Bidirectional LSTM CRF를 이용한 End-to-end 한국어 의미역 결정
End-to-end Learning of Korean Semantic Role Labeling Using Bidirectional LSTM CRF
저자 (Authors)
배장성, 이창기
Jangseong Bae, Changki Lee
출처 (Source)
한국정보과학회 학술발표논문집, 2015.12, 566-568 (3 pages)
발행처 (Publisher)
한국정보과학회
KOREA INFORMATION SCIENCE SOCIETY
URL http://www.dbpia.co.kr/Article/NODE06602453
APA Style 배장성, 이창기 (2015). Bidirectional LSTM CRF를 이용한 End-to-end 한국어 의미역 결정. 한국 정보과학회 학술발표논문집, 566-568.
이용정보 (Accessed)
저작권 안내
DBpia에서 제공되는 모든 저작물의 저작권은 원저작자에게 있으며, 누리미디어는 각 저작물의 내용을 보증하거나 책임을 지지 않습니다. 그리고 DBpia에서 제공되는 저작물은 DBpia와 구독계약을 체결한 기관소속 이용자 혹은 해당 저작물의 개별 구매자 가 비영리적으로만 이용할 수 있습니다. 그러므로 이에 위반하여 DBpia에서 제공되는 저작물을 복제, 전송 등의 방법으로 무단 이용하는 경우 관련 법령에 따라 민, 형사상의 책임을 질 수 있습니다.
Copyright Information
Copyright of all literary works provided by DBpia belongs to the copyright holder(s)and Nurimedia does not guarantee contents of the literary work or assume responsibility for the same. In addition, the literary works provided by DBpia may only be used by the users affiliated to the institutions which executed a subscription agreement with DBpia or the individual purchasers of the literary work(s)for non-commercial purposes. Therefore, any person who illegally uses the literary works provided by DBpia by means of reproduction or transmission shall assume civil and criminal responsibility according to applicable laws and regulations.
강원대학교 114.70.234.***
2018/02/06 15:12 (KST)
Bidirectional LSTM CRF를 이용한 End-to-end 한국어 의미역 결정
배장성O 이창기 강원대학교 컴퓨터과학과
[email protected] [email protected]
End-to-end Learning of Korean Semantic Role Labeling Using Bidirectional LSTM CRF
Jangseong BaeO Changki Lee Kangwon National University
요 약
의미역 결정 연구에 있어 구문 분석 정보는 술어-논항 사이의 의존 관계 정보를 포함하고 있기 때문에 의미역 결정 성능 향상에 큰 도움이 된다. 그러나 의미역 결정 이전에 구문 분석을 수행해야 하는 비용 (overhead)이 발생하게 되고, 구문 분석 단계에서 발생하는 오류를 그대로 답습하는 단점이 있다. 이러 한 문제점을 해결하기 위해 본 논문에서는 구문 분석 정보를 제외하여 형태소 분석 정보만을 사용하는 end-to-end 방식의 한국어 의미역 결정 시스템을 제안하고 순차 데이터 모델링에 적합한 Bidirectional LSTM CRF 모델을 적용해 구문 분석 정보 없이 기존 연구보다 더 높은 성능을 얻을 수 있음을 보인다.
1. 서 론
의미역 결정(semantic role labeling)은 문장의 각 서 술어의 의미와 그 논항(argument)들의 의미역을 결정 하여 “누가, 무엇을, 어떻게, 왜” 등의 의미 관계를 찾 아내는 자연어처리의 한 단계이며 정보 추출, 문서 자 동 분류, 질의 응답 시스템의 중간 과정으로 사용될 수 있다. 최근 의미역 결정 연구에는 Structural SVM, 딥 러닝(deep learning)등 기계학습 알고리즘을 이용한 연 구가 주로 이루어지고 있다[1,2,3].
자연어처리 모듈 개발에 사용되는 대부분의 기계학 습 알고리즘들은 사람이 고안한 자질(feature)을 입력 으로 받고 이 자질들의 최적의 가중치(weight)를 구한 다. 그러나 각 자연어처리 모듈마다 적합한 자질을 설 계하고 최적의 자질 조합을 구하는 것은 많은 시간과 노력을 필요로 한다. 이러한 문제를 해결하기 위해 자 질들을 높은 수준의 표현으로 추상화 시켜줄 수 있는 딥 러닝 기술이 최근 많이 연구되고 있다[4]. Long Short-term Memory(LSTM)를 이용한 Recurrent Neural Network(RNN)는 기존 RNN 모델의 그래디언트 소멸 (vanishing gradient problem) 문제[5]를 해결한 딥 러 닝 모델이다.
구문 분석 정보는 술어와 논항 사이의 의존 관계 정 보를 포함하고 있어 의미역 결정 시스템의 성능 향상 에 크게 기여한다[6]. 따라서 기존 의미역 결정 연구 들은 구문 분석 정보를 의미역 결정의 자질로 사용하 였다. 그러나 구문 분석 정보를 사용하기 위해서는 의 미역 결정 시스템 이전에 구문 분석을 수행해야 하는
비용이 발생하게 된다. 또한 구문 분석 단계에서 발생 하는 오류를 그대로 답습하는 단점이 있다[7]. 따라서 본 논문에서는 구문 분석 정보를 제외하고 형태소 분 석 정보만을 사용하는 end-to-end 방식의 한국어 의 미역 결정 시스템을 제안한다. 이를 위해, 한국어 의미 역 결정을 sequence labeling 문제로 보고 순차 데이 터(sequential data) 모델링에 적합한 Bidirectional LSTM RNN을 한국어 의미역 결정에 적용하고, Conditional Random Field(CRF)를 이용하여 Bidirectional LSTM RNN 모델에 의미역 태그 사이의 의존성(전이 확률)을 추가한다.
2. 관련 연구
의미역 결정 연구는 크게 격틀사전에 기반을 둔 방법 과 말뭉치에 기반을 둔 방법으로 나눌 수 있다. 격틀사 전에 기반을 둔 방법은 서술어와 논항들의 쓰임을 기술 한 격틀사전을 이용하는 방법으로, 서술어와 논항에 대 한 문법 관계를 기술한 격틀(frame)과 논항들의 정보를 기술한 선택제약(selectional restriction) 등을 이용하여 서술어-논항 관계에 부합하는 격틀을 선택하여 의미역 을 결정하는 방법이다. 격틀사전에 기반을 둔 방법은 입 력 문장과 격틀 사이의 유사도 계산 과정을 통해 의미 역이 결정되기 때문에 처리속도가 빠르고 높은 정확률 을 보이지만, 격틀사전의 구축이 어렵고 격틀사전에 기 술되지 않은 임의격을 처리하지 못하는 문제가 있다[8].
말뭉치에 기반을 둔 방법은 의미역이 태깅된 말뭉치 를 구축하고 이를 이용하여 기계학습 방법으로 의미역
2015년 동계학술발표회 논문집
566
강원대학교 | IP: 114.70.234.*** | Accessed 2018/02/06 15:12(KST)
을 결정하는 방법이다. 이 방법은 격틀사전에 기반을 둔 방법에 비해 적용률이 높은 장점이 있으나, 의미역이 태 깅된 말뭉치의 구축이 어렵다는 단점이 있다[8]. 최근 에는 의미역 말뭉치와 기계학습 알고리즘을 이용한 연 구가 활발히 이루어지고 있다[1,2,3].
[2]에서 사용한 Feed Forward Neural Network 모델은 출력 레이블을 결정하기 위해 현재 입력 단어를 포함한 고정된 크기의 윈도우만 볼 수 있다는 단점이 있다. [3]
의 모델은 LSTM 구조로 인해 멀리 떨어져 있는 단어의 정보를 볼 수 있다는 장점이 있으나 이전 단어의 정보 만을 볼 수 있다는 단점이 존재한다. 본 논문에서는 Bidirectional 방법을 사용하여 이전 단어 및 다음 단어 의 정보 모두를 사용할 수 있게 한다.
기존 의미역 결정 연구는[1,2,3] 구문 분석 정보를 자질로 사용한다. 이는 의미역 결정 시스템의 성능을 향 상 시킬 수 있지만 그에 따르는 비용이 발생하며, 구문 분석 단계에서 발생하는 오류를 답습하게 된다. 이러한 문제점 에서 자유롭기 위해 본 논문에서는 구문 분석 정보를 사용하지 않는 end-to-end 방식의 한국어 의미 역 결정 시스템을 제안하고 Bidirectional LSTM CRF 모 델을 이용하여 구문 분석 정보 없이 기존 연구보다 더 높은 성능을 얻을 수 있음을 보인다.
3. end-to-end 한국어 의미역 결정 시스템
이 장에서는 본 논문에서 제안한 end-to-end 한국어 의미역 결정 시스템의 자질과 Bidirectional LSTM CRF 모델에 대해 기술한다.
3.1 end-to-end 한국어 의미역 결정 자질
대부분의 의미역 결정 시스템이 구문 분석 정보를 사 용하는 것과 달리 본 논문에서는 형태소 분석 정보를 바탕으로 한 자질 정보만을 사용한다. 본 논문에서 사용 하는 자질 정보는 표 1과 같다.
표 1. 의미역 결정 자질 정보
본 논문에서 제안한 시스템의 자질(end-to-end) - 서술어와 현재 단어, 현재 단어의 앞뒤 단어 - 현재 단어 및 앞뒤 단어의 품사 정보
- 서술어와 현재 단어 사이의 위치 및 거리 관계 비교 실험을 위한 구문 정보 자질
- 서술어와 현재 단어 사이의 가장 짧은 경로상의 의존 관 계 레이블 및 경로의 길이
- 의존 구문 트리 에서 서술어와 현재 어절의 가장 낮은 공통 부모(LCA: lowest common ancestor)
3.2 Bidirectional LSTM CRF 모델
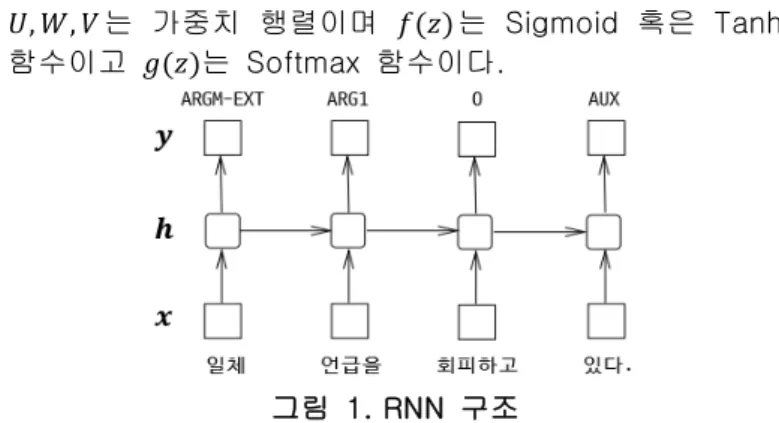
RNN은 순차 데이터를 처리하는데 적합한 형태로 디 자인 되어 있으며 RNN을 언폴드(unfold)한 구조는 그림 1과 같다. 입력 단어 열 𝑥 = (𝑥$, 𝑥&, … , 𝑥() 와 hidden layer의 노드 열 ℎ = (ℎ$, ℎ&, … , ℎ(), 출력 단어 열(의미역 태그 열)을 𝑦 = (𝑦$, 𝑦&, … , 𝑦()라 할 때 RNN은 아래와 같 이 정의된다.
ℎ 𝑡 = 𝑓(𝑈𝑥 𝑡 + 𝑊ℎ(𝑡 − 1)) 𝑦 𝑡 = 𝑔(𝑉ℎ 𝑡 )
𝑈, 𝑊, 𝑉 는 가중치 행렬이며 𝑓(𝑧)는 Sigmoid 혹은 Tanh 함수이고 𝑔(𝑧)는 Softmax 함수이다.
그림 1. RNN 구조
RNN의 그래디언트 소멸 문제를 해결한 LSTM RNN은 다음과 같이 정의된다.
𝑖(= 𝜎(𝑊9:𝑥(+ 𝑊;:ℎ(<$+ 𝑊=:𝑐(<$+ 𝑏:) 𝑓(= 𝜎 𝑊9@𝑥(+ 𝑊;@ℎ(<$+ 𝑊=@𝑐(<$+ 𝑏@ 𝑐(= 𝑓(𝑐(<$+ 𝑖(tanh (𝑊9=𝑥(+ 𝑊;=ℎ(<$+ 𝑏=) 𝑜(= 𝜎 𝑊9F𝑥(+ 𝑊;Fℎ(<$+ 𝑊=F𝑐(<$+ 𝑏F ℎ(= 𝑜(tanh (𝑐()
𝑦(= 𝑔(𝑊;Gℎ(+ 𝑏G)
위 식에서 σ는 sigmoid 함수이고, 𝑖, 𝑓, 𝑜, 𝑐는 각각 input gate, forget gate, output gate, memory cell vector(벡터) 이며 각 벡터의 크기는 hidden layer 벡터 크기와 같다.
가중치 행렬의 아래첨자는 연결된 각 노드를 표시해 준 다. 예를 들어 𝑊;:는 hidden layer와 input gate간의 가 중치 행렬이다. 그림 2는 LSTM memory cell의 구조를 나타낸다.
그림 2. LSTM memory cell 구조
본 논문에서는 Conditional Random Field(CRF)를 LSTM에 추가한[9]의 모델을 한국어 의미역 결정에 적 용한다. CRF는 레이블 인접성 정보를 바탕으로 현재 레 이블을 추측하는 방법이다. 출력 레이블간의 의존성을 추가하기 위해 output layer를 다음과 같이 확장하였다.
𝑦 𝑡 = 𝑊;Gℎ(+ 𝑏G 𝑠 𝑥, 𝑦 = 𝐴(𝑦(<$, 𝑦()
K
:L$
+ 𝑦(
𝑙𝑜𝑔 𝑝(𝑦|𝑥) = 𝑠 𝑥, 𝑦 − 𝑙𝑜𝑔 𝑒𝑥𝑝 (𝑠 𝑥, 𝑦Q )
GQ
2015년 동계학술발표회 논문집
567
강원대학교 | IP: 114.70.234.*** | Accessed 2018/02/06 15:12(KST)
위 식에서 𝐴(𝑦(<$, 𝑦()는 의미역 태그 𝑦(<$에서 𝑦(로 전이 될 확률을 의미하고, 𝑠 𝑥, 𝑦 는 의미역 태그 열의 점수이 다. 𝑙𝑜𝑔 𝑝(𝑦|𝑥)를 구하기 위해 forward 알고리즘을 이용 하며, 최적의 태그 열을 구하기 위해 Viterbi search 알 고리즘을 적용한다. 그림 3은 Bidirectional LSTM CRF모 델의 구조를 나타낸다. 기존 LSTM CRF와 달리 양방향 으로 학습하기 때문에 현재 레이블 결정에 이전 단어와 다음 단어의 정보 모두를 볼 수 있다.
그림 3. Bidirectional LSTM CRF 구조
Bidirectional LSTM CRF 모델의 학습을 위해 Stochastic Gradient Descent(SGD)를 이용하여
−𝑙𝑜𝑔 𝑝(𝑦|𝑥) 를 최소화 하였고, Back-Propagation Through Time(BPTT) 알고리즘을 이용하였다.
4. 실험
본 논문에서 제안한 시스템을 기존 연구와 비교하기 위하여 기존 연구에서 사용한 Korean PropBank[10]를 학습 말뭉치로 사용하였고, 기존연구와 동일한 학습 및 평가 데이터를 구성하였다. 실험에 사용한 한국어 word embedding(단어 표현)은 word2vector[11]를 이용하여 구한 것을 사용하였다. feature embedding은 랜덤으로 초기화한 값을 사용하였고(평균 0, 분산 0.01), 과적합 문제를 줄이기 위해 Dropout[12] 기술을 projection layer와 hidden layer에 적용하였다(0.2, 0.5). 본 논문에 서 제시하고 있는 성능은 논항 인식 및 분류(AIC)에 해 당하며 성능 지표는 F1값 이다.
표 2. 한국어 의미역 결정 실험 결과(AIC, F1)
표 2는 한국어 의미역 결정 실험 결과이다. w/는 구문 분석 정보를 사용하였음을 의미하고 w/o는 본 논문에서 제안하는 구문 분석 정보를 사용하지 않는 end-to-end 방법을 의미한다. Structural SVM과 FFNN에서는 구문 분석 정보의 유무에 따라 의미역 결정 성능 변화가 확 연히(-2.81%, -2.79%) 나타났다. 반면 LSTM을 이용한 Backward LSTM CRF[3]와 Bidirectional LSTM CRF에서 는 경미한 성능하락을 보이거나 성능 하락이 나타나지 않았다(-0.42%, +0.01%). 이는 LSTM 구조가 멀리 있는
단어의 정보를 사용할지, 사용하지 않을지를 정하여 마 치 구문 분석 정보를 사용하는 것과 같은 효과를 나타 낸다고 볼 수 있다. 또한 Bidirectional LSTM CRF의 성 능이 Backward LSTM CRF보다 1.3%내지 1.8% 더 높게 나타났다. 이를 통해 이전 단어들의 정보뿐만 아니라 다 음 단어들의 정보를 같이 보는 것이 한국어 의미역 결 정 시스템 성능 향상에 도움이 됨을 알 수 있었다.
5. 결론
본 논문에서는 Bidirectional LSTM CRF 모델을 이용한 end-to-end 한국어 의미역 결정 시스템을 제안하고, 이를 한국어 의미역 결정에 적용하여 기존 Structural SVM, FFNN, Backward LSTM CRF 보다 더 높은 성능을 얻었다. 또한 Bidirectional LSTM CRF를 이용하여 문장 전체의 정보를 이용할 수 있을 뿐만 아니라 LSTM 구조 를 통해 구문 분석 정보를 사용하는 것과 같은 효과를 낼 수 있음을 알 수 있었다. 따라서 end-to-end 한국 어 의미역 결정 시스템이 구문 분석 정보를 사용하는 시스템에 비해 더 효율적임을 알 수 있었다.
감사의 글
이 논문은 2015년도 정부(미래창조과학부)의 재원으로 정보통 신기술진흥센터의 지원을 받아 수행된 연구임. (No.R0101- 15-0062, 휴먼 지식증강 서비스를 위한 지능 진화형 WiseQA 플랫폼 기술 개발)
참고문헌
[1] 이창기, 임수종, 김현기. Structural SVM 기반의 한국어 의 미역 결정. 정보과학회논문지 제42권 제2호, 220-226. 2015.
[2] 배장성, 이창기, 임수종. 딥 러닝을 이용한 한국어 의미역 결정. KCC, 690-692. 2015.
[3] 배장성, 이창기, 임수종. Backward LSTM CRF를 이용한 한국어 의미역 결정. HCLT, 194-197. 2015.
[4] Ronan Collobert, et al. Natural Language Processing (almost) from scratch. JMLR, 12:2493-2537. 2011.
[5] YAO, Kaisheng, et al. Spoken language understanding using long short-term memory neural networks. In: Spoken Language Technology Workshop(SLT), IEEE. 189-194. 2014.
[6] Punyakanok Vasin, et al. The importance of syntactic parsing and inference in semantic role labeling. Computational Linguistics, 257-287. 2008.
[7] Pradhan Sameer, et al. Semantic role labeling using different syntactic views. ACL, 2005.
[8] 김병수, 외 4인. 부트스트랩핑 알고리즘을 이용한 한국어 격조사의 의미역 결정. KCC, vol 33, no. 1. 2006.
[9] 이창기. Long Short-term Memory 기반의 Recurrnet Neural Network를 이용한 개체명 인식. KCC, 645-647. 2015.
[10] Martha Palmer, et al. Korean Propbank.
http://catalog.ldc.upenn.edu/LDC2006T03.
[11] Tomas Mikolov et al. Distributed Representations of Words and Phrases and their Compositionality. NIPS. 2013.
[12] G.E Dahl, et al. Improving deep neural networks for LVCSR using rectified linear units and dropout. ICASSP, International Conference on IEEE. p. 8609-8613. 2013.
구문 분석 정보 w/ w/o(end-to-end)
Structural SVM(baseline) FFNN
Backward LSTM CRF Bidirectional LSTM CRF
76.96 76.01 76.79 78.16
74.15(-2.81) 73.22(-2.79) 76.37(-0.42) 78.17(+0.01)
2015년 동계학술발표회 논문집
568
강원대학교 | IP: 114.70.234.*** | Accessed 2018/02/06 15:12(KST)