다.
(5)
오류 역전파 과정은 활성화 함수에 의해 큰 영향을 받으며, 가장 대표적인 것이 ‘기울기 소실 문제’이다. 은닉층의 활성화 함수 가 sigmoid 함수인 경우 은닉층의 값 는 0∼1의 범위 를 가지며, 이에 대한 편미분 는 0∼0.25의 범위를 갖게 된다. 만약 은닉층의 수가 늘어난다면 그 수만큼 0.25 이하의 값을 갖는 편미분 항이 여러 번 곱해지게 된다. 그 결
과, 값이 0에 가까워짐에 따라 가중치의 업데이트가 거의 이루어지지 않는 ‘기울기 소실 문제’가 발생하여 인공신 경망의 학습 성능이 크게 저하된다.
오류 역전파 과정에서 활성화 함수로 인해 발생하는 또 다 른 문제는 가중치 업데이트의 방향 제한이다. Fig. 1에서 에 연결된 가중치 ∼를 업데이트할 때 오차의 편미분은 Eq. (4)의 에 ∼을 적용한 것으로, 를 제외한 모든 항의 값이 동일하다. 이때 이전 층으로부터 전달된 입력값 ()의 부호가 모두 동일하다면, 에 연결된 모든 가중치에 대해 동일한 부호의 업데이트가 적용된다. 따라서 다층의 신 경망에서 sigmoid 함수와 같이 함숫값이 모두 양수인 함수가 활성화 함수로 적용된 경우, 다음 층에서는 양수인 값만을 입 력받게 되므로 한 노드에 연결된 가중치에 대해 업데이트 방 향이 (+, …, +) 또는 (-, …, -)으로 제한되어 최적의 값에 도달 하기까지 더 많은 계산이 소요된다.
이처럼 활성화 함수는 오류 역전파 과정에 큰 영향을 주어 인공신경망의 학습 성능을 변화시키는 중요한 요소로, 효율 적인 학습을 위하여 적절한 활성화 함수를 선택하는 것이 중 요하다.
다. 활성화 함수
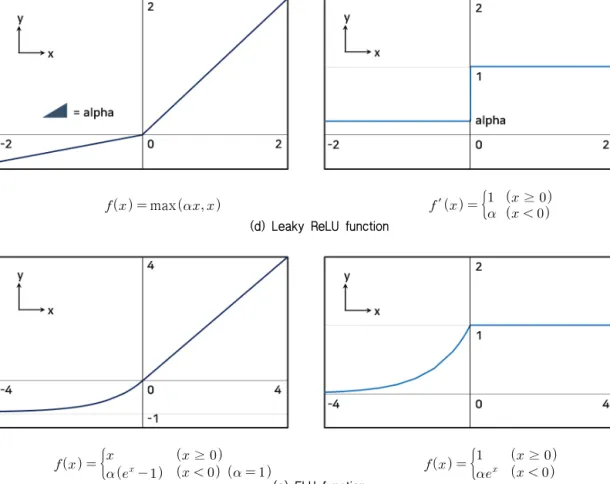
활성화 함수는 입력층에서 은닉층으로, 은닉층에서 다음 은닉층 또는 출력층으로 신호를 전달하기 위한 함수이다. 입 력 자료와 출력 자료 사이의 비선형 관계를 분석하기 위하여 비선형 함수를 활성화 함수로 적용한다. 활성화 함수의 종류 로는 sigmoid, tanh (hyperbolic tangent), ReLU (Rectified Linear Unit), leaky ReLU, ELU (Exponential Linear Unit) 등이 있으며, Fig. 2는 각 함수의 수식과 그래프의 개형, 도함수의 그래프 개형을 나타낸다.
함수 sigmoid는 0∼1의 범위에 분포하며 그래프는 (0, 0.5) 점에 대해 대칭이다. 입력값이 매우 큰 경우 함숫값은 1에 근 사하며, 값이 매우 작은 경우 0에 근사한다. 앞서 언급한 바와 같이, sigmoid 함수는 기울기 소실 문제와 가중치 업데이트 방향의 제한으로 인해 은닉층의 활성화 함수로 적용하기에 한계가 있다. 또한, 수식에 지수함수가 포함되기 때문에 신경 망의 구조가 복잡해질수록 계산 속도가 느려질 수 있다.
함수 tanh는 –1∼1의 범위에 분포하며 그래프는 원점에 대 해 대칭이다. 이에 sigmoid 함수에서 함숫값이 모두 양수인 한계점을 보완할 수 있고, 도함수 값의 범위도 0∼1로 sigmoid 함수에 비해 크다. 그러나 기울기 소실 문제와 지수함수로 인 한 속도 저하 문제가 여전히 존재한다.
ReLU 함수는 sigmoid 함수와 tanh 함수에 존재하는 기울기 소실 문제를 해결한 함수이다. ReLU 함수는 가 양수인 경우 기울기가 1로 일정하기 때문에 입력값이 커지더라도 기울기 소실 문제가 발생하지 않으며, 지수함수로 구성된 sigmoid, tanh 함수보다 계산 속도가 빠르다. 그러나 가 음수인 경우 기울기가 0이 되어 노드가 비활성화되는 문제점 (dying ReLU) 을 지니며, 0 부근에서 함수가 불연속이라는 한계가 있다.
Leaky ReLU 함수는 ReLU 함수에서 노드가 비활성화되는
문제를 해결하기 위해 제안된 함수로, ReLU 함수에 비해 높 은 성능을 내는 것으로 알려져 있다 (Xu et al., 2015). 이 면 기울기가 1인 직선이고, 이면 기울기가 인 직선으 로 이루어져 있으며, 이때 는 일반적으로 0.01을 적용한다 (Geron, 2019). Leaky ReLU 함수는 음의 입력값에 대해서도 노드가 비활성화되지 않고 계속 작용할 수 있다는 장점이 있 지만, ReLU 함수와 마찬가지로 0 부근에서 함수가 불연속이 라는 한계를 지닌다.
′
(a) sigmoid function
′
(b) tanh function max ′ ≥
(c) ReLU function
ELU 함수는 ReLU 계열 함수들이 0 부근에서 불연속이 되 는 것을 개선한 함수로, 인 구간에 지수함수가 포함되어
인 구간의 직선과 부드럽게 연결되는 특징을 갖는다.
ELU 함수는 다른 ReLU 계열 함수들보다 학습 속도나 정확도 측면에서 더 높은 성능을 내는 것으로 알려져 있다 (Clevert et al., 2016).
2. 홍수량 예측 인공신경망 모형
본 연구에서는 인공신경망 기반의 홍수량 예측 모형을 구 축하기 위해 파이썬 (python 3.7.4)의 머신러닝 플랫폼인 tensorflow (version 2.0)와 keras (version 2.2.4)를 사용하였다.
홍수량 예측을 위해 과거 강우량과 유출량을 입력값으로, 미 래 유출량을 목푯값으로 적용하였다.
가. 모형의 구조
국내 홍수예보지점의 홍수 발생 가능성은 선행시간 6시간 을 확보하여 예보하도록 하고 있다. 따라서 인공신경망의 입 력층에는 18개 노드를, 출력층에는 6개 노드를 설정하여, 과
거 9시간 동안의 강우량( ∼)과 유출량( ∼) 자 료를 이용해 1∼6시간 후의 유출량( ∼ )을 예측하는 모형을 구축하였다. 자료의 표준화를 위하여 강우량과 유출 량은 각각의 최댓값과 최솟값을 기준으로 0.05∼0.95 사이의 값으로 변환하여 입력하였다. 홍수량 예측 인공신경망 모형 의 구조식은 Eq. (6)과 같다.
⋯ ⋯ ⋯ (6)
신경망의 층이 깊어질수록 sigmoid 함수와 tanh 함수의 기 울기 소실 문제가 커질 가능성이 있기 때문에 은닉층의 수를 1∼5층으로 달리하며 활성화 함수에 따른 차이를 분석하였다.
은닉층별 노드의 개수는 입력층과 가까운 층부터 순서대로 15개, 10개, 5개, 5개, 5개로 구성하였다 (Fig. 3). 활성화 함수 로는 sigmoid, tanh, ReLU, leaky ReLU, ELU의 5가지를 적용 하였으며, 초매개변수 (hyperparameter)는 동일하게 고정하여 비교⋅분석하였다.
max ′ ≥
(d) Leaky ReLU function
≥ ≥
(e) ELU function
Fig. 2 Summary of the activation functions
Fig. 3 Structure of the flood forecasting model based on Artificial neural networks
나. 모형의 학습
인공신경망 모형의 학습을 위해 오류 역전파 기법을 적용 하였다. 총 오차의 산정을 위한 손실 함수로는 MSE (Mean Squared Error)를 적용하였다. MSE는 오차 제곱의 평균으로, 목푯값을 , 출력값 ′, 자료의 수를 N이라 할 때 계산식은 Eq. (7)과 같다. 최적화 함수로는 Adam (Adaptive Moment Estimation) (Kingma and Ba, 2014)을 사용하였고, 학습률에는 0.001를 적용하였다.
′ (7)
오차의 수렴 속도에 따른 학습 성능을 비교하기 위하여, 결과가 일정 수준에 도달하면 학습을 종료할 수 있도록 keras 의 내부 기능 중 하나인 ‘조기 종료 (Early Stopping)’ 함수를 적용하였다. keras의 조기 종료 함수는 오차가 감소한 시점으
로부터 일정 반복 횟수만큼 추가로 학습을 진행하는 동안 오 차의 감소량이 최소 감소량 을 넘지 못하면 학습을 종료시키 는 함수이다 (Chollet, 2015).
본 연구에서는 검증 (test) 결과의 MSE를 조기 종료 함수의 오차로 설정하였다. 오차의 최소 감소량은 학습이 어느 정도 완료되어 오차의 감소가 더이상 이루어지지 않는 시점을 찾 기 위해 0으로 설정하였다. 추가 반복 횟수의 경우, 오차가 충분히 감소하기 전에 학습이 종료되는 것을 방지하기 위해 여유 있게 설정하되, 너무 과다할 경우 오차가 발산할 수 있으 므로 시행착오법에 따라 50회로 설정하였다. 따라서 최소 오 차 (최적의 학습 결과)가 발생하는 시점은 학습의 종료 시점으 로부터 50회 이전의 시점이 되며, 이때의 반복 횟수를 이용하 여 활성화 함수별 학습 속도를 분석하였다.
3. 연구대상지
인공신경망은 실제 물리현상이 아닌 입⋅출력 자료의 관계 만을 분석하기 때문에 강우-유출 자료를 선정할 때 일관적인 특성을 유지하며 장기간 축적된 자료를 사용하는 것이 중요 하다. 따라서 본 연구에서는 10년 이상의 1시간 단위 강우-유 출 자료를 갖추고 있으며, 자료 기간에 대규모 수리 구조물이 건설되지 않은 유역을 연구대상지로 선정하고자 하였다. 이 와 같은 기준을 통해 경기도 양평군에 위치한 흑천 유역을 연구대상지로 선정하였다. 흑천 유역은 한강 대권역, 남한강 하류 중권역에 속하며, 유역면적은 312.89km2이다. 흑천 유역 의 기상관측소로는 양평 기상관측소, 홍천 기상관측소가 있 으며, 두 기상관측소의 Thiessen 면적비는 각각 77.8%, 22.2%
이다. 유량 관측은 흑천 유역 말단의 흑천교에서 이루어지고 있다 (Fig. 4).
Fig. 4 Location of Heukcheon basin and the weather and gauging stations
양평, 홍천 기상관측소의 강우 자료와 흑천교 유량관측소 의 유출량 자료를 사용하여 모형의 입⋅출력 자료를 구축하 였다. 자료의 시간 간격은 1시간이며, 2007년부터 2018년까지 12년의 자료로부터 28개의 수문곡선을 분리하였다. 전체 수 문곡선 중 75% (21개)는 모형의 학습에, 25% (7개)는 모형의 검증에 사용하였다.
4. 모형의 검증 가. 모형의 성능 평가
인공신경망 기반 홍수량 예측 모형의 성능을 비교하기 위해 5가지 지표를 적용하였다. 우선, 홍수량 예측에 대한 전반적인 평가를 위하여, 통계변량인 (coefficient of determination), NSE (Nash–Sutcliffe Efficiency), RMSE (Root Mean Squared Error)을 적용하였다. 또한, 홍수 예측에 있어서 첨두시간과 첨두유출량을 정확하게 예측하는 것이 중요하므로, 이에 대 한 모의 성능 평가를 위하여 ETp (Error of Time to peak discharge)와 EQp (Error of peak discharge)를 적용하였다 (Hu et al., 2018).
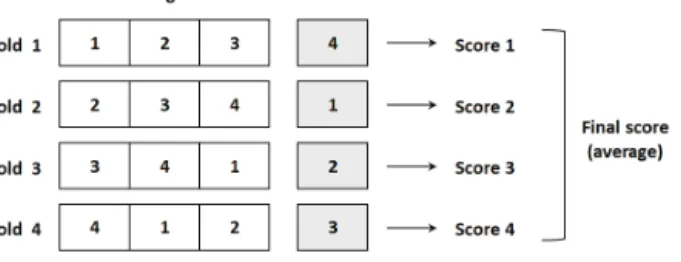
는 모형의 출력값과 목푯값 사이의 상관관계를 나타내 는 지표로 0∼1의 범위에서 나타나며, 가 0이면 출력값과 목푯값 사이에 상관관계가 없고, 1이면 모형의 출력값이 모든 목푯값을 정확히 설명한다고 판단한다. NSE는 모형의 예측 능력을 평가하는 통계적 지표로 -∞∼1의 범위에서 나타나며, NSE가 1에 가까울수록 출력값이 목푯값의 경향을 잘 반영하 고, NSE가 음의 값을 가지면 출력값보다 목푯값의 평균이 더 예측 능력이 좋은 것으로 판단한다. 는 출력값과 목푯값이 유사하지 않아도 서로 선형관계를 이루면 1에 가까운 값이 나타나는 한계가 있으나, NSE는 이러한 한계가 없다. RMSE (Root Mean Squared Error)는 모형의 출력값과 목푯값이 얼마 나 일치하는지를 나타낸다. 출력값과 목푯값이 정확하게 일 치할 때 RMSE는 0이며, 일치하는 정도가 감소할수록 RMSE 값이 커지게 된다.
를 목푯값, 를 목푯값의 평균, ′를 출력값, ′를 출력값 의 평균, 자료수를 N이라고 할 때, , NSE, RMSE의 계산식 은 Eqs. (8)∼(10)과 같다. Table 1은 유역 단위의 수문 모델링 에서 와 NSE을 이용한 성능 평가 기준을 나타낸다
(Moriasi et al., 2015).
′ ′ ′ ′
(8)
′ (9)
′ (10)
ETp는 첨두시간에 대한 오차를, EQp는 첨두유출량에 대한 오차를 의미한다. 모든 사상에 대해 를 목푯값의 첨두시간 (hr), ′을 출력값의 첨두시간 (hr), 를 목푯값의 첨두유출량 (), ′를 출력값의 첨두유출량 ()이라 할 때, ETp 와 EQp의 계산식은 Eqs. (11), (12)와 같다. 각 사상별로 ETp 와 EQp를 산정한 후, 모든 사상에 대한 평균을 결과로 제시 하였다.
ETp ′ (11) EQp ′ × (12)
나. 교차검증
교차검증 (cross validation)은 인공신경망 모형에서 과적합 (overfitting)을 방지하기 위하여 필요한 과정이다. 과적합이란 인공신경망이 특정한 학습 자료에 대해서는 좋은 학습 효과 를 나타내더라도 새로운 자료에 대해서는 좋은 성능을 내지 못할 수 있음을 의미한다 (Aggarwal, 2018). 따라서 한 종류의 학습 자료 (training data)와 검증 자료 (test data)만을 사용하지 않고 여러 종류의 자료 세트를 생성하여 모든 자료가 최소 한 번씩은 학습에 사용될 수 있도록 교차검증을 적용하였다.
교차검증 방법으로는 k-겹 교차검증 (k-fold cross validation)을 사용하였다. k=4를 적용하여 전체 입력 자료를 4개의 부분집합으로 구분하고, 이 중 3개를 학습 자료로, 1개 를 검증 자료로 구분하여 총 4종류의 교차검증 자료 세트를
Measure Very good Good Satisfactory Not satisfactory
≤ ≤ ≤
≤ ≤ ≤
* The temporal scale of the criteria is “daily”, but it was applied as a reference.
Table 1 Performance evaluation criteria for watershed-scale modeling (Moriasi et al., 2015)*
Fig. 5 Training and test data set for k-fold cross validation (ex. k=4) (Chollet, 2017)
생성하였다 (Fig. 5). 교차검증을 통한 모형의 성능은 각 세트 에 대한 값의 평균으로 제시하였다 (Chollet, 2017).
Ⅲ. 결과 및 고찰 1. 홍수량 예측 성능 비교 가. 통계변량에 따른 모의 성능 비교
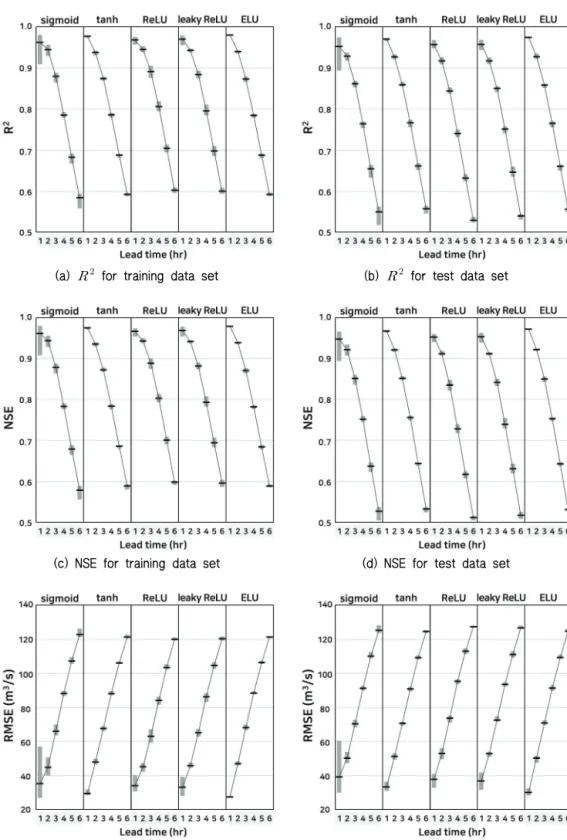
홍수량 예측 인공신경망 모형에서 활성화 함수에 따른 모 의 성능을 통계변량 , NSE, RMSE를 이용하여 평가하고 Fig. 6에 제시하였다. 각 활성화 함수마다 은닉층 1∼5층을 적용하여 통계변량의 최솟값, 평균, 최댓값을 제시하였다.
인공신경망의 학습 및 검증 결과, 활성화 함수의 종류에 상관 없이 일정 수준 이상의 모의 성능을 보이는 것으로 나타났다.
Table 1의 수문 모델링 평가 기준에 따르면, 검증 결과는 선행시 간 1∼3시간에 대해 ≤ ≤ , ≤ ≤
을 만족하여 ‘매우 좋음 (very good)’ 수준, 4시간에 대해
≤ ≤ , ≤ ≤ 을 만족하여 ‘좋음 (good)’ 수준, 5∼6시간에 대해 ≤ ≤ , ≤
≤ 을 만족하여 ‘충분 (satisfactory)’ 수준으로 나타 났다. 선행시간이 길어질수록 입력 자료와 출력 자료 사이의 시간 간격이 벌어지기 때문에 상관성이 점차 떨어짐에 따라 정확도가 감소하였으나, 전반적으로 ‘충분’ 이상의 수준을 달 성하여 수문 모형으로서 예측 능력을 지닌 것으로 분석된다.
활성화 함수에 따른 통계변량의 차이가 크지는 않으나, 근 소한 차이로 tanh 함수와 ELU 함수의 성능이 가장 높게 나타 났다. 검증 결과를 기준으로, tanh 함수와 ELU 함수는 선행시 간 1시간에 대해 가 0.97, NSE가 0.97로 가장 높았고, 선행 시간 6시간에 대해서도 가 0.56, NSE가 0.53으로 가장 높 게 나타났다. RMSE의 경우, 선행시간 1시간에 대해 ELU 함 수에서 30.1 (m3/s)로 가장 낮았고, 선행시간 6시간에 대해 tanh 함수에서 124.6 (m3/s), ELU 함수에서 124.8 (m3/s)로 낮 게 나타나 모의 성능이 가장 좋은 것으로 나타났다.
나. 첨두시간 및 첨두홍수량 모의 성능 비교
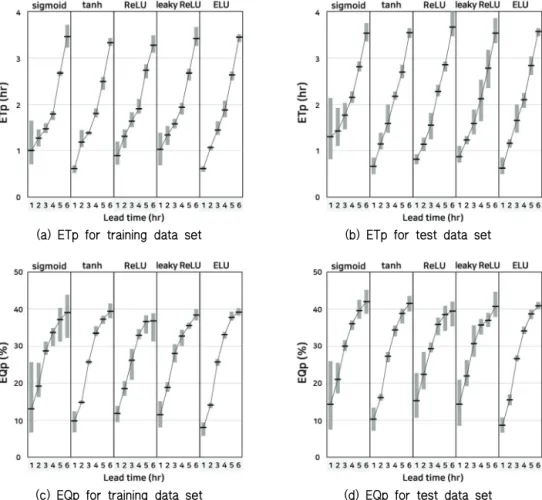
홍수량 예측 인공신경망 모형에서 활성화 함수에 따른 첨 두시간 및 첨두홍수량 모의 성능을 ETp와 EQp를 이용하여 평가하고 Fig. 7에 제시하였다. 각 활성화 함수마다 은닉층 1∼5층을 적용하여 ETp, EQp의 최솟값, 평균, 최댓값을 제시 하였다.
ETp를 이용하여 첨두시간에 대한 모의 성능을 평가한 결 과, tanh 함수와 ELU 함수를 적용했을 때 첨두시간을 비교적 정확하게 예측하는 것으로 나타났다. 선행시간 1시간에 대해 평균 ETp는 tanh 함수에서 0.66 (hr), ELU 함수에서 0.63 (hr) 으로 1시간 미만의 오차를 보인 반면, sigmoid 함수는 1.31 (hr)의 큰 오차를 나타냈다. 선행시간 6시간에 대한 ETp는 tanh 함수와 ELU 함수의 경우 3.43∼3.64 (hr) 범위에 머무는 반면, ReLU 함수와 leaky ReLU 함수의 경우 최대 4.00, 3.86 (hr)까지 증가하여 비교적 큰 오차를 나타냈다.
EQp를 이용하여 첨두홍수량에 대한 모의 성능을 평가한 결과, ELU 함수를 적용했을 때 첨두홍수량을 비교적 정확하 게 예측하는 것으로 나타났다. 선행시간 1시간에 대한 평균 EQp는 ELU 함수에서 8.6%로 가장 낮았으며, ReLU 함수에서 15.2%로 가장 높게 나타났다. 선행시간 6시간에 대해서는, ELU 함수에서 EQp가 40.0∼42.0%의 범위에 머무는 반면, sigmoid 함수와 leaky ReLU 함수의 경우 45.2%, 44.7%까지 증가하여 비교적 큰 오차를 나타냈다. 한편, ReLU 함수와 leaky ReLU 함수에서 선행시간 5∼6시간에 대해 평균 EQp가 낮게 나타나긴 했으나, 선행시간 1∼4시간에 대한 EQp가 ELU 함수 대비 1.6%에서 6.9%까지 높고 선행시간 5∼6시간 에 대해서도 최솟값과 최댓값의 차이가 크기 때문에 성능이 더 좋다고 보기 어려운 것으로 판단된다.
Fig. 8은 sigmoid 함수와 ELU 함수에 따른 홍수 수문곡선 의 모의 결과를 보여준다. 선행시간 1시간에 대해, sigmoid 함수와 ELU 함수 모두 수문곡선의 전반적인 형태를 잘 모의 하고 있으나, 첨두홍수량은 ELU 함수에서 보다 정확하게 모 의되는 것으로 나타났다. 선행시간 6시간에 대해서는 sigmoid 함수와 ELU 함수 모두 수문곡선이 관측치 기준 3∼4 시간 정도 지연되었고, 첨두시간 역시 지연되는 것으로 나타 났다. 첨두홍수량은 sigmoid 함수에서는 관측치의 50% 수준 으로 과소 산정되었으나, ELU 함수에서는 비교적 정확하게 모의되었다.
(a) for training data set (b) for test data set
(c) NSE for training data set (d) NSE for test data set
(e) RMSE for training data set (f) RMSE for test data set
Fig. 6 Statistical values for training and test data set (minimum, average, and maximum values for 1 to 5 hidden layers)
(a) ETp for training data set (b) ETp for test data set
(c) EQp for training data set (d) EQp for test data set
Fig. 7 ETp and EQp for training and test data set (minimum, average, and maximum values for 1 to 5 hidden layers)
(a) Lead time: 1 hr
(b) Lead time: 6 hr
Fig. 8 Observed and simulated hydrographs of the ANNs model (5 hidden layers) with sigmoid and ELU activation functions at the test stage
2. 학습 속도에 따른 성능 비교
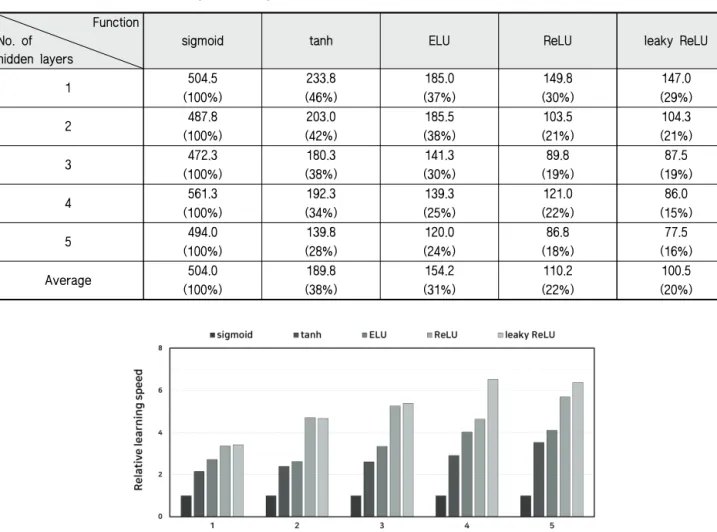
인공신경망의 학습 과정에서 최소 오차가 발생하는 시점까 지의 반복 횟수를 이용하여 활성화 함수별 학습 속도를 분석 하였다. Table 2는 활성화 함수별 반복 횟수를 보여주며, Fig.
9는 sigmoid 함수에 대한 상대적인 학습 속도 (sigmoid 함수의 반복 횟수/함수별 반복 횟수)를 나타낸다.
최소 오차에 도달하기까지 반복 횟수는 sigmoid > tanh >
ELU > ReLU > leaky ReLU 함수의 순서로 나타났다. 최대의 반복 횟수를 보인 sigmoid 함수의 경우 오차가 최소로 수렴하 기까지 평균적으로 504회의 반복이 필요한 것으로 나타났으 며, 이후 tanh 함수부터는 반복 횟수가 큰 폭으로 감소하였다.
반복 횟수가 가장 큰 sigmoid 함수를 기준으로 tanh 함수의 평균 반복 횟수는 38% 수준이며, ELU 함수는 31%, ReLU 함수는 22%, leaky ReLU 함수는 20% 수준으로 나타나 학습 속도가 sigmoid 함수 대비 약 3배에서 5배까지 증가하는 것으 로 나타났다.
활성화 함수에 따른 학습 속도의 개선 효과를 은닉층 수별 로 살펴본 결과, 은닉층의 개수가 증가할수록 sigmoid 함수에 대한 학습 속도의 증가 폭이 더 커지는 것으로 나타났다. ELU 함수의 상대적인 학습 속도는 은닉층이 1개일 때 2.7에서 은 닉층이 5개일 때 4.1로 증가하였으며, leaky ReLU 함수의 경 우 은닉층이 1개일 때 3.4에서 은닉층이 5개일 때 6.4까지 증 가하는 것으로 나타났다.
3. 홍수량 예측을 위한 최적의 활성화 함수 선정 통계변량과 첨두시간 및 첨두홍수량에 대한 지표를 기반으 로 모의 성능을 비교한 결과, 활성화 함수에 따른 차이가 크지 는 않았으나 근소한 차이로 tanh 함수와 ELU 함수의 성능이 좋은 것으로 나타났다. 반면에, 학습 속도에 대해서는 활성화 함수별로 큰 차이가 있었으며, sigmoid 함수의 경우 학습 속도 가 다른 활성화 함수의 1/3∼1/5 수준으로 매우 느리게 나타났다.
학습 속도가 sigmoid 함수에서 유독 느리게 나타난 이유는,
Fig. 9 Relative learning speed depending on the activation functions Function
No. of hidden layers
sigmoid tanh ELU ReLU leaky ReLU
1 504.5 233.8 185.0 149.8 147.0
(100%) (46%) (37%) (30%) (29%)
2 487.8 203.0 185.5 103.5 104.3
(100%) (42%) (38%) (21%) (21%)
3 472.3 180.3 141.3 89.8 87.5
(100%) (38%) (30%) (19%) (19%)
4 561.3 192.3 139.3 121.0 86.0
(100%) (34%) (25%) (22%) (15%)
5 494.0 139.8 120.0 86.8 77.5
(100%) (28%) (24%) (18%) (16%)
Average 504.0 189.8 154.2 110.2 100.5
(100%) (38%) (31%) (22%) (20%)
Table 2 Number of epochs to converge depending on the activation functions
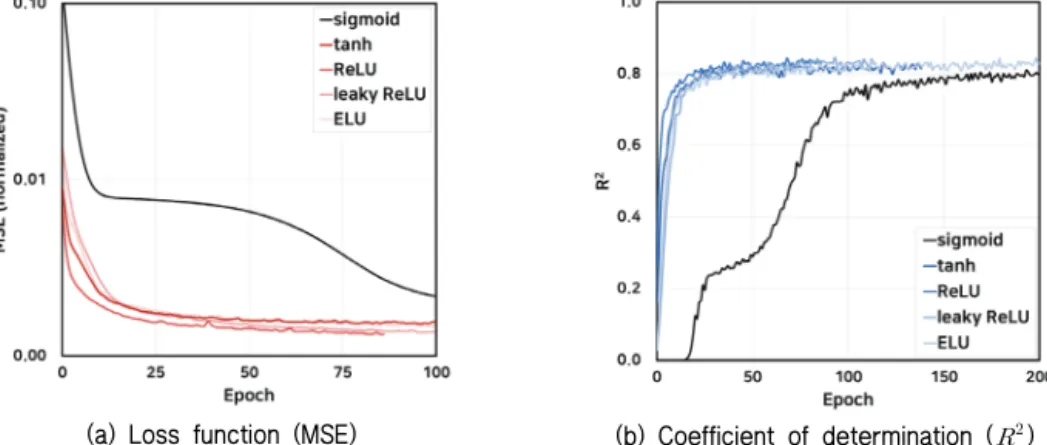
첫째, 오류 역전파 과정에서 기울기 소실 문제에 의한 것으로 분석된다. Fig. 10은 학습 과정에서 반복 횟수에 따른 오차 (MSE)와 의 변화를 나타낸 것으로, 초반에 큰 폭으로 오차 가 감소하는 다른 함수들에 비해 sigmoid 함수에서는 오차의 감소가 매우 더디게 일어나는 것으로 나타났다. 도함수의 값 이 0∼0.25에 분포하는 sigmoid 함수의 특성상 여러 층을 통과 하는 과정에서 기울기가 소실되어 가중치의 업데이트가 충분 하게 일어나지 못하였으며, 그 결과 학습을 위해 더 많은 반복
횟수가 소요된 것으로 판단된다. 또한, 기울기 소실 문제는 층이 깊어질수록 심화하기 때문에 은닉층이 많아질수록 sigmoid 함수의 학습 속도가 다른 함수에 비해 더 낮게 나타난 것으로 판단된다.
두 번째는 오류 역전파 과정에서 가중치 업데이트 방향의 제한에 의한 것이다. 함숫값으로 0과 1 사이의 양수만을 갖는 simgoid 함수의 특성상 하나의 노드에 연결된 가중치들에 대 해 항상 동일한 부호의 업데이트가 적용되어 가중치의 업데
(a) Loss function (MSE) (b) Coefficient of determination () Fig. 10 Changes of the loss function and coefficient of determination () along the training epoch of ANNs
model (3 hidden layers)
(a) sigmoid (b) tanh (c) ReLU
(d) leaky ReLU (e) ELU
Fig. 11 Comparison of the amount of weight updates at every training step (7th node of 2nd hidden layer of ANNs model with 3 hidden layers)
이트 방향에 제한이 생긴다. Fig. 11은 하나의 노드에 연결된 가중치들에 대한 매 학습 단계별 업데이트 값을 나타낸 것으 로, 다양한 부호의 조합이 나타나는 다른 함수에 비해 sigmoid 함수에서는 업데이트 값의 부호가 대부분 동일하다. 따라서 가중치의 업데이트를 위해 같은 경로를 이동하는 경우 sigmoid 함수는 다른 활성화 함수와 비교해 몇 단계를 더 거쳐 야만 하므로 수렴에 이르기까지 반복 횟수가 커진 것으로 분 석된다.
기울기 소실 문제는 tanh 함수에서도 발생할 수 있는 문제 이지만, 본 연구에서는 tanh 함수에서 정확도가 비교적 높고 학습 속도가 sigmoid 함수에 비해 매우 빠른 것으로 보아 이로 인한 성능의 저하가 크게 나타나지 않은 것으로 판단된다. 함 수 tanh 는 도함수 값이 0∼1에 분포하여 sigmoid 함수에 비해 클 뿐만 아니라, 0.05∼0.95 범위로 변환한 입력 자료 중 강우 량은 0.05∼0.35 범위에, 유출량은 0.10∼0.45 범위에 대부분 분포하기 때문에 1에 가까운 기울기가 적용되어 기울기 소실 이 크게 발생하지 않은 것으로 분석된다.
ReLU 함수와 leaky ReLU 함수는 기울기 소실의 문제가 없으므로 효율적으로 학습이 이루어져서 짧은 반복 횟수로도 학습이 완료된 것으로 판단된다. 이 중 ReLU 함수는 모의 결 과 1∼6개의 노드가 비활성화되는 dying ReLU 문제가 발생하 였으며, 이로 인해 효율이 다소 떨어져서 leaky ReLU 함수보 다 학습 속도가 느린 것으로 분석된다. 또한, ReLU 함수 역시
일 때 함숫값이 모두 양수이므로 sigmoid 함수와 같이 가중치 업데이트 방향의 제한이 생길 수 있으나, Fig. 14에서 볼 수 있듯이 sigmoid 함수와 비교해 그 정도가 심하지 않은 것으로 판단된다.
ReLU 함수와 leaky ReLU 함수는 학습 속도의 측면에서는 뛰어나지만, 정확도 측면에서는 tanh 함수와 ELU 함수보다 성능이 다소 떨어진다는 한계가 있다. ReLU, leaky ReLU 함 수와 tanh, ELU 함수를 구분할 수 있는 점은 0 부근에서 함수 의 연속 여부이다. 강우량과 유출량 자료가 연속적인 시계열 자료이기 때문에 tanh, ELU 함수와 같이 연속인 함수일수록 정확도가 비교적 높게 나타난 것으로 판단된다. 또한, tanh 함 수는 sigmoid 함수와 함께 인공신경망에서 사용이 지양되고 있는 추세이지만, 강우-유출 분석에서는 ReLU, leaky ReLU 함수보다도 높은 정확도를 낼 수 있는 것으로 나타났다. 최종 적으로, tanh 함수와 ELU 함수 중에서 ELU 함수의 학습 속도 가 tanh 함수보다 1.2배가량 높으므로, 정확도와 학습 속도를 모두 고려하였을 때 ELU 함수의 모의 성능이 가장 뛰어난 것으로 분석된다. 따라서 인공신경망 기반의 홍수량 예측 모 형에서 최적의 활성화 함수로 ELU 함수를 선정하였다.
Ⅳ. 요약 및 결론
본 연구에서는 인공신경망 기반의 홍수량 예측 모형에서 활성화 함수에 따른 모의 성능을 분석하였다. 기존에 수문 분 야에서 인공신경망의 활성화 함수로 주로 적용해 온 sigmoid, tanh 함수와 최근 딥러닝에서 많이 적용되고 있는 ReLU, leaky ReLU, ELU 함수를 함께 비교⋅분석하였다. 인공신경 망 모형은 과거 9시간의 강우량과 유출량을 통해 1∼6시간 후의 유출량을 예측하도록 구성하였다. 흑천 유역의 1시간 단 위 강우량 및 유출량 자료를 이용하여 입⋅출력 자료를 구축 하고 인공신경망의 학습 및 검증에 활용하였다. 학습 및 검증 과정에는 인공신경망이 특정 자료에만 과적합되는 현상을 방 지하기 위해 k-겹 교차검증 방법을 적용하였으며, 조기 종료 함수를 이용하여 최소 오차에 수렴하면 학습을 종료하도록 설정하였다.
통계변량 , NSE, RMSE와 첨두시간 및 첨두홍수량에 대한 오차 ETp, EQp를 이용하여 홍수량 예측 성능을 평가한 결과, 활성화 함수에 따른 차이는 크지 않은 것으로 나타났다.
다만, 근소한 차이로 tanh 함수와 ELU 함수의 성능이 높았으 며, 특히 첨두시간과 첨두홍수량에 대한 정확도가 비교적 높 게 나타났다. 반면에 학습 속도 측면에서는 활성화 함수에 따 른 차이가 뚜렷하게 나타났으며, leaky ReLU > ReLU > ELU >
tanh > sigmoid 함수의 순서로 속도가 빠르게 나타났다. 특히 sigmoid 함수는 학습 속도가 다른 함수들의 1/3∼1/5 수준으 로 매우 느리게 나타났으며, 이는 오류 역전파 과정에서 발생 한 기울기 소실 문제와 가중치 업데이트 방향의 제한에 의한 것으로 분석된다. 최종적으로 홍수량 예측의 정확도와 학습 속도를 고려하여, 홍수량 예측을 위한 최적의 활성화 함수로 ELU 함수를 선정하였다.
그동안 수문 분야에서 수많은 연구에 인공신경망이 적용되 었으며, 최근에는 딥러닝에 대한 주목과 함께 점차 자료의 용 량이 커지고 신경망의 구조가 복잡해지고 있다. 모형의 구조 가 복잡해질수록 효율을 높이기 위해서는 정확도뿐만 아니라 학습 속도를 개선하는 것이 중요하다. 본 연구의 인공신경망 모형은 구조가 단순하기 때문에 한 번의 반복 횟수에 대한 소요 시간이 짧지만, 더욱 복잡한 구조의 모형에서는 활성화 함수에 따른 속도 개선 효과가 훨씬 크게 나타날 것이다. 따라 서 향후 수문 분야에 인공신경망을 적용하고자 할 때, 기존 함수의 한계점을 보완한 ELU 함수를 사용한다면 정확도와 학습 속도가 개선되어 모형의 효율을 높일 수 있을 것으로 기대된다.
감사의 글
본 결과물은 농림축산식품부의 재원으로 농림식품기술기 획평가원의 농업기반및재해대응기술개발사업의 지원을 받아 연구되었음 (320046-5).
REFERENCES
1. Adamowski, J., and S. O. Prasher, 2012. Comparison of machine learning methods for runoff forecasting in mountainous watersheds with limited data. Journal of Water and Land Development 17(1): 89-97. doi:10.2478/
v10025-012-0038-4.
2. Aggarwal, C. C., 2018. Neural networks and deep learning:
Springer.
3. Chollet, F., 2015. Keras. https://keras.io. Accessed 20Jul.
2020.
4. Chollet, F., 2017. Deep Learning with Python: Manning.
5. Clevert, D. A., T. Unterthiner, and S. Hochreiter, 2016.
Fast and accurate deep network learning by exponential linear units (ELUs). arXiv preprint. arXiv:1511.07289.
6. Dawson, C. W., and R. Wilby, 1998. An artificial neural network approach to rainfall-runoff modeling. Hydrological Sciences 43(1): 47-66. doi:10.1080/02626669809492102.
7. Donate, J. P., C. Paulo, G. S. German, and S. M. Araceli, 2013. Time series forecasting using a weighted cross- validation evolutionary artificial neural network ensemble.
Neurocompution 109: 27-32. doi:10.1016/j.neucom.2012.02.053.
8. Glorot, X., and Y. Bengio, 2010. Understanding the difficulty of training deep feedforward neural networks. In Proc. Thirteenth International Conference on Artificial Intelligence and Statistics: 249-256.
9. Goodfellow, I., Y. Bengio, and A. Courville, 2016. Deep Learning: MIT press.
10. Hsu, K. N., H. V. Gupta, and S. sorooshian, 1995.
Artificial neural network modeling of the rainfall-runoff process. Water Resources Research 31(10): 2517-2530.
doi:10.1029/95WR01955.
11. Hu, C., Q. Wu, H. Li, S. Jian, N. Li, and Z. Lou, 2018.
Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 10(11):
1543. doi:10.3390/w10111543.
12. Jeung, M., S. Baek, J. Beom, K. H. Cho, Y. Her, and K.
Yoon, 2019. Evaluation of random forest and regression tree methods for estimation of mass first flush ratio in
urban catchments. Journal of Hydrology 575: 1099-1110.
doi:10.1016/j.jhydrol.2019.05.079.
13. Kang, M. S., and S. W. Park, 2003, Short-term flood forecasting using artificial neural networks. Journal of The Korean Society of Agricultural Engineers 45(2): 45-57 (in Korean).
14. Kang, M. S., M. G. Kang, S. W. Park, J. J. Lee, and R.
H. Yoo, 2006. Application of grey model and artificial neural networks to flood forecasting. Journal of the American Water Resources Association 42(2): 473-486.
15. Kim, J. H., 1993. A study on hydrologic forecasting of stream flows based on artificial neural network. Ph.D. diss., Incheon, Republic of Korea: Inha University (in Korean).
16. Kingma, D. P., and J. Ba, 2014. Adam: A method for stochastic optimization. arXiv preprint. arXiv:1412.6980.
17. Krizhevsky, A., I. Sutskever, and G. E. Hinton, 2017.
Imagenet classification with deep convolutional neural networks. Communications of the ACM 60(6): 84-90.
doi:10.1145/3065386.
18. Lau, M. M., and K. H. Lim, 2017. Investigation of activation functions in deep belief network. 2017 2nd International Conference on Control and Robotics Engineering (ICCRE): 201-206. doi:10.1109/ICCRE.2017.
7935070.
19. Lee, G. S., S. C. Park, H. M. Lee, and Y. H. Jin, 2000.
The prediction of runoff using artificial neural network in the Young-san River. Journal of Korea Water Resources Association 33(1): 251-256 (in Korean).
20. Marina, C., P. Andreussi, and A. Soldati, 1999. River flood forecasting with a neural network model. Water Resources Research 35(4): 1191-1197. doi:10.1029/1998WR900086.
21. Ministry of the Interior and Safety, 2018. Statistical yearbook of natural disaster (in Korean).
22. Moriasi, D. N., M. W. Gitau, N. Pai, and P. Daggupati, 2015. Hydrologic and water quality models: performance measures and evaluation criteria. Transactions of the ASABE 58(6): 1763-1785. doi:10.13031/trans.58.10715.
23. Sarkar, A., and R. Kumar, 2012. Artificial neural networks for event based rainfall-runoff modeling. Journal of Water Resource and Protection 4(10): 891. doi:10.4236/jwarp.
2012.410105.
24. Solomatine, D., L. M. See, and R. J. Abrahart, 2009.
Data-driven modelling: concepts, approaches and experiences. In Practical Hydroinformatics: 17-30.
25. Song, J. H., Y. Her, K. Suh, M. S. Kang, and H. Kim,
2019. Regionalization of a Rainfall-Runoff Model:
Limitations and Potentials. Water 11(11): 2257. doi:10.3390/
w11112257.
26. Xu, B., N. Wang, T. Chen, and M. Li, 2015. Empirical evaluation of rectified activations in convolutional network. arXiv preprint. arXiv:1505.00853.
27. Young, C. C., W. C. Liu, and M. C. Wu, 2017. A physically based and machine learning hybrid approach for
accurate rainfall-runoff modeling during extreme typhoon events. Applied Soft Computing 53: 205-216. doi:10.1016/
j.asoc.2016.12.052.
28. Zealnad, C. M., D. H. Burn, and S. P. Simonovic, 1999.
Short term stream flow forecasting using artificial neural networks. Journal of Hydrology 214: 32-48. doi:10.1016/
S0022-1694(98)00242-X.